
Kurs
Vorverarbeitung für Machine Learning in Python
4 Std.
66.5K
Hast du dich schon mal gefragt, wie ein Computer eigentlich eine Funktion wie sin(x) oder eˣ berechnet?
Computer können die meisten mathematischen Funktionen nicht direkt auswerten. Sie können nur addieren, subtrahieren, multiplizieren und dividieren. Wenn du also in Python math.sin(0.5) aufrufst, muss das in eine Abfolge grundlegender Rechenschritte übersetzt werden. Diese Übersetzung ist eine Polynomapproximation – und Taylor-Reihen sind das mathematische Fundament dahinter.
Mit einer Taylor-Reihe lässt sich fast jede glatte Funktion als unendliche Summe einfacherer Terme darstellen, die aus den Ableitungen der Funktion an einem einzigen Punkt aufgebaut sind. Verstehst du dieses Prinzip, ergeben viele Dinge in Data Science und Machine Learning plötzlich Sinn – vom Gradientenabstieg bis hin zum Verhalten bestimmter Aktivierungsfunktionen.
In diesem Artikel zeige ich dir, was Taylor-Reihen sind, wie sie mathematisch funktionieren, wo sie in Data Science und Machine Learning auftauchen und wie sie sich zu anderen Reihen verhalten, die dir begegnen werden.
Taylor-Reihen gibt es seit Jahrhunderten. Brook Taylor führte sie 1715 ein, wobei James Gregory und Colin Maclaurin die Idee maßgeblich weiterentwickelten.
Das Ziel: komplexe Funktionen mithilfe von Polynomen darzustellen – denn mit denen lässt sich viel einfacher arbeiten.
Eine Taylor-Reihe approximiert eine Funktion, indem sie sie als unendliche Summe von Termen ausdrückt, die jeweils aus den Ableitungen der Funktion an einem einzigen Punkt gewonnen werden. Je mehr Terme du berücksichtigst, desto näher kommt die Approximation der tatsächlichen Funktion.
Die allgemeine Formel lautet:
Allgemeine Taylor-Reihen-Formel
Jeder Term dieser Summe besteht aus drei Bausteinen:
f⁽ⁿ⁾(a) – die n-te Ableitung der Funktion, ausgewertet am Entwicklungspunkt a
n! – die Fakultät von n, die verhindert, dass die Terme unkontrolliert wachsen
(x - a)ⁿ – der Entwicklungsterm, der misst, wie weit x vom Zentrum entfernt ist
Der Entwicklungspunkt a ist der Anker der Reihe. Für a = 0 erhältst du den Spezialfall der Maclaurin-Reihe – dazu gleich mehr.
Die Exponentialfunktion eˣ eignet sich perfekt als Einstieg. Ihre Ableitung ist sie selbst, daher gilt f⁽ⁿ⁾(0) = 1 für jedes n. Um a = 0 zentriert, wird die Taylor-Reihe zu:
Konkretes Beispiel
Angenommen, du willst e⁰·⁵ approximieren. Setze einfach x = 0.5 in die ersten vier Terme ein – hier ein Python-Beispiel:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Konkretes Beispiel in Python
Der exakte Wert von e⁰·⁵ liegt bei ungefähr 1.6487. Schon mit vier Termen liegst du innerhalb von 0,2 % des wahren Werts. Mit weiteren Termen wird die Approximation noch genauer.
Das ist die Stärke der Taylor-Reihen.
Funktionen wie eˣ, sin(x) und cos(x) sind direkt schwer zu berechnen, aber ihre Taylor-Reihen reduzieren sie auf einfache Arithmetik. Genau damit kann ein Computer arbeiten.
Eine Taylor-Reihe ist nur nützlich, wenn sie tatsächlich gegen die Funktion konvergiert, die du approximieren willst. Schauen wir uns an, was das bedeutet – und was passiert, wenn nicht.
Beim Entwickeln einer Taylor-Reihe baust du schrittweise ein Polynom auf. Jeder Term fügt Informationen über das Verhalten der Funktion in der Nähe des Entwicklungspunkts a hinzu.
Betrachte sin(x), zentriert bei a = 0:
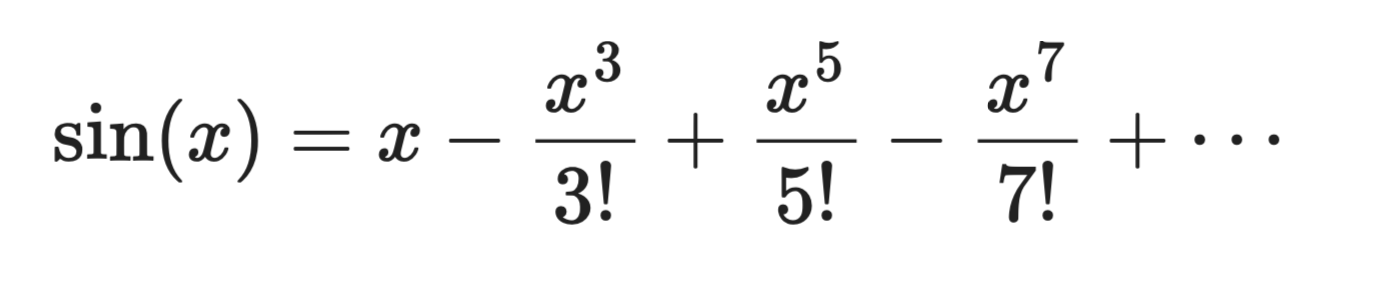
Taylor-Entwicklung
Der erste Term, x, ist eine grobe lineare Näherung. Mit dem zweiten Term kommt die Kurve näher heran. Mit weiteren Termen ähnelt das Polynom in der Nähe von x = 0 immer stärker dem echten sin(x).
Einfach gesagt: Bei der Entwicklung tauschst du eine exakte, aber schwer zu berechnende Funktion gegen ein Polynom, mit dem du praktisch arbeiten kannst.
Unendlich viele Terme wirst du nie berechnen. In der Praxis brichst du nach wenigen Termen ab und akzeptierst einen kleinen Fehler. Das Ergebnis ist eine abgeschnittene Taylor-Reihe, der Fehler heißt Abschneidefehler.
Die Lagrange-Form des Restglieds liefert eine Schranke für diesen Fehler. Für eine nach n Termen abgeschnittene Reihe gilt:
Lagrange-Restglied
Dabei ist c ein Punkt zwischen x und a. Du kennst c nicht exakt, aber du kannst f⁽ⁿ⁺¹⁾(c) abschätzen, wenn du weißt, wie groß die Ableitungen deiner Funktion werden können.
So kannst du das interpretieren:
Je weiter x vom Entwicklungspunkt a entfernt ist, desto größer der Fehler
Je mehr Terme du berücksichtigst, desto kleiner der Fehler
Funktionen mit großen, schnell wachsenden Ableitungen sind schwerer genau zu approximieren
Angenommen, du näherst sin(0.1) mit drei Termen an:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Approximation in Python
Drei Terme liefern dir Genauigkeit auf zehn Dezimalstellen, wenn x nahe 0 liegt. Das ist der Abschneidefehler in Aktion – klein, aber nicht null.
Eine Taylor-Reihe konvergiert an einer Stelle x, wenn die Partialsummen mit zunehmender Termanzahl einem festen Wert immer näher kommen. Dieser Wert sollte f(x) sein – das ist aber nicht immer garantiert.
Der Konvergenzradius R gibt an, wie weit von der Mitte die Reihe gültig bleibt. Innerhalb dieses Radius konvergiert sie. Außerhalb wachsen die Terme statt zu schrumpfen – die Approximation bricht zusammen.
Konvergenzformel
Verschiedene Funktionen haben unterschiedliche Radien:
eˣ, sin(x) und cos(x) konvergieren für alle x, also R = ∞
ln(1 + x) konvergiert nur für -1 < x <= 1, daher R = 1
1/1-x konvergiert für |x| < 1, also R = 1
Eine Funktion kann auch einen unendlichen Konvergenzradius haben und trotzdem an bestimmten Punkten nicht mit ihrer Taylor-Reihe übereinstimmen. Solche nichtanalytischen Funktionen sind Randfälle, die man kennen sollte – auch wenn sie in Data Science selten sind.
Prüfe also immer, ob x innerhalb des Konvergenzradius liegt, bevor du einer Taylor-Approximation vertraust.
Taylor-Reihen tauchen an mehr Stellen auf, als du denkst – von Physiksimulationen bis zum Lösen differentialer Gleichungen. Aber ihre größte Rolle im Alltag von Data Scientists liegt in der Optimierung und Modellapproximation.
Jedes Mal, wenn du ein Machine-Learning-Modell trainierst, führst du eine Form der Optimierung aus. Und oft steckt eine Taylor-Reihe hinter dieser Optimierung.
Gradient Descent nutzt eine Taylor-Näherung erster Ordnung. Wenn du den Gradienten einer Verlustfunktion L(θ) an den aktuellen Parametern θ berechnest, fragst du im Kern: „Wenn ich einen kleinen Schritt in diese Richtung gehe, wie stark ändert sich der Loss?“ Das ist eine Taylor-Entwicklung erster Ordnung um den aktuellen Punkt:
Taylor-Reihen in der Optimierung
Das funktioniert, ignoriert aber die Krümmung. Wenn die Lossfläche gekrümmt ist, kann eine Approximation erster Ordnung überschießen oder ineffiziente Schritte machen.
Newtons Methode behebt das, indem sie den Term zweiter Ordnung einbezieht – die Hessematrix H, die die Krümmung erfasst:
Taylor-Reihen in der Optimierung (2)
Setzt du die Ableitung dieses Ausdrucks gleich null, erhältst du den optimalen Schritt. Der Haken: Die vollständige Hesse zu berechnen, ist bei großen Modellen teuer. Verfahren wie L-BFGS approximieren sie – so erhältst du den Großteil des Nutzens zu einem Bruchteil der Kosten.
Manche Aktivierungsfunktionen sind rechenintensiv. Taylor-Reihen liefern günstigere Alternativen, die für die meisten Zwecke ausreichend genau sind.
Die Sigmoid-Funktion σ(x) = 1 / (1 + e⁻ˣ) erfordert eine Exponentialberechnung, die teuer ist. In der Nähe von x = 0 lautet ihre Taylor-Entwicklung:
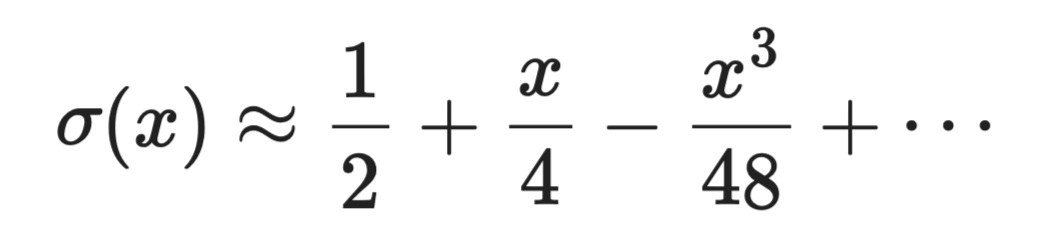
Taylor-Reihen in der Approximation
In Hardware-umgebungen mit knappen Ressourcen wie Edge-Geräten oder FPGAs können solche Polynomapproximationen exakte Berechnungen durch wenige Multiply-Add-Operationen ersetzen.
GELU, eingesetzt in Transformermodellen wie BERT und GPT, wird oft über eine Taylor-basierte Approximation der Fehlerfunktion erf(x) implementiert, da die exakte Form ein Integral ohne geschlossene Lösung beinhaltet.
XGBoost ist eine der am weitesten verbreiteten Gradient-Boosting-Bibliotheken und nutzt eine Taylor-Entwicklung zweiter Ordnung der Verlustfunktion, um jeden neuen Baum zu fitten.
In jedem Boosting-Schritt approximiert XGBoost den Loss als:
XGBoost-Loss-Approximation
Dabei ist g_i der Gradient erster Ordnung und h_i der Gradient zweiter Ordnung (Hesse) des Loss bezüglich der aktuellen Vorhersage. Durch beide Terme kann XGBoost schneller und genauer Bäume fitten als Methoden erster Ordnung – ein wesentlicher Grund für die starke Performance auf tabellarischen Daten.
Nur weil Taylor-Reihen überall in Data Science einsetzbar sind, heißt das nicht, dass sie für jedes Problem das geeignete Allzweckwerkzeug sind. Einiges kann schiefgehen.
Approximationfehler addieren sich: In tiefen Netzen kettelst du viele Operationen aneinander. Ein kleiner Taylor-Fehler in einer Schicht potenziert sich über die Schichten hinweg und kann die Trainingsstabilität beeinflussen.
Der Konvergenzradius zählt: Taylor-Approximationen sind nur in der Nähe des Entwicklungspunkts zuverlässig. Entfernen sich die Eingaben stark von der Stelle, an der die Approximation gebaut wurde – etwa bei Inferenz auf Out-of-Distribution-Daten –, kann sie zusammenbrechen.
Hochdimensionale Hessen sind teuer: Methoden zweiter Ordnung sind mächtig, skalieren aber schlecht. Ein Modell mit n Parametern hat eine n × n-Hesse. Bei Millionen Parametern ist das Speichern und Invertieren ohne Approximationen praktisch unmöglich.
Wenn du diese Trade-offs verstehst, weißt du, wann sich ein Taylor-basierter Ansatz lohnt – und wann eine einfache Methode erster Ordnung ausreicht.
Einige Taylor-Reihen begegnen dir überall in Mathematik, Physik und Machine Learning. Diese solltest du kennen, wenn du es mit Data Science ernst meinst.
Die Exponentialfunktion eˣ ist am einfachsten herzuleiten, da jede Ableitung von eˣ wieder eˣ ist. Für a = 0 ist jeder Koeffizient 1:
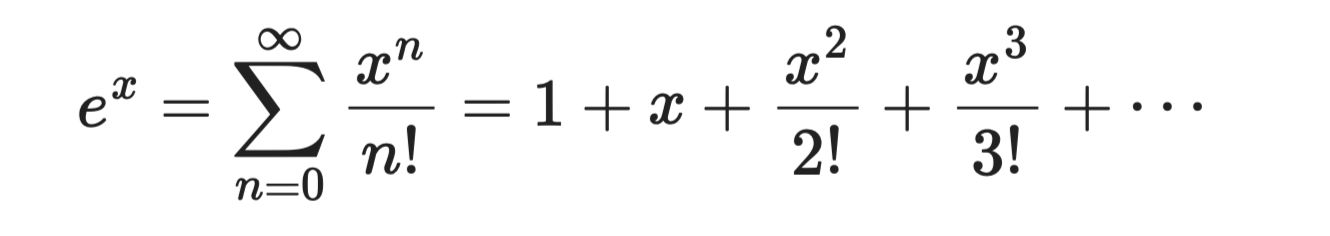
Exponentialfunktion
Diese Reihe konvergiert für alle x – sie ist also zuverlässig und angenehm zu handhaben. Sie bildet die Grundlage für Sigmoid und Softmax in Klassifikationsmodellen.
Die Sinusfunktion enthält nur ungerade Potenzen – weil sin(x) eine ungerade Funktion ist: sin(-x) = -sin(x).
Sinusfunktion
Wie bei eˣ konvergiert sie für alle x. Die wechselnden Vorzeichen ergeben sich daraus, dass die Ableitungen von sin(x) zyklisch durch cos(x), -sin(x), -cos(x) usw. laufen.
Der Kosinus ist das gerade Gegenstück zum Sinus – er enthält nur gerade Potenzen:
Kosinusfunktion
Siehst du dir beide Reihen zusammen an, erkennst du ihre Komplementarität. Daraus folgt auch Eulers berühmte Identität: eⁱˣ = cos(x) + i·sin(x).
Der natürliche Logarithmus ln(1 + x) hat eine Taylor-Reihe um x = 0:
Natürliche-Logarithmus-Funktion
Anders als die vorherigen konvergiert diese nur für -1 < x <= 1. Außerhalb dieses Bereichs divergiert die Reihe. Das spielt z. B. bei der Kreuzentropie eine Rolle, wo Log-Wahrscheinlichkeiten im gültigen Bereich bleiben müssen.
Die geometrische Reihe ist eines der ältesten und meistgenutzten Ergebnisse der Mathematik:
Geometrische Reihe
Sie konvergiert nur für |x| < 1. Sie ist der Ausgangspunkt für viele andere Taylor-Reihen und taucht in der Wahrscheinlichkeitstheorie, Signalverarbeitung und überall dort auf, wo abgezinste zukünftige Werte summiert werden.
Wenn du etwas Handfestes, Ausdruckbares suchst, das an die Wand neben deinem Bett kann – ich hab da was für dich:

Taylor-Reihen Spickzettel
Diese fünf Reihen decken den Großteil der Fälle ab, die dir in Data Science und Machine Learning begegnen.
Taylor-, Fourier- und Maclaurin-Reihen approximieren Funktionen, lösen aber unterschiedliche Probleme und sind in verschiedenen Kontexten am stärksten.
Taylor- und Fourier-Reihen stellen Funktionen beide als unendliche Summen dar – allerdings auf völlig unterschiedliche Weise.
Eine Taylor-Reihe baut die Funktion aus Polynomen auf – Potenzen von (x - a). Sie zoomt auf einen Punkt und beschreibt das lokale Verhalten über Ableitungen. Das Ergebnis ist nahe beim Punkt a sehr genau, entfernt davon nimmt die Genauigkeit ab.
Eine Fourier-Reihe nutzt Sinus- und Kosinusfunktionen als Bausteine:
Fourier-Reihe
Statt lokales Verhalten zu erfassen, bilden Fourier-Reihen globales periodisches Verhalten über ein gesamtes Intervall ab. Sie sind für sich wiederholende Funktionen gedacht – Audio, Saisonalität oder alles, was oszilliert.
So lassen sich beide direkt vergleichen:
Taylor vs. Fourier – Vergleich
Signalverarbeitung und Zeitreihenanalyse sind klassische Anwendungsfelder für Fourier-Reihen – Spektralanalyse, Frequenzzerlegung und sogar neuronale Architekturen wie FNet, das Attention durch Fourier-Transformationen ersetzt.
Arbeitest du mit Tabellendaten, Bildern oder Optimierung, sind Taylor-Reihen meist relevanter. Geht es um Audio, Zeitreihen oder periodische Strukturen, passen Fourier-Reihen besser.
Das ist einfach: Eine Maclaurin-Reihe ist eine um a = 0 zentrierte Taylor-Reihe.
Die allgemeine Taylor-Formel lautet:
Maclaurin-Reihe
Setzt du a = 0, erhältst du:
Maclaurin-Reihe bei a = 0
Colin Maclaurin nutzte diesen Spezialfall so häufig, dass er einen eigenen Namen bekam – mathematisch ist es einfach eine Taylor-Reihe mit besonderem Entwicklungspunkt.
In der Praxis sind die meisten Reihen, die du siehst – eˣ, sin(x), cos(x), ln(1 + x) – Maclaurin-Reihen, weil das Zentrieren in Null die Algebra vereinfacht. Musst du in der Nähe eines anderen Punkts approximieren, wählst du a ≠ 0 und erhältst die allgemeine Taylor-Reihe.
Kurz: Jede Maclaurin-Reihe ist eine Taylor-Reihe, aber nicht jede Taylor-Reihe ist eine Maclaurin-Reihe.
Taylor-Reihen und lineare Modelle wirken zunächst unabhängig, doch es gibt eine nützliche Verbindung – sie beginnt bei der Taylor-Näherung erster Ordnung.
Schneidest du eine Taylor-Reihe nach dem ersten Term ab, erhältst du eine lineare Approximation einer Funktion in der Nähe eines Punkts a:
Taylor-Reihen und lineare Modelle (1)
Das ist eine Gerade. Sie hat eine Steigung (f'(a)) und einen Achsenabschnitt (f(a) - f'(a) ⋅ a). Kommt dir bekannt vor? Das ist dieselbe Struktur wie bei der einfachen linearen Regression:
Taylor-Reihen und lineare Modelle (2)
Der Unterschied liegt in der Herleitung. In der Taylor-Approximation ergeben sich Steigung und Achsenabschnitt aus den Ableitungen an einem Punkt. In der linearen Regression werden sie aus Daten geschätzt, um den Vorhersagefehler zu minimieren. Strukturell leisten beide dasselbe.
Sie erklärt, warum lineare Modelle in manchen Situationen gut funktionieren – und in anderen nicht.
Die lineare Regression nimmt an, dass der Zusammenhang zwischen Input und Output linear ist – oder so behandelt werden kann. Taylor-Reihen sagen dir, wann diese Annahme hält: wenn deine Eingaben nahe bei einem festen Punkt bleiben und die zu approximierende Funktion glatt ist. Entfernen sich die Eingaben stark, bricht die lineare Approximation zusammen – derselbe Grund, warum lineare Regression bei stark nichtlinearen Mustern oft versagt.
Generalisierte lineare Modelle (GLMs) machen diese Verbindung noch deutlicher.
Die logistische Regression modelliert zum Beispiel die Log-Odds eines Outcomes als lineare Funktion. Die Verbindung zwischen linearem Prädiktor und Ausgabewahrscheinlichkeit läuft über die Sigmoid-Funktion – und wie du gesehen hast, besitzt die Sigmoid-Funktion eine gutartige Taylor-Entwicklung nahe Null.
Verstehst du, dass die Taylor-Entwicklung erster Ordnung ein lineares Modell liefert, ist der nächste Schritt, weitere Terme aufzunehmen – und du erhältst ein Polynommodell.
Eine Taylor-Entwicklung zweiter Ordnung ergibt:
Taylor-Reihe zweiter Ordnung
Das ist ein Quadratpolynom – also eine Regressionsform mit Quadratterm. Jeder zusätzliche Taylor-Term entspricht einem Polynom höheren Grades. So erweitert die Polynomregression die lineare Regression, um gekrümmte Zusammenhänge abzubilden.
Taylor-Reihen geben dir damit auch eine saubere Sicht auf den Bias-Variance-Trade-off in der Regression. Eine Approximation erster Ordnung (lineares Modell) ist schnell und interpretierbar, hat aber hohen Bias, wenn der wahre Zusammenhang nichtlinear ist. Höhere Ordnungen passen die Daten in der Nähe des Entwicklungspunkts besser an, riskieren aber mit jedem zusätzlichen Term Überanpassung.
Wenn du tiefer in die lineare Regression einsteigen möchtest, ist das Tutorial Essentials of Linear Regression in Python ein guter nächster Schritt. Für R-Nutzer deckt der Kurs Intermediate Regression in R Polynomregression und Modelldiagnostik im Detail ab.
Taylor-Reihen sind eines dieser Werkzeuge, die dir überall begegnen, sobald du weißt, wonach du schauen musst.
Du hast gesehen, wie sie es Computern ermöglichen, Funktionen wie eˣ und sin(x) mit einfacher Arithmetik zu berechnen, wie Konvergenz und Abschneidefehler die Genauigkeit bestimmen und wie dieselbe Idee den Gradientenabstieg, XGBoost und Aktivierungsfunktions-Approximationen im modernen Machine Learning antreibt.
Die fünf bekannten Reihen – Exponential-, Sinus-, Kosinus-, Logarithmus- und Geometrische Reihe – lohnen sich auswendig zu kennen. Sie kommen so oft vor, dass Wiedererkennen auf Anhieb Zeit spart.
Als Nächstes empfiehlt sich das algorithmische Denken, das diese Mathematik begleitet. Unser Kurs Data Structures and Algorithms in Python ist eine solide Basis. Er hilft dir zu verstehen, wie sich mathematische Ideen in lauffähigen, skalierbaren Code übersetzen lassen.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
Mark Pedigo
Tutorial
Aditya Sharma
Tutorial
Stephen Gruppetta
