
Cours
Prétraitement pour le Machine Learning en Python
4 h
66.5K
Vous vous êtes déjà demandé comment un ordinateur calcule réellement une fonction comme sin(x) ou eˣ ?
Les ordinateurs ne peuvent pas évaluer directement la plupart des fonctions mathématiques. Ils savent seulement additionner, soustraire, multiplier et diviser. Donc, lorsque vous appelez math.sin(0.5) en Python, il faut convertir cet appel en une suite d’opérations arithmétiques de base. Cette conversion repose sur l’approximation polynomiale, dont les séries de Taylor constituent le socle mathématique.
Une série de Taylor permet de réécrire quasiment toute fonction régulière comme une somme infinie de termes plus simples, chacun construit à partir des dérivées de la fonction en un point donné. Une fois l’idée comprise, beaucoup de notions en data science et en apprentissage automatique deviennent plus claires : du fonctionnement de la descente de gradient au comportement de certaines fonctions d’activation.
Dans cet article, je vous présente ce que sont les séries de Taylor, leur fonctionnement mathématique, leurs usages en data science et en machine learning, ainsi que leurs liens avec d’autres types de séries.
Les séries de Taylor existent depuis des siècles. Brook Taylor les a introduites en 1715, et James Gregory ainsi que Colin Maclaurin y ont également apporté des contributions majeures.
L’objectif est de représenter des fonctions complexes par des polynômes, bien plus faciles à manipuler.
Une série de Taylor approxime une fonction en l’exprimant comme une somme infinie de termes, chacun dérivé des dérivées de la fonction en un point. Plus vous incluez de termes, plus l’approximation se rapproche de la fonction réelle.
La formule générale est la suivante :
Formule générale des séries de Taylor
Chaque terme de la somme comporte trois éléments :
f⁽ⁿ⁾(a) - la n-ième dérivée de la fonction évaluée au point central a
n! - la factorielle de n, qui évite que les termes ne croissent sans contrôle
(x - a)ⁿ - le terme d’extension, qui mesure l’écart entre x et le point central
Le point central a est l’ancrage de la série. Lorsque a = 0, on obtient un cas particulier appelé série de Maclaurin — nous y reviendrons.
La fonction exponentielle eˣ est un premier exemple idéal. Sa dérivée est elle-même, donc f⁽ⁿ⁾(0) = 1 pour tout n. Centrée en a = 0, la série de Taylor devient :
Exemple concret
Supposons que vous vouliez approximer e⁰·⁵. Il suffit d’injecter x = 0.5 dans les quatre premiers termes — voici un exemple en Python :
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Exemple concret en Python
La valeur réelle de e⁰·⁵ est d’environ 1.6487. Avec seulement quatre termes, vous êtes déjà à moins de 0,2 % de l’exact. Ajoutez des termes, et l’approximation se resserre.
C’est toute la force des séries de Taylor.
Des fonctions comme eˣ, sin(x) et cos(x) sont difficiles à évaluer directement, mais leurs séries de Taylor les ramènent à de l’arithmétique de base — exactement ce qu’un ordinateur sait traiter.
Une série de Taylor n’est utile que si elle converge effectivement vers la fonction que vous cherchez à approximer. Voyons ce que cela signifie et ce qui se passe quand ce n’est pas le cas.
Développer une série de Taylor revient à construire un polynôme terme par terme. Chaque terme ajoute de l’information sur le comportement de la fonction au voisinage du point central a.
Prenons sin(x) centré en a = 0 :
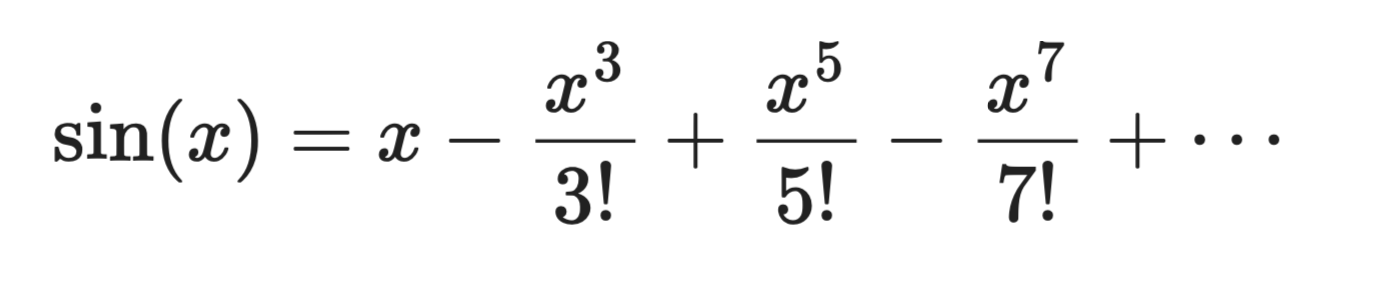
Développement en série de Taylor
Le premier terme, x, fournit une approximation linéaire grossière. Ajoutez le deuxième terme, la courbe se rapproche. Ajoutez-en d’autres, et le polynôme finit par épouser sin(x) près de x = 0.
En clair, le développement remplace une fonction exacte mais coûteuse à calculer par un polynôme exploitable en pratique.
Vous ne calculerez jamais une infinité de termes. En pratique, vous vous arrêtez après quelques-uns et acceptez une petite erreur. Le résultat s’appelle une série de Taylor tronquée, et l’erreur induite est l’erreur de troncature.
Le reste de Lagrange vous donne une borne supérieure sur cette erreur. Pour une série tronquée après n termes :
Reste de Lagrange
Où c est un point entre x et a. Vous ne connaissez pas c exactement, mais vous pouvez borner f⁽ⁿ⁺¹⁾(c) si vous savez à quel point les dérivées de votre fonction peuvent croître.
Voici comment l’interpréter :
Plus x s’éloigne du point central a, plus l’erreur augmente
Plus vous conservez de termes, plus l’erreur diminue
Les fonctions avec des dérivées grandes et croissant rapidement sont plus difficiles à approximer avec précision
Supposons que vous approximez sin(0.1) avec trois termes :
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Approximation en Python
Trois termes vous donnent une précision à dix décimales lorsque x est proche de 0. C’est l’erreur de troncature à l’œuvre — faible, mais non nulle.
Une série de Taylor converge en un point x si les sommes partielles se rapprochent d’une valeur fixe à mesure que vous ajoutez des termes. Cette valeur devrait être f(x) — mais ce n’est pas toujours garanti.
Le rayon de convergence R indique jusqu’où, à partir du point central, la série reste valable. À l’intérieur de ce rayon, la série converge. Au-delà, les termes grossissent au lieu de décroître et l’approximation s’effondre.
Formule de convergence
Les fonctions ont des rayons différents :
eˣ, sin(x) et cos(x) convergent pour tout x, donc R = ∞
ln(1 + x) ne converge que pour -1 < x <= 1, donc R = 1
1/1-x converge pour |x| < 1, donc R = 1
Une fonction peut aussi avoir un rayon de convergence infini sans pour autant coïncider avec sa série de Taylor en certains points. On parle alors de fonctions non analytiques — un cas limite à connaître, même s’il est rare en data science.
En résumé, vérifiez toujours si x se situe dans le rayon de convergence avant de faire confiance à une approximation de Taylor.
Les séries de Taylor apparaissent bien plus souvent qu’on ne le pense — des simulations physiques à la résolution de équations différentielles. Mais leur impact le plus concret au quotidien pour un data scientist concerne l’optimisation et l’approximation de modèles.
Chaque entraînement de modèle de machine learning implique une forme d’optimisation. Et les séries de Taylor sont souvent en coulisses.
La descente de gradient utilise une approximation de Taylor du premier ordre. Quand vous calculez le gradient d’une fonction de perte L(θ) au point courant θ, vous vous demandez en substance : « si je me déplace d’un petit pas dans cette direction, de combien la perte change-t-elle ? » C’est un développement de Taylor du premier ordre autour du point courant :
Séries de Taylor et optimisation
Cela fonctionne, mais ignore la courbure. Si la surface de perte est courbe, une approximation du premier ordre peut dépasser la cible ou avancer de manière inefficace.
La méthode de Newton corrige cela en incluant le terme du second ordre — la matrice hessienne H, qui capture la courbure :
Séries de Taylor et optimisation (2)
En annulant la dérivée de cette expression, on obtient le pas optimal. En contrepartie, calculer la hessienne complète est coûteux pour les grands modèles. Des méthodes comme L-BFGS l’approximent et en retirent l’essentiel des bénéfices pour une fraction du coût.
Certaines fonctions d’activation sont coûteuses à calculer. Les séries de Taylor offrent des alternatives polynomiales moins chères, suffisamment précises dans la plupart des cas.
La fonction sigmoïde σ(x) = 1 / (1 + e⁻ˣ) nécessite de calculer une exponentielle, opération coûteuse. Au voisinage de x = 0, son développement de Taylor est :
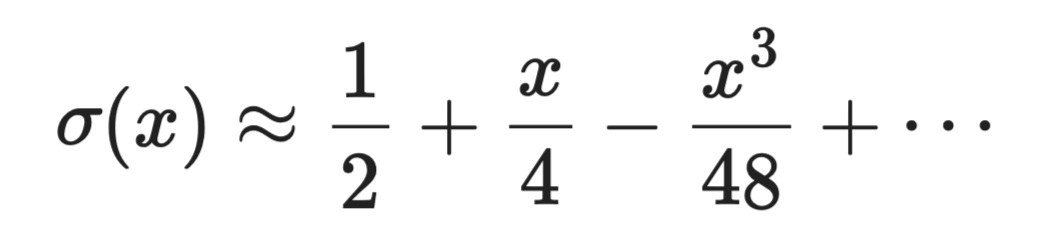
Séries de Taylor et approximation
Dans des environnements contraints (edge, FPGA), ce type d’approximation polynomiale peut remplacer des calculs exacts par quelques opérations de type multiply-add.
GELU, utilisée dans les transformeurs comme BERT et GPT, est souvent implémentée via une approximation basée sur Taylor de la fonction d’erreur erf(x), la forme exacte impliquant une intégrale sans solution fermée.
XGBoost, l’une des bibliothèques de gradient boosting les plus utilisées, exploite un développement de Taylor du second ordre de la perte pour ajuster chaque nouvel arbre.
À chaque itération de boosting, XGBoost approxime la perte ainsi :
Approximation de la perte dans XGBoost
Où g_i est le gradient du premier ordre et h_i le gradient du second ordre (hessien) de la perte par rapport à la prédiction courante. Utiliser les deux termes permet à XGBoost d’ajuster des arbres plus vite et plus précisément que les méthodes du premier ordre — une raison majeure de ses performances sur données tabulaires.
Ce n’est pas parce que les séries de Taylor sont partout en data science qu’elles sont la solution universelle. Plusieurs écueils existent.
L’erreur d’approximation s’accumule : dans les réseaux profonds, vous enchaînez de nombreuses opérations. Une petite erreur d’approximation à une couche se propage et peut nuire à la stabilité de l’entraînement
Le rayon de convergence compte : les approximations de Taylor ne sont fiables qu’au voisinage du point de développement. Si vos entrées s’en éloignent — par exemple en inférence sur des données hors distribution — l’approximation peut s’effondrer
Les hessiennes en grande dimension coûtent cher : les méthodes du second ordre sont puissantes mais passent mal à l’échelle. Un modèle avec n paramètres a une hessienne n × n. Pour des millions de paramètres, stocker et inverser cette matrice est irréaliste sans approximations.
En comprenant ces compromis, vous saurez quand une approche basée sur Taylor vaut le coup et quand une méthode du premier ordre suffit.
Quelques séries de Taylor reviennent partout en mathématiques, en physique et en machine learning. Voici celles à connaître si vous prenez la data science au sérieux.
La fonction exponentielle eˣ est la plus simple à développer, car chaque dérivée de eˣ est eˣ elle-même. Évalués en a = 0, tous les coefficients valent 1 :
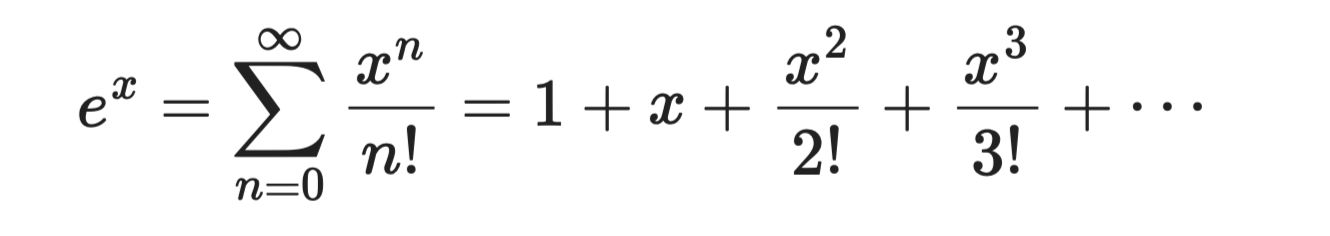
Fonction exponentielle
Cette série converge pour tout x, ce qui la rend fiable et facile à utiliser. Elle sert de base aux fonctions sigmoïde et softmax en classification.
La fonction sinus ne contient que des puissances impaires, car sin(x) est une fonction impaire — sin(-x) = -sin(x) :
Fonction sinus
Comme eˣ, elle converge pour tout x. Les signes alternent car les dérivées de sin(x) cyclent entre cos(x), -sin(x), -cos(x), puis reviennent.
Le cosinus est le pendant pair du sinus — il ne contient que des puissances paires :
Fonction cosinus
En juxtaposant les séries du sinus et du cosinus, on voit leur complémentarité. Cette relation mène à la célèbre identité d’Euler : eⁱˣ = cos(x) + i·sin(x).
Le logarithme népérien ln(1 + x) possède une série de Taylor centrée en x = 0 :
Logarithme népérien
Contrairement aux trois précédentes, cette série ne converge que pour -1 < x <= 1. En dehors, elle diverge. On retrouve cette contrainte dans la perte d’entropie croisée, où les probabilités log doivent rester dans un intervalle valide.
La série géométrique est l’un des résultats les plus anciens et les plus utilisés en mathématiques :
Série géométrique
Elle ne converge que pour |x| < 1. C’est le point de départ de nombreuses autres séries de Taylor, omniprésente en théorie des probabilités, en traitement du signal et partout où l’on somme des valeurs futures actualisées.
Si vous cherchez quelque chose de concret, à imprimer et à afficher près de votre bureau, voici ce qu’il vous faut :

Aide-mémoire des séries de Taylor
Ces cinq séries couvrent la majorité des cas que vous rencontrerez en data science et en machine learning.
Taylor, Fourier et Maclaurin approximent toutes des fonctions, mais pour des problèmes et des contextes différents.
Taylor et Fourier représentent des fonctions comme des sommes infinies, mais selon des approches radicalement différentes.
Une série de Taylor construit la fonction à partir de polynômes — des puissances de (x - a). Elle zoome sur un point unique et capture le comportement local via les dérivées. Le résultat est précis près du point a, mais la précision décroît à mesure qu’on s’en éloigne.
Une série de Fourier utilise des sinus et cosinus comme briques de base :
Séries de Fourier
Plutôt que de capturer le comportement local, les séries de Fourier modélisent un comportement périodique global sur tout un intervalle. Elles sont conçues pour des fonctions qui se répètent — signaux audio, saisonnalités, tout ce qui oscille.
Voici une comparaison côte à côte :
Comparaison Taylor vs Fourier
Le traitement du signal et l’analyse de séries temporelles recourent massivement aux séries de Fourier — analyse spectrale, décomposition fréquentielle, voire certaines architectures de réseaux comme FNet, qui remplace l’attention par des transformées de Fourier.
Si vous travaillez sur des données tabulaires, des images ou l’optimisation, les séries de Taylor sont l’outil le plus pertinent. Pour l’audio, les séries temporelles ou toute structure périodique, privilégiez Fourier.
C’est simple : une série de Maclaurin est une série de Taylor centrée en a = 0.
La formule générale de Taylor est :
Séries de Maclaurin
En posant a = 0, on obtient :
Séries de Maclaurin pour a = 0
Colin Maclaurin a tellement utilisé ce cas spécifique qu’il a reçu un nom distinct, mais mathématiquement, ce n’est rien d’autre qu’une série de Taylor pour un point central particulier.
En pratique, la plupart des séries que vous verrez — eˣ, sin(x), cos(x), ln(1 + x) — sont des séries de Maclaurin, car centrer en zéro simplifie l’algèbre. Si vous devez approximer une fonction près d’un autre point, vous choisissez a ≠ 0 et obtenez une série de Taylor générale.
En conclusion, toute série de Maclaurin est une série de Taylor, mais l’inverse n’est pas vrai.
Les séries de Taylor et les modèles linéaires peuvent sembler éloignés au premier abord, mais le lien vaut le détour — et il commence avec l’approximation de Taylor du premier ordre.
En tronquant une série de Taylor après le premier terme, vous obtenez une approximation linéaire de la fonction au voisinage d’un point a :
Séries de Taylor et modèles linéaires (1)
C’est une droite, avec une pente (f'(a)) et une ordonnée à l’origine (f(a) - f'(a) ⋅ a). Cela vous rappelle un modèle de régression linéaire simple ?
Séries de Taylor et modèles linéaires (2)
La différence réside dans l’origine des paramètres. En approximation de Taylor, la pente et l’ordonnée proviennent des dérivées de la fonction en un point. En régression linéaire, elles sont estimées sur des données pour minimiser l’erreur de prédiction. Structurellement, c’est la même idée.
Il explique pourquoi les modèles linéaires réussissent dans certains cas et échouent dans d’autres.
La régression linéaire suppose que la relation entrée-sortie est — ou peut être traitée comme — linéaire. Les séries de Taylor vous disent exactement quand cette hypothèse tient : quand vos entrées restent proches d’un point fixe et que la fonction est lisse. Si vous vous en éloignez, l’approximation linéaire se dégrade — comme la régression linéaire sur des données fortement non linéaires.
Les modèles linéaires généralisés (GLM) rendent le lien encore plus explicite.
La régression logistique, par exemple, modélise le log-odds d’un événement comme une fonction linéaire. Le lien entre le prédicteur linéaire et la probabilité passe par la sigmoïde — dont nous avons vu qu’elle possède un développement de Taylor bien comporté près de zéro.
Si une approximation de Taylor du premier ordre donne un modèle linéaire, ajouter des termes fournit un modèle polynomial.
Une approximation du second ordre donne :
Série de Taylor du second ordre
C’est un quadratique — une régression polynomiale avec un terme au carré. Chaque terme supplémentaire correspond à un polynôme de degré plus élevé, ce qui permet à la régression polynomiale d’étendre la régression linéaire pour capturer des relations courbes.
Les séries de Taylor offrent ainsi un cadre rigoureux pour penser le compromis biais-variance en régression. Un premier ordre (modèle linéaire) est rapide et interprétable mais fortement biaisé si la relation vraie est non linéaire. Des ordres plus élevés ajustent mieux au voisinage du point de développement mais augmentent le risque de surapprentissage.
Pour approfondir la régression linéaire et ses conditions de succès, le tutoriel Essentials of Linear Regression in Python est une bonne prochaine étape. Pour les utilisateurs de R, le cours Intermediate Regression in R couvre en détail la régression polynomiale et le diagnostic de modèles.
Les séries de Taylor sont de ces outils mathématiques qui, une fois repérés, réapparaissent partout.
Vous avez vu comment elles permettent aux ordinateurs d’évaluer eˣ et sin(x) par de simples opérations arithmétiques, comment la convergence et l’erreur de troncature conditionnent la précision, et comment la même idée alimente la descente de gradient, XGBoost et les approximations de fonctions d’activation en ML moderne.
Les cinq séries phares — exponentielle, sinus, cosinus, logarithme, géométrique — valent la peine d’être mémorisées. Elles reviennent si souvent que les reconnaître d’emblée fait gagner un temps réel.
À partir d’ici, l’étape suivante consiste à se familiariser avec la pensée algorithmique qui accompagne ce type de mathématiques. Notre cours Data Structures and Algorithms in Python est un excellent point de départ pour consolider cette base — et comprendre comment ces idées mathématiques deviennent du code robuste et scalable.
Apprenez avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Laiba Siddiqui
Tutoriel
DataCamp Team
Tutoriel
Stephen Gruppetta
Tutoriel
Aditya Sharma
