
Lernpfad
Professioneller Dateningenieur in Python
40 Std.
Daten-Workflows und Pipelines erfordern oft eine präzise Koordination, um sicherzustellen, dass die Aufgaben in der richtigen Reihenfolge ausgeführt werden. Der gerichtete azyklische Graph (Directed Acyclic Graph, DAG) ist ein mächtiges Werkzeug, um diese Arbeitsabläufe effizient zu verwalten und Fehler zu vermeiden.
In diesem Artikel werden wir uns mit DAGs und ihrer Bedeutung für das Data Engineering befassen, einige ihrer Anwendungen betrachten und anhand eines praktischen Beispiels mit Airflow verstehen, wie man sie einsetzt.
Um zu verstehen, was eine DAG ist, müssen wir zunächst einige Schlüsselbegriffe definieren. In der Informatik ist ein Graph eine nicht-lineare Datenstruktur, die aus Knoten und Kanten besteht . Knoten stellen einzelne Entitäten oder Objekte dar, während Kanten diese Knoten verbinden und Beziehungen oder Verbindungen zwischen ihnen darstellen.
In einem gerichteten Graphen haben diese Kanten eine bestimmte Richtung und zeigen eine einseitige Beziehung zwischen den Knoten an. Das heißt, wenn es eine Kante von Knoten A zu Knoten B gibt, impliziert das eine Verbindung von A zu B, aber nicht unbedingt von B zu A.
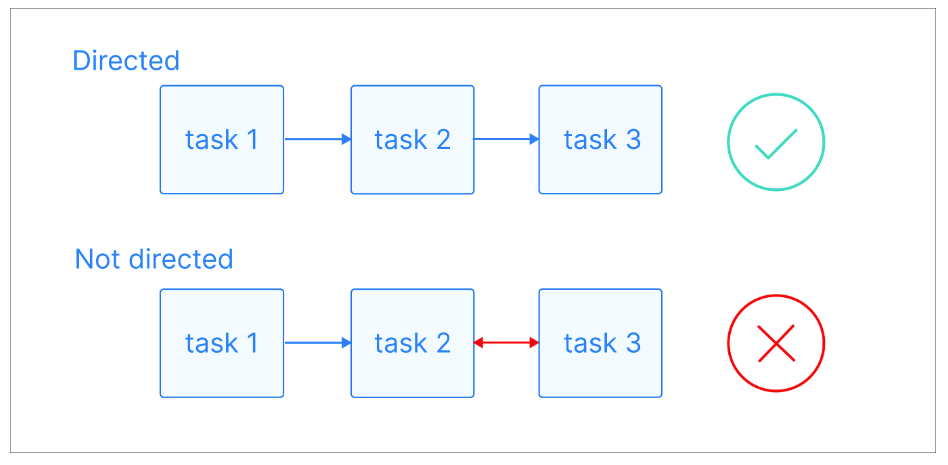
Gerichtete Graphen visuelle Erklärung. Bildquelle: Astronom
Ein Pfad ist eine Folge von Knoten, die durch gerichtete Kanten verbunden sind. Sie beginnt an einem bestimmten Knotenpunkt und folgt der Richtung der Kanten, um einen anderen Knotenpunkt zu erreichen. Ein Pfad kann beliebig lang sein, von einem einzelnen Knoten bis zu einer Folge von vielen Knoten, solange die Richtung der Kanten konsequent eingehalten wird.
Da wir nun einige grundlegende Definitionen haben, wollen wir uns ansehen, was eine DAG ist: Ein DAG ist ein gerichteter Graph ohne gerichtete Zyklen, bei dem jeder Knoten eine bestimmte Aufgabe darstellt und jede Kante die Abhängigkeit zwischen ihnen anzeigt.
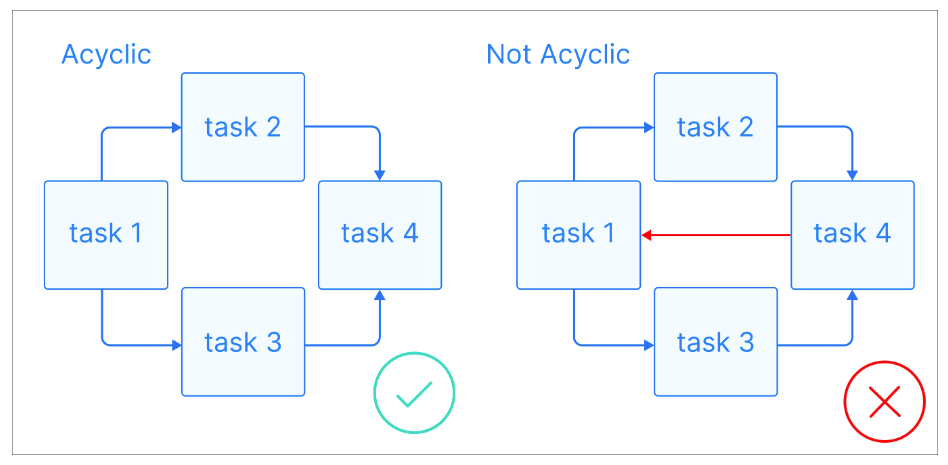 Azyklische Graphen visuelle Erklärung. Bildquelle: Astronomer
Azyklische Graphen visuelle Erklärung. Bildquelle: Astronomer
Das Wichtigste an DAGs ist, dass sie azyklischsind , d.h., wenn du an einem Knotenpunkt beginnst, kannst du dich nur vorwärts bewegen und nie zu einem vorherigen Knotenpunkt zurückkehren. So wird sichergestellt, dass die Aufgaben der Reihe nach ausgeführt werden können, ohne dass es zu Endlosschleifen kommt. DAGs haben oft eine hierarchische Struktur, bei der die Aufgaben in Ebenen oder Schichten organisiert sind. Aufgaben auf einer höheren Ebene hängen in der Regel von der Erledigung von Aufgaben auf niedrigeren Ebenen ab.
Als Data Engineer oder jemand, der Data-Engineering-Aufgaben wahrnimmt, stehst du oft vor der Herausforderung, komplexe Datenpipelines zu erstellen, die die Ausführung von Schritten erfordern, die jeweils von den vorherigen abhängen. Da kommen die DAGs ins Spiel!
Da sie Aufgaben als Knoten und Abhängigkeiten als Kanten darstellen können, erzwingen DAGs eine logische Ausführungsreihenfolge, die sicherstellt, dass Aufgaben auf der Grundlage ihrer Abhängigkeiten nacheinander ausgeführt werden. Das verhindert Fehler und Unstimmigkeiten, wenn Aufgaben nicht in der richtigen Reihenfolge ausgeführt werden. Wenn ein Schritt fehlschlägt, können DAGs die betroffenen Aufgaben identifizieren und erneut ausführen, was Zeit und Mühe spart.
Wenn du neu im Aufbau von Datenpipelines bist oder deine Grundlagen vertiefen möchtest, bietet der Kurs Understanding Data Engineering einen hervorragenden Ausgangspunkt.
Die azyklische Natur von DAGs ist eine der wichtigsten Eigenschaften, die sie ideal für Datenpipelines macht. Sie sorgen dafür, dass Aufgaben ohne Endlosschleifen oder rekursive Abhängigkeiten ausgeführt werden können, die zu einer Instabilität des Systems führen können.
Betrachten wir ein einfaches Beispiel für eine Datenpipeline:
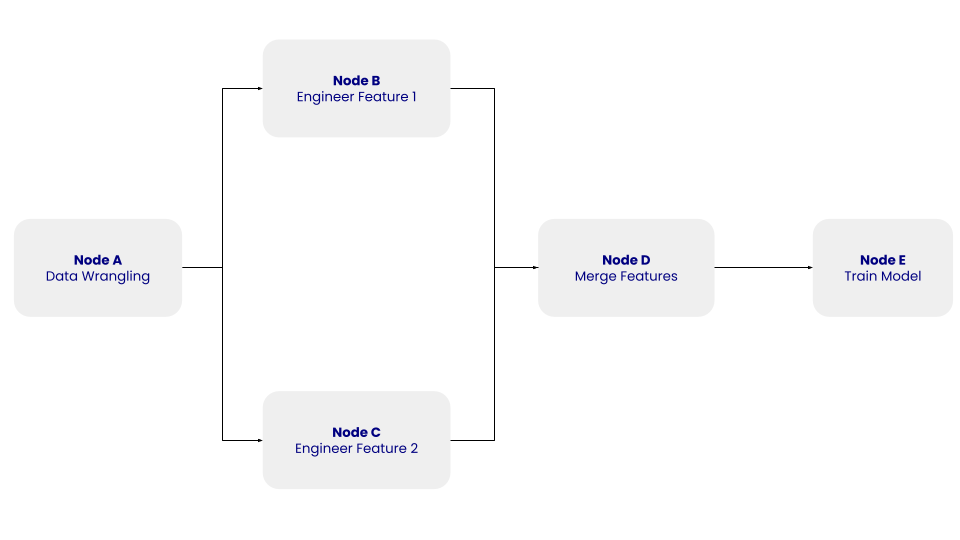 Die Struktur dieser einfachen DAG mit den Knoten A, B, C, D und E und ihren Abhängigkeiten. Bild vom Autor.
Die Struktur dieser einfachen DAG mit den Knoten A, B, C, D und E und ihren Abhängigkeiten. Bild vom Autor.
In der obigen DAG steht Knoten A für den Schritt des Data Wrangling, der den Schritt der Datenbereinigung beinhaltet, bei dem die extrahierten Daten bereinigt und vorverarbeitet werden. Die Knoten B und C stehen für die Schritte des Feature Engineering, bei denen die bereinigten Daten unabhängig voneinander in zwei Merkmale umgewandelt werden. Im Knoten D werden die Merkmale zusammengeführt. Knoten E schließlich steht für den Schritt des Modelltrainings, bei dem ein maschinelles Lernmodell auf den transformierten Daten trainiert wird.
Die DAG kümmert sich nicht darum, was in den Aufgaben passiert, sondern um die Reihenfolge, in der sie ausgeführt werden sollen.
Außerdem kannst du mit DAGs automatisierte, skalierbare Daten-Workflows erstellen, insbesondere in verteilten Systemen und Cloud-Umgebungen. Sie zerlegen komplexe Datenverarbeitungsaufgaben in kleinere, unabhängige und überschaubare Teilaufgaben, die es DAGs ermöglichen, parallel ausgeführt zu werden und Ressourcen effizient zu nutzen. Diese Skalierbarkeit ist besonders wichtig, wenn es um große Datensätze und komplexe Datenpipelines geht, denn sie ermöglicht eine kostengünstige Datenverarbeitung.
Und schließlich können DAGs eine visuelle Darstellung jeder Datenpipeline liefern, die dir hilft, den Arbeitsablauf zu verstehen und zu kommunizieren. Diese visuelle Klarheit ist wichtig, wenn du mit anderen Teammitgliedern oder nicht-technischen Interessengruppen zusammenarbeitest. Wenn du den Datenfluss und die Abhängigkeiten zwischen den Aufgaben verstehst, ist es einfacher, Probleme zu erkennen und zu beheben, die Ressourcennutzung zu optimieren und fundierte Entscheidungen über Verbesserungen in der Pipeline zu treffen.
Der Kurs über ETL und ELT in Python ist eine großartige Ressource für praktische Übungen zum Erstellen und Optimieren von Datenpipelines.
DAGs sind weit verbreitet und haben verschiedene Anwendungen in der Datentechnik. Über einige von ihnen haben wir im vorherigen Abschnitt gesprochen. Lass uns einige von ihnen genauer untersuchen.
Eine der häufigsten Anwendungen von DAGs ist die Orchestrierung von Extraktions-, Transformations- und Ladeprozessen (ETL). ETL-Pipelines beinhalten die Extraktion von Daten aus verschiedenen Quellen, die Umwandlung in ein geeignetes Format und das Laden in ein Zielsystem.
Tools wie Apache Airflow und Luigi nutzen beispielsweise DAGs, um ETL-Pipelines effizient zu orchestrieren. Ein praktischer Anwendungsfall könnte darin bestehen, Daten aus einem CRM-System zu integrieren, sie so umzuwandeln, dass sie mit deinen Geschäftsanforderungen übereinstimmen, und sie für Analysen in ein Snowflake Data Warehouse zu laden.
Du kannst DAGs auch zur Überwachung und Protokollierung von Task-Laufzeiten in deinen ETL-Prozessen nutzen. Dies kann helfen, Engpässe oder Aufgaben zu identifizieren, die optimiert werden müssen.
DAGs eignen sich auch hervorragend für die Verwaltung komplexer Daten-Workflows, die mehrere Aufgaben und Abhängigkeiten beinhalten. Ein Workflow für maschinelles Lernen kann zum Beispiel Aufgaben wie Feature Engineering, Modelltraining und Modellbereitstellung umfassen.
Ein DAG in Apache Airflow könnte zum Beispiel Skripte zur Auswahl von Merkmalen ausführen und das Modelltraining erst nach der Verarbeitung der Merkmale auslösen, um Abhängigkeiten zu verwalten und die Reproduzierbarkeit zu gewährleisten.
DAGs werden häufig in Datenverarbeitungspipelines eingesetzt, um den Datenfluss aus verschiedenen Quellen zu verwalten und in wertvolle Erkenntnisse umzuwandeln. Ein DAG in Apache Spark könnte zum Beispiel Clickstream-Daten von einer Website verarbeiten, sie aggregieren, um die Sitzungsdauer zu berechnen und die Erkenntnisse in ein Dashboard einspeisen.
DAGs in Spark werden nicht explizit von den Nutzern definiert, sondern werden intern vom Framework erstellt, um die Ausführung von Transformationen zu optimieren.
Beim maschinellen Lernen helfen DAGs dabei, die Arbeitsabläufe iterativ und modular zu gestalten. Sie ermöglichen es dir, mit verschiedenen Vorverarbeitungsschritten, Algorithmen und Hyperparametern zu experimentieren und gleichzeitig die Pipeline zu organisieren.
Tools wie Kubeflow Pipelines und MLflow nutzen DAGs zur Verwaltung von Workflows für maschinelles Lernen und ermöglichen so nahtloses Experimentieren und Deployment. Du kannst DAGs zum Beispiel nutzen, um durch die Erkennung von Datendriften ausgelöste Retraining-Pipelines zu aktivieren und so sicherzustellen, dass deine Modelle im Laufe der Zeit genau und relevant bleiben.
Du hast verschiedene Tools, die dir helfen, DAGs effektiv zu verwalten und zu orchestrieren. Schauen wir uns einige der beliebtesten Optionen an:
Apache Airflow ist eine weit verbreitete Plattform zum Erstellen, Planen und Überwachen von Arbeitsabläufen. Es eignet sich hervorragend zur Definition komplexer Datenpipelines als DAGs. Airflow bietet eine benutzerfreundliche Oberfläche zur Visualisierung und Verwaltung dieser DAGs, die das Verständnis und die Fehlersuche in Datenworkflows erleichtert. Seine Flexibilität und Skalierbarkeit haben es zur ersten Wahl für viele Data Engineering Teams gemacht.
Prefect ist ein modernes Orchestrierungstool, das die Erstellung und Verwaltung von Daten-Workflows vereinfacht. Es bietet eine Python-basierte API für die Definition von DAGs, die die Integration in bestehenden Python-Code erleichtert. Prefect legt großen Wert auf Zuverlässigkeit und Beobachtbarkeit und bietet Funktionen wie automatische Wiederholungsversuche, Backfills und eine zuverlässige Überwachung.
Dask ist eine Parallel-Computing-Bibliothek für Python, die verteilte Daten-Workflows verwaltet. Sie kann Berechnungen über mehrere Kerne oder Maschinen parallelisieren und ist damit ideal für große Datenverarbeitungsaufgaben. Dask verwendet ein DAG-basiertes Ausführungsmodell, um Aufgaben zu planen und zu koordinieren und so eine effiziente Ressourcennutzung sicherzustellen.
Kubeflow Pipelines ist eine Open-Source-Plattform für den Aufbau und die Bereitstellung von skalierbaren Machine-Learning-Workflows. Es nutzt DAGs, um End-to-End-Workflows zu definieren, von der Datenvorverarbeitung bis zur Modellbereitstellung. Die enge Integration mit Kubernetes macht es zu einer guten Wahl für die Ausführung von Workflows in Cloud-Umgebungen. Kubeflow bietet außerdem eine visuelle Schnittstelle für die Verwaltung und Überwachung von Arbeitsabläufen, die Transparenz und Kontrolle bietet.
Dagster ist eine Orchestrierungsplattform, die für moderne Daten-Workflows entwickelt wurde. Sie betont Modularität und Typsicherheit, was das Testen und Warten von DAGs erleichtert. Dagster lässt sich in gängige Tools wie Apache Spark, Snowflake und dbt integrieren und ist damit eine hervorragende Wahl für Data-Engineering-Teams mit unterschiedlichen Technologien.
Bevor du eine DAG erstellst, musst du Apache Airflow einrichten. Du kannst es mit Docker oder einem Paketmanager wie pip installieren:
pip install apache-airflowNach der Installation musst du den Airflow Webserver und den Scheduler konfigurieren. Dazu gehört das Einrichten und Initialisieren von Datenbankverbindungen und das Starten des Webservers:
airflow db init
airflow webserver --port 8080Wenn Airflow eingerichtet ist, kannst du deine DAG erstellen. Du kannst Python verwenden, um die DAG und ihre Aufgaben wie folgt zu definieren:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2In diesem Beispiel enthält die einfache DAG zwei Aufgaben: task_1 und task_2. Der >> Operator stellt eine Abhängigkeit zwischen den Aufgaben her und sorgt dafür, dass task_2 erst ausgeführt wird, wenn task_1 fertig ist.
Sobald deine DAG definiert und in Airflow implementiert ist, kannst du über die Weboberfläche mit ihr interagieren.
DAGs werden auf eine von zwei Arten ausgeführt:
schedule zu definieren.Jedes Mal, wenn du eine DAG ausführst, wird eine neue Instanz dieser DAG, genannt DAG-Lauf, erstellt. DAG-Läufe können für dieselbe DAG parallel laufen und haben jeweils ein definiertes Datenintervall, das den Zeitraum der Daten angibt, mit denen die Aufgaben arbeiten sollen.
Nach der Auslösung kannst du den Fortschritt in der DAG-Ansicht verfolgen, die den Workflow visuell darstellt.
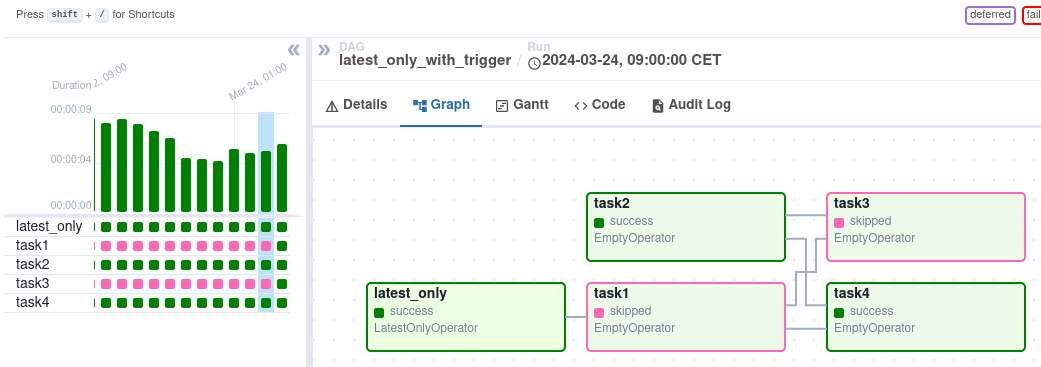 DAG-Ansicht auf der Airflow-Schnittstelle. Bildquelle: Airflow
DAG-Ansicht auf der Airflow-Schnittstelle. Bildquelle: Airflow
Die Graph Ansicht bietet einen detaillierten Blick auf einen bestimmten DAG-Lauf und zeigt die Abhängigkeiten von Aufgaben und die Ausführungszeiten. Die Ansicht Task Instances bietet detaillierte Informationen über einzelne Tasks, einschließlich ihres Status, ihrer Start- und Endzeiten und ihrer Protokolle. Du kannst Aufgabenprotokolle untersuchen, um Fehler zu beheben und die Ursache von Ausfällen zu verstehen. Die Ansicht Aufgabeninstanzen zeigt auch die Aufgabendauer an und hilft dir, mögliche Leistungsprobleme zu erkennen.
DAGs sind ein grundlegendes Konzept in der Datentechnik und bieten eine visuelle und strukturierte Möglichkeit, komplexe Arbeitsabläufe darzustellen. Das Verständnis von Knoten, Kanten und Abhängigkeiten hilft dir, Datenpipelines effizient zu gestalten und zu verwalten.
DAGs werden häufig eingesetzt, um ETL-Prozesse zu orchestrieren, Datenverarbeitungspipelines zu verwalten und Workflows für maschinelles Lernen zu automatisieren. Du kannst Tools wie Apache Airflow, Prefect und Dask nutzen, um DAGs effektiv zu erstellen und zu verwalten. Diese Tools bieten benutzerfreundliche Oberflächen, Planungsfunktionen und erweiterte Überwachungs-, Fehlerbehandlungs- und Skalierungsfunktionen.
Um praktische Erfahrungen zu sammeln, kannst du in diesem Einführungskurs zu Airflow in Python lernen, wie man DAGs effektiv erstellt und verwaltet. Für ein breiteres Verständnis von Data-Engineering-Konzepten und -Workflows bietet dieser Kurs zum Verständnis von Data-Engineering eine hervorragende Grundlage!
Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Derrick Mwiti
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
