
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Amazon EC2 (Elastic Compute Cloud) ist ein wichtiger Baustein von AWS. Damit können wir virtuelle Server in der Cloud aufstellen, die sich an unsere Bedürfnisse anpassen lassen. Aber nicht alle EC2-Instanzen sind gleich, und die Wahl des richtigen Typs kann einen großen Unterschied für unsere Leistung und Kosten machen.
In diesem Leitfaden erkläre ich dir die verschiedenen EC2-Instanztypen, ihre Einsatzmöglichkeiten und wie du die für dich am besten geeignete Instanz auswählst.
Wenn du eine Instanzin AWSstartest, musst dueinen Instanztyp auswählen. Jeder Typ ist ein anderes Paket an Rechenleistung, das CPU, Arbeitsspeicher, Speicher und Netzwerkkapazität umfasst. Diese Typen helfen dabei, den Bedarf deiner Anwendung mit der richtigen Menge an Ressourcen abzustimmen, damit du nicht mehr bezahlst, als du verbrauchst.
Deshalb ist die Wahl des richtigen Instanztyps die Grundlage für den Aufbau einer effizienten, kostengünstigen Infrastruktur. Das ist eine der besten Möglichkeiten, um sicherzustellen, dass deine Cloud-Einrichtung reibungslos funktioniert und mit deiner Arbeitslast mitwächst.
AWS sortiert seine Instance-Typen in Familien. Jede Familiengruppe hat ähnliche Leistungsprofile, so dass es einfacher ist, die richtige Gruppe für deine Arbeit zu finden.
Zum Beispiel:
Diese Struktur hilft uns, uns schnell auf die Optionen zu konzentrieren, die für unseren speziellen Anwendungsfall geeignet sind.
Die AWS EC2-Instanztypenfolgen Namenskonventionen, diedir zeigen, was jede Instanz kann oder wofür sie optimiert ist. Mal sehen, wie du diese Namen entschlüsseln kannst, um den richtigen zu wählen.
Die Instanztypen werden nach ihrer Instanzfamilie und Instanzgröße benannt. Der erste Teil des Instanznamens beschreibt die Instanzfamilie und der zweite Teil gibt die Instanzgröße an. Beide werden durch einen Punkt getrennt ..
Nimm einen Instanznamen wie m5.large. Sie besteht aus drei wichtigen Teilen:
m ) verrät dir den allgemeinen Zweck der Instanz. In diesem Fall steht m für "general-purpose".5 ) gibt die Version an. Höhere Zahlen bedeuten in der Regel neuere Hardware und bessere Leistung.large) bezieht sich auf die Größe von Ressourcen wie CPU und Speicher.m5.large bedeutet, dass du eine universell einsetzbare Instanz der fünften Generation mit einer moderaten Menge an Ressourcen bekommst.
Das Bild unten erklärt das Format:
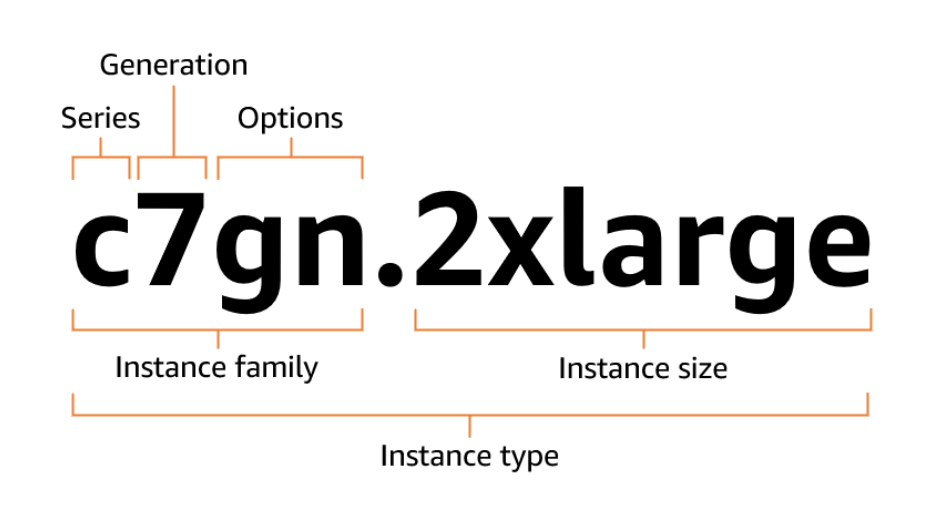
EC2-Instanztyp-Nennungskonvention. Source: AWS-Dokumente
Schauen wir uns ein paar weitere Beispiele an und entschlüsseln sie:
t4g.micro ist eine burstable Instanz, die Graviton (ARM-basierte) Prozessoren verwendet und für leichte, gelegentliche Arbeitslasten geeignet ist.r6g.xlarge ist eine speicheroptimierte Instanz der 6. Generation, die ebenfalls auf Graviton basiert und ideal für speicherintensive Anwendungen ist, wie z. B. In-Memory-Datenbanken.c7gn.2xlarge ist eine rechenoptimierte Instanz der 7. Generation mit verbesserter Netzwerk- und EBS-Unterstützung, angetrieben von Graviton-Prozessoren.Hier sind einige beliebte Serien und die dazugehörigen Optionen, zusammen mit Notationen.
|
Serie |
Optionen |
|
|
Die vollständige Liste der Serien und Optionen findest du in der AWS-Dokumentation.
Schauen wir uns nun die verschiedenen Instanztypen genauer an.
General-Purpose-Instanzen bieten eine ausgewogene Mischung aus Rechen-, Speicher- und Netzwerkleistung. Sie sind eine gute Wahl, wenn deine Arbeitslast nicht stark in eine Richtung geht, was ideal für Webserver, Entwicklungsumgebungen und Backend-Systeme ist.
AWS bietet zwei Hauptserien in dieser Kategorie an: die T-Serie und die M-Serie. Schauen wir uns diese genauer an:
Die Instanzen der T-Serie sind für Burstable Performance ausgelegt. Sie bieten eine Grundausstattung an CPU-Leistung, können aber bei Bedarf vorübergehend hochgefahren werden. Die Burst-Fähigkeit basiert auf einem Credit-System, d.h. wenn deine Instanz weniger als ihre Basis-CPU nutzt, erhält sie Credits. Wenn die Nachfrage ansteigt, gibt er diese Guthaben aus, um die Leistung zu steigern.
Wenn du den "unbegrenzten" Modus aktivierst, kann deine Instanz weiterhin über ihr Guthaben hinausgehen, aber du musst für die zusätzliche Nutzung bezahlen.
Diese Instanzen sind ideal für variable oder niedrige bis mittlere CPU-Auslastungen, wie z. B.:
Angenommen, du betreibst eine kleine Web-App. Die meiste Zeit läuft es reibungslos mit minimaler CPU-Auslastung. Wenn du eine Kampagne startest und der Traffic in die Höhe schießt, werden die gespeicherten Credits verwendet, um die zusätzliche Last zu bewältigen. Nach dem Rausch kehrt er zu seinem Ausgangswert zurück und fängt wieder an, Credits zu sammeln.
Zu den beliebten Typen gehören t4g, t3 und t2, erhältlich in Größen wie t4g.nano.
Die Instanzen der M-Serie bieten ein ausgewogenes Verhältnis zwischen CPU und Speicher, mit etwa 4 GB RAM pro vCPU. Das macht sie vielseitig einsetzbar für allgemeine Arbeitslasten, die keine speziellen Rechen- oder Speicherkonfigurationen benötigen.
Wir können sie verwenden für:
Einige Beispiele dafür sind m6i, m8g und mac, die jeweils in verschiedenen Größen erhältlich sind, wie z.B. m8g.medium.
Wenn deine Workloads viel Verarbeitung, aber wenig Speicher benötigen, sind rechenoptimierte Instanzen eine gute Wahl. Sie liefern Hochgeschwindigkeitsleistung für CPU-intensive Aufgaben, ideal für Analysen, Mediencodierung oder Spieleinrichtungen.
AWS bietet diese Leistung mit der C-Serie an. Schauen wir uns diese im Detail an:
Die Instanzen der C-Serie sind für hohe Rechenleistung bei geringem Speicher-Overhead ausgelegt. Das bedeutet, dass du mehr CPU-Leistung pro Gigabyte Arbeitsspeicher bekommst, was perfekt für Anwendungen ist, bei denen Geschwindigkeit wichtiger ist als Speicher oder Arbeitsspeicher.
Für maximalen Durchsatz und Effizienz verwenden diese Instanzen die neuesten Prozessoren, darunter Intel-, AMD- und AWS Graviton-Chips.
Wir können sie verwenden für:
Einige Beispiele, die dir begegnen könnten, sind c6g, c7i, c5n und c4. Es gibt sie in verschiedenen Größen, so dass du sie je nach deinem Bedarf vergrößern oder verkleinern kannst.
Das ist der Unterschied zwischen rechenoptimierten Instanzen:
Nachhaltigkeit: Viele Instanzen der C-Serie verwenden AWS Graviton-Prozessoren, die energieeffizienter sind und dazu beitragen, deinen ökologischen Fußabdruck zu verringern.
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
