
Curso
Preprocesamiento para machine learning en Python
4 h
66.5K
¿Te has preguntado alguna vez cómo calcula realmente un ordenador una función como sin(x) o eˣ?
Los ordenadores no pueden evaluar directamente la mayoría de funciones matemáticas. Solo saben sumar, restar, multiplicar y dividir. Así que cuando llamas a math.sin(0.5) en Python, algo tiene que convertir eso en una secuencia de operaciones aritméticas básicas. Ese "algo" es la aproximación polinómica, y las series de Taylor son su fundamento matemático.
Una serie de Taylor te permite reescribir casi cualquier función suave como una suma infinita de términos más simples, construidos a partir de las derivadas de la función en un único punto. Cuando entiendes esta idea, muchas cosas en ciencia de datos y aprendizaje automático empiezan a encajar: desde cómo funciona el descenso por gradiente hasta por qué ciertos activadores se comportan como lo hacen.
En este artículo, te explicaré qué son las series de Taylor, cómo funcionan matemáticamente, dónde aparecen en ciencia de datos y machine learning, y cómo se relacionan con otros tipos de series.
Las series de Taylor existen desde hace siglos. Brook Taylor las introdujo en 1715, aunque James Gregory y Colin Maclaurin también hicieron contribuciones clave a la idea.
El objetivo era encontrar una forma de representar funciones complejas mediante polinomios, que son mucho más manejables.
Una serie de Taylor aproxima una función expresándola como una suma infinita de términos, cada uno derivado de las derivadas de la función en un único punto. Cuantos más términos incluyas, más se acercará la aproximación a la función real.
La fórmula general es:
Fórmula general de la serie de Taylor
Cada término de la suma tiene tres componentes:
f⁽ⁿ⁾(a) - la n-ésima derivada de la función evaluada en el punto central a
n! - el factorial de n, que evita que los términos crezcan sin control
(x - a)ⁿ - el término de expansión, que mide la distancia de x al punto central
El punto central a es donde anclas la serie. Cuando a = 0, obtienes un caso especial llamado serie de Maclaurin; hablaremos de ello más adelante.
La función exponencial eˣ es un primer ejemplo perfecto. Su derivada es ella misma, así que f⁽ⁿ⁾(0) = 1 para todo n. Centrada en a = 0, la serie de Taylor queda así:
Ejemplo concreto
Digamos que quieres aproximar e⁰·⁵. Sustituye x = 0.5 en los cuatro primeros términos; aquí tienes un ejemplo en Python:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Ejemplo concreto en Python
El valor real de e⁰·⁵ es aproximadamente 1.6487. Con solo cuatro términos ya estás a menos del 0,2% de la respuesta exacta. Si añades más términos, la aproximación mejora.
Esa es la potencia de las series de Taylor.
Funciones como eˣ, sin(x) y cos(x) son difíciles de evaluar directamente, pero su serie de Taylor las reduce a aritmética básica. Justo con lo que un ordenador puede trabajar.
Una serie de Taylor solo es útil si realmente converge a la función que quieres aproximar. Veamos qué significa y qué pasa cuando no ocurre.
Cuando expandes una serie de Taylor, construyes un polinomio término a término. Cada término añade información sobre el comportamiento de la función cerca del punto central a.
Toma sin(x) centrada en a = 0:
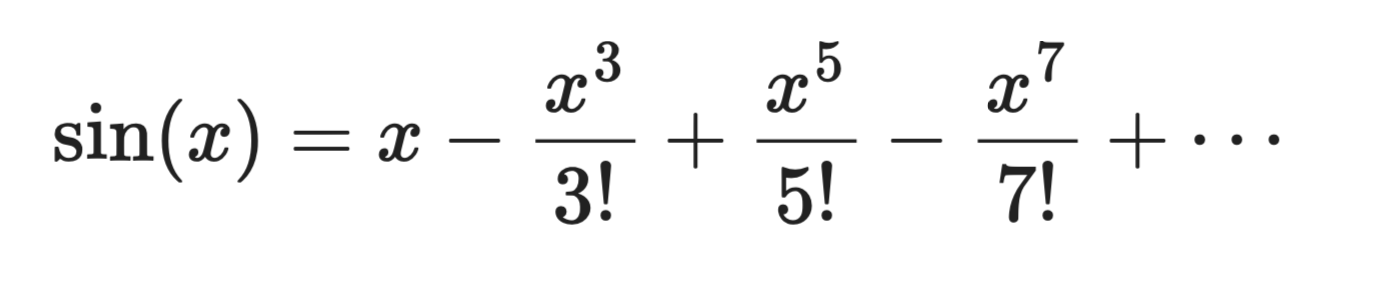
Expansión de la serie de Taylor
El primer término, x, es una aproximación lineal burda. Añade el segundo y la curva se ajusta más. Añade más términos y el polinomio empieza a parecerse a sin(x) cerca de x = 0.
En pocas palabras, expandir significa cambiar una función exacta pero difícil de calcular por un polinomio con el que sí puedes trabajar.
Nunca vas a calcular infinitos términos. En la práctica, te detienes tras unos pocos y aceptas un pequeño error. El resultado se llama serie de Taylor truncada, y el error introducido es el error de truncamiento.
El resto de Lagrange te da una cota para ese error. Para una serie truncada tras n términos:
Resto de Lagrange
Donde c es un punto entre x y a. No conoces c exactamente, pero puedes acotar f⁽ⁿ⁺¹⁾(c) si sabes cuánto pueden crecer las derivadas de tu función.
Así puedes interpretarlo
Cuanto más lejos esté x del punto central a, mayor será el error
Cuantos más términos incluyas, menor será el error
Las funciones con derivadas grandes y de crecimiento rápido son más difíciles de aproximar con precisión
Supón que aproximas sin(0.1) con tres términos:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Aproximación en Python
Tres términos te dan precisión de hasta diez decimales cuando x está cerca de 0. Ese es el error de truncamiento en acción: pequeño, pero no nulo.
Una serie de Taylor converge en un punto x si las sumas parciales se acercan cada vez más a un valor fijo a medida que añades términos. Ese valor debería ser f(x), pero no siempre está garantizado.
El radio de convergencia R indica hasta qué distancia del punto central la serie sigue siendo válida. Dentro de ese radio, la serie converge. Fuera, los términos crecen en lugar de decrecer, y la aproximación se viene abajo.
Fórmula de convergencia
Funciones distintas tienen radios distintos:
eˣ, sin(x) y cos(x) convergen para todo x, por lo que R = ∞
ln(1 + x) solo converge para -1 < x <= 1, así que R = 1
1/1-x converge para |x| < 1, por lo que R = 1
Una función también puede tener radio de convergencia infinito y aun así no coincidir con su serie de Taylor en ciertos puntos. Se denominan funciones no analíticas; son casos límite poco frecuentes en ciencia de datos, pero conviene conocerlos.
Así que, antes de fiarte de una aproximación de Taylor, comprueba siempre si x cae dentro del radio de convergencia.
Las series de Taylor aparecen en más sitios de los que imaginas: desde simulaciones de física hasta la resolución de ecuaciones diferenciales. Pero su mayor impacto en tu día a día como data scientist está en la optimización y la aproximación de modelos.
Cada vez que entrenas un modelo de machine learning, ejecutas algún tipo de optimización. Y las series de Taylor suelen estar detrás de esa optimización.
El descenso por gradiente usa una aproximación de Taylor de primer orden. Cuando calculas el gradiente de una función de pérdida L(θ) en los parámetros actuales θ, esencialmente preguntas: «si doy un pequeño paso en esta dirección, ¿cuánto cambia la pérdida?» Eso es una expansión de Taylor de primer orden alrededor del punto actual:
Series de Taylor en optimización
Funciona, pero ignora la curvatura. Si la superficie de pérdida es curva, una aproximación de primer orden puede pasarse de largo o dar pasos ineficientes.
El método de Newton corrige esto incluyendo el término de segundo orden: la matriz Hessiana H, que captura la curvatura:
Series de Taylor en optimización (2)
Igualar a cero la derivada de esta expresión te da el paso óptimo que debes dar. El coste es que calcular la Hessiana completa es caro en modelos grandes. Métodos como L-BFGS la aproximan y logran gran parte del beneficio a una fracción del coste.
Algunas funciones de activación son costosas de calcular. Las series de Taylor te dan alternativas más baratas y lo bastante precisas para la mayoría de casos.
La función sigmoide σ(x) = 1 / (1 + e⁻ˣ) requiere calcular una exponencial, que es costoso. Cerca de x = 0, su expansión de Taylor es:
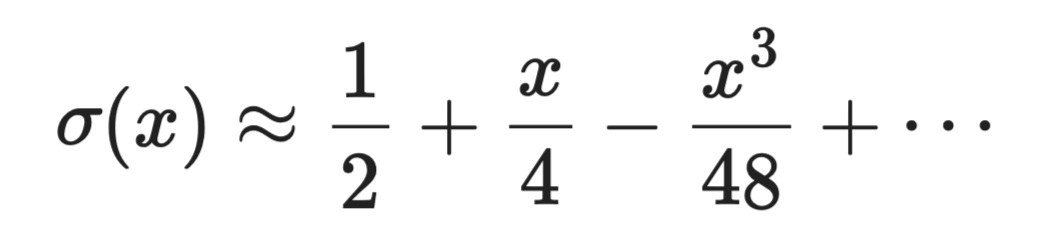
Serie de Taylor en aproximación
En entornos con limitaciones de hardware, como dispositivos edge o FPGAs, estas aproximaciones polinómicas pueden sustituir cálculos exactos por unas pocas operaciones de multiplicar y sumar.
GELU, usada en modelos tipo transformer como BERT y GPT, suele implementarse mediante una aproximación basada en Taylor de la función error erf(x), ya que su forma exacta implica una integral sin solución en forma cerrada.
XGBoost es una de las librerías de gradient boosting más usadas y emplea una expansión de Taylor de segundo orden de la función de pérdida para ajustar cada árbol nuevo.
En cada paso de boosting, XGBoost aproxima la pérdida como:
Aproximación de la pérdida en XGBoost
Donde g_i es el gradiente de primer orden y h_i es el gradiente de segundo orden (Hessiano) de la pérdida respecto a la predicción actual. Usar ambos términos permite a XGBoost ajustar árboles más rápido y con más precisión que los métodos de primer orden, lo que explica gran parte de su rendimiento en datos tabulares.
Que las series de Taylor puedan usarse por toda la ciencia de datos no significa que sean la solución para todo. Hay un par de cosas que pueden salir mal.
El error de aproximación se acumula: en redes profundas, encadenas muchas operaciones. Un pequeño error de Taylor en una capa se compone a lo largo de las capas y puede afectar a la estabilidad del entrenamiento
El radio de convergencia importa: las aproximaciones de Taylor solo son fiables cerca del punto de expansión. Si tus entradas se alejan de donde construiste la aproximación —por ejemplo, en inferencia con datos fuera de distribución—, la aproximación puede fallar
Las Hessianas de alta dimensión son caras: los métodos de segundo orden son potentes pero no escalan bien. Un modelo con n parámetros tiene una Hessiana de n × n. En modelos con millones de parámetros, almacenar e invertir esa matriz es inviable sin aproximaciones.
Si entiendes estos compromisos, sabrás cuándo merece la pena un enfoque basado en Taylor y cuándo basta con uno de primer orden.
Hay un par de series de Taylor que aparecen por todas partes en matemáticas, física y machine learning. Estas son las que conviene conocer si vas en serio con la ciencia de datos.
La función exponencial eˣ es la serie de Taylor más sencilla de derivar, ya que cada derivada de eˣ es la propia eˣ. Evaluada en a = 0, todos los coeficientes son 1:
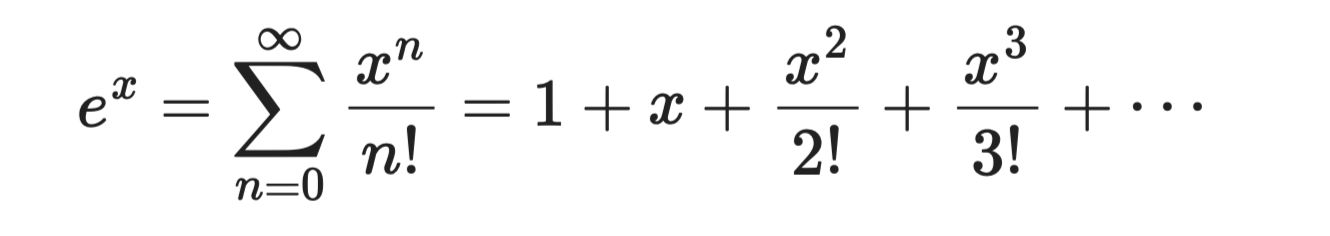
Función exponencial
Esta serie converge para todo x, lo que la hace fiable y fácil de usar. Es la base de las funciones sigmoide y softmax usadas en modelos de clasificación.
La función seno solo contiene potencias impares, consecuencia de que sin(x) es una función impar —es decir, sin(-x) = -sin(x):
Función seno
Al igual que eˣ, converge para todo x. Los signos alternos provienen de que las derivadas de sin(x) ciclan por cos(x), -sin(x), -cos(x) y vuelta a empezar.
El coseno es el contrapunto par del seno: solo contiene potencias pares:
Función coseno
Si miras juntas las series de seno y coseno, verás que son complementarias. Esta relación conduce a la famosa identidad de Euler: eⁱˣ = cos(x) + i·sin(x).
El logaritmo natural ln(1 + x) tiene una serie de Taylor centrada en x = 0:
Función logaritmo natural
A diferencia de las tres anteriores, esta solo converge para -1 < x <= 1. Si llevas x fuera de ese rango, la serie diverge. Esto aparece en la pérdida de entropía cruzada, donde las probabilidades logarítmicas deben permanecer en un rango válido.
La serie geométrica es uno de los resultados más antiguos y usados en matemáticas:
Serie geométrica
Solo converge para |x| < 1. Es el punto de partida para derivar muchas otras series de Taylor, y aparece en teoría de la probabilidad, procesado de señal y en cualquier parte donde sumes valores futuros descontados.
Si buscas algo tangible, imprimible, para colgar al lado de la cama, aquí lo tienes:

Chuleta rápida de series de Taylor
Estas cinco series cubren la mayoría de casos que verás en ciencia de datos y machine learning.
Las series de Taylor, Fourier y Maclaurin todas aproximan funciones, pero resuelven problemas distintos y funcionan mejor en contextos diferentes.
Las series de Taylor y Fourier representan funciones como sumas infinitas, pero lo hacen de maneras completamente distintas.
Una serie de Taylor construye la función con polinomios —potencias de (x - a)—. Funciona haciendo zoom en un punto y capturando el comportamiento local mediante las derivadas. El resultado es preciso cerca del punto a, pero la precisión disminuye al alejarse.
Una serie de Fourier usa senos y cosenos como bloques de construcción:
Serie de Fourier
En lugar de capturar el comportamiento local en un punto, las series de Fourier capturan el comportamiento periódico global a lo largo de todo un intervalo. Están pensadas para funciones que se repiten: señales de audio, patrones estacionales o cualquier cosa que oscile.
Así se comparan, a grandes rasgos:
Comparativa Taylor vs. Fourier
Las series de Fourier aparecen en procesado de señal y análisis de series temporales: análisis espectral, descomposición en frecuencias e incluso algunas arquitecturas neuronales como FNet, que sustituye la atención por transformadas de Fourier.
Si trabajas con datos tabulares, imágenes u optimización, las series de Taylor son la herramienta más relevante. Si trabajas con audio, series temporales o cualquier cosa con estructura periódica, las series de Fourier encajan mejor.
Esta es sencilla: una serie de Maclaurin es simplemente una serie de Taylor centrada en a = 0.
La serie de Taylor general es:
Serie de Maclaurin
Si fijas a = 0 obtienes:
Serie de Maclaurin con a = 0
Colin Maclaurin usó tanto este caso particular que acabó con nombre propio, pero matemáticamente no es más que una serie de Taylor con un punto central específico.
En la práctica, la mayoría de series que verás —eˣ, sin(x), cos(x), ln(1 + x)— son series de Maclaurin, porque centrar en cero simplifica el álgebra. Cuando necesitas aproximar una función cerca de otro punto, desplazas el centro a a ≠ 0 y obtienes la serie de Taylor general.
En resumen, toda serie de Maclaurin es una serie de Taylor, pero no toda serie de Taylor es de Maclaurin.
Las series de Taylor y los modelos lineales pueden parecer cosas distintas, pero hay una conexión interesante, que empieza con la aproximación de Taylor de primer orden.
Si truncas una serie de Taylor tras el primer término, obtienes una aproximación lineal de una función cerca de un punto a:
Series de Taylor y modelos lineales (1)
Es una recta. Tiene una pendiente (f'(a)) y una intersección (f(a) - f'(a) ⋅ a). ¿Te suena? Es la misma estructura que un modelo de regresión lineal simple:
Series de Taylor y modelos lineales (2)
La diferencia está en el origen de cada una. En una aproximación de Taylor, la pendiente y la intersección vienen dadas por las derivadas de la función en un punto. En regresión lineal, se estiman a partir de datos para minimizar el error de predicción. Pero, estructuralmente, hacen lo mismo.
Explica por qué los modelos lineales funcionan bien en ciertas situaciones y fallan en otras.
La regresión lineal asume que la relación entre entrada y salida es —o puede tratarse como— lineal. Las series de Taylor te dicen exactamente cuándo se cumple esa suposición: cuando tus entradas permanecen cerca de un punto fijo y la función que aproximas es suave. Si alejas las entradas de ese punto, la aproximación lineal se rompe, por la misma razón por la que la regresión lineal falla a menudo con datos con patrones muy no lineales.
Los modelos lineales generalizados (GLM) hacen esta conexión aún más explícita.
La regresión logística, por ejemplo, modela el logit (log-odds) del resultado como una función lineal. El vínculo entre el predictor lineal y la probabilidad de salida pasa por la función sigmoide, y como has visto, la sigmoide tiene una expansión de Taylor bien comportada cerca de cero.
Una vez que entiendes que una expansión de Taylor de primer orden te da un modelo lineal, el siguiente paso es incluir más términos para obtener un modelo polinómico.
Una expansión de Taylor de segundo orden te da:
Serie de Taylor de segundo orden
Esto es un cuadrático: un modelo de regresión polinómica con término al cuadrado. Cada término adicional de Taylor corresponde a un polinomio de grado superior, que es como la regresión polinómica amplía la lineal para capturar relaciones curvas.
Así, las series de Taylor te dan una forma fundamentada de pensar sobre la compensación sesgo-varianza en regresión. Una aproximación de primer orden (modelo lineal) es rápida e interpretable, pero presenta alto sesgo si la relación real es no lineal. Las aproximaciones de mayor orden ajustan mejor cerca del punto de expansión, pero arriesgan sobreajuste al añadir términos.
Si quieres profundizar en regresión lineal y cuándo funciona, el tutorial Essentials of Linear Regression in Python es un buen siguiente paso. Para usuarios de R, el curso Intermediate Regression in R cubre regresión polinómica y diagnóstico de modelos en detalle.
Las series de Taylor son una de esas herramientas matemáticas que, una vez las conoces, no dejan de aparecer.
Has visto cómo permiten a los ordenadores evaluar funciones como eˣ y sin(x) con aritmética básica, cómo la convergencia y el error de truncamiento determinan la precisión de una aproximación, y cómo la misma idea impulsa el descenso por gradiente, XGBoost y las aproximaciones de funciones de activación en el machine learning moderno.
Las cinco series más conocidas —exponencial, seno, coseno, logaritmo y geométrica— merecen la pena memorizarlas. Aparecen tan a menudo que reconocerlas al instante te ahorra tiempo real.
A partir de aquí, el siguiente paso es afianzar el pensamiento algorítmico que acompaña a este tipo de matemáticas. Nuestro curso Data Structures and Algorithms in Python es un buen lugar para construir esa base. Te ayudará a entender cómo estas ideas matemáticas se traducen en código que funciona y escala.
Aprende con DataCamp
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
Tutorial
Bekhruz Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
