
Kurs
Arbeiten mit DeepSeek in Python
3 Std.
1.2K
DeepSeek hat gerade die Version 3.2-Expveröffentlicht :. Das ist ein neues Modell, das die API-Kosten um mehr als die Hälfte runterbringt. Wenn du schon mal mit großen Sprachmodellen gearbeitet hast, weißt du, dass die Verarbeitung langer Kontexte schnell teuer wird. Diese neue Version löst das Problem mit einer Technik namens„ DeepSeek Sparse Attention”.
In diesem Tutorial erkläre ich dir, was v3.2 „ ” von früheren DeepSeek-Versionen unterscheidet , wie „Sparse Attention” im Hintergrund funktioniert und wie du das Modell in deinen Projekten einsetzen kannst. Wir zeigen dir die Grundlagen von API-Aufrufen und erstellen ein Demo-Projekt, das zeigt, wo dieses Modell am besten funktioniert.
Am Ende wirst du eine Streamlit-App erstellen, die die Kosten verschiedener LLMs vergleicht, darunter DeepSeek v3.2:
Fangen wir mit ein paar Infos zu DeepSeek und den Änderungen in dieser Version an.
DeepSeek ist ein Open-Source-KI-Unternehmen aus China, das große Sprachmodelle unter der MIT-Lizenz entwickelt. Ihre Modelle konkurrieren mit GPT-5 und Claude bei Aufgaben wie Schlussfolgerungen, Programmierung und allgemeinen Aufgaben. Das Unternehmen hat im letzten Jahr mehrere Versionen rausgebracht, darunter DeepSeek-V3 und DeepSeek-R1, die wegen ihrer starken Leistung bei geringeren Kosten als Closed-Source-Alternativen Aufmerksamkeit erregten.
Vor Version 3.2 war die neueste Version v3.1-Terminus, ein Modell mit 685 Milliarden Parametern. Obwohl es eine solide Leistung zeigte, war die Verarbeitung langer Kontexte immer noch ziemlich teuer. Hier kommt die neue experimentelle Version ins Spiel.
DeepSeek veröffentlicht v3.2-Exp am 29. September 2025 (2025-09-29). Das „Exp“ steht für „experimentell“, was bedeutet, dass das Modell noch getestet und verbessert wird. Erwarte noch keine Stabilität auf Produktionsniveau, aber du kannst es für Forschung und Projekte nutzen, bei denen du die neuesten Funktionen ausprobieren willst.
Das Modell basiert auf v3.1-Terminus und hat die gleiche 685B-Parameterarchitektur. Was es besonders macht, ist, wie es Infos intern verarbeitet. Es nutzt ein OpenAI-kompatibles API-Format. Wenn du also schon mal das OpenAI SDK benutzt hast, weißt du schon, wie DeepSeek funktioniert (ich erkläre in diesem Artikel auch, wie du deinen ersten API-Aufruf machst).
Hier ist die große Veränderung: DeepSeek hat die API-Preise im Vergleich zu v3.1 um mehr als 50 % gesenkt. Und die Leistung blieb gleich. Du kriegst die gleiche Qualität der Antworten zum halben Preis.
Dieser Preisrückgang kam durch eine technische Verbesserung namens DeepSeek Sparse Attention (DSA). Anstatt das Modell auf jedes einzelne Token in deiner Eingabe achten zu lassen (was ziemlich aufwendig ist), konzentriert sich DSA gezielt auf das, was wirklich wichtig ist. Wir schauen uns im nächsten Abschnitt an, wie das funktioniert.
Wenn du die kompletten technischen Details wissen willst, DeepSeek hat einen technischen Bericht auf GitHub veröffentlicht, der die Änderungen an der Architektur und die Benchmark-Ergebnisse erklärt.
Bevor wir uns mit dem Code beschäftigen, lass uns darüber reden, warum v3.2 billiger und schneller ist . Die Antwort liegt darin, wie das Modell deine Eingaben verarbeitet.
Wenn du Text an ein Sprachmodell schickst, zerlegt es deine Eingabe in Token (also Wörter oder Teile von Wörtern). Dann muss das Modell rausfinden, welche Token miteinander zu tun haben. Dieser Vorgang heißt Aufmerksamkeit.
Bei herkömmlichen Transformatorenschaut jedes Token auf jedes andere Token. Wenn du 1.000 Token hast, überprüft jeder einzelne alle anderen 999. Das sind 1 Million Vergleiche. Bei 10.000 Tokens bist du bei 100 Millionen Vergleichen. Die Rechnung ist quadratisch: Wenn du die Eingabelänge verdoppelst, vervierfachst du den Rechenaufwand.
Deshalb ist die Verarbeitung langer Kontexte so teuer. Deine API-Rechnung wird schnell teurer, wenn deine Dokumente länger werden.
Nicht alle Token müssen alle anderen Token berücksichtigen. Wenn du gerade diesen Satz liest, liest du nicht ständig jedes vorhergehende Wort erneut. Du konzentrierst dich auf das, was wichtig ist.
Wenig Aufmerksamkeit hat denselben Effekt. Anstatt jedes Token mit jedem anderen Token zu vergleichen, sucht das Modell gezielt aus, welche Vergleiche wichtig sind. Ein paar ältere Ansätze dazu sind:
Diese Methoden sparen Rechenleistung, sind aber ziemlich unflexibel. Sie legen vorher fest, welche Token interagieren können, egal was in deinem eigentlichen Text steht. Manchmal braucht man ein Wort am Anfang eines Dokuments, um eine Verbindung zu etwas am Ende herzustellen. Feste Muster können das übersehen.
DSA geht einen anderen Weg. Anstatt feste Muster zu verwenden, lernt es anhand des Inhalts selbst, welche Token tatsächlich aufeinander achten müssen. Das Modell findet relevante Verbindungen im Handumdrehen.
So funktioniert es im Großen und Ganzen. Während des Trainings hat DeepSeek jedem Aufmerksamkeitslayer einen Auswahlmechanismus hinzugefügt. Dieser Mechanismus schaut sich deine Tokens an und entscheidet, welche Aufmerksamkeitsverbindungen es wert sind, berechnet zu werden. Es behält die wichtigen Sachen und lässt den Rest weg.
Die Auswahl ist nicht zufällig. Das Modell hat während des Trainings gelernt, welche Arten von Verbindungen für verschiedene Aufgaben wichtig sind. Wenn du eine Anfrage zum Thema Code schickst, konzentriert sich das System auf andere Muster als beim Versand eines Rechtsdokuments.
Das Ergebnis: DSA reduziert die Anzahl der Aufmerksamkeitsvorgänge, ohne die Ausgabequalität zu beeinträchtigen. Im technischen Bericht zeigt DeepSeek, dass„ ” Version 3.2 bei Benchmarks fast genauso gut abschneidet wie Version 3.1-Terminus „ ”, dabei aber weniger Rechenleistung pro Token braucht. Du kriegst die gleiche Modellqualität zu ungefähr der Hälfte der API-Kosten.
Hier ist, was DSA in der Praxis bedeutet:
Die Vorteile zeigen sich am besten in diesen Anwendungsfällen:
Wenn deine Anwendung mit langen Eingaben arbeitet, macht DSA einen echten Unterschied. Du sparst nicht nur Geld. Du machst deine Aufgaben besser, bei denen du dich sonst schwer tust, dich zu konzentrieren.
Jetzt, wo du weißt, wie DSA funktioniert, lass uns das Modell über seine API nutzen.
Du brauchst Python 3.8 oder neuer auf deinem Rechner installiert. Wenn du noch keine Erfahrung mit der Arbeit mit LLMs über APIs hast, solltest du dir vielleicht den den Leitfaden von DataCamp zum Thema KI, um dich mit den Grundlagen vertraut zu machen. Wir haben auch ein ausführlicheres DeepSeek-API-Tutorial, das frühere Versionen abdeckt, falls du dich näher damit beschäftigen möchtest.
Die gute Nachricht: Wenn du schon mal die API von OpenAI benutzt hast, weißt du schon, wie DeepSeek funktioniert. Das API-Format ist das gleiche.
Hol dir zuerst deinen API-Schlüssel von platform.deepseek.com. Du musst ein Konto erstellen, falls du noch keins hast.
Installiere die benötigten Pakete:
uv add openai python-dotenvMach eine Datei namens „ .env “ in deinem Projektverzeichnis und füge deinen API-Schlüssel hinzu:
DEEPSEEK_API_KEY=your_api_key_hereHier ist ein einfaches Beispiel mit dem OpenAI SDK. Der einzige Unterschied zur Verwendung der API von OpenAI ist der Parameter „ base_url “ und dein API-Schlüssel:
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI-compatible client with DeepSeek endpoint
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# Send a chat completion request to DeepSeek v3.2
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Explain sparse attention in one sentence."}
]
)
# Print the model's response
print(response.choices[0].message.content)Wenn du das ausführst, bekommst du eine Antwort wie:
Sparse attention reduces computational cost by having each token attend to only a subset of relevant tokens rather than all tokens in a sequence.Das Modell „ deepseek-chat “ ist die nicht-denkende Art von „ v3.2-Exp “. Es bearbeitet deine Anfrage und gibt eine Antwort, ohne die einzelnen Schritte zu zeigen.
Wenn du sehen willst, wie das Modell denkt, schau dir mal deepseek-reasoner an. Dieses Modell zeigt dir den Gedankengang, bevor es dir die endgültige Antwort gibt:
# Use deepseek-reasoner to see the model's reasoning process
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Which is larger: 9.11 or 9.8?"}
]
)
# Print both reasoning and final answer
print("Reasoning:", response.choices[0].message.reasoning_content)
print("Answer:", response.choices[0].message.content)Das gibt ungefähr so was aus:
Reasoning: To compare 9.11 and 9.8, I need to look at the digits after the decimal point. 9.11 has digits 1 and 1 after the decimal, making it 9 + 0.11. Meanwhile, 9.8 is 9 + 0.8. Since 0.8 is greater than 0.11, 9.8 is the larger number.
Answer: 9.8 is larger than 9.11.Das Schlussfolgerungsmodell kann bis zu 64.000 Token an Schlussfolgerungsinhalten generieren (Standardwert ist 32.000), bevor es die endgültige Antwort liefert. Beachte, dass es einige Parameter wie temperature oder top_p nicht unterstützt. Die offizielle API von DeepSeek unterstützt noch keinen Parameter „ reasoning_effort ” zur Steuerung der Argumentationstiefe (obwohl einige Drittanbieter wie LangChain diesen Parameter zu ihren Integrationen hinzugefügt haben).
Das Antwortobjekt folgt der Struktur von OpenAI. Du kannst auf den Inhalt über response.choices[0].message.content zugreifen, die Token-Nutzung mit response.usage überprüfen und das verwendete Modell mit response.model ansehen.
Die API ist nicht deine einzige Option. DeepSeek stellt seine Modelle als Open Source zur Verfügung, sodass du sie selbst ausprobieren kannst.
Hugging Face: Das Modell findest du unter huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp. Du kannst die Inferenz-Anbieter von Hugging Face nutzen, um das Modell zu starten, ohne dich um die Infrastruktur kümmern zu müssen, oder die Gewichte für die lokale Inferenz runterladen. Der lokale Weg klappt gut, wenn du die Hardware hast (denk an Rechenzentrumsbudgets oder eine kleine GPU-Farm in deinem Schrank für ein Modell mit 685 Milliarden Parametern).
vLLM: Für selbst gehostete Bereitstellungen in großem Maßstab bietet vLLM optimierte Inferenz mit v3.2-Unterstützung. Es ist schneller als das Ausführen des Modells über Standardtransformatoren und kann gut mit Batch-Verarbeitung umgehen. Benutz das, wenn du das Modell in der Produktion einsetzt und über eine solide Infrastruktur verfügst, die das unterstützt.
Für die meisten Entwickler, die gerade anfangen, ist die API die richtige Wahl. Du bezahlst nur für das, was du wirklich nutzt, und DeepSeek kümmert sich um Skalierung und Wartung.
Du hast gesehen, wie die API von DeepSeek v3.2 funktioniert, und deine ersten Aufrufe gemacht. Jetzt probieren wir es mal mit einem echten Vergleich aus.
Spart die geringe Aufmerksamkeit von DeepSeek bei der Verarbeitung langer Kontexte tatsächlich Geld? Und wie schneidet es im Vergleich zu GPT-5 und Claude Sonnet 4.5 ab?
Um das zu klären, machen wir ein Vergleichstool, das mehrere Forschungsarbeiten in einen Kontext packt und die gleiche Frage an alle vier Modelle schickt. Du siehst genau, wie viel jedes Modell kostet, wie schnell es reagiert und welche Antworten es gibt.
Die meisten Dokumentenanalysesysteme nutzen RAG: Sie zerlegen deine Dokumente in kleine Teile, speichern sie und holen nur die relevanten Teile raus, wenn du eine Frage stellst. Das klappt gut für einfache Suchvorgänge, aber du verlierst die Verbindungen zwischen verschiedenen Teilen deiner Dokumente. Was, wenn man für die Antwort die Zusammenhänge zwischen mehreren Artikeln verstehen muss?
Langkontextmodelle lösen das, indem sie alles auf einmal lesen. Kein Chunking, kein Abrufen, kein fehlender Kontext. Du lädst einfach alle deine Dokumente in eine einzige Eingabeaufforderung und lässt das Modell das ganze Bild sehen. Das Problem sind die Kosten. Bei der herkömmlichen Vorgehensweise wird die Verarbeitung von mehr als 50.000 Tokens schnell teuer.
Hier checken wir mal die spärliche Aufmerksamkeit von DeepSeek. Wir machen eine App, die drei Forschungsarbeiten (insgesamt ungefähr 57.000 Token) in einen einzigen Kontext lädt und vergleicht, wie vier Modelle mit derselben Anfrage umgehen: GPT-5, Claude Sonnet 4.5, DeepSeek v3.2-Exp (mit spärlicher Aufmerksamkeit) und DeepSeek v3.1-Terminus (die vorherige Version ohne spärliche Aufmerksamkeit). Du siehst die Kostenunterschiede, Reaktionszeiten und die Ausgabequalität im Vergleich.
So sieht die fertige Anwendung aus:
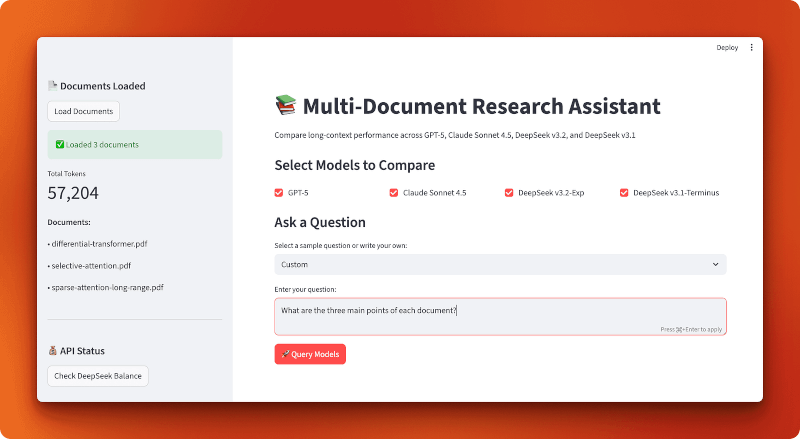
Anmerkung: Der Rest dieses Abschnitts zeigt dir genau, wie du diese App von Grund auf neu erstellen kannst. Du musst es nicht erstellen, um die Vergleichsergebnisse zu verstehen, aber wenn du dir den Code anschaust, bekommst du praktische Muster für die Erstellung deiner eigenen Anwendungen mit langem Kontext mit DeepSeek.
Wir machen das als Streamlit-App mit drei Modulen: eins zum Laden von Dokumenten, eins für die Modellkonfiguration und eins für die Abfrageverarbeitung. Der Ablauf ist echt einfach: PDFs laden, Modelle auswählen, eine Frage stellen und die Ergebnisse vergleichen.
Mach zuerst ein Projektverzeichnis und installiere die Abhängigkeiten:
mkdir multi-document-qa
cd multi-document-qa
uv add streamlit langchain langchain-openai langchain-anthropic langchain-community pypdf tiktoken python-dotenv matplotlib pandasMach eine Datei namens „ .env “ mit deinen API-Schlüsseln:
OPENAI_API_KEY=your_openai_key
ANTHROPIC_API_KEY=your_anthropic_key
DEEPSEEK_API_KEY=your_deepseek_keyLade drei Forschungsarbeiten zu Aufmerksamkeitsmechanismen runter:
mkdir documents
cd documents
curl -L -o selective-attention.pdf "https://arxiv.org/pdf/2410.02703"
curl -L -o differential-transformer.pdf "https://arxiv.org/pdf/2410.05258"
curl -L -o sparse-attention-long-range.pdf "https://arxiv.org/pdf/2406.16747"
cd ..Diese drei Dokumente haben zusammen 57.204 Token, wenn sie geladen werden.
Erstell die Datei „ document_loader.py “:
from langchain_community.document_loaders import PyPDFLoader
import tiktoken
from pathlib import Path
def load_documents(documents_dir="documents"):
docs_path = Path(documents_dir)
pdf_files = list(docs_path.glob("*.pdf"))
all_text = ""
document_names = []
# Load each PDF and concatenate with separators
for pdf_file in sorted(pdf_files):
loader = PyPDFLoader(str(pdf_file))
pages = loader.load()
doc_text = "\n\n".join([page.page_content for page in pages])
all_text += f"\n\n=== Document: {pdf_file.name} ===\n\n{doc_text}"
document_names.append(pdf_file.name)Die Funktion lädt alle PDFs aus einem Verzeichnis, holt den Text von jeder Seite raus und hängt alles mit Dokumententrennzeichen zusammen.
# Count tokens using GPT-4 encoding (accurate across providers)
encoding = tiktoken.encoding_for_model("gpt-4")
token_count = len(encoding.encode(all_text))
return all_text, token_count, document_namesDie Token-Zählung nutzt tiktoken mit GPT-4-Kodierung, was genaue Schätzungen für alle Anbieter liefert, weil sie eine ähnliche Tokenisierung verwenden. Schau dir das komplette document_loader.py auf GitHub an.
Erstell die Datei „ model_config.py “:
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
import os
# Pricing per million tokens (as of October 2025)
MODEL_PRICING = {
"gpt-5": {"input": 2.50, "output": 10.00, "name": "GPT-5"},
"claude-sonnet-4-5-20250929": {"input": 3.00, "output": 15.00, "name": "Claude Sonnet 4.5"},
"deepseek-chat": {"input": 0.28, "output": 0.42, "name": "DeepSeek v3.2-Exp"},
"deepseek-chat-v3.1": {"input": 0.55, "output": 2.19, "name": "DeepSeek v3.1-Terminus"},
}Das Preiswörterbuch zeigt die Kosten pro Million Token an (Stand: Oktober 2025). DeepSeek v3.2 mit Sparse Attention ist ungefähr 10 Mal günstiger als GPT-5 und Claude, während v3.1 mit dem doppelten Preis von v3.2 dazwischen liegt.
def get_model(model_name):
"""Initialize a chat model by name using LangChain's unified interface."""
if model_name == "gpt-5":
return ChatOpenAI(model="gpt-5", temperature=0, api_key=os.getenv("OPENAI_API_KEY"))
elif model_name == "claude-sonnet-4-5-20250929":
return ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0,
api_key=os.getenv("ANTHROPIC_API_KEY"))
elif model_name == "deepseek-chat":
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com")
elif model_name == "deepseek-chat-v3.1":
# Note: v3.1-Terminus endpoint expires on October 15, 2025
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015")
def calculate_cost(model_name, input_tokens, output_tokens):
"""Calculate total cost based on input and output token usage."""
pricing = MODEL_PRICING[model_name]
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return input_cost + output_costDie Funktion „ get_model() ” macht jedes Modell über die einheitliche Schnittstelle von LangChain startklar. DeepSeek-Modelle nutzen OpenAI-kompatible Endpunkte mit benutzerdefinierten Basis-URLs. Anmerkung: Der Endpunkt v3.1-Terminus läuft am 15. Oktober 2025 ab. Das komplette model_config.py Skript ist auf GitHub.
Erstell die Datei „ query_handler.py “:
import time
from langchain_core.messages import SystemMessage, HumanMessage
from model_config import get_model, calculate_cost, MODEL_PRICING
def query_model(model_name, context, question):
"""Query a model with document context and track performance metrics."""
model = get_model(model_name)
# Embed full document context in system prompt
system_prompt = f"""Use the given context to answer the question.
If you don't know the answer, say you don't know. Keep the answer concise.
Context:
{context}"""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=question)
]
# Track response time
start_time = time.time()Das System-Prompt packt alle 57.000 Token der Dokumente rein. Traditionell wird jedes Zeichen mit jedem anderen Zeichen verglichen. DeepSeek v3.2 ignoriert unwichtige Verbindungen und spart so Kosten.
try:
response = model.invoke(messages)
elapsed_time = time.time() - start_time
# Extract token usage (different providers use different formats)
if hasattr(response, 'response_metadata') and 'token_usage' in response.response_metadata:
token_usage = response.response_metadata['token_usage']
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
elif hasattr(response, 'usage_metadata'):
input_tokens = response.usage_metadata.get('input_tokens', 0)
output_tokens = response.usage_metadata.get('output_tokens', 0)
# Calculate total cost
cost = calculate_cost(model_name, input_tokens, output_tokens)
return {
"model": MODEL_PRICING[model_name]["name"],
"response": response.content,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"cost": cost,
"time": elapsed_time,
"error": None
}Verschiedene LangChain-Integrationen zeigen die Token-Nutzung in unterschiedlichen Formaten an (OpenAI nutzt response_metadata, Anthropic nutzt usage_metadata), also checken wir beide. Die Funktion misst die Zeit, zählt die Token, rechnet die Kosten aus und gibt ein Wörterbuch mit allen Metriken zurück. Schau dir die komplette query_handler.py auf GitHub an.
Erstell die Datei „ app.py “:
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
from document_loader import load_documents
from query_handler import query_model
from dotenv import load_dotenv
# Load API keys from .env file
load_dotenv()
# Configure Streamlit page with wide layout
st.set_page_config(
page_title="Multi-Document Research Assistant",
page_icon="📚",
layout="wide"
)
st.title("📚 Multi-Document Research Assistant")
st.markdown("Compare long-context performance across GPT-5, Claude Sonnet 4.5, DeepSeek v3.2, and DeepSeek v3.1")Standardmäßige Streamlit-Einrichtung mit breitem Layout für Vergleiche nebeneinander.
# Sidebar for document loading
with st.sidebar:
st.header("📄 Documents Loaded")
if st.button("Load Documents"):
with st.spinner("Loading documents..."):
# Load all PDFs and count tokens
context, token_count, doc_names = load_documents("documents")
st.session_state.context = context
st.session_state.token_count = token_count
st.session_state.doc_names = doc_names
# Display loaded documents info
if "token_count" in st.session_state:
st.success(f"✅ Loaded {len(st.session_state.doc_names)} documents")
st.metric("Total Tokens", f"{st.session_state.token_count:,}")
st.write("**Documents:**")
for name in st.session_state.doc_names:
st.write(f"• {name}")Die Seitenleiste lädt Dokumente und zeigt die Anzahl der Token an. Der Sitzungsstatus von Streamlit sorgt dafür, dass Dokumente zwischen den Interaktionen geladen bleiben.
# Main content area
if "context" not in st.session_state:
st.info("👈 Click 'Load Documents' in the sidebar to begin")
else:
st.subheader("Select Models to Compare")
col1, col2, col3, col4 = st.columns(4)
# Model selection checkboxes
with col1:
use_gpt5 = st.checkbox("GPT-5", value=True)
with col2:
use_claude = st.checkbox("Claude Sonnet 4.5", value=True)
with col3:
use_deepseek_v32 = st.checkbox("DeepSeek v3.2-Exp", value=True)
with col4:
use_deepseek_v31 = st.checkbox("DeepSeek v3.1-Terminus", value=True)
# Sample questions for quick testing
sample_questions = [
"Compare the main approaches to attention mechanisms described in these documents",
"What are the key differences between sparse and dense attention?",
"Summarize the common themes across all documents"
]Vier Kästchen zum Ankreuzen für die Modellauswahl und vorgefertigte Beispielfragen.
# Question input with samples
question_choice = st.selectbox(
"Select a sample question or write your own:",
["Custom"] + sample_questions
)
if question_choice == "Custom":
question = st.text_area("Enter your question:", height=100)
else:
question = st.text_area("Enter your question:", value=question_choice, height=100)
# Query button and model execution
if st.button("🚀 Query Models", type="primary"):
if not question:
st.error("Please enter a question")
else:
# Build list of selected models
selected_models = []
if use_gpt5:
selected_models.append("gpt-5")
if use_claude:
selected_models.append("claude-sonnet-4-5-20250929")
if use_deepseek_v32:
selected_models.append("deepseek-chat")
if use_deepseek_v31:
selected_models.append("deepseek-chat-v3.1")Die Leute suchen sich eine Frage aus oder schreiben ihre eigene und klicken dann auf „Modelle abfragen“, um den Vergleich für die ausgewählten Modelle zu starten.
results = []
# Query each model sequentially with progress indicator
for model_name in selected_models:
with st.spinner(f"Querying {model_name}..."):
result = query_model(
model_name,
st.session_state.context,
question
)
results.append(result)
# Store results in session state for persistence
st.session_state.results = resultsJedes Modell wird nacheinander abgefragt, wobei ein Spinner den Fortschritt anzeigt.
# Display results if available
if "results" in st.session_state:
st.divider()
st.subheader("📊 Results")
results = st.session_state.results
# Show model responses in expandable panels
st.markdown("### Responses")
for result in results:
with st.expander(f"**{result['model']}** - ${result['cost']:.4f} | {result['time']:.2f}s"):
if result['error']:
st.error(f"Error: {result['error']}")
else:
st.write(result['response'])
# Create metrics comparison table
metrics_df = pd.DataFrame([
{
"Model": r['model'],
"Input Tokens": r['input_tokens'],
"Output Tokens": r['output_tokens'],
"Total Tokens": r['total_tokens'],
"Cost ($)": f"${r['cost']:.4f}",
"Time (s)": f"{r['time']:.2f}"
}
for r in results
])
st.dataframe(metrics_df, use_container_width=True)Die Ergebnisse zeigen die Reaktion jedes Modells in ausklappbaren Feldern mit Kosten und Zeitangaben in der Kopfzeile, gefolgt von einer sortierbaren Metrik-Tabelle.
# Create visualization charts
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Chart 1: Cost comparison bar chart
axes[0, 0].bar([r['model'] for r in results], [r['cost'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 0].set_title('Cost Comparison')
axes[0, 0].set_ylabel('Cost ($)')
axes[0, 0].tick_params(axis='x', rotation=45)
# Chart 2: Response time bar chart
axes[0, 1].bar([r['model'] for r in results], [r['time'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 1].set_title('Response Time Comparison')
axes[0, 1].set_ylabel('Time (seconds)')
# Chart 3: Token usage grouped bar chart
models = [r['model'] for r in results]
input_tokens = [r['input_tokens'] for r in results]
output_tokens = [r['output_tokens'] for r in results]
x = range(len(models))
width = 0.35
axes[1, 0].bar([i - width/2 for i in x], input_tokens, width, label='Input', color='#1f77b4')
axes[1, 0].bar([i + width/2 for i in x], output_tokens, width, label='Output', color='#ff7f0e')
axes[1, 0].set_title('Token Usage Comparison')
axes[1, 0].legend()Vier Matplotlib-Diagramme in einem 2x2-Raster: Kostenbalken, Zeitbalken, gruppierte Token-Verbrauchsbalken und ein Streudiagramm für Kosten im Vergleich zur Zeit.
# Chart 4: Cost vs time tradeoff scatter plot
axes[1, 1].scatter([r['cost'] for r in results], [r['time'] for r in results],
s=100, alpha=0.6, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
for i, r in enumerate(results):
axes[1, 1].annotate(r['model'], (r['cost'], r['time']), fontsize=8, ha='right')
axes[1, 1].set_title('Cost vs Time Trade-off')
axes[1, 1].set_xlabel('Cost ($)')
axes[1, 1].set_ylabel('Time (seconds)')
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
st.pyplot(fig)
# Display key findings
if len(results) > 1:
cheapest = min(results, key=lambda x: x['cost'])
fastest = min(results, key=lambda x: x['time'])
col1, col2 = st.columns(2)
with col1:
st.metric("Most Cost-Effective", cheapest['model'], f"${cheapest['cost']:.4f}")
with col2:
st.metric("Fastest Response", fastest['model'], f"{fastest['time']:.2f}s")Die wichtigsten Ergebnisse zeigen automatisch die günstigsten und schnellsten Modelle an. Schau dir die komplette app.py auf GitHub ansehen.
Starte die App:
streamlit run app.pyKlick auf „Dokumente laden“, um die drei PDF-Dateien (insgesamt 57.204 Token) zu laden. Wähle die Modelle aus, die du vergleichen willst (standardmäßig alle vier), denk dir eine Frage aus oder schreib eine, und klick dann auf „Modelle abfragen”.
Erwartete Antwortzeiten für einen Kontext mit 57.000 Token:
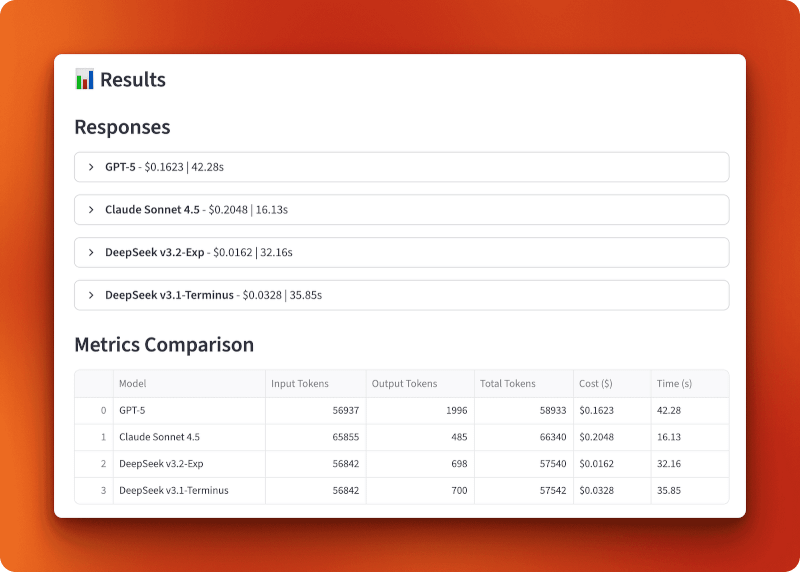
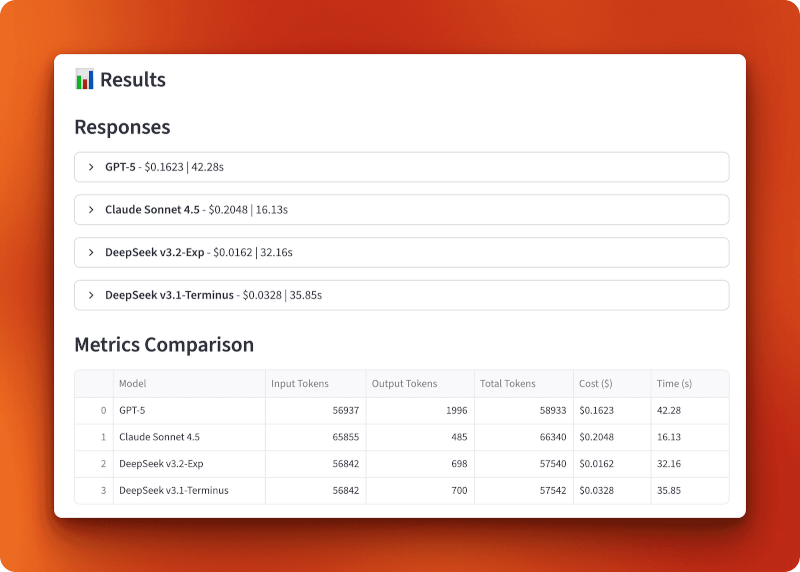
GPT-5 hat 56.937 Eingabetoken verarbeitet und 1.996 Ausgabetoken für 0,1623 $ in 42,28 Sekunden gemacht. Claude Sonnet 4.5 hat 65.855 Eingabetoken verarbeitet und 485 Ausgabetoken für 0,2048 $ in 16,13 Sekunden erzeugt – am schnellsten, aber auch am teuersten. DeepSeek v3.2-Exp hat 56.842 Eingabetoken verarbeitet und 698 Ausgabetoken in nur 32,16 Sekunden für nur 0,0162 $ erzeugt. DeepSeek v3.1-Terminus hat 56.842 Eingabetoken verarbeitet und 700 Ausgabetoken für 0,0328 $ in 35,85 Sekunden erzeugt.
Der Vergleich zwischen Version 3.1 und Version 3.2 zeigt, wie sich die spärliche Aufmerksamkeit auswirkt. Beide haben die gleichen Eingaben verarbeitet und fast die gleichen Ausgaben erzeugt (698 gegenüber 700 Tokens), aber v3.2 hat nur halb so viel gekostet (0,0162 $ gegenüber 0,0328 $) und lief etwas schneller (32,16 s gegenüber 35,85 s). Das ist eine Kostenreduzierung um das Doppelte gegenüber der spärlichen Aufmerksamkeit allein.
Im Vergleich zu GPT-5 und Claude ist v3.2 zehnmal günstiger als GPT-5 (0,0162 $ gegenüber 0,1623 $) und dreizehnmal günstiger als Claude (0,0162 $ gegenüber 0,2048 $). Bei über 100 Abfragen dieser Länge würdest du mit DeepSeek v3.2 16,20 $ ausgeben, während es mit GPT-5 162,30 $ und mit Claude 204,80 $ wären.
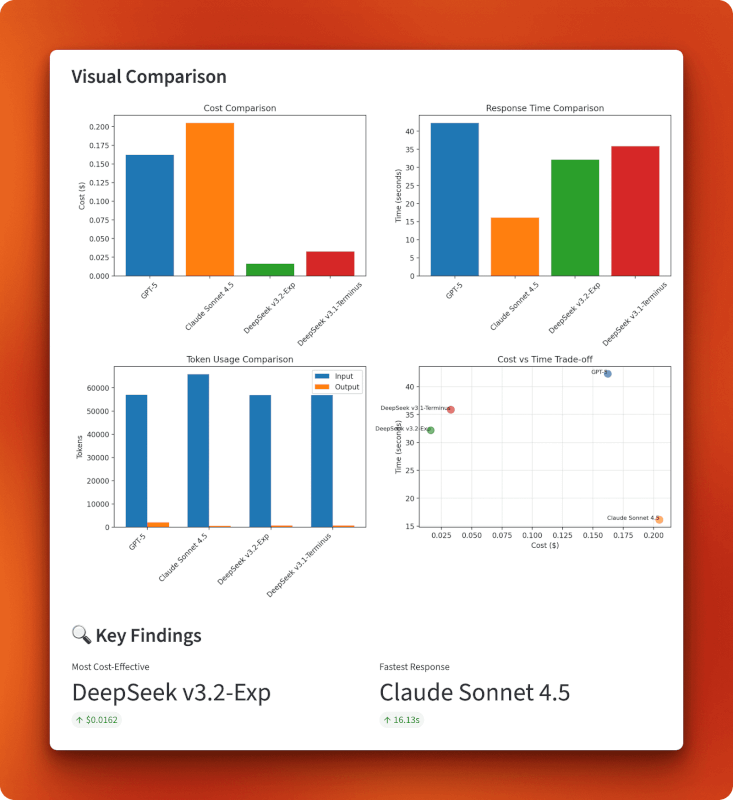
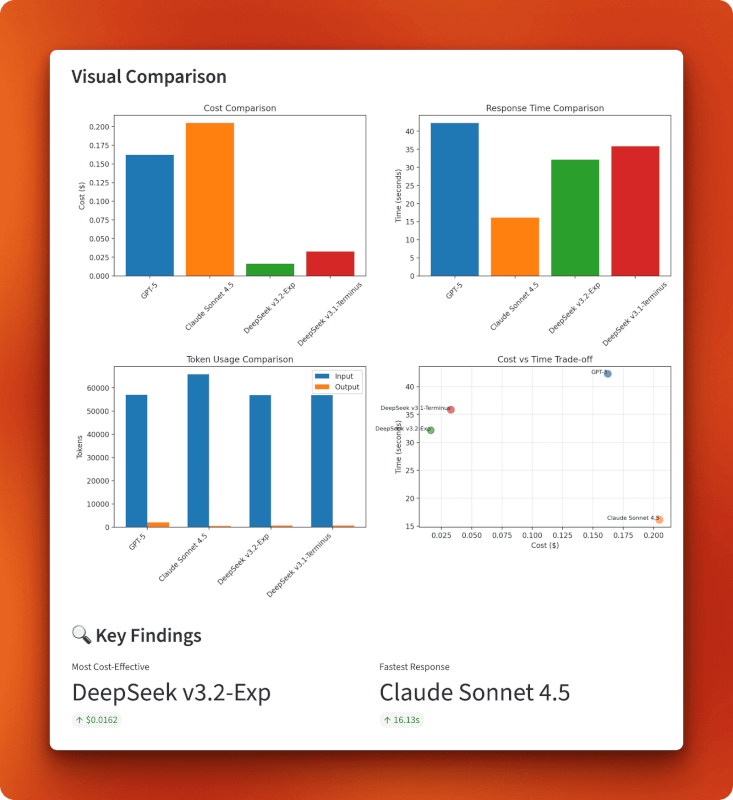
Die Diagramme zeigen, dass DeepSeek v3.2 im unteren linken Quadranten des Kosten-Zeit-Verhältnisses liegt: Mit 0,0162 US-Dollar ist es insgesamt am günstigsten und hat trotzdem eine gute Geschwindigkeit von 32 Sekunden. Claude setzt auf Geschwindigkeit statt auf Kosten (teuer, aber am schnellsten), GPT-5 hinkt in beiden Bereichen hinterher (teuer und am langsamsten) und v3.1 liegt dazwischen. Die Grafik zur Token-Nutzung zeigt, dass alle Modelle ähnliche Eingabegrößen verarbeiten, aber die Ausgabelängen unterschiedlich sind – GPT-5 hat mit 1.996 Token die längste Antwort generiert, Claude hat sich mit 485 Token kurz gefasst und beide DeepSeek-Versionen haben ähnliche Ausgaben mit etwa 700 Token produziert.
Das Laden vollständiger Dokumente in den Kontext funktioniert am besten, wenn du ein dokumentübergreifendes Verständnis brauchst. Wenn deine Frage Ideen aus drei verschiedenen Artikeln miteinander verbinden muss, könnten diese Verbindungen beim Chunking und Abrufen übersehen werden. Das Model muss alles auf einen Blick sehen können.
Dieses Muster passt zu mehreren Anwendungsfällen:
Der Ansatz klappt nicht so gut, wenn:
Die spärliche Aufmerksamkeit von DeepSeek verändert die Wirtschaftlichkeit der Verarbeitung langer Kontexte. Was früher 0,15 bis 0,20 Dollar pro Abfrage gekostet hat, kostet jetzt nur noch 0,01 bis 0,02 Dollar. Das macht Ansätze mit vollem Kontext praktisch für Anwendungen, die täglich Hunderte oder Tausende von Abfragen ausführen.
DeepSeek v3.2 macht mit seiner spärlichen Aufmerksamkeit dasselbe Modell wie v3.1, kostet aber nur die Hälfte. Der von uns entwickelte Vergleich mehrerer Dokumente hat das in der Praxis gezeigt. Die Verarbeitung von 57.000 Tokens hat mit Version 3.2 0,0162 $ gekostet, während es mit Version 3.1 0,0328 $ waren. Beide Versionen haben fast die gleichen Ergebnisse gebracht. Im Vergleich zu GPT-5 und Claude ist v3.2 10- bis 13-mal günstiger und hat trotzdem vernünftige Antwortzeiten. Bei Anwendungen, die regelmäßig lange Kontexte verarbeiten, summieren sich diese Einsparungen schnell.
Wenn du an der Dokumentanalyse, an Recherchetools oder an einer Anwendung arbeitest, die mit langen Kontexten zu tun hat, solltest du v3.2 mal ausprobieren. Denk einfach dran, dass es noch im Versuchsstadium ist, also probier es aus, bevor du es in der Produktion einsetzt.
Wenn du mehr über die neuesten Entwicklungen im Bereich KI erfahren willst, schau dir diese Blogs an:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Moez Ali
