
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
In letzter Zeit hat sich das Feld der großen Sprachmodelle (LLMs) schnell verändert. Neuere LLMs sind kleiner und intelligenter, was sie im Vergleich zu den größeren Modellen billiger und einfacher zu bedienen macht.
Mit der Veröffentlichung von Llama 3.2 haben wir jetzt Zugang zu kleineren Modellen, wie den Varianten 1B und 3B. Auch wenn diese kleineren Modelle bei allgemeinen Aufgaben nicht die Genauigkeit größerer Modelle erreichen, können sie so fein abgestimmt werden, dass sie in bestimmten Bereichen, wie z. B. der Klassifizierung von Emotionen bei Kundeninteraktionen, außergewöhnlich gut abschneiden. Diese Fähigkeit ermöglicht es ihnen, traditionelle Modelle in diesen Bereichen zu ersetzen.
In diesem Tutorial werden wir die Möglichkeiten von Llama 3.2 Vision und Lightweight-Modellen erkunden. Wir werden lernen, wie wir auf das Llama 3.2 3B Modell zugreifen, es an einem Datensatz zur Kundenbetreuung feinabstimmen und es anschließend zusammenführen und in den Hugging Face Hub exportieren. Am Ende werden wir das Modell in das GGUF-Format konvertieren und es lokal mit der Jan-Anwendung verwenden.
Wenn du neu im Bereich der Künstlichen Intelligenz bist, ist es sehr empfehlenswert, dass du die KI-Grundlagen Lernpfad zu besuchen, um die Grundlagen von chatGPT, großen Sprachmodellen, generativer KI und mehr zu lernen.

Bild vom Autor
Die Familie der Llama 3.2 Open-Source-Modelle hat zwei Varianten: die Lightweight- und die Vision-Modelle . Die Bildverarbeitungsmodelle zeichnen sich durch die Verknüpfung von Bild und Sprache aus, während die leichtgewichtigen Modelle gut in der mehrsprachigen Texterstellung und dem Aufruf von Tools für Edge Devices sind.
Das leichte Modell hat zwei kleinere Varianten: 1B und 3B. Diese Modelle sind gut für die mehrsprachige Texterstellung und den Aufruf von Werkzeugen geeignet. Sie sind klein, so dass sie auf einem Gerät laufen können, um sicherzustellen, dass die Daten das Gerät nie verlassen, und bieten eine schnelle Texterstellung bei geringen Rechenkosten.
Um diese effizienten, leichtgewichtigen Modelle zu erstellen, verwendet Llama 3.2 Pruning- und Wissensdestillationstechniken. Durch Pruning wird die Größe des Modells bei gleichbleibender Leistung reduziert, und bei der Wissensdestillation werden größere Netzwerke genutzt, um Wissen mit kleineren zu teilen und so deren Leistung zu verbessern.
Das 3B-Modell übertrifft andere Modelle wie Gemma 2 (2.6B) und Phi 3.5-mini bei Aufgaben wie dem Befolgen von Anweisungen, dem Zusammenfassen, dem Umschreiben von Aufforderungen und der Verwendung von Hilfsmitteln.
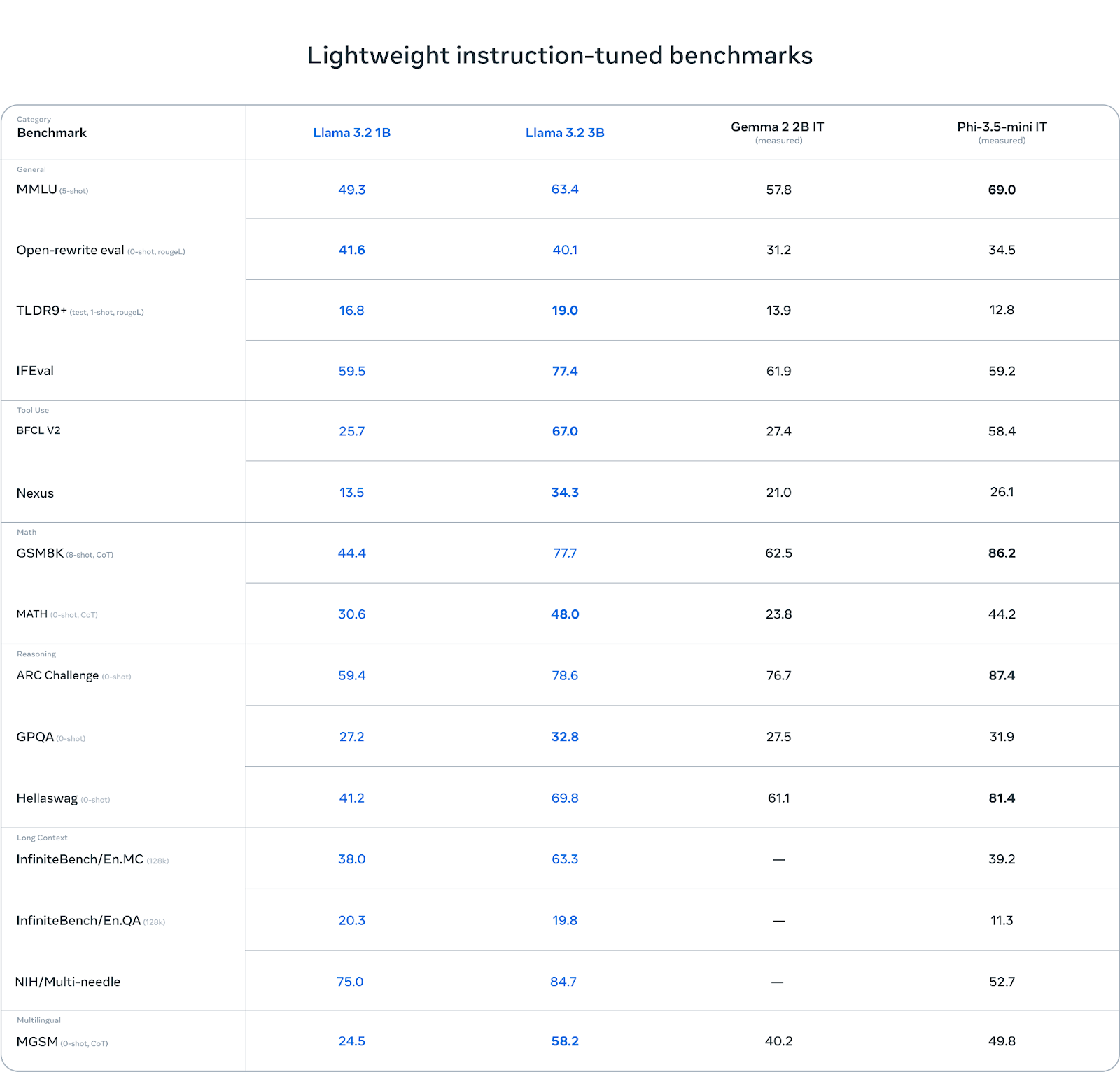
Quelle: Llama 3.2: Revolutionierung von Edge AI und Vision mit offenen, anpassbaren Modellen
Die Vision-Modelle gibt es in zwei Varianten: 11B und 90B. Diese Modelle sind so konzipiert, dass sie das Image Reasoning unterstützen. Die 11B und 90B können Dokumente, Diagramme und Grafiken verstehen und interpretieren und Aufgaben wie Bildunterschriften und visuelle Erdung durchführen. Diese fortschrittlichen Sehfähigkeiten wurden durch die Integration von vortrainierten Bildkodierern mit Sprachmodellen ermöglicht, die aus Kreuzaufmerksamkeitsschichten bestehende Adaptergewichte verwenden.
Verglichen mit Claude 3 Haiku und GPT-4o minihaben die Llama 3.2-Vision-Modelle bei der Bilderkennung und verschiedenen visuellen Verstehensaufgaben brilliert, was sie zu robusten Werkzeugen für multimodale KI-Anwendungen macht.
Quelle: Llama 3.2: Revolutionierung von Edge AI und Vision mit offenen, anpassbaren Modellen
Du kannst mehr über Llama 3.2 Anwendungsfälle, Benchmarks, Llama Guard 3 und die Modellarchitektur erfahren, indem du unseren neuesten Blog liest, Llama 3.2 Guide: Funktionsweise, Anwendungsfälle und mehr.
Auch wenn das Llama 3.2-Modell frei verfügbar und quelloffen ist, musst du die Geschäftsbedingungen akzeptieren und das Formular auf der Website ausfüllen.
Um Zugang zum neuesten Llama 3.2-Modell auf der Kaggle-Plattform zu erhalten:
Quelle: Llama herunterladen
Quelle: Meta | Llama 3.2 | Kaggle
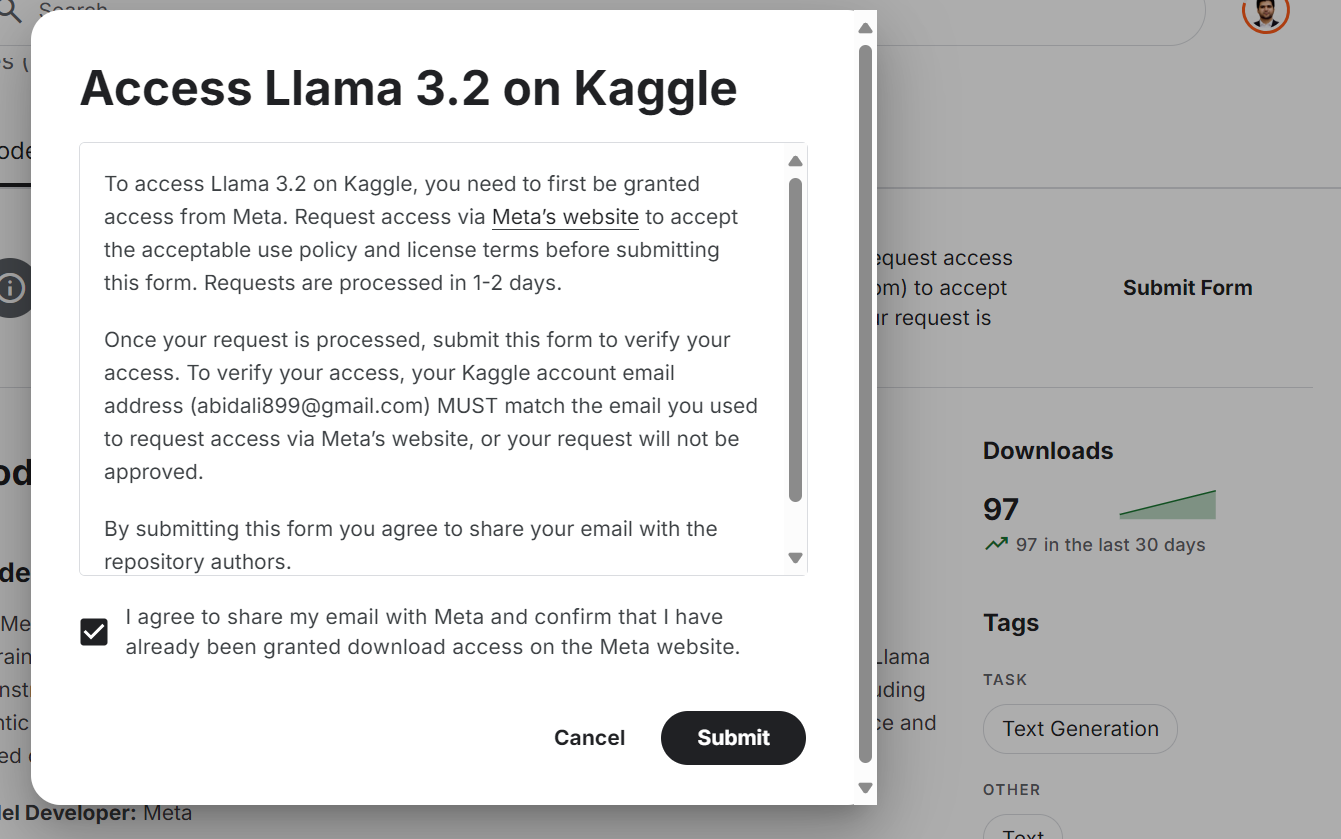
Quelle: Meta | Llama 3.2 | Kaggle
%%capture
%pip install -U transformers acceleratefrom transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
import torch
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)pad_token_id ein, um keine Warnmeldungen zu erhalten.if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
if model.config.pad_token_id is None:
model.config.pad_token_id = model.config.eos_token_idpipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [{"role": "user", "content": "Who is Vincent van Gogh?"}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])Die Antwort ist ziemlich genau.

from IPython.display import Markdown, display
messages = [
{
"role": "system",
"content": "You are a skilled Python developer specializing in database management and optimization.",
},
{
"role": "user",
"content": "I'm experiencing a sorting issue in my database. Could you please provide Python code to help resolve this problem?",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=512, do_sample=True)
display(
Markdown(
outputs[0]["generated_text"].split(
"<|start_header_id|>assistant<|end_header_id|>"
)[1]
)
)Das Ergebnis ist sehr genau. Das Modell schneidet trotz seiner nur 3 Milliarden Parameter ziemlich gut ab.
Wenn du Schwierigkeiten hast, auf die Llama 3.2 Leichtgewichtsmodelle zuzugreifen, schaue bitte im Notebook nach, Zugriff auf die Llama 3.2 Leichtgewichtsmodelle.
Der Zugriff auf das Vision-Modell ist einfach, und du musst dir keine Gedanken über den GPU-Speicher machen, da wir in diesem Leitfaden mehrere GPUs verwenden werden.
Quelle: Meta | Llama 3.2 Vision | Kaggle
Quelle: Meta | Llama 3.2 Vision | Kaggle
%%capture
%pip install -U transformers accelerateimport torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
base_model = "/kaggle/input/llama-3.2-vision/transformers/11b-vision-instruct/1"
processor = AutoProcessor.from_pretrained(base_model)
model = MllamaForConditionalGeneration.from_pretrained(
base_model,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)Wie wir sehen können, werden fast 25 GB GPU-Speicher verwendet. Auf einem Laptop oder der kostenlosen Version von Google Colab wird das nicht möglich sein.
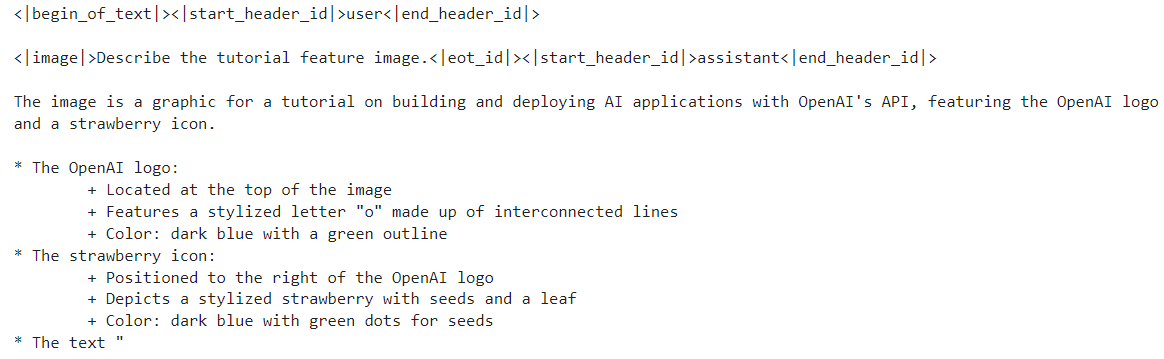
import requests
from PIL import Image
url = "https://media.datacamp.com/cms/google/ad_4nxcz-j3ir2begccslzay07rqfj5ttakp2emttn0x6nkygls5ywl0unospj2s0-mrwpdtmqjl1fagh6pvkkjekqey_kwzl6qnodf143yt66znq0epflvx6clfoqw41oeoymhpz6qrlb5ajer4aeniogbmtwtd.png"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Describe the tutorial feature image."}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=120)
print(processor.decode(output[0]))Als Ergebnis erhalten wir eine detaillierte Beschreibung des Bildes. Das ist ziemlich genau.
Wenn du beim Ausführen des obigen Codes auf Probleme stößt, lies bitte die Zugriff auf die Llama 3.2 Vision Modelle Kaggle Notizbuch.
In diesem Abschnitt lernst du, wie du das Llama 3.2 3B Instruct Modell mit Hilfe der Transformers Bibliothek an den Kundenbetreuungsdatensatz anpassen kannst. Wir werden Kaggle nutzen, um auf freie GPUs zuzugreifen und mehr RAM als Colab zu bekommen.
Starte das neue Notizbuch auf Kaggle und setze die Umgebungsvariablen. Wir werden die Hugging Face API nutzen, um das Modell zu speichern, und Weights & Biases, um seine Leistung zu verfolgen.
Installiere und aktualisiere alle notwendigen Python-Pakete.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbLade die Python-Pakete und -Funktionen, die wir bei der Feinabstimmung und Auswertung verwenden werden.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatMelde dich mit deinem API-Schlüssel bei Hugging Face CLI an.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Melde dich mit deinem API-Schlüssel bei Weights & Biases an und richte das neue Projekt ein.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3.2 on Customer Support Dataset',
job_type="training",
anonymous="allow"
)Setze die Variablen für den Basismodus, den Datensatz und den neuen Modellnamen. Wir werden sie in diesem Projekt an mehreren Stellen verwenden, daher ist es besser, sie zu Beginn festzulegen, um Verwirrung zu vermeiden.
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
dataset_name = "bitext/Bitext-customer-support-llm-chatbot-training-dataset"Lege den Datentyp und die Aufmerksamkeitsimplementierung fest.
# Set torch dtype and attention implementation
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Lade das Modell und den Tokenizer, indem du das lokale Modellverzeichnis angibst. Auch wenn unser Modell klein ist, wird das Laden des vollständigen Modells und die Feinabstimmung einige Zeit in Anspruch nehmen. Stattdessen werden wir das Modell in 4-Bit-Quantisierung laden.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Wir laden den Bitext-Kunden-Support-llm-Chatbot Datensatz aus dem Hugging Face Hub. Es handelt sich um einen hybriden synthetischen Datensatz, den wir verwenden werden, um unseren eigenen Chatbot für den Kundensupport zu erstellen.
Wir werden nur 1000 Proben laden, mischen und auswählen. Wir stimmen das Modell auf einer kleinen Teilmenge ab, um die Trainingszeit zu verkürzen, aber du kannst jederzeit das vollständige Modell auswählen.
Als Nächstes erstellen wir die Spalte "Text" anhand der Systemanweisungen, der Benutzerabfragen und der Antworten des Assistenten. Dann wandeln wir die JSON-Antwort in das Chat-Format um.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
def format_chat_template(row):
row_json = [{"role": "system", "content": instruction },
{"role": "user", "content": row["instruction"]},
{"role": "assistant", "content": row["response"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
Wie wir sehen können, haben wir die Kundenanfrage und die Antwort des Assistenten in einem Chatformat kombiniert.
dataset['text'][3]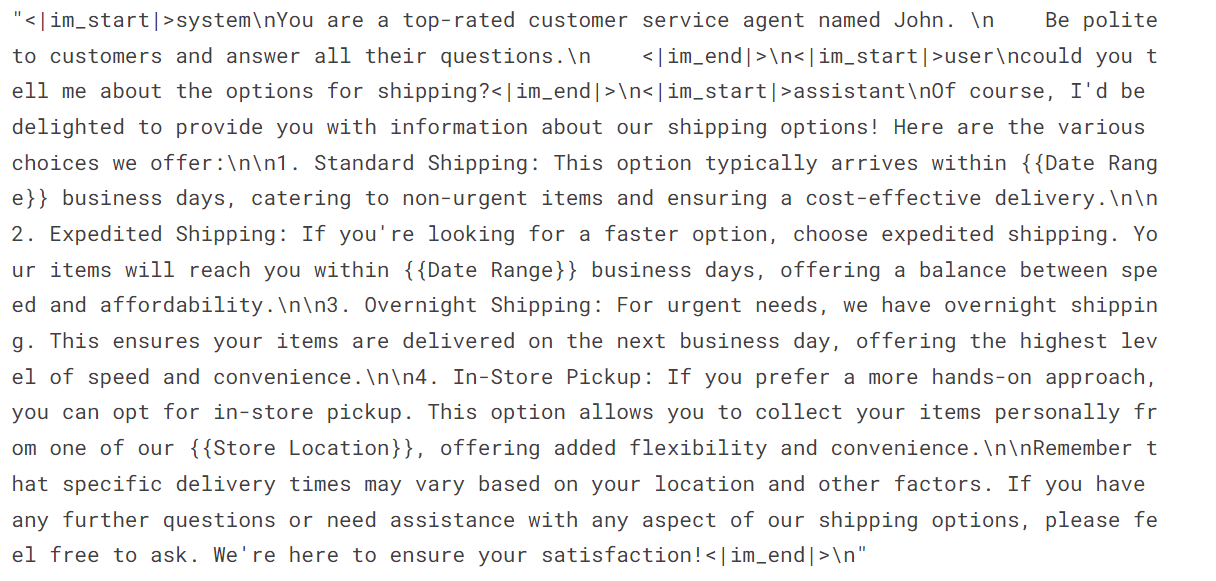
Extrahiere den Namen des linearen Modells aus dem Modell.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Verwende den linearen Modulnamen, um den LoRA-Adapter zu erstellen. Wir werden nur den LoRA-Adopter feinjustieren und den Rest des Modells stehen lassen, um Speicherplatz zu sparen und die Trainingszeit zu verkürzen.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Wir konfigurieren die Hyperparameter des Modells, um es in der Kaggle-Umgebung laufen zu lassen. Du kannst jeden Hyperparameter verstehen, indem du dich auf die Feineinstellung von Llama 2 Tutorial nachlesen und sie ändern, um das Training auf deinem System zu optimieren.
#Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Wir werden nun einen Supervised Fine-Tuning (SFT)-Trainer einrichten und einen Trainings- und Evaluierungsdatensatz, eine LoRA-Konfiguration, ein Trainingsargument, einen Tokenizer und ein Modell bereitstellen.
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Starte den Trainingsprozess und überwache die Trainings- und Validierungsverluste.
trainer.train()Der Trainingsverlust verringerte sich allmählich. Das ist ein gutes Zeichen.
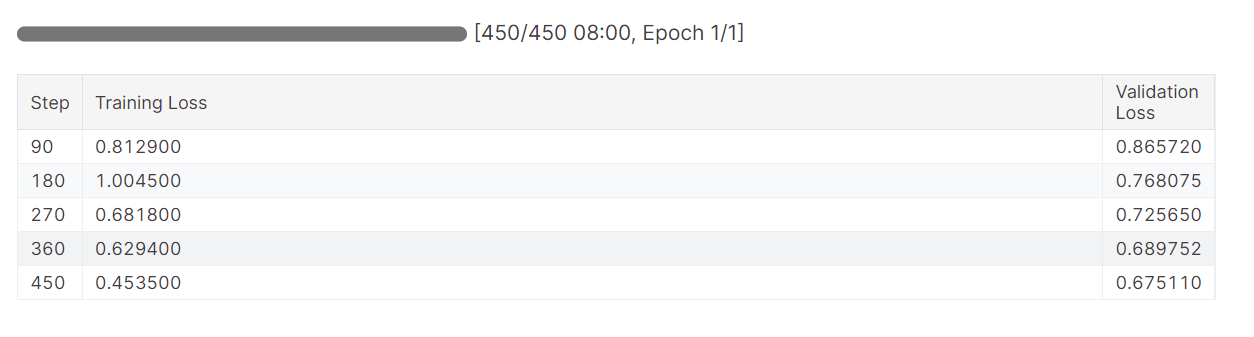
Die detaillierte Laufhistorie wird erstellt, wenn wir den Lauf "Gewichte & Verzerrungen" beenden.
wandb.finish()
Du kannst jederzeit das Dashboard Gewichte & Verzerrungen besuchen, um die Modellmetriken gründlich zu überprüfen.
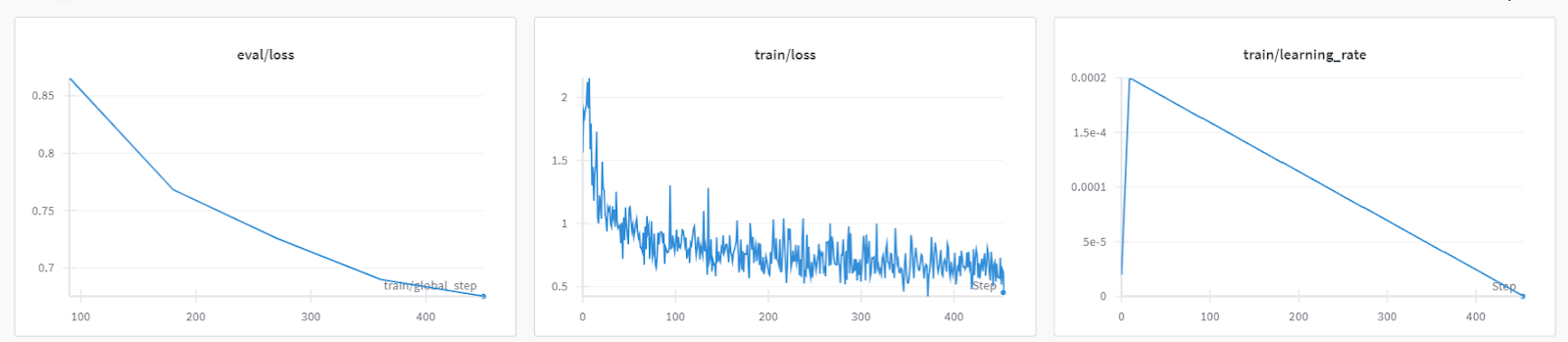
Um das fein abgestimmte Modell zu testen, werden wir es mit dem Beispielprompt aus dem Datensatz versehen.
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I bought the same item twice, cancel order {{Order Number}}"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])Das fein abgestimmte Modell hat den Stil übernommen und eine genaue Antwort gegeben.

Speichere das feinabgestimmte Modell lokal und schiebe es auch zum Hugging Face Hub. Die Funktion push_to_hub erstellt ein neues Modell-Repository und überträgt die Modelldateien in dein Hugging Face-Repository.
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)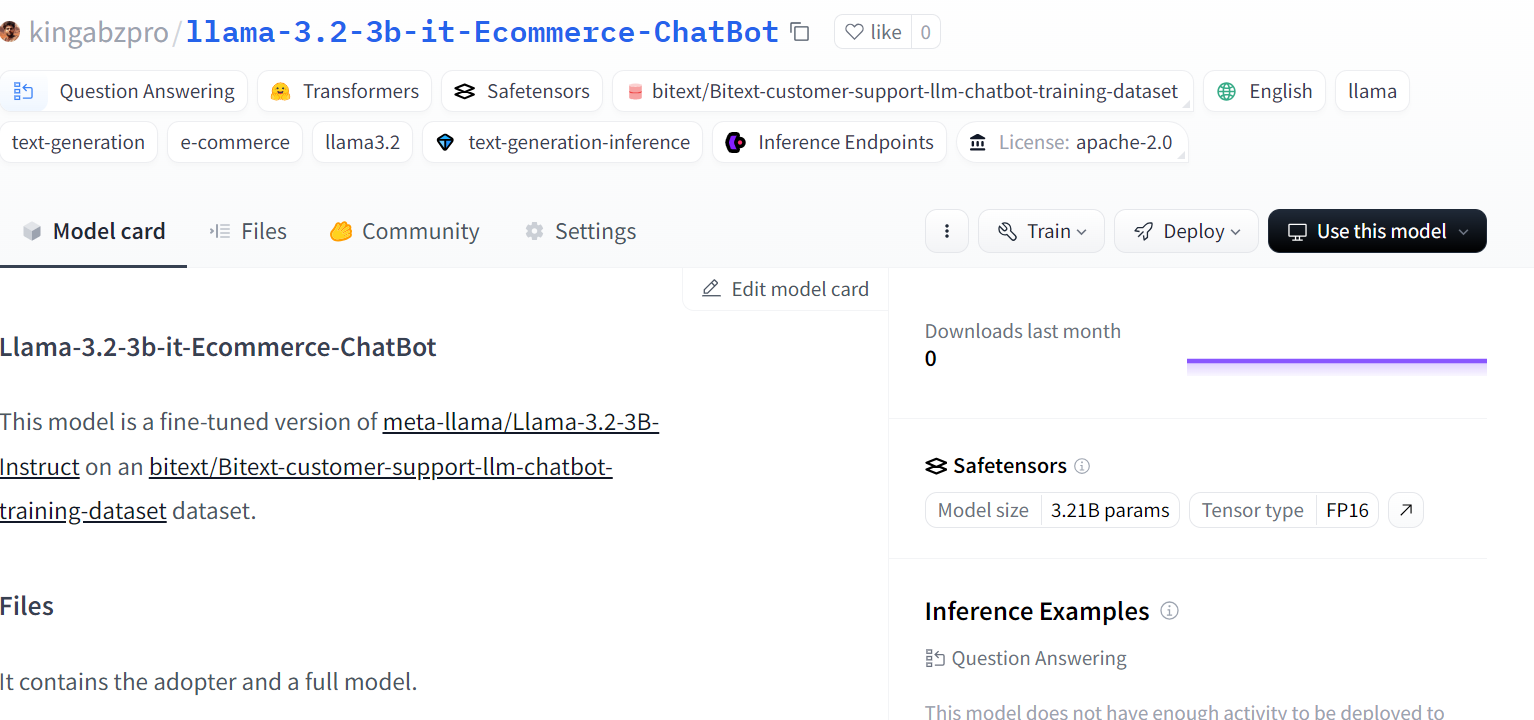
Quelle: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
Für die Feinabstimmung der größeren Llama 3-Modelle solltest du dir Folgendes ansehen Feinabstimmung von Llama 3.1 für die Textklassifikation Tutorial. Dieses Tutorial ist sehr beliebt und wird dir helfen, die LLMs zur kompletten Aufgabe zu finden.
Klicke auf die Schaltfläche "Version speichern" oben rechts, wähle die Option "Schnell speichern" und ändere die Option "Ausgabe speichern", um die Modelldatei und den gesamten Code zu speichern.
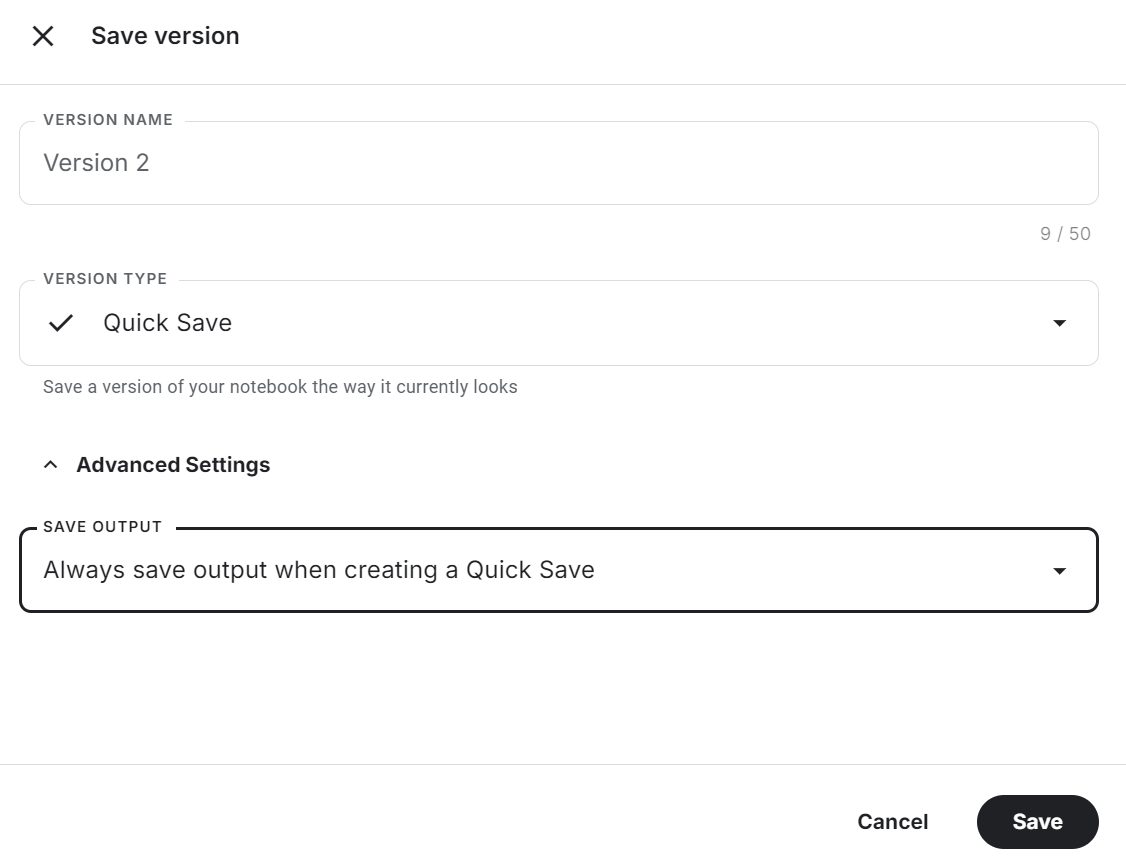
Schau dir die Feinabstimmung von Llama 3.2 auf Customer Support Kaggle-Notizbuch für den Quellcode, die Ergebnisse und die Ausgabe.
Dies ist ein sehr codebasierter Leitfaden. Wenn du einen Leitfaden ohne oder mit wenig Code für die Feinabstimmung der LLMs suchst, schau dir den LlaMA-Factory WebUI Beginner's Guide an: Feinabstimmung der LLMs.
Wir erstellen ein neues Notebook und fügen das zuvor gespeicherte Notebook hinzu, um auf den feinabgestimmten LoRA-Adapter zuzugreifen und Speicherprobleme zu vermeiden.
Stelle sicher, dass du auch das Basismodell "Llama 3.2 3B Instruct" hinzugefügt hast.
Installiere und aktualisiere alle notwendigen Python-Pakete.
%%capture
%pip install -U bitsandbytes
%pip install transformers==4.44.2
%pip install -U accelerate
%pip install -U peft
%pip install -U trlMelde dich bei Hugging Face CLI an, um das zusammengeführte Modell an den Hugging Face Hub zu senden.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Gib den Standort für das Basismodell an und stimme LoRA ab. Wir verwenden sie, um das Basismodell zu laden und es mit dem Adapter zusammenzuführen.
# Model
base_model_url = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model_url = "/kaggle/input/fine-tune-llama-3-2-on-customer-support/llama-3.2-3b-it-Ecommerce-ChatBot/"Lade den Tokenizer und das vollständige Modell.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)Wende das Chat-Format auf das Modell und den Tokenizer an. Führe dann das Basismodell mit dem LoRA-Adapter zusammen.
# Merge adapter with base model
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Um zu überprüfen, ob das Modell erfolgreich zusammengeführt wurde, gibst du ihm die Musteraufforderung und generierst die Umkehrung.
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I have to see what payment payment modalities are accepted"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])Wie wir sehen können, funktioniert unser fein abgestimmtes Modell perfekt.

Speichere den Tokenizer und das Modell lokal.
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)Schiebe den Tokenizer und das zusammengeführte Modell in das Hugging Face Modell-Repository.
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)Nach ein paar Minuten kannst du alle Modelldateien mit Metadaten in deinem Hugging Face-Repository einsehen.
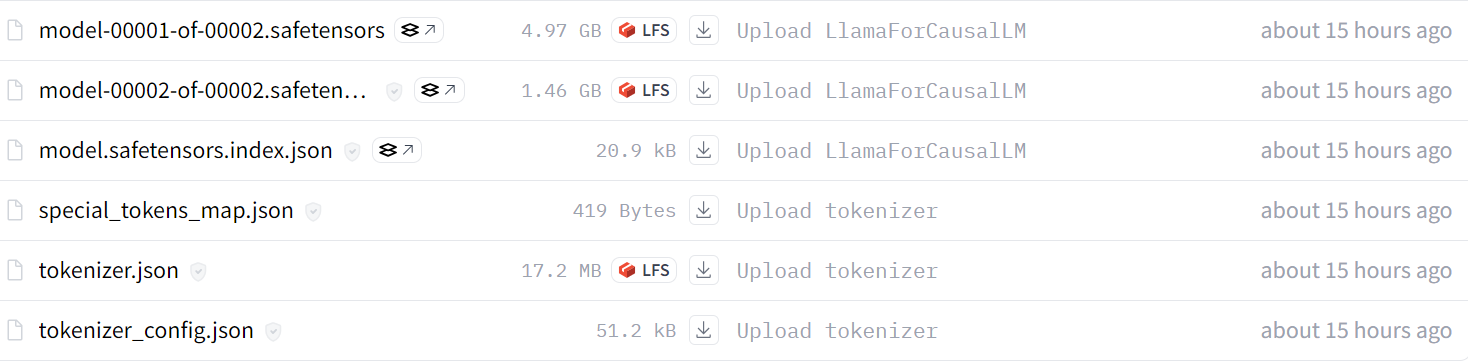
Quelle: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
Du kannst dir den Quellcode auch in der Zusammenführen und Exportieren von fein abgestimmtem Llama 3.2 Kaggle-Notizbuch nachlesen, um mehr über das Zusammenführen und Hochladen deines Modells in den Hugging Face Hub zu erfahren.
Der nächste Schritt in diesem Projekt besteht darin, das vollständige Modell in das GGUF-Format zu konvertieren und es dann zu quantisieren. Danach kannst du sie lokal mit deiner Lieblings-Chat-App wie Jan, Msty oder GPT4ALL nutzen. Folge dem Feinabstimmung von Llama 3 und seine lokale Nutzung um zu erfahren, wie du alle LLM in das GGUF-Format konvertierst und lokal auf deinem Laptop verwendest.
Um das fein abgestimmte Modell lokal zu verwenden, müssen wir es zunächst in das GGUF-Format umwandeln. Und warum? Denn dies ist ein llama.cpp-Format und wird von allen Desktop-Chatbot-Anwendungen akzeptiert.
Die Umwandlung des zusammengeführten Modells in das Format llama.ccp ist ganz einfach. Alles, was wir tun müssen, ist, in den GGUF My Repo Hugging Face Hub. Melde dich mit deinem Hugging Face-Konto an. Tippe den Link zum Repository für das Feinabstimmungsmodell "kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot" ein und drücke auf die Schaltfläche "Senden".
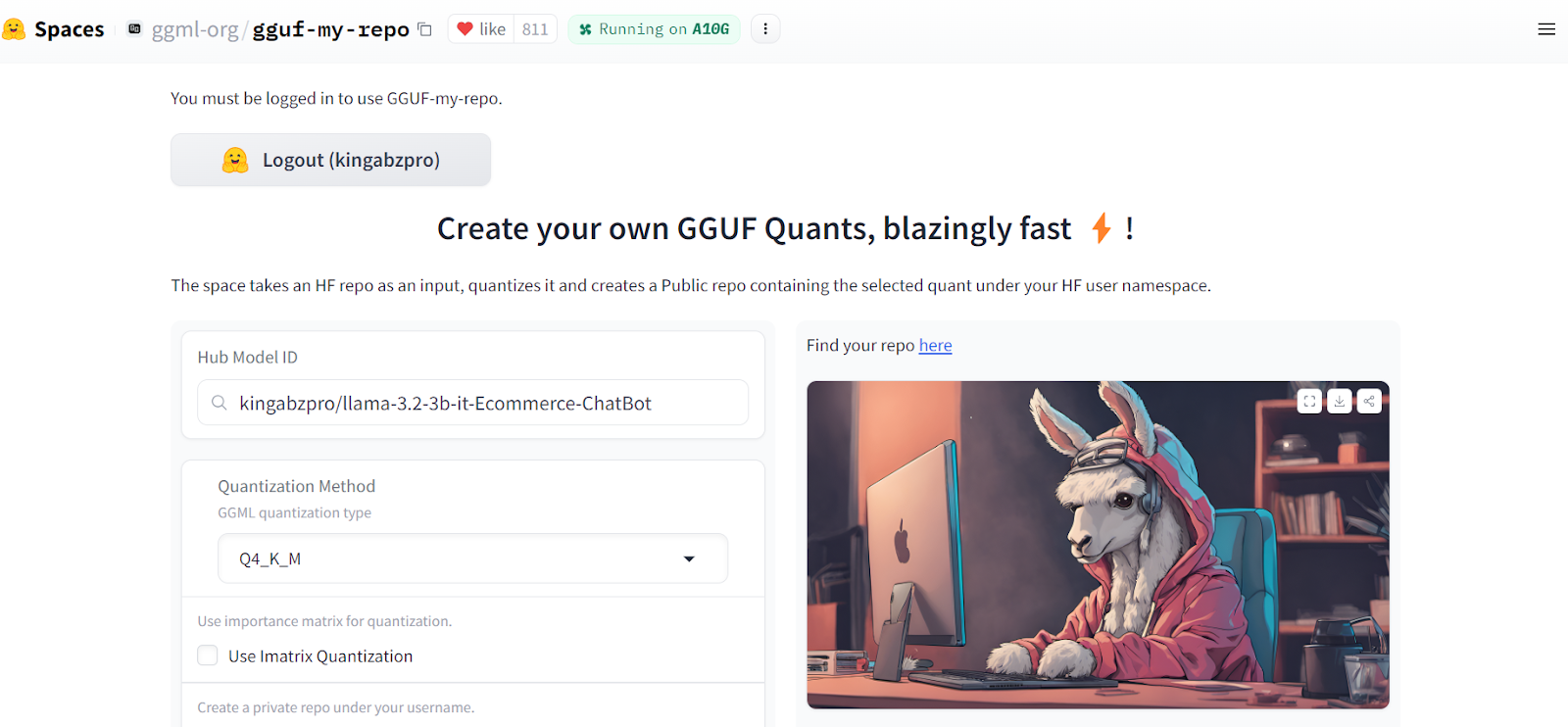
Quelle: GGUF Mein Repo
Innerhalb weniger Sekunden wird die quantisierte Version des Modells in einem neuen Hugging Face Repository erstellt.
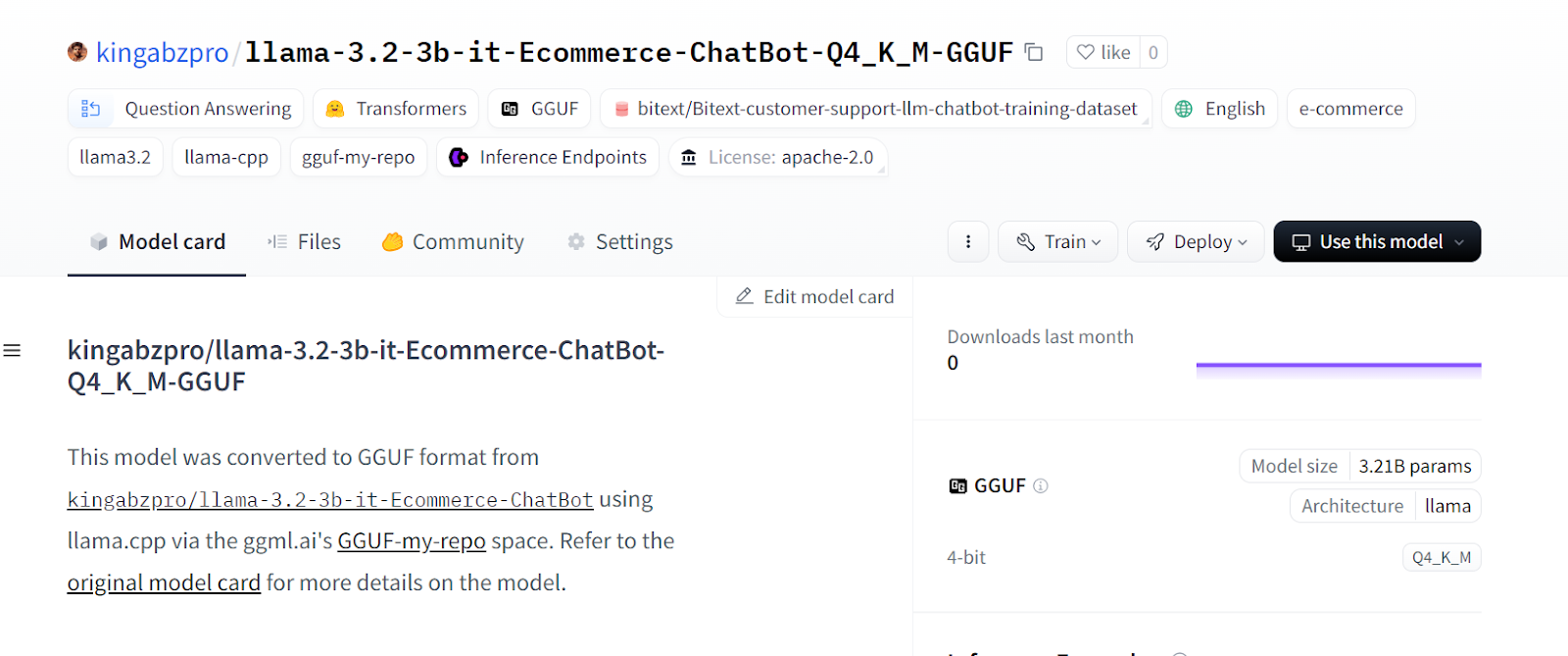
Source: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot-Q4_K_M-GGUF
Klicke auf den Reiter "Dateien" und lade nur die GGUF-Datei herunter.
Source: llama-3.2-3b-it-ecommerce-chatbot-q4_k_m.gguf
Wir werden die Jan Chatbot-Anwendung, um unser fein abgestimmtes Modell lokal zu nutzen. Gehe auf die offizielle Website jan.ai, um die Anwendung herunterzuladen und zu installieren.
Quelle: Jan
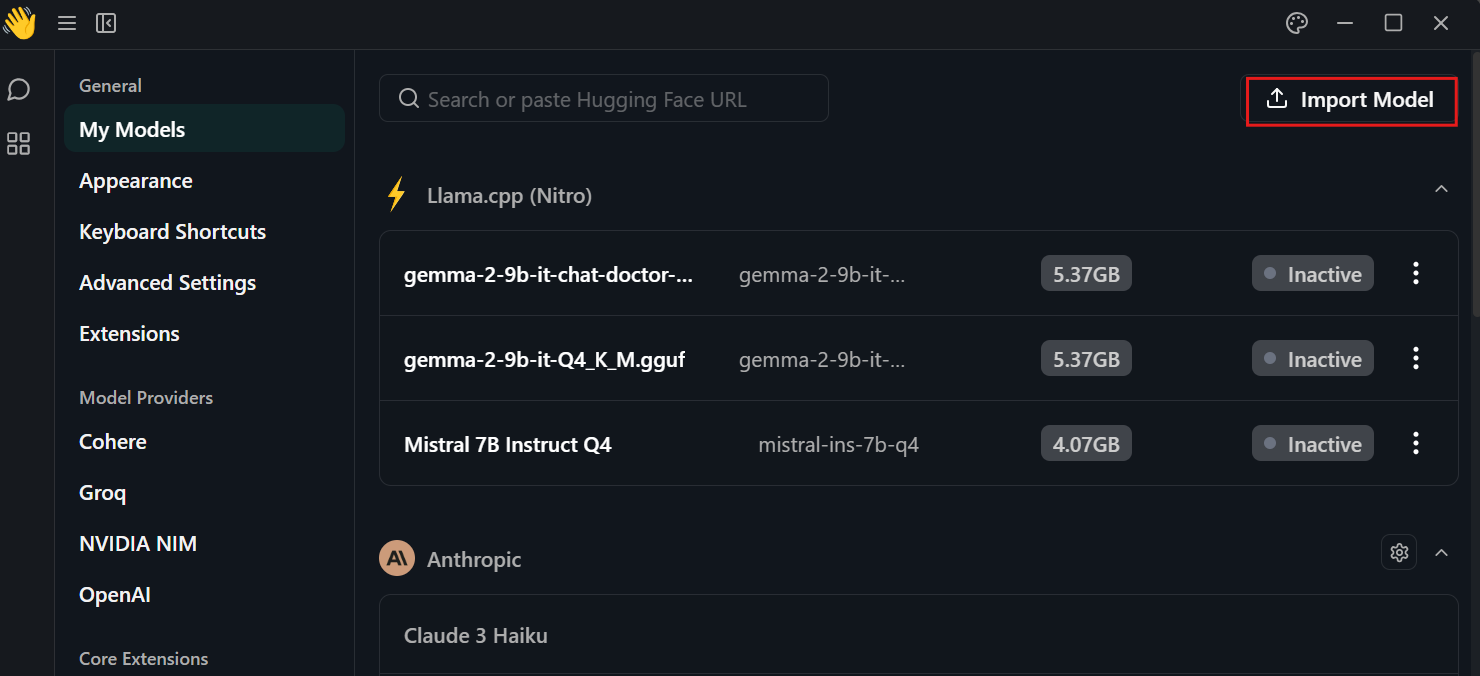
Klicke auf die Einstellung, wähle das Menü "Meine Modelle" und drücke die Schaltfläche "Modell importieren". Gib ihm dann das lokale Verzeichnis des Modells.
Gehe zum Chat-Menü und wähle das Feinabstimmungsmodell, wie unten gezeigt.
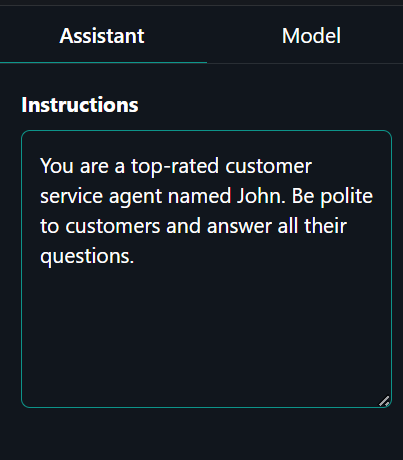
Klicke auf die Registerkarte "Assistent" auf der rechten Seite und gib die Systemaufforderung ein.
Systemaufforderung: "Du bist ein erstklassiger Kundenbetreuer namens John. Sei höflich zu den Kunden und beantworte alle ihre Fragen."
Klicke auf den Reiter "Modell", direkt neben dem Reiter "Assistent" und ändere das Stopp-Token in "<|eot_id|>"
Das war's. Alles, was du tun musst, ist, den KI-Kundenservice über dein Problem zu informieren.
Prompt: "Wie bestelle ich mehrere Artikel beim selben Anbieter?"
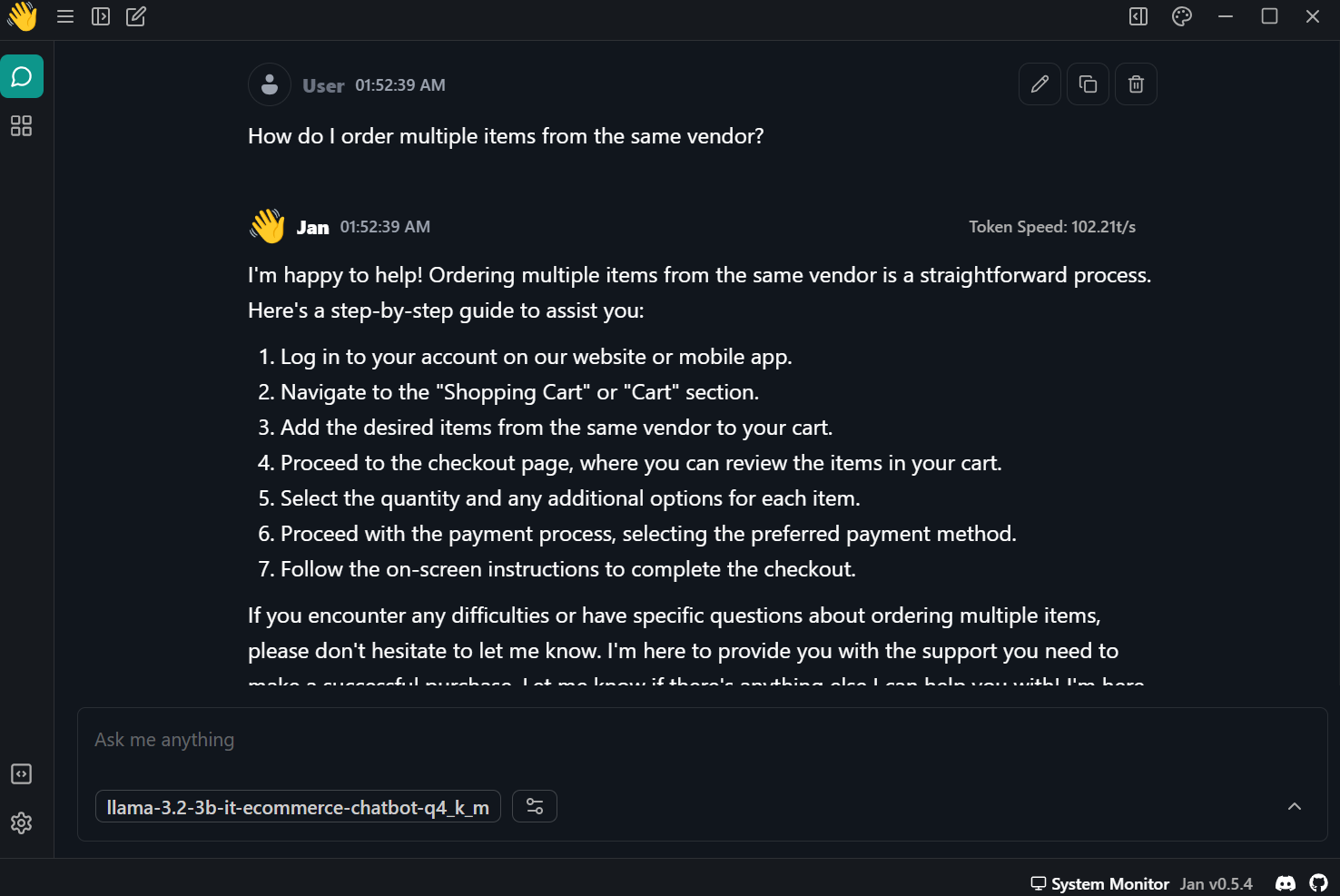
Die Antwort war genau und superschnell - fast 102 Token pro Sekunde.
Durch die Feinabstimmung der kleineren LLMs können wir Kosten sparen und die Inferenzzeit verbessern. Mit genügend Daten kannst du die Leistung des Modells bei bestimmten Aufgaben ähnlich wie beim GPT-4-mini verbessern. Kurz gesagt, die Zukunft der KI besteht darin, mehrere kleinere LLMs in einem Netz mit einer Master-Slave-Beziehung einzusetzen.
Das Mastermodell empfängt die erste Aufforderung und entscheidet, welches spezialisierte Modell zur Erstellung der Antworten verwendet werden soll. Das reduziert die Rechenzeit, verbessert die Ergebnisse und senkt die laufenden Kosten.
In diesem Tutorial haben wir Llama 3.2 kennengelernt und erfahren, wie man in Kaggle darauf zugreift. Wir haben auch gelernt, das leichtgewichtige Llama 3.2 Modell auf den Kundensupport-Datensatz abzustimmen, damit es lernt, in einem bestimmten Stil zu antworten und genaue domänenspezifische Informationen zu liefern. Dann haben wir den LoRA-Adapter mit dem Basismodell zusammengeführt und das vollständige Modell an den Hugging Face Hub übertragen. Schließlich konvertierten wir das zusammengeführte Modell in das GGUF-Format und verwendeten es lokal auf dem Laptop mit der Jan-Chatbot-Anwendung.
Nimm unser Arbeiten mit Hugging Face interaktiven Kurs, um mehr über die Verwendung des Werkzeugs und die Feinabstimmung der Modelle zu erfahren.
Top LLM-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
