
Kurs
Vorverarbeitung für Machine Learning in Python
4 Std.
66.5K
Wenn du ein Ingenieur für maschinelles Lernen bist, hast du wahrscheinlich schon einmal Docker in einem deiner Projekte eingesetzt - sei es für die Bereitstellung des Inferenz-Endpunkts eines Modells oder für die Automatisierung der Pipeline für maschinelles Lernen für Training, Auswertung und Bereitstellung. Docker vereinfacht diese Prozesse und sorgt für Konsistenz und Skalierbarkeit in Produktionsumgebungen.
Aber hier ist die Frage: Kennst du alle Docker-Images, die auf Docker Hub und GitHub verfügbar sind? Mit diesen vorgefertigten Bildern kannst du Zeit sparen, da du keine Bilder mehr lokal erstellen musst. Stattdessen kannst du sie direkt in deinen Dockerfiles oder Docker Compose Setups verwenden und so die Entwicklung und Bereitstellung beschleunigen.
In diesem Blog stellen wir dir die 12 besten Docker-Container-Images vor, die für maschinelle Lernprozesse entwickelt wurden. Dazu gehören Tools für Entwicklungsumgebungen, Deep-Learning-Frameworks, Lifecycle-Management für maschinelles Lernen, Workflow-Orchestrierung und große Sprachmodelle.
Wenn du Docker noch nicht kennst, solltest du den Kurs Einführung in Docker besuchen, um die Grundlagen zu verstehen.
Wenn du schon einmal den Satz "Das funktioniert auf meinem Rechner" gehört hast, dann weißt du, wie schwer es ist, eine konsistente Entwicklerumgebung über mehrere Plattformen und Stufen hinweg zu erhalten. Hier kommen Docker-Container ins Spiel, denn sie kapseln Code, Abhängigkeiten und Konfigurationen in einem portablen Image und sorgen so für Konsistenz in verschiedenen Umgebungen. Die Modelle und die Endpunkt-API verhalten sich bei der Entwicklung, beim Testen und beim Produktionseinsatz identisch, unabhängig von den Variationen der zugrunde liegenden Infrastruktur.
Durch die Isolierung von Abhängigkeiten - wie z. B. bestimmte Versionen von Python, PyTorch oder CUDA - stellt Docker die Reproduzierbarkeit von Experimenten sicher und reduziert Konflikte zwischen Bibliotheken.
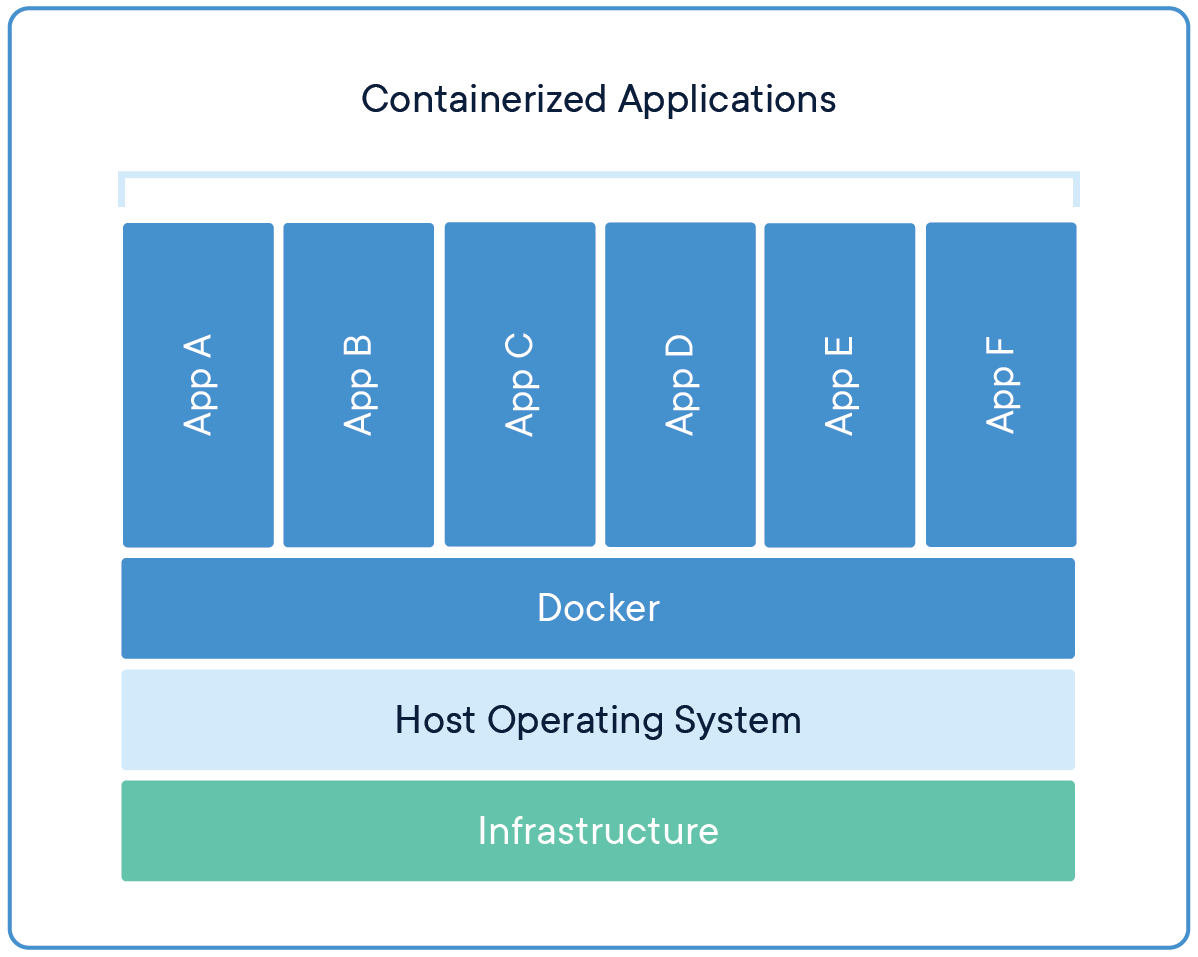
Quelle: Docker
Du kannst das Docker-Image mit deinem Team teilen, und sie können einfach das Image ziehen, um mehrere Instanzen zu erstellen. Dieser Prozess rationalisiert auch die Bereitstellung, indem Modelle in Container mit APIs verpackt werden, was eine nahtlose Integration mit Orchestrierungstools wie Kubernetes für einen skalierbaren Produktionsbetrieb ermöglicht.
Kurz gesagt, als Ingenieur für maschinelles Lernen musst du wissen, wie man mit Docker-Images umgeht und Docker-Container in der Cloud einsetzt.
Verstehe die Kernkonzepte der Containerisierung, indem du dich für den Kurzkurs Containerisierung und Virtualisierungskonzepte anmeldest.
Um einen nahtlosen Workflow für die Entwicklung von maschinellem Lernen einzurichten, brauchst du eine zuverlässige Umgebung mit wichtigen Tools und Bibliotheken. Diese Docker-Container-Images bieten vorkonfigurierte Setups für Data Science, Coding und Experimente.
Python ist das Rückgrat der meisten Machine-Learning-Projekte, denn fast alle wichtigen Frameworks und Anwendungen wie TensorFlow, PyTorch und scikit-learn basieren auf Python. Seine Beliebtheit erstreckt sich auch auf die Bereitstellung, wo Python häufig in Docker-Images verwendet wird, um konsistente Umgebungen für die Modellinferenz zu schaffen. Zum Beispiel:
FROM python:3.8
RUN pip install --no-cache-dir numpy pandasDie Einfachheit von Python, sein umfangreiches Bibliotheks-Ökosystem und seine Kompatibilität mit Tools wie Docker machen es zur ersten Wahl für die Entwicklung und den Einsatz von Machine Learning.
Die Jupyter Docker Stacks bieten eine umfassende Umgebung für Data Science und maschinelles Lernen, einschließlich Jupyter Notebook und einer Reihe beliebter Data Science Bibliotheken. Du kannst das Image ganz einfach von Docker Hub abrufen und lokal verwenden. Außerdem kannst du diese Instanz in der Cloud bereitstellen und sie mit deinem Team teilen.
Um das Jupyter Data Science Notebook zu starten, benutze den folgenden Befehl:
docker run -it --rm -p 8888:8888 jupyter/datascience-notebookEs kann auch mit einem Dockerfile verwendet werden, sodass du keine Python-Pakete mit pip installieren musst. Du musst nur die Anwendung starten oder ein Python-Skript ausführen. Hier ist ein Beispiel für ein Dockerfile:
FROM jupyter/datascience-notebook:latestDieses Bild enthält beliebte Bibliotheken wie NumPy, pandas, matplotlib und scikit-learn sowie das Jupyter Notebook für interaktives Rechnen. Es ist ideal für die Datenexploration, die Visualisierung und Experimente mit maschinellem Lernen und hat sich in der Data-Science-Community zu einer festen Größe entwickelt.
Weitere Informationen findest du auf dem Blog Docker für Data Science: Eine Einführung, wo du etwas über Docker-Befehle, die Dockerisierung von Machine Learning-Anwendungen und branchenweite Best Practices erfährst.
Kubeflow-Notebook-Images sind für den Einsatz in Kubernetes-Pods konzipiert, die für Machine-Learning-Workflows in Kubernetes entwickelt wurden. Du kannst zwischen drei Arten von Notizbüchern wählen: JupyterLab, RStudio und Visual Studio Code (Code-Server).
Teste es lokal, indem du den folgenden Befehl ausführst:
docker run -it --rm -p 8888:8888 kubeflownotebookswg/jupyter-pytorchKubeflow Notebooks-Images sind besonders nützlich in Umgebungen, in denen Kubernetes die zugrunde liegende Infrastruktur ist. Sie erleichtern kollaborative und skalierbare Machine-Learning-Projekte und integrieren sich nahtlos in Kubernetes für skalierbare und reproduzierbare Machine-Learning-Workflows.
Erfahre mehr über Docker und Kubernetesim Lernpfad Containerisierung und Virtualisierung mit Docker und Kubernetes. Dieser interaktive Lernpfad ermöglicht es dir, Anwendungen in modernen Umgebungen zu erstellen und einzusetzen.
Deep Learning-Frameworks benötigen optimierte Umgebungen für Training und Inferenz. Diese Container-Images werden mit den notwendigen Abhängigkeiten vorverpackt geliefert, was Zeit bei der Installation und Einrichtung spart.
PyTorch ist eines der führenden Deep-Learning-Frameworks und bekanntn für seinen modularen Ansatz zum Aufbau tiefer neuronaler Netze. Du kannst ein Dockerfile erstellen und deine Modellinferenz einfach ausführen, ohne das PyTorch-Paket zu installieren, indem du den Befehl pip verwendest.
FROM pytorch/pytorch:latest
RUN python main.pyDas PyTorch Docker-Image wird häufig für das Training und den Einsatz von Modellen in der Forschung und Produktion verwendet. Es bietet eine optimierte Umgebung für die Entwicklung und den Einsatz von Deep-Learning-Modellen, insbesondere für die Verarbeitung natürlicher Sprache und für Computer-Vision-Aufgaben.
TensorFlow ist ein weiteres führendes Deep-Learning-Framework, das inademia und Industrie weit verbreitet ist. Es funktioniert gut mit dem Google-Ökosystem und allen TensorFlow-unterstützenden Paketen für experimentelles Tracking und Model Serving.
FROM tensorflow/tensorflow:latest
RUN python main.pyDas TensorFlow-Docker-Image enthält das TensorFlow-Python-Paket und seine Abhängigkeiten, die oft für die GPU-Beschleunigung optimiert sind. Das macht sie ideal für die Erstellung und den Einsatz von Machine Learning-Modellen, insbesondere in großen Produktionsumgebungen.
Die NVIDIA CUDA Deep Learning Runtime ( ) ist für die Beschleunigung von Deep Learning-Berechnungen auf GPUs unerlässlich. Du kannst dies ganz einfach zu deinem Dockerfile hinzufügen, sodass du CUDA nicht mehr manuell für die Ausführung von GPU-beschleunigten Machine Learning-Aufgaben einrichten musst.
FROM nvidia/cuda
RUN python main.pyNVIDIA CUDA Docker-Images bieten eine Laufzeitumgebung, die für Deep-Learning-Anwendungen mit NVIDIA-GPUs optimiert ist und die Leistung von Deep-Learning-Modellen deutlich verbessert.
Mehr darüber, wie GPUs Data ScienceWorkflows beschleunigen, erfährst duim Polars GPU Acceleration Blog Post.
Für die Verwaltung des Lebenszyklus des maschinellen Lernens - vom Experimentieren bis zum Einsatz - sind spezielle Tools erforderlich. Diese Docker-Images vereinfachen die Versionskontrolle, den Lernpfad und die Bereitstellung.
MLflow ist eine Open-Source-Plattform für die Verwaltung des Lebenszyklus von maschinellem Lernen, einschließlich Experimenten, Reproduzierbarkeit und Einsatz. Du kannst den MLflow-Server mit dem folgenden Befehl starten, der den MLflow-Server zum Speichern und Versionieren von Experimenten, Modellen und Artefakten bereitstellt. Außerdem bietet es ein interaktives Dashboard, auf dem die Manager die Experimente und Modelle einsehen können.
docker run -it --rm -p 9000:9000 ghcr.io/mlflow/mlflowHugging Face Transformers wird für vieleriöse Anwendungen eingesetzt, von der Suche nach großen Sprachmodellen bis hin zur Erstellung von Modellen zur Bilderzeugung. Es baut auf PyTorch, TensorFlow und anderen wichtigen Deep-Learning-Frameworks auf. Das bedeutet, dass du damit jedes beliebige Modell für maschinelles Lernen laden, es feinabstimmen, die Leistung verfolgen und deine Arbeit in Hugging Face speichern kannst.
FROM huggingface/transformers-pytorch-gpu
RUN python main.pyHugging Face Transformers Docker-Images sind beliebt, um große Sprachmodelle schnell und effizient zu optimieren und einzusetzen. Insgesamt hängt das moderne KI-Ökosystem stark von diesem Paket ab, und du kannst es in dein Dockerfile einbinden, um alle Funktionen zu nutzen, ohne dich um Abhängigkeiten zu kümmern.
Projekte zum maschinellen Lernen beinhalten oft komplexe Arbeitsabläufe, die eine Automatisierung und Zeitplanung erfordern. Diese Tools zur Workflow-Orchestrierung helfen dabei, Pipelines für maschinelles Lernen zu optimieren.
Apache Airflow ist eineOpen-Source-Plattform für die programmgesteuerte Erstellung, Planung und Überwachung von Arbeitsabläufen.
docker run -it --rm -p 8080:8080 apache/airflowAirflow wird häufig für die Orchestrierung komplexer Pipelines für maschinelles Lernen eingesetzt. Es bietet eine Plattform für das Erstellen, Planen und Überwachen von Arbeitsabläufen als gerichtete azyklische Graphen (DAGs) und ist damit für die Automatisierung und Verwaltung von Daten-Workflows im Bereich des maschinellen Lernens unverzichtbar.
n8n ist ein Open-Source-Workflow Automatisierungswerkzeug, das aufgrund seiner Flexibilität und Benutzerfreundlichkeit immer beliebter wird, insbesondere bei der Automatisierung von Workflows für maschinelles Lernen. Du kannst es lokal ausführen und deine eigene RAG-Anwendung mithilfe der Drag-and-Drop-Schnittstelle erstellen.
docker run -it --rm -p 5678:5678 n8nio/n8nn8n bietet eine benutzerfreundliche Oberfläche zur Erstellung von Workflows, die verschiedene Dienste und APIs integrieren. Es ist besonders nützlich, um sich wiederholende Aufgaben zu automatisieren und verschiedene Systeme und Dienste in Machine-Learning-Projekten zu verbinden.
Wenn du mehr über die Erstellung von Machine Learning Workflows in Python erfahren möchtest, solltest du den Kurs Designing Machine Learning Workflows in Python besuchen.
Mit der zunehmenden Verbreitung von LLMs helfen spezielle Docker-Container, diese Modelle effizient einzusetzen und zu skalieren.
Ollama wurde entwickelt, um große Sprachmodelle lokal einzusetzen und auszuführen. Mit dem Ollama Docker kannst du die LLMs herunterladen und bereitstellen, damit du sie in deine Anwendungen integrieren kannst. Es ist der einfachste Weg, um sowohl quantisierte als auch vollständige große Sprachmodelle in der Produktion einzusetzen.
docker run -it --rm ollama/ollamaQdrant ist eine Vektorsuchmaschine, die für den Einsatz von Anwendungen zur Suche nach Vektorähnlichkeit verwendet wird. Es wird mit einem Dashboard und einem Server geliefert, mit dem du dich verbinden kannst, um Vektordaten schnell zu senden und abzurufen.
docker run -it --rm -p 6333:6333 qdrant/qdrantQdrant bietet Werkzeuge für die effiziente Ähnlichkeitssuche und das Clustering von hochdimensionalen Daten. Sie ist besonders nützlich für Anwendungen wie Empfehlungssysteme, Bild- und Textsuche und semantische Suche, die in Projekten des maschinellen Lernens mit großen Sprachmodellen immer wichtiger werden.
In diesem Blog haben wir 12 wichtige Docker-Container-Images vorgestellt, die für Machine-Learning-Projekte geeignet sind. Diese Bilder bieten ein umfassendes Toolkit, von Entwicklungsumgebungen bis hin zu Tools für große Sprachmodelle. Mit diesen Containern können Datenwissenschaftler und Ingenieure konsistente, reproduzierbare und skalierbare Projektumgebungen aufbauen, die Arbeitsabläufe rationalisieren und die Produktivität steigern.
Der nächste Schritt im Lernprozess besteht darin, dein eigenes Projekt mit diesen Docker-Container-Images zu bauen!
Wenn du lernen willst, wie du deine eigenen KI-Anwendungen mit den neuesten KI-Entwicklungstools erstellst , solltest du dir den Lernpfad " KI-Anwendungen entwickeln" ansehen.
Lerne mehr über maschinelles Lernen und KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
