Courses
Pythonで学ぶMachine Learningの前処理
4時間
66.6K
コンピュータが実際に sin(x) や eˣ のような関数をどのように計算しているのか、不思議に思ったことはありませんか?
コンピュータはほとんどの数学関数を直接評価できません。足し算・引き算・掛け算・割り算しかできないからです。つまり、Python で math.sin(0.5) を呼び出すとき、何かがそれを基本的な算術の並びに変換する必要があります。その「何か」が多項式近似であり、テイラー級数はその数学的基盤です。
テイラー級数を使うと、ほぼすべての滑らかな関数を、ある一点での導関数から構成される、より単純な項の無限和として書き換えられます。この考え方を理解すると、データサイエンスや機械学習の多くのことが腑に落ちます——勾配降下法の仕組みから、特定の活性化関数がどのように振る舞うのかまで。
本記事では、テイラー級数とは何か、数学的にどのように機能するのか、データサイエンスや機械学習のどこで登場するのか、そして他の種類の級数との関係について解説します。
テイラー級数は何世紀も前から知られています。1715 年に Brook Taylor が導入し、James Gregory や Colin Maclaurin もこのアイデアに大きく貢献しました。
目的は、扱いやすい多項式を使って複雑な関数を表現する方法を見つけることでした。
テイラー級数は、関数を無限和として表し、その各項は一点における導関数から導かれます。項を多く含めるほど、近似は元の関数に近づきます。
一般形は次のとおりです。
テイラー級数の一般式
各項は次の 3 要素で構成されます。
f⁽ⁿ⁾(a) - 中心点 a における関数の n 階導関数の値
n! - n の階乗。項の増大を抑える役割をします
(x - a)ⁿ - 展開項。x が中心点からどれだけ離れているかを表します
中心点 a は級数を固定する位置です。a = 0 のとき、マクローリン級数と呼ばれる特別な場合になります(詳細は後述)。
指数関数 eˣ は最初の例として最適です。導関数が自分自身なので、すべての n について f⁽ⁿ⁾(0) = 1 となります。a = 0 を中心とすると、テイラー級数は次のようになります。
具体例
たとえば e⁰·⁵ を近似したいとします。x = 0.5 を最初の 4 項に代入するだけです——Python の例は次のとおりです。
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Python による具体例
実際の e⁰·⁵ の値はおよそ 1.6487 です。わずか 4 項でも真値から 0.2% 以内に収まります。項を増やせば近似はさらに精密になります。
これがテイラー級数の威力です。
eˣ、sin(x)、cos(x) のような関数は直接評価が難しい一方で、テイラー級数により基本的な算術に還元できます。これはまさにコンピュータが扱える形式です。
テイラー級数は、近似したい関数へ実際に収束するときにだけ有用です。収束とは何を意味し、収束しないとどうなるのかを見ていきましょう。
テイラー級数を展開するとは、多項式を 1 項ずつ組み立てていくことです。各項は中心点 a 付近での関数の振る舞いに関する情報を追加します。
a = 0 を中心とした sin(x) を考えます。
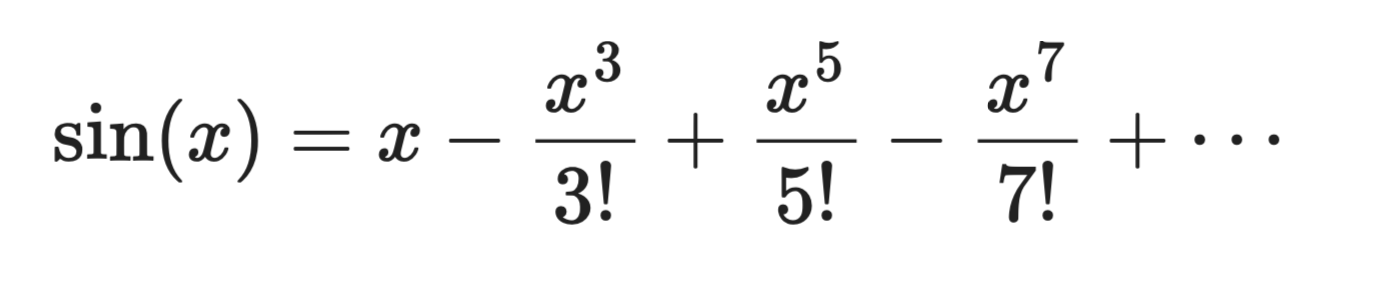
テイラー級数の展開
第 1 項 x は大まかな線形近似です。第 2 項を加えると曲線はさらに近づきます。さらに項を加えると、多項式は x = 0 付近で sin(x) そのもののように見えてきます。
平たく言えば、展開とは、厳密だが計算しにくい関数を、実際に扱える多項式に置き換えることです。
無限に多くの項を計算することはありません。実務では、いくつかの項で打ち切って小さな誤差を受け入れます。これを打切りテイラー級数と呼び、そのときに生じる誤差を打切り誤差といいます。
ラグランジュの剰余項は、その誤差の上界を与えます。n 項で打ち切った場合:
ラグランジュの剰余項
ここで c は x と a の間のどこかの点です。c 自体はわかりませんが、関数の導関数がどれくらい大きくなり得るかがわかっていれば、f⁽ⁿ⁺¹⁾(c) を上から抑えられます。
次のように解釈できます。
中心点 a から x が遠いほど、誤差は大きくなる
項を多く含めるほど、誤差は小さくなる
導関数が大きく急激に増加する関数は、正確な近似が難しい
たとえば、sin(0.1) を 3 項で近似してみます。
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Python による近似
3 項あれば、x が 0 に近いときに 10 桁精度が得られます。これが打切り誤差の働きです——小さいものの、ゼロではありません。
ある点 x でテイラー級数が収束するとは、項を加えるにつれて部分和がある一定値に近づいていくことです。その一定値は f(x) であるべきですが、常に保証されるわけではありません。
収束半径 R は、中心点からどれだけ離れても級数が有効でいられるかを示します。半径の内側では級数は収束します。外側では項が減衰せず増大し、近似は破綻します。
収束の式
関数により収束半径は異なります。
eˣ、sin(x)、cos(x) はすべての x で収束するので、R = ∞
ln(1 + x) は -1 < x <= 1 でのみ収束するので、R = 1
1/1-x は |x| < 1 で収束するので、R = 1
無限の収束半径を持ちながら、特定の点でテイラー級数と一致しない関数もあります。これらは非解析関数と呼ばれ、データサイエンスで目にすることは稀ですが、知っておく価値のある端的な例外です。
したがって、テイラー近似を信頼する前に、x が収束半径の内側にあるかどうかを常に確認してください。
テイラー級数は、物理シミュレーションから 微分方程式の解法まで、思った以上に多くの場面に現れます。ただし、データサイエンティストの日常業務における最大の影響は、最適化とモデル近似にあります。
機械学習モデルを学習させるたびに、何らかの最適化を実行しています。そして、その背後にはしばしばテイラー級数があります。
勾配降下法 は一次のテイラー近似を用います。現在のパラメータ θ における損失関数 L(θ) の勾配を計算するとき、実質的には「この方向に小さく動くと、損失はどれだけ変わるか?」と問うているのです。これは現在の点の周りでの一次テイラー展開です。
最適化におけるテイラー級数
これは有効ですが、曲率を無視します。損失面が曲がっている場合、一次近似では行き過ぎたり、非効率なステップになったりします。
ニュートン法 は、曲率を捉えるヘッセ行列 H を含む二次の項を取り入れることで、これを補正します。
最適化におけるテイラー級数 (2)
この式の導関数を 0 にすると、取るべき最適ステップが得られます。代償として、大規模モデルでは完全なヘッセ行列の計算が高コストです。L-BFGS のような手法はそれを近似し、コストの一部で大部分の利点を得ます。
一部の活性化関数は計算コストが高いものがあります。テイラー級数は、ほとんどの用途に十分な精度を持つ、より軽量な代替手段を提供します。
たとえば シグモイド関数 σ(x) = 1 / (1 + e⁻ˣ) は指数関数の計算を要し、コストが高い関数です。 x = 0 付近でのテイラー展開は次のとおりです。
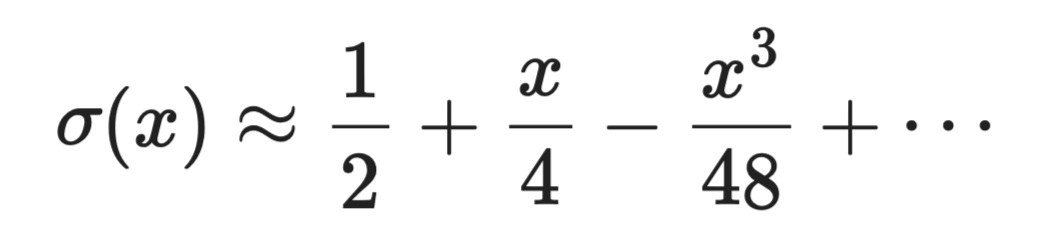
近似におけるテイラー級数
エッジデバイスや FPGA のようなハードウェア制約の厳しい環境では、このような多項式近似により、厳密計算を少数の乗算・加算に置き換えられます。
GELU は、BERT や GPT のようなトランスフォーマーモデルで用いられ、誤差関数 erf(x) のテイラー近似に基づいて実装されることがよくあります。厳密形は閉じた形を持たない積分を含むためです。
XGBoost は最も広く使われる勾配ブースティングのライブラリの一つで、各新規ツリーを適合させる際に損失関数の二次のテイラー展開を用います。
各ブースティングステップで、XGBoost は損失を次のように近似します。
XGBoost の損失近似
ここで g_i は一次の勾配、h_i は現在の予測に対する損失の二次の勾配(ヘッセ行列)です。両方の項を使うことで、XGBoost は一次法よりも速く高精度にツリーを適合でき、これが表形式データで優れた性能を発揮する大きな理由です。
テイラー級数がデータサイエンスの至る所で使えるからといって、何にでも当てはめられる万能の金槌というわけではありません。いくつか問題になり得る点があります。
近似誤差の蓄積: 深いネットワークでは多くの演算を連鎖させます。ある層での小さなテイラー近似の誤差が層をまたいで複利的に増幅し、学習の安定性に影響し得ます
収束半径の重要性: テイラー近似は展開点の近傍でのみ信頼できます。推論時に分布外データで入力が近似を構築した場所から大きく外れると、近似は崩れる可能性があります
高次元ヘッセ行列の高コスト: 二次法は強力ですがスケールしにくいです。n 個のパラメータを持つモデルではヘッセ行列は n × n。数百万パラメータのモデルでは、その行列の保存や逆行列計算は近似なしには現実的ではありません。
これらのトレードオフを理解していれば、テイラーに基づく手法が価値のある場面と、より単純な一次法で十分な場面を見極められます。
いくつかのテイラー級数は数学・物理・機械学習の至る所に現れます。データサイエンスに本気で取り組むなら、これらは押さえておくべきです。
指数関数 eˣ は導出が最も簡単なテイラー級数です。eˣ のすべての導関数が eˣ 自身だからです。a = 0 で評価すると、すべての係数は 1 になります。
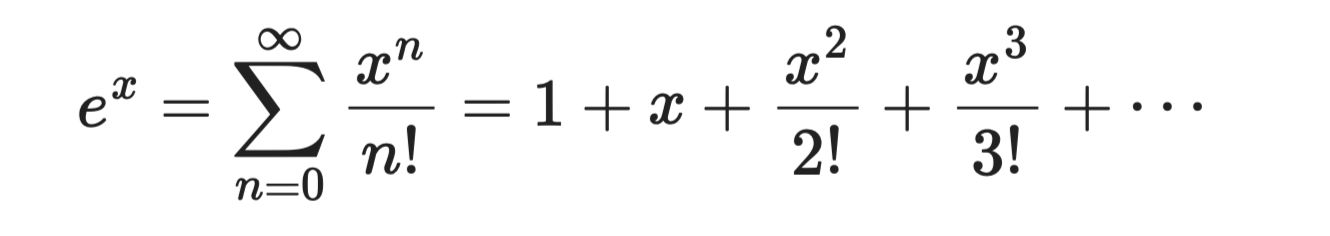
指数関数
この級数はすべての x で収束するため、扱いやすく信頼できます。分類モデルで使われるシグモイドやソフトマックスの基盤でもあります。
正弦関数は奇数次のべきのみを含みます。これは sin(x) が奇関数、つまり sin(-x) = -sin(x) であることに由来します。
正弦関数
eˣ と同様、すべての x で収束します。符号が交互になるのは、sin(x) の導関数が cos(x)、-sin(x)、-cos(x)、そして元に戻る、という周期をたどるためです。
余弦関数は正弦関数の偶関数版で、偶数次のべきのみを含みます。
余弦関数
正弦級数と余弦級数を並べて見ると、相補的であることに気づくはずです。この関係はオイラーの有名な恒等式 eⁱˣ = cos(x) + i·sin(x) へとつながります。
自然対数 ln(1 + x) は x = 0 を中心としたテイラー級数を持ちます。
自然対数関数
先の 3 つと異なり、これは -1 < x <= 1 でのみ収束します。この範囲を外れると級数は発散します。これはクロスエントロピー損失でも問題になり、対数確率は有効な範囲にとどめる必要があります。
等比級数は数学で最も古く、最もよく使われる結果の一つです。
等比級数
これは |x| < 1 でのみ収束します。多くの他のテイラー級数を導く出発点であり、確率論、信号処理、割引現在価値の総和などに現れます。
壁に貼っておけるような、手元に置ける早見表が欲しい方のために用意しました。

テイラー級数クイックリファレンス
これら 5 つの級数で、データサイエンスや機械学習で遭遇する大半のケースをカバーできます。
テイラー級数、フーリエ級数、マクローリン級数はいずれも関数を近似しますが、解く問題も最適な文脈も異なります。
テイラー級数とフーリエ級数はいずれも関数を無限和で表しますが、そのアプローチはまったく異なります。
テイラー級数は (x - a) のべき、すなわち多項式から関数を構築します。一点にズームインし、その点での導関数を通じて局所的な振る舞いを捉えます。結果は中心点 a 付近で正確ですが、離れるにつれて精度は落ちます。
フーリエ級数は正弦波と余弦波を構成要素として用います。
フーリエ級数
一点での局所的な振る舞いを捉えるのではなく、区間全体にわたる周期的な大域的振る舞いを捉えます。繰り返す関数、すなわち音声信号、季節性パターン、振動するあらゆるものに適しています。
両者の比較を並べると次のようになります。
テイラー vs. フーリエの比較
フーリエ級数は信号処理や時系列解析で登場します——スペクトル解析、周波数分解、さらには注意機構をフーリエ変換で置き換える FNet のようなニューラルネットワークアーキテクチャでも使われます。
表形式データ、画像、または最適化を扱うならテイラー級数がより関係します。音声、時系列、周期構造のあるものを扱うならフーリエ級数の方が適しています。
これは簡単です。マクローリン級数は単に a = 0 を中心としたテイラー級数です。
テイラー級数の一般形は次のとおりです。
マクローリン級数
a = 0 とすれば、次のようになります。
a = 0 におけるマクローリン級数
Colin Maclaurin は自身の研究でこの特別な場合を頻繁に用いたため、独自の名称が与えられましたが、数学的には、特定の中心点におけるテイラー級数にほかなりません。
実務では、目にする多くの級数——eˣ、sin(x)、cos(x)、ln(1 + x)——はマクローリン級数です。0 を中心にすると代数がすっきりするからです。別の点で近似が必要な場合は、中心を a ≠ 0 に移して一般のテイラー級数を得ます。
まとめると、すべてのマクローリン級数はテイラー級数ですが、すべてのテイラー級数がマクローリン級数とは限りません。
テイラー級数と線形モデルは一見無関係に見えるかもしれませんが、知っておくべきつながりがあります。その出発点は一次のテイラー近似です。
テイラー級数を第 1 項で打ち切ると、点 a 付近での関数の線形近似が得られます。
テイラー級数と線形モデル (1)
これは直線です。傾き(f'(a))と切片(f(a) - f'(a) ⋅ a)があります。聞き覚えがあるでしょうか。これは 単回帰 モデルと同じ構造です。
テイラー級数と線形モデル (2)
違いは出自です。テイラー近似では、傾きと切片は一点での導関数により定まります。線形回帰では、予測誤差を最小化するようデータから推定されます。しかし構造的には、どちらも同じことを行っています。
線形モデルが有効な状況と破綻する状況の理由が説明できます。
線形回帰は、入力と出力の関係が線形である(あるいは線形と見なせる)と仮定します。テイラー級数は、その仮定がいつ成り立つかを正確に教えてくれます——入力が一定の点の近くにとどまり、近似する関数が滑らかなときです。入力がその点から大きく離れると、線形近似は破綻します。これは、強い非線形パターンを持つデータで線形回帰がうまくいかない理由と同じです。
一般化線形モデル(GLM)は、この関係をさらに明確にします。
たとえばロジスティック回帰は、アウトカムの対数オッズを線形関数としてモデル化します。線形予測子と出力確率のあいだのつながりはシグモイド関数を介しており、先ほど見たようにシグモイドは 0 付近でよく振る舞うテイラー展開を持ちます。
一次のテイラー展開が線形モデルを与えると理解したら、次は項を増やす段階です。すると多項式モデルになります。
二次のテイラー展開は次のようになります。
二次のテイラー級数
これは二次式であり、二乗項を持つ多項式回帰モデルです。テイラーの各追加項はより高次数の多項式に対応し、多項式回帰が曲がった関係を捉えるべく線形回帰を拡張する仕組みになっています。
したがってテイラー級数は、回帰におけるバイアス・バリアンスのトレードオフを考えるうえで理にかなった方法を与えます。一次近似(線形モデル)は高速で解釈しやすい反面、真の関係が非線形であればバイアスが大きくなります。高次近似は展開点付近でデータによりよく適合しますが、項を増やすにつれて過学習のリスクが高まります。
線形回帰とその有効性をさらに深掘りしたい方は、Essentials of Linear Regression in Python チュートリアルが次の一歩として適しています。R ユーザーには、Intermediate Regression in R のコースで多項式回帰やモデル診断を詳しく扱っています。
テイラー級数は、一度見つけ方を知ると何度も目にする数学ツールの一つです。
テイラー級数により eˣ や sin(x) のような関数を基本的な算術で計算できること、収束と打切り誤差が近似の精度を左右すること、そして同じ考え方が勾配降下法、XGBoost、現代の機械学習における活性化関数の近似を支えていることを見てきました。
指数・正弦・余弦・対数・等比の 5 つの有名な級数は覚えておく価値があります。頻繁に登場するため、見た瞬間にわかるようになれば本当に時間の節約になります。
ここから先は、この種の数学と並走するアルゴリズム的思考に慣れることが次のステップです。弊社のData Structures and Algorithms in Python コースは、その基礎を築くのに最適です。数学的なアイデアが、実際に動きスケールするコードへどう翻訳されるのかが理解できるようになります。
DataCamp で学ぶ
Courses
Courses
Courses