Course
Introduction to R
4 hr
3M
This R loops tutorial will look into the constructs available in R for looping, when the constructs should be used, and how to make use of alternatives, such as R’s vectorization feature, to perform your looping tasks more efficiently.
The post will present a few looping examples to then criticize and deprecate these in favor of the most popular vectorized alternatives amongst the very many that are available in the rich set of libraries that R offers.
In general, the advice of this R tutorial on loops would be: learn about loops. They offer you a detailed view of what it is supposed to happen at the elementary level as well as they provide you with an understanding of the data that you’re manipulating.
And after you have gotten a clear understanding of loops, get rid of them.
Put your effort into learning about vectorized alternatives. It pays off in terms of efficiency.
To practice interactively, try the chapter on loops in our intermediate R course.
“Looping”, “cycling”, “iterating” or just replicating instructions is an old practice that originated well before the invention of computers. It is nothing more than automating a multi-step process by organizing sequences of actions or ‘batch’ processes and by grouping the parts that need to be repeated.
All modern programming languages provide special constructs that allow for the repetition of instructions or blocks of instructions.
Broadly speaking, there are two types of these special constructs or loops in modern programming languages. Some loops execute for a prescribed number of times, as controlled by a counter or an index, incremented at each iteration cycle. These are part of the for loop family.
On the other hand, some loops are based on the onset and verification of a logical condition. The condition is tested at the start or the end of the loop construct. These variants belong to the while or repeat family of loops, respectively.
According to the R base manual, among the control flow commands, the loop constructs are for, while and repeat, with the additional clauses break and next.
Remember that control flow commands are the commands that enable a program to branch between alternatives, or to “take decisions”, so to speak.
You can always see these control flow commands by invoking ?Control at the RStudio command line.
?ControlThis flow chart shows the R loop structures:
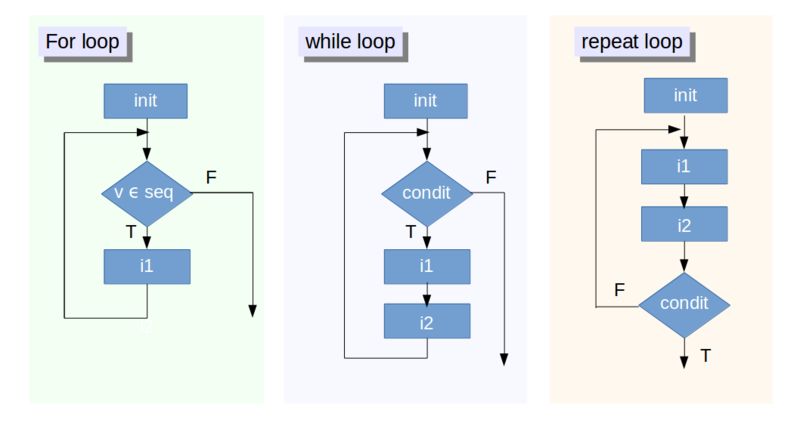
The next sections will take a closer look at each of these structures that are shown in the figure above. We will start our discussion with the structure on the left, and we will continue the next sections by gradually moving to the structures on the right.
For a video introduction to for loops and a follow-up exercise, try the For Loop chapter in our intermediate R course.
This loop structure, made of the rectangular box ‘init’ (or initialization), the diamond or rhombus decision, and the rectangular box i1 is executed a known number of times.
In flowchart terms, rectangular boxes mean something like “do something which does not imply decisions”. Rhombi or diamonds, on the other hand, are called “decision symbols” and therefore translate into questions which only have two possible logical answers, namely, True (T) or False (F).
Note that, to keep things simple, other possible symbols have been omitted from the figure.
One or more instructions within the initialization rectangle are followed by the evaluation of the condition on a variable which can assume values within a specified sequence. In the figure, this is represented by the diamond: the symbols mean “does the variable v’s current value belong to the sequence seq?”.
In other words, you are testing whether v’s current value is within a specified range. You normally define this range in the initialization, with something like 1:100 to ensure that the loop starts.
If the condition is not met and the resulting outcome is False, the loop is never executed. This is indicated by the loose arrow on the right of the for loop structure. The program will then execute the first instruction found after the loop block.
If the condition is verified, an instruction -or block of instructions- i1 is executed. And perhaps this block of instructions is another loop. In such cases, you speak of a nested loop.
Once this is done, the condition is then evaluated again. This is indicated by the lines going from i1 back to the top, immediately after the initialization box. In R -and in Python, it is possible to express this in plain English, by asking whether our variable belongs to a range of values or not.
Note that in other languages, for example in C, the condition is made more explicit with the use of a logical operator, such as greater or less than, equal to, …
Here is an example of a simple for loop:
# Create a vector filled with random normal values
u1 <- rnorm(30)
print("This loop calculates the square of the first 10 elements of vector u1")
# Initialize `usq`
usq <- 0.
for (i in 1:10) {
# i-th element of `u1` squared into `i`-th position of `usq`
usq[i] <- u1[i] * u1[i]
print(usq[i])
}
print(i)The for block is contained within curly braces. These can be placed either immediately after the test condition or beneath it, preferably followed by an indentation. None of this is compulsory, but the curly braces definitely enhance the readability of your code and allow to spot the loop block and potential errors within it easily.
Note that the vector of the squares, usq, is initialized. This would not be necessary in plain RStudio code, but in the markup version, knitr would not compile because a reference to the vector is not found before its use in the loop, thus throwing an error within RStudio. For more information on knitr, go to the R Markdown page.
Now that you know for loops can also be nested, you’re probably wondering why and when you would be using this in your code.
Well, suppose you wish to manipulate a bi-dimensional array by setting its elements to specific values.
Then you might do something like this:
# Insert your own integer here
my_int <- 42
nr <- as.integer(my_int)
# Create a `n` x `n` matrix with zeros
mymat <- matrix(0, nr, nr)
# For each row and for each column, assign values based on position
# These values are the product of two indexes
for (i in 1:dim(mymat)[1]) {
for (j in 1:dim(mymat)[2]) {
mymat[i, j] = i * j
}
}Tip: for more information on the matrix() function, visit R Documentation.
i runs over the lines and j runs over the columns.Well, you made the very familiar multiplication table that you should know by heart.
You can also choose an integer and then produce a table according to your choice: you can assign an integer to a variable if the table is square or to two variables if the table is rectangular. This variable will then serve as upper bounds to the indexes i and j.
# Show the first 10x10 chunk or the first `nr` x `nr` chunk
if (nr > 10) {
mymat[1:10, 1:10]
} else
mymat[1:nr, 1:nr]Note that to prevent the user from deluging the screen with huge tables, you put a condition at the end to print the first 10 x 10 chunk, only if the user asked for an integer greater than 10. Else, an n x n chunk will be printed.
The complete code looks like this:
# Insert your own integer here
my_int <- 42
nr <- as.integer(my_int)
# Create a `n` x `n` matrix with zeroes
mymat <- matrix(0, nr, nr)
# For each row and for each column, assign values based on position
# These values are the product of two indexes
for (i in 1:dim(mymat)[1]) {
for (j in 1:dim(mymat)[2]) {
mymat[i, j] = i * j
}
}
# Show the first 10x10 chunk or the first `nr` x `nr` chunk
if (nr > 10) {
mymat[1:10, 1:10]
} else
mymat[1:nr, 1:nr]The for loop is by far the most popular, and its construct implies that the number of iterations is fixed and known in advance, as in cases like “generate the first 200 prime numbers” or “enlist the 10 most important customers”.
But what if you do not know or control the number of iterations, and one or several conditions may occur which are not predictable beforehand?
For example, you may want to count the number of clients living in an area identified by a specified postal code, or the number of clicks on a web page banner within the last two days, or similar unforeseen events.
In cases like these, the while loop and its cousin repeat may come to the rescue…
The while loop, set in the middle of the figure above, is made of an initialization block as before, followed by a logical condition. This condition is typically expressed by the comparison between a control variable and a value, by using greater than, less than or equal to, but any expression that evaluates to a logical value, True or False, is legitimate.
If the result is False (F), the loop is never executed, as indicated by the loose arrow on the right of the figure. The program will then execute the first instruction it finds after the loop block.
If it is True (T), the instruction or block of instructions i1 is executed next.
Note that an additional instruction or block of instructions i2 was added: this serves as an update for the control variable, which may alter the result of the condition at the start of the loop, but this is not necessary. Or maybe you want to add an increment to a counter to keep trace of the number of iterations executed. The iterations cease once the condition evaluates to false.
The format is while(cond) expr, where cond is the condition to test and expr is an expression.
For example, the following loop asks the user with a User Defined Function or UDF to enter the correct answer to the universe and everything question. It will then continue to do so until the user gets the answer right:
# Your User Defined Function
readinteger <- function(){
n <- readline(prompt="Please, enter your ANSWER: ")
}
response <- as.integer(readinteger())
while (response!=42) {
print("Sorry, the answer to whatever the question MUST be 42");
response <- as.integer(readinteger());
}As a start, use a user defined function to get the user input before entering the loop. This loop will continue as long as the answer is not the expected 42.
In other words, you do this because otherwise, R would complain about the missing expression that was supposed to provide the required True or False -and in fact, it does not know ‘response’ before using it in the loop. You also do this because, if you answer right at first attempt, the loop will not be executed at all.
The repeat loop is located at the far right of the flow chart that you find above. This loop is similar to the while loop, but it is made so that the blocks of instructions i1 and i2 are executed at least once, no matter what the result of the condition.
Adhering to other languages, one could call this loop “repeat until” to emphasize the fact that the instructions i1 and i2 are executed until the condition remains False (F) or, equivalently, becomes True (T), thus exiting; but in any case, at least once.
As a variation of the previous example, you may write:
readinteger <- function(){
n <- readline(prompt="Please, enter your ANSWER: ")
}
repeat {
response <- as.integer(readinteger());
if (response == 42) {
print("Well done!");
break
} else print("Sorry, the answer to whatever the question MUST be 42");
}After the now familiar input function, you have the repeat loop whose block is executed at least once and that will terminate whenever the if condition is verified.
Note that you had to set a condition within the loop upon which to exit with the clause break. This clause introduces us to the notion of exiting or interrupting cycles within loops.
So how do you exit from a loop?
In other terms, aside from the “natural” end of the loop, which occurs either because you reached the prescribed number of iterations (for) or because you met a condition (while, repeat), can you stop or interrupt the loop?
And if yes, how?
The break statement responds to the first question: you have seen this in the last example.
breakWhen the R interpreter encounters a break, it will pass control to the instruction immediately after the end of the loop (if any). In the case of nested loops, the break will permit to exit only from the innermost loop.
Here’s an example.
This chunk of code defines an m x n matrix of zeros and then enters a nested for loop to fill the locations of the matrix, but only if the two indexes differ. The purpose is to create a lower triangular matrix, that is a matrix whose elements below the main diagonal are non-zero. The others are left untouched to their initialized zero value.
When the indexes are equal and thus the condition in the inner loop, which runs over the column index j is fulfilled, a break is executed and the innermost loop is interrupted with a direct jump to the instruction following the inner loop. This instruction is a print() instruction. Then, control gets to the outer for condition (over the rows, index i), which is evaluated again.
If the indexes differ, the assignment is performed and the counter is incremented by 1. At the end, the program prints the counter ctr, which contains the number of elements that were assigned.
# Make a lower triangular matrix (zeroes in upper right corner)
m = 10
n = 10
# A counter to count the assignment
ctr = 0
# Create a 10 x 10 matrix with zeroes
mymat = matrix(0, m, n)
for (i in 1:m) {
for (j in 1:n) {
if (i == j) {
break
} else {
# you assign the values only when i<>j
mymat[i, j] = i * j
ctr = ctr + 1
}
}
print(i * j)
}
# Print how many matrix cells were assigned
print(ctr)Note that it might be a bit over-cautious to put curly brackets even when they’re not strictly necessary. You usually do it to make sure that whatever is opened with a {, is also closed with a }. So if you notice unmatched numbers of { or }, you know there is an error, although the opposite is not necessarily true!
next in Loopsnext discontinues a particular iteration and jumps to the next cycle. In fact, it jumps to the evaluation of the condition holding the current loop.
In other languages, you may find the (slightly confusing) equivalent called “continue”, which means the same: wherever you are, upon the verification of the condition, jump to the evaluation of the loop.
A simpler example of keeping the loop ongoing while discarding a particular cycle upon the occurrence of a condition is:
m = 20
for (k in 1:m) {
if (!k %% 2)
next
print(k)
}This piece of code prints all uneven numbers within the interval 1:m (here m=20). In other words, all integers except the ones with non zero remainder when divided by 2 (thus the use of the modulus operand %%), as specified by the if test, will be printed.
Numbers whose remainder is zero will not be printed, as the program jumps to the evaluation of the i in 1:m condition and ignores any instruction that might follow. In this case, print(k) is ignored.
repeat: make sure that a termination is explicitly set by testing a condition or you can end up in an infinite loop.All this is good and well, but when should you use loops in R and when not?
Every time some operation(s) has to be repeated, a loop may come in handy.
You only need to specify how many times or upon which conditions those operations need execution: you assign initial values to a control loop variable, perform the loop and then, once the loop has finished, you typically do something with the results.
But when are you supposed to use loops?
Couldn’t you replicate the desired instruction for the sufficient number of times?
Well, a rule of thumb could be that if you need to perform an action (say) three times or more, then a loop would serve you better. It makes the code more compact, readable, and maintainable and you may save some typing: let’s say you discover that a certain instruction needs to be repeated once more than initially foreseen: instead of re-writing the full instruction, you can just alter the value of a variable in the test condition.
Yet, the peculiar nature of R suggests not to use loops at all(!) whenever alternatives exist.
Luckily, there are some alternatives!
R enjoys a feature that few programming languages do, which is called vectorization.
As the word suggest, vectorization is the operation of converting repeated operations on simple numbers (“scalars”) into single operations on vectors or matrices. You have seen several examples of this in the subsections above.
Now, a vector is the elementary data structure in R and is “a single entity consisting of a collection of things”, according to the R base manual.
So, a collection of numbers is a numeric vector.
If you combine vectors (of the same length), you obtain a matrix. You can do this vertically or horizontally, using different R instructions. Thus in R, a matrix is seen as a collection of horizontal or vertical vectors. By extension, you can vectorize repeated operations on vectors.
Many of the above loop constructs can be made implicit by using vectorization.
I say “implicit”, because they do not really disappear. At a lower level, the alternative vectorized form translates into code which will contain one or more loops in the lower level language the form was implemented and compiled (Fortran, C, or C++ ).
These are hidden to the user and are usually faster than the equivalent explicit R code, but unless you’re planning to implement your own R functions using one of those languages, this is totally transparent to you.
The most elementary case you can think of is the addition of two vectors v1 and v2 into a vector v3, which can be done either element-by-element with a for loop:
v1 <- c(3,4,5)
v2 <- c(3,4,6)
v3 <- c(0,0,0)
n = length(v1)
for (i in 1:n) {
v3[i] <- v1[i] + v2[i]
}
v3Or you can also use the “native” vectorized form:
v3 = v1 + v2
v3Note that you say “native” because R can recognize all the arithmetic operators as acting on vectors and matrices.
Similarly, for two matrices A and B, instead of adding the elements of A[i,j] and B[i,j] in corresponding positions, for which you need to take care of two indexes i and j, you tell R to do the following:
A <- matrix(1:6, nrow = 3, ncol = 2)
B <- matrix(c(2,4,3,1,5,7), nrow=3, ncol=2)
C= A + B
CAnd this is very simple indeed!
Why would vectorization run faster, given that the number of elementary operations is seemingly the same?
This is best explained by looking at the internal nuts and bolts of R, which would demand a separate post, but succinctly: in the first place, R is an interpreted language and as such, all the details about variable definition are taken care by the interpreter. You do not need to specify that a number is a floating point or allocate memory using a pointer in memory, for example.
The R interpreter “understands” these issues from the context as you enter your commands, but it does so on a command-by-command basis. It will therefore need to deal with such definitions every time you issue a given command, even if you just repeat it.
A compiler, instead, solves literally all the definitions and declarations at compilation time over the entire code; the latter is translated into a compact and optimized binary code, before you try to execute anything. Now, as R functions are written in one of these lower-level languages, they are more efficient.
In practice, if one looked at the low-level code, one would discover calls to C or C++, usually implemented within what is called a wrapper code.
Secondly, in languages supporting vectorization (like R or Matlab), every instruction making use of a numeric datum, acts on an object which is natively defined as a vector, even if only made of one element. This is the default when you define, for example, a single numeric variable: its inner representation in R will always be a vector, despite it being made of one number only.
The loops continue to exist under the hood, but at the lower and much faster C/C++ compiled level. The advantage of having a vector means that the definitions are solved by the interpreter only once, on the entire vector, irrespective of its size, in contrast to a loop performed on a scalar, where definitions and allocations need to be done on a element by element basis, and this is slower.
Finally, dealing with native vector format allows to utilize very efficient Linear Algebra routines (like BLAS or Basic Linear Algebra Subprograms), so that when executing vectorized instructions, R leverages on these efficient numerical routines. So the message would be, if possible, to process whole data structures within a single function call to avoid all the copying operations that are executed.
But enough with digressions, let’s make a general example of vectorization, and then in the next subsection, you’ll dive into more specific and popular R vectorized functions to substitute loops.
Let’s go back to the notion of “growing data”, a typically inefficient way of “updating” a data frame.
First, you create an m x n matrix with replicate(m, rnorm(n)) with m=10 column vectors of n=10 elements each, constructed with rnorm(n), which creates random normal numbers.
Then you transform it into a data frame (thus 10 observations of 10 variables) and perform an algebraic operation on each element using a nested for loop: at each iteration, a sinusoidal function increments every element that is referred by the two indexes.
The following example is a bit artificial, but it could represent the addition of a signal to some random noise:
# This is a bad loop with 'growing' data
set.seed(42)
m = 10
n = 10
# Create matrix of normal random numbers
mymat <- replicate(m, rnorm(n))
# Transform into data frame
mydframe <- data.frame(mymat)
for (i in 1:m) {
for (j in 1:n) {
mydframe[i, j] <- mydframe[i, j] + 10 * sin(0.75 * pi)
print(mydframe)
}
}Here, most of the execution time consists of copying and managing the loop.
Let’s see how a vectorized solution looks like:
set.seed(42)
m = 10
n = 10
mymat <- replicate(m, rnorm(n))
mydframe <- data.frame(mymat)
mydframe <- mydframe + 10 * sin(0.75 * pi)
mydframeThis looks simpler: the last line takes the place of the nested for loop. Note the use of the set.seed() to ensure that the two implementations give exactly the same result.
Let’s now quantify the execution time for the two solutions.
You can do this by using R system commands, like system.time() to which a chunk of code can be passed like this:
Tip: just put the code you want to evaluate in between the parentheses of the system.time() function.
# Insert `system.time()` to measure loop execution
for (i in 1:m) {
for (j in 1:n) {
mydframe[i, j] <- mydframe[i, j] + 10 * sin(0.75 * pi)
}
}
# Add `system.time()` to measure vectorized execution
mydframe <- mydframe + 10 * sin(0.75 * pi) In the code chunk above, you do the job of choosing m and n, the matrix creation and its transformation into a data frame only once at the start, and then evaluate the for chunk against the “one-liner” of the vectorized version with the two separate call to system.time().
You see that already with a minimal setting of m=n=10 the vectorized version is 7 time faster, although for such low values, it is barely important for the user.
Differences become noticeable (at the human scale) if you put m=n=100, whereas increasing to 1000 causes the for loop look like hanging for several tens of seconds, whereas the vectorized form still performs in a blink of an eye.
For m=n=10000 the for loop hangs for more than a minute while the vectorized requires 2.54 sec. Of course, these measures should be taken lightly and will depend on the hardware and software configuration, possibly avoiding overloading your laptop with a few dozens of open tabs in your internet browser, and several applications running in the background; but these measures are illustrative of the differences.
In fairness, the increase of m and n severely affects also the matrix generation as you can easily see by placing another system.time() call around the replication function.
You are invited to play around with m and n to see how the execution time changes, by plotting the execution time as a function of the product m x n. This is the relevant indicator, because it expresses the dimension of the matrices created. It thus also quantifies the number of iterations necessary to complete the task via the nset-ed for loop.
So this is an example of vectorization. But there are many others. In R News, a newsletter for the R project at page 46, there are very efficient functions for calculating sums and means for certain dimensions in arrays or matrices, like: rowSums(), colSums(), rowMeans(), and colMeans().
Furthermore, the newsletter also mentions that “…the functions in the ‘apply’ family, named [s,l,m,t]apply, are provided to apply another function to the elements/dimensions of objects. These ‘apply’ functions provide a compact syntax for sometimes rather complex tasks that is more readable and faster than poorly written loops.”.
apply(): an example# define matrix `mymat` by replicating the sequence `1:5` for `4` times and transforming into a matrix
mymat <- matrix(rep(seq(5), 4), ncol = 5)
# `mymat` sum on rows
apply(mymat, 1, sum)
# `mymat` sum on columns
apply(mymat, 2, sum)
# With user defined function within the apply that adds any number `y` to the sum of the row
# `y` is set at `4.5`
apply(mymat, 1, function(x, y)
sum(x) + y, y = 4.5)
# Or produce a summary column wise for each column
apply(mymat, 2, function(x, y)
summary(mymat))You use data frames often: in this particular case, you must ensure that the data have the same type or else, forced data type conversions may occur, which is most likely not what you want. For example, in a mixed text and number data frame, numeric data will be converted to strings or characters.
So now, this journey brought us from the fundamental loop constructs used in programming to the (basic) notion of vectorization and to an example of the use of one of the apply() family of functions, which come up frequently in R.
In terms of code flow control, you dealt only with loops: for, while, repeat and the way to interrupt and exit these.
As the last subsections hint that loops in R should be avoided, you may ask why on earth should you learn about them.
Now, in my opinion, you should learn these programming structures because:
If for loops in R prove no challenge to you anymore after reading this tutorial, you might consider taking DataCamp's Intermediate R course. This course will strengthen your knowledge of the topics in Intermediate R with a bunch of new and fun exercises. If, however, loops hold no secrets for you any longer, DataCamp's Writing Functions in R course, taught by Hadley and Charlotte Wickham could interest you. Also, check out the For Loops in R tutorial.
Run and edit the code from this tutorial online
Run codeLearn more about R
Course
Course
Course
Tutorial
Ryan Sheehy
Tutorial
Aditya Sharma
Tutorial
Olivia Smith
Tutorial
Olivia Smith
Tutorial
Olivia Smith
Tutorial
Carlo Fanara