
Lernpfad
Grundlagen der Statistik mit Python
20 Std.
Die ROC-Kurve veranschaulicht die Kompromisse zwischen der Wahr-Positiv-Rate (TPR) und der Falsch-Positiv-Rate (FPR) bei verschiedenen Schwellenwerten. Sie gibt Aufschluss darüber, wie gut das Modell den Kompromiss zwischen der Erkennung positiver Instanzen und der Vermeidung von Fehlalarmen bei verschiedenen Schwellenwerten ausbalancieren kann. AUC, oder Area Under the Curve, ist ein einzelner skalarer Wert zwischen 0 und 1, der eine Momentaufnahme der Leistung des Modells darstellt. Du berechnest die AUC erst, nachdem du die ROC-Kurve erstellt hast, denn die AUC ist die Fläche unter der Kurve.
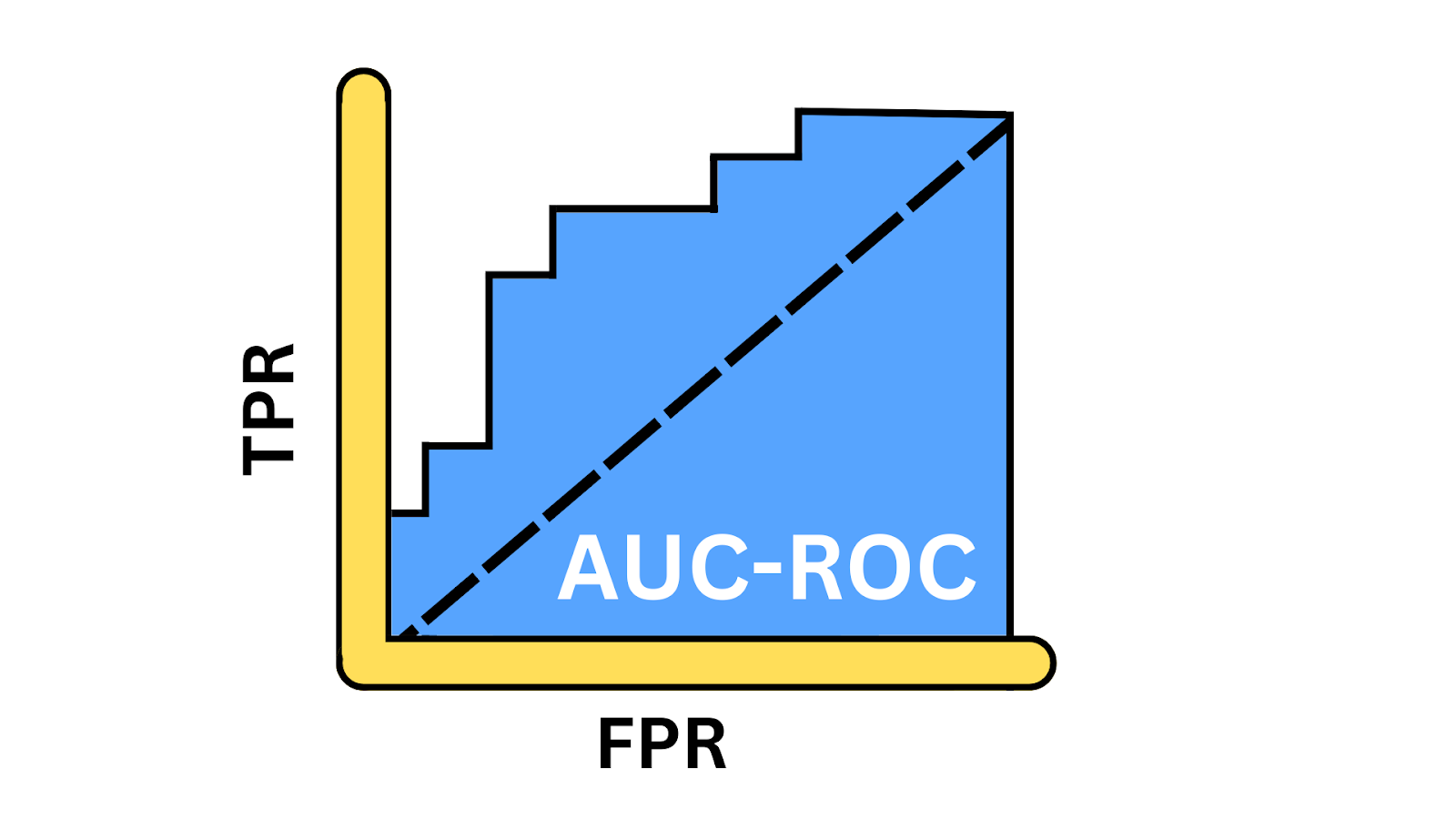
Abbildung der AUC-ROC-Kurve. Bild vom Autor
Die True-Positive-Rate, auch Sensitivität oder Recall genannt, spiegelt die Fähigkeit eines Modells wider, positive Instanzen korrekt zu identifizieren. Sie misst den Anteil der tatsächlich positiven Fälle, die das Modell erfolgreich identifiziert. Mathematisch lässt sich das wie folgt ausdrücken durch die folgende Gleichung ausgedrückt werden:
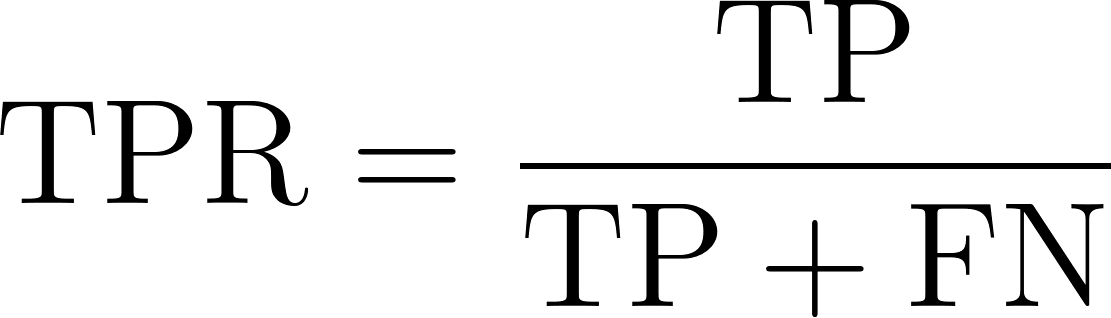
Wo:
FPR gibt an, wie oft unser Modell negative Klasseninstanzen fälschlicherweise als positiv klassifiziert. Sie misst den Anteil der tatsächlich negativen Instanzen, die vom Modell fälschlicherweise als positiv identifiziert werden, und gibt damit die Rate der Fehlalarme an. Mathematisch lässt sich das wie folgt ausdrücken.

Wo:
Lasst uns die Szenarien verstehen, in denen AUC-ROC eine relevantere Kennzahl ist.
Der AUC-ROC ist ein aggregiertes Leistungsmaß für alle möglichen Klassifizierungsschwellenwerte. Im Gegensatz zu Genauigkeit, Präzision oder F1-Score, die von einem bestimmten Schwellenwert abhängen, wird die Leistung des Modells bei verschiedenen Betriebspunkten berücksichtigt.
Der AUC-ROC ist ein einziger skalarer Wert, der den Vergleich mehrerer Modelle erleichtert, unabhängig von ihren Klassifizierungsschwellenwerten. Durch seine Schwellenwertunabhängigkeit ist es die bessere Wahl, um einen fairen Vergleich zwischen Modellen mit unterschiedlichen optimalen Schwellenwerten zu ziehen.
Die meisten realen Datensätze sind unausgewogen, d. h. eine Klasse ist unverhältnismäßig stärker vertreten als die andere, z. B. bei der Stimmungsanalyse, der Betrugserkennung und der Krebserkennung. In solchen Szenarien liefern Messgrößen wie die Genauigkeit eine irreführende Bewertung der Modellleistung, da sie auf die Mehrheitsklasse ausgerichtet sind. In solchen Szenarien sind Metriken wie AUC-ROC zuverlässiger.
Werfen wir einen Blick auf einige der wichtigsten Ideen.
Um die ROC-Kurve zum Leben zu erwecken, berechnen wir die TPR und FPR bei verschiedenen Schwellenwerten. Beginnen wir mit dem Importieren der Bibliotheken, die für diese Demo benötigt werden.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as pltAls Nächstes erstellen wir mit der Funktion make-classification() einen binären Klassifizierungsdatensatz mit 1000 Stichproben und 20 Merkmalen.
# Generate a binary classification dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=0)Teilen wir den Datensatz in Trainings- und Testdaten auf - wir trainieren das Modell auf dem Trainingsset und messen seine Leistung auf dem ungesehenen Testdatenset.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)Als Nächstes definieren wir das Modellobjekt, indem wir die Klasse LogisticRegression() aufrufen, und trainieren es dann mit der Methode fit auf den Trainingsdaten, wobei X_train die Features und y_train die Labels repräsentiert.
# Train a Logistic Regression model
model = LogisticRegression()
model.fit(X_train, y_train)Jetzt ist das Modell trainiert und bereit, Vorhersagen zu treffen. Wir rufen die Funktion predict_proba() auf, um die Wahrscheinlichkeit für eine positive Klasse zu erzeugen. Wir verwenden die Methode predict(), um Bewertungskennzahlen wie Genauigkeit, Präzision, Wiedererkennung und F1-Score zu berechnen.
# Predict the probabilities for the test set
y_probs = model.predict_proba(X_test)[:, 1]
# Predict the classes for the test set
y_pred = model.predict(X_test)Als Nächstes berechnen und drucken wir alle diese Metriken mit ihren jeweiligen Funktionen.
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
# Calculate other metrics
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# Print the metrics
print(f"AUC - ROC Score: {roc_auc:.2f}")
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")AUC-ROC Score: 0.93
Accuracy: 0.87
Precision: 0.87
Recall: 0.87
F1 Score: 0.87Nun wollen wir die ROC-Kurve zusammen mit der diagonalen Linie, die ein Zufallsmodell darstellt, visualisieren. Um dies zu berechnen, benötigen wir FPR und TPR für jede diskrete Schwelle zwischen 0 und 1. In der folgenden Grafik stellt die orangefarbene Kurve die ROC dar und die Fläche unter dieser Kurve beträgt 0,93.
# Plotting the ROC Curve
fpr, tpr, thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()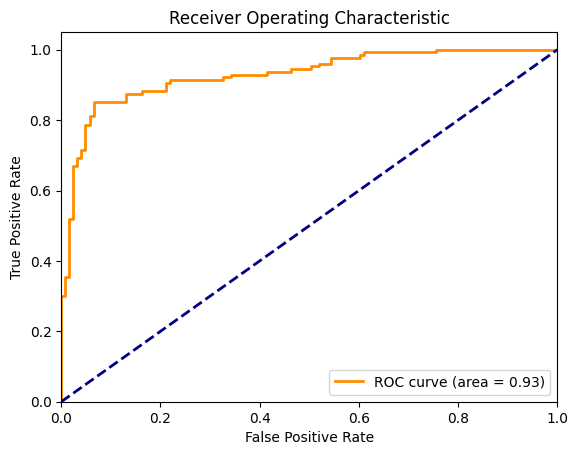
ROC-Kurve für die logistische Regression. Bild vom Autor
Nun wollen wir denselben Datensatz verwenden und die Leistung der vier Klassifizierungsalgorithmen mithilfe von ROC vergleichen. Wir beginnen mit dem Import von RandomForestClassifier, KNeighborsClassifier und SVC und vergleichen diese mit LogisticRegression.
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# Define the models
models = {
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"SVM": SVC(probability=True),
"K-Nearest Neighbors": KNeighborsClassifier()
}
# Initialize a dictionary to store AUC - ROC scores
roc_auc_scores = {}
# Plot the ROC curves
plt.figure(figsize=(10, 8))
for name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict the probabilities
y_probs = model.predict_proba(X_test)[:, 1]
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
roc_auc_scores[name] = roc_auc
# Compute ROC curve
fpr, tpr, _ = roc_curve(y_test, y_probs)
# Plot ROC curve
plt.plot(fpr, tpr, lw=2, label=f'{name} (AUC = {roc_auc:.2f})')
# Plot the diagonal 50% line
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# Customize the plot
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve Comparison')
plt.legend(loc="lower right")
plt.show()
# Print the AUC - ROC scores for each model
for name, score in roc_auc_scores.items():
print(f'{name}: AUC - ROC = {score:.2f}')Für jedes Modellobjekt wiederholen wir die fit() und predict_proba(), berechnen die entsprechenden FPR und TPR und stellen dann die jeweiligen Kurven dar.
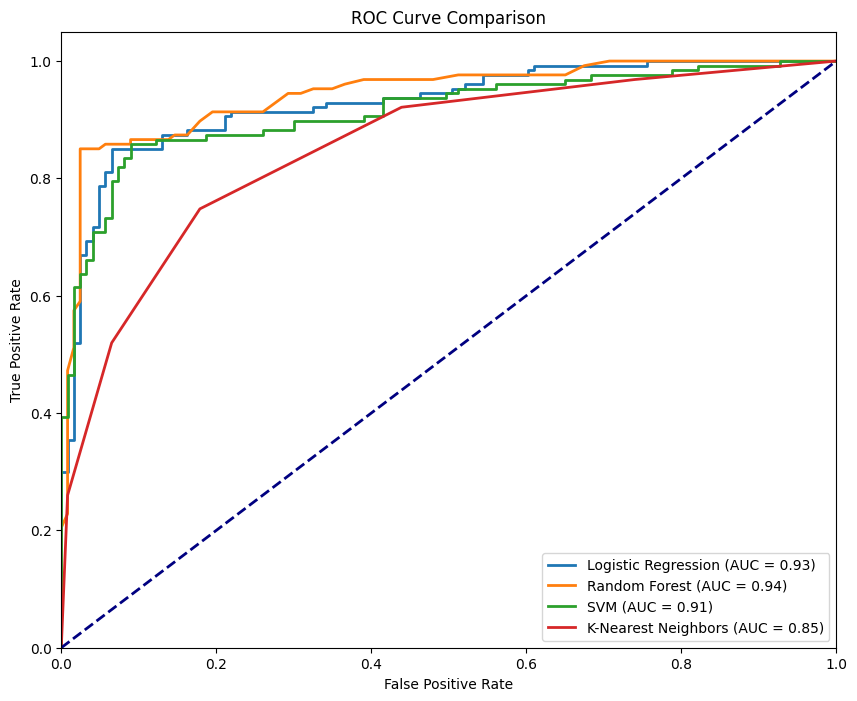
ROC-Kurve für verschiedene Modelle. Bild vom Autor
Die obige Abbildung zeigt alle vier Kurven, die den vier Klassifikatoren entsprechen, wobei der RandomForestClassifier mit einem AUC-ROC von 0,94 am besten abschneidet, während der KNeighborsClassifier mit einem AUC-ROC von 0,85 am schlechtesten abschneidet. Ein ideales Modell würde die linke obere Ecke des Diagramms umarmen - dort, wo die TPR maximiert und die FPR minimiert ist. Je näher die Kurve an diesem Punkt liegt, desto besser ist die Leistung des Modells.
Schauen wir uns die Kennzahlen an, die die AUC-ROC-Kurve liefert, und verstehen wir ihre Bedeutung.
Die AUC-Werte geben einen schnellen Überblick darüber, wie gut das Modell funktioniert. Wenn der AUC nahe bei 1 liegt, ist unser Modell auf dem Höhepunkt seiner Leistungsfähigkeit. Es zeigt eine hervorragende Leistung mit einer starken Fähigkeit, zwischen Klassen zu unterscheiden. Ein AUC-Wert um 0,5 ist besorgniserregend, da er zeigt, dass das Modell nicht besser ist als das zufällige Raten und somit keine Trennschärfe besitzt. Ein AUC-Wert, der näher bei 0 liegt, ist eine alarmierende Situation. Das deutet darauf hin, dass das Modell völlig falsch liegt, schlimmer noch als ein Münzwurf.
TPR oder Sensitivität ist eine wichtige Kennzahl, die angibt, wie gut unser Modell die positiven Instanzen erfasst. Die TPR wird als der Anteil der tatsächlich positiven Ergebnisse berechnet, die vom Modell richtig erkannt wurden. Das ist ein wichtiger Indikator für die Effektivität unseres Modells bei der Erkennung der echten Signale (Positivmeldungen). Eine hohe TPR bedeutet, dass unser Modell sehr gut erkennt, was am wichtigsten ist.
Auf der anderen Seite hilft uns die FPR, das Rauschen zu verstehen - wie oft unser Modell fälschlicherweise Negatives als Positives identifiziert. FPR ist der Anteil der tatsächlichen Negativmeldungen, die unser Modell fälschlicherweise als Positivmeldungen kennzeichnet. Das ist eine wichtige Kennzahl, um die Kompromisse, die unser Modell eingeht, zu bewerten. Eine hohe FPR weist auf eine Tendenz zu Fehlalarmen hin, die je nach Anwendung kostspielig sein können.
Die Schönheit und die Herausforderung der binären Klassifizierung liegen in der Einstellung der Schwellenwerte. Deshalb stimmen wir die Sensitivität (TPR) und Spezifität (1 - FPR) unseres Modells genau ab. Wir können steuern, wie empfindlich unser Modell auf die Erkennung positiver Klasseninstanzen reagiert, und die Zahl der Falsch-Positiven reduzieren, indem wir den Schwellenwert anpassen. In den meisten realen Szenarien können die Kosten von falsch-negativen (fehlenden positiven) gegenüber falsch-positiven (falschen Alarmen) erheblich variieren.
Der AUC-ROC ist nicht nur ein theoretisches Konzept. Hier erfährst du, wie diese praktische Kennzahl in verschiedenen Branchen eingesetzt wird, um wichtige Entscheidungen zu treffen:
Die AUC-ROC wird verwendet, um verschiedene diagnostische Tests zu vergleichen. Das ist besonders nützlich, wenn die Kosten für falsch negative Ergebnisse (z. B. das Übersehen einer Krankheit) viel höher sind als für falsch positive Ergebnisse (z. B. eine unnötige Behandlung). Ein bemerkenswertes Beispiel wäre die Krebsvorsorge, bei der der Schwellenwert für weitere Tests auf der Grundlage von Risikofaktoren und verfügbaren Ressourcen angepasst werden kann.
Modelle des maschinellen Lernens werden zunehmend eingesetzt, um betrügerische Aktivitäten im Finanzsektor zu erkennen. Wenn man bedenkt, dass Betrugstransaktionen sehr selten sind, sind solche Datensätze sehr unausgewogen. Daher ist AUC-ROC ein effektiver Bewertungsmaßstab, der es auch ermöglicht, den Schwellenwert auf der Grundlage verschiedener Faktoren anzupassen, z. B. der Höhe des mit der Transaktion verbundenen Risikos, der Kosten für die manuelle Überprüfung jeder Transaktion und der Kosten für die Unannehmlichkeiten für die Kunden.
Ähnlich wie bei der Betrugsaufdeckung sind auch Cyberangriffe relativ seltene Ereignisse. Daher findet AUC-ROC auch in der Cybersicherheit Anwendung, wo es darum geht, Bedrohungen zu erkennen und eine Ermüdung durch falsch-positive Meldungen zu vermeiden.
AUC-ROC ist eine beliebte Kennzahl für die Bewertung von binären Klassifizierungsmodellen, aber es gibt Szenarien, in denen andere Kennzahlen geeigneter sein können. Wir wollen einige Alternativen untersuchen und herausfinden, wann man sie einsetzen sollte:
Die Precision-Recall-Kurve (PRC) ist eine Metrik für unausgewogene Datensätze, die den Wert des maschinellen Lernmodells erheblich beeinflusst, wenn falsch-positive und falsch-negative Ergebnisse unterschiedliche Kosten haben. Im Gegensatz zum AUC-ROC, der bei unausgewogenen Datensätzen eine irreführend optimistische Sichtweise vermitteln kann, konzentriert sich PRC mehr auf die Leistung in Bezug auf die positive Klasse.
Die F1-Punktzahl ist das harmonische Mittel aus Precision und Recall und stellt eine einzige Metrik dar, die beide ausgleicht. Sie wird verwendet, wenn wir eine klare, einstellige Zusammenfassung der Modellleistung benötigen, insbesondere bei unausgewogenen Datensätzen. Die AUC-ROC bietet eine globalere Sicht, während F1 ein bestimmter Punkt auf der PRC-Kurve ist.
Der AUC-ROC ist der Goldstandard bei binären Klassifizierungsproblemen, weil er einen ausgewogeneren Überblick darüber gibt, wie gut das Modell bei verschiedenen Schwellenwerten abschneidet, vor allem in Szenarien mit Klassenungleichheit.
Wir glauben, dass der beste Weg, das Gelernte zu festigen, die praktische Anwendung ist. Die Vielseitigkeit von Python gibt uns die perfekte Möglichkeit, grundlegende Konzepte zu beherrschen. Egal, ob wir unsere Grundlagen auffrischen oder fortgeschrittenere Themen erforschen wollen, jetzt ist der ideale Zeitpunkt, um einzusteigen. Lass uns unsere Python-Grundlagen wiederholen und uns selbst herausfordern, indem wir mit AUC-ROC an komplexen Datensätzen arbeiten.
Lerne Python und Statistik mit DataCamp
Lernpfad
Kurs
Kurs