
Kurs
KI-Agenten mit dem Google ADK entwickeln
1 Std.
6.5K
Die Live-Demo von ChatGPT Agent war echt beeindruckend: im Internet nach Geschenken suchen, Reisen buchen, Präsentationen erstellen. Der Ankündigungspost zeigte beeindruckende Benchmark-Ergebnisse, die darauf hindeuten, dass der Agent komplexe reale Aufgaben bewältigen kann.
Aber Live-Demos zeigen immer sorgfältig ausgewählte Beispiele, und Benchmarks erfassen nicht die komplexe Realität der täglichen Arbeitsabläufe, die der Agent laut OpenAI lösen kann.
Also habe ich den Agenten fünf anspruchsvollen Tests unterzogen, die echte Arbeitssituationen widerspiegeln – Aufgaben, bei denen mehrere Browser-Tabs gleichzeitig geöffnet sein müssen, Infos von verschiedenen Websites abgeglichen werden müssen und Ergebnisse geliefert werden müssen, die ich auch wirklich gebrauchen kann. Dieser Artikel zeigt, was passiert, wenn Marketingversprechen auf die Praxis treffen.
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter„The Median “ schicken , der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
ChatGPT Agent ist die neueste Premium-Funktion von OpenAI für Nutzer der Versionen Plus, Pro und Enterprise. Es vereint drei Tools, die früher separat funktioniert haben: Tiefgehende Forschung, Operator und die Kernlogik des Sprachmodells. Der große Unterschied? Der Agent kriegt seinen eigenen virtuellen Computer zum Arbeiten.
Das ist wichtig, weil die alte Konfiguration Probleme hatte. Der Modus „Deep Research“ war super zum Analysieren, aber man konnte nichts anklicken. Der Bediener konnte zwar auf Websites navigieren, aber ihm fehlte die Denkfähigkeit, die für gründliche Recherchen so wichtig ist. Der Agent macht das klar, indem er beide Fähigkeiten an einem Ort zusammenfasst.
Du findest den Agenten als weitere Option in deiner Chat-Symbolleiste. Aber anders als das normale ChatGPT läuft es auf einem virtuellen Computer mit vollen Rechten für:
Dank der virtuellen Computerkonfiguration kann der Agent jetzt Sachen machen, die vorher nicht möglich waren.
Als ich es mit einer Bildungsaufgabe der UNESCO ausprobiert habe, habe ich 14 Minuten lang zugeschaut, wie es funktioniert hat. Das war die Eingabeaufforderung (die ChatGPT selbst bei meiner ersten Interaktion mit dem Agenten vorgeschlagen hat):
Pull the latest available data from the UNESCO Institute for Statistics on national student-teacher ratios and total teaching staff counts for primary and secondary education.
Create a spreadsheet with two tabs: one for primary education and one for secondary.
Each should include country name, student-teacher ratio, total number of teachers, gross enrollment, and year of reporting.
Add a summary tab highlighting the countries with the most strained and most favorable ratios, sorted accordingly.
Ensure consistent country naming across tabs.Hier ist, was es während der Ausführung der Eingabeaufforderung verarbeiten konnte:
Ich habe sowohl dem Agenten als auch o3-pro die gleiche knifflige Aufgabe gegeben: UNESCO-Daten zum Verhältnis von Schülern zu Lehrern rausholen und eine formatierte Tabelle mit mehreren Registerkarten erstellen. Die Ergebnisse zeigten deutliche Unterschiede.
Der Agent hat 14 Minuten gearbeitet und eine Tabelle mit 222 Ländern geliefert. Eine Anforderung wurde nicht erfüllt (die Registerkarte „Zusammenfassung“ mit den besten/schlechtesten Verhältnissen) und die Liste wurde alphabetisch statt nach Verhältnissen sortiert. Das könnte Kontextüberladung – das heißt, das Modell vergisst beim Bearbeiten einer langen Aufgabe die ursprünglichen Details.
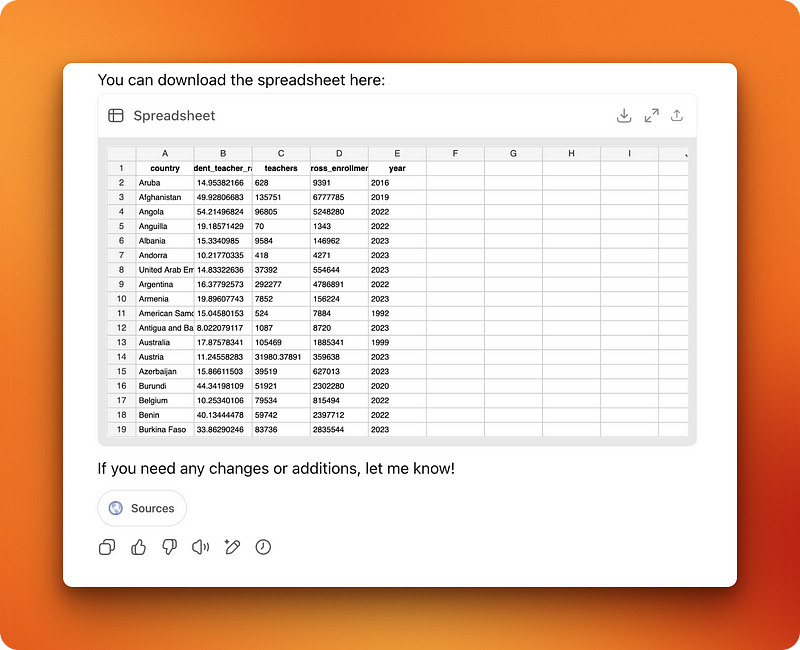
Andererseits hat o3-pro 18 Minuten gebraucht, um das Problem zu durchdenken. Dann stieß es auf Hindernisse, die der Agent vorher automatisch gelöst hatte. Da o3-pro keine Dateien runterladen kann, musste ich zwei Ressourcen manuell runterladen, entpacken und ein Python-Skript ausführen, das es geschrieben hat. Ich hab das Skript nicht getestet, aber es war klar, dass diese Methode mindestens 10 Minuten mehr Zeit in meinen Arbeitsablauf bringen würde.
Wenn der Agent läuft, kannst du alles in Echtzeit beobachten. Du kannst jederzeit die Kontrolle über den Browser übernehmen, aber für Aufgaben ohne sensible Daten oder Interaktionen funktioniert er auch alleine einwandfrei.
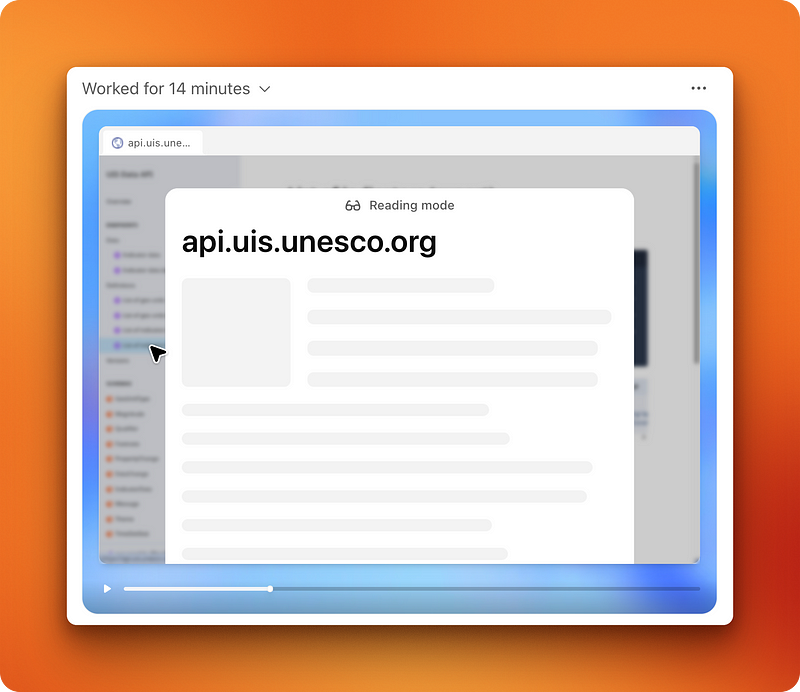
Wenn der Agent fertig ist, kannst du auf zwei Arten überprüfen, was passiert ist. Es gibt eine komplette Videoaufnahme, die du anhalten und wieder abspielen kannst (nach dem ersten Reiz ist das aber ziemlich langweilig). Dazu gibt's eine detaillierte Zeitleiste mit den Gründen für jeden Schritt, den tatsächlich ausgeführten Befehlen und den durchgeführten Dateioperationen.
Das Coole daran? Sobald der Agent eine Aufgabe erledigt hat, kannst du im normalen Chat-Modus Folgefragen stellen. Es merkt sich alles, was es gelernt hat, und kann auf die gesammelten Daten zugreifen.
Die erste Forschungsaufgabe hat gezeigt, dass der Agent komplexe Daten sammeln kann. Aber ich musste noch was anderes ausprobieren – Aufgaben, bei denen man ständig mit der Maus auf Webseiten rumklicken muss. Sonst würde ich bei meinen Tastaturkürzeln bleiben und alles selbst machen.
Mir fiel sofort ein, dass ich Figuren und Diagramme erstellen könnte. Ich mache das oft für Blogbeiträge, daher schien es mir ein guter Testfall zu sein.
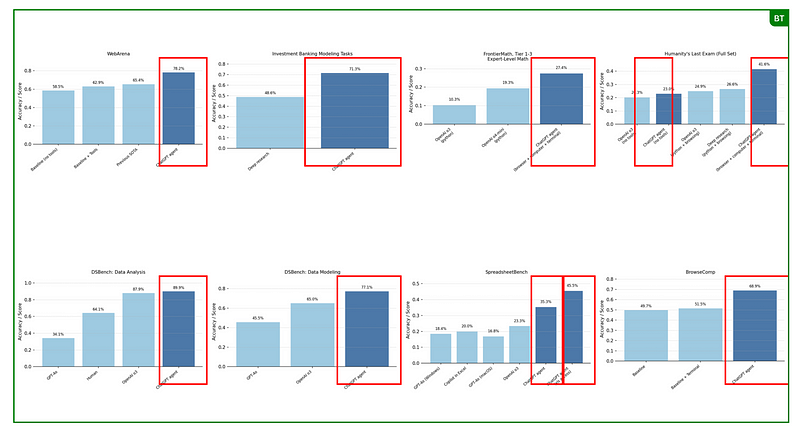
Während ich für diesen Artikel recherchiert habe, habe ich den Beitrag von OpenAI gelesen, in dem sie die Veröffentlichung von „ den Ankündigungspost von OpenAI über ChatGPT Agent. Der Beitrag hat 6–7 Bilder mit Benchmark-Ergebnissen, die zeigen, wie gut der Agent abschneidet. Anstatt jeden Benchmark einzeln aufzulisten, habe ich den Agenten gebeten, eine Collage zu erstellen, die ich diesem Blogbeitrag hinzufügen kann.
I want you to open the following link, combine all benchmark results' images into a single collage and highlight the columns where ChatGPT's agent results are given.
<link>
https://openai.com/index/introducing-chatgpt-agent/
</link>Ich wollte einfach nur alle Benchmark-Diagramme von der Webseite holen, sie nebeneinander in Zeilen anordnen und rote Rechtecke um die Spalten mit der Leistung von Agent ziehen. Für jeden, der Canva mal so zum Spaß benutzt, dauert das nur ein paar Minuten: Bilder raussuchen, anordnen, ein paar Rechtecke zeichnen.
Für ein KI-Programm ist das aber ziemlich kompliziert und man muss viel mit der Maus rumhantieren. Der Agent hat 9 Minuten gebraucht und dann was echt Enttäuschendes geliefert.
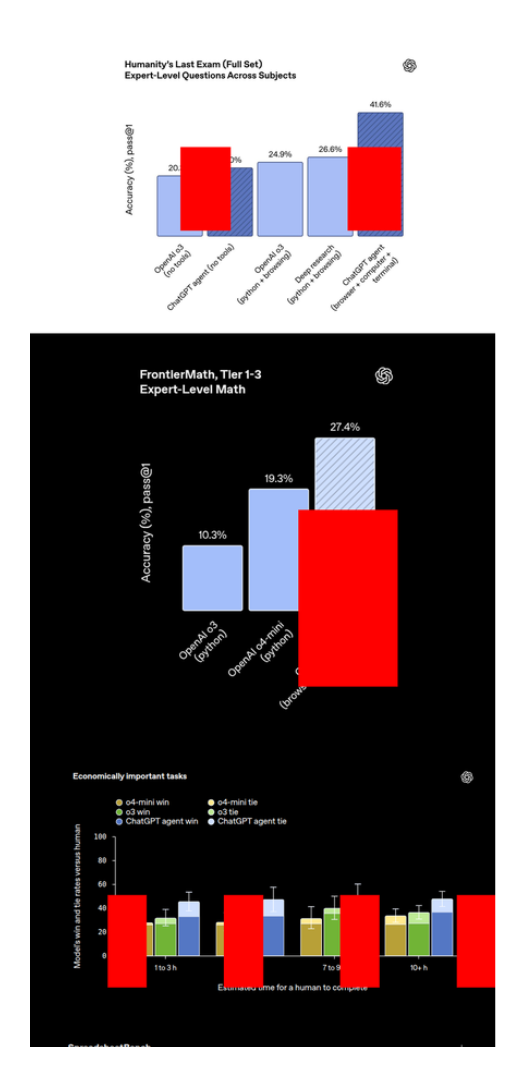
Das Bild war komplett auf die Höhe ausgerichtet, statt wie erwartet in einem Raster. Die roten Rechtecke waren keine sauberen Umrisse, sondern ausgefüllte Formen, die über die ganzen Bilder verteilt waren. Noch schlimmer war, dass es auf ganz andere Websites gewandert war und Benchmark-Ergebnisse von irgendwelchen Seiten gezogen hatte, statt von dem Beitrag, den ich angegeben hatte.
Es hat auch Canva komplett ignoriert, obwohl ich es mit meinem Konto verbunden hatte.
Ich hab einen neuen Thread mit genaueren Anweisungen gestartet:
I want you to open the following webpage where you will find a bunch of benchmark results given in the form of images on the performance of ChatGPT Agent. Your task is to combine all those images given in the webpage (ONLY IN THAT WEBPAGE, DON'T SEARCH FOR ADDITIONAL INFORMATION) into a single collage where you organize the images side-by-side in rows. Afterward, highlight the columns where ChatGPT Agent's performance is shown with a red rectangle. Use Canva to do this task
<link>
https://openai.com/index/introducing-chatgpt-agent/
</link>Zuerst hat der Agent beim Versuch, den Ankündigungsbeitrag zu lesen, ein CAPTCHA getroffen. Ich musste selbst die Kontrolle übernehmen und die Bilder der Fußgängerüberwege aussuchen. Dann hat es 18 Minuten lang funktioniert, bevor es mich aufgefordert hat, mich bei Canva anzumelden.
Die Anmeldung hat nicht so gut geklappt. Der virtuelle Computer und der Browser hängen – ganz anders als die schnelle Reaktion, die du beim Einloggen auf Websites erwartest. Tastenkombinationen wie Cmd + V zum Einfügen von Passwörtern brauchen länger, bis sie funktionieren.
Nachdem ich Agent bei Canva angemeldet hatte, ging es wieder an die Arbeit mit der Benutzeroberfläche.
Nachdem ich 8 Minuten lang zugesehen hatte, wie er ratlos herumfummelte, musste ich eingreifen. Der Agent hat versucht, die Bilder mit den Benchmark-Ergebnissen einzeln von Hand zu zeichnen, anstatt die tatsächlich heruntergeladenen Bilder zu verwenden.
Ich hab noch mal nachgefragt:
No, you are going in the wrong direction on Canva.
What I meant was that after you grabbed the benchmark results' images, paste them into canva and organize them one-by-one into a 16:9 collage with ChatGPT Agent's performance highlighted with a red rectangleDer Agent hat es diesmal verstanden, aber es war klar, dass er nicht wirklich wusste, wie er die Aufgabe erledigen sollte.
Es hat echt etwas gedauert, den Ankündigungsbeitrag nochmal zu lesen und die Benchmark-Bilder runterzuladen. Der Download war echt nervig langsam – der Agent war sich nicht sicher, ob er „Bildlink kopieren“, „Bild speichern“ oder andere Optionen im Rechtsklick-Menü nehmen sollte oder lieber den „Bild herunterladen“-Button oben rechts.
Nachdem die Bilder endlich auf Canva hochgeladen waren, fing der Agent mit der eigentlichen Layoutarbeit an. Das hat gezeigt, wie schlecht die räumliche Kontrolle wirklich ist. Zu sehen, wie es versuchte, Bilder an die richtige Stelle zu ziehen, war wie einem Kind beim Arbeiten am Computer zuzuschauen. Es gab immer wieder Probleme mit der Ausrichtung und der natürlichen Position der Elemente.
Ein weiteres Problem tauchte auf, als der Agent versuchte, Rechtecke um die Benchmark-Balken zu zeichnen. Für uns ist das ganz einfach – mit einer sanften Mausbewegung zeichnest du ein Rechteck. Für den Agenten war das echt 'ne schwierige Aufgabe. Da es keine räumliche und visuelle Designintelligenz hat, hat es Python-Skripte und OCR verwendet, um zu erkennen, welche Balken die Leistung des Agenten anzeigen, und dann die genauen Koordinaten für die Platzierung der Rechtecke berechnet.
Der ganze Vorgang hat über 75 Minuten gedauert, inklusive allem Hin und Her. Der Agent hat mir in meinem Canva-Konto eine „Untitled Design Page 2” (Unbenannte Designseite 2) hinterlassen.
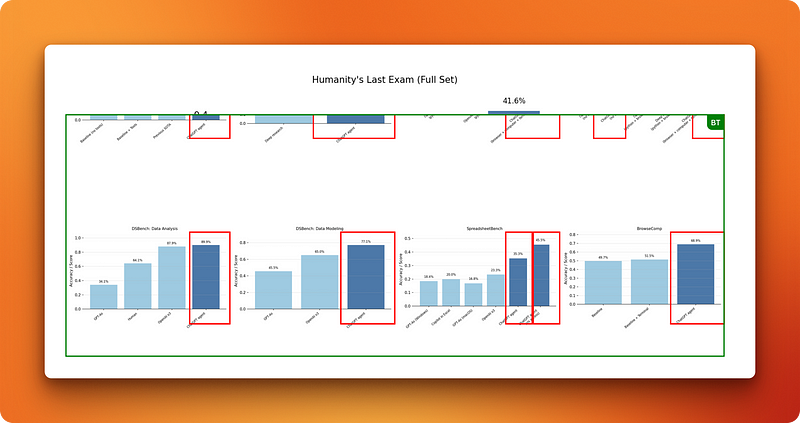
Das Bild sah abgeschnitten aus, weil der Agent versucht hatte, ein Titeltextelement hinzuzufügen, wodurch der obere Teil irgendwie ausgeblendet wurde. Nach ein paar manuellen Größenänderungen hatte ich eine funktionierende Collage, die aber immer noch ziemlich grob war, verglichen mit dem, was selbst ein unerfahrener Designer in wenigen Minuten hinbekommen würde.
Der Zeitaufwand hat sich für die Qualität echt nicht gelohnt. Um die Sache noch schlimmer zu machen, habe ich später herausgefunden, dass der Agent die Rechteck-Werkzeuge von Canva gar nicht benutzt hatte – er hatte die Rechtecke in Python gezeichnet und dann das bearbeitete Bild in Canva hochgeladen. Das hieß, dass ich diese schrägen Rechtecke später nicht mehr manuell anpassen oder verschieben konnte.
Da wurde mir klar, dass ich dem Agenten eine zu komplizierte Aufgabe gegeben hatte. Die Collage war echt kompliziert – Web-Scraping, räumliches Denken, mehrere Bilder bearbeiten und dazu noch präzise Designarbeit, alles auf einmal.
Also hab ich was Einfacheres probiert: Cover-Bilder für Blog-Beiträge erstellen. Das ist echt eine Aufgabe, die ich nicht so gerne mache. Wenn der Agent das übernehmen könnte, wäre das echt super.
Ich hab die Anforderungen einfach gehalten: „Ich schreibe gerade ein Tutorial über den neuen Agent-Modus von ChatGPT. Deine Aufgabe ist es, ein Coverbild im Format 16:9 mit den Markenfarben von DataCamp für das Tutorial zu erstellen. Es muss das Stichwort „ChatGPT Agent” und alle Roboterfiguren enthalten, die du neben diesem Stichwort findest. Benutz Canva, um diese Aufgabe zu erledigen.
Dieses Mal hatte ich viel bessere Ergebnisse. Der Agent hat die Farben von DataCamp richtig rausgesucht und die beiden Elemente nebeneinander in Canva eingefügt. Die Ausrichtung der Elemente war immer noch nicht ganz richtig – Text und Bilder waren nicht perfekt zueinander ausgerichtet –, aber wenigstens wurden echte Canva-Elemente verwendet.

Das heißt, ich musste kein fertiges Design hochladen, sondern konnte die Elemente einfach selbst an die richtige Stelle ziehen. Ein paar schnelle Änderungen und schon hatte ich ein brauchbares Titelbild.
Ein cooles Detail: Obwohl ich mich während der letzten komplizierten Aufgabe in einem anderen Chat-Thread von „ “ bei Canva angemeldet hatte , musste ich mich hier nicht nochmal einloggen. Der virtuelle Computer speichert anscheinend den Browserverlauf, Cookies und Anmeldedaten über mehrere Sitzungen hinweg. Das ist praktisch für Arbeitsabläufe, aber wichtig zu wissen, wenn du nicht willst, dass ChatGPT diese Infos speichert – dann musst du sie manuell löschen.
Dieses Mal habe ich beschlossen, den Agenten an etwas zu testen, womit ich in der Vergangenheit Probleme hatte. Ich bin ein AFOL (erwachsener Lego-Fan) und vor ein paar Monaten habe ich ChatGPT gebeten, eine CSV-Datei für ein 10.000-teiliges Lego Technic Starter-Großpackung mit dem Modell o3 zu erstellen.
Die Erstellung langer CSV-Dateien ist für LLMs schwierig, weil es zu viele kleine Details gibt, die man im Auge behalten muss. Als dann eine CSV-Datei mit mindestens 50 verschiedenen Teilen, deren IDs, Namen und Beträgen erstellt wurde, stellte ich fest, dass es bei bestimmten Teil-IDs trotz Zugriff auf die Websuche zu vielen Fehlern kam.
Meine Recherche endete hier, weil ich nicht die Geduld hatte, jede Teilnummer doppelt zu checken und sicherzustellen, dass die Nummern auch wirklich existieren und mit den Teilen übereinstimmen, die o3 auf BrickLink, einem offiziellen Marktplatz für Lego-Teile und -Sets, kaufen wollte.
Aber jetzt, wo ich den Agent hatte, der das doppelte Durchsuchen für mich übernehmen konnte, bat ich o3 noch mal um eine CSV-Datei, aber der Einfachheit halber für eine kleinere Sammlung mit 3.000 Stücken:
I want you to generate me a 3000-piece bulk pack for getting started with Lego Technic.
I am interested in building cars and motorized mechanisms as a hobby.
The bulk pack you generate must be saved to a CSV file with the following columns:
- Part ID
- Part name
- Amount
Use the official part IDs and names so that when I upload the CSV to bricklink, I can place an order with a single clickDas Model hat 5 Minuten nachgedacht und mir dann die CSV-Datei gegeben. Dann bin ich zu einem neuen Thread gewechselt (weil sich herausstellte, dass der Agent-Modus deaktiviert wird, wenn die erste Eingabeaufforderung in einem Chat-Thread nicht für den Agenten bestimmt ist).
Ich hab die Datei hochgeladen und das hier eingegeben:
I attached a 3,000-piece Lego Technic starter pack list. Your task is to double-check that each part listed in the list actually exists and that part IDs actually match part names. You must use BrickLink website (only BrickLink) as a single source of truth.
If certain part IDs or names are incorrect, correct them. Afterward, create a wishlist on BrickLink that will allow me to one-click order them later. When creating the wishlist, ask me to log in to BrickLink and I will do that for you.
Der Agent ging los. Nach 5 Minuten auf der BrickLink-Website hat es drei Teile gefunden, die anders benannt waren, und hat sie korrigiert. Genau diese nervige Überprüfungsarbeit wollte ich mir sparen.
Dann wurde ich aufgefordert, mich einzuloggen, um eine Wunschliste unter meinem Konto zu erstellen. Ich hab mich mit meinen Zugangsdaten angemeldet und der Agent hat die Kontrolle übernommen, um eine Wunschliste zu erstellen.
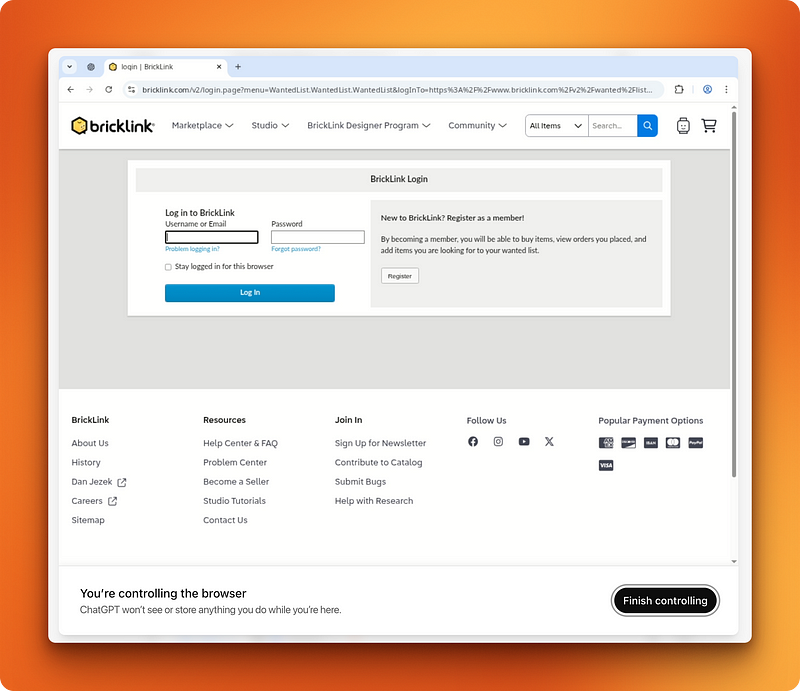
Bevor ich auf den letzten Button „Wunschliste erstellen“ geklickt habe, wurde ich zur Bestätigung aufgefordert, wie es vor so wichtigen Schritten üblich ist. Ich hab mit Ja geantwortet, und genau da ist der Arbeitsablauf abgestürzt.
Der Agent meinte, die Wunschliste sei erstellt worden, aber als ich in mein Konto schaute, war nichts zu finden. Eigentlich sollte der letzte Button „Wunschliste erstellen“ gedrückt und dann die CSV-Datei hochgeladen werden, um die Aufgabe abzuschließen. Der letzte Teil wurde aber weggelassen.
Aber klar, der schwierige Teil – also die eigentliche Recherche, bei der man immer wieder von CSV zu BrickLink und dann wieder zurück musste – wurde vom Agenten richtig gemacht. Es hat Dutzende von Teil-IDs überprüft, die Namensinkonsistenzen gefunden und behoben. Das hat mir stundenlanges manuelles Nachschlagen erspart.
Der Fehler ist ganz am Ende bei der Erstellung der Wunschliste aufgetreten, wahrscheinlich weil der Agent den mehrstufigen Upload-Prozess von BrickLink nicht richtig verstanden hat. Auch wenn es nervig war, haben wir das Wichtigste geschafft: Jetzt hatte ich eine geprüfte CSV-Datei mit den richtigen Teil-IDs, die ich selbst manuell auf BrickLink hochladen konnte.
Zum Schluss wollte ich die PowerPoint-Funktionen des Agenten testen, weil in der Ankündigung die Erstellung von Präsentationen als eine der praktischen Anwendungen des Agenten genannt wurde. PowerPoint vermeide ich um jeden Preis und benutze Gamma, wenn ich eine Präsentation machen muss.
Jetzt wollte ich mal sehen, ob der Agent mit Gamma mithalten kann. Das war meine Vorgabe:
I want you to build me a presentation pitch deck for convincing existing Manus users to the newly released ChatGPT Agent.
Here is the announcement post that you can use for information: https://openai.com/index/introducing-chatgpt-agent/Der Agent hat gleich nachgehakt:
Do you have any specific preferences for slide count, visual style, or key points you'd like emphasized?Darauf hab ich geantwortet:
Yes, keep it to 10 slides max, use a minimalistic white, black and red (gradients are allowed) for the style.
If possible, look for direct comparisons between Manus and ChatGPT AgentDer Agent hat 13 Minuten lang an der Präsentation gearbeitet. Interessanterweise wurde dafür nicht Google Slides verwendet, sondern das Terminal, um eine Kombination aus Python- und JavaScript-Code auszuführen!
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
