course
Preprocessing w uczeniu maszynowym w Pythonie
4 godz.
67.2K
Czy kiedykolwiek zastanawiali się Państwo, jak komputer właściwie oblicza funkcję taką jak sin(x) czy eˣ?
Komputery nie potrafią bezpośrednio obliczać większości funkcji matematycznych. Umią tylko dodawać, odejmować, mnożyć i dzielić. Gdy więc wywołują Państwo w Pythonie math.sin(0.5), coś musi przekształcić to w sekwencję podstawowych działań arytmetycznych. Tym czymś jest aproksymacja wielomianowa, a szeregi Taylora stanowią jej matematyczny fundament.
Szereg Taylora pozwala przepisać niemal każdą gładką funkcję jako nieskończoną sumę prostszych wyrazów, zbudowanych z pochodnych funkcji w jednym punkcie. Kiedy zrozumie się tę ideę, wiele rzeczy w data science i uczeniu maszynowym zaczyna się układać w całość — od działania spadku gradientowego po to, dlaczego niektóre funkcje aktywacji zachowują się tak, a nie inaczej.
W tym artykule wyjaśnię, czym są szeregi Taylora, jak działają matematycznie, gdzie pojawiają się w data science i uczeniu maszynowym oraz jak mają się do innych typów szeregów, na które mogą się Państwo natknąć.
Szeregi Taylora są znane od wieków. Brook Taylor wprowadził je w 1715 roku, choć istotny wkład w tę ideę mieli także James Gregory i Colin Maclaurin.
Celem było znalezienie sposobu reprezentacji złożonych funkcji za pomocą wielomianów, z którymi pracuje się znacznie łatwiej.
Szereg Taylora aproksymuje funkcję, wyrażając ją jako nieskończoną sumę wyrazów, z których każdy pochodzi od pochodnych funkcji w jednym punkcie. Im więcej wyrazów uwzględnimy, tym bliższa rzeczywistej funkcji staje się aproksymacja.
Ogólna formuła wygląda tak:
Ogólna formuła szeregu Taylora
Każdy wyraz tej sumy składa się z trzech elementów:
f⁽ⁿ⁾(a) — n-ta pochodna funkcji obliczona w punkcie centralnym a
n! — silnia n, która zapobiega niekontrolowanemu wzrostowi wyrazów
(x - a)ⁿ — wyraz rozwinięcia, który mierzy, jak daleko x jest od punktu centralnego
Punkt centralny a to miejsce zakotwiczenia szeregu. Gdy a = 0, otrzymujemy szczególny przypadek zwany szeregiem Maclaurina — o tym później.
Funkcja wykładnicza eˣ to idealny pierwszy przykład. Jej pochodna jest równa jej samej, więc f⁽ⁿ⁾(0) = 1 dla każdego n. Dla centrum w a = 0 szereg Taylora przyjmuje postać:
Konkretny przykład
Załóżmy, że chcą Państwo przybliżyć e⁰·⁵. Wystarczy podstawić x = 0.5 do pierwszych czterech wyrazów — oto przykład w Pythonie:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Konkretny przykład w Pythonie
Rzeczywista wartość e⁰·⁵ to około 1.6487. Już przy czterech wyrazach uzyskują Państwo dokładność na poziomie 0,2% względem prawdziwej wartości. Dodanie kolejnych wyrazów jeszcze poprawia przybliżenie.
Na tym polega moc szeregów Taylora.
Funkcje takie jak eˣ, sin(x) i cos(x) są trudne do bezpośredniego obliczenia, ale ich szeregi Taylora sprowadzają je do podstawowej arytmetyki. Z tym komputer radzi sobie doskonale.
Szereg Taylora jest użyteczny tylko wtedy, gdy faktycznie zbiega do aproksymowanej funkcji. Przyjrzyjmy się, co to znaczy i co się dzieje, gdy tak nie jest.
Rozwijając szereg Taylora, budują Państwo wielomian wyraz po wyrazie. Każdy kolejny wyraz dodaje więcej informacji o zachowaniu funkcji w pobliżu punktu centralnego a.
Weźmy sin(x) z centrum w a = 0:
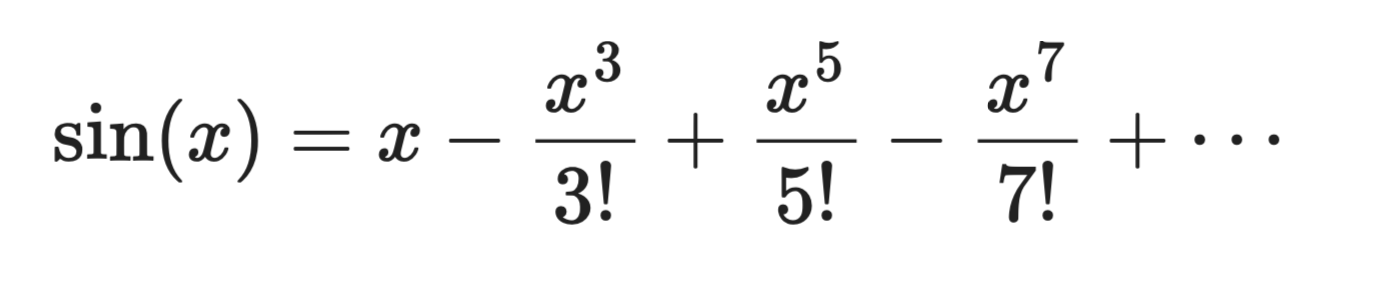
Rozwinięcie szeregu Taylora
Pierwszy wyraz, x, to zgrubne przybliżenie liniowe. Dodanie drugiego wyrazu przybliża krzywą. Dodając kolejne, wielomian zaczyna w pobliżu x = 0 wyglądać niemal identycznie jak sin(x).
Mówiąc prościej, rozwinięcie oznacza zamianę dokładnej, ale trudnej do obliczenia funkcji na wielomian, z którym można realnie pracować.
Nigdy nie obliczają Państwo nieskończonej liczby wyrazów. W praktyce przerywa się po kilku i akceptuje niewielki błąd. Taki wynik nazywa się obciętym szeregiem Taylora, a wprowadzony błąd to błąd obcięcia.
Reszta w sensie Lagrange’a daje ograniczenie tego błędu. Dla szeregu obciętego po n wyrazach:
Reszta Lagrange’a
Gdzie c to pewien punkt między x a a. Dokładna wartość c nie jest znana, ale można ograniczyć f⁽ⁿ⁺¹⁾(c), jeśli wiadomo, jak duże mogą być pochodne danej funkcji.
Można to interpretować następująco
Im dalej x leży od punktu centralnego a, tym większy błąd
Im więcej wyrazów uwzględnimy, tym mniejszy błąd
Funkcje o dużych, szybko rosnących pochodnych trudniej dokładnie aproksymować
Załóżmy, że aproksymują Państwo sin(0.1) trzema wyrazami:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Aproksymacja w Pythonie
Trzy wyrazy dają dokładność do dziesięciu miejsc po przecinku, gdy x jest bliskie 0. To działanie błędu obcięcia — mały, ale niezerowy.
Szereg Taylora jest zbieżny w punkcie x, jeśli sumy częściowe, wraz z dodawaniem kolejnych wyrazów, zbliżają się do stałej wartości. Tą wartością powinno być f(x) — ale nie zawsze jest to gwarantowane.
Promień zbieżności R określa, jak daleko od punktu centralnego szereg pozostaje poprawny. Wewnątrz tego promienia szereg jest zbieżny. Poza nim wyrazy rosną zamiast maleć, a aproksymacja się załamuje.
Wzór na zbieżność
Różne funkcje mają różne promienie zbieżności:
eˣ, sin(x) i cos(x) są zbieżne dla wszystkich wartości x, więc R = ∞
ln(1 + x) zbiega tylko dla -1 < x <= 1, więc R = 1
1/1-x zbiega dla |x| < 1, więc R = 1
Funkcja może mieć też nieskończony promień zbieżności, a mimo to nie być równa swojemu szeregowi Taylora w niektórych punktach. To tzw. funkcje nieanalityczne — przypadki brzegowe warte znajomości, choć rzadko spotykane w data science.
Zatem przed zaufaniem aproksymacji Taylora zawsze warto sprawdzić, czy x mieści się w promieniu zbieżności.
Szeregi Taylora pojawiają się częściej, niż można by się spodziewać — od symulacji fizycznych po rozwiązywanie równań różniczkowych. Jednak ich największy wpływ w codziennej pracy data scientista dotyczy optymalizacji i aproksymacji modeli.
Za każdym razem, gdy trenują Państwo model uczenia maszynowego, wykonywana jest jakaś forma optymalizacji. I często stoi za nią szereg Taylora
Spadek gradientowy wykorzystuje aproksymację Taylora rzędu pierwszego. Gdy obliczają Państwo gradient funkcji straty L(θ) w bieżących parametrach θ, to de facto pada pytanie: „jeśli wykonam mały krok w tym kierunku, o ile zmieni się strata?” To jest rozwinięcie Taylora pierwszego rzędu wokół bieżącego punktu:
Szeregi Taylora w optymalizacji
To działa, ale ignoruje krzywiznę. Jeśli powierzchnia straty jest zakrzywiona, przybliżenie pierwszego rzędu może przeszacowywać krok lub wybierać nieefektywne kierunki.
Metoda Newtona rozwiązuje ten problem, uwzględniając człon drugiego rzędu — macierz Hessego H, która opisuje krzywiznę:
Szeregi Taylora w optymalizacji (2)
Wyzerowanie pochodnej tego wyrażenia daje optymalny krok. Minusem jest to, że pełna macierz Hessego jest kosztowna obliczeniowo w dużych modelach. Metody takie jak L-BFGS ją przybliżają, dając większość korzyści przy ułamku kosztu.
Niektóre funkcje aktywacji są kosztowne obliczeniowo. Szeregi Taylora dostarczają tańszych alternatyw, wystarczająco dokładnych w większości zastosowań.
Funkcja sigmoidalna σ(x) = 1 / (1 + e⁻ˣ) wymaga obliczenia eksponenty, co jest kosztowne. W pobliżu x = 0 jej rozwinięcie Taylora to:
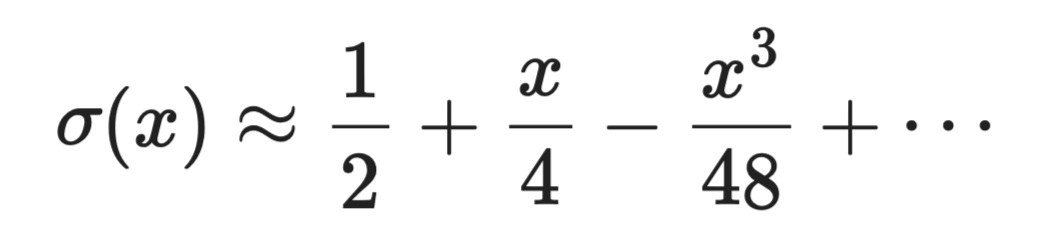
Szeregi Taylora w aproksymacji
W środowiskach z ograniczeniami sprzętowymi, jak urządzenia brzegowe czy FPGA, takie aproksymacje wielomianowe mogą zastąpić dokładne obliczenia garścią operacji mnożenia i dodawania.
Funkcja GELU, używana w modelach transformatorowych, takich jak BERT i GPT, jest często implementowana poprzez aproksymację funkcji błędu erf(x) opartą na szeregu Taylora, ponieważ dokładna postać obejmuje całkę bez rozwiązania w formie zamkniętej.
XGBoost to jedna z najpopularniejszych bibliotek boostingowych, która wykorzystuje rozwinięcie Taylora drugiego rzędu funkcji straty do dopasowania każdego nowego drzewa.
Na każdym kroku boostingu XGBoost aproksymuje stratę jako:
Aproksymacja straty w XGBoost
Gdzie g_i to gradient pierwszego rzędu, a h_i to gradient drugiego rzędu (Hessian) straty względem bieżącej predykcji. Wykorzystanie obu wyrazów pozwala XGBoost szybciej i dokładniej dopasowywać drzewa niż metody pierwszego rzędu, co w dużej mierze tłumaczy jego świetne wyniki na danych tabelarycznych.
To, że szeregi Taylora można stosować w wielu miejscach w data science, nie oznacza, że są uniwersalnym młotkiem na każdy gwóźdź. Kilka rzeczy może pójść nie tak.
Błąd aproksymacji się kumuluje: w głębokich sieciach łączą Państwo wiele operacji. Niewielki błąd aproksymacji Taylora na jednej warstwie narasta w kolejnych, co może wpływać na stabilność treningu
Promień zbieżności ma znaczenie: aproksymacje Taylora są wiarygodne tylko w pobliżu punktu rozwinięcia. Jeśli wejścia oddalą się od miejsca, w którym zbudowano aproksymację — np. podczas wnioskowania na danych spoza rozkładu — przybliżenie może się załamać
Wysokowymiarowe Hessiany są kosztowne: metody drugiego rzędu są potężne, ale słabo się skalują. Model z n parametrami ma macierz Hessego n × n. Dla modeli z milionami parametrów przechowywanie i odwracanie tej macierzy jest niepraktyczne bez aproksymacji.
Znając te kompromisy, będą Państwo wiedzieć, kiedy podejście oparte na Taylorze ma sens, a kiedy wystarczy prostsza metoda pierwszego rzędu.
Kilka szeregów Taylora pojawia się wszędzie w matematyce, fizyce i uczeniu maszynowym. Te warto znać, jeśli poważnie traktują Państwo data science.
Funkcja wykładnicza eˣ jest najprostsza do wyprowadzenia, ponieważ każda jej pochodna to ponownie eˣ. Dla a = 0 każdy współczynnik wynosi 1:
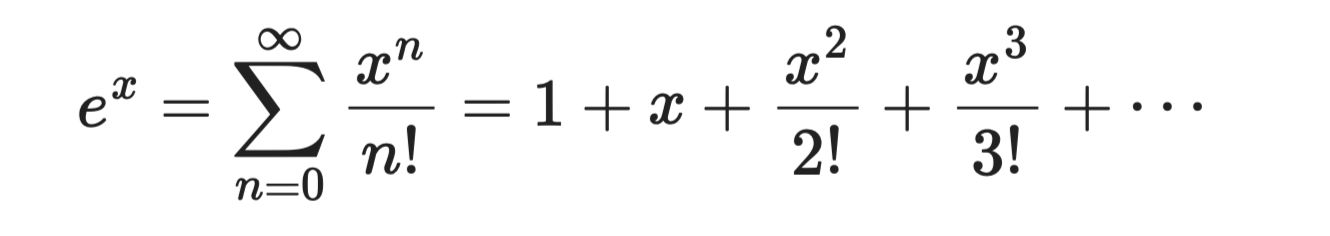
Funkcja wykładnicza
Ten szereg zbiega dla wszystkich wartości x, dzięki czemu jest niezawodny i łatwy w użyciu. To podstawa funkcji sigmoid i softmax używanych w modelach klasyfikacyjnych.
Funkcja sinus zawiera wyłącznie potęgi nieparzyste, co wynika z faktu, że sin(x) jest funkcją nieparzystą — tzn. sin(-x) = -sin(x):
Funkcja sinus
Podobnie jak eˣ, szereg ten zbiega dla każdego x. Naprzemienne znaki wynikają z faktu, że pochodne sin(x) cyklicznie przechodzą przez cos(x), -sin(x), -cos(x) i z powrotem.
Cosinus jest parzystym odpowiednikiem sinusa — zawiera tylko potęgi parzyste:
Funkcja cosinus
Zestawiając szeregi sinusa i cosinusa, widać ich komplementarność. Ta relacja prowadzi do słynnej tożsamości Eulera: eⁱˣ = cos(x) + i·sin(x).
Logarytm naturalny ln(1 + x) ma szereg Taylora z centrum w x = 0:
Funkcja logarytmu naturalnego
W przeciwieństwie do trzech poprzednich, ten szereg zbiega tylko dla -1 < x <= 1. Poza tym zakresem szereg rozbiega się. Ma to znaczenie np. w stracie entropii krzyżowej, gdzie logarytmy prawdopodobieństw muszą pozostawać w prawidłowym zakresie.
Szereg geometryczny to jedno z najstarszych i najczęściej używanych twierdzeń w matematyce:
Szereg geometryczny
Zbiega tylko dla |x| < 1. To punkt wyjścia do wyprowadzania wielu innych szeregów Taylora i pojawia się w teorii prawdopodobieństwa, przetwarzaniu sygnałów oraz wszędzie tam, gdzie sumuje się zdyskontowane wartości przyszłe.
Jeśli szukają Państwo czegoś namacalnego, do wydrukowania i powieszenia na ścianie obok łóżka — oto jest:

Szybka ściąga z szeregów Taylora
Te pięć szeregów obejmuje większość przypadków spotykanych w data science i uczeniu maszynowym.
Szeregi Taylora, Fouriera i Maclaurina wszystkie aproksymują funkcje, ale rozwiązują różne problemy i najlepiej sprawdzają się w odmiennych kontekstach.
Zarówno szeregi Taylora, jak i Fouriera reprezentują funkcje jako nieskończone sumy, lecz robią to w zupełnie inny sposób.
Szereg Taylora buduje funkcję z wielomianów — potęg (x - a). Działa, przybliżając lokalne zachowanie funkcji w jednym punkcie poprzez pochodne. Wynik jest dokładny w pobliżu punktu centralnego a, ale dokładność maleje wraz z oddalaniem się.
Szereg Fouriera używa sinusów i cosinusów jako klocków konstrukcyjnych:
Szereg Fouriera
Zamiast ujmować zachowanie lokalne w punkcie, szeregi Fouriera chwytają globalną periodyczność na całym przedziale. Są projektowane dla funkcji, które się powtarzają — jak sygnały audio, wzorce sezonowe czy wszystko, co oscyluje.
Oto porównanie obu podejść obok siebie:
Porównanie: Taylor vs. Fourier
Szeregi Fouriera pojawiają się w przetwarzaniu sygnałów i analizie szeregów czasowych — analiza widmowa, dekompozycja częstotliwościowa, a nawet niektóre architektury sieci neuronowych, jak FNet, który zastępuje mechanizm uwagi transformatą Fouriera.
Jeśli pracują Państwo z danymi tabelarycznymi, obrazami lub optymalizacją, właściwszym narzędziem będą szeregi Taylora. Jeśli zaś z dźwiękiem, szeregami czasowymi lub strukturą periodyczną — lepsze będą szeregi Fouriera.
To proste. Szereg Maclaurina to po prostu szereg Taylora z centrum w a = 0.
Ogólna postać szeregu Taylora to:
Szereg Maclaurina
Ustawiając a = 0, otrzymujemy:
Szereg Maclaurina dla a = 0
Colin Maclaurin tak często korzystał z tego szczególnego przypadku, że zyskał on własną nazwę, ale matematycznie to po prostu szereg Taylora dla konkretnego punktu centralnego.
W praktyce większość spotykanych szeregów — eˣ, sin(x), cos(x), ln(1 + x) — to szeregi Maclaurina, bo centrum w zerze upraszcza rachunki. Gdy trzeba przybliżać funkcję w pobliżu innego punktu, przesuwa się centrum na a ≠ 0 i otrzymuje ogólny szereg Taylora.
Podsumowując: każdy szereg Maclaurina jest szeregiem Taylora, ale nie każdy szereg Taylora jest szeregiem Maclaurina.
Szeregi Taylora i modele liniowe mogą z początku wydawać się niepowiązane, ale istnieje warte uwagi połączenie — zaczyna się ono od przybliżenia Taylora pierwszego rzędu.
Obcinając szereg Taylora po pierwszym wyrazie, otrzymujemy liniową aproksymację funkcji w pobliżu punktu a:
Szeregi Taylora a modele liniowe (1)
To prosta linia. Ma nachylenie (f'(a)) i wyraz wolny (f(a) - f'(a) ⋅ a). Brzmi znajomo? To ta sama struktura, co w modelu prostej regresji liniowej:
Szeregi Taylora a modele liniowe (2)
Różnica tkwi w pochodzeniu. W przybliżeniu Taylora nachylenie i wyraz wolny wynikają z pochodnych funkcji w jednym punkcie. W regresji liniowej są estymowane z danych, by minimalizować błąd predykcji. Strukturalnie jednak robią to samo.
Wyjaśnia, dlaczego modele liniowe dobrze działają w pewnych sytuacjach, a zawodzą w innych.
Regresja liniowa zakłada, że zależność między wejściem a wyjściem jest — lub może być traktowana jako — liniowa. Szeregi Taylora mówią dokładnie, kiedy to założenie ma sens — gdy wejścia pozostają blisko ustalonego punktu, a aproksymowana funkcja jest gładka. Jeśli odsuną się Państwo daleko od tego punktu, przybliżenie liniowe się załamuje — z tego samego powodu regresja liniowa często zawodzi na danych o silnie nieliniowych zależnościach.
Uogólnione modele liniowe (GLM) czynią to powiązanie jeszcze wyraźniejszym.
Regresja logistyczna, na przykład, modeluje logit (logarytm ilorazu szans) jako funkcję liniową. Związek między liniowym predyktorem a prawdopodobieństwem wyjściowym przechodzi przez funkcję sigmoidalną — a jak pokazano wcześniej, sigmoid ma dobrze zachowujące się rozwinięcie Taylora w pobliżu zera.
Skoro przybliżenie Taylora pierwszego rzędu daje model liniowy, kolejnym krokiem jest dołożenie wyrazów — i otrzymujemy model wielomianowy.
Rozwinięcie Taylora drugiego rzędu daje:
Szereg Taylora drugiego rzędu
To funkcja kwadratowa — regresja wielomianowa z wyrazem do kwadratu. Każdy kolejny wyraz Taylora odpowiada wielomianowi wyższego stopnia, dlatego regresja wielomianowa rozszerza regresję liniową o możliwość uchwycenia zakrzywień.
Szeregi Taylora dają więc uporządkowany sposób myślenia o kompromisie bias–variance w regresji. Aproksymacja pierwszego rzędu (model liniowy) jest szybka i interpretowalna, ale ma duży bias, jeśli prawdziwa zależność jest nieliniowa. Wyższe rzędy lepiej dopasowują dane w pobliżu punktu rozwinięcia, ale wraz z dodawaniem wyrazów rośnie ryzyko nadmiernego dopasowania.
Aby pogłębić wiedzę o regresji liniowej i zrozumieć, kiedy działa, dobrym kolejnym krokiem jest poradnik Essentials of Linear Regression in Python. Dla użytkowników R kurs Intermediate Regression in R szczegółowo omawia regresję wielomianową i diagnostykę modeli.
Szeregi Taylora to jedno z tych narzędzi matematycznych, które — gdy raz się je pozna — zaczynają się pojawiać na każdym kroku.
Widzieli Państwo, jak umożliwiają komputerom obliczanie funkcji takich jak eˣ i sin(x) poprzez podstawową arytmetykę, jak zbieżność i błąd obcięcia decydują o dokładności przybliżenia oraz jak ta sama idea zasila spadek gradientowy, XGBoost i aproksymacje funkcji aktywacji we współczesnym uczeniu maszynowym.
Warto zapamiętać pięć znanych szeregów — wykładniczy, sinus, cosinus, logarytmiczny, geometryczny. Pojawiają się na tyle często, że rozpoznanie ich od razu realnie oszczędza czas.
Kolejnym krokiem jest swobodne myślenie algorytmiczne, które idzie w parze z taką matematyką. Nasz kurs Data Structures and Algorithms in Python to solidna podstawa. Pomoże zrozumieć, jak idee matematyczne przekładają się na kod, który działa i się skaluje.
Ucz się z DataCamp
course
course
course