Course
Preprocessing for Machine Learning in Python
4 ч
66.6K
Вы когда-нибудь задумывались, как компьютер на самом деле вычисляет функции вроде sin(x) или eˣ?
Компьютеры не могут напрямую вычислять большинство математических функций. Они умеют только складывать, вычитать, умножать и делить. Поэтому, когда вы вызываете в Python math.sin(0.5), что-то должно преобразовать это в последовательность базовых арифметических операций. Этим чем‑то является полиномиальная аппроксимация, а ряды Тейлора — её математическая основа.
Ряд Тейлора позволяет переписать почти любую гладкую функцию как бесконечную сумму более простых слагаемых, каждое из которых построено из производных функции в одной точке. Поняв эту идею, многое в data science и машинном обучении начинает складываться — от того, как работает градиентный спуск, до причин поведения некоторых функций активации.
В этой статье я расскажу, что такое ряды Тейлора, как они устроены математически, где встречаются в data science и ML и как соотносятся с другими типами рядов.
Рядам Тейлора уже несколько веков. Брук Тейлор представил их в 1715 году, хотя существенный вклад внесли также Джеймс Грегори и Колин Маклорен.
Цель состояла в том, чтобы представить сложные функции с помощью многочленов, с которыми гораздо проще работать.
Ряд Тейлора аппроксимирует функцию, представляя её как бесконечную сумму слагаемых, каждое из которых выводится из производных функции в одной точке. Чем больше слагаемых вы берёте, тем ближе аппроксимация к реальной функции.
Общая формула такова:
Общая формула ряда Тейлора
Каждое слагаемое в сумме состоит из трёх компонентов:
f⁽ⁿ⁾(a) — n‑я производная функции, вычисленная в центре разложения a
n! — факториал n, который не даёт слагаемым бесконтрольно расти
(x - a)ⁿ — степень отклонения, показывающая, насколько x удалён от центра
Точка центра a — это якорь ряда. Когда a = 0, получается частный случай — ряд Маклорена; об этом позже.
Экспонента eˣ — идеальный первый пример. Её производная равна самой функции, так что f⁽ⁿ⁾(0) = 1 для любого n. При центре a = 0 ряд Тейлора имеет вид:
Конкретный пример
Допустим, вам нужно аппроксимировать e⁰·⁵. Просто подставьте x = 0.5 в первые четыре слагаемых — вот пример на Python:
x = 0.5
approx = 1 + x + x**2/2 + x**3/6
print(approx)
Пример на Python
Истинное значение e⁰·⁵ примерно равно 1.6487. Всего с четырьмя слагаемыми вы уже в пределах 0,2% от точного ответа. Добавляйте термы — и аппроксимация становится точнее.
В этом и сила рядов Тейлора.
Функции вроде eˣ, sin(x) и cos(x) трудно вычислять напрямую, но их ряды Тейлора сводят задачу к базовой арифметике — именно с этим компьютер и умеет работать.
Ряд Тейлора полезен лишь тогда, когда он действительно сходится к функции, которую вы аппроксимируете. Давайте разберёмся, что это значит и что бывает, когда нет.
Когда вы разлагаете функцию в ряд Тейлора, вы строите многочлен по одному слагаемому за раз. Каждое слагаемое добавляет информацию о поведении функции возле центра a.
Возьмём sin(x) с центром a = 0:
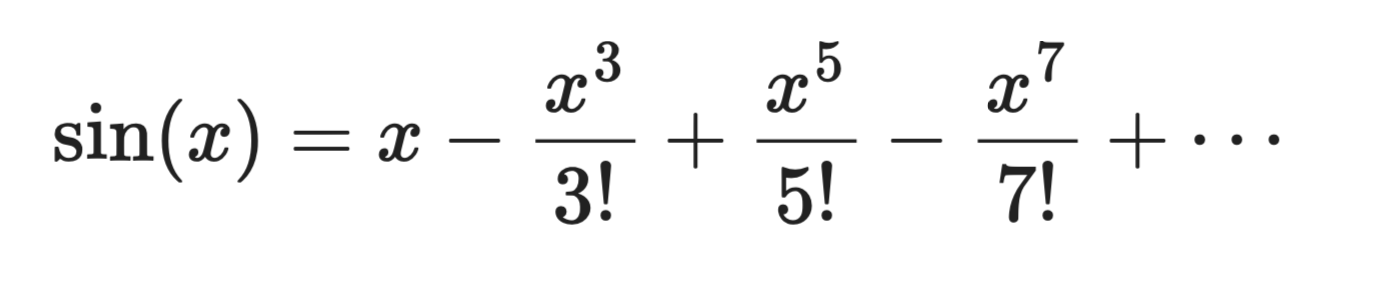
Разложение в ряд Тейлора
Первое слагаемое, x, — грубая линейная аппроксимация. Добавьте второе — кривая приблизится сильнее. Добавляя новые члены, многочлен начинает выглядеть как sin(x) возле x = 0.
Проще говоря, разложение — это обмен точной, но трудновычислимой функции на многочлен, с которым реально работать.
Бесконечно много членов вы не посчитаете. На практике вы останавливаетесь после нескольких и принимаете небольшую погрешность. Результат называется усечённым рядом Тейлора, а возникающая погрешность — ошибкой усечения.
Остаток Лагранжа даёт верхнюю границу этой ошибки. Для ряда, усечённого после n членов:
Остаток Лагранжа
Здесь c — некоторая точка между x и a. Точное c неизвестно, но можно ограничить f⁽ⁿ⁺¹⁾(c), если вы знаете, насколько велики могут быть производные вашей функции.
Вот как это интерпретировать
Чем дальше x от центра a, тем больше ошибка
Чем больше членов вы включаете, тем меньше ошибка
Функции с большими, быстро растущими производными сложнее точно аппроксимировать
Допустим, вы аппроксимируете sin(0.1) тремя слагаемыми:
x = 0.1
approx = x - x**3/6 + x**5/120
print(approx)
print(np.sin(0.1)) 
Аппроксимация на Python
Три члена дают точность до десяти знаков после запятой, когда x близок к 0. Это и есть ошибка усечения в действии — малая, но не нулевая.
Ряд Тейлора сходится в точке x, если частичные суммы всё ближе подходят к фиксированному значению при добавлении новых членов. Этим значением должно быть f(x) — но это не всегда гарантировано.
Радиус сходимости R показывает, насколько далеко от центра ряд остаётся корректным. Внутри радиуса ряд сходится. Вне его слагаемые растут, и аппроксимация рушится.
Формула сходимости
У разных функций разные радиусы:
eˣ, sin(x) и cos(x) сходятся при любых x, значит R = ∞
ln(1 + x) сходится только при -1 < x <= 1, значит R = 1
1/1-x сходится при |x| < 1, значит R = 1
Функция может иметь бесконечный радиус сходимости, но всё же не совпадать со своим рядом Тейлора в отдельных точках. Такие функции называют неаналитическими — редкий, но полезный для общего кругозора случай, хоть в data science они почти не встречаются.
Поэтому перед тем, как доверять аппроксимации Тейлора, всегда проверяйте, попадает ли x в радиус сходимости.
Ряды Тейлора встречаются чаще, чем вы думаете — от физических симуляций до решения дифференциальных уравнений. Но их главный вклад в вашей повседневной работе как дата-сайентиста — в оптимизации и аппроксимации моделей.
Каждый раз, когда вы обучаете модель, вы запускаете некоторую форму оптимизации. И часто за этой оптимизацией стоит ряд Тейлора
Градиентный спуск использует тейлоровскую аппроксимацию первого порядка. Когда вы вычисляете градиент функции потерь L(θ) в текущих параметрах θ, вы по сути спрашиваете: «Если сделать маленький шаг в этом направлении, насколько изменится лосс?» Это и есть разложение первого порядка вокруг текущей точки:
Ряд Тейлора в оптимизации
Это работает, но игнорирует кривизну. Если поверхность лосса изогнута, аппроксимация первого порядка может «перешагивать» минимум или делать неэффективные шаги.
Метод Ньютона исправляет это, включая член второго порядка — матрицу Гессе H, учитывающую кривизну:
Ряд Тейлора в оптимизации (2)
Приравнивание производной этого выражения к нулю даёт оптимальный шаг. Компромисс в том, что вычисление полного Гессиана для больших моделей дорого. Такие методы, как L-BFGS, аппроксимируют его, получая большую часть выгоды за малую долю стоимости.
Некоторые функции активации дороги в вычислении. Ряды Тейлора дают более дешёвые альтернативы, достаточно точные для большинства задач.
Функция сигмоида σ(x) = 1 / (1 + e⁻ˣ) требует вычисления экспоненты, что дорого. В окрестности x = 0 её разложение Тейлора:
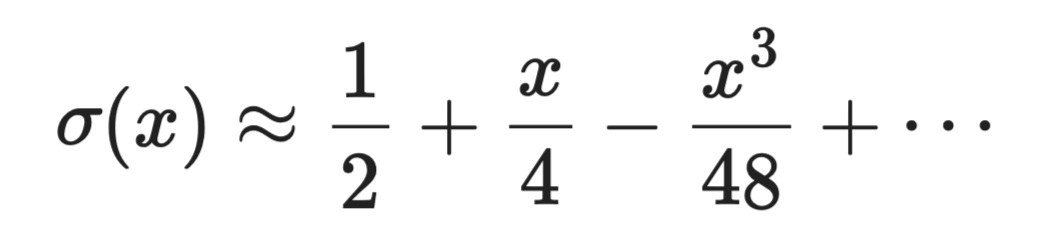
Ряд Тейлора для аппроксимации
Для ограниченных по ресурсам сред — edge‑устройств или FPGA — такие полиномиальные аппроксимации позволяют заменить точные вычисления несколькими операциями умножения‑сложения.
GELU, используемая в трансформерах вроде BERT и GPT, часто реализуется через тейлоровскую аппроксимацию функции ошибки erf(x), поскольку её точная форма включает интеграл без элементарного решения.
XGBoost — одна из самых популярных библиотек градиентного бустинга — использует разложение функции потерь второго порядка Тейлора для подгонки каждого нового дерева.
На каждом шаге бустинга XGBoost аппроксимирует лосс как:
Аппроксимация лосса в XGBoost
Где g_i — градиент первого порядка, а h_i — второй порядок (Гессиан) лосса по текущему предсказанию. Использование обоих членов позволяет XGBoost обучать деревья быстрее и точнее, чем методы первого порядка, что во многом объясняет его эффективность на табличных данных.
То, что ряды Тейлора можно применять повсюду в data science, ещё не делает их «молотком» для любого «гвоздя». Возможны проблемы.
Накопление ошибки аппроксимации: в глубоких сетях вы сцепляете множество операций. Небольшая тейлоровская ошибка на одном слое накапливается по слоям и может влиять на стабильность обучения
Важен радиус сходимости: аппроксимации Тейлора надёжны только рядом с точкой разложения. Если входы уезжают далеко от области, для которой строилась аппроксимация (например, при инференсе на данных вне распределения), она может развалиться
Дорогие Гессианы в высоких размерностях: методы второго порядка мощны, но плохо масштабируются. Модель с n параметрами имеет Гессиан n × n. Для миллионов параметров хранение и обращение такой матрицы непрактично без аппроксимаций.
Понимая эти компромиссы, вы будете знать, когда подход на основе Тейлора оправдан, а когда достаточно простого метода первого порядка.
Пара рядов Тейлора встречаются повсеместно в математике, физике и ML. Эти стоит знать, если вы серьёзно занимаетесь data science.
Функция eˣ — самый простой для вывода ряд Тейлора, так как каждая производная eˣ равна ей самой. При a = 0 все коэффициенты равны 1:
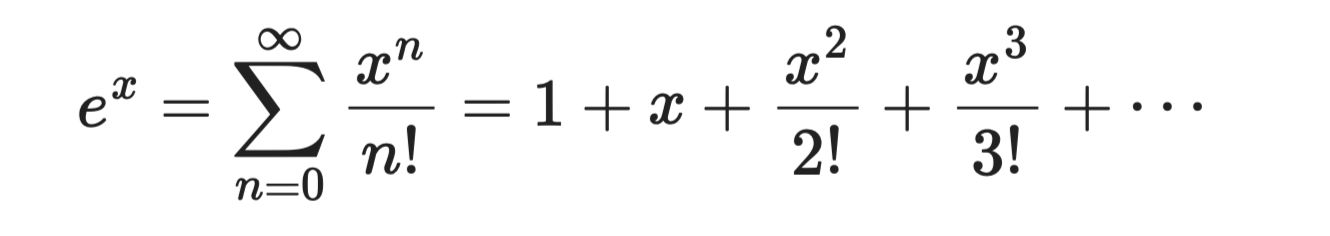
Экспонента
Этот ряд сходится при любых x, что делает его надёжным и удобным. Он лежит в основе сигмоиды и softmax, используемых в задачах классификации.
Ряд для синуса содержит только нечётные степени, что следует из нечётности sin(x) — то есть sin(-x) = -sin(x):
Синус
Как и eˣ, этот ряд сходится при всех x. Чередование знаков связано с тем, что производные sin(x) циклично проходят через cos(x), -sin(x), -cos(x) и обратно.
Косинус — чётная «пара» синуса: содержит только чётные степени.
Косинус
Сопоставив ряды синуса и косинуса, видно их взаимодополняемость. Это приводит к знаменитой формуле Эйлера: eⁱˣ = cos(x) + i·sin(x).
Натуральный логарифм ln(1 + x) имеет разложение в точке x = 0:
Логарифм
В отличие от трёх предыдущих, этот ряд сходится только при -1 < x <= 1. Если выйти за пределы, ряд расходится. Это важно, например, в кросс-энтропии, где логарифмы вероятностей должны оставаться в допустимых границах.
Геометрический ряд — один из древнейших и самых используемых результатов в математике:
Геометрический ряд
Он сходится только при |x| < 1. Это отправная точка для вывода многих других рядов Тейлора; он встречается в теории вероятностей, обработке сигналов и везде, где суммируются дисконтированные будущие значения.
Если вы ищете что‑то наглядное, распечатать и повесить на стену — вот, держите:

Краткая шпаргалка по рядам Тейлора
Эти пять рядов покрывают большинство случаев, с которыми вы столкнётесь в data science и машинном обучении.
Ряды Тейлора, Фурье и Маклорена все аппроксимируют функции, но решают разные задачи и лучше работают в разных контекстах.
И ряды Тейлора, и Фурье представляют функции в виде бесконечных сумм, но делают это принципиально по‑разному.
Ряд Тейлора строит функцию из многочленов — степеней (x - a). Он «приближает» одну точку и описывает локальное поведение через производные. Результат точен возле центра a, но точность падает по мере удаления.
Ряд Фурье использует синусы и косинусы как строительные блоки:
Ряд Фурье
Вместо локального поведения в точке ряды Фурье описывают глобальную периодическую структуру на всём интервале. Они предназначены для периодических функций — звуковые сигналы, сезонность и всё, что колеблется.
Вот как их можно сравнить бок о бок:
Сравнение: Тейлор vs. Фурье
Ряды Фурье применяются в обработке сигналов и анализе временных рядов — спектральный анализ, разложение по частотам и даже некоторые архитектуры нейросетей вроде FNet, где внимание заменяется преобразованиями Фурье.
Если вы работаете с табличными данными, изображениями или оптимизацией, более уместны ряды Тейлора. Если с аудио, временными рядами или чем‑то периодическим — лучше подойдут ряды Фурье.
Это просто: ряд Маклорена — это ряд Тейлора с центром в a = 0.
Общая формула ряда Тейлора:
Ряд Маклорена
Подставьте a = 0 — и получите:
Ряд Маклорена при a = 0
Колин Маклорен столь часто использовал этот частный случай, что он получил отдельное имя, но математически это тот же ряд Тейлора при конкретном центре.
На практике большинство встречающихся рядов — eˣ, sin(x), cos(x), ln(1 + x) — это ряды Маклорена, потому что центр в нуле упрощает алгебру. Когда нужно аппроксимировать функцию возле другой точки, сдвигают центр на a ≠ 0 и получают общий ряд Тейлора.
Итак, любой ряд Маклорена — это ряд Тейлора, но не каждый ряд Тейлора — ряд Маклорена.
На первый взгляд ряды Тейлора и линейные модели не связаны, но есть важная связь, начинающаяся с аппроксимации первого порядка.
Если обрезать ряд Тейлора после первого члена, получится линейная аппроксимация функции в окрестности точки a:
Ряды Тейлора и линейные модели (1)
Это прямая. У неё есть наклон (f'(a)) и пересечение с осью (f(a) - f'(a) ⋅ a). Знакомо? Это та же структура, что и у модели простой линейной регрессии:
Ряды Тейлора и линейные модели (2)
Разница в происхождении. В тейлоровской аппроксимации наклон и сдвиг определяются производными функции в одной точке. В линейной регрессии они оцениваются по данным для минимизации ошибки предсказания. Но структурно они делают одно и то же.
Она объясняет, почему линейные модели хорошо работают в одних случаях и проваливаются в других.
Линейная регрессия предполагает, что связь между входом и выходом линейна — или может рассматриваться как линейная. Ряд Тейлора точно указывает, когда это предположение верно: когда входы остаются близко к фиксированной точке, а аппроксимируемая функция гладкая. Если увести входы далеко, линейная аппроксимация ломается — по той же причине линейная регрессия часто не справляется с ярко нелинейными данными.
Обобщённые линейные модели (GLM) делают эту связь ещё очевиднее.
Например, логистическая регрессия моделирует логиты вероятности как линейную функцию. Связь между линейным предиктором и выходной вероятностью проходит через сигмоиду — а у сигмоиды, как мы видели, хорошо ведущий себя ряд Тейлора возле нуля.
Понимая, что разложение первого порядка даёт линейную модель, следующий шаг — добавить больше членов и получить полиномиальную модель.
Разложение второго порядка даёт:
Ряд Тейлора второго порядка
Это квадратичная модель — полиномиальная регрессия с квадратом. Каждый дополнительный член ряда соответствует полиному более высокой степени — так полиномиальная регрессия расширяет линейную, чтобы захватывать кривизну.
Следовательно, ряд Тейлора даёт принципиальный взгляд на компромисс смещения и разброса в регрессии. Аппроксимация первого порядка (линейная модель) быстра и интерпретируема, но имеет высокое смещение, если истинная связь нелинейна. Высшие порядки лучше подгоняют данные возле точки разложения, но при добавлении членов растёт риск переобучения.
Если хотите углубиться в линейную регрессию и условия её применимости, Essentials of Linear Regression in Python — хороший следующий шаг. Для пользователей R курс Intermediate Regression in R подробно рассматривает полиномиальную регрессию и диагностику моделей.
Ряды Тейлора — из тех математических инструментов, которые попадаются повсюду, как только вы начинаете их замечать.
Вы увидели, как они позволяют компьютерам вычислять функции вроде eˣ и sin(x) с помощью базовой арифметики; как сходимость и ошибка усечения определяют точность аппроксимации; и как та же идея лежит в основе градиентного спуска, XGBoost и аппроксимаций функций активации в современном ML.
Пять известных рядов — экспонента, синус, косинус, логарифм, геометрический — стоит запомнить. Они встречаются достаточно часто, чтобы распознавание их «с налёта» реально экономило время.
Дальше логичный шаг — освоить алгоритмическое мышление, идущее рука об руку с такой математикой. Наш курс Data Structures and Algorithms in Python поможет заложить фундамент: понять, как математические идеи превращаются в код, который работает и масштабируется.
Learn with DataCamp
Course
Course
Course