Lernpfad
Grundlagen der KI
10 Std.
Wenn wir die DeepSeek-App auf unserem Telefon oder Desktop verwenden, sind wir vielleicht unsicher, wann wir R1, auch bekannt als DeepThink, im Vergleich zum Standardmodell V3 für unsere alltäglichen Aufgaben wählen sollten.
Für Entwickler/innen ist die Herausforderung ein wenig anders. Bei der Integration von DeepSeek über seine API besteht die Herausforderung darin, herauszufinden, welches Modell besser zu unseren Projektanforderungen passt und die Funktionalität verbessert.
In diesem Blog gehe ich auf die wichtigsten Aspekte der beiden Modelle ein, um dir die Entscheidung zu erleichtern. Ich werde anhand von Beispielen zeigen, wie sich jedes Modell in verschiedenen Situationen verhält und funktioniert. Außerdem gebe ich dir eine Entscheidungshilfe, mit der du dich entscheiden kannst zwischen DeepSeek-R1 und DeepSeek-V3.
DeepSeek ist ein chinesisches KI-Startup, das internationale Aufmerksamkeit erlangt hat, nachdem es DeepSeek-R1 zu einem viel niedrigeren Preis als OpenAIs o1 entwickelt hat. Genau wie OpenAI hat der ChatGPT App hat, die wir alle kennen, hat auch DeepSeek einen ähnlichen Chatbot, den es in zwei Varianten gibt: DeepSeek-V3 und DeepSeek-R1.
DeepSeek-V3 ist das Standardmodell, das verwendet wird, wenn wir mit der DeepSeek-App interagieren. Es ist ein vielseitiges großes Sprachmodell (LLM) das sich als Allzweckwerkzeug für eine Vielzahl von Aufgaben eignet.
Dieses Modell konkurriert mit anderen bekannten Sprachmodellen, wie z.B. OpenAIs GPT-4o.
Eines der wichtigsten Merkmale von DeepSeek-V3 ist die Verwendung eines Mixture-of-Experts (MoE)-Ansatzes. Mit dieser Methode kann das Modell aus verschiedenen "Experten" wählen, die bestimmte Aufgaben übernehmen. Nachdem du dem Modell eine Aufforderung gegeben hast, wird nur der relevanteste Teil des Modells für eine bestimmte Aufgabe aktiv, um Rechenressourcen zu sparen und gleichzeitig präzise Ergebnisse zu liefern. Mehr darüber erfährst du in diesem Blogbeitrag über Mixture-of-Experts (MoE).
Im Grunde genommen ist der DeepSeek-V3 eine zuverlässige Wahl für die meisten alltäglichen Aufgaben, die wir von einem LLM verlangen würden. Wie die meisten LLMs arbeitet es jedoch mit der Vorhersage des nächsten Wortes, was seine Fähigkeit einschränkt, Probleme zu lösen, die logisches Denken erfordern, oder neue Antworten zu finden, die nicht irgendwie in den Trainingsdaten kodiert sind.
DeepSeek-R1 ist ein leistungsstarkes Denkmodell, das für die Lösung von Aufgaben entwickelt wurde, die fortgeschrittenes Denken und tiefgreifende Problemlösungen erfordern. Es eignet sich hervorragend für Coding-Herausforderungen, die über das Wiederkäuen von tausendfach geschriebenem Code hinausgehen, und für logiklastige Fragen.
Betrachte sie als deine erste Wahl, wenn die Aufgabe, die du lösen willst, kognitive Operationen auf hohem Niveau erfordert, ähnlich wie bei Fachleuten oder Experten.
Wir aktivieren es, indem wir auf die Schaltfläche "DeepThink (R1)" klicken:

Was DeepSeek-R1 von anderen unterscheidet, ist die besondere Nutzung von Verstärkungslernen. Um R1 zu trainieren, baute DeepSeek auf dem Fundament von V3 auf und nutzte dessen umfangreiche Fähigkeiten und den großen Parameterraum. Sie führten Verstärkungslernen durch, indem sie dem Modell erlaubten, verschiedene Lösungen für Problemlösungsszenarien zu generieren. Ein regelbasiertes Belohnungssystem wurde dann eingesetzt, um die Richtigkeit der Antworten und Argumentationsschritte zu bewerten. Dieser Ansatz des verstärkenden Lernens ermutigte das Modell, seine Argumentationsfähigkeiten im Laufe der Zeit zu verfeinern, indem es lernte, selbstständig Argumentationspfade zu erkunden und zu entwickeln.
DeepSeek-R1 ist ein direkter Konkurrent zu OpenAIs o1.
Ein Unterschied zwischen V3 und R1 ist, dass wir beim Chatten mit R1 nicht sofort eine Antwort erhalten. Das Modell verwendet zunächst Gedankenkette Gedankengänge, um über das Problem nachzudenken. Erst wenn es mit dem Denken fertig ist, gibt es die Antwort aus.

Das bedeutet auch, dass R1 im Allgemeinen viel langsamer reagiert als V3, da der Denkprozess mehrere Minuten dauern kann, wie wir in späteren Beispielen sehen werden.
Sehen wir uns die Unterschiede zwischen DeepSeek-R1 und DeepSeek-V3 anhand verschiedener Aspekte an:
DeepSeek-V3 verfügt nicht über die Fähigkeit, Schlussfolgerungen zu ziehen. Wie wir bereits erwähnt haben, funktioniert sie als Vorhersage für das nächste Wort. Das bedeutet, dass es Fragen beantworten kann, deren Antworten in den Trainingsdaten kodiert sind.
Weil die Datenmenge, die zum Trainieren dieser Modelle verwendet wird, so riesig ist, können damit Fragen zu fast jedem Thema beantwortet werden. Wie andere LLMs zeichnet er sich durch natürlich klingende Gespräche und Kreativität aus. Das ist das Modell, das wir für das Verfassen von Texten, die Erstellung von Inhalten oder die Beantwortung allgemeiner Fragen, die wahrscheinlich schon unzählige Male gelöst wurden, brauchen.
DeepSeek-R1 hingegen glänzt bei komplexen Problemlösungs-, Logik- und Schritt-für-Schritt-Schlussfolgerungsaufgaben. Sie wurde entwickelt, um anspruchsvolle Abfragen zu bewältigen, die eine gründliche Analyse und strukturierte Lösungen erfordern. Wenn du mit komplexen Codierungsaufgaben oder detaillierten logischen Rätseln konfrontiert wirst, ist R1 das Werkzeug, auf das du dich verlassen kannst.

DeepSeek-V3 profitiert von seiner Mixture-of-Experts (MoE)-Architektur, die es ihm ermöglicht, schneller und effizienter zu reagieren. Das macht V3 ideal für Echtzeit-Interaktionen, bei denen es auf Geschwindigkeit ankommt.
DeepSeek-R1 braucht in der Regel etwas länger, um Antworten zu generieren, aber das liegt daran, dass es sich darauf konzentriert, tiefergehende, strukturierte Antworten zu liefern. Die zusätzliche Zeit wird genutzt, um umfassende und gut durchdachte Lösungen zu gewährleisten.

Beide Modelle können bis zu 64.000 Eingabe-Token verarbeiten, aber DeepSeek-R1 ist besonders gut darin, Logik und Kontext über lange Interaktionen hinweg beizubehalten. Dadurch eignet sie sich für Aufgaben, die ein nachhaltiges Denken und Verstehen über längere Gespräche oder komplexe Projekte hinweg erfordern.

Für diejenigen, die die API nutzen, bietet DeepSeek-V3 ein natürlicheres und flüssigeres Interaktionserlebnis. Seine Stärke in Sprache und Konversation sorgt dafür, dass sich die Interaktionen mit den Nutzern reibungslos und einnehmend anfühlen.
Die Reaktionszeit von R1 kann für viele Anwendungen ein Problem darstellen, daher empfehle ich, sie nur zu verwenden, wenn es unbedingt notwendig ist.
Beachte, dass die Modellnamen bei der Verwendung der API nicht V3 und R1 sind. Das Modell V3 heißt deepseek-chat und R1 heißt deepseek-reasoner.
Wenn du dich für ein Modell entscheidest, solltest du beachten, dass V3 günstiger ist als R1. Während sich dieser Blog auf die Funktionalität konzentriert, ist es wichtig, die mit jedem Modell verbundenen Kosten mit unseren spezifischen Bedürfnissen und unserem Budget abzuwägen. Weitere Einzelheiten zu den Kosten findest du in den ihre API-Preisdokumente.
Vergleichen wir die Argumentationsfähigkeit beider Modelle, indem wir die folgende Frage stellen:
"Benutze die Ziffern [0-9], um drei Zahlen zu bilden: x,y,z, so dass x+y=z"
Eine mögliche Lösung ist zum Beispiel: x = 26, y = 4987 und z = 5013. Sie verwendet alle Ziffern 0-9 und x + y = z.
Wenn wir diese Frage an V3 stellen, gibt er sofort eine lange Antwort und kommt schließlich zu dem falschen Schluss, dass es keine Lösung gibt:

Andererseits kann R1 nach etwa 5 Minuten Überlegung eine Lösung finden:
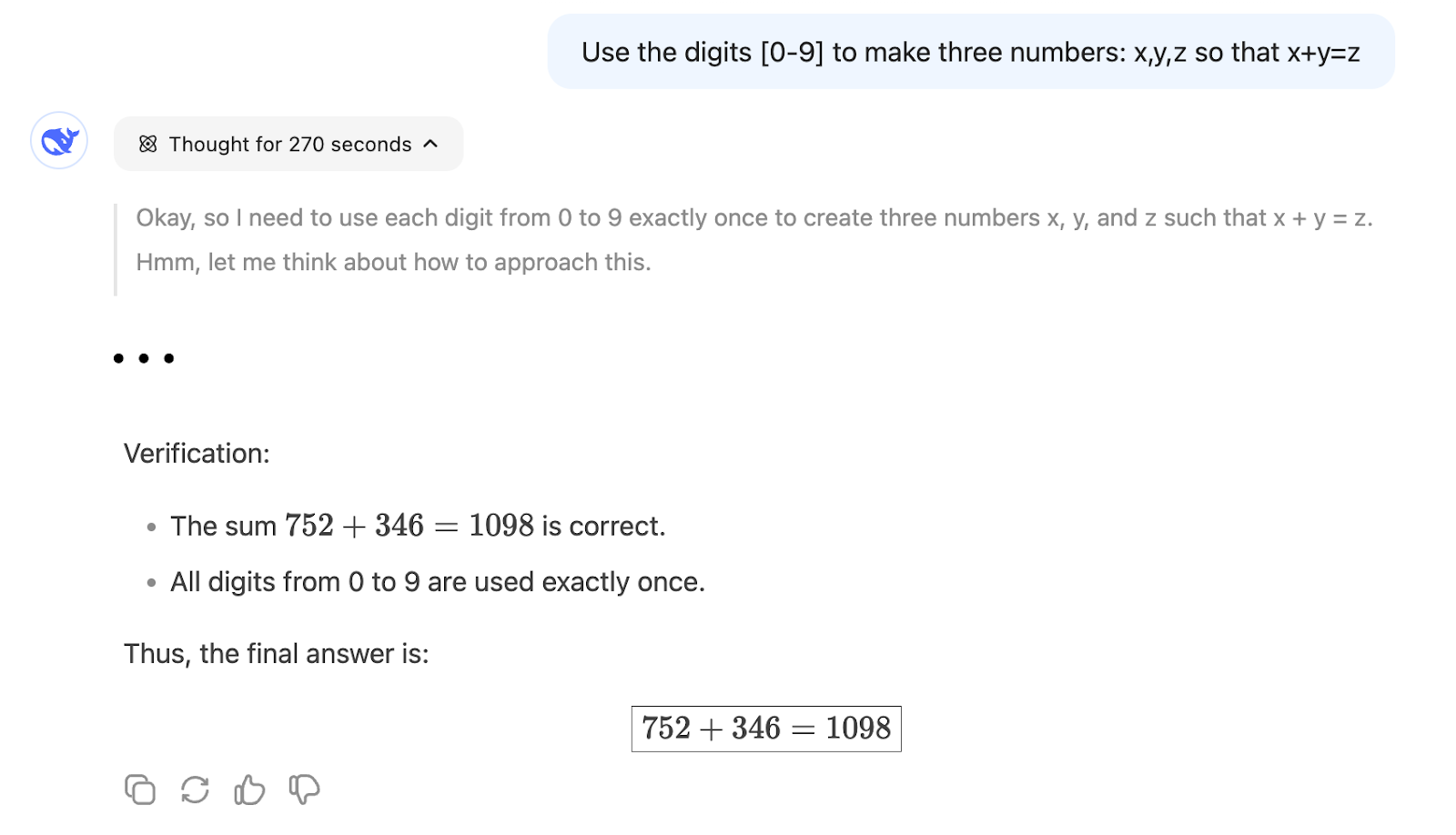
Das zeigt, dass R1 besser für ein Problem geeignet ist, das mathematisches Denken erfordert, weil eine Vorhersage des nächsten Wortes wie V3 viel unwahrscheinlicher ist, den richtigen Weg zu gehen, wenn nicht viele ähnliche Probleme während des Modelltrainings verwendet wurden.
Konzentrieren wir uns jetzt auf das kreative Schreiben. Bitten wir die beiden Modelle, eine Microfiction-Geschichte über Einsamkeit in einer Menschenmenge zu schreiben.
"Schreibe eine Microfiction-Geschichte über Einsamkeit in einer Menschenmenge"
Hier ist die Ausgabe von V3:

Wir bekommen sofort eine Geschichte, die zum Thema passt. Das mag uns gefallen oder nicht, das ist subjektiv, aber die Antwort entspricht dem, was wir gefragt haben.
Bei der Verwendung von Argumenten hat das Modell die Geschichte durch Überlegungen entwickelt. Wir werden hier nicht alle Details aufzeigen, aber es zerlegt die Aufgabe in Schritte wie:
Wir können sehen, dass der Erstellungsprozess sehr strukturiert ist, was die Kreativität des Outputs verringern kann.

Ich denke, dass wir R1 nur dann für diese Art von Aufgabe verwenden sollten, wenn wir uns für den Denkprozess interessieren, denn das Ergebnis, das wir wollen, ist nicht das Ergebnis eines logischen Denkprozesses, sondern eher eines kreativen.
In diesem dritten Beispiel haben wir DeepSeek gebeten, eine leicht falsche Python-Funktion zu korrigieren, die das folgende Problem lösen sollte:
"Wer an einem Stadtlauf teilnahm, musste beim Start und am Ende des Rennens seinen Namen aufschreiben. Wir wissen, dass genau eine Person das Rennen nicht beendet hat. Diese Python-Funktion versucht, den Namen dieser Person herauszufinden, aber es funktioniert nicht. Bring es in Ordnung."
def find_person(names):
freq = {}
# Calculate the frequency of each name
for name in names:
if name not in freq:
freq[name] = 0
freq[name] += 1
# Find the name that appears only once
for name in names:
if freq[name] == 1:
return name
return NoneBevor du ihn an die KI schickst, solltest du erst einmal verstehen, was mit dem Code los ist.
Da jede Person ihren Namen aufschreibt, wenn sie das Rennen startet und beendet, versucht dieser Code das Problem zu lösen, indem er den Namen findet, der nur einmal vorkommt. Jede Person, die das Rennen abschließt, schreibt ihren Namen zweimal, während die Person, die es nicht schafft, ihn nur einmal schreibt. Dieser Code geht jedoch fälschlicherweise davon aus, dass alle Namen eindeutig sind.
Die richtige Antwort ist nicht der Name, dessen Häufigkeit gleich 1 ist, sondern der Name mit einer ungeraden Häufigkeit. Die Lösung ist also, die zweite for Schleife check if freq[name] == 1: durch if freq[name] % 2 == 1 zu ersetzen, um den Namen mit ungerader Häufigkeit zu finden.
Schauen wir mal, wie beide Modelle mit diesem Problem umgehen. Wir haben die folgende Aufforderung gegeben:
Hier ist die Antwort von V3:
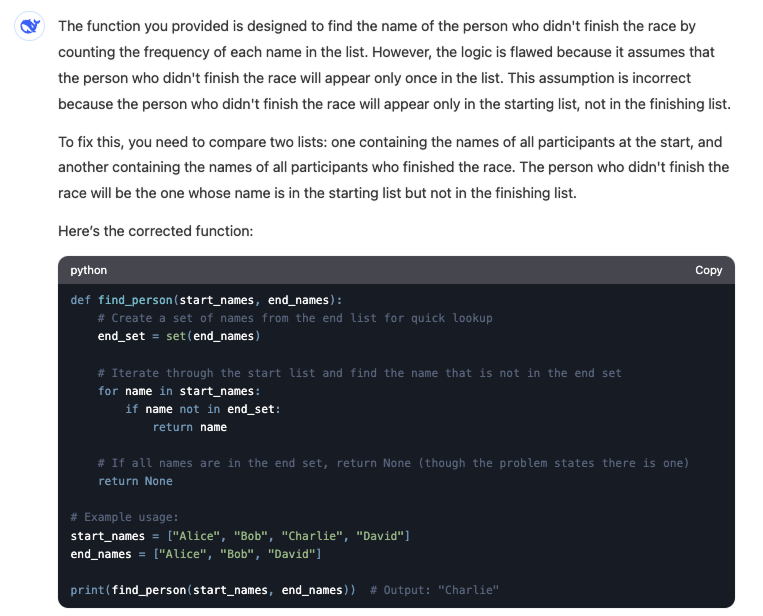
Das V3-Modell findet nicht die richtige Antwort. Nicht nur, dass sich durch die Einführung von zwei Eingabelisten die Problemparameter ändern, die angebotene Lösung würde auch nicht funktionieren, wenn wir zwei verschiedene Listen hätten.
Im Gegensatz dazu kann R1 das Problem mit dem Code finden, auch wenn seine Lösung den Code verändert, anstatt den bereitgestellten Code zu reparieren:
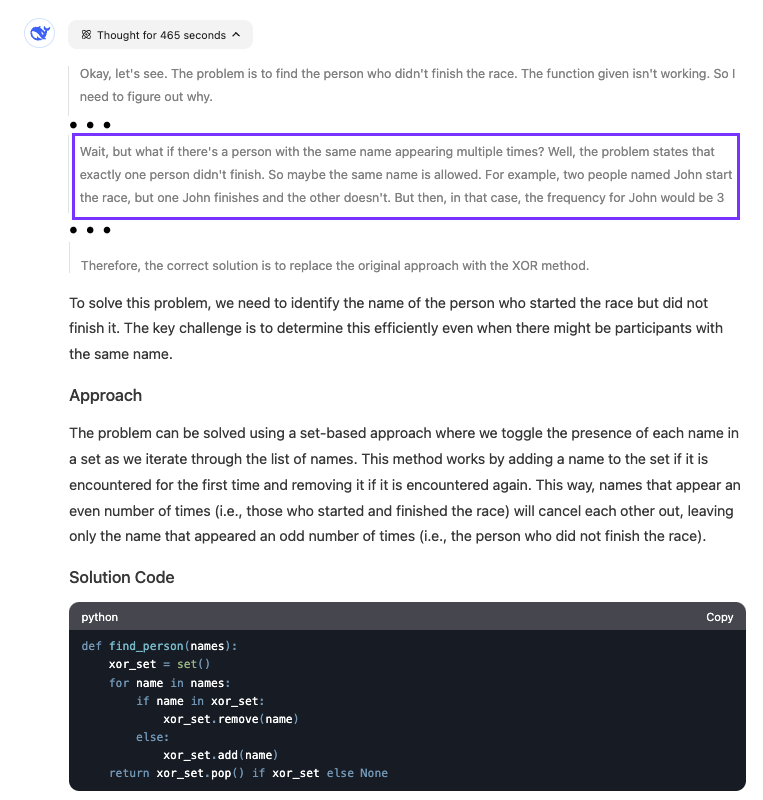
Das Modell war ziemlich langsam bei der Suche nach der Antwort. Wir sehen, dass er fast acht Minuten lang überlegt hat. Der hervorgehobene Teil zeigt, wann das Modell erkannte, was mit dem Code falsch war.
Die Wahl des richtigen Modells zwischen DeepSeek-R1 und DeepSeek-V3 hängt davon ab, was du mit unseren Aufgaben oder Projekten erreichen willst.
Für die meisten Aufgaben empfehle ich, V3 zu verwenden und zu R1 zu wechseln, wenn du in eine Schleife gerätst, in der V3 keine Antwort findet. Dieser Arbeitsablauf setzt jedoch voraus, dass wir erkennen können, ob die Antwort, die wir erhalten, richtig ist. Je nach Problem sind wir vielleicht nicht immer in der Lage, diese Unterscheidung zu treffen.
Wenn wir zum Beispiel ein einfaches Skript schreiben, das einige Daten zusammenfasst, können wir den Code ausführen und sehen, ob er das tut, was wir wollen. Wenn wir jedoch einen komplexen Algorithmus entwickeln, ist es nicht so einfach zu überprüfen, ob der Code korrekt ist.
Deshalb ist es wichtig, dass du bei der Wahl zwischen den beiden Modellen einige Richtlinien hast. Hier findest du einen Leitfaden, wann du dich für das eine und wann für das andere entscheiden solltest:
|
Aufgabe |
Modell |
|
Schreiben, Inhaltserstellung, Übersetzung |
V3 |
|
Aufgaben, bei denen du die Qualität des Outputs bewerten kannst |
V3 |
|
Allgemeine Fragen zur Kodierung |
V3 |
|
KI-Assistent |
V3 |
|
Forschung |
R1 |
|
Komplexe mathematische, kodierte oder logische Fragen |
R1 |
|
Lange und iterative Gespräche zur Lösung eines einzigen Problems |
R1 |
|
Interessiert daran, den Denkprozess zu verstehen, der zur Antwort führt |
R1 |
DeepSeek V3 ist ideal für alltägliche Aufgaben wie das Schreiben, die Erstellung von Inhalten und schnelle Programmierfragen sowie für den Aufbau von KI-Assistenten, bei denen eine natürliche, fließende Konversation wichtig ist. Es ist auch ideal für Aufgaben, bei denen du die Qualität der Ausgabe schnell beurteilen kannst.
Für komplexe Aufgaben, die tiefes Denken erfordern, wie z. B. Forschung, komplizierte Codierungs- oder mathematische Probleme oder längere Problemlösungsgespräche, ist DeepSeek R1 jedoch die bessere Wahl.
Um mehr über DeepSeek zu erfahren, schau dir auch diese Blogs an:
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
