
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
O Amazon EC2 (Elastic Compute Cloud) é um componente essencial do AWS. Isso nos permite ativar servidores virtuais na nuvem que podem ser dimensionados para atender às nossas necessidades. No entanto, nem todas as instâncias do EC2 são iguais, e a escolha do tipo certo pode fazer uma grande diferença no desempenho e nos custos.
Neste guia, explicarei os diferentes tipos de instância do EC2, seus usos e como escolher a que funciona melhor para você.
Quando você iniciar uma instânciano AWS, vocêprecisará escolher um tipo de instância. Cada tipo é um pacote diferente de potência de computação, que inclui CPU, memória, armazenamento e capacidade de rede. Esses tipos ajudam a combinar as necessidades do seu aplicativo com a quantidade certa de recursos, para que você não pague por mais do que usa.
É por isso que a escolha do tipo certo de instância é a base da criação de uma infraestrutura eficiente e econômica. Essa é uma das melhores maneiras de garantir que a configuração da nuvem funcione sem problemas e seja dimensionada de acordo com a carga de trabalho que você tem.
O AWS classifica seus tipos de instância em famílias. Cada grupo de família tem perfis de desempenho semelhantes, portanto, é mais fácil encontrar o grupo certo para o seu trabalho.
Por exemplo:
Essa estrutura nos ajuda a identificar rapidamente as opções que se encaixam em nosso caso de uso específico.
Os tipos de instância do AWS EC2seguem convenções de nomenclatura que mostram a você o que cada instância pode fazer ou para o que está otimizada. Vamos ver como você pode decodificar esses nomes para escolher o certo com mais confiança.
Os tipos de instância são nomeados com base em sua família de instância e tamanho da instância. A primeira parte do nome da instância descreve a família da instância e a segunda parte informa o tamanho da instância. Ambos são separados por um ponto final ..
Considere um nome de instância como m5.large. Ele é composto de três partes principais:
m ) informa a você o objetivo geral da instância. Nesse caso, m significa finalidade geral.5 ) indica a versão. Números mais altos geralmente significam hardware mais novo e melhor desempenho.large) refere-se à escala de recursos como CPU e memória.m5.large significa que você está recebendo uma instância de uso geral, da quinta geração, com uma quantidade moderada de recursos.
A imagem abaixo explica visualmente o formato:
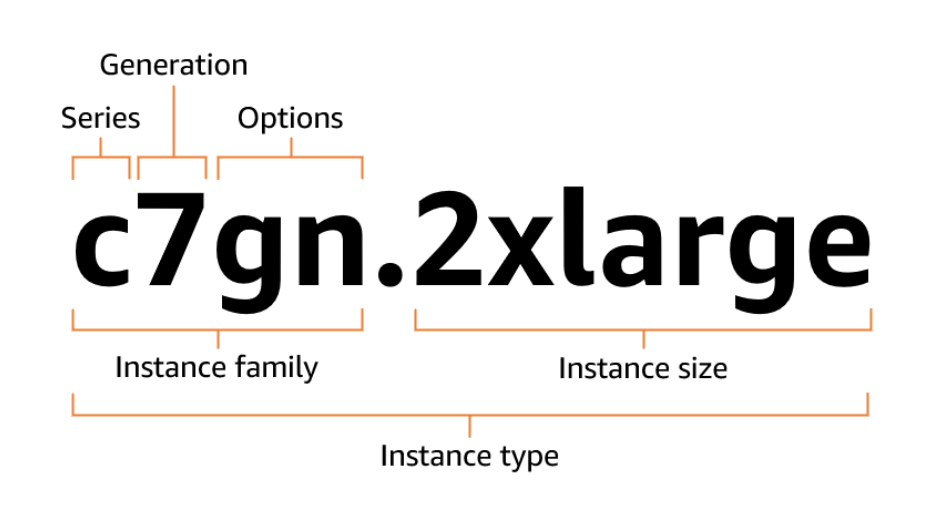
Convenção de nomenclatura do tipo de instância do EC2. Portanto,urce: Documentos da AWS
Vamos dar uma olhada em mais alguns exemplos e decodificá-los:
t4g.micro é uma instância expansível que usa processadores Graviton (baseados em ARM), adequados para cargas de trabalho leves e ocasionais.r6g.xlarge é uma instância otimizada para memória da 6ª geração, também baseada em Graviton, ideal para aplicativos com uso intensivo de memória, como bancos de dados na memória.c7gn.2xlarge é uma instância otimizada para computação, de 7ª geração, com rede aprimorada e suporte a EBS, alimentada por processadores Graviton.Aqui estão algumas séries populares e suas opções correspondentes, juntamente com as notações.
|
Série |
Opções |
|
|
Para obter a lista completa de séries e opções, consulte a documentação da AWS .
Agora, vamos verificar os diferentes tipos de instância com mais detalhes.
As instâncias de uso geral oferecem uma combinação equilibrada de computação, memória e potência de rede. Eles são uma ótima opção quando sua carga de trabalho não se inclina muito em uma direção, o que é ideal para servidores da Web, ambientes de desenvolvimento e sistemas de back-end.
A AWS oferece duas séries principais nessa categoria: a série T e a série M. Vamos dar uma olhada mais de perto:
As instâncias da série T são criadas para um desempenho expansível. Eles fornecem um nível básico de potência da CPU, mas podem aumentar temporariamente quando necessário. Esse recurso de burst é executado em um sistema de crédito, o que significa que quando sua instância usa menos do que a CPU de linha de base, ela ganha créditos. Quando a demanda aumenta, ele gasta esses créditos para aumentar o desempenho.
Se você ativar o modo "ilimitado", sua instância poderá continuar a estourar além do seu saldo de crédito, mas você será cobrado pelo uso extra.
Essas instâncias são ideais para cargas de trabalho de CPU variáveis ou de baixa a moderada, como:
Suponha que você execute um pequeno aplicativo da Web. Na maioria das vezes, ele é executado sem problemas com o mínimo de uso da CPU. Quando você lança uma campanha e o tráfego aumenta, ele usa créditos salvos para gerenciar a carga extra. Após a corrida, ele retorna à sua linha de base e começa a ganhar créditos novamente.
Seus tipos populares incluem t4g, t3 e t2, disponíveis em tamanhos como t4g.nano.
As instâncias da série M oferecem uma relação equilibrada entre CPU e memória, com aproximadamente 4 GB de RAM por vCPU. Isso os torna versáteis para cargas de trabalho de uso geral que não precisam de configurações especializadas de computação ou memória.
Podemos usá-los para:
Alguns de seus exemplos são m6i, m8g e mac, cada um disponível em vários tamanhos, como m8g.medium.
Quando suas cargas de trabalho são pesadas em termos de processamento, mas leves em termos de necessidades de memória, as instâncias otimizadas para computação são uma ótima opção. Eles oferecem desempenho de alta velocidade para tarefas que exigem muita CPU, ideais para análise, codificação de mídia ou infraestrutura de jogos.
A AWS oferece esse poder por meio da série C. Vamos explorá-los em detalhes:
As instâncias da série C são projetadas para alto desempenho de computação com menos sobrecarga de memória. Isso significa que você obtém mais potência da CPU por gigabyte de RAM, o que é perfeito para aplicativos em que a velocidade é mais importante do que o armazenamento ou a memória.
Para obter o máximo de rendimento e eficiência, essas instâncias usam os processadores mais recentes, incluindo chips Intel, AMD e AWS Graviton.
Podemos usá-los para:
Alguns exemplos que você pode encontrar são c6g, c7i, c5n, e c4. Cada um deles vem em uma variedade de tamanhos, de modo que você pode aumentar ou diminuir a escala de acordo com suas necessidades.
Aqui está o que diferencia as instâncias otimizadas para computação:
Sustentabilidade: Muitas instâncias da série C usam processadores AWS Graviton, que são mais eficientes em termos de energia e ajudam a reduzir sua pegada de carbono.
Saiba mais sobre a AWS com estes cursos!
Programa
Curso
Curso
blog
Srujana Maddula
13 min
blog
Natassha Selvaraj
15 min
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Bex Tuychiev