course
Preprocessing for Machine Learning in Python
4 घंटा
66.6K
क्या आपने कभी सोचा है कि कंप्यूटर वास्तव में sin(x) या eˣ जैसे फलनों की गणना कैसे करता है?
कंप्यूटर अधिकांश गणितीय फलनों का सीधे मान नहीं निकाल सकते। वे केवल जोड़, घटाव, गुणा और भाग कर सकते हैं। तो जब आप Python में math.sin(0.5) कॉल करते हैं, तो किसी चीज़ को उसे बुनियादी अंकगणित के क्रम में बदलना पड़ता है। वह चीज़ है बहुपद अपरूपण, और टेलर श्रेणियाँ उसके पीछे की गणितीय नींव हैं।
टेलर श्रेणी आपको लगभग किसी भी समतल (smooth) फलन को सरल पदों के अनंत योग के रूप में लिखने देती है, जहाँ हर पद उस फलन के एक ही बिंदु पर लिए गए अवकलजों से बनता है। एक बार यह विचार समझ में आ जाए, तो डेटा साइंस और मशीन लर्निंग की बहुत-सी बातें स्पष्ट होने लगती हैं — ग्रेडिएंट डिसेंट कैसे काम करता है से लेकर कुछ एक्टिवेशन फंक्शनों का व्यवहार वैसा क्यों होता है।
इस लेख में, मैं आपको टेलर श्रेणियाँ क्या हैं, वे गणितीय रूप से कैसे काम करती हैं, डेटा साइंस और मशीन लर्निंग में वे कहाँ दिखती हैं, और वे अन्य तरह की श्रेणियों से कैसे संबंधित हैं — इन सबके बारे में बताऊँगा।
टेलर श्रेणियाँ सदियों से प्रचलित हैं। ब्रुक टेलर ने 1715 में इन्हें प्रस्तुत किया, हालांकि जेम्स ग्रेगरी और कॉलिन मैक्लॉरिन ने भी इस विचार में महत्वपूर्ण योगदान दिया।
लक्ष्य था जटिल फलनों को बहुपदों के माध्यम से निरूपित करना — क्योंकि बहुपदों के साथ काम करना कहीं आसान है।
टेलर श्रेणी किसी फलन को उसके एक बिंदु पर लिए गए अवकलजों से निकले पदों के अनंत योग के रूप में व्यक्त करके उसका अपरूपण करती है। जितने अधिक पद शामिल करेंगे, अपरूपण उतना ही वास्तविक फलन के करीब पहुँचेगा।
सामान्य सूत्र यह है:
टेलर श्रेणी का सामान्य सूत्र
इस योग के हर पद में तीन घटक होते हैं:
f⁽ⁿ⁾(a) - केंद्र बिंदु a पर फलन का nवाँ अवकलज
n! - n का फैक्टोरियल, जो पदों को अनियंत्रित रूप से बढ़ने से रोकता है
(x - a)ⁿ - प्रसार (expansion) पद, जो मापता है कि x केंद्र बिंदु से कितना दूर है
केंद्र बिंदु a वह स्थान है जहाँ आप श्रेणी को एंकर करते हैं। जब a = 0 होता है, तो एक विशेष स्थिति मिलती है जिसे मैक्लॉरिन श्रेणी कहते हैं — इस पर आगे बात करेंगे।
घातीय फलन eˣ उपयुक्त पहला उदाहरण है। इसका अवकलज वही खुद है, इसलिए हर n के लिए f⁽ⁿ⁾(0) = 1। a = 0 पर केंद्रित टेलर श्रेणी यह बनती है:
ठोस उदाहरण
मान लें आप e⁰·⁵ का अपरूपण करना चाहते हैं। बस x = 0.5 को पहले चार पदों में रखें — यहाँ एक Python उदाहरण है:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Python में ठोस उदाहरण
e⁰·⁵ का वास्तविक मान लगभग 1.6487 है। केवल चार पदों से ही आप सही उत्तर के 0.2% के भीतर पहुँच जाते हैं। और पद जोड़ें, तो अपरूपण और सटीक होगा।
यही टेलर श्रेणियों की शक्ति है।
eˣ, sin(x) और cos(x) जैसे फलनों का प्रत्यक्ष मान निकालना कठिन है, पर उनकी टेलर श्रेणियाँ उन्हें बुनियादी अंकगणित तक सीमित कर देती हैं — और यही वह है जिससे कंप्यूटर काम करता है।
टेलर श्रेणी तभी उपयोगी है जब वह वास्तव में उस फलन की ओर अभिसरित (converge) हो, जिसका आप अपरूपण कर रहे हैं। देखें, इसका अर्थ क्या है और जब ऐसा नहीं होता तो क्या होता है।
जब आप टेलर श्रेणी का प्रसार करते हैं, तो आप एक-एक करके बहुपद बनाते हैं। हर पद केंद्र बिंदु a के पास फलन के व्यवहार की और जानकारी जोड़ता है।
मान लें sin(x) को a = 0 पर केंद्रित किया जाए:
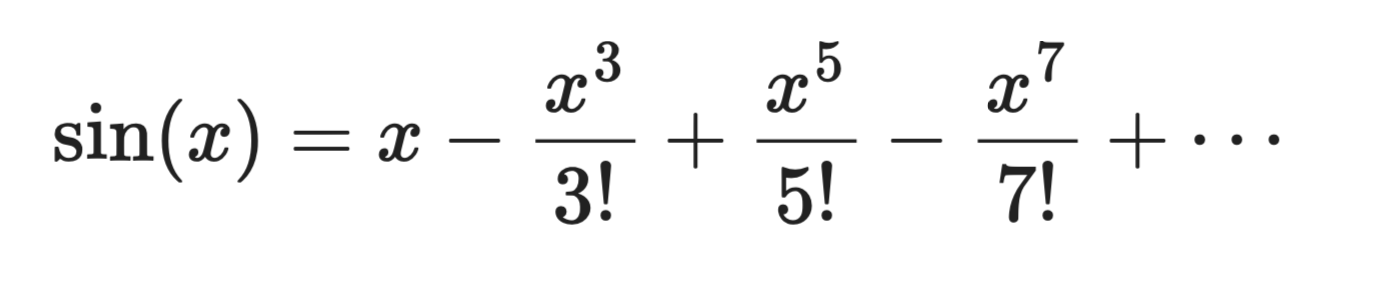
टेलर श्रेणी का प्रसार
पहला पद x एक मोटा रैखिक अपरूपण है। दूसरा पद जोड़ें तो वक्र और करीब आता है। और पद जोड़ें, तो बहुपद x = 0 के पास ठीक-ठीक sin(x) जैसा दिखने लगता है।
सीधी भाषा में, प्रसार का मतलब है कि आप एक सटीक किंतु कठिन-से-गणना फलन की जगह ऐसा बहुपद ले रहे हैं जिसके साथ आप वास्तव में काम कर सकें।
आप कभी भी अनंत पदों की गणना नहीं करेंगे। व्यवहार में, आप कुछ पदों पर रुकते हैं और थोड़ी त्रुटि स्वीकार करते हैं। इस परिणाम को कटित (truncated) टेलर श्रेणी कहते हैं, और इससे आने वाली त्रुटि को कटन त्रुटि (truncation error) कहते हैं।
लाग्रांज शेष (Lagrange remainder) उस त्रुटि की एक सीमा देता है। n पदों के बाद कटित श्रेणी के लिए:
लाग्रांज शेष
जहाँ c x और a के बीच का कोई बिंदु है। आपको c का ठीक मान नहीं पता, पर यदि आपको अपने फलन के अवकलजों के अधिकतम आकार का अंदाज़ा है, तो आप f⁽ⁿ⁺¹⁾(c) को सीमाबद्ध कर सकते हैं।
इसे यूँ समझें
जितना अधिक x केंद्र बिंदु a से दूर होगा, त्रुटि उतनी ही बड़ी होगी
जितने अधिक पद शामिल करेंगे, त्रुटि उतनी ही छोटी होगी
जिन फलनों के अवकलज बड़े और तेजी से बढ़ते हैं, उनका सटीक अपरूपण कठिन होता है
मान लें आप sin(0.1) को तीन पदों से अपरूपित कर रहे हैं:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Python में अपरूपण
जब x 0 के पास होता है, तो तीन पद आपको दस दशमलव स्थानों तक की शुद्धता दे देते हैं। यही कटन त्रुटि का प्रभाव है — बहुत छोटी, पर शून्य नहीं।
किसी बिंदु x पर टेलर श्रेणी तब अभिसरित होती है जब अधिक पद जोड़ने पर आंशिक योग किसी नियत मान के और-और पास आते जाते हैं। वह नियत मान f(x) होना चाहिए — पर यह हमेशा सुनिश्चित नहीं होता।
अभिसरण त्रिज्या R बताती है कि केंद्र बिंदु से कितनी दूर तक श्रेणी मान्य रहती है। इस त्रिज्या के भीतर श्रेणी अभिसरित होती है। इसके बाहर, पद सिकुड़ने के बजाय बढ़ते हैं और अपरूपण विफल हो जाता है।
अभिसरण सूत्र
अलग-अलग फलनों की अलग अभिसरण त्रिज्याएँ होती हैं:
eˣ, sin(x) और cos(x) सभी x मानों के लिए अभिसरित होती हैं, इसलिए R = ∞
ln(1 + x) केवल -1 < x <= 1 के लिए अभिसरित होती है, इसलिए R = 1
1/1-x |x| < 1 के लिए अभिसरित होती है, इसलिए R = 1
किसी फलन की अभिसरण त्रिज्या अनंत भी हो सकती है, फिर भी कुछ बिंदुओं पर वह अपनी टेलर श्रेणी के बराबर न हो। इन्हें अननालीय (non-analytic) फलन कहते हैं — डेटा साइंस में ये कम दिखते हैं, पर जानना उपयोगी है।
तो, टेलर अपरूपण पर भरोसा करने से पहले हमेशा जाँचें कि x अभिसरण त्रिज्या के भीतर है या नहीं।
टेलर श्रेणियाँ उम्मीद से कहीं ज्यादा जगह दिखती हैं — भौतिकी सिमुलेशन से लेकर गणितीय अंतर समीकरणों के हल तक। लेकिन एक डेटा वैज्ञानिक के रूप में रोज़मर्रा के काम में इनका सबसे बड़ा प्रभाव अनुकूलन और मॉडल अपरूपण में है।
जब भी आप कोई मशीन लर्निंग मॉडल प्रशिक्षित करते हैं, आप किसी न किसी रूप में अनुकूलन चला रहे होते हैं। और अक्सर उस अनुकूलन के पीछे टेलर श्रेणी होती है।
ग्रेडिएंट डिसेंट प्रथम-क्रम (first-order) टेलर अपरूपण का उपयोग करता है। जब आप वर्तमान पैरामीटरों θ पर किसी लॉस फलन L(θ) का ग्रेडिएंट निकालते हैं, तो आप मूलतः पूछ रहे होते हैं: "यदि मैं इस दिशा में छोटा-सा कदम लूँ, तो लॉस कितना बदलेगा?" यह वर्तमान बिंदु के आस-पास का प्रथम-क्रम टेलर प्रसार है:
अनुकूलन में टेलर श्रेणी
यह काम करता है, पर वक्रता (curvature) को नज़रअंदाज़ करता है। यदि लॉस सतह मुड़ी हुई है, तो प्रथम-क्रम अपरूपण ज़्यादा आगे निकल सकता है या अल्प-प्रभावी कदम उठा सकता है।
न्यूटन विधि इसे दूसरे-क्रम के पद — हेसेयन मैट्रिक्स H — को शामिल कर ठीक करती है, जो वक्रता को दर्ज करता है:
अनुकूलन में टेलर श्रेणी (2)
इस अभिव्यक्ति का अवकलज शून्य करने पर उठाए जाने वाले इष्टतम कदम का मान मिलता है। समझौता यह है कि बड़े मॉडलों के लिए पूर्ण हेसेयन की गणना महँगी होती है। L-BFGS जैसी विधियाँ इसका अपरूपण करती हैं, जिससे कम लागत पर अधिकांश लाभ मिल जाता है।
कुछ एक्टिवेशन फंक्शन की गणना महँगी होती है। टेलर श्रेणियाँ आपको सस्ते विकल्प देती हैं जो अधिकांश उद्देश्यों के लिए पर्याप्त रूप से सटीक होते हैं।
the sigmoid function σ(x) = 1 / (1 + e⁻ˣ) के लिए घातांक की गणना करनी पड़ती है, जो महँगी है। x = 0 के पास इसका टेलर प्रसार यह है:
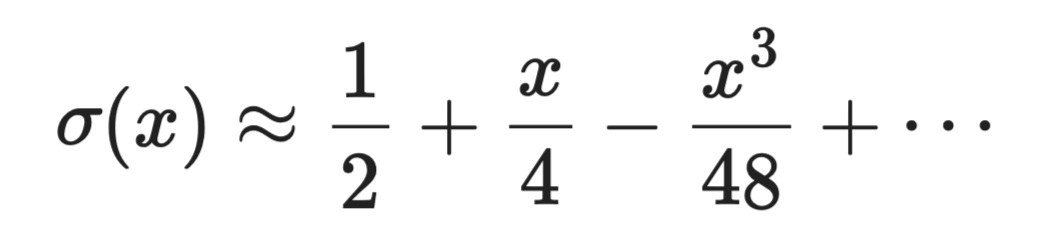
अपरूपण में टेलर श्रेणी
एज डिवाइस या FPGA जैसी हार्डवेयर-सीमित स्थितियों में, ऐसे बहुपद अपरूपण सटीक गणनाओं की जगह कुछ मल्टिप्लाई-ऐड ऑपरेशनों से काम चला देते हैं।
GELU, जो BERT और GPT जैसे ट्रांसफॉर्मर मॉडलों में प्रयुक्त होता है, को अक्सर त्रुटि फलन erf(x) के टेलर-आधारित अपरूपण से लागू किया जाता है, क्योंकि इसके सटीक रूप में ऐसा समाकलन है जिसका बंद-रूप हल नहीं है।
XGBoost सबसे व्यापक रूप से प्रयुक्त ग्रेडिएंट बूस्टिंग लाइब्रेरी में से एक है, और यह प्रत्येक नए पेड़ को फिट करने के लिए लॉस फलन के द्वितीय-क्रम टेलर प्रसार का उपयोग करती है।
हर बूस्टिंग चरण पर, XGBoost लॉस का अपरूपण इस प्रकार करती है:
XGBoost लॉस अपरूपण
जहाँ g_i प्रथम-क्रम ग्रेडिएंट है और h_i वर्तमान प्रेडिक्शन के सापेक्ष लॉस का द्वितीय-क्रम ग्रेडिएंट (हेसेयन) है। दोनों पदों का उपयोग XGBoost को प्रथम-क्रम विधियों की तुलना में तेज़ और अधिक सटीक पेड़ फिट करने देता है — यही कारण है कि यह टेबलर डेटा पर इतना अच्छा काम करता है।
सिर्फ इसलिए कि टेलर श्रेणियाँ डेटा साइंस में हर जगह इस्तेमाल हो सकती हैं, इसका मतलब यह नहीं कि वे हर समस्या की सार्वभौमिक औज़ार हैं। कुछ बातें गलत भी हो सकती हैं।
अपरूपण त्रुटि जुड़ती जाती है: गहरे नेटवर्क में आप कई ऑपरेशनों की कड़ियाँ जोड़ते हैं। एक लेयर पर छोटी टेलर अपरूपण त्रुटि परत-दर-परत बढ़ सकती है, जिससे प्रशिक्षण स्थिरता प्रभावित हो सकती है
अभिसरण त्रिज्या मायने रखती है: टेलर अपरूपण केवल प्रसार बिंदु के पास विश्वसनीय होते हैं। यदि आपके इनपुट उस बिंदु से दूर बहक जाएँ — जैसे, आउट-ऑफ-डिस्ट्रिब्यूशन डेटा पर इन्फरेंस के समय — तो अपरूपण टूट सकता है
उच्च-आयामी हेसेयन महँगे होते हैं: द्वितीय-क्रम विधियाँ शक्तिशाली हैं पर उतनी स्केलेबल नहीं। n पैरामीटरों वाले मॉडल का हेसेयन n × n मैट्रिक्स होता है। लाखों पैरामीटरों वाले मॉडल के लिए उस मैट्रिक्स को संग्रहीत करना और उलटना, अपरूपण के बिना व्यावहारिक नहीं।
यदि आप इन समझौतों को समझते हैं, तो आप जान पाएँगे कि कब टेलर-आधारित तरीका सार्थक है और कब सरल प्रथम-क्रम विधि पर्याप्त है।
कुछ टेलर श्रेणियाँ गणित, भौतिकी और मशीन लर्निंग में हर जगह दिखती हैं। यदि आप डेटा साइंस को गंभीरता से लेते हैं, तो इन्हें जानना उपयोगी है।
घातीय फलन eˣ की टेलर श्रेणी निकालना सबसे सरल है, क्योंकि eˣ का हर अवकलज eˣ ही होता है। a = 0 पर मान निकालने पर हर गुणांक 1 होता है:
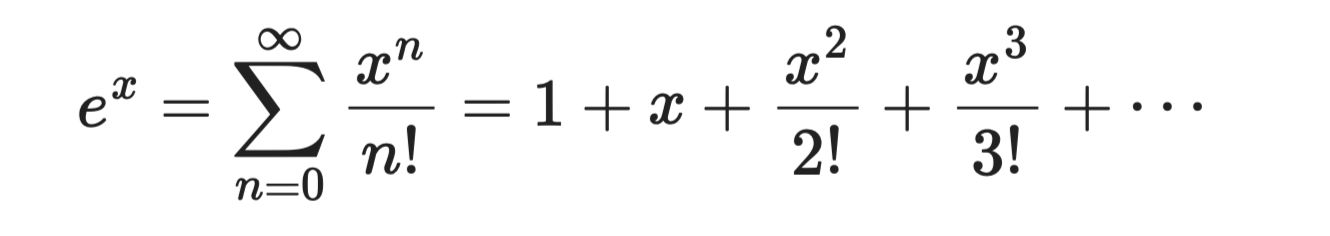
घातीय फलन
यह श्रेणी सभी x मानों के लिए अभिसरित होती है, जिससे इसके साथ काम करना आसान और विश्वसनीय होता है। यही वर्गीकरण मॉडलों में प्रयुक्त सिग्मॉइड और सॉफ़्टमैक्स फलनों की नींव है।
साइन फलन में केवल विषम घातें आती हैं — यह इस तथ्य का परिणाम है कि sin(x) एक odd फलन है, अर्थात sin(-x) = -sin(x):
साइन फलन
eˣ की तरह यह भी सभी x के लिए अभिसरित होती है। वैकल्पिक संकेत (alternating signs) इसलिए आते हैं क्योंकि sin(x) के अवकलज cos(x), -sin(x), -cos(x) और फिर से वापस — इस चक्र से गुजरते हैं।
कोसाइन साइन का even समकक्ष है — इसमें केवल सम घातें आती हैं:
कोसाइन फलन
यदि आप साइन और कोसाइन की श्रेणियों को साथ देखें, तो वे पूरक दिखाई देंगी। यही संबंध ऑयलर की प्रसिद्ध पहचान की ओर ले जाता है: eⁱˣ = cos(x) + i·sin(x)।
प्राकृतिक लघुगणक ln(1 + x) की टेलर श्रेणी x = 0 पर केंद्रित होती है:
प्राकृतिक लघुगणक फलन
पिछली तीनों के विपरीत, यह केवल -1 < x <= 1 के लिए अभिसरित होती है। यदि आप x को इस सीमा से बाहर धकेलें, तो श्रेणी अपसारी हो जाती है। यह क्रॉस-एंट्रॉपी लॉस में सामने आता है, जहाँ लॉग-प्रायिकताएँ मान्य सीमा में रहनी चाहिए।
ज्यामितीय श्रेणी गणित के सबसे पुराने और सर्वाधिक प्रयुक्त परिणामों में से एक है:
ज्यामितीय श्रेणी
यह केवल |x| < 1 के लिए अभिसरित होती है। कई अन्य टेलर श्रेणियाँ निकालने का यही प्रारंभिक बिंदु है, और यह प्रायिकता, सिग्नल प्रोसेसिंग, तथा जहाँ भी आप छूटे हुए (discounted) भविष्य के मानों का योग करते हैं — वहाँ दिखती है।
यदि आप कुछ ठोस, प्रिंट करने योग्य, बिस्तर के पास दीवार पर टाँगने लायक चीज़ ढूँढ रहे हैं, तो यह लीजिए:

टेलर श्रेणी त्वरित संदर्भ
ये पाँच श्रेणियाँ डेटा साइंस और मशीन लर्निंग में मिलने वाले अधिकांश मामलों को कवर करती हैं।
टेलर, फूरिए और मैक्लॉरिन श्रेणियाँ सभी फलनों का अपरूपण करती हैं, पर वे अलग समस्याएँ सुलझाती हैं और अलग संदर्भों में सर्वश्रेष्ठ काम करती हैं।
टेलर और फूरिए, दोनों श्रेणियाँ फलनों को अनंत योग के रूप में दर्शाती हैं, पर बिल्कुल अलग तरीकों से।
टेलर श्रेणी बहुपदों — (x - a) की घातें — से फलन बनाती है। यह एक बिंदु पर ज़ूम-इन करके, अवकलजों के जरिए स्थानीय व्यवहार को पकड़ती है। परिणाम केंद्र बिंदु a के पास सटीक होता है, पर दूर जाने पर सटीकता घटती है।
फूरिए श्रेणी साइन और कोसाइन को बिल्डिंग ब्लॉक्स के रूप में उपयोग करती है:
फूरिए श्रेणी
किसी बिंदु के स्थानीय व्यवहार को पकड़ने के बजाय, फूरिए श्रेणियाँ किसी अंतराल पर वैश्विक आवधिक (periodic) व्यवहार को पकड़ती हैं। ये उन फलनों के लिए बनी हैं जो दोहराते हैं — जैसे ऑडियो संकेत, मौसमी पैटर्न, या कोई भी दोलनकारी चीज़।
दोनों की आमने-सामने तुलना कुछ यूँ दिखती है:
टेलर बनाम फूरिए तुलना
फूरिए श्रेणियाँ सिग्नल प्रोसेसिंग और टाइम सीरीज़ विश्लेषण में दिखती हैं — स्पेक्ट्रल विश्लेषण, फ़्रीक्वेंसी अपघटन, और यहाँ तक कि FNet जैसे कुछ न्यूरल नेटवर्क आर्किटेक्चर में, जो अटेंशन की जगह फूरिए ट्रांसफॉर्म लेते हैं।
यदि आप टेबलर डेटा, इमेज या अनुकूलन के साथ काम कर रहे हैं, तो टेलर श्रेणियाँ अधिक प्रासंगिक हैं। यदि आप ऑडियो, टाइम सीरीज़, या किसी भी आवधिक संरचना वाली चीज़ पर काम कर रहे हैं, तो फूरिए श्रेणियाँ अधिक उपयुक्त हैं।
यह सरल है। मैक्लॉरिन श्रेणी, a = 0 पर केंद्रित टेलर श्रेणी ही है।
टेलर श्रेणी का सामान्य सूत्र है:
मैक्लॉरिन श्रेणी
a = 0 रखें, तो आपको यह मिलता है:
a = 0 पर मैक्लॉरिन श्रेणी
कॉलिन मैक्लॉरिन ने अपने काम में इस विशेष स्थिति का इतना उपयोग किया कि इसे अलग नाम मिल गया, पर गणितीय रूप से यह किसी विशेष केंद्र बिंदु पर टेलर श्रेणी से अधिक कुछ नहीं।
व्यवहार में, जो श्रेणियाँ आप ज़्यादातर देखेंगे — eˣ, sin(x), cos(x), ln(1 + x) — वे मैक्लॉरिन श्रेणियाँ हैं, क्योंकि शून्य पर केंद्रित करने से बीजगणित साफ़ रहता है। जब आपको किसी अन्य बिंदु के पास अपरूपण चाहिए, तो आप केंद्र a ≠ 0 पर शिफ्ट करके सामान्य टेलर श्रेणी लेते हैं।
निष्कर्षतः, हर मैक्लॉरिन श्रेणी टेलर श्रेणी है, पर हर टेलर श्रेणी मैक्लॉरिन नहीं।
पहली नज़र में टेलर श्रेणी और रैखिक मॉडल असंबंधित लग सकते हैं, पर एक उपयोगी कड़ी है — और वह प्रथम-क्रम टेलर अपरूपण से शुरू होती है।
जब आप टेलर श्रेणी को पहले पद के बाद काटते हैं, तो आपको बिंदु a के पास फलन का रैखिक अपरूपण मिलता है:
टेलर श्रेणी और रैखिक मॉडल (1)
यह एक सीधी रेखा है। इसका ढलान (f'(a)) और अवरोध (f(a) - f'(a) ⋅ a) होता है। परिचित लग रहा है? यही संरचना सरल रैखिक प्रतिगमन मॉडल की भी है:
टेलर श्रेणी और रैखिक मॉडल (2)
अंतर उनके उद्गम में है। टेलर अपरूपण में ढलान और अवरोध, एक ही बिंदु पर फलन के अवकलजों से निर्धारित होते हैं। रैखिक प्रतिगमन में वे डेटा से आँके (estimate) जाते हैं ताकि भविष्यवाणी त्रुटि को घटाया जा सके। पर संरचनात्मक रूप से, दोनों एक ही काम कर रहे हैं।
यह समझाती है कि रैखिक मॉडल कुछ स्थितियों में अच्छे क्यों काम करते हैं और अन्य में क्यों विफल।
रैखिक प्रतिगमन मानता है कि आपके इनपुट और आउटपुट के बीच संबंध रैखिक है — या रैखिक माना जा सकता है। टेलर श्रेणी ठीक-ठीक बताती है कि यह मान कब सही है — जब आपके इनपुट किसी नियत बिंदु के पास रहते हैं और जिस फलन का आप अपरूपण कर रहे हैं वह समतल है। यदि आप इनपुट को उस बिंदु से दूर धकेलते हैं, तो रैखिक अपरूपण टूट जाता है — यही कारण है कि प्रबल अवैधैखिक (nonlinear) पैटर्न वाले डेटा पर रैखिक प्रतिगमन अक्सर विफल होता है।
सामान्यीकृत रैखिक मॉडल (GLMs) इस कड़ी को और स्पष्ट करते हैं।
उदाहरण के लिए, लॉजिस्टिक प्रतिगमन किसी परिणाम के लॉग-ऑड्स को एक रैखिक फलन के रूप में मॉडल करता है। रैखिक प्रेडिक्टर और आउटपुट प्रायिकता के बीच कड़ी सिग्मॉइड फलन से होकर जाती है — और जैसा आपने पहले देखा, सिग्मॉइड का शून्य के पास अच्छा-खासा टेलर प्रसार है।
एक बार समझ आ जाए कि प्रथम-क्रम टेलर प्रसार आपको रैखिक मॉडल देता है, अगला कदम और पद जोड़ना है — और आपको बहुपद (polynomial) मॉडल मिल जाता है।
द्वितीय-क्रम टेलर प्रसार यह देता है:
द्वितीय-क्रम टेलर श्रेणी
यह एक द्विघात है — वर्ग पद वाला बहुपद प्रतिगमन मॉडल। हर अतिरिक्त टेलर पद उच्च-घात के बहुपद से मेल खाता है, और इसी तरह बहुपद प्रतिगमन, वक्र संबंधों को पकड़ने के लिए रैखिक प्रतिगमन का विस्तार करता है।
तो टेलर श्रेणी आपको प्रतिगमन में बायस-वैरिएंस संतुलन के बारे में सुसंगत ढंग से सोचने का तरीका देती है। प्रथम-क्रम अपरूपण (रैखिक मॉडल) तेज़ और व्याख्येय होता है पर यदि वास्तविक संबंध अवैधैखिक है, तो उसमें उच्च बायस होगा। उच्च-क्रम अपरूपण, प्रसार बिंदु के पास डेटा को बेहतर फिट करते हैं पर जैसे-जैसे आप पद जोड़ते हैं, अतिफिटिंग का जोखिम बढ़ता है।
यदि आप रैखिक प्रतिगमन और उसके काम करने के समय पर और गहराई से जाना चाहते हैं, तो Essentials of Linear Regression in Python ट्यूटोरियल अच्छा अगला कदम है। R उपयोगकर्ताओं के लिए, Intermediate Regression in R कोर्स बहुपद प्रतिगमन और मॉडल डायग्नॉस्टिक्स को विस्तार से कवर करता है।
टेलर श्रेणियाँ उन गणितीय औज़ारों में से हैं जो एक बार ध्यान आ जाएँ, तो बार-बार सामने आती हैं।
आपने देखा कि वे कंप्यूटरों को eˣ और sin(x) जैसे फलनों का मान बुनियादी अंकगणित से निकालने देती हैं; अभिसरण और कटन त्रुटि किस तरह सटीकता तय करते हैं; और यही विचार ग्रेडिएंट डिसेंट, XGBoost और आधुनिक मशीन लर्निंग के एक्टिवेशन फंक्शन अपरूपणों को कैसे शक्ति देता है।
ये पाँच प्रसिद्ध श्रेणियाँ — घातीय, साइन, कोसाइन, लघुगणक, ज्यामितीय — याद रखने लायक हैं। ये इतनी बार आती हैं कि उन्हें पहचानना वाकई समय बचाता है।
यहाँ से अगला कदम है उस एल्गोरिद्मिक सोच में सहज होना जो इस तरह के गणित के साथ चलती है। हमारा Data Structures and Algorithms in Python कोर्स उस नींव को बनाने की ठोस जगह है। यह आपको समझाएगा कि गणितीय विचार कोड में कैसे बदलते हैं जो काम करता है और स्केल होता है।
DataCamp के साथ सीखें
course
course
course