
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.6K
Bevor du mit der Feinabstimmung des GPT-4o Mini-Modells beginnst, empfehlen wir schnelle Technik, promptes Verkettenund Funktionsaufrufe um die Modellantworten anzupassen und domänenspezifische Antworten zu erhalten.
Eine Feinabstimmung ist notwendig, wenn du den Stil, den Ton oder das Format anpassen möchtest. Sie wird eingesetzt, um die Zuverlässigkeit und Genauigkeit zu verbessern, komplexe Prompts zu bearbeiten oder eine neue Aufgabe zu erfüllen, die der Prompt-Engineer nicht lösen konnte.
In diesem Lernprogramm werden wir das GPT-4o Mini-Modell feinabstimmen, um Text in "Stress" und "Nicht-Stress" zu klassifizieren. Anschließend greifen wir über die OpenAI API und den OpenAI Playground auf das fein abgestimmte Modell zu. Schließlich bewerten wir das feinabgestimmte Modell, indem wir seine Leistung vor und nach der Abstimmung anhand verschiedener Klassifizierungsmetriken vergleichen.

Bild vom Autor
Das GPT-4o Mini ist das kostengünstigste allgemeinsprachliche Modell auf dem Markt. Es erreicht 82% auf dem MMLU und übertrifft derzeit die Claude 3.5 Sonnet bei den Chat-Einstellungen in der LMSYS-Rangliste. Der Preis liegt bei 15 Cent pro Million Input-Token und 60 Cent pro Million Output-Token, was 60% günstiger ist als GPT-3.5 Turbo.
Das GPT-4o mini unterstützt derzeit Text und Bilder als Eingabe. Das Modell hat ein Kontextfenster von 128K Token, unterstützt bis zu 16K Output-Token pro Anfrage und verfügt über Wissen bis zum Oktober 2023. GPT-4o Mini kann nicht-englischen Text verarbeiten, da es den GPT-4o Tokenizer verwendet. Wir bekommen das Beste aus beiden Welten zu einem niedrigen Preis.
In unserem Blog erfährst du mehr über den Anwendungsfall, die Chatvervollständigungs-API und detaillierte Benchmarks von GPT-4o Mini, Was ist GPT-4o Mini?
Gehe zur OpenAI Website und erstelle ein Konto. Die Feinabstimmung ist teuer und die Nutzung des GPT-4o Mini über die API erfordert, dass du eine Zahlungsmethode mit deinem Konto verknüpft hast. Um Probleme zu vermeiden, solltest du sicherstellen, dass du mindestens 10 USD Guthaben auf deinem Konto hast, bevor du versuchst, das Modell fein abzustimmen.
Gehe zum Haupt-Dashboard, klicke auf den Reiter "API-Schlüssel" und generiere den geheimen OpenAI-API-Schlüssel.
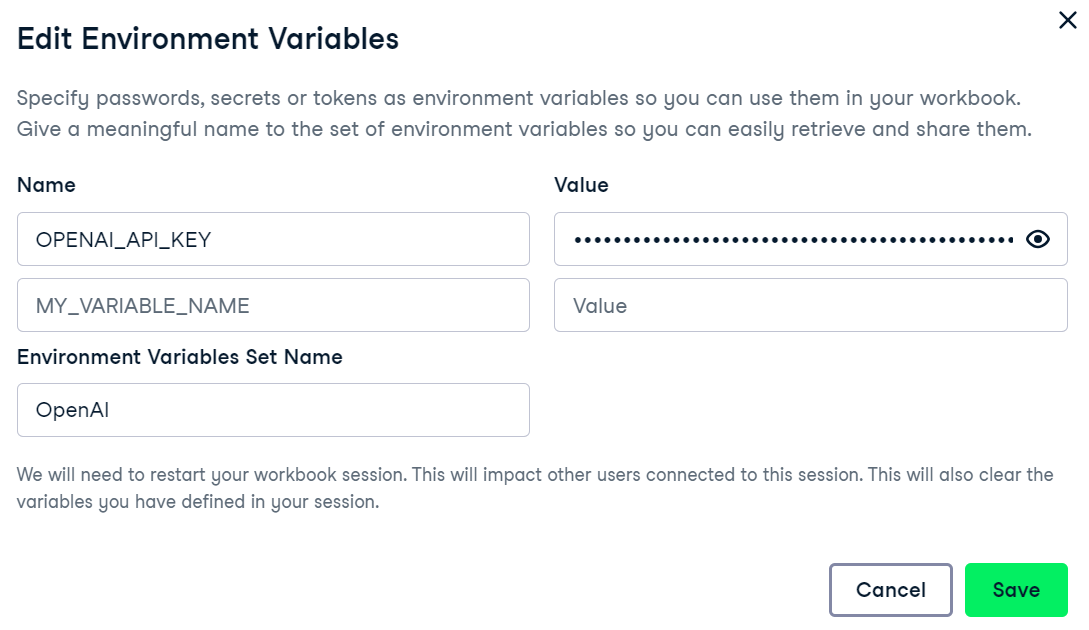
Wir verwenden DataCamp's DataLab als unseren Code-Editor. Um die Umgebungsvariable für den OpenAI API-Schlüssel einzurichten, gehst du auf die Registerkarte Umgebung und klickst auf die Option Umgebungsvariable. Füge dann die Umgebungsvariable für den API-Schlüssel hinzu und aktiviere sie wie unten gezeigt.
Installiere das OpenAI Python-Paket, um auf den GPT-4o Mini zuzugreifen.
%%capture
%pip install openai
Erstelle den Client mit dem OpenAI-API-Schlüssel und generiere eine Antwort mit der Musteraufforderung. Die Chatvervollständigungsfunktion benötigt den Modellnamen und die Nachrichten in einer Liste im Wörterbuchformat.
from IPython.display import Markdown, display
from openai import OpenAI
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(api_key=openai_api_key)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a great philosopher."},
{"role": "user", "content": "What is the meaning of life?"}
]
)
display(Markdown(response.choices[0].message.content))Unsere OpenAI API ist vollständig eingerichtet und wir sind bereit, mit der Feinabstimmung zu beginnen.

Neu bei OpenAIs API? Du kannst dem einfachen und detaillierten Tutorial GPT-4o API Tutorial folgen: Erste Schritte mit der API von OpenAI um zu verstehen, wie man ein paar Zeilen Code schreibt, um auf moderne Modelle zuzugreifen.
In diesem Abschnitt werden wir das GPT-4o Mini Modell auf Erkennung von Stress aus Social Media Artikeln aus dem Kaggle-Datensatz. Der Datensatz enthält Beiträge von Reddit und Twitter, die in Stress- und Nicht-Stress-Labels unterteilt sind.
Wir werden nun den Datensatz laden und verarbeiten.
Hinweis: Achte auf das korrekte Datensatzformat, das die Systemabfrage, die Benutzerabfrage und die Antwort umfasst. Die Antwort wird das Label sein.
import pandas as pd
import json
from sklearn.model_selection import train_test_split
# Load the CSV file with the correct delimiter
file_path = 'Reddit_Title.csv' # Change this to your local path
data = pd.read_csv(file_path, sep=';')
# Clean up and drop unnecessary columns, and select the top 200 rows
data_cleaned = data[['title', 'label']].head(200)
# Mapping the 'label' column to more human-readable text
label_mapping = {0: "non-stress", 1: "stress"}
data_cleaned['label'] = data_cleaned['label'].map(label_mapping)
# Split the data into training and validation sets (80% train, 20% validation)
train_data, validation_data = train_test_split(data_cleaned, test_size=0.2, random_state=42)
def save_to_jsonl(data, output_file_path):
jsonl_data = []
for index, row in data.iterrows():
jsonl_data.append({
"messages": [
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": row['title']},
{"role": "assistant", "content": f"\"{row['label']}\""}
]
})
# Save to JSONL format
with open(output_file_path, 'w') as f:
for item in jsonl_data:
f.write(json.dumps(item) + '\n')
# Save the training and validation sets to separate JSONL files
train_output_file_path = 'stress_detection_train.jsonl'
validation_output_file_path = 'stress_detection_validation.jsonl'
save_to_jsonl(train_data, train_output_file_path)
save_to_jsonl(validation_data, validation_output_file_path)
print(f"Training dataset save to {train_output_file_path}")
print(f"Validation dataset save to {validation_output_file_path}")Ausgabe:
Training dataset save to stress_detection_train.jsonl
Validation dataset save to stress_detection_validation.jsonlWir werden nun den OpenAI-Client verwenden, um sowohl die Trainings- als auch die Validierungsdatensätze für die Feinabstimmung hochzuladen.
train_file = client.files.create(
file=open(train_output_file_path, "rb"),
purpose="fine-tune"
)
valid_file = client.files.create(
file=open(validation_output_file_path, "rb"),
purpose="fine-tune"
)
print(f"Training file Info: {train_file}")
print(f"Validation file Info: {valid_file}")Die OpenAI API validiert zunächst den Datensatz, lädt dann die Datensätze hoch und generiert Metadaten, die wir zur Feinabstimmung des Modells verwenden können.
Training file Info: FileObject(id='file-b2lo2chod6xuMhYg9JcEsnp6', bytes=48563, created_at=1727133513, filename='stress_detection_train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)
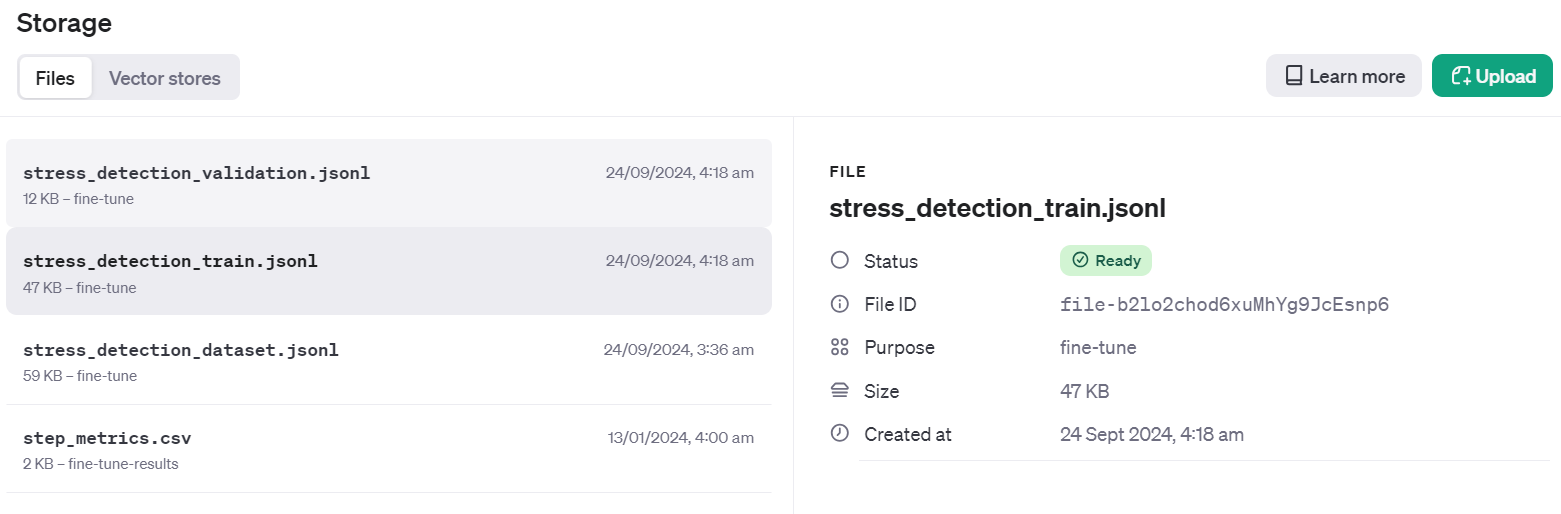
Validation file Info: FileObject(id='file-Fae0AVSUhTGr49qhQz8d2yyp', bytes=12284, created_at=1727133514, filename='stress_detection_validation.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)Um zu überprüfen, ob der Datensatz erfolgreich in die Cloud übertragen wurde, gehst du zum Dashboard und klickst auf den Reiter "Speicher". Zwei Dateien werden dort vorhanden sein und können verwendet werden.
Erstelle den Feinabstimmungsauftrag mithilfe der Client-API. Die Feinabstimmungsfunktion benötigt die Datei-ID des Trainingsdatensatzes, die Datei-ID des Validierungsdatensatzes, den Modellnamen und die Hyperparameter. Wir werden unser Modell für drei Epochen feinabstimmen. Um die Leistung des Modells zu verbessern, kannst du immer mit dem gesamten Datensatz mit mindestens 5 Epochen trainieren.
model = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=valid_file.id,
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = model.id
status = model.status
print(f'Fine-tuning model with jobID: {job_id}.')
print(f"Training Response: {model}")
print(f"Training Status: {status}")Sobald wir die Funktion ausführen, wird der Feinabstimmungsjob gestartet und die Protokolle werden angezeigt.
Fine-tuning model with jobID: ftjob-rgIMFxZSsWDqCNfOev54e4Jq.
Training Response: FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='validating_files', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=None, integrations=[], user_provided_suffix=None)
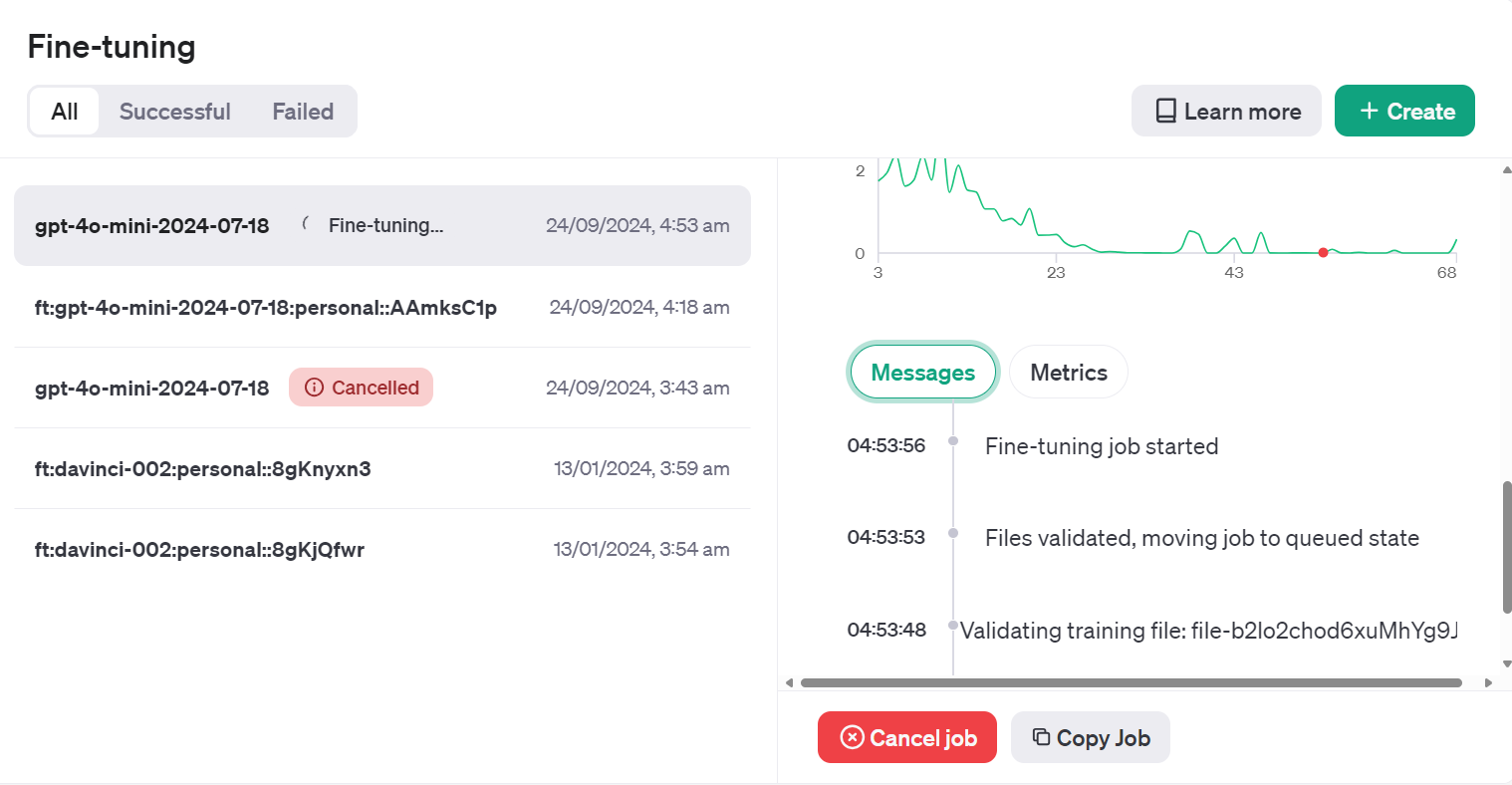
Training Status: validating_filesWir können den Status des Feinabstimmungsauftrags im Dashboard einsehen, indem wir auf die Registerkarte "Feinabstimmung" und dann auf die Auftrags-ID klicken.
Oder wir können den Status des Feinsteuerungsauftrags mit der Funktion jobs.retrieve überprüfen.
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve(job_id)Ausgabe:
FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='running', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=1727135943, integrations=[], user_provided_suffix=None)Wenn du denkst, dass der Verlust nicht abnimmt, kannst du den Auftrag jederzeit über die Funktion jobs.cancel abbrechen.
# Cancel a job
client.fine_tuning.jobs.cancel(job_id)Wenn die Feinabstimmung abgeschlossen ist, erhältst du eine E-Mail, die dir mitteilt, dass das feinabgestimmte Modell einsatzbereit ist.
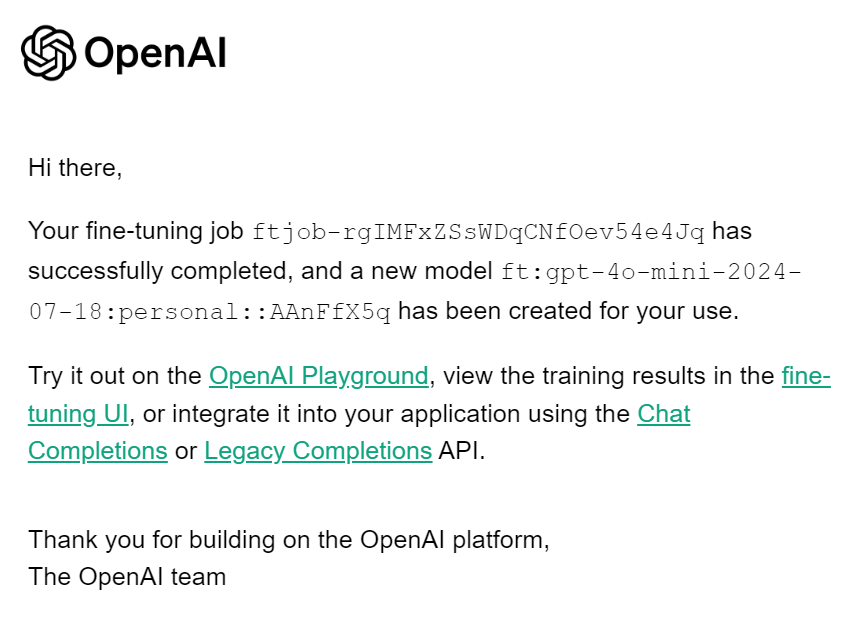
Um auf das Feinabstimmungsmodell zuzugreifen, müssen wir den Namen des Feinabstimmungsmodells erfahren. Dazu sammeln wir Informationen über alle Feinabstimmungsaufträge, wählen den letzten aus und wählen dann den Modellnamen.
result = client.fine_tuning.jobs.list()
# Retrieve the fine tuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)Das ist unser fein abgestimmter Modellname.
ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5qErzeuge Ruhe, indem du der Chatvervollständigungsfunktion einen fein abgestimmten Modellnamen, Nachrichten mit einer korrekten Systemaufforderung und ein Beispiel aus dem Datensatz gibst.
completion = client.chat.completions.create(
model = fine_tuned_model,
messages=[
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": "Just went to my first homecoming, and they played a song I've always wanted to dance to at an official dance. Sorry for the terrible quality, but my happiness in this moment couldn't be exaggerated!"}
]
)
print(completion.choices[0].message.content)Erfolg! Ich habe das Etikett richtig vorausgesagt.
"non-stress"Wenn du mit deinem Modell unzufrieden bist, kannst du es jederzeit mit dem folgenden Befehl löschen. Das werden wir nicht tun, da wir zuerst weitere Modellevaluierungen durchführen müssen.
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete(fine_tuned_model)Es gibt eine weitere Möglichkeit, auf das fein abgestimmte Modell zuzugreifen und es effizienter an verschiedenen Aufforderungen zu testen.
Gehe zum OpenAI Dashboard, klicke auf den Reiter "Feineinstellungen", wähle den kürzlich ausgeführten Job aus und klicke dann auf die Schaltfläche "Playground" unten rechts.
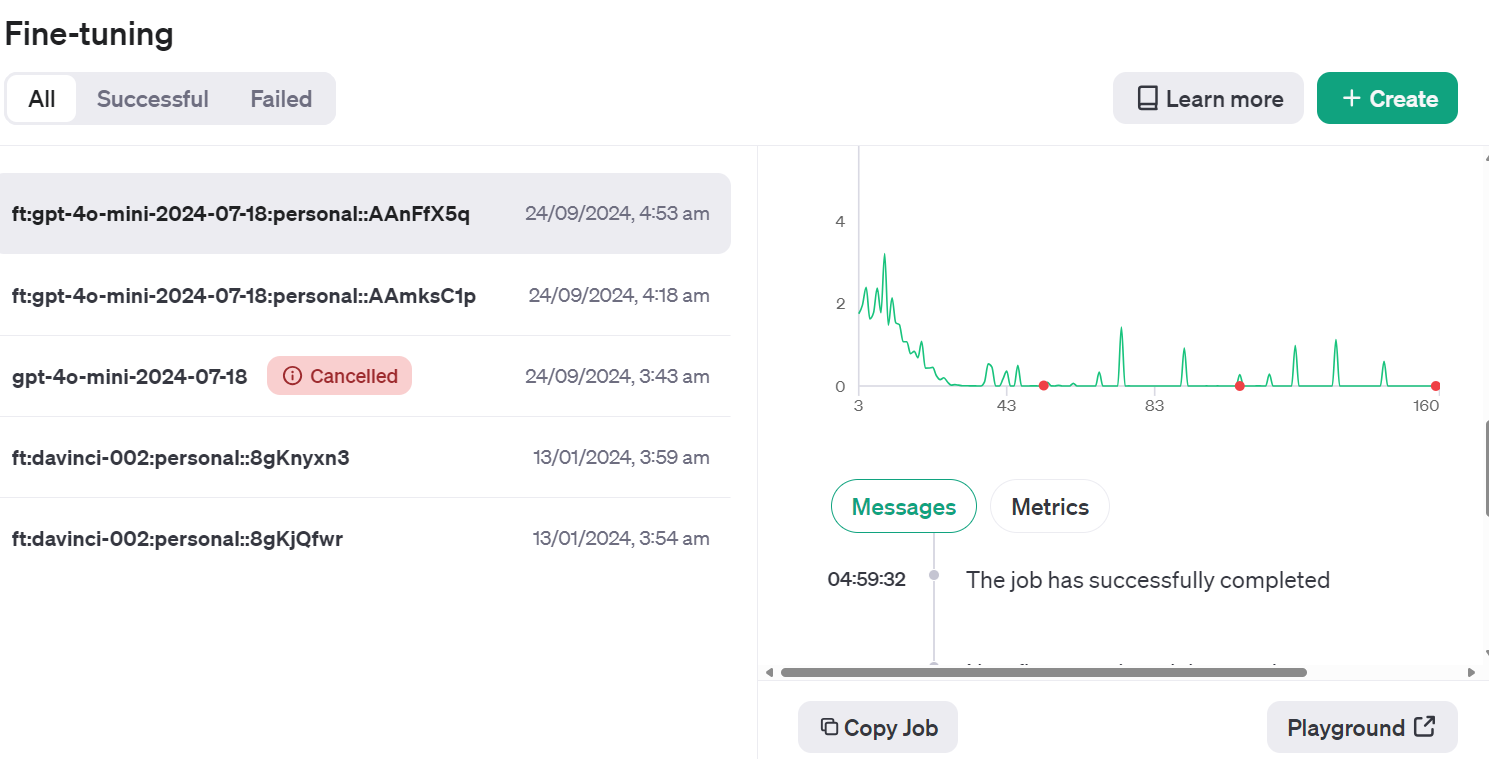
Er bringt dich zur Chatbot-Anwendung. Dort kannst du eine System-Eingabeaufforderung bereitstellen und mit dem Tippen des Reddit-Beispielposts beginnen.
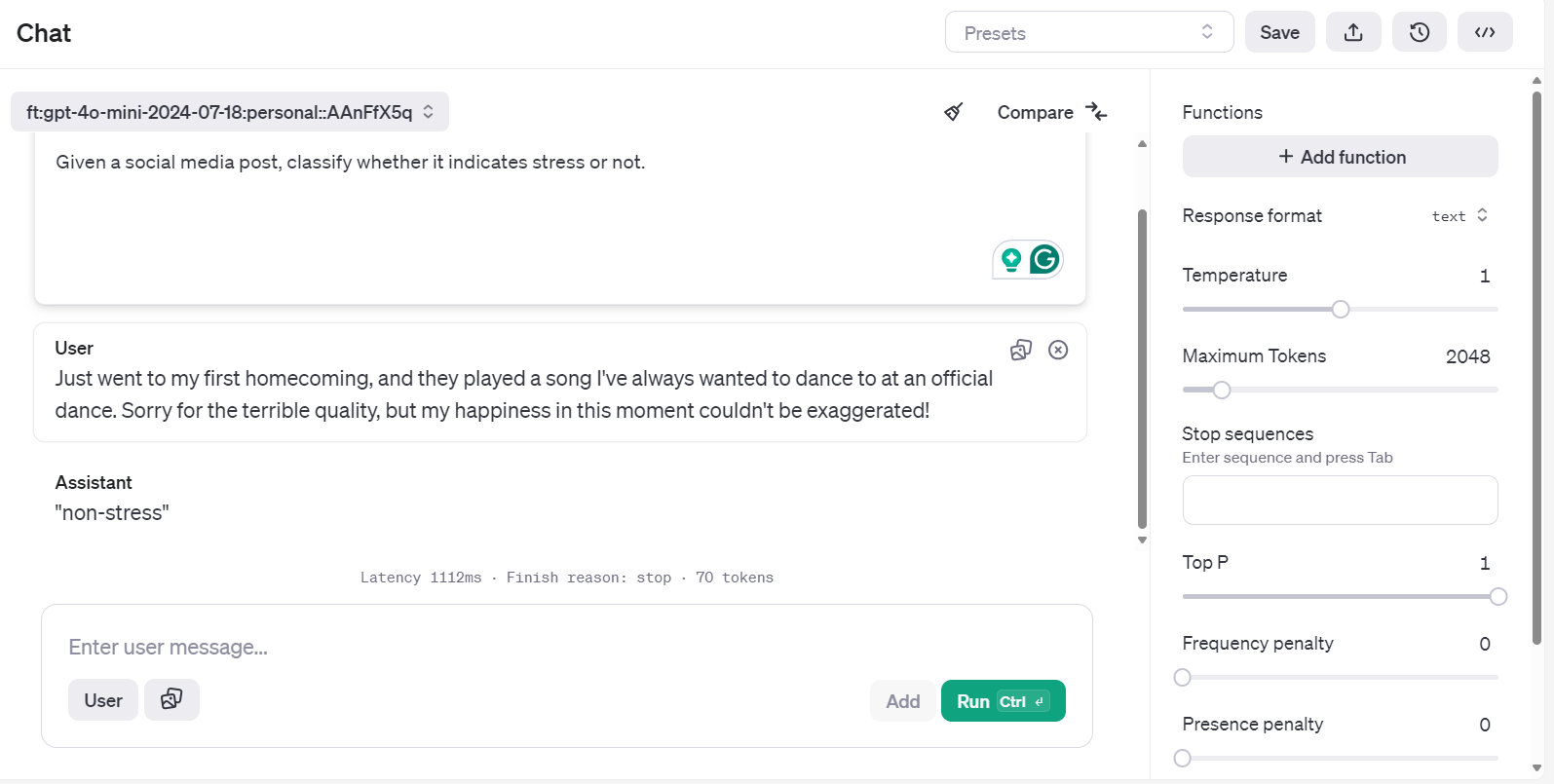
Du kannst sogar dieselbe Eingabeaufforderung ausführen und sie zur besseren Analyse mit einem anderen Modell vergleichen.
Wir haben das Modell verfeinert und denken, dass es gut genug ist. Aber hast du schon einmal überlegt, ob es nicht schon von Anfang an besser war? Wir haben keinen detaillierten Vorher-Nachher-Vergleich gemacht.
In diesem Abschnitt verwenden wir Validierungsdaten, um die Labels mit dem Basismodell vorherzusagen und es dann mit einem fein abgestimmten Modell zu vergleichen. Wir werden beide Modelle anhand der Genauigkeit, des Klassifizierungsberichts und der Konfusionsmetriken vergleichen.
Erstelle eine predict Funktion, die den Datensatz und den Modellnamen eingibt, um eine Liste der vorhergesagten Bezeichnungen zu erstellen. Sie verwendet die gleichen Systemmeldungen und Beitragstitel aus dem Datensatz.
def predict(test, model):
y_pred = []
categories = ["non-stress", "stress"]
for index, row in test.iterrows():
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'.",
},
{"role": "user", "content": row["title"]},
],
)
answer = response.choices[0].message.content
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_predDann erstellen wir die Funktion evaluate, die aus den vorhergesagten und tatsächlichen Bezeichnungen eine Genauigkeitsbewertung, einen Klassifizierungsbericht und eine Verwirrungsmetrik erstellt.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
def evaluate(y_true, y_pred):
labels = ["non-stress", "stress"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(
x, -1
) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f"Accuracy: {accuracy:.3f}")
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [
i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label
]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f"Accuracy for label {labels[label]}: {label_accuracy:.3f}")
# Generate classification report
class_report = classification_report(
y_true=y_true_mapped,
y_pred=y_pred_mapped,
target_names=labels,
labels=list(range(len(labels))),
)
print("\nClassification Report:")
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(
y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels)))
)
print("\nConfusion Matrix:")
print(conf_matrix)
Gib der Funktion predict den Validierungsdatensatz und den Namen des Basismodells an. Dann gibst du die vorhergesagten und tatsächlichen Kennzeichnungen an die Funktion evaluate weiter und erstellst einen Bericht zur Modellbewertung.
y_pred = predict(validation_data, "gpt-4o-mini-2024-07-18")
y_true = validation_data["label"]
evaluate(y_true, y_pred)Unser Basismodell ist ziemlich gut darin, den Text zu klassifizieren. Wir haben eine Genauigkeit von 92,5 % erreicht.
Accuracy: 0.925
Accuracy for label non-stress: 0.947
Accuracy for label stress: 0.905
Classification Report:
precision recall f1-score support
non-stress 0.90 0.95 0.92 19
stress 0.95 0.90 0.93 21
accuracy 0.93 40
macro avg 0.93 0.93 0.92 40
weighted avg 0.93 0.93 0.93 40
Confusion Matrix:
[[18 1]
[ 2 19]]Verwenden wir die Funktion predict mit dem fein abgestimmten Modellnamen, um Stressbezeichnungen zu erzeugen. Dann können wir die vorhergesagten und die tatsächlichen Bezeichnungen verwenden, um den detaillierten Bericht über die Modellgleichung zu erstellen.
fine_tuned_model = "ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5q"
y_pred = predict(validation_data,fine_tuned_model)
evaluate(y_true, y_pred)Die Leistung unseres Modells hat sich verbessert. Wir haben eine Genauigkeit von 97,5 % erreicht, was eine deutliche Verbesserung darstellt.
Accuracy: 0.975
Accuracy for label non-stress: 1.000
Accuracy for label stress: 0.952
Classification Report:
precision recall f1-score support
non-stress 0.95 1.00 0.97 19
stress 1.00 0.95 0.98 21
accuracy 0.97 40
macro avg 0.97 0.98 0.97 40
weighted avg 0.98 0.97 0.98 40
Confusion Matrix:
[[19 0]
[ 1 20]]Die Feinabstimmung bei bestimmten Aufgaben kann die Genauigkeit deutlich verbessern. Dies war nur ein Beispieltest, aber in realen Projekten verbessert die Feinabstimmung die Genauigkeit und Leistung des Modells bei Klassifizierungsaufgaben, Styling und strukturierter Ausgabe.
Wenn du Probleme beim Ausführen des obigen Codes hast, schau bitte im DataLab-Arbeitsbereich nach: Fine-tuning GPT-4 Mini.
Der nächste Schritt auf deinem Weg ist, dieses fein abgestimmte Modell zu nutzen, um eine richtige KI-Anwendung zu erstellen. Du kannst es lernen, indem du dem Code folgst: KI-Assistenten mit GPT-4o erstellen.
In diesem Tutorial haben wir das GPT-4o-Minimodell erfolgreich so angepasst, dass es Text in "Stress" und "Nicht-Stress" einteilt. Auf dieses fein abgestimmte Modell haben wir dann über die OpenAI-API und die OpenAI-Spielwiese zugegriffen, was eine praktische Anwendung und weitere Tests ermöglicht.
Die Auswertung des fein abgestimmten Modells lieferte aufschlussreiche Ergebnisse, die eine Verbesserung der Klassifizierungsleistung bei verschiedenen Metriken im Vergleich zum Basismodell zeigten. Dieser Prozess machte deutlich, wie wichtig die Feinabstimmung ist, um ein zuverlässiges und genaues Ergebnis zu erzielen, insbesondere bei Aufgaben wie der Textklassifizierung.
Wenn du ein freies, quelloffenes Modell verwenden möchtest, haben wir ein hervorragendes Tutorial Feinabstimmung von Llama 3.2 und seine lokale Nutzung: Eine Schritt-für-Schritt-Anleitung. In dieser Anleitung zeigen wir dir, wie du das neueste Llama-Modell verfeinerst und in das GGUF-Format konvertierst, um es lokal auf deinem Laptop zu verwenden.
Top DataCamp OpenAI Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
