
programa
Fundamentos de Estadística en Python
20 h
La curva ROC ofrece una representación visual de las compensaciones entre la tasa de verdaderos positivos (TPR) y la tasa de falsos positivos (FPR) con distintos umbrales. Proporciona información sobre lo bien que el modelo puede equilibrar las compensaciones entre detectar instancias positivas y evitar falsos positivos a través de diferentes umbrales. AUC, o Área Bajo la Curva, es un valor escalar único que va de 0 a 1, y que da una instantánea del rendimiento del modelo. Sólo calculas el AUC después de generar la curva ROC, porque el AUC representa el área bajo la curva.
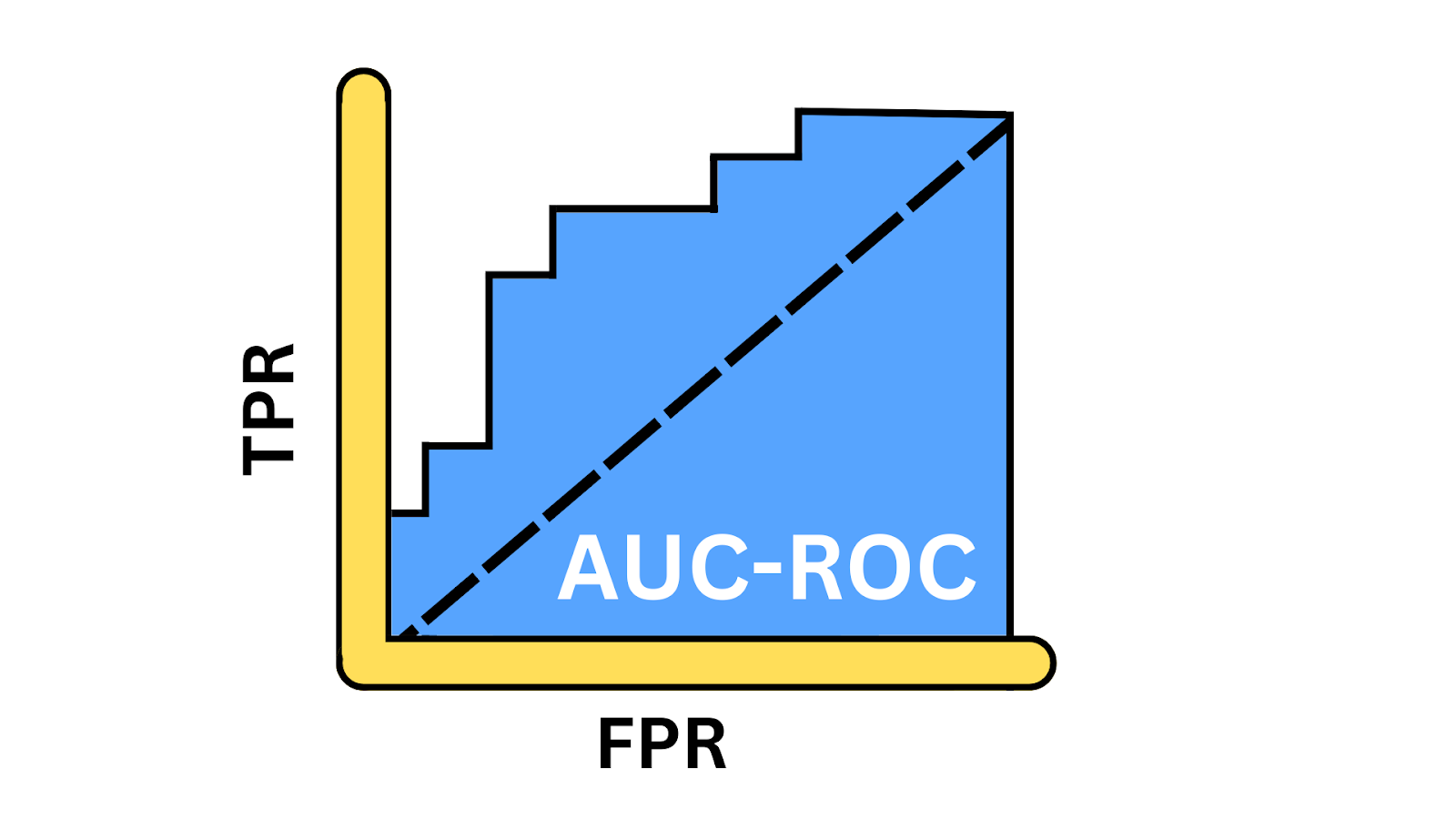
Ilustración de la curva AUC-ROC. Imagen del autor
La tasa de verdaderos positivos, también conocida como sensibilidad o recuerdo, refleja la capacidad de un modelo para identificar correctamente los casos positivos. Mide la proporción de casos positivos reales que el modelo identifica con éxito. Matemáticamente, esto puede expresarse mediante la siguiente ecuación:
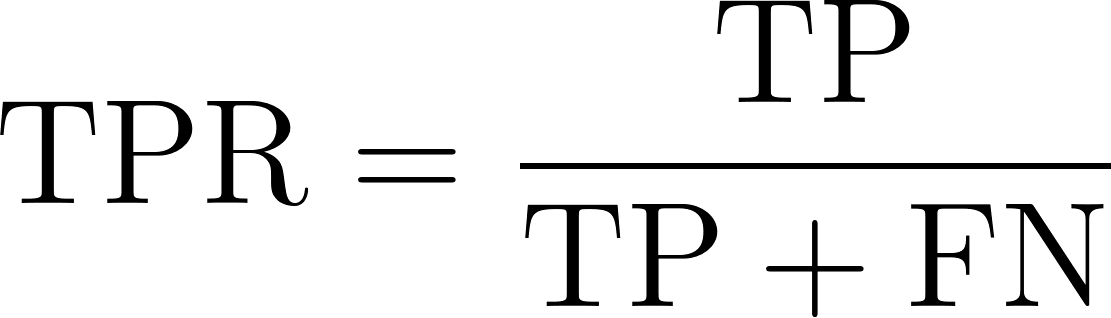
Dónde:
FPR representa la frecuencia con la que nuestro modelo clasifica incorrectamente como positivas las instancias de clase negativas. Mide la proporción de instancias negativas reales que el modelo identifica incorrectamente como positivas, lo que indica la tasa de falsas alarmas. Matemáticamente esto se puede expresar de la siguiente manera.

Dónde:
Comprendamos los escenarios en los que el AUC-ROC es una métrica más relevante.
El AUC-ROC proporciona una medida de rendimiento agregada en todos los umbrales de clasificación posibles. A diferencia de la exactitud, la precisión o la puntuación F1, que dependen de un umbral concreto, tiene en cuenta el rendimiento del modelo en distintos puntos de funcionamiento.
El AUC-ROC es un valor escalar único que facilita la comparación de varios modelos, independientemente de sus umbrales de clasificación. Su naturaleza independiente del umbral hace que sea la mejor opción para establecer una comparación justa entre modelos con diferentes umbrales óptimos.
La mayoría de los conjuntos de datos de la vida real son desequilibrados, en los que una clase es desproporcionadamente mayor que la otra, por ejemplo, el análisis de sentimientos, la detección del fraude y la detección del cáncer. En tales situaciones, las métricas como la precisión proporcionan una evaluación engañosa del rendimiento del modelo, ya que están sesgadas hacia la clase mayoritaria. En estos casos, métricas como AUC-ROC son más fiables.
Veamos algunas de las ideas clave.
Para dar vida a la curva ROC, calcularemos el TPR y el FPR con distintos umbrales. Empecemos por importar las bibliotecas necesarias para esta demostración.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as pltA continuación, generaremos un conjunto de datos de clasificación binaria utilizando la función make-classification(), con 1000 muestras y 20 características.
# Generate a binary classification dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=0)Dividamos el conjunto de datos en datos de entrenamiento y datos de prueba: entrenaremos el modelo en el conjunto de datos de entrenamiento y mediremos su rendimiento en el conjunto de datos de prueba no visto.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)A continuación, definimos el objeto modelo llamando a la clase LogisticRegression() y luego lo entrenamos utilizando el método fit sobre los datos de entrenamiento, donde X_train tiene las características y y_train representa las etiquetas.
# Train a Logistic Regression model
model = LogisticRegression()
model.fit(X_train, y_train)Ahora, el modelo está entrenado y listo para generar predicciones. Llamamos a la función predict_proba() para generar la probabilidad de una clase positiva. Utilizamos el método predict() para calcular métricas de evaluación como la exactitud, la precisión, el recuerdo y la puntuación F1.
# Predict the probabilities for the test set
y_probs = model.predict_proba(X_test)[:, 1]
# Predict the classes for the test set
y_pred = model.predict(X_test)A continuación, calculamos e imprimimos todas estas métricas utilizando sus respectivas funciones.
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
# Calculate other metrics
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# Print the metrics
print(f"AUC - ROC Score: {roc_auc:.2f}")
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")AUC-ROC Score: 0.93
Accuracy: 0.87
Precision: 0.87
Recall: 0.87
F1 Score: 0.87Ahora, visualicemos la curva ROC junto con la línea diagonal que representa un modelo de azar. Para calcularlo, necesitamos FPR y TPR para cada umbral discreto entre 0 y 1. En el gráfico siguiente, la curva naranja representa el ROC y el área bajo esta curva es de 0,93.
# Plotting the ROC Curve
fpr, tpr, thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()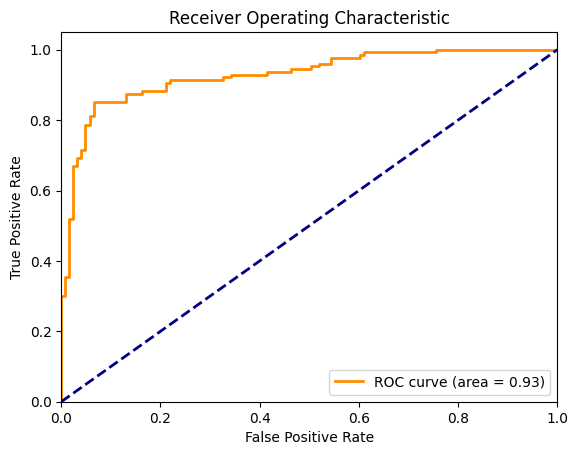
Curva ROC para la regresión logística. Imagen del autor
Ahora, utilicemos el mismo conjunto de datos y comparemos el rendimiento de cuatro algoritmos de clasificación utilizando el ROC. Empezaremos importando los sitios RandomForestClassifier, KNeighborsClassifier, y SVC y los compararemos con el sitio LogisticRegression.
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# Define the models
models = {
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"SVM": SVC(probability=True),
"K-Nearest Neighbors": KNeighborsClassifier()
}
# Initialize a dictionary to store AUC - ROC scores
roc_auc_scores = {}
# Plot the ROC curves
plt.figure(figsize=(10, 8))
for name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict the probabilities
y_probs = model.predict_proba(X_test)[:, 1]
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
roc_auc_scores[name] = roc_auc
# Compute ROC curve
fpr, tpr, _ = roc_curve(y_test, y_probs)
# Plot ROC curve
plt.plot(fpr, tpr, lw=2, label=f'{name} (AUC = {roc_auc:.2f})')
# Plot the diagonal 50% line
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# Customize the plot
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve Comparison')
plt.legend(loc="lower right")
plt.show()
# Print the AUC - ROC scores for each model
for name, score in roc_auc_scores.items():
print(f'{name}: AUC - ROC = {score:.2f}')Para cada objeto modelo, repetimos fit() y predict_proba(), calculamos el FPR y el TPR correspondientes y, a continuación, trazamos sus curvas respectivas.
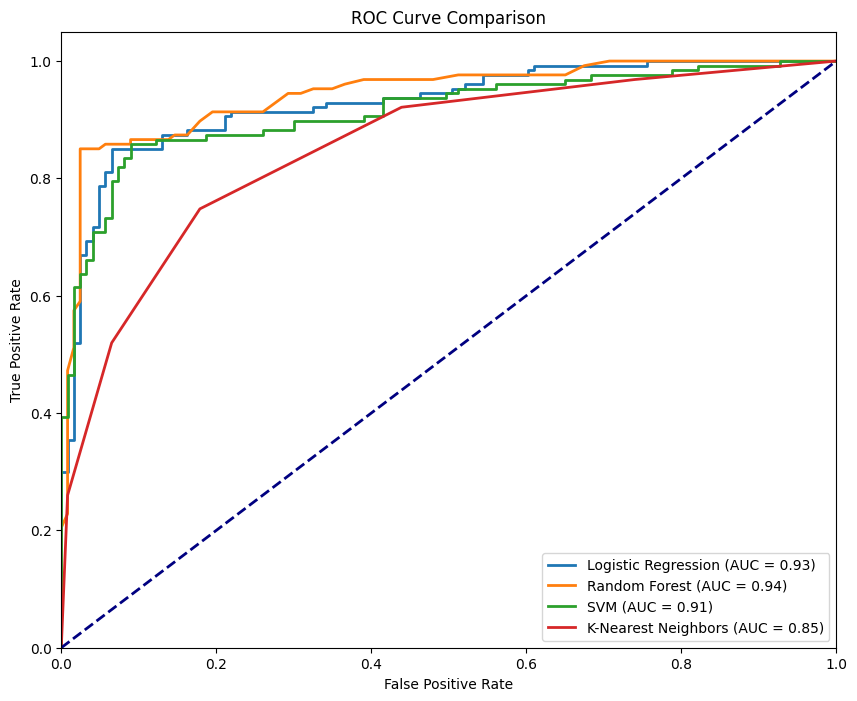
Curva ROC para diferentes modelos. Imagen del autor
La figura anterior muestra las cuatro curvas correspondientes a los cuatro clasificadores, donde el RandomForestClassifier es el que mejor funciona, con un AUC-ROC de 0,94, mientras que el KNeighborsClassifier es el que menos funciona, con un AUC-ROC de 0,85. Un modelo ideal abrazaría la esquina superior izquierda del gráfico, donde se maximiza el TPR y se minimiza el FPR. Cuanto más se acerque la curva a este punto, mejor será el rendimiento del modelo.
Desglosemos las métricas que proporciona la curva AUC-ROC y comprendamos su significado.
Los valores AUC proporcionan una referencia rápida para comprender el rendimiento del modelo. Cuando el AUC se acerca a 1, nuestro modelo está en lo más alto. Muestra un rendimiento excelente con una gran capacidad para distinguir entre clases. Un AUC en torno a 0,5 es un escenario preocupante, ya que pone de manifiesto que el modelo no obtiene mejores resultados que las conjeturas aleatorias, lo que indica que no tiene poder discriminatorio. Una puntuación AUC cercana a 0 es una situación alarmante. Esto indica que el modelo se equivoca por completo, incluso más que si lanzara una moneda al aire.
La TPR, o sensibilidad, es una métrica crítica que indica lo bien que nuestro modelo capta las instancias positivas. El TPR se calcula como la proporción de positivos reales identificados correctamente por el modelo. Es un indicador clave de la eficacia de nuestro modelo para detectar las señales verdaderas (positivas). Un TPR alto significa que nuestro modelo está haciendo un gran trabajo a la hora de reconocer lo que más importa.
Por otro lado, el FPR nos ayuda a comprender el ruido: con qué frecuencia nuestro modelo identifica falsamente los negativos como positivos. FPR es la proporción de negativos reales que nuestro modelo marca incorrectamente como positivos. Es una métrica vital para evaluar las compensaciones que hace nuestro modelo. Un FPR alto indica una tendencia a producir falsas alarmas, que pueden ser costosas según la aplicación.
La belleza y el reto de la clasificación binaria residen en la configuración de los umbrales, por lo que ajustamos con precisión la sensibilidad (TPR) y la especificidad (1 - FPR) de nuestro modelo. Podemos controlar la sensibilidad de nuestro modelo para detectar instancias de clase positivas y reducir los falsos positivos ajustando el umbral. En la mayoría de los escenarios del mundo real, el coste de los falsos negativos (omitir un positivo) frente a los falsos positivos (falsas alarmas) puede variar significativamente.
El AUC-ROC no es sólo un concepto teórico; he aquí cómo se utiliza esta métrica práctica en todos los sectores para impulsar decisiones críticas:
El AUC-ROC se utiliza para comparar diferentes pruebas diagnósticas. Es especialmente útil cuando el coste de los falsos negativos (por ejemplo, pasar por alto una enfermedad) puede ser mucho mayor que el de los falsos positivos (por ejemplo, un tratamiento innecesario). Un ejemplo digno de mención sería el cribado del cáncer, en el que el umbral para realizar más pruebas puede ajustarse en función de los factores de riesgo y de la disponibilidad de recursos.
Los modelos de aprendizaje automático se utilizan cada vez más para identificar actividades fraudulentas en el sector financiero. Teniendo en cuenta que las transacciones fraudulentas son significativamente raras, estos conjuntos de datos están muy desequilibrados. Por tanto, el AUC-ROC es una métrica de evaluación eficaz que también permite ajustar el umbral en función de diversos factores, como la magnitud del riesgo que entraña la transacción, el coste de verificar manualmente cada transacción y el coste de las molestias para el cliente.
Al igual que la detección del fraude, los ciberataques también son sucesos relativamente raros. De ahí que el AUC-ROC también encuentre aplicación en ciberseguridad, equilibrando entre detectar amenazas y evitar la fatiga de alerta por falsos positivos.
AUC-ROC es una métrica popular para evaluar modelos de clasificación binaria, pero hay escenarios en los que otras métricas alternativas pueden ser más adecuadas. Exploremos algunas alternativas y cuándo utilizarlas:
La curva precisión-recuerdo (PRC) es una métrica para conjuntos de datos desequilibrados que influye significativamente en el valor del modelo de aprendizaje automático cuando los falsos positivos y los falsos negativos tienen costes diferentes. A diferencia del AUC-ROC, que puede dar una visión engañosamente optimista en conjuntos de datos desequilibrados, el PRC se centra más en el rendimiento relativo a la clase positiva.
La puntuación F1 es la media armónica de la precisión y la recuperación, proporcionando una única métrica que equilibra ambas. Se utiliza cuando necesitamos un resumen claro, de un solo número, del rendimiento del modelo, especialmente en conjuntos de datos desequilibrados. AUC-ROC proporciona una visión más global, mientras que F1 es un punto específico de la curva PRC.
El AUC-ROC es un patrón oro en los problemas de clasificación binaria porque proporciona una visión más equilibrada del rendimiento del modelo a través de diferentes umbrales, especialmente en escenarios de desequilibrio de clases.
Creemos que la mejor forma de reforzar nuestro aprendizaje es mediante la práctica. La versatilidad de Python nos brinda la oportunidad perfecta para dominar conceptos esenciales. Tanto si estamos refrescando nuestros fundamentos como explorando temas más avanzados, ahora es el momento ideal para sumergirnos. Volvamos a los fundamentos de Python y desafiémonos a nosotros mismos trabajando con AUC-ROC en conjuntos de datos complejos.
Aprende Python y Estadística con DataCamp
programa
Curso
Curso
Tutorial
Adam Shafi
Tutorial
Moez Ali
Tutorial
Aditya Sharma
Tutorial
DataCamp Team