


Lernpfad
ChatGPT-Grundlagen
3 Std.
Benutze die OpenAI API und mehr!
o3 ist OpenAIs neuestes Grenzmodell, das entwickelt wurde, um die Denkfähigkeiten bei einer Reihe komplexer Aufgaben wie Programmierung, Mathematik, Wissenschaft und visuelle Wahrnehmung zu verbessern.
Das o3-Schlussfolgermodell ist das erste Schlussfolgermodellmit Zugriff auf die autonome Werkzeugnutzung. Das bedeutet, dass o3 die Suche, Python, Bilderzeugung und Interpretation nutzen kann, um seine Aufgaben zu erfüllen.
Dies hat sich in einer starken Leistung bei anspruchsvollen Benchmarks niedergeschlagen, die das Lösen von Problemen in der realen Welt testen, bei denen frühere Modelle Schwierigkeiten hatten. OpenAI hebt die Verbesserungen von o3 gegenüber o1 hervor und bezeichnet es als das bisher leistungsfähigste und vielseitigste Modell.
o3 baut direkt auf dem Fundament von o1 auf, aber die Verbesserungen sind in wichtigen Bereichen erheblich. OpenAI hat o3 als ein Modell positioniert, das für komplexere Denkaufgaben entwickelt wurde, was sich in den Benchmarks widerspiegelt.
Bei der Prüfung von Software-Engineering-Aufgaben erreichte o3 eine Genauigkeit von 69,1 % beim SWE-Bench Verified Software Engineering Benchmark, was eine deutliche Verbesserung gegenüber o1 (48,9 %) ist.
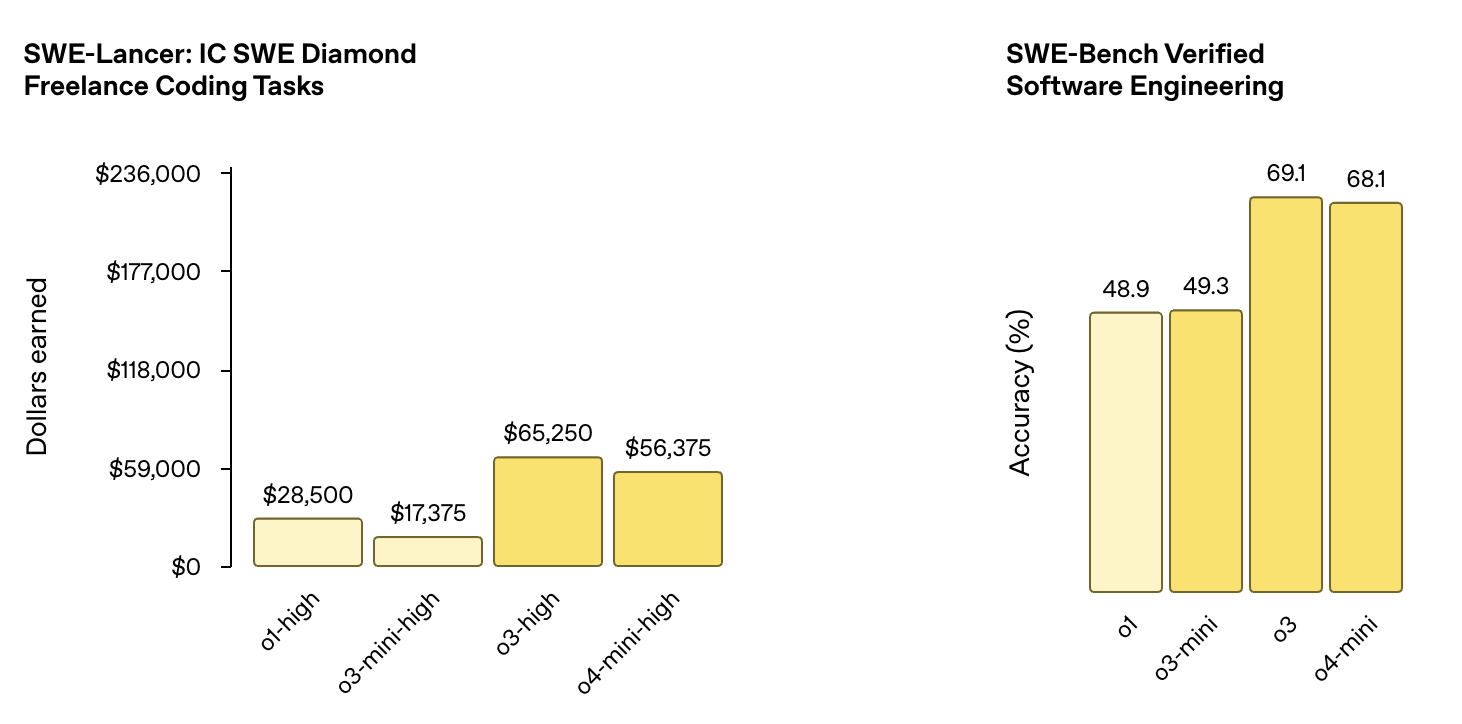
Quelle: OpenAI
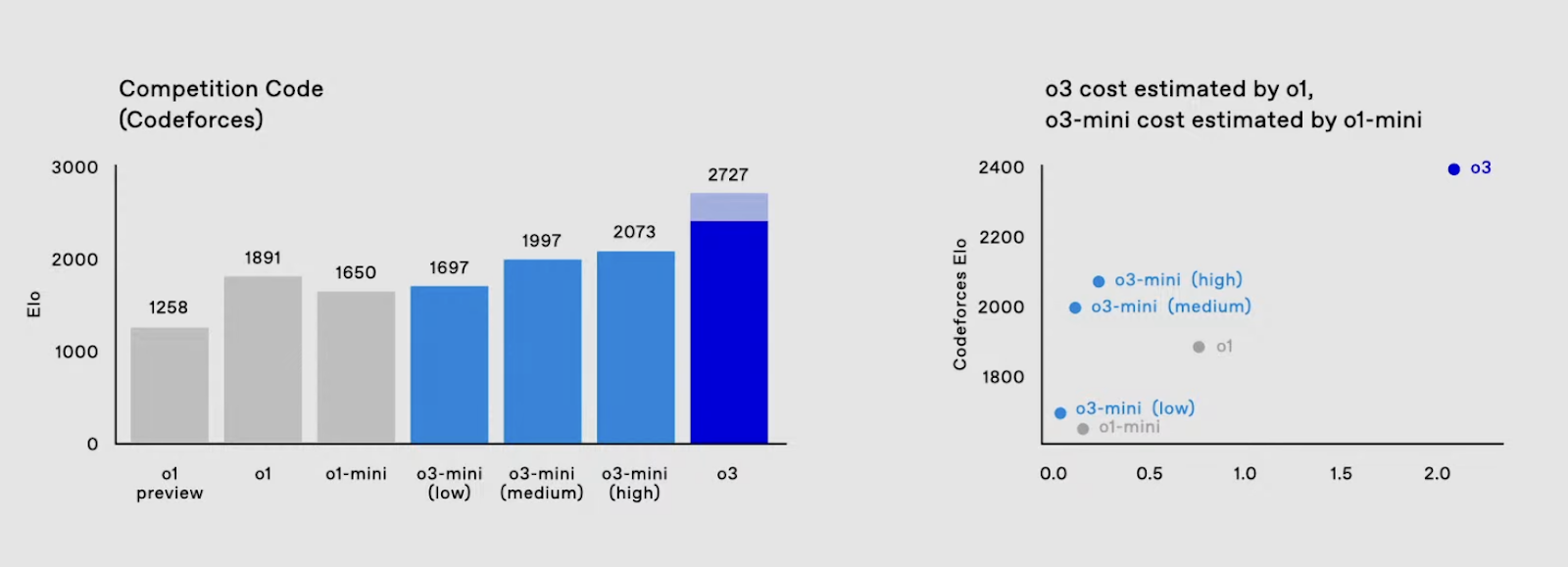
Auch bei der Wettbewerbsprogrammierung erreichte o3 eine ELO-Punktzahl von 2706 und übertraf damit den bisherigen Höchstwert von o1 (1891) bei weitem. Außerdem schneidet o3 bei den Code-Editing-Benchmarks deutlich besser ab. Beim Aider Polyglot Code Editing Benchmark übertrifft die o3-Variante die o1-Variante auf ganzer Linie.
Quelle: OpenAI
Die Verbesserungen beschränken sich nicht nur auf das Programmieren. o3 schneidet auch im mathematischen Denken besser ab und erreicht beim AIME 2024 eine Genauigkeit von 91,6 % im Vergleich zu 74,3 % bei o1. Auf dem AIME 2025 hat sie außerdem 88,9 % erreicht. Diese Fortschritte deuten darauf hin, dass das Modell differenziertere und schwierigere Probleme bewältigen kann und sich damit den Benchmarks annähert, die traditionell von menschlichen Experten dominiert werden.
Quelle: OpenAI
Ähnlich deutlich ist der Sprung bei den naturwissenschaftlichen Benchmarks. Beim GPQA Diamond, der die Leistung bei wissenschaftlichen Fragen auf PhD-Niveau misst, erreichte o3 eine Genauigkeit von 83,3 %, gegenüber 78 % bei o1. Diese Fortschritte zeigen, dass das Modell die Fähigkeit, technisch anspruchsvolle Probleme zu lösen, in allen Disziplinen verbessert hat.
Quelle: OpenAI
Einer der auffälligsten Aspekte des neuen o3-Modells ist seine Fähigkeit, Bilder direkt in seine Denkkette einzubeziehen. Das bedeutet, dass o3 beim Lösen von Problemen visuelles und textuelles Denken kombinieren kann, was sich in der Leistung von o3 bei verschiedenen Benchmarks zum visuellen Denken widerspiegelt.
Quelle: OpenAI
So übertrifft o3 o1 bei einer Reihe von Benchmarks zum visuellen Denken, darunter der MMMU College-Level Benchmark zum visuellen Problemlösen (82,9 % gegenüber 77,6 % bei o1), der MathVista Visual Math Reasoning Benchmark (86,8 % gegenüber 71,8 % bei o1) und der CharXiv-Reasoning Scientific Figure Reasoning Benchmark (78,6 % gegenüber 55,1 % bei o1).
Quelle: OpenAI
Ein Bereich, in dem die Fortschritte von o3 besonders bemerkenswert sind, ist der EpochAI Frontier Math Benchmark.
Er gilt als einer der anspruchsvollsten Benchmarks in der KI, weil er aus neuartigen, unveröffentlichten Problemen besteht, die absichtlich so gestaltet sind, dass sie viel schwieriger sind als Standarddatensätze. Viele dieser Probleme sind auf dem Niveau der mathematischen Forschung und erfordern oft Stunden oder sogar Tage von professionellen Mathematikern, um ein einziges Problem zu lösen. Aktuelle KI-Systeme erreichen bei diesem Benchmark in der Regel weniger als 2 %, was seine Schwierigkeit unterstreicht.
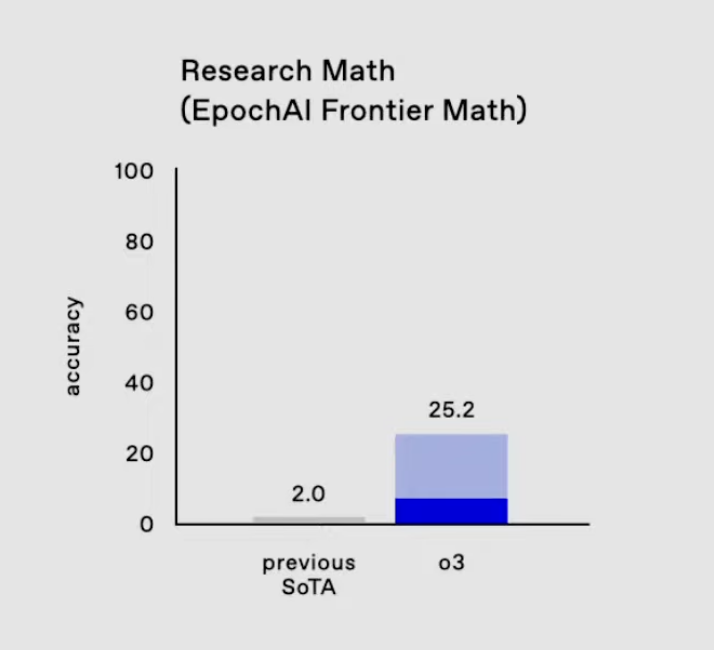
O3 auf EpochAI Frontier Math. Quelle: OpenAI
Epic AI's Frontier Math ist wichtig, weil es die Modelle über das Auswendiglernen oder die Optimierung von bekannten Mustern hinausbringt. Stattdessen wird ihre Fähigkeit getestet, zu verallgemeinern, abstrakt zu denken und Probleme zu lösen, mit denen sie noch nie in Berührung gekommen sind - Eigenschaften, die für die Weiterentwicklung der KI-Fähigkeiten unerlässlich sind. o3s Ergebnis von 25,2 % bei diesem Benchmark ist ein Sprung über den bisherigen Stand der Technik. .
Einer der bemerkenswertesten Erfolge von o3 ist seine Leistung beim ARC AGI Benchmark, einem Test, der weithin als Goldstandard für die Bewertung der allgemeinen Intelligenz in der KI gilt.
Das 2019 von François Chollet entwickelte ARC (Abstraction and Reasoning Corpus) konzentriert sich darauf, die Fähigkeit einer KI zu bewerten, neue Fähigkeiten aus minimalen Beispielen zu lernen und zu verallgemeinern. Im Gegensatz zu herkömmlichen Benchmarks, die oft vortrainiertes Wissen oder Mustererkennung testen, sind die ARC-Aufgaben so konzipiert, dass sie die Modelle herausfordern, Regeln und Transformationen im Handumdrehen abzuleiten - Aufgaben, die Menschen intuitiv lösen können, mit denen sich die KI aber bisher schwer getan hat.
Was ARC AGI besonders schwierig macht, ist die Tatsache, dass jede Aufgabe unterschiedliche logische Fähigkeiten erfordert. Die Modelle können sich nicht auf auswendig gelernte Lösungen oder Vorlagen verlassen, sondern müssen sich bei jeder Prüfung auf völlig neue Herausforderungen einstellen. Bei einer Aufgabe könnte es zum Beispiel darum gehen, Muster in geometrischen Transformationen zu erkennen, während bei einer anderen Aufgabe Schlussfolgerungen über Zahlenfolgen gezogen werden müssen. Diese Vielfalt macht ARC AGI zu einem starken Maßstab dafür, wie gut eine KI wirklich wie ein Mensch denken und lernen kann.
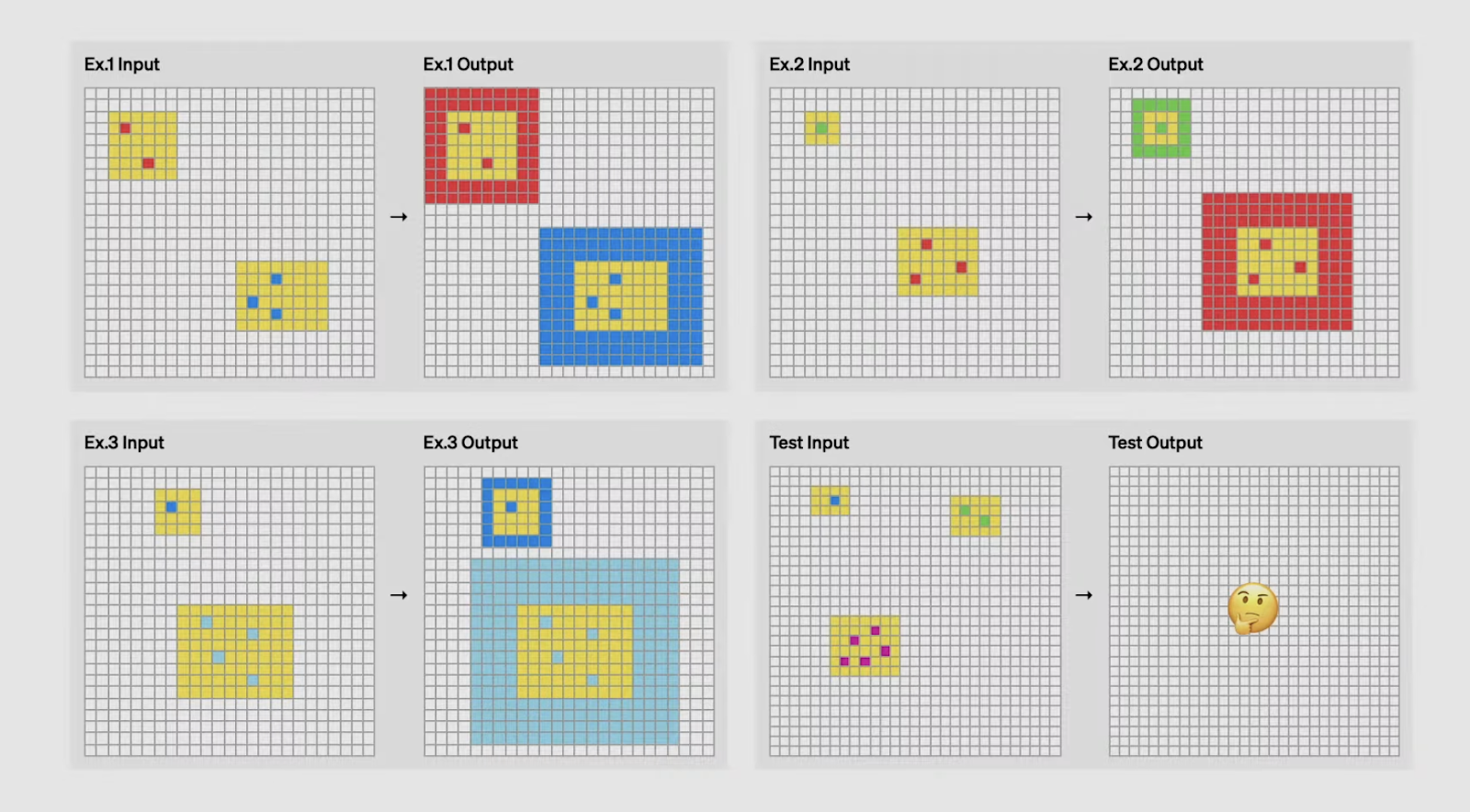
Kannst du die Logik erraten, mit der die Eingabe in eine Ausgabe umgewandelt wird? Quelle: OpenAI
Die Leistung von o3 bei ARC AGI ist ein wichtiger Meilenstein. Bei niedrigen Recheneinstellungen erreichte o3 76 % im halbprivaten Holdout-Set - ein Wert, der weit über dem aller vorherigen Modelle liegt.
Bei Tests mit hohen Recheneinstellungen erreichte er sogar noch beeindruckendere 88 % und übertraf damit die 85 %-Schwelle, die oft als Leistung auf menschlichem Niveau genannt wird. Dies ist das erste Mal, dass eine KI den Menschen bei diesem Benchmark übertrifft und damit einen neuen Standard für logische Aufgaben setzt.
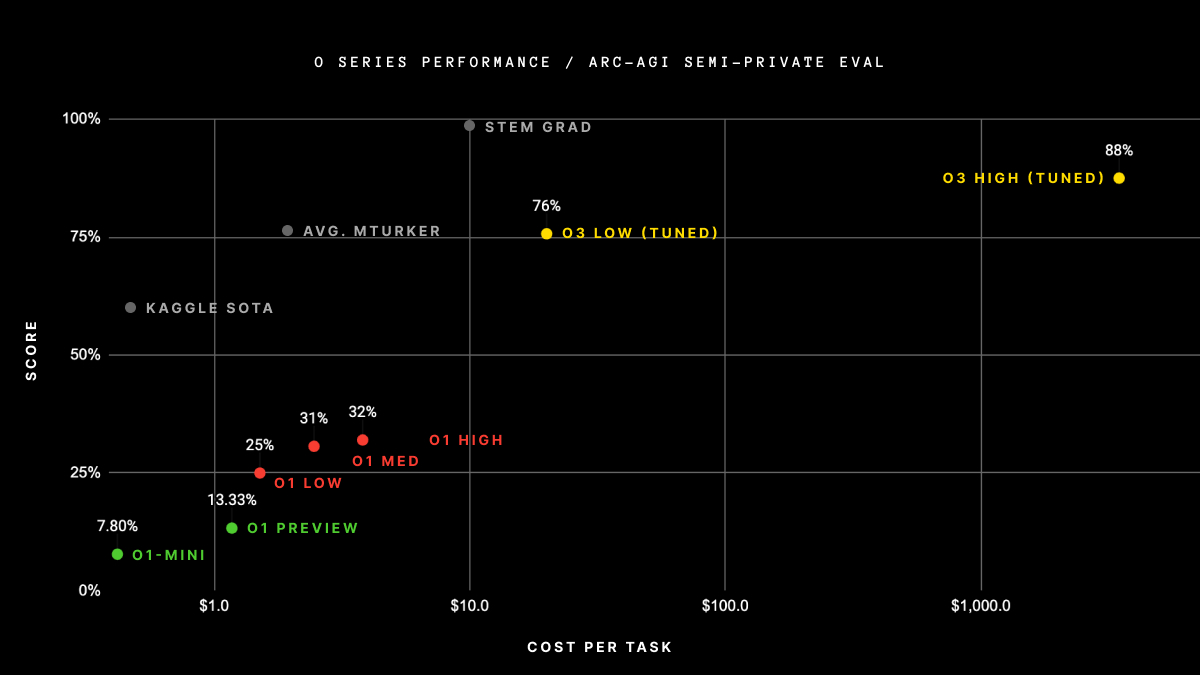
Quelle: ArcPrize
Wir glauben, dass diese Ergebnisse besonders bemerkenswert sind, weil sie zeigen, dass o3 in der Lage ist, Aufgaben zu bewältigen, die Anpassungsfähigkeit und Verallgemeinerung erfordern, anstatt auswendig gelerntes Wissen oder rohe Berechnungen. Das ist ein klares Indiz dafür, dass o3 auf dem Weg zu echter allgemeiner Intelligenz ist, die über domänenspezifische Fähigkeiten hinausgeht und in Bereiche vordringt, von denen man bisher dachte, sie seien ausschließlich menschliches Terrain.
Die obigen Ergebnisse basieren jedoch auf der Version von o3, die im Rahmen des OpenAI-Events "12 Days of Christmas" im Dezember veröffentlicht wurde. OpenAI hat bestätigt, dass sich die neu veröffentlichte Version von o3 von der in den obigen Tests gezeigten Version unterscheidet. ARC AGI wird die aktualisierten Leistungsergebnisse von o3 bald veröffentlichen.
Eine so große Leistungsverbesserung passiert nicht einfach so. Das Team von OpenAI hat einige Durchbrüche entdeckt, um diese Art von Zahlen zu erreichen:
OpenAI fand heraus, dass eine Erhöhung des Rechenbudgets während des Reinforcement-Learning-Trainings die Leistung des Modells verbessert - ähnlich dem Skalierungsverhalten, das wir beim überwachten Pre-Training in GPT-Modellen gesehen haben. Aber anstatt die Vorhersage des nächsten Wortes zu optimieren, lernt o3 durch die Maximierung der Belohnungen des Verstärkungslernens, oft durch eine durch das Werkzeug unterstützte Umgebung.
Mit anderen Worten: OpenAI behandelt das Verstärkungslernen eher wie ein Vortraining, indem es sowohl die Dauer als auch die Rechenleistung erhöht - und es scheint zu funktionieren. Dadurch werden Fähigkeiten freigeschaltet, die von langfristiger Planung und sequentiellem Denken profitieren, wie z.B. kompetitives Programmieren und mehrstufige mathematische Beweise. In Verbindung mit dem Einsatz von Werkzeugen wird der Leistungsgewinn noch deutlicher.
o3 zeigt auch deutliche Verbesserungen im visuellen Denken. Er versteht nicht nur Bilder, sondern integriert sie direkt in seine Denkschleife. Dazu gehört es, Bilder zu interpretieren, zu manipulieren und erneut zu betrachten, während du Probleme löst. Das ist ein Grund, warum o3 bei Aufgaben mit wissenschaftlichen Zahlen, mathematischen Diagrammen und sogar bei der Planung von Fotos gut abschneidet.
Eine wichtige Neuerung ist, dass o3 das Rohbild während des gesamten Rechenprozesses im Speicher behält. Anstatt eine statische Beschriftung zu verarbeiten und das Bild zu verwerfen, kann es bei Bedarf mit Werkzeugen zoomen, drehen oder verschiedene Teile des Bildes erneut betrachten. Das macht die Argumentation dynamischer und ermöglicht es, mit unübersichtlichen visuellen Eingaben umzugehen, z. B. mit einem verschwommenen Whiteboard, einem handgezeichneten Diagramm oder einem Foto eines Konferenzplans.
In einem Beispiel nutzte OpenAI o3, um ein qualitativ minderwertiges Bild eines Veranstaltungsplans zu lesen und eine Reiseroute zu planen, die jede Veranstaltung mit zehnminütigen Pausen dazwischen berücksichtigt - etwas, das sowohl das Parsen des visuellen Layouts als auch die Anwendung von Echtzeitbeschränkungen erfordern würde.

Wir wollten die visuellen Fähigkeiten mit einem eigenen Schnelltest testen. Wir gaben o1 zunächst eine rudimentäre Zeichnung und fragten es: "Welches Fraktal beginnen wir zu zeichnen?"
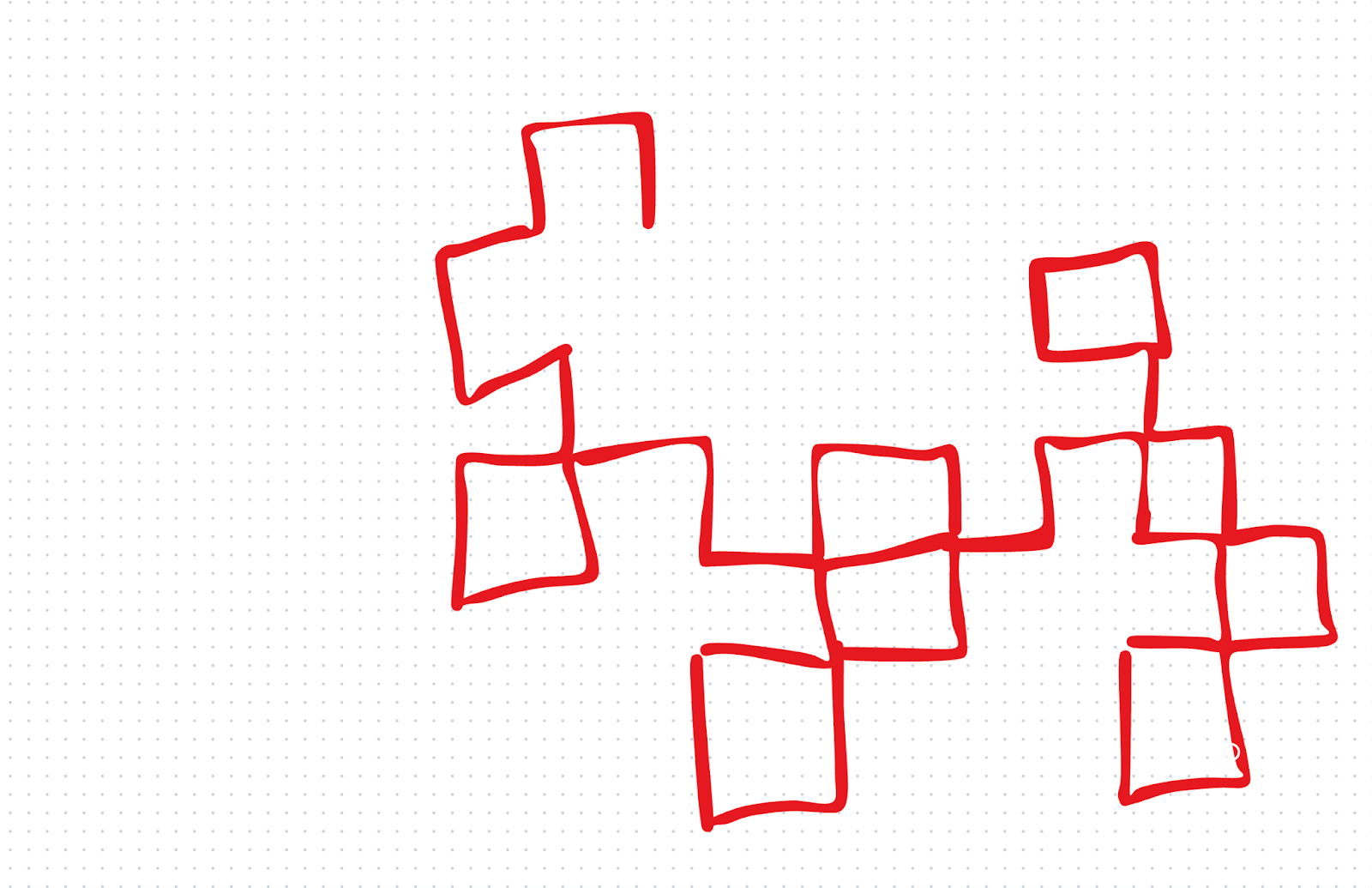
o1 hat falsch geantwortet. o3 hingegen hat es richtig gemacht: Es sagte uns, dass wir anfangen, die Drachenkurve zu ziehen. Das war ein kleiner Test, aber wir waren von dem Ergebnis beeindruckt, denn wir haben o3 nicht viel zugemutet.

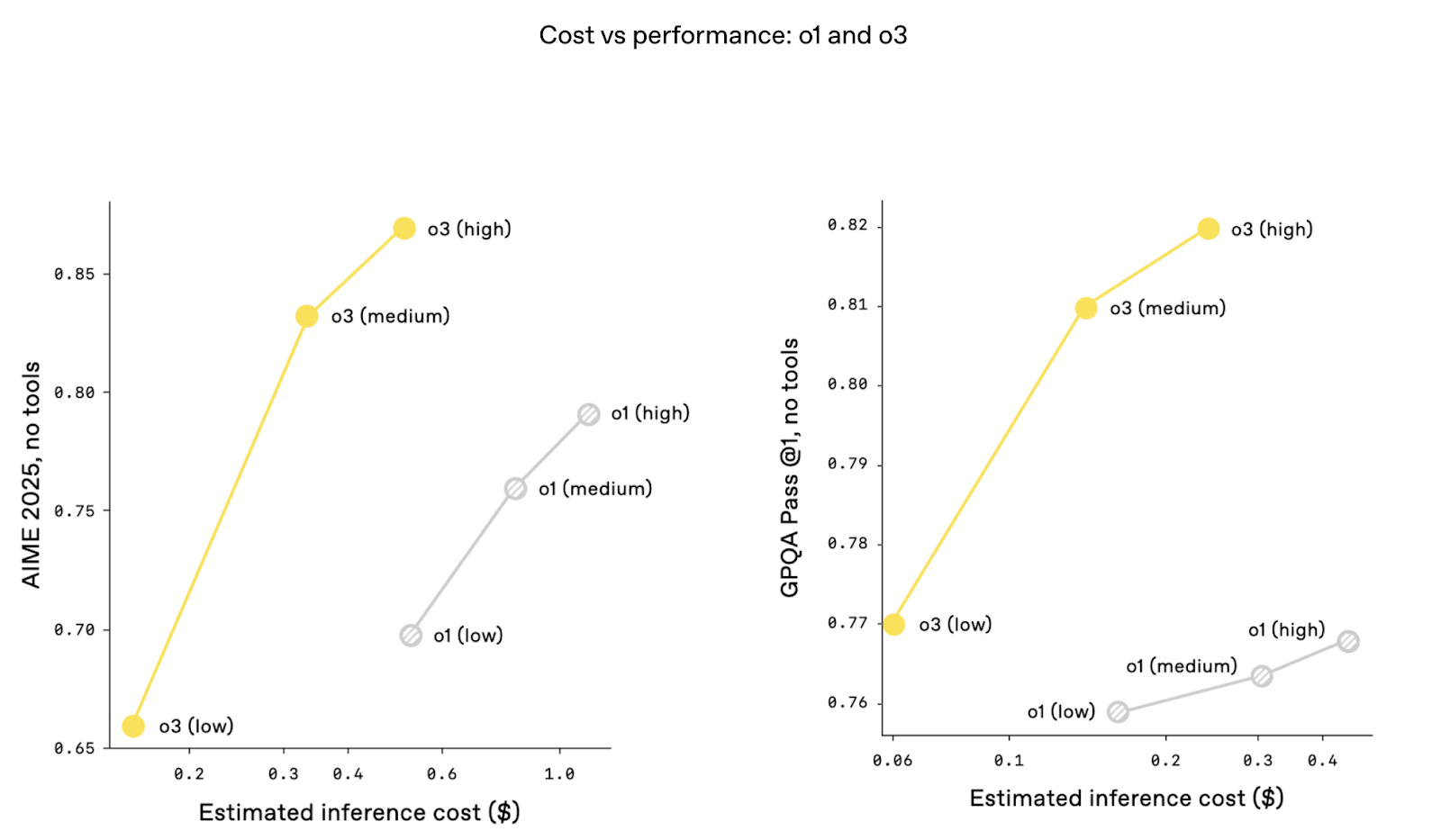
Interessanterweise ist das Verhältnis zwischen Kosten und Leistung bei o3 besser. Das heißt, die Leistung ist bei gleichbleibenden Inferenzkosten höher. Dies könnte auf Optimierungen der Architektur zurückzuführen sein, die den Token-Durchsatz verbessern und die Latenzzeit verringern. Die Kosten sind ein großes Diskussionsthema, seit Deepseek-R1 eine sehr hohe Leistung zu einem Bruchteil der Kosten von ChatGPT angekündigt hat.
Im April 2025 wurde o3-mini vollständig durch o4-mini in chatGPT und der APIersetzt. o4-mini bietet bei den meisten Benchmarks eine bessere Leistung, fügt native multimodale Eingaben hinzu und behält die Kompatibilität mit Tools bei - und ist dabei schneller und günstiger als o3. Tatsächlich übernimmt o4-mini jetzt die Rolle, die o3-mini ausfüllen sollte. Der folgende Inhalt gilt jedoch weiterhin für o3-mini.
o3-mini wurde neben o3 als kosteneffiziente Alternative eingeführt, um mehr Nutzerinnen und Nutzern erweiterte Argumentationsfähigkeiten zur Verfügung zu stellen und gleichzeitig die Leistung zu erhalten. OpenAI beschreibt o3-mini als eine Neudefinition der "Kosten-Leistungs-Grenze" bei Reasoning-Modellen, die es für Aufgaben zugänglich macht, die eine hohe Genauigkeit erfordern, aber mit Ressourcenbeschränkungen zurechtkommen müssen.
Eine der herausragenden Eigenschaften von o3-mini ist seine adaptive Denkzeit, mit der die Nutzer/innen die Denkleistung des Modells an die Komplexität der Aufgabe anpassen können. Für einfachere Probleme können die Nutzer/innen auswählen, um die Geschwindigkeit und Effizienz zu maximieren.
Bei anspruchsvolleren Aufgaben kann das Modell dank der Optionen für einen höheren Denkaufwand eine vergleichbare Leistung wie o3 selbst erbringen, allerdings zu einem Bruchteil der Kosten. Diese Flexibilität ist besonders für Entwickler und Forscher interessant, die mit verschiedenen Anwendungsfällen arbeiten.
Quelle: OpenAI
Die Live-Demo hat gezeigt, dass o3-mini hält, was es verspricht. In einer Programmieraufgabe wurde o3-mini zum Beispiel damit beauftragt, ein Python-Skript zu erstellen, um einen lokalen Server mit einer interaktiven Benutzeroberfläche für Tests zu erstellen. Trotz der Komplexität der Aufgabe hat das Modell gut abgeschnitten und gezeigt, dass es mit den Herausforderungen der Programmierung umgehen kann.
Quelle: OpenAI
Wir sehen o3-mini als praktische Lösung für Szenarien, in denen Kosteneffizienz und Leistung übereinstimmen müssen.
Es hat etwas länger gedauert, bis O3 verfügbar war, und einige der Gründe dafür könnten mit Innovationen im Bereich Sicherheit zusammenhängen.
OpenAI hat nach eigenen Angaben seine Sicherheitstrainingsdatensätze überarbeitet und Tausende von gezielten Ablehnungsaufforderungen eingeführt. Sie nannten bestimmte Kategorien: biologische Bedrohungen, Malware-Generierung und Jailbreak-Techniken. Dank dieser aufgefrischten Trainingsdaten konnte o3 bei internen Benchmarks wie der Handhabung der Befehlshierarchie und der Widerstandsfähigkeit gegen Gefängnisausbrüche eine hohe Ablehnungsgenauigkeit nachweisen. Um dies zu erreichen, haben die Teammitglieder von OpenAI Berichten zufolge tausend Stunden damit verbracht, unsichere Inhalte zu markieren.
OpenAI hat auch einen auf Schlussfolgerungen basierenden LLM-Monitor implementiert (den sie als "sicherheitsfokussierten, schlussfolgernden Monitor" bezeichnen). Zusätzlich zum Training des Modells, bei unsicheren Aufforderungen "Nein" zu sagen, hat OpenAI eine zusätzliche Sicherheitsebene eingeführt, die auf einem schlussfolgernden LLM basiert. Stell dir das wie ein parallel laufendes Überwachungsmodell vor, das speziell darauf trainiert ist, die Absichten und potenziellen Risiken von Benutzereingaben zu durchschauen und sich dabei an von Menschen geschriebenen Sicherheitsregeln zu orientieren.
OpenAI hat einen proaktiven Ansatz für die Sicherheitstests von o3 und o3 mini gewählt, indem es Forschern den Zugang für öffentliche Sicherheitstests öffnet, bevor die Modelle vollständig veröffentlicht werden.
Ein zentrales Merkmal der Sicherheitsstrategie von OpenAI für o3 ist die deliberative Ausrichtung, eine Methode, die über traditionelle Sicherheitsansätze hinausgeht. Die folgende Grafik zeigt, wie sich die deliberative Ausrichtung von anderen Methoden wie RLHF (Reinforcement Learning with Human Feedback) unterscheidet, RLAIF (Reinforcement Learning with AI Feedback) und Inferenzzeit-Verfeinerungstechniken wie Self-REFINE.
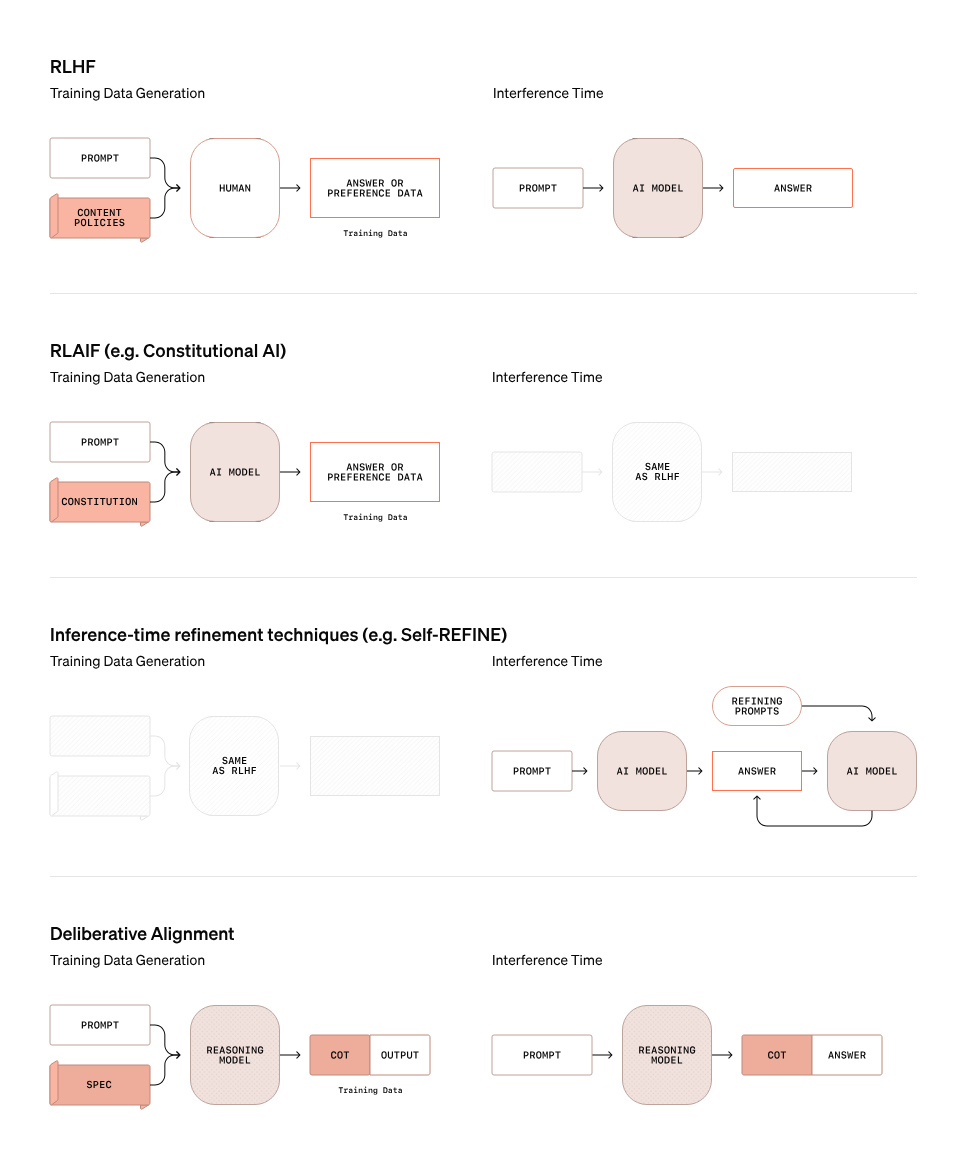
Quelle: OpenAI
Beim deliberativen Abgleich verlässt sich das Modell nicht einfach auf statische Regeln oder Präferenzdaten, um zu bestimmen, ob eine Aufforderung sicher oder unsicher ist. Stattdessen nutzt es seine Denkfähigkeiten, um Aufforderungen in Echtzeit zu bewerten. Die Grafik oben veranschaulicht diesen Prozess:
OpenAI geht davon aus, dass wir uns weiter über Sicherheit informieren wollen. In Erwartung dessen veröffentlichten sie ihr Preparedness Framework mit ihren Ideen zur Messung und zum Schutz vor schweren Schäden.
In der ChatGPT-Modellauswahl siehst du jetzt o3 und o4-mini. Laut der Ankündigung von OpenAI wird o3-pro voraussichtlich in den nächsten Wochen starten. Es wird dieselben Funktionen wie die anderen Modelle der o-Serie enthalten, z. B. Python, Browsing und Bildanalyse.
Wenn du wissen willst, wann o3-pro verfügbar ist, melde dich für den DataCamp-Newsletter The Median an und wir informieren dich, sobald er erscheint.
O3 und o3 mini verdeutlichen die wachsende Komplexität von KI-Systemen und die Herausforderungen, sie verantwortungsvoll freizugeben. Die Benchmarks sind zwar beeindruckend, aber wir interessieren uns mehr für die Fragen, die diese Modelle aufwerfen: Wie gut werden sie auch in der Praxis funktionieren? Sind die Sicherheitsmaßnahmen robust genug, um Grenzfälle in großem Umfang zu bewältigen?
Für uns sind o3 und o3 mini frühe Signale für KI-Systeme, die auf dem Weg zu mehr Autonomie sind. Ihr beeindruckendes Denkvermögen und ihre Anpassungsfähigkeit deuten darauf hin, dass wir nicht mehr mit Werkzeugen arbeiten, sondern mit Agenten, die in unserem Namen handeln. Was passiert, wenn diese Systeme offene Aufgaben ohne menschliche Führung bewältigen? Wie bewerten wir Modelle, die ihre eigenen Ziele und nicht nur ihre Ergebnisse generieren?
Wenn du dich für weitere KI-Themen interessierst, empfehlen wir dir:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
