
Programa
Fundamentos de estatística em Python
20 h
A curva ROC oferece uma representação visual das compensações entre a taxa de verdadeiros positivos (TPR) e a taxa de falsos positivos (FPR) em vários limites. Ele fornece insights sobre como o modelo pode equilibrar as compensações entre detectar instâncias positivas e evitar falsos positivos em diferentes limites. A AUC, ou Área sob a curva, é um valor escalar único que varia de 0 a 1 e fornece um instantâneo do desempenho do modelo. Você só calcula a AUC depois de gerar a curva ROC porque a AUC representa a área abaixo da curva.
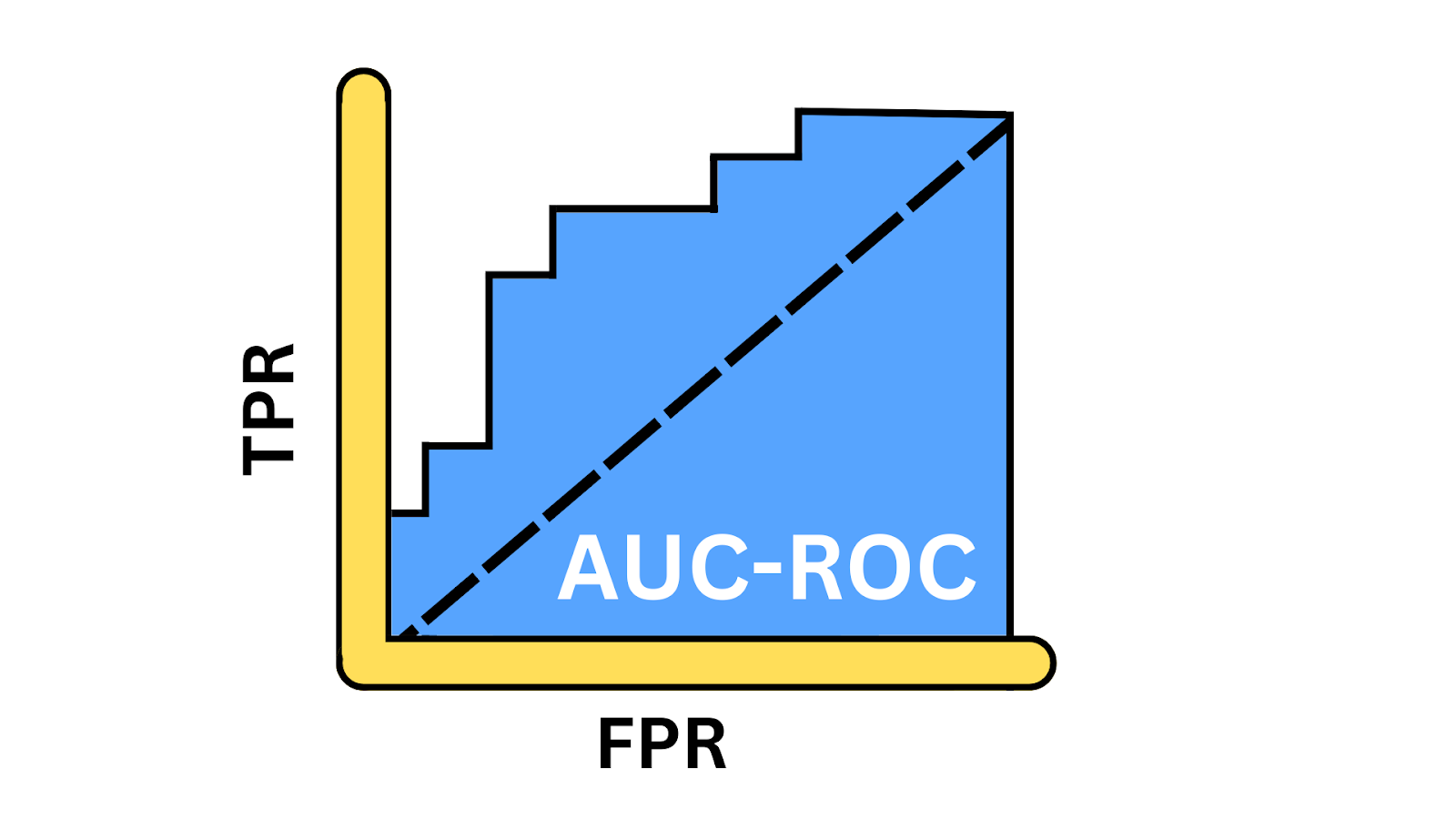
Ilustração da curva AUC-ROC. Imagem do autor
A taxa de verdadeiros positivos, também conhecida como sensibilidade ou recall, reflete a capacidade de um modelo de identificar corretamente as instâncias positivas. Ele mede a proporção de casos positivos reais que o modelo identifica com sucesso. Matematicamente, isso pode ser expresso pela equação a seguir:
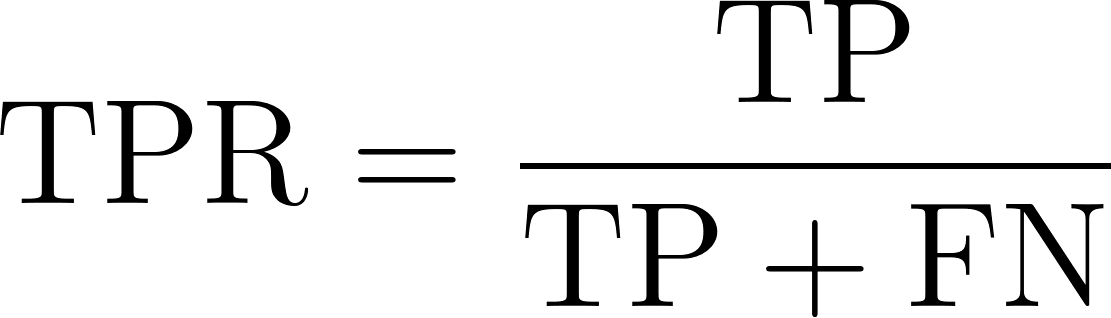
Onde:
O FPR representa a frequência com que nosso modelo classifica incorretamente as instâncias de classe negativa como positivas. Ele mede a proporção de instâncias negativas reais que são incorretamente identificadas como positivas pelo modelo, indicando a taxa de alarmes falsos. Em termos matemáticos, isso pode ser expresso da seguinte forma.

Onde:
Vamos entender os cenários em que a AUC-ROC é uma métrica mais relevante.
O AUC-ROC fornece uma medida de desempenho agregada em todos os limites de classificação possíveis. Diferentemente da exatidão, da precisão ou da pontuação F1, que dependem de um limite específico, ele considera o desempenho do modelo em diferentes pontos de operação.
O AUC-ROC é um valor escalar único que facilita a comparação de vários modelos, independentemente de seus limites de classificação. Sua natureza independente de limite faz com que seja a melhor opção para fazer uma comparação justa entre modelos com diferentes limites ideais.
A maioria dos conjuntos de dados da vida real é desequilibrada, em que uma classe é desproporcionalmente maior que a outra, por exemplo, análise de sentimentos, detecção de fraudes e detecção de câncer. Nesses cenários, métricas como a precisão fornecem uma avaliação enganosa do desempenho do modelo, pois são tendenciosas em relação à classe majoritária. Nesses cenários, métricas como AUC-ROC são mais confiáveis.
Vamos dar uma olhada em algumas das principais ideias.
Para dar vida à curva ROC, calcularemos o TPR e o FPR em vários limites. Vamos começar importando as bibliotecas necessárias para esta demonstração.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as pltEm seguida, geraremos um conjunto de dados de classificação binária usando a função make-classification(), com 1.000 amostras e 20 recursos.
# Generate a binary classification dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=0)Vamos dividir o conjunto de dados em dados de treinamento e de teste - treinaremos o modelo no conjunto de treinamento e mediremos seu desempenho no conjunto de dados de teste não visto.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)Em seguida, definimos o objeto do modelo chamando a classe LogisticRegression() e o treinamos usando o método fit nos dados de treinamento, em que X_train tem os recursos e y_train representa os rótulos.
# Train a Logistic Regression model
model = LogisticRegression()
model.fit(X_train, y_train)Agora, o modelo está treinado e pronto para gerar previsões. Chamamos a função predict_proba() para gerar a probabilidade de uma classe positiva. Usamos o método predict() para calcular métricas de avaliação, como exatidão, precisão, recall e pontuação F1.
# Predict the probabilities for the test set
y_probs = model.predict_proba(X_test)[:, 1]
# Predict the classes for the test set
y_pred = model.predict(X_test)Em seguida, calculamos e imprimimos todas essas métricas usando suas respectivas funções.
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
# Calculate other metrics
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# Print the metrics
print(f"AUC - ROC Score: {roc_auc:.2f}")
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")AUC-ROC Score: 0.93
Accuracy: 0.87
Precision: 0.87
Recall: 0.87
F1 Score: 0.87Agora, vamos visualizar a curva ROC junto com a linha diagonal que representa um modelo de chance aleatória. Para calcular isso, precisamos de FPR e TPR para cada limite discreto entre 0 e 1. No gráfico abaixo, a curva laranja representa o ROC e a área sob essa curva é de 0,93.
# Plotting the ROC Curve
fpr, tpr, thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()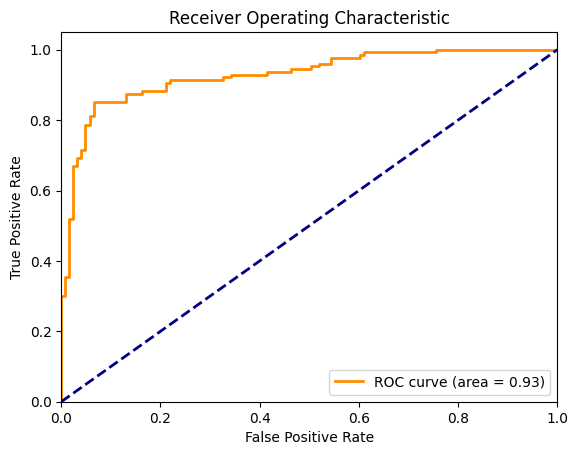
Curva ROC para regressão logística. Imagem do autor
Agora, vamos usar o mesmo conjunto de dados e comparar o desempenho de quatro algoritmos de classificação usando o ROC. Começaremos importando os sites RandomForestClassifier, KNeighborsClassifier e SVC e comparando-os com o site LogisticRegression.
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# Define the models
models = {
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"SVM": SVC(probability=True),
"K-Nearest Neighbors": KNeighborsClassifier()
}
# Initialize a dictionary to store AUC - ROC scores
roc_auc_scores = {}
# Plot the ROC curves
plt.figure(figsize=(10, 8))
for name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict the probabilities
y_probs = model.predict_proba(X_test)[:, 1]
# Calculate the AUC - ROC score
roc_auc = roc_auc_score(y_test, y_probs)
roc_auc_scores[name] = roc_auc
# Compute ROC curve
fpr, tpr, _ = roc_curve(y_test, y_probs)
# Plot ROC curve
plt.plot(fpr, tpr, lw=2, label=f'{name} (AUC = {roc_auc:.2f})')
# Plot the diagonal 50% line
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# Customize the plot
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve Comparison')
plt.legend(loc="lower right")
plt.show()
# Print the AUC - ROC scores for each model
for name, score in roc_auc_scores.items():
print(f'{name}: AUC - ROC = {score:.2f}')Para cada objeto modelo, repetimos fit() e predict_proba(), calculamos o FPR e o TPR correspondentes e, em seguida, traçamos suas respectivas curvas.
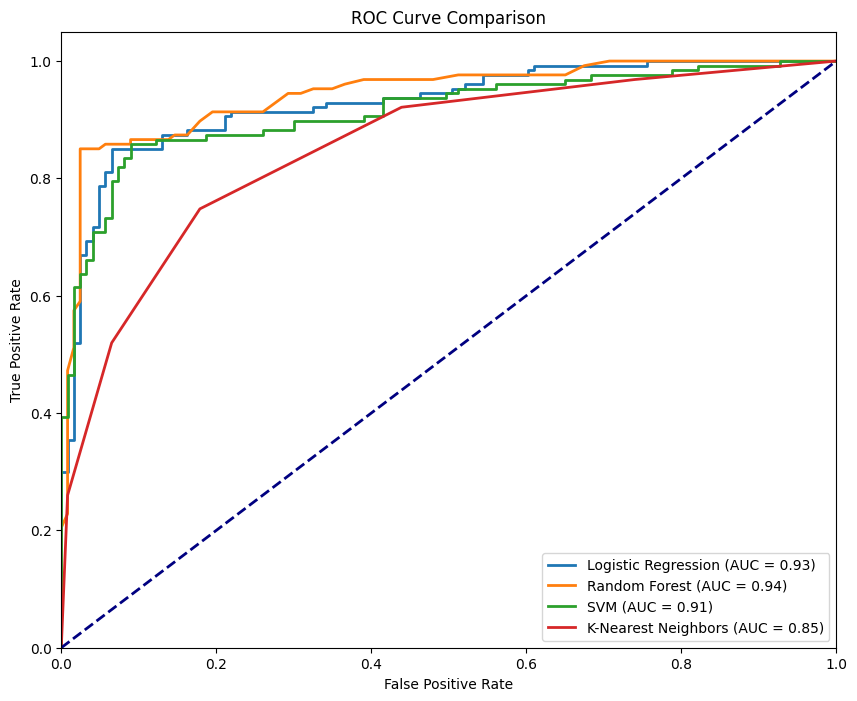
Curva ROC para diferentes modelos. Imagem do autor
A figura acima mostra todas as quatro curvas correspondentes aos quatro classificadores, onde o RandomForestClassifier tem o melhor desempenho com um AUC-ROC de 0,94, enquanto o KNeighborsClassifier tem o menor desempenho com um AUC-ROC de 0,85. Um modelo ideal abraçaria o canto superior esquerdo do gráfico, onde o TPR é maximizado e o FPR é minimizado. Quanto mais próxima a curva estiver desse ponto, melhor será o desempenho do modelo.
Vamos detalhar as métricas que a curva AUC-ROC fornece e entender sua importância.
Os valores de AUC fornecem uma referência rápida para você entender o desempenho do modelo. Quando o AUC está próximo de 1, nosso modelo está no topo de seu jogo. Ele mostra um excelente desempenho com uma forte capacidade de distinguir entre as classes. A AUC em torno de 0,5 é um cenário preocupante, pois destaca que o modelo não está se saindo melhor do que a adivinhação aleatória, indicando que não há poder discriminatório. Uma pontuação AUC próxima de 0 é uma situação alarmante. Isso indica que o modelo está totalmente errado, ainda pior do que o lançamento de uma moeda.
O TPR, ou sensibilidade, é uma métrica crítica que informa o quanto nosso modelo está capturando as instâncias positivas. O TPR é calculado como a proporção de positivos reais identificados corretamente pelo modelo. É um indicador importante da eficácia do nosso modelo na detecção de sinais verdadeiros (positivos). Um TPR alto significa que nosso modelo está fazendo um ótimo trabalho ao reconhecer o que é mais importante.
Por outro lado, o FPR nos ajuda a entender o ruído - com que frequência nosso modelo identifica falsamente os negativos como positivos. FPR é a proporção de negativos reais que nosso modelo sinaliza incorretamente como positivos. É uma métrica vital para avaliar as compensações que nosso modelo está fazendo. Um FPR alto indica uma tendência a produzir alarmes falsos, que podem ser caros, dependendo da aplicação.
A beleza e o desafio da classificação binária estão nas configurações de limite e, portanto, ajustamos a sensibilidade (TPR) e a especificidade (1 - FPR) do nosso modelo. Podemos controlar a sensibilidade do nosso modelo à detecção de instâncias de classe positivas e reduzir os falsos positivos ajustando o limite. Na maioria dos cenários do mundo real, o custo de falsos negativos (falta de um positivo) versus falsos positivos (alarmes falsos) pode variar significativamente.
A AUC-ROC não é apenas um conceito teórico; veja como essa métrica prática é usada em todos os setores para orientar decisões críticas:
O AUC-ROC é usado para comparar diferentes testes de diagnóstico. Isso é especialmente útil quando o custo de falsos negativos (por exemplo, não detectar uma doença) pode ser muito maior do que o de falsos positivos (por exemplo, tratamento desnecessário). Um exemplo digno de nota seria o rastreamento do câncer, em que o limite para testes adicionais pode ser ajustado com base em fatores de risco e disponibilidade de recursos.
Os modelos de aprendizado de máquina são cada vez mais usados para identificar atividades fraudulentas no setor financeiro. Considerando que as transações fraudulentas são significativamente raras, esses conjuntos de dados são altamente desequilibrados. Portanto, a AUC-ROC é uma métrica de avaliação eficaz que também permite ajustar o limite com base em vários fatores, como a magnitude do risco envolvido na transação, o custo da verificação manual de cada transação e o custo da inconveniência para o cliente.
Da mesma forma que a detecção de fraudes, os ataques cibernéticos também são eventos relativamente raros. Portanto, o AUC-ROC também encontra aplicação na segurança cibernética, equilibrando a detecção de ameaças e evitando a fadiga de alertas de falsos positivos.
A AUC-ROC é uma métrica popular para avaliar modelos de classificação binária, mas há cenários em que métricas alternativas podem ser mais adequadas. Vamos explorar algumas alternativas e quando você deve usá-las:
A curva de precisão-recall (PRC) é uma métrica para conjuntos de dados desequilibrados que afeta significativamente o valor do modelo de aprendizado de máquina quando falsos positivos e falsos negativos têm custos diferentes. Ao contrário do AUC-ROC, que pode dar uma visão enganosamente otimista em conjuntos de dados desequilibrados, o PRC se concentra mais no desempenho relativo à classe positiva.
A pontuação F1 é a média harmônica da precisão e da recuperação, fornecendo uma única métrica que equilibra ambas. É usado quando precisamos de um resumo claro e com um único número do desempenho do modelo, especialmente em conjuntos de dados desequilibrados. A AUC-ROC oferece uma visão mais global, enquanto a F1 é um ponto específico na curva PRC.
O AUC-ROC é um padrão ouro em problemas de classificação binária porque oferece uma visão mais equilibrada do desempenho do modelo em diferentes limites, especialmente em cenários de desequilíbrio de classes.
Acreditamos que a melhor maneira de reforçar nosso aprendizado é por meio da prática. A versatilidade do Python nos dá a oportunidade perfeita para dominar conceitos essenciais. Quer estejamos atualizando nossos fundamentos ou explorando tópicos mais avançados, agora é o momento ideal para você mergulhar de cabeça. Vamos revisitar nossos conceitos básicos de Python e nos desafiar trabalhando com o AUC-ROC em conjuntos de dados complexos.
Aprenda Python e Estatística com o DataCamp
Programa
Curso
Curso
Tutorial
Aditya Sharma
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Avinash Navlani

