
Kurs
Arbeiten mit DeepSeek in Python
3 Std.
1.2K
DeepSeek-OCR is a new large vision-language model that understands structure, parses tables, extracts charts, and can even tackle math, memes, and multiple languages.
In this guide, I put DeepSeek-OCR to the test on real-world tasks end-to-end—from handwritten notes to complex charts, memes, and multilingual documents. We’ll walk through:
By the end, you’ll see where DeepSeek-OCR shines and where it still struggles. If you’re exploring open-source OCR, you’ll want to see these experiments before you pick your pipeline. I also recommend checking out our DeepSeek V3.2-Speciale tutorial.
DeepSeek-OCR is a 3B parameter open vision-language model trained for document understanding. It leverages context optical compression by mapping large 2D visual contexts into compressed vision tokens, letting it process huge documents efficiently.
Some of the key features include:
DeepSeek-OCR is designed to handle a wide variety of document images, from charts and tables to handwriting, math, and multilingual text. Rather than treating images and text as separate domains, it leverages the visual modality as a compression engine for long text, allowing large language models (LLMs) to process much more information using dramatically fewer tokens. Let’s break down its architecture and what sets it apart:
At a high level, DeepSeek-OCR consists of two major components:
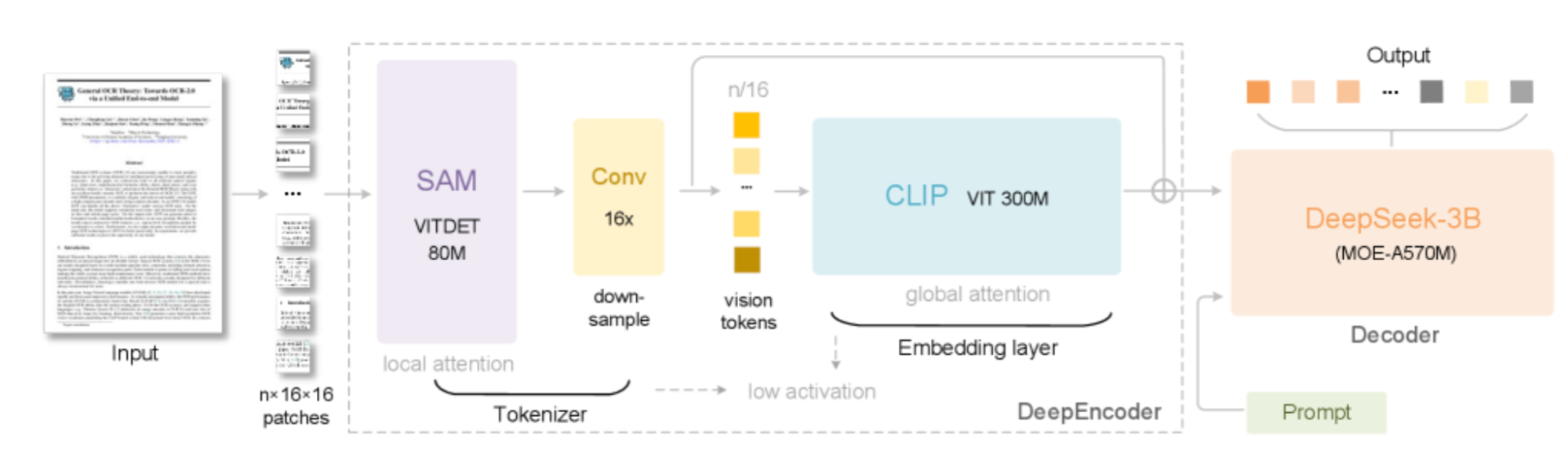
Source: DeepSeek-OCR: Contexts Optical Compression
1. Input image preprocessing: The pipeline begins with a document image, like a scanned contract, handwritten note, financial table, etc. This image is split into a grid of 16x16 pixel patches as the smallest visual words the model understands.
2. DeepEncoder: DeepEncoder is a multi-stage vision engine designed to balance resolution, memory use, and information compression. It operates in three main stages:
3. Vision tokens to text: The MoE Decoder compresses vision tokens that are fed into the DeepSeek-3B MoE (Mixture-of-Experts) decoder by efficient inference while activating only the most relevant experts per sample, reducing compute cost without sacrificing accuracy.
4. Prompt-driven flexibility: The system guides the output format (Markdown, HTML tables, SMILES chemical formulas, multilingual layouts, etc.) simply by changing the prompt, much like with LLMs.
DeepSeek-OCR demonstrates that a single document image can be “compressed” into as few as 1/10th the tokens needed for plain text, without substantial loss in accuracy.
In this section, we will set up a complete Gradio web application for DeepSeek-OCR to run OCR directly in your browser or Google Colab. With just a few steps, you can upload images of charts, tables, handwritten notes, memes, math, multilingual text, and get a structured output with bounding boxes.
Before you begin, make sure the following prerequisites are in place:
!pip install -q "transformers==4.46.3" "tokenizers==0.20.3" einops addict easydict pillow gradioThe above command installs all the required Python libraries for DeepSeek-OCR and Gradio, including the latest compatible versions of transformers, tokenizers, image processing (pillow), and the Gradio UI toolkit.
Note: This code runs on an L4 GPU with High RAM on Google Colab.
Now we have all the dependencies installed. Next, we set up our imports.
import os, time, torch, gradio as gr
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from datetime import datetime
import random
import stringWe import all the essential Python modules for file I/O, model inference (torch), UI building (gradio), image handling (PIL), and utility functions for managing file paths and random run IDs.
Once all the required libraries are installed, you’re ready to load the DeepSeek-OCR model from Hugging Face. However, accessing certain models requires authentication with a Hugging Face access token.
Here is how to set up your Hugging Face access token in Google Colab:
Now you’re ready to authenticate and proceed with loading the model!
model_id = "deepseek-ai/DeepSeek-OCR"
tok = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
if tok.pad_token is None and tok.eos_token is not None:
tok.pad_token = tok.eos_token
model = AutoModel.from_pretrained(
model_id,
trust_remote_code=True,
use_safetensors=True,
attn_implementation="eager"
).to(dtype=torch.bfloat16, device="cuda").eval()The above code loads the official DeepSeek-OCR model and tokenizer directly from Hugging Face. It then ensures tokenizer compatibility by setting the pad token and loads the model in a bfloat16 format.
Now our model is ready, next we create a new directory for each model output to keep every OCR run organized. This ensures that the extracted text, bounding box visualizations, and log files are stored and never overwrite previous results.
def new_run_dir(base="/content/runs"):
os.makedirs(base, exist_ok=True)
ts = datetime.now().strftime("%Y%m%d-%H%M%S")
rid = ''.join(random.choices(string.ascii_lowercase + string.digits, k=5))
path = os.path.join(base, f"run_{ts}_{rid}")
os.makedirs(path)
return pathThe new_run_dir function creates a unique output directory for each image processing run, based on the current timestamp and a random suffix. This ensures results from different runs do not overwrite each other and helps organize output files for inspection or debugging.
This step is our main engine for the DeepSeek-OCR Gradio app. It starts by converting the uploaded image into the right format and resizing it if the file is too large. Each time we run the model, it saves all outputs in a new folder.
def gr_ocr(image, mode, custom_prompt, base_size, image_size, crop_mode):
img = image.convert("RGB")
if max(img.size) > 2000:
s = 2000 / max(img.size)
img = img.resize((int(img.width*s), int(img.height*s)), Image.LANCZOS)
run_dir = new_run_dir()
img_path_proc = os.path.join(run_dir, "input.png")
img.save(img_path_proc, optimize=True)
if mode == "Custom Prompt" and custom_prompt.strip():
prompt = custom_prompt.strip()
else:
prompt = DEMO_MODES[mode]["prompt"]
t0 = time.time()
try:
with torch.inference_mode():
_ = model.infer(
tok,
prompt=prompt,
image_file=img_path_proc,
output_path=run_dir,
base_size=base_size,
image_size=image_size,
crop_mode=crop_mode,
save_results=True,
test_compress=True
)
except ZeroDivisionError:
print(" [Patched] Division by zero in compression ratio (valid_img_tokens==0). Ignored.")
dt = time.time() - t0
result_file = os.path.join(run_dir, "result.mmd")
if not os.path.exists(result_file):
result_file = os.path.join(run_dir, "result.txt")
result = "[No text extracted]"
if os.path.exists(result_file):
with open(result_file, "r", encoding="utf-8") as f:
result = f.read().strip() or "[No text extracted]"
boxed_path = os.path.join(run_dir, "result_with_boxes.jpg")
boxed_img = Image.open(boxed_path) if os.path.exists(boxed_path) else None
stats = f"""
**{dt:.1f}s** | Image: {img.size[0]}×{img.size[1]} px
**Output directory:** {run_dir}
"""
return result, stats, boxed_imgThe gr_ocr function encapsulates the preprocessing, inference, and post-processing logic for DeepSeek-OCR’s Gradio application. It performs the following steps:
torch.inference_mode() context to ensure no gradient computations are performed, reducing memory usage and increasing inference speed.ZeroDivisionError during rare edge cases in token compression without disrupting the user experience.Let’s move on to our interactive UI and see DeepSeek-OCR in action.
In the final step, we define an interactive Gradio interface for DeepSeek-OCR, enabling users to easily upload images, select different OCR extraction modes, adjust advanced settings, and view outputs within a single web-based UI.
DEMO_MODES = {
"Document ➔ Markdown": {
"prompt": "<image>\n<|grounding|>Convert the document to markdown.",
"desc": "Extracts full document text as Markdown, preserving structure (headings, tables, lists, etc.).",
"base_size": 1024, "image_size": 640, "crop_mode": False
},
"Chart Deep Parsing": {
"prompt": "<image>\nParse all charts and tables. Extract data as HTML tables.",
"desc": "Extracts tabular/chart data into HTML tables.",
"base_size": 1024, "image_size": 640, "crop_mode": False
},
"Chemical Formula Recognition": {
"prompt": "<image>\nExtract all chemical formulas and SMILES.",
"desc": "Extracts chemical structures and formulae.",
"base_size": 1024, "image_size": 768, "crop_mode": False
},
"Geometry Parsing": {
"prompt": "<image>\nExtract all geometric figures and their measurements.",
"desc": "Parses diagrams and extracts geometric data.",
"base_size": 1024, "image_size": 768, "crop_mode": False
},
"Plain Text Extraction": {
"prompt": "<image>\nFree OCR.",
"desc": "Fast, plain text OCR of the image.",
"base_size": 768, "image_size": 512, "crop_mode": False
},
"Multilingual Document": {
"prompt": "<image>\n<|grounding|>Extract text. Preserve all languages and structure.",
"desc": "Extracts multi-language content, preserves structure.",
"base_size": 1024, "image_size": 640, "crop_mode": False
},
"Custom Prompt": {
"prompt": "",
"desc": "Provide your own custom prompt for flexible OCR or parsing.",
"base_size": 1024, "image_size": 640, "crop_mode": False
}
}
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown("""
<div style="text-align:center;">
<h1>DeepSeek-OCR Demo</h1>
</div>
""")
with gr.Row():
with gr.Column():
gr.Markdown("### Input")
image_input = gr.Image(type="pil", label="Upload Document/Image", height=350)
gr.Markdown("#### Demo Modes (From Paper)")
mode = gr.Radio(
choices=list(DEMO_MODES.keys()), value="Document to Markdown", label="Select Capability to Test"
)
desc = gr.Markdown(DEMO_MODES["Document to Markdown"]["desc"])
custom_prompt = gr.Textbox(label="Custom Prompt", visible=False)
with gr.Accordion("Advanced Settings", open=False):
base_size = gr.Slider(512, 1280, value=DEMO_MODES["Document to Markdown"]["base_size"], step=64, label="Base Size")
image_size = gr.Slider(512, 1280, value=DEMO_MODES["Document to Markdown"]["image_size"], step=64, label="Image Size")
crop_mode = gr.Checkbox(value=DEMO_MODES["Document to Markdown"]["crop_mode"], label="Dynamic Resolution (Crop Mode)")
process_btn = gr.Button("Process Image", variant="primary")
with gr.Column():
gr.Markdown("### Results")
ocr_output = gr.Textbox(label="Extracted Content", lines=22, show_copy_button=True)
status_out = gr.Markdown("_Process an image to see stats and output dir_")
boxed_output = gr.Image(label="Result with Bounding Boxes", type="pil")
def update_mode(selected):
d = DEMO_MODES[selected]
return d["desc"], gr.update(visible=selected=="Custom Prompt"), d["base_size"], d["image_size"], d["crop_mode"]
mode.change(update_mode, inputs=mode,
outputs=[desc, custom_prompt, base_size, image_size, crop_mode])
process_btn.click(
gr_ocr,
inputs=[image_input, mode, custom_prompt, base_size, image_size, crop_mode],
outputs=[ocr_output, status_out, boxed_output]
)
demo.launch(share=True, debug=True)Let’s understand this code in subsections:
DEMO_MODES dictionary encapsulates all major OCR capabilities supported by DeepSeek-OCR, such as "Document to Markdown", "Chart Deep Parsing", "Chemical Formula Recognition", and more. Each mode includes a default prompt, description, and recommended image processing parameters, allowing users to switch extraction tasks on the fly.Blocks API. The interface is split into two main columns, an input panel that lets users upload an image, choose the OCR mode, and fine-tune advanced parameters like image size and crop mode. The output panel displays the extracted OCR content, inference statistics, and an annotated image with bounding boxes around detected regions.gr_ocr by passing all current UI selections as arguments. The outputs are then immediately rendered in the output panel.Note: You may need to restart the session on Google Colab if it still returns output from the previous input.
Now that our Gradio application is set up, let’s put DeepSeek-OCR to the test with a series of practical examples.
Within the DeepSeek-OCR Gradio demo, I wanted to see how well the model could extract tabular data from charts. This is still challenging for most OCR and vision models.
I tried two classic test cases:

DeepSeek-OCR returned an HTML table for each chart, with cells corresponding to categories, values, and labels it found in the image.
What worked: The model captured all visible text and structure in the chart, and the output was in HTML table format, which is machine-usable and keeps the table logic intact. It even processed complex financial charts, attempting to tabulate every number and label.
Where it struggled: The raw output was very verbose, with lots of <td> and <tr> tags, making it hard to interpret at a glance. In complex charts, the model sometimes duplicated entries or lost the higher-level visual structure, resulting in an overwhelming table of repeated "BUY"/"SELL" signals and values.
For real-world workflows, you’d want to post-process the HTML for readability or import it into Excel or Pandas.

DeepSeek-OCR’s chart parsing is a smart chart digitization feature, but the HTML-heavy output is best suited for downstream data pipelines or further parsing, not quick human review.
For my next test, I wanted to see how well DeepSeek-OCR could handle extracting chemical information from structured images. The model’s chemical extraction mode is designed to convert both tabular chemical data and graphical molecular structures into machine-readable formats such as HTML tables and SMILES notation.
I uploaded two kinds of images for this experiment, and here is what I encapsulated:

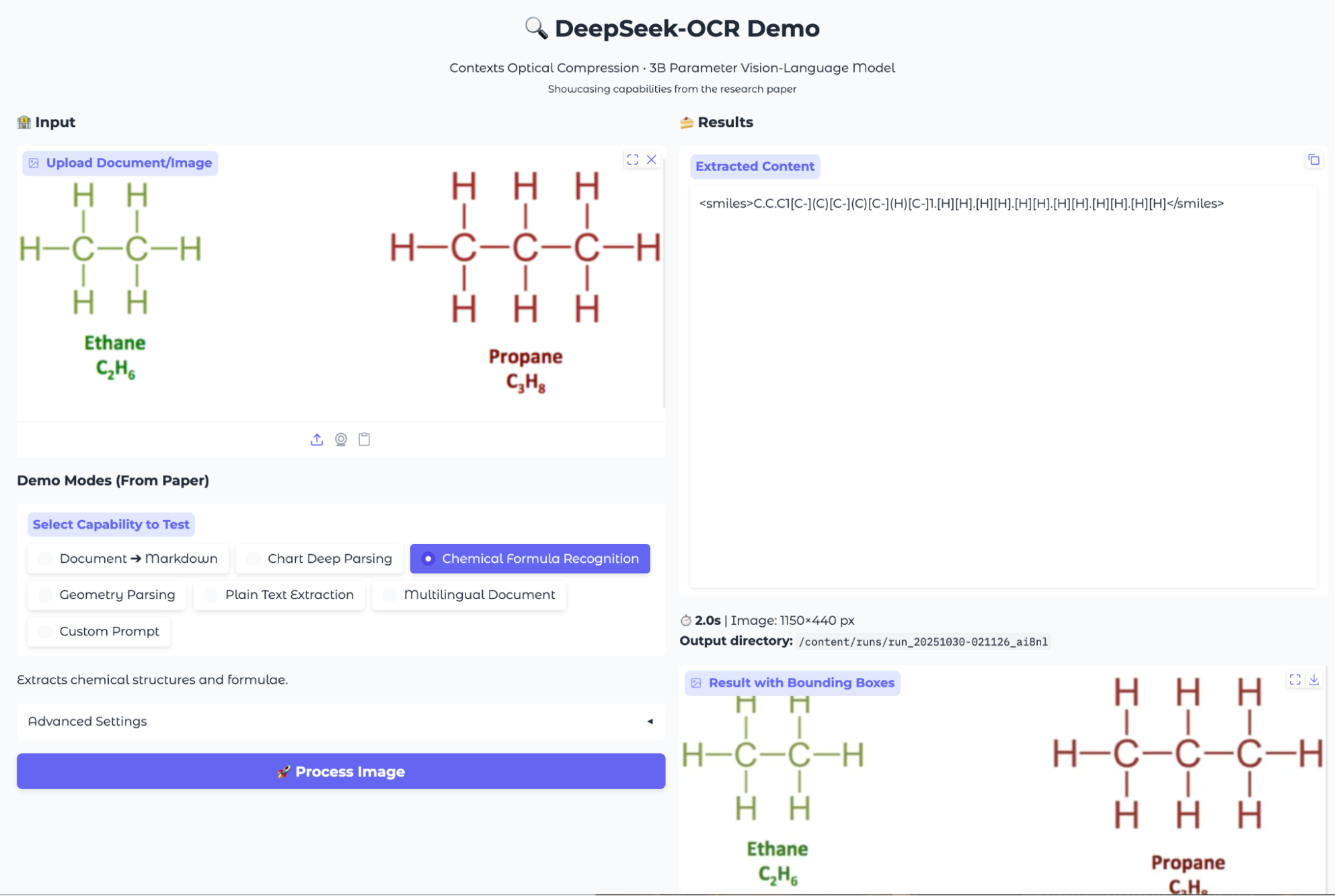
Overall, the chemical formula extraction capability offers a quick way to digitize chemical data and attempt molecular structure recognition, but further refinement is needed for reliable chemical parsing, especially with complex structures.
Next, I wanted to see how well DeepSeek-OCR could handle handwritten notes, a classic challenge for OCR systems, especially when the handwriting is stylized or varies in size.
I uploaded an image of a handwritten chemistry list, containing compound names on lined paper. Once processed, the model's Document to Markdown mode extracted the text and preserved the structure surprisingly well. It recognized the header and listed each compound on its own line, just as they appeared in the original image. The bounding boxes visually confirmed that the model correctly identified each line and separated the individual text blocks.
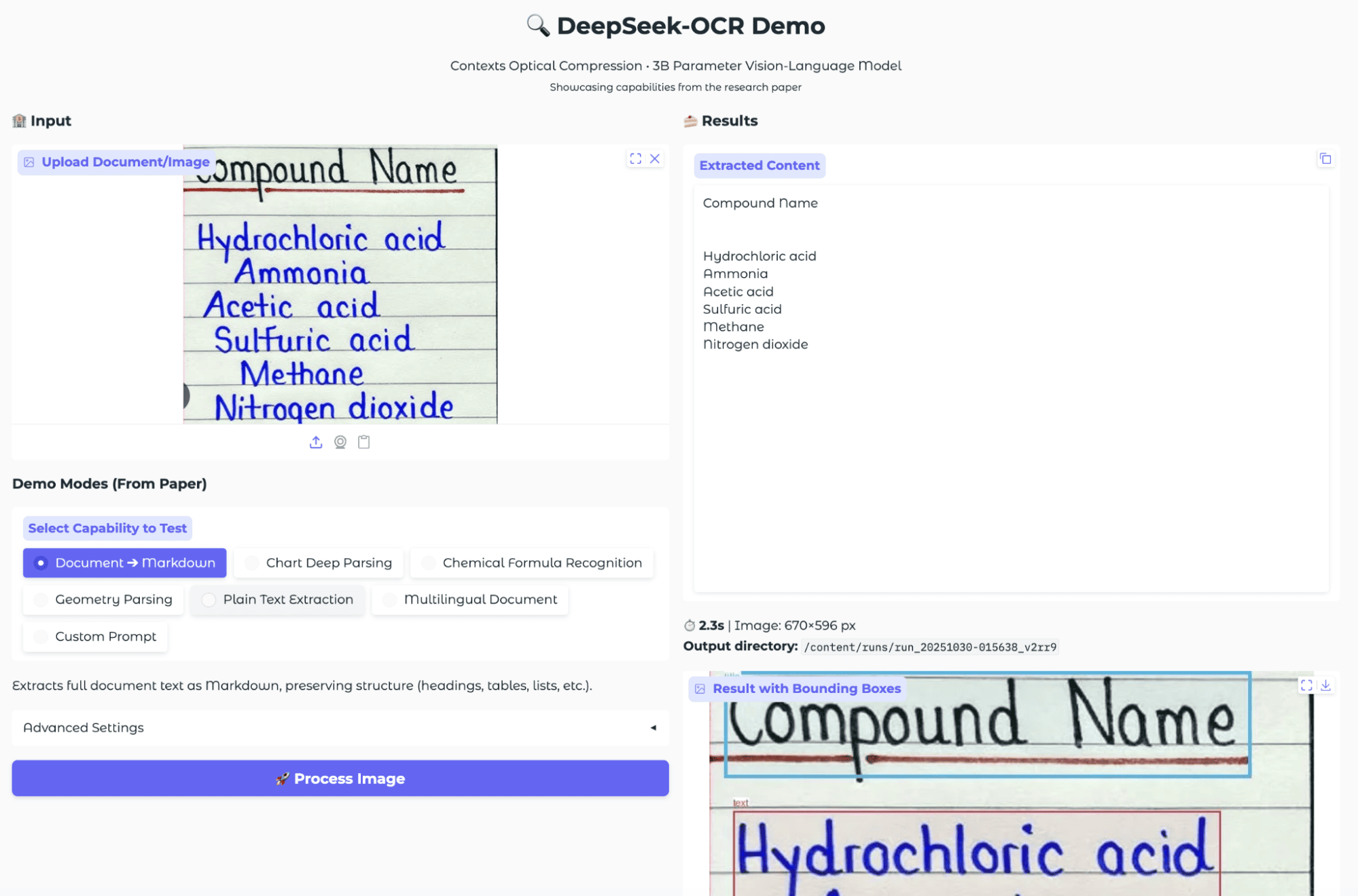
This result demonstrates the model’s ability to transcribe handwritten content into digital text. While some minor formatting details may be lost, but the overall extraction was highly accurate for this example.
Another standard test for OCR is to read and correctly interpret mathematical equations written in standard textbook notation. For this experiment, I uploaded an image containing some complex equations set in LaTeX-style math fonts to evaluate if the model can not only detect but also accurately extract and format these expressions.
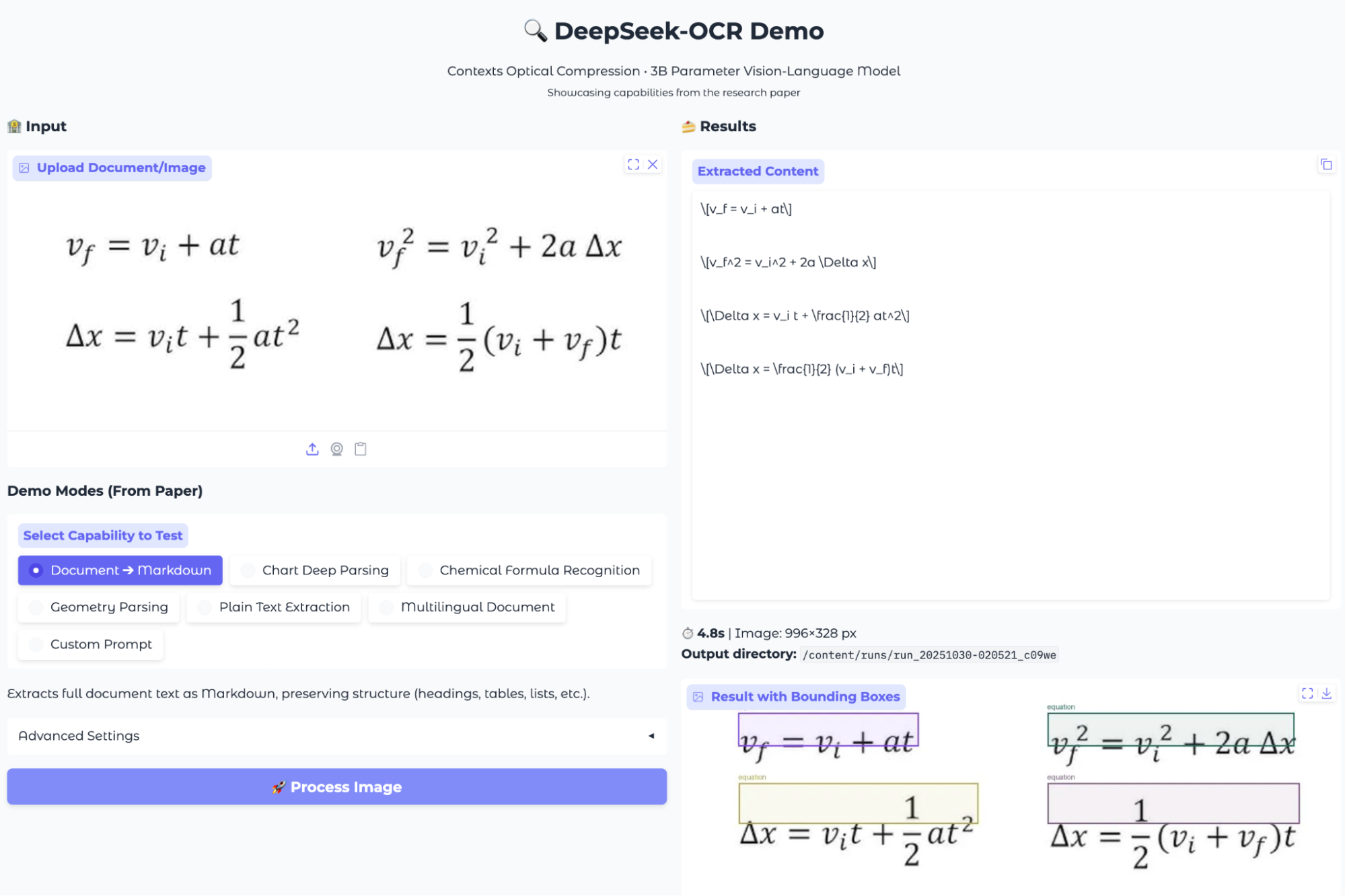
DeepSeek-OCR successfully detected all four equations in the image and extracted them as LaTeX strings. The recognized output was structured cleanly, with each equation transcribed to a separate line in standard LaTeX format.
The bounding boxes also overlaid on the original image correctly (approximately), demonstrating that the model can accurately localize and segment individual mathematical expressions.
What stood out is that the extracted content maintained the mathematical structure using commands like \frac for fractions and proper variable formatting, making the result directly reusable for documentation.
One of the most common and valuable OCR tasks is extracting tabular data from images of documents, especially when dealing with scanned reports, research papers, or datasets. To evaluate DeepSeek-OCR’s ability in this area, I uploaded an image containing a structured economic comparison table across multiple countries.
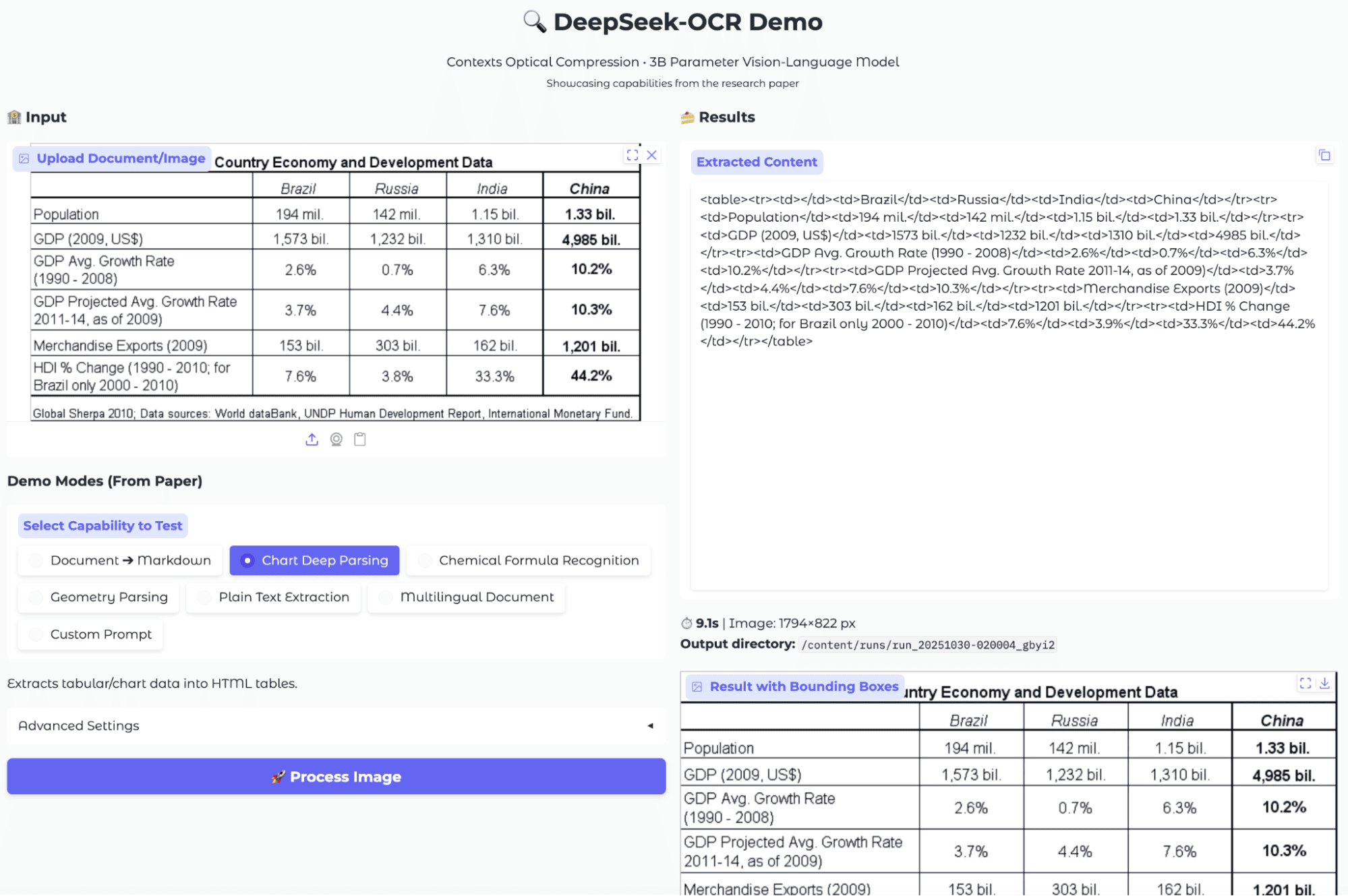
After selecting the "Chart Deep Parsing" mode and processing the image, DeepSeek-OCR attempted to convert the visual table into an HTML table structure. The extracted content (on the right) contains a series of <table> and <td> tags, mapping the table rows and columns as plain text. The bounding box output further confirmed that the model correctly identified and segmented the main table region in the image.
The model shows reliable extraction for simple tables, though post-processing may be needed as the output format (raw HTML) is less user-friendly for quick review or downstream data analysis.
For this example, I wanted to test how the model handles text extraction from popular meme images. This is a real-world scenario where text is often overlaid on complex backgrounds, uses varying fonts, and may not always follow typical document structures.
I uploaded a classic meme image with large, white, capitalized text overlaying a scene from a movie (Leonardo DiCaprio in Django Unchained) and ran the Document to Markdown extraction mode.
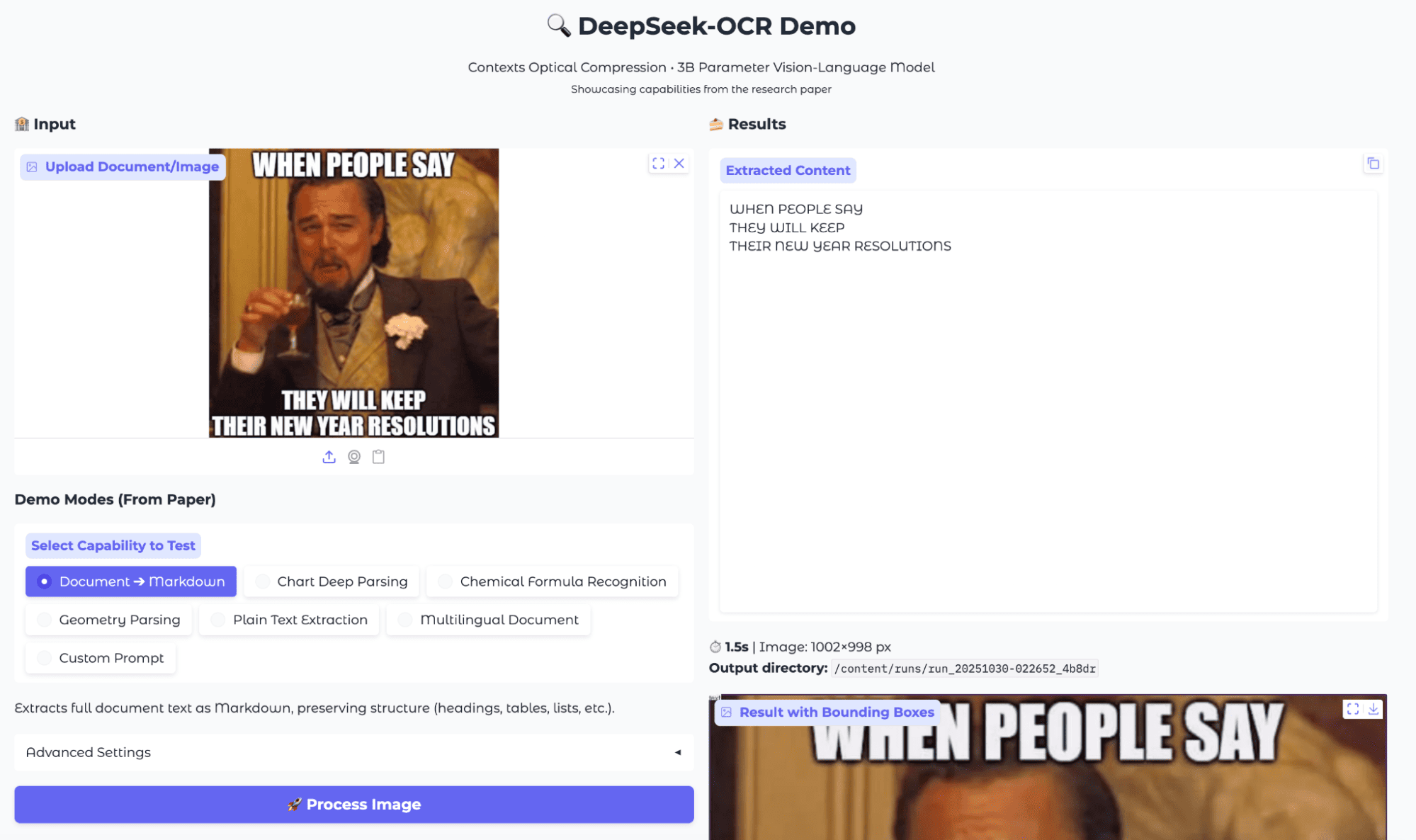
Source: Media.io
The OCR result for this meme was surprisingly robust. It was able to capture all the relevant words in the correct order, without introducing spelling mistakes or skipping over text, even with the complex background.
While there is no structural markup, the extraction is highly usable for downstream tasks like meme sentiment analysis, content moderation, or text-based meme search.
One of DeepSeek-OCR’s unique strengths is its support for multilingual text extraction, which is especially useful for documents or images containing a mix of global languages.
I tested this capability with a variety of samples, including a real-world street sign with Chinese text, and a synthetic sample containing a mixture of Chinese, Japanese, and Korean sentences.
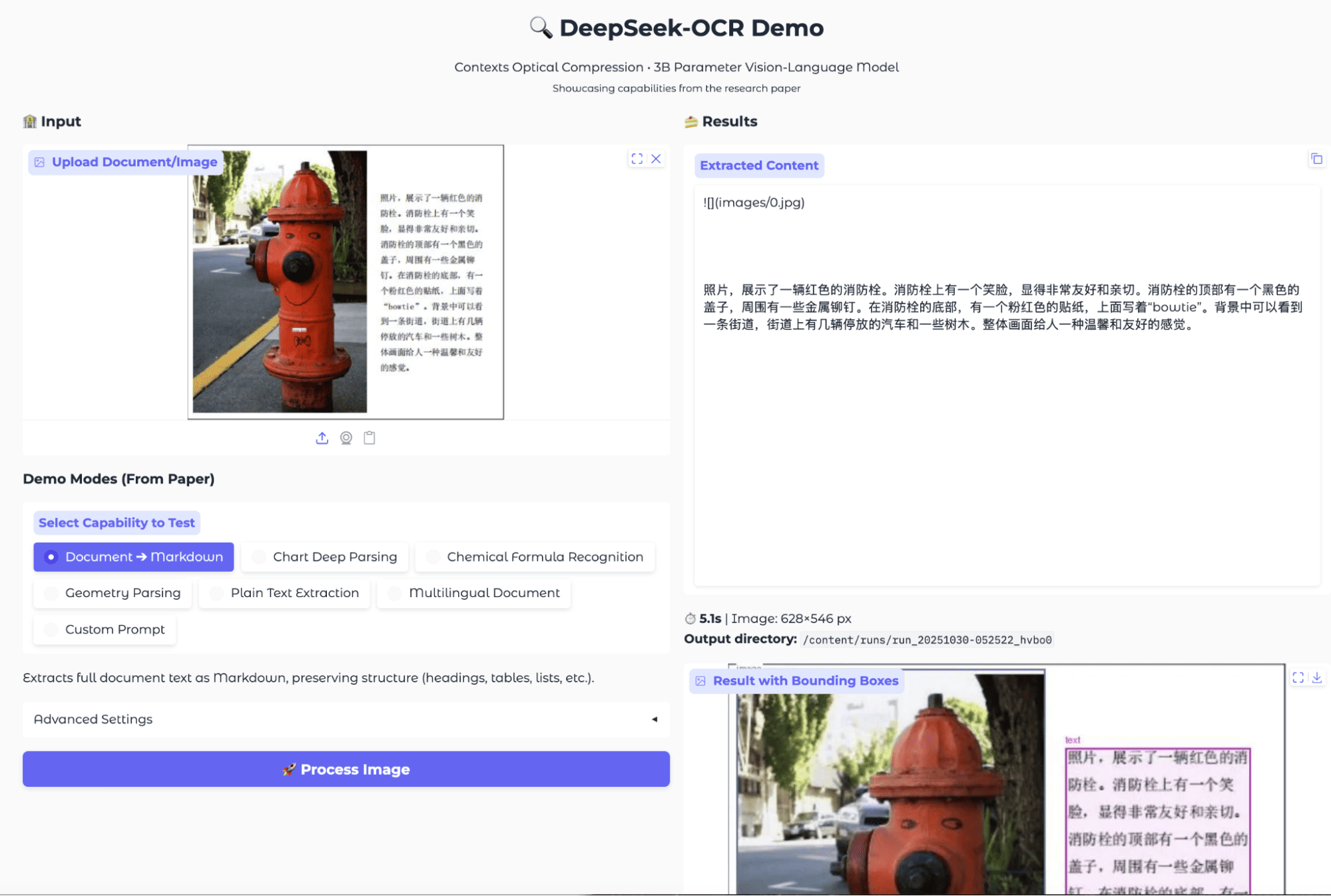
Source: DeepSeek OCR Hugging Face
When processing these multilingual samples, DeepSeek-OCR’s document-to-Markdown mode was able to accurately detect and extract non-English scripts. For the street photo, the model identified and returned the entire paragraph of Chinese text.

For the mixed-language example, it correctly separated and labeled the Chinese, Japanese, and Korean sections, preserving their formatting and text blocks. The bounding box overlays also showed precise detection of each language’s text region.
However, there are two important caveats:
Despite these minor issues, DeepSeek-OCR delivers strong multilingual OCR capabilities that can reliably handle mixed scripts and real-world photos.
DeepSeek-OCR bridges the gap between classic OCR and modern multimodal LLMs. Its biggest win is versatility i.e., you get a single pipeline that reads scanned documents, extracts complex tables and charts, understands equations and chemical structures, and even works with memes, handwriting, and dozens of languages.
That said, DeepSeek-OCR is not flawless. Chart and table outputs can be overly verbose, chemical structure recognition sometimes falls short, and multilingual processing can be noticeably slow. Complex visual layouts may require post-processing for direct use.
But for research, academic workflows, rapid prototyping, and anyone needing advanced OCR beyond just plain text, DeepSeek-OCR already feels like a serious upgrade over legacy tools.
If you’re keen to learn more about the DeepSeek ecosystem, I recommend checking out the Working with DeepSeek in Python course.
Top DataCamp Courses
Kurs
Kurs
Kurs
Blog
François Aubry
8 Min.
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Aashi Dutt