
Courses
Gradient Boosting Cực Mạnh với XGBoost
4 giờ
61.1K
Python là một trong những ngôn ngữ lập trình phổ biến nhất được sử dụng trên nhiều lĩnh vực công nghệ, đặc biệt là khoa học dữ liệu và học máy. Python cung cấp một ngôn ngữ cấp cao, hướng đối tượng, dễ viết mã, với bộ sưu tập thư viện phong phú cho vô số trường hợp sử dụng. Nó có hơn 200.000 thư viện.
Một trong những lý do khiến Python rất giá trị đối với khoa học dữ liệu là bộ sưu tập khổng lồ các thư viện thao tác dữ liệu, trực quan hóa dữ liệu, học máy và học sâu. Do hệ sinh thái thư viện khoa học dữ liệu của Python quá phong phú, hầu như không thể bao quát hết trong một bài viết. Danh sách các thư viện hàng đầu dưới đây chỉ tập trung vào năm mảng chính:
Còn nhiều lĩnh vực khác không được đề cập trong danh sách này; ví dụ như MLOps, Dữ liệu Lớn, và Thị giác Máy tính. Danh sách trong blog này không theo thứ tự cụ thể nào và không nhằm coi như một bảng xếp hạng.
NumPy là một trong những thư viện Python mã nguồn mở được dùng rộng rãi nhất, chủ yếu cho tính toán khoa học. Các hàm toán học tích hợp cho phép tính toán siêu nhanh và hỗ trợ dữ liệu đa chiều cùng ma trận lớn. Nó cũng được dùng trong đại số tuyến tính. Mảng NumPy thường được ưu tiên hơn danh sách vì sử dụng ít bộ nhớ hơn và thuận tiện, hiệu quả hơn.
Theo trang web của NumPy, đây là một dự án mã nguồn mở nhằm kích hoạt tính toán số trong Python. Nó được tạo vào năm 2005 và phát triển dựa trên công trình ban đầu của các thư viện Numeric và Numarray. Một trong những lợi thế lớn của NumPy là được phát hành theo giấy phép BSD sửa đổi, nhờ đó sẽ luôn miễn phí cho mọi người dùng.
NumPy được phát triển công khai trên GitHub với sự đồng thuận của cộng đồng NumPy và cộng đồng Python khoa học rộng hơn. Bạn có thể tìm hiểu thêm trong khóa học Numpy nhập môn của chúng tôi.
⭐ Sao GitHub: 25K | Tổng lượt tải: 2,4 tỷ
Pandas là một thư viện mã nguồn mở thường được dùng trong khoa học dữ liệu. Chủ yếu dùng để phân tích, thao tác và làm sạch dữ liệu. Pandas cho phép mô hình hóa và phân tích dữ liệu đơn giản mà không cần viết quá nhiều mã. Như trên trang web nêu rõ, pandas là công cụ mã nguồn mở nhanh, mạnh, linh hoạt và dễ dùng cho phân tích và thao tác dữ liệu. Một số tính năng chính của thư viện này gồm:
Bắt đầu với pandas rất đơn giản và trực quan. Bạn có thể xem Phân tích hoạt động của cảnh sát với pandas của DataCamp để học cách dùng pandas trên các tập dữ liệu thực tế.
⭐ Sao GitHub: 41K | Tổng lượt tải: 1,6 tỷ
Trong khi Pandas vẫn là mặc định cho dữ liệu nhỏ, Polars đã trở thành tiêu chuẩn cho xử lý dữ liệu hiệu năng cao. Được viết bằng Rust, nó dùng bộ máy "đánh giá lười" để xử lý các tập dữ liệu (10GB–100GB+) vốn thường làm treo máy thiếu RAM. Khác với Pandas thực thi thao tác tuần tự, Polars tối ưu hóa truy vấn đầu-cuối và chạy song song trên mọi lõi CPU sẵn có.
Nó được thiết kế như một bản nâng cấp thay thế trực tiếp cho khối lượng công việc nặng, cung cấp cú pháp thường dễ đọc hơn và nhanh hơn 10–50 lần so với DataFrame truyền thống.
Dưới đây là ví dụ mã lọc, nhóm và tổng hợp chọn lọc từ một tập dữ liệu CSV khổng lồ:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ Sao GitHub: 40K+ | Trạng thái: Tiêu chuẩn Hiệu năng Cao
Matplotlib là một thư viện toàn diện để tạo các trực quan hóa Python tĩnh, tương tác và động. Rất nhiều gói của bên thứ ba mở rộng và xây dựng trên chức năng của Matplotlib, bao gồm nhiều giao diện vẽ cấp cao (Seaborn, HoloViews, ggplot, v.v.)
Matplotlib được thiết kế để có chức năng tương đương MATLAB, với lợi thế bổ sung là có thể dùng Python. Nó cũng có ưu điểm là miễn phí và mã nguồn mở. Nó cho phép người dùng trực quan hóa dữ liệu bằng nhiều loại biểu đồ khác nhau, bao gồm nhưng không giới hạn ở scatterplot, histogram, biểu đồ cột, biểu đồ sai số và boxplot. Hơn nữa, mọi biểu đồ đều có thể triển khai chỉ với vài dòng mã.
Ví dụ biểu đồ phát triển bằng Matplotlib
Bắt đầu với Matplotlib qua hướng dẫn từng bước này.
⭐ Sao GitHub: 18,7K | Tổng lượt tải: 653 triệu
Một khung trực quan hóa dữ liệu Python phổ biến khác dựa trên Matplotlib, Seaborn là giao diện cấp cao để tạo các trực quan thống kê đẹp mắt và hữu ích, vốn rất quan trọng để nghiên cứu và thấu hiểu dữ liệu. Thư viện Python này gắn kết chặt chẽ với các cấu trúc dữ liệu của NumPy và pandas. Nguyên tắc cốt lõi của Seaborn là biến trực quan hóa thành thành phần thiết yếu của phân tích và khám phá dữ liệu; do đó, các thuật toán vẽ của nó sử dụng data frame bao trùm toàn bộ tập dữ liệu.
Thư viện ví dụ Seaborn
Hướng dẫn Seaborn cho người mới bắt đầu này là tài nguyên tuyệt vời giúp bạn làm quen với thư viện trực quan hóa năng động này.
⭐ Sao GitHub: 11,6K | Tổng lượt tải: 180 triệu
Plotly, thư viện đồ thị mã nguồn mở cực kỳ phổ biến, có thể dùng để tạo các trực quan hóa dữ liệu tương tác. Plotly được xây dựng trên thư viện JavaScript Plotly (plotly.js) và có thể dùng để tạo trực quan hóa web có thể lưu thành tệp HTML hoặc hiển thị trong Jupyter notebook và ứng dụng web bằng Dash.
Nó cung cấp hơn 40 loại biểu đồ độc đáo, như scatter, histogram, đường, cột, tròn, thanh sai số, box plot, nhiều trục, sparkline, dendrogram và biểu đồ 3D. Plotly còn có biểu đồ đường đồng mức, vốn không quá phổ biến ở các thư viện trực quan hóa dữ liệu khác.
Nếu bạn muốn trực quan hóa tương tác hoặc đồ họa dạng bảng điều khiển, Plotly là lựa chọn tốt thay thế Matplotlib và Seaborn. Hiện nó được phát hành theo giấy phép MIT.
Bạn có thể bắt đầu làm chủ Plotly hôm nay với khóa học trực quan hóa Plotly.
⭐ Sao GitHub: 14,7K | Tổng lượt tải: 190 triệu
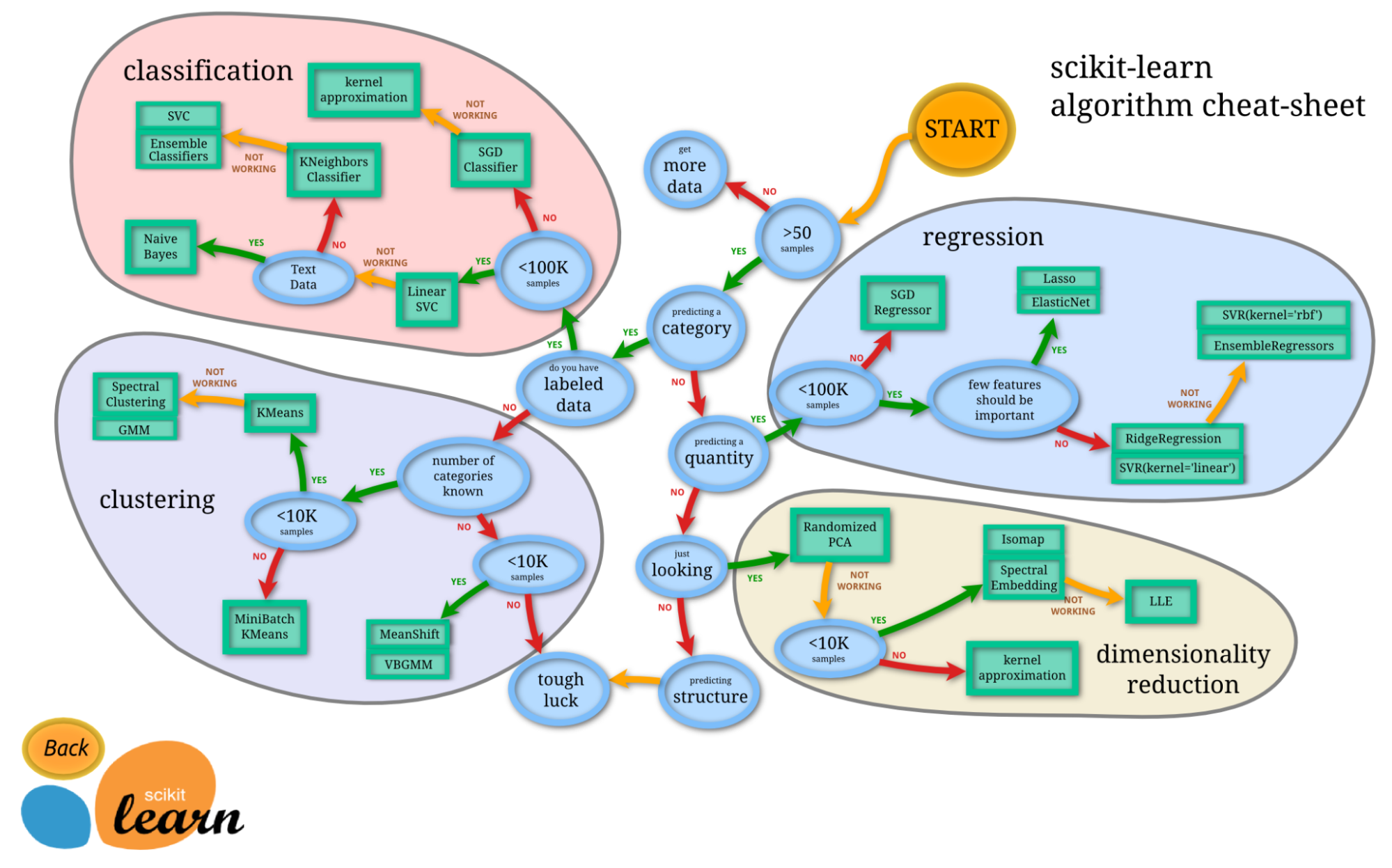
Cụm từ học máy và scikit-learn gần như không thể tách rời. Scikit-learn là một trong những thư viện học máy được dùng nhiều nhất trong Python. Được xây dựng trên NumPy, SciPy và Matplotlib, đây là thư viện Python mã nguồn mở có thể dùng thương mại theo giấy phép BSD. Nó là công cụ đơn giản và hiệu quả cho các tác vụ phân tích dữ liệu dự đoán.
Ra mắt ban đầu năm 2007 như một dự án Google Summer of Code, Scikit-learn là dự án do cộng đồng dẫn dắt; tuy nhiên, các khoản tài trợ từ tổ chức và tư nhân giúp đảm bảo tính bền vững.
Điều tuyệt vời nhất ở scikit-learn là rất dễ sử dụng.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Ghi công: Mã được trích lại từ tài liệu chính thức của scikit-learn.
Bạn có thể tự thử scikit-learn với hướng dẫn scikit-learn cho người mới bắt đầu này.
⭐ Sao GitHub: 57K | Tổng lượt tải: 703 triệu
Thời kỳ các Nhà khoa học Dữ liệu chỉ bàn giao các báo cáo PDF tĩnh đã qua. Streamlit biến các script Python thành ứng dụng web tương tác, có thể chia sẻ chỉ trong vài phút. Không cần kiến thức HTML, CSS hay JavaScript. Năm 2025, nó được dùng rộng rãi để xây dựng công cụ nội bộ, nguyên mẫu bảng điều khiển và bản demo mô hình tương tác cho các bên liên quan.
Với các lệnh API đơn giản như st.write() và st.slider(), bạn có thể xây dựng frontend phản ứng theo thời gian thực với thay đổi dữ liệu, thu hẹp khoảng cách giữa phân tích và kỹ thuật.
⭐ Sao GitHub: 42K+ | Trạng thái: Thiết yếu cho Triển khai
Vốn là công cụ phát triển web, Pydantic nay là nền tảng của ngăn xếp AI. Nó thực hiện xác thực dữ liệu và quản lý thiết lập bằng chú thích kiểu của Python. Trong kỷ nguyên LLM, đảm bảo dữ liệu (và đầu ra mô hình) tuân thủ nghiêm ngặt một schema cụ thể là điều then chốt.
Pydantic là động cơ đứng sau các thư viện như LangChain và Hugging Face, đảm bảo các đầu ra JSON lộn xộn từ mô hình AI được ép thành các đối tượng Python có cấu trúc, hợp lệ và không làm hỏng mã hạ nguồn của bạn.
⭐ Sao GitHub: 26K+ | Trạng thái: Hạ tầng Trọng yếu
LightGBM là thư viện tăng cường độ dốc mã nguồn mở cực kỳ phổ biến, sử dụng các thuật toán dựa trên cây. Nó mang lại các ưu điểm sau:
Có thể dùng cho cả bài toán giám sát phân loại và hồi quy. Bạn có thể xem tài liệu chính thức hoặc GitHub để tìm hiểu thêm về framework tuyệt vời này.
⭐ Sao GitHub: 15,8K | Tổng lượt tải: 162 triệu
XGBoost là một thư viện tăng cường độ dốc phân tán được sử dụng rộng rãi, được tạo ra để có tính di động, linh hoạt và hiệu quả. Nó cho phép triển khai các thuật toán học máy trong khung tăng cường độ dốc. XGBoost cung cấp (GBDT) cây quyết định tăng cường độ dốc, một kỹ thuật tăng cường cây song song mang lại lời giải nhanh và chính xác cho nhiều bài toán khoa học dữ liệu. Cùng một mã có thể chạy trên các môi trường phân tán chính (Hadoop, SGE, MPI) và giải vô số bài toán.
XGBoost đã trở nên rất phổ biến vài năm gần đây nhờ giúp các cá nhân và đội ngũ giành chiến thắng hầu như mọi cuộc thi dữ liệu có cấu trúc trên Kaggle. Ưu điểm của XGBoost gồm:
XGBoost được phát triển và bảo trì bởi các thành viên cộng đồng tích cực và được cấp phép theo giấy phép Apache. Hướng dẫn XGBoost này là tài nguyên tuyệt vời nếu bạn muốn tìm hiểu thêm.
⭐ Sao GitHub: 25,2K | Tổng lượt tải: 179 triệu
Catboost là thư viện tăng cường độ dốc trên cây quyết định nhanh, mở rộng, hiệu năng cao dùng cho xếp hạng, phân loại, hồi quy và các tác vụ học máy khác cho Python, R, Java và C++. Hỗ trợ tính toán trên CPU và GPU.
Với tư cách là hậu duệ của thuật toán MatrixNet, nó được dùng rộng rãi cho nhiệm vụ xếp hạng, dự báo và gợi ý. Nhờ tính phổ dụng, nó có thể áp dụng trên nhiều lĩnh vực và nhiều loại bài toán.
Các ưu điểm của CatBoost theo kho lưu trữ của họ là:
⭐ Sao GitHub: 7,5K | Tổng lượt tải: 53 triệu
Statsmodels cung cấp các lớp và hàm cho phép người dùng ước lượng nhiều mô hình thống kê, thực hiện kiểm định thống kê và khám phá dữ liệu thống kê. Một danh sách toàn diện các thống kê kết quả được cung cấp cho mỗi bộ ước lượng. Độ chính xác của kết quả sau đó có thể được kiểm tra đối chiếu với các gói thống kê hiện có.
Hầu hết kết quả kiểm định trong thư viện đã được kiểm chứng với ít nhất một gói thống kê khác: R, Stata hoặc SAS. Một số tính năng của statsmodels:
Khóa học statsmodels nhập môn này là điểm khởi đầu tuyệt vời nếu bạn muốn tìm hiểu thêm.
⭐ Sao GitHub: 9,2K | Tổng lượt tải: 161 triệu
Bộ thư viện phần mềm mã nguồn mở RAPIDS thực thi toàn bộ pipeline khoa học dữ liệu và phân tích hoàn toàn trên GPU. Nó mở rộng liền mạch từ máy trạm GPU đến máy chủ đa GPU và cụm nhiều nút với Dask. Dự án được NVIDIA hỗ trợ và cũng dựa vào Numba, Apache Arrow và nhiều dự án mã nguồn mở khác.
cuDF là thư viện DataFrame trên GPU dùng để nạp, nối, tổng hợp, lọc và thao tác dữ liệu. Nó được phát triển dựa trên định dạng bộ nhớ theo cột trong Apache Arrow. Nó cung cấp API tương tự pandas, quen thuộc với kỹ sư dữ liệu & nhà khoa học dữ liệu, cho phép họ dễ dàng tăng tốc quy trình làm việc mà không cần đi sâu vào lập trình CUDA.
cuML là bộ thư viện triển khai các thuật toán học máy và các hàm nguyên thủy toán học có API tương thích với các dự án RAPIDS khác. Nó cho phép nhà khoa học dữ liệu, nhà nghiên cứu và kỹ sư phần mềm chạy các tác vụ ML dạng bảng truyền thống trên GPU mà không cần đi sâu vào lập trình CUDA. API Python của cuML thường tương đồng với scikit-learn.
Khung tối ưu siêu tham số mã nguồn mở này chủ yếu dùng để tự động hóa tìm kiếm siêu tham số. Nó sử dụng vòng lặp, điều kiện và cú pháp Python để tự động tìm siêu tham số tối ưu, có thể tìm kiếm không gian lớn và cắt tỉa các thử nghiệm kém tiềm năng để cho kết quả nhanh hơn. Tốt nhất là nó dễ song song hóa và mở rộng trên các tập dữ liệu lớn.
Các tính năng chính theo kho GitHub của họ:
⭐ Sao GitHub: 9,1K | Tổng lượt tải: 18 triệu
Thư viện học máy mã nguồn mở cực kỳ phổ biến này tự động hóa quy trình làm việc học máy trong Python với rất ít mã. Đây là công cụ đầu-cuối cho quản lý mô hình và học máy, có thể tăng tốc mạnh mẽ chu kỳ thử nghiệm.
So với các thư viện học máy mã nguồn mở khác, PyCaret cung cấp giải pháp ít mã có thể thay thế hàng trăm dòng mã chỉ bằng vài dòng. Điều này khiến thử nghiệm nhanh và hiệu quả theo cấp số nhân.
PyCaret hiện được phát hành theo giấy phép MIT. Để tìm hiểu thêm về PyCaret, bạn có thể xem tài liệu chính thức hoặc kho GitHub của họ hoặc xem hướng dẫn PyCaret nhập môn này.
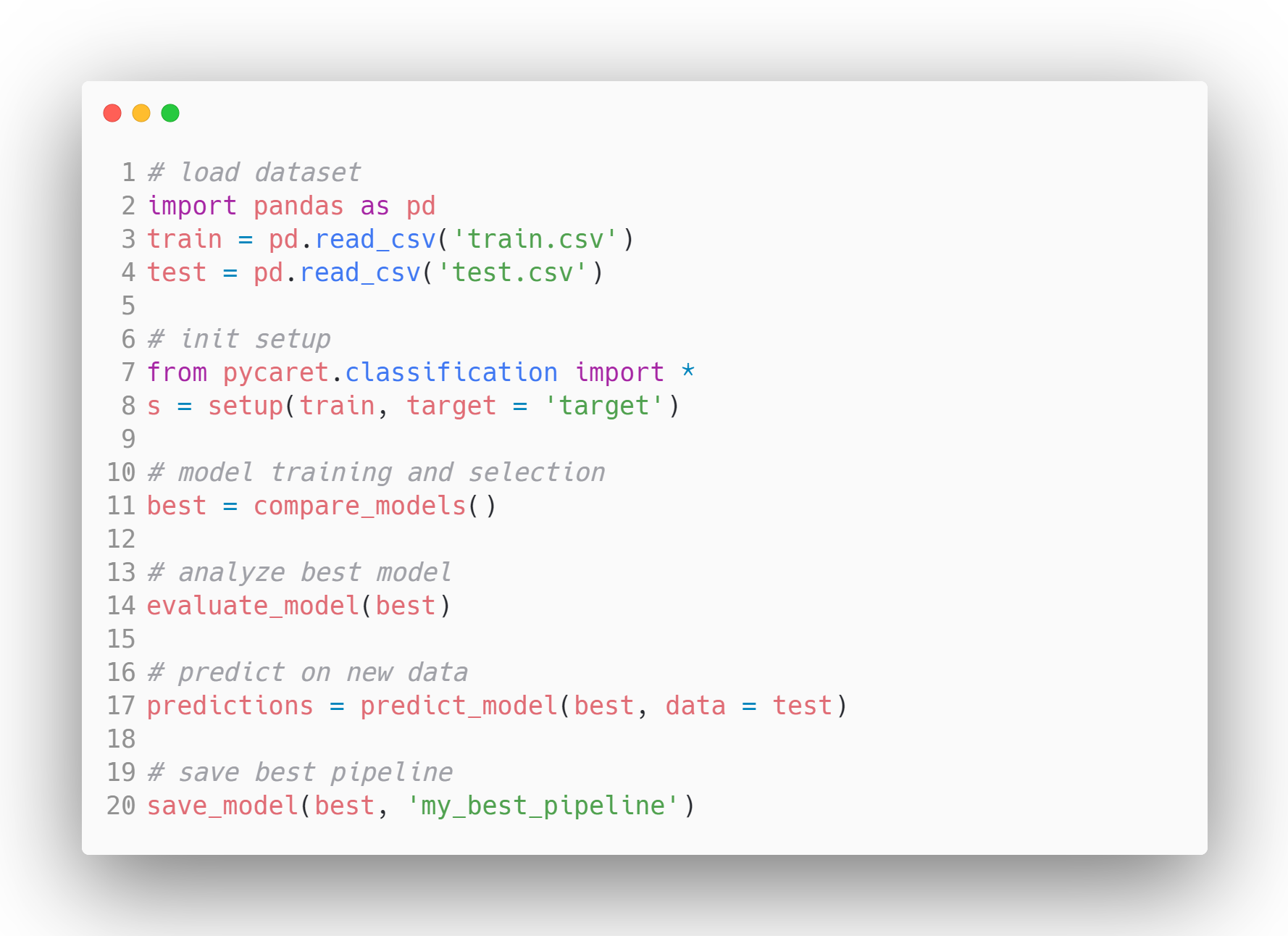
Quy trình mô hình minh họa trong PyCaret - Nguồn
⭐ Sao GitHub: 8,1K | Tổng lượt tải: 3,9 triệu
H2O là nền tảng học máy và phân tích dự đoán cho phép xây dựng mô hình học máy trên dữ liệu lớn. Nó cũng cung cấp khả năng đưa các mô hình đó vào sản xuất dễ dàng trong môi trường doanh nghiệp.
Mã lõi của H2O được viết bằng Java. Các thuật toán sử dụng khung Java Fork/Join cho đa luồng và được triển khai trên nền tảng khung Map/Reduce phân tán của H2O.
H2O được cấp phép theo Apache License, Version 2.0, và có sẵn cho các ngôn ngữ Python, R và Java. Để tìm hiểu thêm về H2O AutoML, hãy xem tài liệu chính thức.
⭐ Sao GitHub: 10,6K | Tổng lượt tải: 15,1 triệu
Auto-sklearn là bộ công cụ học máy tự động và là sự thay thế phù hợp cho mô hình scikit-learn. Nó tự động tinh chỉnh siêu tham số và lựa chọn thuật toán, tiết kiệm đáng kể thời gian cho người làm học máy. Thiết kế của nó phản ánh các tiến bộ gần đây trong siêu học, xây dựng tổ hợp và tối ưu hóa Bayes.
Được xây dựng như tiện ích bổ sung cho scikit-learn, auto-sklearn dùng quy trình tìm kiếm Tối ưu hóa Bayes để xác định pipeline mô hình hoạt động tốt nhất cho một tập dữ liệu nhất định.
Auto-sklearn cực kỳ dễ dùng và có thể áp dụng cho cả bài toán giám sát phân loại và hồi quy.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Nguồn: Ví dụ trích lại từ tài liệu chính thức của auto-sklearn.
Để tìm hiểu thêm về auto-sklearn, hãy xem kho GitHub của họ.
⭐ Sao GitHub: 7,3K | Tổng lượt tải: 675K
FLAML là thư viện Python nhẹ tự động tìm các mô hình học máy chính xác. Nó tự động chọn bộ học và siêu tham số, tiết kiệm đáng kể thời gian và công sức cho người làm học máy. Theo kho GitHub của họ, một số tính năng của FLAML là:
Chỉ với ba dòng mã, bạn có thể có một estimator kiểu scikit-learn với động cơ AutoML nhanh này.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Nguồn: Ví dụ trích lại từ kho GitHub chính thức
⭐ Sao GitHub: 3,5K | Tổng lượt tải: 456K
Trong khi các thư viện AutoML khác tập trung vào tốc độ, AutoGluon (phát triển bởi Amazon) tập trung vào độ vững và độ chính xác tiên tiến. Nó nổi tiếng với chiến lược "xếp chồng tổ hợp nhiều lớp", thường cho phép vượt trội hơn các mô hình do con người tinh chỉnh trên các benchmark dữ liệu dạng bảng.
Nó không chỉ hỗ trợ dữ liệu dạng bảng mà còn cả bài toán đa phương thức. Nghĩa là bạn có thể huấn luyện một bộ dự đoán duy nhất trên tập dữ liệu chứa đồng thời các cột văn bản, hình ảnh và số mà không cần kỹ thuật đặc trưng phức tạp.
Đoạn mã sau cho thấy cú pháp AutoGluon:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ Sao GitHub: 10K+ | Trạng thái: Độ chính xác Hàng đầu
TensorFlow là thư viện mã nguồn mở phổ biến cho tính toán số hiệu năng cao do nhóm Google Brain tại Google phát triển, và là trụ cột trong lĩnh vực nghiên cứu học sâu.
Như trên trang chính thức nêu, TensorFlow là nền tảng mã nguồn mở đầu-cuối cho học máy. Nó cung cấp bộ công cụ, thư viện và tài nguyên cộng đồng rộng lớn, linh hoạt cho nhà nghiên cứu và nhà phát triển học máy.
Một số tính năng của TensorFlow khiến nó trở thành thư viện học sâu phổ biến và được dùng rộng rãi:
Để tìm hiểu thêm về TensorFlow, hãy xem hướng dẫn chính thức hoặc kho GitHub, hoặc tự dùng theo hướng dẫn TensorFlow từng bước này.
⭐ Sao GitHub: 180K | Tổng lượt tải: 384 triệu
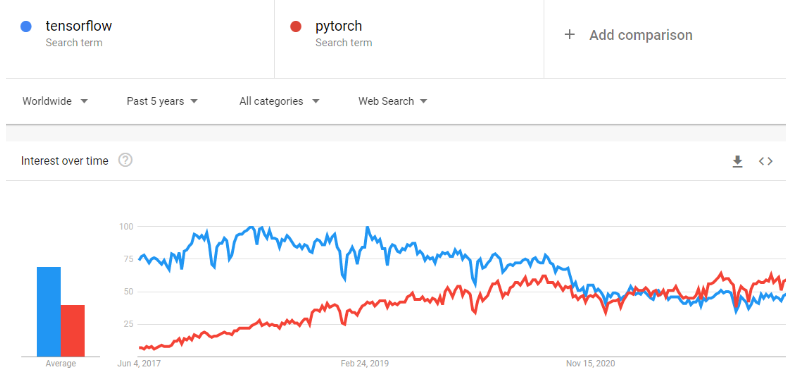
PyTorch là một framework học máy giúp rút ngắn đáng kể hành trình từ thử nghiệm nghiên cứu đến triển khai sản xuất. Nó là thư viện tensor tối ưu cho học sâu bằng GPU và CPU, và được coi là lựa chọn thay thế TensorFlow. Theo thời gian, độ phổ biến của PyTorch đã vượt TensorFlow trên Google Trends.
Nó được phát triển và duy trì bởi Facebook và hiện có thể dùng theo giấy phép BSD.
Theo trang web chính thức, các tính năng chính của PyTorch là:
⭐ Sao GitHub: 74K | Tổng lượt tải: 119 triệu
FastAI là thư viện học sâu cung cấp các thành phần cấp cao giúp tạo ra kết quả tiên tiến một cách dễ dàng. Nó cũng bao gồm các thành phần cấp thấp có thể hoán đổi để phát triển cách tiếp cận mới. Mục tiêu là làm được cả hai điều này mà không làm giảm nhiều tính dễ dùng, linh hoạt hay hiệu năng.
Tính năng:
Để tìm hiểu thêm về dự án, hãy xem tài liệu chính thức.
⭐ Sao GitHub: 25,1K | Tổng lượt tải: 6,1 triệu
Keras là API học sâu được thiết kế cho con người, không phải máy móc. Keras tuân theo các thực hành tốt nhất để giảm gánh nặng nhận thức: cung cấp API nhất quán và đơn giản, tối thiểu hóa số thao tác người dùng cần cho các trường hợp dùng phổ biến, và đưa ra thông báo lỗi rõ ràng, có thể hành động. Keras trực quan đến mức TensorFlow đã chọn Keras làm API mặc định trong bản phát hành TF 2.0.
Keras cung cấp cơ chế đơn giản hơn để biểu đạt mạng nơ-ron và cũng bao gồm một số công cụ tốt nhất cho phát triển mô hình, xử lý tập dữ liệu, trực quan hóa đồ thị và hơn thế nữa.
Tính năng:
Để tìm hiểu thêm về Keras, hãy xem tài liệu chính thức hoặc học khóa nhập môn: Deep Learning với Keras.
⭐ Sao GitHub: 60,2K | Tổng lượt tải: 163 triệu
PyTorch Lightning cung cấp giao diện cấp cao cho PyTorch. Khung nhẹ, hiệu năng cao của nó có thể tổ chức mã PyTorch để tách biệt nghiên cứu khỏi kỹ thuật, giúp thí nghiệm học sâu dễ hiểu và tái lập hơn. Nó được phát triển để tạo các mô hình học sâu có thể mở rộng, chạy liền mạch trên phần cứng phân tán.
Theo trang chính thức, PyTorch Lightning được thiết kế để bạn dành nhiều thời gian cho nghiên cứu và ít hơn cho kỹ thuật. Chỉ cần tái cấu trúc nhanh là bạn có thể:
Để tìm hiểu thêm về thư viện này, hãy xem trang web chính thức.
⭐ Sao GitHub: 25,6K | Tổng lượt tải: 18,2 triệu
JAX là thư viện tính toán số hiệu năng cao do Google phát triển. Nếu PyTorch là tiêu chuẩn thân thiện người dùng, thì JAX là "chiếc F1" dành cho các nhà nghiên cứu (bao gồm DeepMind) cần tốc độ cực hạn. Nó cho phép mã NumPy được biên dịch tự động chạy trên bộ tăng tốc (GPU/TPU) thông qua XLA (Accelerated Linear Algebra).
Khả năng thực hiện vi phân tự động trên các hàm Python thuần khiến nó được ưa chuộng để phát triển thuật toán mới từ đầu, đặc biệt trong mô hình sinh và mô phỏng vật lý.
⭐ Sao GitHub: 35K+ | Trạng thái: Tiêu chuẩn Nghiên cứu
spaCy là thư viện xử lý ngôn ngữ tự nhiên mã nguồn mở, cấp công nghiệp trong Python. spaCy xuất sắc ở các tác vụ trích xuất thông tin quy mô lớn. Nó được viết từ đầu bằng Cython với quản lý bộ nhớ cẩn trọng. Nếu ứng dụng của bạn cần xử lý các bản trích xuất web khổng lồ, spaCy là thư viện lý tưởng.
Tính năng:
Để tìm hiểu thêm về spaCy, hãy xem trang web chính thức hoặc kho GitHub. Bạn cũng có thể làm quen nhanh với các chức năng của nó bằng tờ phao spaCY tiện dụng này.
⭐ Sao GitHub: 28K | Tổng lượt tải: 81 triệu
Hugging Face Transformers là thư viện mã nguồn mở của Hugging Face. Transformers cho phép API dễ dàng tải xuống và huấn luyện các mô hình tiền huấn luyện tiên tiến. Việc dùng mô hình tiền huấn luyện có thể giảm chi phí tính toán, lượng phát thải carbon và tiết kiệm thời gian phải huấn luyện từ đầu. Các mô hình phù hợp cho nhiều loại dữ liệu, bao gồm:
Thư viện transformers hỗ trợ tích hợp liền mạch giữa ba thư viện học sâu phổ biến nhất: PyTorch, TensorFlow và JAX. Bạn có thể huấn luyện mô hình trong ba dòng mã ở một framework, và nạp để suy luận bằng framework khác. Kiến trúc mỗi transformer được định nghĩa trong một module Python độc lập, giúp dễ tùy chỉnh cho thí nghiệm và nghiên cứu.
Thư viện hiện được phát hành theo Apache License 2.0.
Để tìm hiểu thêm về transformers, hãy xem trang web chính thức hoặc kho GitHub và xem hướng dẫn của chúng tôi về sử dụng Transformers và Hugging Face.
⭐ Sao GitHub: 119K | Tổng lượt tải: 62 triệu
LangChain là khung điều phối tiêu chuẩn ngành cho các Mô hình Ngôn ngữ Lớn (LLM). Nó cho phép nhà phát triển "xâu chuỗi" các thành phần khác nhau, ví dụ kết nối một LLM (như GPT 5.2) với các nguồn tính toán hoặc tri thức khác.
Nó trừu tượng hóa độ phức tạp khi làm việc với prompt, cho phép bạn dễ dàng xây dựng "Agent" có thể dùng công cụ (như máy tính, Google Search, hoặc Python REPL) để giải các bài toán suy luận nhiều bước.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ Sao GitHub: 123K+ | Trạng thái: Thiết yếu cho GenAI
Trong khi LangChain xử lý suy luận, LlamaIndex xử lý dữ liệu. Đây là khung hàng đầu cho RAG (Retrieval-Augmented Generation). Nó chuyên về nạp, lập chỉ mục và truy xuất dữ liệu riêng tư của bạn (PDF, cơ sở dữ liệu SQL, bảng Excel) để LLM có thể trả lời câu hỏi về dữ liệu đó một cách chính xác.
Năm 2025, "trò chuyện với tài liệu của bạn" là yêu cầu tiêu chuẩn trong kinh doanh, và LlamaIndex cung cấp các cấu trúc dữ liệu tối ưu để làm điều đó hiệu quả và không ảo tưởng.
⭐ Sao GitHub: 35K+ | Trạng thái: Tiêu chuẩn RAG
Để khiến LLM "ghi nhớ" thông tin, bạn cần Cơ sở dữ liệu Vector. ChromaDB là cơ sở dữ liệu vector mã nguồn mở, bản địa AI, đã trở thành mặc định cho nhà phát triển Python. Nó xử lý độ phức tạp của việc nhúng văn bản (chuyển từ thành danh sách số) và lưu trữ để tìm kiếm ngữ nghĩa.
Không giống cơ sở dữ liệu SQL truyền thống khớp từ khóa chính xác, ChromaDB cho phép truy vấn theo nghĩa, biến nó thành bộ nhớ dài hạn cho các ứng dụng AI hiện đại.
⭐ Sao GitHub: 25K+ | Trạng thái: Tiêu chuẩn Vector Store
Việc chọn thư viện Python phù hợp cho các tác vụ khoa học dữ liệu, học máy hoặc xử lý ngôn ngữ tự nhiên là quyết định quan trọng có thể ảnh hưởng đáng kể đến thành công của dự án. Với vô vàn thư viện sẵn có, điều cốt yếu là cân nhắc nhiều yếu tố để đưa ra lựa chọn sáng suốt. Dưới đây là các cân nhắc chính để định hướng bạn:
Bằng cách đánh giá cẩn trọng các yếu tố này, bạn có thể đưa ra quyết định sáng suốt khi chọn thư viện Python cho nỗ lực khoa học dữ liệu hoặc học máy của mình. Hãy nhớ rằng thư viện tốt nhất cho dự án của bạn phụ thuộc vào các yêu cầu và mục tiêu cụ thể mà bạn muốn đạt được.
Để khởi động sự nghiệp khoa học dữ liệu, hãy tham gia lộ trình Data Scientist in Python.
Khóa học về Thư viện Python tại DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút