
Courses
Tiền xử lý cho Machine Learning bằng Python
4 giờ
66.5K
Bạn đã bao giờ tự hỏi máy tính thực sự tính một hàm như sin(x) hoặc eˣ như thế nào chưa?
Máy tính không thể trực tiếp tính hầu hết các hàm toán học. Chúng chỉ có thể cộng, trừ, nhân và chia. Vì vậy khi bạn gọi math.sin(0.5) trong Python, cần có thứ gì đó chuyển lệnh đó thành một chuỗi các phép toán cơ bản. Thứ đó là xấp xỉ đa thức, và chuỗi Taylor là nền tảng toán học phía sau.
Chuỗi Taylor cho phép bạn viết lại gần như bất kỳ hàm trơn nào dưới dạng tổng vô hạn của các hạng tử đơn giản hơn, mỗi hạng được xây dựng từ các đạo hàm của hàm tại một điểm duy nhất. Khi bạn hiểu ý tưởng này, nhiều thứ trong khoa học dữ liệu và máy học sẽ trở nên "vỡ òa" - từ cách gradient descent hoạt động đến lý do tại sao một số hàm kích hoạt có hành vi như vậy.
Trong bài viết này, tôi sẽ hướng dẫn bạn chuỗi Taylor là gì, cách chúng vận hành về mặt toán học, chúng xuất hiện ở đâu trong khoa học dữ liệu và máy học, và cách chúng liên hệ với các loại chuỗi khác mà bạn sẽ gặp.
Chuỗi Taylor đã xuất hiện từ hàng thế kỷ. Brook Taylor giới thiệu chúng vào năm 1715, dù James Gregory và Colin Maclaurin cũng có những đóng góp quan trọng cho ý tưởng này.
Mục tiêu là tìm cách biểu diễn các hàm phức tạp bằng các đa thức, vốn dễ xử lý hơn nhiều.
Chuỗi Taylor xấp xỉ một hàm bằng cách biểu diễn nó như một tổng vô hạn các hạng tử, mỗi hạng được suy ra từ các đạo hàm của hàm tại một điểm duy nhất. Bạn lấy càng nhiều hạng, xấp xỉ càng gần với hàm thực tế.
Công thức tổng quát như sau:
Công thức tổng quát của chuỗi Taylor
Mỗi hạng trong tổng này gồm ba thành phần:
f⁽ⁿ⁾(a) - đạo hàm bậc n của hàm được tính tại điểm trung tâm a
n! - giai thừa của n, giúp các hạng không tăng vô tội vạ
(x - a)ⁿ - hạng khai triển, đo khoảng cách của x so với điểm trung tâm
Điểm trung tâm a là nơi bạn "neo" chuỗi. Khi a = 0, bạn có một trường hợp đặc biệt gọi là chuỗi Maclaurin - sẽ nói kỹ hơn ở phần sau.
Hàm mũ eˣ là ví dụ khởi đầu hoàn hảo. Đạo hàm của nó chính là nó, nên f⁽ⁿ⁾(0) = 1 với mọi n. Lấy tâm tại a = 0, chuỗi Taylor trở thành:
Ví dụ cụ thể
Giả sử bạn muốn xấp xỉ e⁰·⁵. Chỉ cần thay x = 0.5 vào bốn hạng đầu - đây là ví dụ Python:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Ví dụ cụ thể trong Python
Giá trị thực của e⁰·⁵ xấp xỉ 1.6487. Chỉ với bốn hạng, bạn đã nằm trong sai số 0,2% so với đáp án đúng. Thêm nhiều hạng hơn, xấp xỉ sẽ khít hơn.
Đó là sức mạnh của chuỗi Taylor.
Các hàm như eˣ, sin(x) và cos(x) khó tính trực tiếp, nhưng chuỗi Taylor biến chúng thành số học cơ bản. Đó chính xác là thứ máy tính xử lý tốt.
Chuỗi Taylor chỉ hữu ích nếu nó thực sự hội tụ về hàm bạn đang cố xấp xỉ. Hãy xem điều đó nghĩa là gì và chuyện gì xảy ra khi nó không hội tụ.
Khi bạn khai triển chuỗi Taylor, bạn đang xây một đa thức từng hạng một. Mỗi hạng bổ sung thêm thông tin về hành vi của hàm gần điểm trung tâm a.
Xét sin(x) lấy tâm tại a = 0:
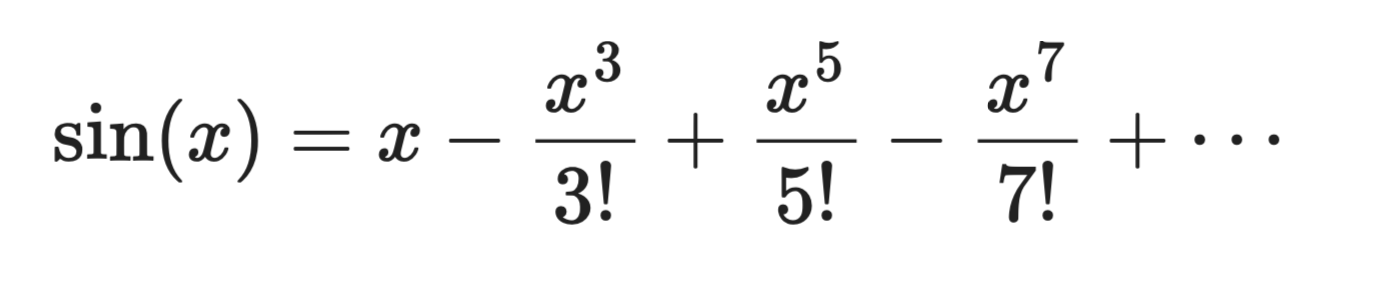
Khai triển chuỗi Taylor
Hạng đầu, x, là xấp xỉ tuyến tính thô. Thêm hạng thứ hai, đường cong tiến gần hơn. Thêm nhiều hạng nữa, đa thức bắt đầu trông y hệt sin(x) gần x = 0.
Nói nôm na, khai triển nghĩa là bạn đánh đổi một hàm chính xác nhưng khó tính lấy một đa thức mà bạn có thể thực sự làm việc cùng.
Bạn sẽ không bao giờ tính vô hạn hạng. Trên thực tế, bạn dừng sau vài hạng và chấp nhận một sai số nhỏ. Kết quả gọi là chuỗi Taylor cắt cụt, và sai số do nó gây ra gọi là sai số cắt cụt.
Số dư Lagrange cho bạn một chặn trên của sai số đó. Đối với một chuỗi bị cắt sau n hạng:
Số dư Lagrange
Trong đó c là một điểm nào đó giữa x và a. Bạn không biết chính xác c, nhưng có thể chặn f⁽ⁿ⁺¹⁾(c) nếu bạn biết đạo hàm của hàm có thể lớn đến mức nào.
Diễn giải như sau
Càng xa điểm trung tâm a, sai số của x càng lớn
Bạn lấy càng nhiều hạng, sai số càng nhỏ
Các hàm có đạo hàm lớn, tăng nhanh khó xấp xỉ chính xác hơn
Giả sử bạn đang xấp xỉ sin(0.1) với ba hạng:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Xấp xỉ trong Python
Ba hạng cho độ chính xác đến 10 chữ số thập phân khi x gần 0. Đó là sai số cắt cụt đang vận hành - nhỏ, nhưng không bằng 0.
Một chuỗi Taylor hội tụ tại một điểm x nếu các tổng riêng tiến dần đến một giá trị cố định khi bạn thêm nhiều hạng hơn. Giá trị cố định đó phải là f(x) - nhưng điều đó không phải lúc nào cũng được đảm bảo.
Bán kính hội tụ R cho bạn biết chuỗi còn hiệu lực xa đến đâu so với điểm trung tâm. Bên trong bán kính đó, chuỗi hội tụ. Bên ngoài, các hạng tăng thay vì giảm, và xấp xỉ sụp đổ.
Công thức hội tụ
Các hàm khác nhau có bán kính khác nhau:
eˣ, sin(x) và cos(x) hội tụ với mọi giá trị x, nên R = ∞
ln(1 + x) chỉ hội tụ với -1 < x <= 1, nên R = 1
1/1-x hội tụ với |x| < 1, nên R = 1
Một hàm cũng có thể có bán kính hội tụ vô hạn nhưng vẫn không bằng chuỗi Taylor của nó tại một số điểm. Chúng được gọi là hàm không giải tích, và là một trường hợp biên đáng biết, dù hiếm gặp trong khoa học dữ liệu.
Vì vậy, luôn kiểm tra xem x có nằm trong bán kính hội tụ trước khi tin vào một xấp xỉ Taylor hay không.
Chuỗi Taylor xuất hiện ở nhiều nơi hơn bạn tưởng - từ mô phỏng vật lý đến giải phương trình vi phân. Nhưng tác động lớn nhất của chúng trong công việc hàng ngày của bạn với tư cách là nhà khoa học dữ liệu là ở tối ưu hóa và xấp xỉ mô hình.
Mỗi lần bạn huấn luyện một mô hình máy học, bạn đang chạy một dạng tối ưu hóa nào đó. Và chuỗi Taylor thường đứng sau quá trình tối ưu hóa đó
Gradient descent sử dụng xấp xỉ Taylor bậc nhất. Khi bạn tính gradient của hàm mất mát L(θ) tại bộ tham số hiện tại θ, về bản chất bạn đang hỏi: "nếu tôi dịch một bước nhỏ theo hướng này, mất mát thay đổi bao nhiêu?" Đó là một khai triển Taylor bậc nhất quanh điểm hiện tại:
Chuỗi Taylor trong tối ưu hóa
Cách này hoạt động, nhưng bỏ qua độ cong. Nếu bề mặt mất mát cong, xấp xỉ bậc nhất có thể vượt quá hoặc tiến từng bước kém hiệu quả.
Phương pháp Newton khắc phục điều này bằng cách đưa vào hạng bậc hai - ma trận Hessian H, theo dõi độ cong:
Chuỗi Taylor trong tối ưu hóa (2)
Đặt đạo hàm của biểu thức này bằng không cho bạn bước đi tối ưu. Sự đánh đổi là tính toàn bộ Hessian rất tốn kém với các mô hình lớn. Các phương pháp như L-BFGS thay vào đó xấp xỉ nó, giúp thu được phần lớn lợi ích với một phần nhỏ chi phí.
Một số hàm kích hoạt tốn chi phí tính toán. Chuỗi Taylor cung cấp các phương án rẻ hơn nhưng đủ chính xác cho hầu hết mục đích.
Hàm sigmoid σ(x) = 1 / (1 + e⁻ˣ) yêu cầu tính số mũ, vốn tốn kém. Gần x = 0, khai triển Taylor của nó là:
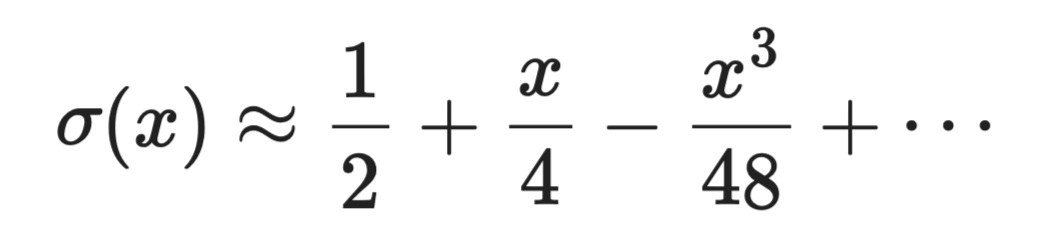
Chuỗi Taylor trong xấp xỉ
Với môi trường bị hạn chế phần cứng như thiết bị biên hoặc FPGA, các xấp xỉ đa thức như thế này có thể thay thế phép tính chính xác bằng một vài phép nhân-cộng.
GELU, được dùng trong các mô hình transformer như BERT và GPT, thường được hiện thực thông qua xấp xỉ dựa trên Taylor của hàm lỗi erf(x), vì dạng chính xác liên quan đến một tích phân không có nghiệm đóng.
XGBoost là một trong những thư viện gradient boosting được dùng rộng rãi nhất và nó sử dụng khai triển Taylor bậc hai của hàm mất mát để khớp mỗi cây mới.
Ở mỗi bước boosting, XGBoost xấp xỉ mất mát như sau:
Xấp xỉ mất mát trong XGBoost
Trong đó g_i là gradient bậc nhất và h_i là gradient bậc hai (Hessian) của mất mát theo dự đoán hiện tại. Việc dùng cả hai hạng giúp XGBoost khớp cây nhanh và chính xác hơn các phương pháp bậc nhất, là một phần lớn lý do nó hiệu quả trên dữ liệu dạng bảng.
Chỉ vì chuỗi Taylor có thể dùng khắp nơi trong khoa học dữ liệu không có nghĩa chúng là chiếc búa vạn năng cho mọi chiếc đinh bạn thấy. Vài điều có thể trục trặc.
Sai số xấp xỉ tích lũy: Trong mạng sâu, bạn xâu chuỗi nhiều phép toán lại. Một sai số Taylor nhỏ ở một tầng sẽ cộng dồn qua các tầng, có thể ảnh hưởng đến độ ổn định huấn luyện
Bán kính hội tụ rất quan trọng: Xấp xỉ Taylor chỉ đáng tin gần điểm khai triển. Nếu đầu vào trôi xa khỏi nơi xấp xỉ được xây dựng - ví dụ, khi suy luận trên dữ liệu ngoài phân phối - xấp xỉ có thể sụp đổ
Hessian chiều cao rất đắt đỏ: Các phương pháp bậc hai mạnh mẽ nhưng không mở rộng tốt. Một mô hình có n tham số sẽ có Hessian n × n. Với mô hình hàng triệu tham số, lưu trữ và nghịch đảo ma trận đó là bất khả thi nếu không xấp xỉ.
Nếu bạn hiểu những đánh đổi này, bạn sẽ biết khi nào nên dùng cách tiếp cận dựa trên Taylor và khi nào một phương pháp bậc nhất đơn giản là đủ tốt.
Một vài chuỗi Taylor xuất hiện ở khắp toán học, vật lý và máy học. Đây là những chuỗi đáng biết nếu bạn nghiêm túc với khoa học dữ liệu.
Hàm mũ eˣ là chuỗi Taylor dễ suy ra nhất, vì mọi đạo hàm của eˣ đều là eˣ. Tính tại a = 0, mọi hệ số đều là 1:
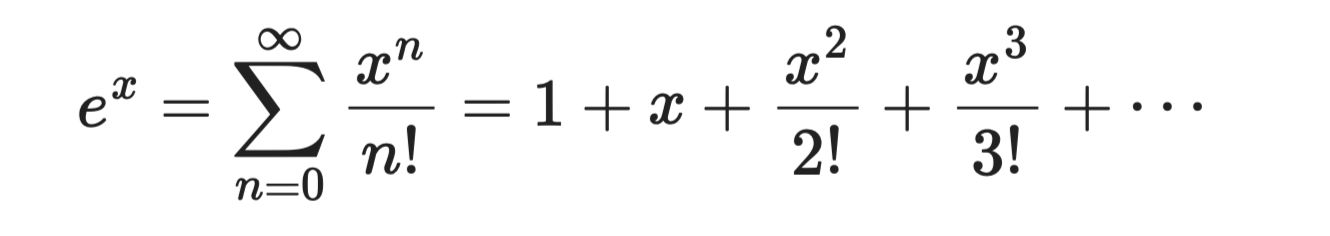
Hàm mũ
Chuỗi này hội tụ với mọi giá trị x, khiến nó đáng tin cậy và dễ sử dụng. Nó là nền tảng cho các hàm sigmoid và softmax dùng trong mô hình phân loại.
Hàm sine chỉ chứa lũy thừa lẻ, điều này xuất phát từ việc sin(x) là hàm lẻ - nghĩa là sin(-x) = -sin(x):
Hàm sine
Giống eˣ, chuỗi này hội tụ với mọi x. Các dấu xen kẽ đến từ việc các đạo hàm của sin(x) luân phiên qua cos(x), -sin(x), -cos(x), rồi quay lại.
Cosine là đối ngẫu chẵn của sine - nó chỉ chứa lũy thừa chẵn:
Hàm cosine
Nếu bạn xem chuỗi sine và cosine cùng nhau, bạn sẽ thấy chúng bổ sung cho nhau. Mối quan hệ này dẫn đến đồng nhất thức nổi tiếng của Euler: eⁱˣ = cos(x) + i·sin(x).
Logarit tự nhiên ln(1 + x) có chuỗi Taylor lấy tâm tại x = 0:
Hàm logarit tự nhiên
Không giống ba chuỗi trước, chuỗi này chỉ hội tụ với -1 < x <= 1. Nếu bạn đẩy x ra ngoài khoảng đó, chuỗi sẽ phân kỳ. Điều này xuất hiện trong mất mát entropy chéo, nơi log xác suất cần giữ trong phạm vi hợp lệ.
Chuỗi hình học là một trong những kết quả cổ xưa và được dùng nhiều nhất trong toán học:
Chuỗi hình học
Chuỗi này chỉ hội tụ với |x| < 1. Đây là điểm khởi đầu để suy ra nhiều chuỗi Taylor khác, và xuất hiện trong xác suất, xử lý tín hiệu, và bất cứ nơi nào bạn cộng các giá trị tương lai có chiết khấu.
Nếu bạn muốn thứ gì đó hữu hình, in ra được, để treo trên tường cạnh giường ngủ, tôi có sẵn cho bạn đây:

Tham khảo nhanh chuỗi Taylor
Năm chuỗi này bao phủ phần lớn các trường hợp bạn sẽ gặp trong khoa học dữ liệu và máy học.
Taylor, Fourier và Maclaurin đều xấp xỉ hàm, nhưng chúng giải quyết những bài toán khác nhau và hoạt động tốt nhất trong các ngữ cảnh khác nhau.
Chuỗi Taylor và Fourier đều biểu diễn hàm như tổng vô hạn, nhưng làm theo những cách hoàn toàn khác nhau.
Chuỗi Taylor xây hàm từ các đa thức - lũy thừa của (x - a). Nó hoạt động bằng cách phóng to một điểm và nắm bắt hành vi cục bộ của hàm thông qua các đạo hàm. Kết quả chính xác gần điểm trung tâm a, nhưng độ chính xác giảm dần khi bạn đi xa.
Chuỗi Fourier dùng sine và cosine làm khối xây dựng:
Chuỗi Fourier
Thay vì nắm bắt hành vi cục bộ tại một điểm, chuỗi Fourier nắm bắt hành vi tuần hoàn toàn cục trên cả một khoảng. Chúng được thiết kế cho các hàm lặp lại - nghĩ đến tín hiệu âm thanh, mẫu theo mùa, hoặc bất cứ thứ gì dao động.
So sánh hai loại như sau:
So sánh Taylor và Fourier
Chuỗi Fourier xuất hiện trong xử lý tín hiệu và phân tích chuỗi thời gian - phân tích phổ, phân rã theo tần số, và thậm chí một số kiến trúc mạng nơ-ron như FNet thay thế attention bằng biến đổi Fourier.
Nếu bạn làm việc với dữ liệu bảng, ảnh, hoặc tối ưu hóa, chuỗi Taylor là công cụ phù hợp hơn. Nếu bạn làm việc với âm thanh, chuỗi thời gian, hay bất cứ thứ gì có cấu trúc tuần hoàn, chuỗi Fourier phù hợp hơn.
Phần này đơn giản. Chuỗi Maclaurin chỉ là chuỗi Taylor lấy tâm tại a = 0.
Công thức chuỗi Taylor tổng quát là:
Chuỗi Maclaurin
Đặt a = 0 và bạn có:
Chuỗi Maclaurin tại a = 0
Colin Maclaurin dùng trường hợp cụ thể này quá thường xuyên trong công trình của ông nên nó có tên riêng, nhưng về mặt toán học, nó không gì khác ngoài chuỗi Taylor tại một điểm trung tâm cụ thể.
Trong thực tế, hầu hết các chuỗi bạn thấy - eˣ, sin(x), cos(x), ln(1 + x) - là chuỗi Maclaurin, vì lấy tâm tại không giúp đại số gọn gàng. Khi cần xấp xỉ một hàm gần điểm khác, bạn dịch tâm đến a ≠ 0 và nhận chuỗi Taylor tổng quát.
Tóm lại, mọi chuỗi Maclaurin đều là chuỗi Taylor, nhưng không phải mọi chuỗi Taylor đều là chuỗi Maclaurin.
Chuỗi Taylor và các mô hình tuyến tính thoạt nhìn có vẻ không liên quan, nhưng có một mối liên hệ đáng biết, bắt đầu từ xấp xỉ Taylor bậc nhất.
Khi bạn cắt chuỗi Taylor sau hạng đầu tiên, bạn nhận được một xấp xỉ tuyến tính của hàm gần một điểm a:
Chuỗi Taylor và mô hình tuyến tính (1)
Đây là một đường thẳng. Nó có hệ số góc (f'(a)) và tung độ gốc (f(a) - f'(a) ⋅ a). Nghe quen chứ? Đó là cùng cấu trúc với mô hình hồi quy tuyến tính đơn:
Chuỗi Taylor và mô hình tuyến tính (2)
Điểm khác biệt là nguồn gốc của mỗi bên. Trong xấp xỉ Taylor, hệ số góc và tung độ gốc được xác định bởi các đạo hàm của hàm tại một điểm. Trong hồi quy tuyến tính, chúng được ước lượng từ dữ liệu để tối thiểu hóa sai số dự đoán. Nhưng về cấu trúc, chúng làm cùng một việc.
Nó giải thích vì sao các mô hình tuyến tính hoạt động tốt trong một số tình huống và thất bại ở những tình huống khác.
Hồi quy tuyến tính giả định mối quan hệ giữa đầu vào và đầu ra là - hoặc có thể được xem như - tuyến tính. Chuỗi Taylor cho bạn biết chính xác khi nào giả định đó đúng - khi đầu vào của bạn ở gần một điểm cố định, và hàm bạn xấp xỉ là trơn. Nếu đẩy đầu vào ra xa điểm đó, xấp xỉ tuyến tính sụp đổ, cũng là lý do hồi quy tuyến tính thường thất bại trên dữ liệu có mẫu phi tuyến mạnh.
Các mô hình tuyến tính tổng quát (GLM) làm mối liên hệ này còn rõ ràng hơn.
Ví dụ, hồi quy logistic mô hình hóa log-odds của một kết cục như một hàm tuyến tính. Mối liên kết giữa bộ dự đoán tuyến tính và xác suất đầu ra đi qua hàm sigmoid - và như bạn đã thấy, sigmoid có khai triển Taylor tốt gần không.
Khi hiểu rằng khai triển Taylor bậc nhất cho bạn một mô hình tuyến tính, bước tiếp theo là thêm nhiều hạng hơn, và bạn có một mô hình đa thức.
Khai triển Taylor bậc hai cho bạn:
Chuỗi Taylor bậc hai
Đây là một bậc hai - mô hình hồi quy đa thức với hạng bình phương. Mỗi hạng Taylor bổ sung tương ứng với một đa thức bậc cao hơn, là cách hồi quy đa thức mở rộng hồi quy tuyến tính để nắm bắt các mối quan hệ cong.
Vì thế chuỗi Taylor cho bạn một cách tiếp cận có cơ sở để suy nghĩ về đánh đổi bias-variance trong hồi quy. Xấp xỉ bậc nhất (mô hình tuyến tính) nhanh và dễ diễn giải nhưng có bias cao nếu mối quan hệ thực là phi tuyến. Các xấp xỉ bậc cao khớp dữ liệu tốt hơn gần điểm khai triển nhưng có nguy cơ overfit khi thêm nhiều hạng.
Nếu bạn muốn đào sâu về hồi quy tuyến tính và khi nào nó hiệu quả, hướng dẫn Essentials of Linear Regression in Python là bước tiếp theo tốt. Với người dùng R, khóa học Intermediate Regression in R đề cập chi tiết hồi quy đa thức và chẩn đoán mô hình.
Chuỗi Taylor là một trong những công cụ toán học mà bạn sẽ liên tục bắt gặp một khi biết để ý.
Bạn đã thấy cách chúng cho phép máy tính tính các hàm như eˣ và sin(x) thông qua số học cơ bản, cách hội tụ và sai số cắt cụt quyết định độ chính xác của xấp xỉ, và cách cùng một ý tưởng vận hành gradient descent, XGBoost, và các xấp xỉ hàm kích hoạt trong máy học hiện đại.
Năm chuỗi quen thuộc - mũ, sine, cosine, logarit, hình học - đáng để ghi nhớ. Chúng xuất hiện đủ thường xuyên để việc nhận ra ngay lập tức sẽ tiết kiệm thời gian thực sự.
Từ đây, bước tiếp theo là làm quen với tư duy thuật toán đi kèm với kiểu toán này. Khóa học Cấu trúc dữ liệu và Thuật toán trong Python của chúng tôi là nơi vững chắc để xây nền tảng đó. Nó sẽ giúp bạn hiểu cách các ý tưởng toán học chuyển thành mã chạy được và mở rộng tốt.
Học cùng DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút