Courses
Python 中的机器学习预处理
4小时
66.6K
您是否想过,计算机究竟如何计算像 sin(x) 或 eˣ 这样的函数?
计算机无法直接求值大多数数学函数。它们只能做加、减、乘、除。所以当您在 Python 中调用 math.sin(0.5) 时,必须将其转换为一串基本算术运算。这个“转换器”就是多项式近似,而泰勒级数是其背后的数学基础。
泰勒级数允许您把几乎任何光滑函数改写为无穷项之和,每一项都基于函数在某一点的各阶导数。理解了这个思想,数据科学和机器学习中的许多概念就会豁然开朗——从梯度下降如何工作到某些激活函数为何呈现那样的行为。
本文将带您了解什么是泰勒级数、它在数学上如何运行、它在数据科学与机器学习中的应用场景,以及它与您会见到的其他类型级数之间的关系。
泰勒级数已有数百年历史。Brook Taylor 于 1715 年提出这一概念,而 James Gregory 和 Colin Maclaurin 也对此作出了重要贡献。
其目标是用多项式来表示复杂函数,因为多项式更易于处理。
泰勒级数通过把函数表示为无穷项之和来近似该函数,每一项都由函数在某一点的导数导出。包含的项越多,近似就越接近真实函数。
其一般公式如下:
泰勒级数通用公式
求和中的每一项由三个部分构成:
f⁽ⁿ⁾(a) —— 在中心点 a 处计算的第 n 阶导数
n! —— n 的阶乘,用来抑制各项的增长
(x - a)ⁿ —— 展开项,衡量 x 距离中心点的远近
中心点 a 是您锚定级数的位置。当 a = 0 时,会得到一个特殊情形,称为麦克劳林级数——稍后会详细介绍。
指数函数 eˣ 是一个完美的入门例子。它的导数等于自身,因此对任意 n 都有 f⁽ⁿ⁾(0) = 1。以 a = 0 为中心,泰勒级数变为:
具体示例
假设您想近似 e⁰·⁵。只需把 x = 0.5 代入前四项——下面是一个 Python 示例:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Python 中的具体示例
e⁰·⁵ 的真实值约为 1.6487。仅用四项,误差就已在 0.2% 以内。增加更多项,近似会更精确。
这就是泰勒级数的威力。
像 eˣ、sin(x) 和 cos(x) 这样的函数难以直接求值,但它们的泰勒级数把问题化为基本的算术运算——这正是计算机擅长的。
只有当泰勒级数确实收敛到您要近似的函数时,它才有用。让我们看看这意味着什么,以及在不收敛时会发生什么。
展开泰勒级数时,您是在逐项构建一个多项式。每一项都为中心点 a 附近的函数行为提供更多信息。
以 a = 0 为中心的 sin(x):
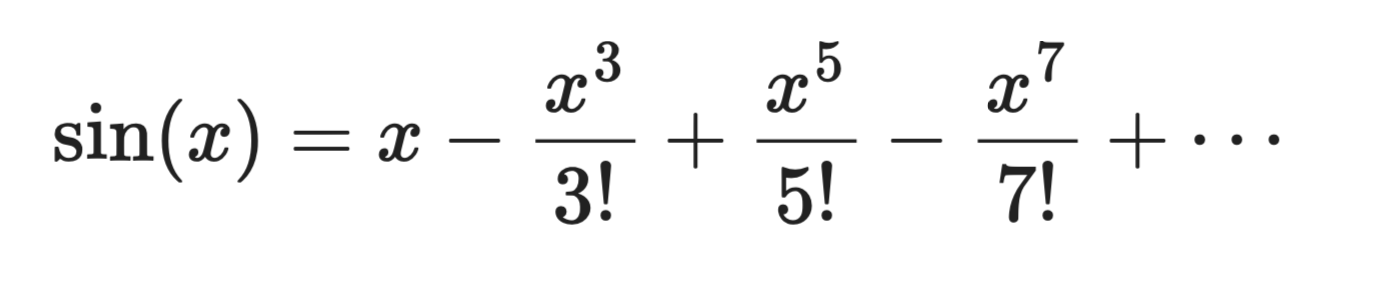
泰勒级数展开
第一项 x 是粗略的线性近似。加入第二项,曲线更贴近。继续加项,多项式在 x = 0 附近会越来越像 sin(x) 本身。
通俗地说,展开就是用一个可操作的多项式去替代一个精确但难以计算的函数。
您不可能计算无穷多项。在实践中,通常取前若干项并接受一个小误差。结果称为截断泰勒级数,由此引入的误差称为截断误差。
拉格朗日余项可以给出该误差的上界。若级数在取到第 n 项后截断:
拉格朗日余项
其中 c 是介于 x 与 a 之间的某点。您无法精确知道 c,但如果知道函数各阶导数可能达到的大小,就能为 f⁽ⁿ⁺¹⁾(c) 设定界限。
可这样理解:
x 距离中心点 a 越远,误差越大
包含项数越多,误差越小
导数值大且增长快的函数更难被精确近似
假设您用三项来近似 sin(0.1):
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Python 中的近似
当 x 接近 0 时,三项即可达到 10 位小数的精度。这就是截断误差的体现——很小,但并非为零。
若随项数增加,部分和越来越接近某个固定值,则称泰勒级数在点 x 处收敛。这个固定值应为 f(x)——但并非总能保证。
收敛半径 R 告诉您离中心点多远时级数仍然有效。半径内,级数收敛;半径外,各项增长而非衰减,近似便会失效。
收敛公式
不同函数的收敛半径不同:
eˣ、sin(x) 与 cos(x) 对所有 x 都收敛,因此 R = ∞
ln(1 + x) 仅在 -1 < x <= 1 内收敛,因此 R = 1
1/1-x 在 |x| < 1 时收敛,因此 R = 1
也有函数的收敛半径为无穷,但在某些点上仍不等于其泰勒级数。这类函数称为非解析函数,虽在数据科学中少见,但值得了解。
因此,在信任某个泰勒近似前,务必检查 x 是否位于收敛半径内。
泰勒级数出现的地方比您想象得多——从物理仿真到求解 微分方程。但在您作为数据科学家的日常工作中,其最大影响体现在优化与模型近似上。
每次训练机器学习模型,您都在运行某种形式的优化。而泰勒级数常常是该优化背后的基石。
梯度下降使用一阶泰勒近似。当您在当前参数 θ 处计算损失函数 L(θ) 的梯度时,本质上是在问:“若沿这个方向迈出一小步,损失会变化多少?”这正是一阶泰勒在当前点的展开:
优化中的泰勒级数
这方法可行,但忽略了曲率。如果损失面有弯曲,一阶近似可能会越步或采取低效的更新。
牛顿法通过引入二阶项——赫塞矩阵 H 来记录曲率,从而改进这一点:
优化中的泰勒级数(2)
将该表达式的导数置零即可得到最优步长。权衡在于:对大型模型计算完整的赫塞矩阵代价高昂。像 L-BFGS 这样的方法会对其进行近似,以较低成本获得大部分收益。
某些激活函数的计算代价较高。泰勒级数能提供更廉价、对多数用途而言足够精确的替代方案。
Sigmoid 函数 σ(x) = 1 / (1 + e⁻ˣ) 需要计算指数,这很昂贵。在 x = 0 附近,其泰勒展开为:
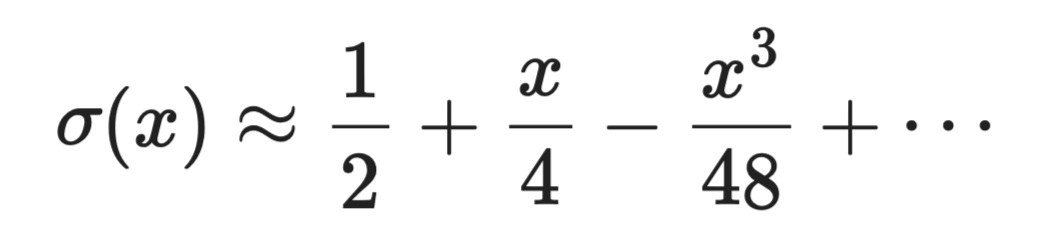
近似中的泰勒级数
在受硬件限制的环境(如边缘设备或 FPGA)中,这类多项式近似可以用少量乘加运算替代精确计算。
GELU(用于 BERT 与 GPT 等 Transformer 模型)常通过对误差函数 erf(x) 的泰勒近似来实现,因为其精确形式涉及一个没有初等闭式解的积分。
XGBoost 是最广泛使用的梯度提升库之一,它使用损失函数的二阶泰勒展开来拟合每棵新树。
在每个提升步骤,XGBoost 将损失近似为:
XGBoost 损失近似
其中 g_i 为一阶梯度,h_i 为相对于当前预测的二阶梯度(赫塞矩阵对角项)。同时使用二者让 XGBoost 比一阶方法更快、更准确地拟合树,这也是它在表格数据上表现优异的重要原因。
尽管泰勒级数在数据科学中几乎无处不在,但这并不意味着它是“见招拆招”的万能工具。以下几件事可能会出问题。
近似误差会累积: 在深层网络中,您会把很多操作串联在一起。某一层上很小的泰勒近似误差会在各层间复合,影响训练稳定性
收敛半径很关键: 泰勒近似只在展开点附近可靠。如果输入远离构建近似的位置——例如在分布外数据上推理时——近似可能会崩溃
高维赫塞矩阵代价高: 二阶方法虽强大,但可扩展性较差。含有 n 个参数的模型,其赫塞矩阵为 n × n。对拥有数百万参数的模型而言,存储和求逆都不现实,除非采用近似。
理解这些权衡,您就能判断何时值得采用基于泰勒的方法,何时更简单的一阶方法已经足够。
在数学、物理与机器学习中,有几类泰勒级数几乎无处不在。如果您认真从事数据科学,这些值得掌握。
指数函数 eˣ 的泰勒级数推导最简单,因为 eˣ 的每阶导数仍是 eˣ 本身。在 a = 0 处计算,每个系数都是 1:
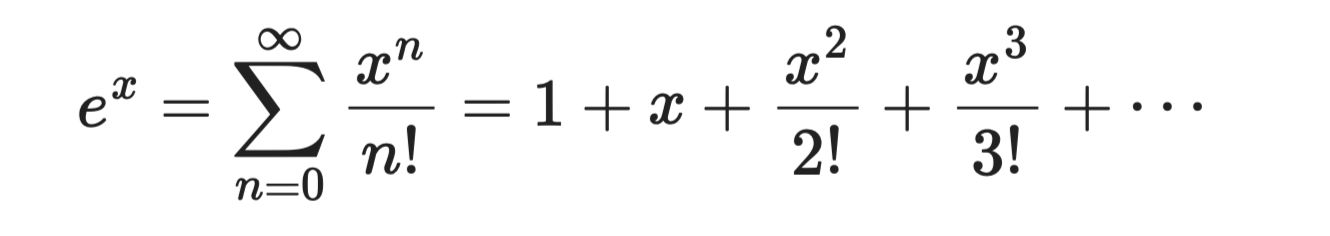
指数函数
该级数对所有 x 都收敛,因此可靠且易用。它是分类模型中 sigmoid 和 softmax 函数的基础。
正弦函数的级数仅包含奇次幂,这源于 sin(x) 是奇函数——即 sin(-x) = -sin(x):
正弦函数
与 eˣ 相似,该级数对所有 x 都收敛。交替的符号来自 sin(x) 的导数在 cos(x)、-sin(x)、-cos(x) 之间循环变换所致。
余弦函数是正弦的偶函数对应物——只包含偶次幂:
余弦函数
同时观察正弦与余弦级数,您会发现它们彼此互补。这种关系引出了欧拉著名恒等式:eⁱˣ = cos(x) + i·sin(x)。
自然对数 ln(1 + x) 在 x = 0 处的泰勒级数为:
自然对数函数
不同于前面三个,该级数仅在 -1 < x <= 1 内收敛。若将 x 推到区间外,级数会发散。这在交叉熵损失中会遇到,因为对数概率需要保持在有效范围内。
等比级数是数学中最古老也最常用的结果之一:
等比级数
它只在 |x| < 1 时收敛。它是推导许多其他泰勒级数的起点,并出现在概率论、信号处理以及任何涉及对贴现未来值求和的问题中。
如果您想要点看得见、能打印、能贴在床头的东西,我已为您准备好:

泰勒级数速查表
这五类级数覆盖了您在数据科学与机器学习中会遇到的大多数情形。
泰勒、傅里叶和麦克劳林级数都用于近似函数,但它们解决的问题不同,适用场景也不同。
泰勒与傅里叶级数都把函数表示为无穷和,但方式截然不同。
泰勒级数用多项式——(x - a) 的幂——来构建函数。它通过聚焦单个点,并用各阶导数捕捉函数的局部行为。结果在中心点 a 附近很准确,但随着距离增大精度下降。
傅里叶级数用正弦与余弦作为基函数:
傅里叶级数
傅里叶级数并非在一点上捕捉局部行为,而是捕捉整个区间上的全局周期性行为。它为周期性函数而设计——如音频信号、季节性模式或任何振荡现象。
两者并列比较如下:
泰勒 vs. 傅里叶对比
傅里叶级数出现在信号处理和时间序列分析中——谱分析、频率分解,甚至一些神经网络架构(如 FNet)会用傅里叶变换替代注意力机制。
如果您处理表格数据、图像或优化问题,泰勒级数更相关;若处理音频、时间序列或任何具有周期结构的对象,傅里叶级数更合适。
这一点很简单。麦克劳林级数只是以 a = 0 为中心的泰勒级数。
泰勒级数的一般公式为:
麦克劳林级数
令 a = 0,就得到:
a = 0 时的麦克劳林级数
Colin Maclaurin 在其研究中如此频繁地使用这一特例,以至于它有了专名;但从数学上看,它不过是在特定中心点的泰勒级数。
在实践中,您看到的大多数级数——eˣ、sin(x)、cos(x)、ln(1 + x)——都是麦克劳林级数,因为以零为中心能让代数更简洁。当您需要在其他点附近近似函数时,只需把中心移到 a ≠ 0,得到一般的泰勒级数。
总之,每个麦克劳林级数都是泰勒级数,但不是每个泰勒级数都是麦克劳林级数。
泰勒级数与线性模型乍看似乎无关,但它们之间有一层值得了解的联系,这始于一阶泰勒近似。
当您把泰勒级数截断到第一项时,就得到在点 a 附近的线性近似:
泰勒级数与线性模型(1)
这是一条直线。它有斜率(f'(a))和截距(f(a) - f'(a) ⋅ a)。是否耳熟?这与简单线性回归的结构相同:
泰勒级数与线性模型(2)
不同之处在于来路。泰勒近似中的斜率与截距由函数在单点的导数决定;线性回归中的二者由数据估计以最小化预测误差。但在结构上,它们做的是同一件事。
它解释了为什么线性模型在某些情形下表现良好,而在另一些则失效。
线性回归假设输入与输出之间的关系是——或可以被视为——线性的。泰勒级数准确地告诉您这种假设何时成立:当输入停留在某个固定点附近且所近似的函数足够光滑时。如果输入远离该点,线性近似会失效,这也是线性回归在强非线性数据上常常失败的原因。
广义线性模型(GLM)更明确地体现了这种联系。
例如,逻辑回归将结果的对数几率建模为线性函数。线性预测子与输出概率之间通过 sigmoid 函数相连——而如前所述,sigmoid 在零点附近有良好的泰勒展开。
理解一阶泰勒展开对应线性模型后,下一步就是加入更多项,得到多项式模型。
二阶泰勒展开为:
二阶泰勒级数
这是一个二次项——带平方项的多项式回归模型。每加入一项泰勒项,就对应更高次数的多项式,这正是多项式回归扩展线性回归以刻画曲线关系的方式。
因此,泰勒级数为您提供了理解回归中偏差-方差权衡的有原则路径。一阶近似(线性模型)速度快且可解释,但若真实关系是非线性的,则偏差较大。高阶近似能在展开点附近更好拟合数据,但随着增项也更易过拟合。
若想更深入理解线性回归及其适用场景,Essentials of Linear Regression in Python 教程是不錯的下一步。R 用户可参考 Intermediate Regression in R 课程,详细覆盖多项式回归与模型诊断。
泰勒级数是那种一旦学会就会在各处“刷存在感”的数学工具。
您已经看到,它如何让计算机用基本算术来评估 eˣ 和 sin(x) 等函数;收敛与截断误差如何决定近似精度;以及同一个思想如何为梯度下降、XGBoost 与现代机器学习中的激活函数近似提供动力。
指数、正弦、余弦、对数与等比这五类常见级数值得熟记。它们出现得足够频繁,做到一眼识别能实实在在节省时间。
接下来,建议您熟悉与这类数学并行的算法化思维。我们的 Data Structures and Algorithms in Python 课程是打好这方面基础的绝佳选择,帮助您理解如何把数学思想转化为可运行且可扩展的代码。
与 DataCamp 一起学习
Courses
Courses
Courses