
Cours
Prétraitement pour le Machine Learning en Python
4 h
66.6K
Si vous êtes un ingénieur en apprentissage automatique, il y a de fortes chances que vous ayez utilisé Docker dans l'un de vos projets, que ce soit pour déployer le point final d'inférence d'un modèle ou pour automatiser le pipeline d'apprentissage automatique pour la formation, l'évaluation et le déploiement. Docker simplifie ces processus et garantit la cohérence et l'évolutivité des environnements de production.
Mais voici la question : Connaissez-vous toutes les images Docker disponibles sur Docker Hub et GitHub ? Ces images préconstruites peuvent vous faire gagner du temps en vous évitant d'avoir à les construire localement. Au lieu de cela, vous pouvez les extraire et les utiliser directement dans vos Dockerfiles ou vos configurations Docker Compose, ce qui accélère le développement et le déploiement.
Dans ce blog, nous allons explorer les 12 meilleures images de conteneurs Docker conçues pour les flux de travail d'apprentissage automatique. Il s'agit notamment d'outils pour les environnements de développement, les cadres d'apprentissage profond, la gestion du cycle de vie de l'apprentissage automatique, l'orchestration des flux de travail et les grands modèles de langage.
Si vous ne connaissez pas Docker, suivez ce cours d'introduction à Docker pour en comprendre les bases.
Si vous avez déjà entendu l'expression "ça marche sur ma machine", vous comprenez la difficulté de maintenir un environnement de développement cohérent sur plusieurs plates-formes et à différents stades. C'est là qu'interviennent les conteneurs Docker, qui encapsulent le code, les dépendances et les configurations dans une image portable, garantissant ainsi la cohérence entre les différents environnements. Les modèles et l'API d'extrémité se comportent de manière identique pendant le développement, les tests et les déploiements de production, quelles que soient les variations de l'infrastructure sous-jacente.
En isolant les dépendances - telles que des versions spécifiques de Python, PyTorch ou CUDA - Docker assure la reproductibilité des expériences et réduit les conflits entre les bibliothèques.
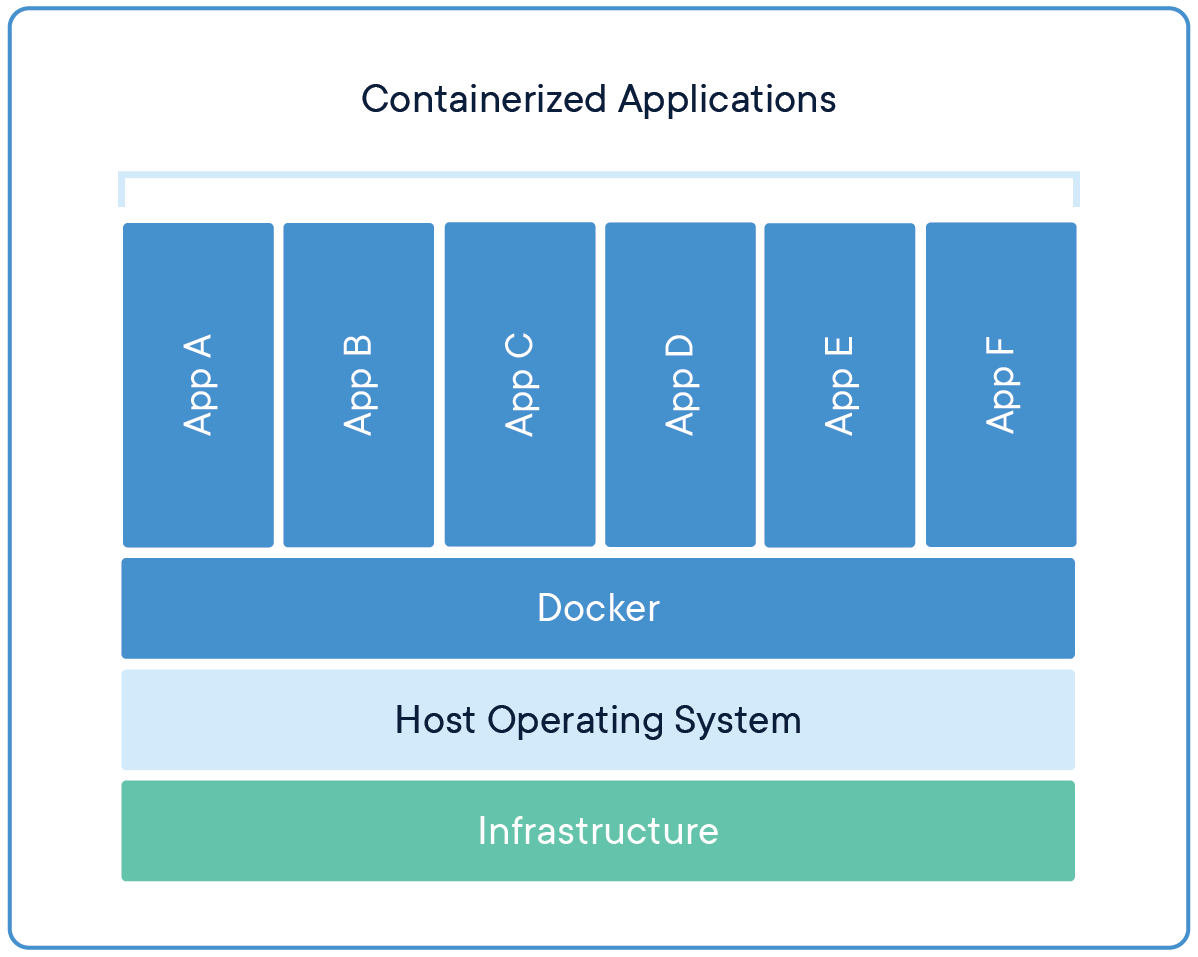
Source : Docker
Vous pouvez partager l'image Docker avec votre équipe, et ils peuvent simplement tirer l'image pour créer plusieurs instances. Ce processus rationalise également le déploiement en conditionnant les modèles dans des conteneurs avec des API, ce qui permet une intégration transparente avec des outils d'orchestration tels que Kubernetes pour un service de production évolutif.
En bref, en tant qu'ingénieur en apprentissage automatique, vous devez savoir comment manipuler les images Docker et déployer des conteneurs Docker dans le cloud.
Comprenez les concepts de base de la conteneurisation en vous inscrivant à la courte formation Concepts de conteneurisation et de virtualisation.
Pour mettre en place un flux de développement d'apprentissage automatique transparent, vous avez besoin d'un environnement fiable avec des outils et des bibliothèques essentiels. Ces images de conteneurs Docker fournissent des configurations préconfigurées pour la science des données, le codage et l'expérimentation.
Python est l'épine dorsale de la plupart des projets d'apprentissage automatique, car presque tous les principaux cadres et applications, tels que TensorFlow, PyTorch et scikit-learn, sont construits autour de lui. Sa popularité s'étend au déploiement, où Python est couramment utilisé dans les images Docker pour créer des environnements cohérents pour l'inférence de modèles. Par exemple :
FROM python:3.8
RUN pip install --no-cache-dir numpy pandasLa simplicité de Python, son vaste écosystème de bibliothèques et sa compatibilité avec des outils comme Docker en font un choix de premier ordre pour le développement et le déploiement de l'apprentissage automatique.
Les piles Jupyter Docker fournissent un environnement complet pour la science des données et l'apprentissage automatique, y compris Jupyter Notebook et une suite de bibliothèques populaires pour la science des données. Vous pouvez facilement extraire l'image de Docker Hub et l'utiliser localement. En outre, vous pouvez déployer cette instance sur le cloud et la partager avec votre équipe.
Pour lancer le Jupyter Data Science Notebook, utilisez la commande suivante :
docker run -it --rm -p 8888:8888 jupyter/datascience-notebookIl peut également être utilisé avec un fichier Dockerfile, ce qui vous évite d'installer des paquets Python à l'aide de pip. Il vous suffit de lancer l'application ou d'exécuter un script Python. Voici un exemple de fichier Docker :
FROM jupyter/datascience-notebook:latestCette image comprend des bibliothèques populaires telles que NumPy, pandas, matplotlib et scikit-learn, ainsi que Jupyter Notebook pour l'informatique interactive. Il est idéal pour l'exploration des données, la visualisation et les expériences d'apprentissage automatique, ce qui en fait un élément essentiel de la communauté de la science des données.
Pour plus d'informations, consultez le blog Docker for Data Science : Une introduction, où vous pourrez découvrir les commandes Docker, la dockérisation des applications d'apprentissage automatique et les meilleures pratiques de l'industrie.
Les images Kubeflow Notebook sont conçues pour fonctionner dans les pods Kubernetes, qui sont construits pour les flux de travail d'apprentissage automatique sur Kubernetes. Vous avez le choix entre trois types de carnets : JupyterLab, RStudio et Visual Studio Code (serveur de code).
Testez-le localement en exécutant la commande suivante :
docker run -it --rm -p 8888:8888 kubeflownotebookswg/jupyter-pytorchLes images Kubeflow Notebooks sont particulièrement utiles dans les environnements où Kubernetes est l'infrastructure sous-jacente. Ils facilitent les projets d'apprentissage automatique collaboratifs et évolutifs et s'intègrent parfaitement à Kubernetes pour des flux de travail d'apprentissage automatique évolutifs et reproductibles.
Découvrez Docker et Kubernetesen suivant le cursus de compétences Conteneurisation et virtualisation avec Docker et Kubernetes. Ce cursus interactif vous permettra de construire et de déployer des applications dans des environnements modernes.
Les cadres d'apprentissage profond nécessitent des environnements optimisés pour la formation et l'inférence. Ces images de conteneurs sont préemballées avec les dépendances nécessaires, ce qui permet de gagner du temps lors de l'installation et de la configuration.
PyTorch est l'un des principaux cadres d'apprentissage profond connusn pour son approche modulaire de la construction de réseaux neuronaux profonds. Vous pouvez créer un fichier Docker et exécuter votre modèle d'inférence facilement sans installer le paquet PyTorch à l'aide de la commande pip.
FROM pytorch/pytorch:latest
RUN python main.pyL'image Docker PyTorch est largement utilisée pour l'entraînement et le déploiement de modèles dans des contextes de recherche et de production. Il fournit un environnement optimisé pour développer et déployer des modèles d'apprentissage profond, en particulier dans les tâches de traitement du langage naturel et de vision par ordinateur.
TensorFlow est un autre cadre d'apprentissage profond de premier plan largement adopté dans l'academia et l'industrie. Il fonctionne bien avec l'écosystème Google et tous les paquets supportant TensorFlow pour le suivi expérimental et le service de modèles.
FROM tensorflow/tensorflow:latest
RUN python main.pyL'image Docker TensorFlow inclut le package Python TensorFlow et ses dépendances, souvent optimisés pour l'accélération GPU. Il est donc idéal pour élaborer et déployer des modèles d'apprentissage automatique, en particulier dans les environnements de production à grande échelle.
Le runtime d'apprentissage profond NVIDIA CUDA est essentiel pour accélérer les calculs d'apprentissage profond sur les GPU. Vous pouvez facilement l'ajouter à votre fichier Docker, éliminant ainsi la nécessité de configurer manuellement CUDA pour exécuter des tâches d'apprentissage automatique accélérées par le GPU.
FROM nvidia/cuda
RUN python main.pyLes images Docker NVIDIA CUDA offrent un environnement d'exécution optimisé pour les applications de deep learning utilisant les GPU NVIDIA, améliorant ainsi de manière significative les performances des modèles de deep learning.
Vous pouvez en savoir plus sur la façon dont les GPU accélèrent lesflux de travail en science des donnéesdans l'article du blog Polars sur l'accélération GPU.
La gestion du cycle de vie de l'apprentissage automatique - de l'expérimentation au déploiement - nécessite des outils spécialisés. Ces images Docker rationalisent la gestion des versions, le suivi et le déploiement.
MLflow est une plateforme open-source permettant de gérer le cycle de vie de l'apprentissage automatique, y compris l'expérimentation, la reproductibilité et le déploiement. Vous pouvez lancer le serveur MLflow à l'aide de la commande suivante, qui fournira le serveur MLflow pour le stockage et la gestion des versions des expériences, des modèles et des artefacts. Il fournit également un tableau de bord interactif permettant aux gestionnaires de visualiser les expériences et les modèles.
docker run -it --rm -p 9000:9000 ghcr.io/mlflow/mlflowHugging Face Transformers est largement utilisé pour varieuses applications, de la recherche de grands modèles de langage à la construction de modèles de génération d'images. Il est construit au-dessus de PyTorch, TensorFlow, et d'autres frameworks majeurs d'apprentissage profond. Cela signifie que vous pouvez l'utiliser pour charger n'importe quel modèle d'apprentissage automatique, l'affiner, suivre les performances et enregistrer votre travail sur Hugging Face.
FROM huggingface/transformers-pytorch-gpu
RUN python main.pyHugging Face Transformers Les images Docker sont très appréciées pour affiner et déployer rapidement et efficacement de grands modèles de langage. Dans l'ensemble, l'écosystème moderne de l'IA dépend fortement de ce paquet, et vous pouvez l'incorporer dans votre fichier Docker pour profiter de toutes ses fonctionnalités sans vous soucier des dépendances.
Les projets d'apprentissage automatique impliquent souvent des flux de travail complexes qui nécessitent une automatisation et une planification. Ces outils d'orchestration de flux de travail permettent de rationaliser les pipelines d'apprentissage automatique.
Apache Airflow est uneplateforme open-sourcepermettant de créer, planifier et contrôler des flux de travail de manière programmatique.
docker run -it --rm -p 8080:8080 apache/airflowAirflow est largement utilisé pour orchestrer des pipelines complexes d'apprentissage automatique. Il fournit une plate-forme pour la création, l'ordonnancement et le suivi des flux de travail sous la forme de graphes acycliques dirigés (DAG), ce qui le rend indispensable dans l'ingénierie de l'apprentissage automatique pour automatiser et gérer les flux de données.
n8n est un outil d'automatisation de flux de travail open-source qui gagne en popularité en raison de sa flexibilité et de sa facilité d'utilisation, en particulier pour l'automatisation des flux de travail d'apprentissage automatique. Vous pouvez l'exécuter localement et créer votre propre application RAG à l'aide de l'interface "glisser-déposer".
docker run -it --rm -p 5678:5678 n8nio/n8nn8n fournit une interface conviviale pour créer des flux de travail intégrant divers services et API. Il est particulièrement utile pour automatiser les tâches répétitives et connecter différents systèmes et services dans les projets d'apprentissage automatique.
Pour en savoir plus sur la création de workflows d'apprentissage automatique en Python, pensez à suivre la formation Conception de workflows d'apprentissage automatique en Python.
À mesure que les LLM se généralisent, les conteneurs Docker spécialisés permettent de déployer et de mettre à l'échelle ces modèles de manière efficace.
Ollama est conçu pour déployer et exécuter localement de grands modèles de langage. En utilisant le Docker Ollama, vous pouvez télécharger et servir les LLM, ce qui vous permet de les intégrer dans vos applications. C'est le moyen le plus simple d'utiliser des modèles linguistiques quantifiés et complets en production.
docker run -it --rm ollama/ollamaQdrant est un moteur de recherche vectoriel utilisé pour déployer des applications de recherche par similarité vectorielle. Il est livré avec un tableau de bord et un serveur auquel vous pouvez vous connecter pour envoyer et récupérer rapidement des données vectorielles.
docker run -it --rm -p 6333:6333 qdrant/qdrantQdrant fournit des outils pour la recherche efficace de similarités et le regroupement de données à haute dimension. Elle est particulièrement utile dans des applications telles que les systèmes de recommandation, la recherche d'images et de textes, et la recherche sémantique, qui sont de plus en plus importantes dans les projets d'apprentissage automatique impliquant de grands modèles de langage.
Dans ce blog, nous avons exploré 12 images de conteneurs Docker essentielles adaptées aux projets d'apprentissage automatique. Ces images fournissent une boîte à outils complète, depuis les environnements de développement jusqu'aux outils pour les grands modèles de langage. En tirant parti de ces conteneurs, les scientifiques et les ingénieurs peuvent créer des environnements de projet cohérents, reproductibles et évolutifs, rationalisant ainsi les flux de travail et améliorant la productivité.
La prochaine étape du processus d'apprentissage consiste à construire votre propre projet à l'aide de ces images de conteneurs Docker !
Si vous souhaitez apprendre à créer vos propres applications d'IA avec les derniers outils de développement d'IA, consultez le cursus Développer des applications d'IA.
Apprenez-en plus sur l'apprentissage automatique et l'IA grâce à ces cours !
Cours
Cours
Cours