
Curso
Trabajar con la API de OpenAI
3 h
142.5K
Antes de empezar a poner a punto el modelo GPT-4o Mini, te recomendamos ingeniería rápida, encadenamiento rápidoy llamada a funciones para personalizar las respuestas del modelo y obtener respuestas específicas del dominio.
El ajuste fino es necesario cuando quieres ajustar el estilo, el tono o el formato. Se utiliza para mejorar la fiabilidad y la precisión, manejar avisos complejos o realizar una nueva tarea que el ingeniero de avisos no pudo realizar.
En este tutorial, afinaremos el modelo GPT-4o Mini para clasificar el texto en etiquetas de "estrés" y "no estrés". Posteriormente, accederemos al modelo afinado utilizando la API de OpenAI y el patio de recreo de OpenAI. Por último, evaluaremos el modelo afinado comparando su rendimiento antes y después de afinarlo utilizando varias métricas de clasificación.

Imagen del autor
GPT-4o Mini es el modelo de gran lengua general más rentable que existe. Obtiene un 82% en la MMLU y actualmente supera a Claude 3.5 Sonnet en preferencias de chat en la clasificación LMSYS. Su precio es de 15 céntimos por millón de fichas de entrada y 60 céntimos por millón de fichas de salida, lo que es un 60% más barato que el GPT-3.5 Turbo.
GPT-4o mini admite actualmente texto e imágenes como entrada. El modelo tiene una ventana de contexto de 128K fichas, admite hasta 16K fichas de salida por solicitud, y tiene conocimientos hasta octubre de 2023. GPT-4o Mini puede manejar texto no inglés, ya que utiliza el tokenizador GPT-4o. Obtenemos lo mejor de ambos mundos a bajo coste.
Conoce el caso de uso, la API de finalización del chat y los puntos de referencia detallados de GPT-4o Mini leyendo nuestro blog, ¿Qué es GPT-4o Mini?
Ir a la página OpenAI y crea una cuenta. El ajuste es caro, y utilizar el GPT-4o Mini a través de la API requiere que tengas un método de pago asociado a tu cuenta. Para evitar cualquier contratiempo, asegúrate de que tienes al menos un saldo de 10 USD en tu cuenta antes de intentar ajustar el modelo.
Ve al panel principal, haz clic en la pestaña "Claves API" y genera la clave secreta de la API de OpenAI.
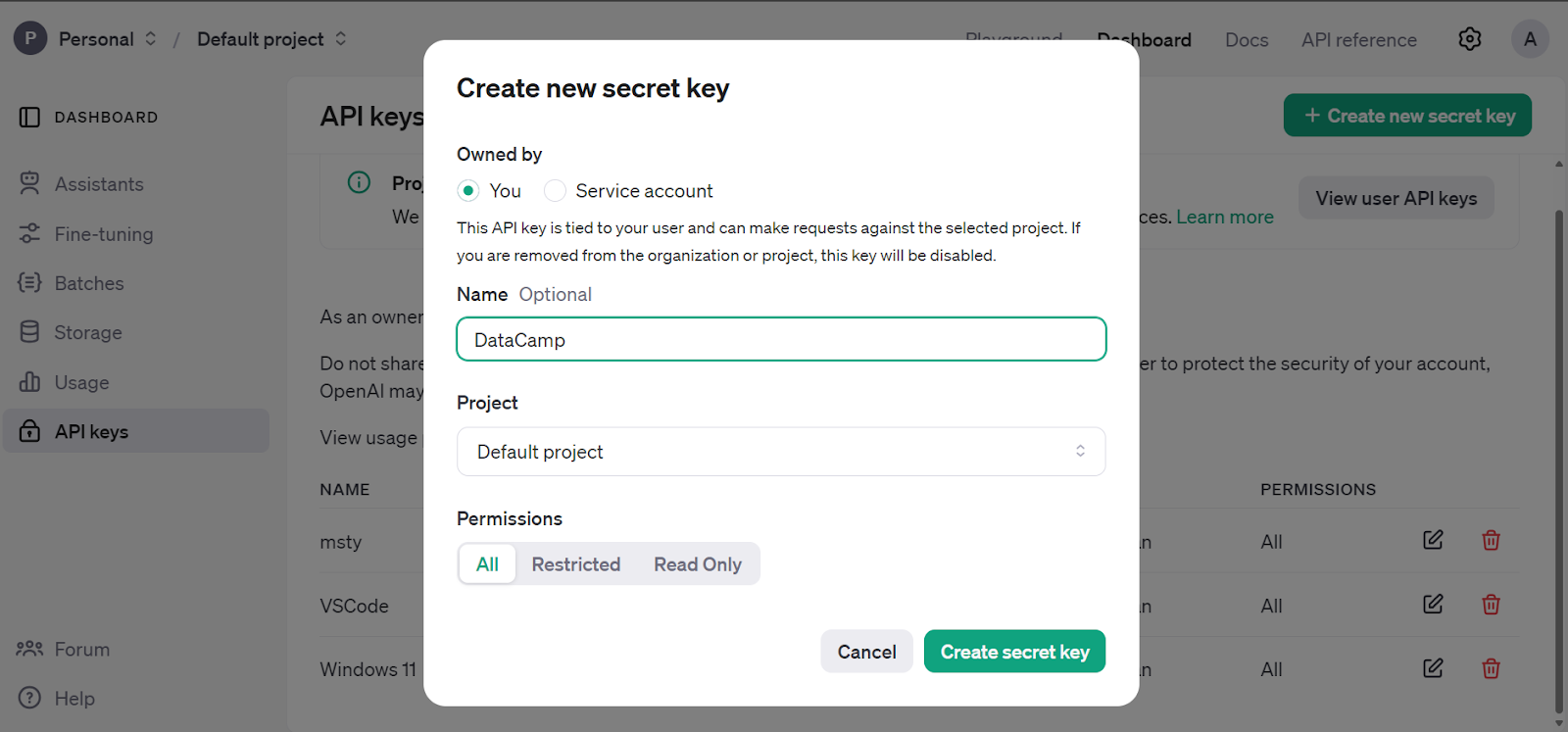
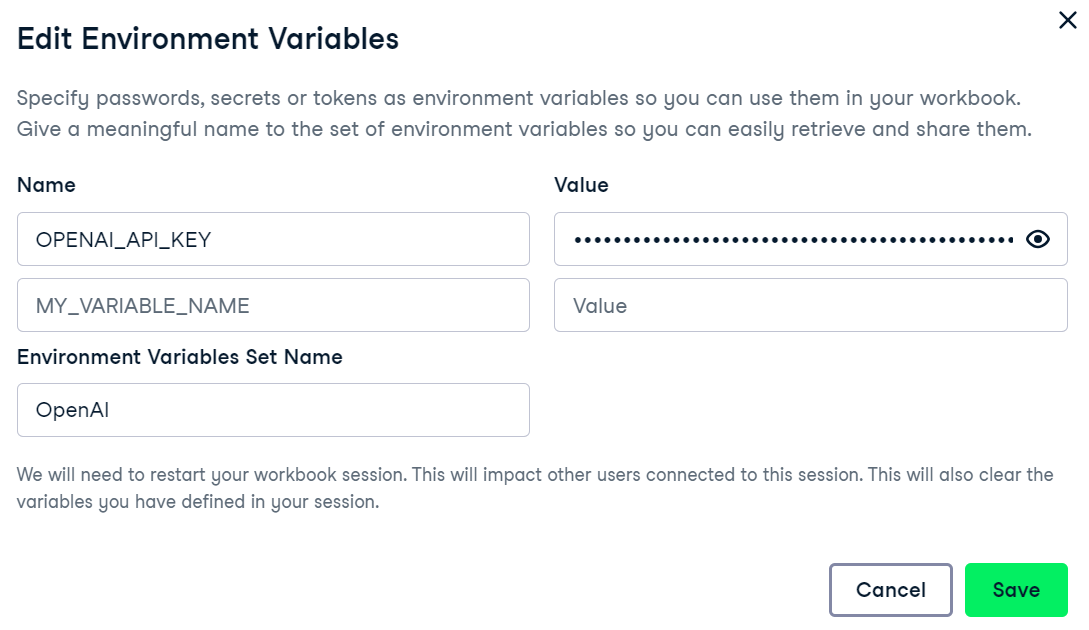
Estamos utilizando el DataLab como editor de código. Para configurar la variable de entorno de la clave de la API de OpenAI, ve a la pestaña entorno y haz clic en la opción variable de entorno. A continuación, añade la variable de entorno para la clave API y actívala como se muestra a continuación.
Instala el paquete OpenAI Python para acceder a la GPT-4o Mini.
%%capture
%pip install openai
Crea el cliente utilizando la clave de la API de OpenAI y genera una respuesta utilizando el ejemplo de consulta. La función de completar chat requiere el nombre del modelo y los mensajes en formato de lista de diccionario.
from IPython.display import Markdown, display
from openai import OpenAI
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(api_key=openai_api_key)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a great philosopher."},
{"role": "user", "content": "What is the meaning of life?"}
]
)
display(Markdown(response.choices[0].message.content))Nuestra API OpenAI está totalmente configurada, y estamos listos para iniciar el trabajo de ajuste.

¿Eres nuevo en la API de OpenAI? Puedes seguir el sencillo y detallado tutorial Tutorial de la API GPT-4o: Primeros pasos con la API de OpenAI para entender cómo escribir unas pocas líneas de código para acceder a modelos de última generación.
En esta sección, pondremos a punto el modelo GPT-4o Mini sobre Detección de estrés en artículos de redes sociales de Kaggle. El conjunto de datos contiene publicaciones de Reddit y Twitter, clasificándolas en etiquetas de estrés y no estrés.
Ahora cargaremos y procesaremos el conjunto de datos.
Nota: Asegúrate de que el formato del conjunto de datos es correcto, lo que incluye la consulta al sistema, la consulta al usuario y la respuesta. La respuesta será la etiqueta.
import pandas as pd
import json
from sklearn.model_selection import train_test_split
# Load the CSV file with the correct delimiter
file_path = 'Reddit_Title.csv' # Change this to your local path
data = pd.read_csv(file_path, sep=';')
# Clean up and drop unnecessary columns, and select the top 200 rows
data_cleaned = data[['title', 'label']].head(200)
# Mapping the 'label' column to more human-readable text
label_mapping = {0: "non-stress", 1: "stress"}
data_cleaned['label'] = data_cleaned['label'].map(label_mapping)
# Split the data into training and validation sets (80% train, 20% validation)
train_data, validation_data = train_test_split(data_cleaned, test_size=0.2, random_state=42)
def save_to_jsonl(data, output_file_path):
jsonl_data = []
for index, row in data.iterrows():
jsonl_data.append({
"messages": [
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": row['title']},
{"role": "assistant", "content": f"\"{row['label']}\""}
]
})
# Save to JSONL format
with open(output_file_path, 'w') as f:
for item in jsonl_data:
f.write(json.dumps(item) + '\n')
# Save the training and validation sets to separate JSONL files
train_output_file_path = 'stress_detection_train.jsonl'
validation_output_file_path = 'stress_detection_validation.jsonl'
save_to_jsonl(train_data, train_output_file_path)
save_to_jsonl(validation_data, validation_output_file_path)
print(f"Training dataset save to {train_output_file_path}")
print(f"Validation dataset save to {validation_output_file_path}")Salida:
Training dataset save to stress_detection_train.jsonl
Validation dataset save to stress_detection_validation.jsonlAhora utilizaremos el cliente OpenAI para cargar los conjuntos de datos de entrenamiento y validación para su ajuste.
train_file = client.files.create(
file=open(train_output_file_path, "rb"),
purpose="fine-tune"
)
valid_file = client.files.create(
file=open(validation_output_file_path, "rb"),
purpose="fine-tune"
)
print(f"Training file Info: {train_file}")
print(f"Validation file Info: {valid_file}")La API de OpenAI validará primero el conjunto de datos, luego lo cargará y generará metadatos que podremos utilizar para afinar el modelo.
Training file Info: FileObject(id='file-b2lo2chod6xuMhYg9JcEsnp6', bytes=48563, created_at=1727133513, filename='stress_detection_train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)
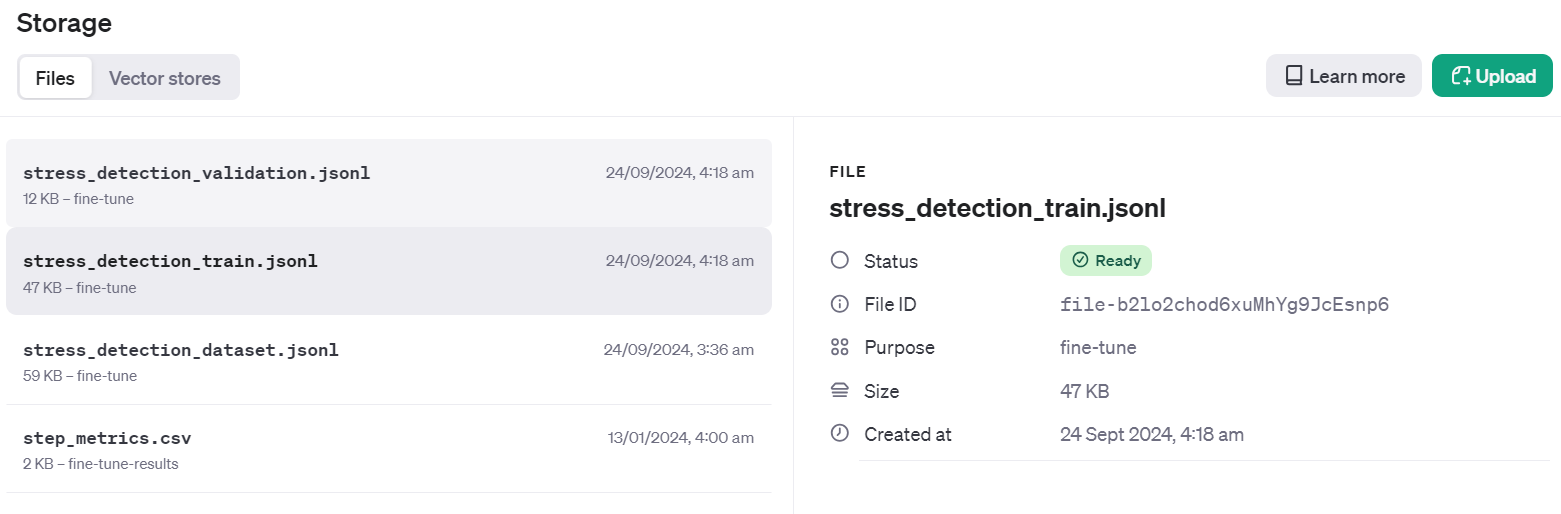
Validation file Info: FileObject(id='file-Fae0AVSUhTGr49qhQz8d2yyp', bytes=12284, created_at=1727133514, filename='stress_detection_validation.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)Para comprobar si el conjunto de datos se ha enviado correctamente a la nube, ve al Panel de control y haz clic en la pestaña "Almacenamiento". Dos archivos estarán allí y listos para ser utilizados.
Crea el trabajo de ajuste fino utilizando la API de cliente. La función de ajuste fino requiere el ID del archivo del conjunto de datos de entrenamiento, el ID del archivo del conjunto de datos de validación, el nombre del modelo y los hiperparámetros. Pondremos a punto nuestro modelo durante tres épocas. Para mejorar el rendimiento del modelo, siempre puedes entrenarte en el conjunto de datos completo con al menos 5 épocas.
model = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=valid_file.id,
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = model.id
status = model.status
print(f'Fine-tuning model with jobID: {job_id}.')
print(f"Training Response: {model}")
print(f"Training Status: {status}")Una vez que ejecutemos la función, el trabajo de ajuste se iniciará y mostrará los registros.
Fine-tuning model with jobID: ftjob-rgIMFxZSsWDqCNfOev54e4Jq.
Training Response: FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='validating_files', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=None, integrations=[], user_provided_suffix=None)
Training Status: validating_filesPodemos ver el estado del trabajo de ajuste fino en el panel de control haciendo clic en la pestaña "Ajuste fino" y pulsando en el ID del trabajo.
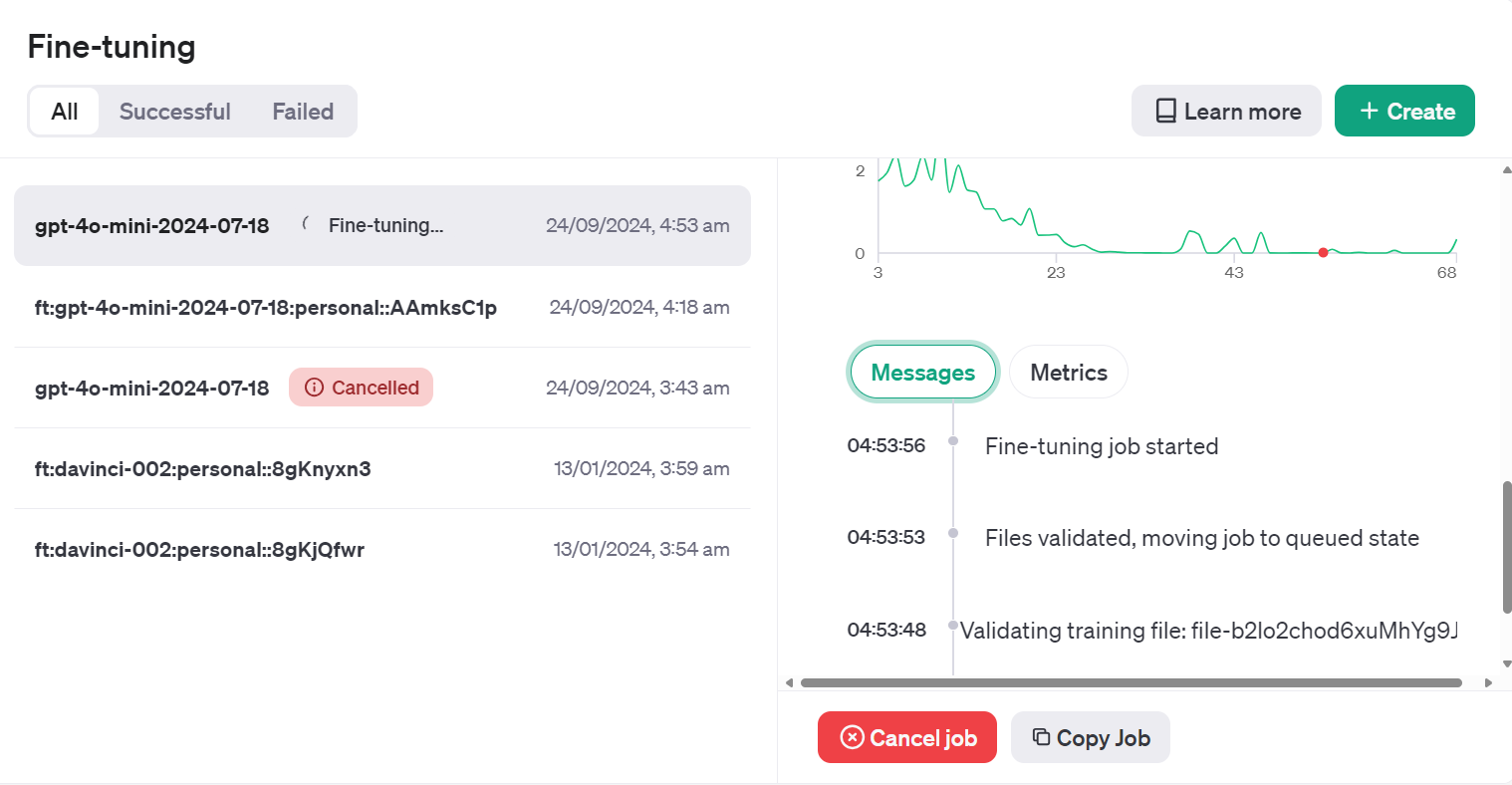
O podemos comprobar el estado del trabajo de ajuste fino utilizando la función jobs.retrieve.
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve(job_id)Salida:
FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='running', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=1727135943, integrations=[], user_provided_suffix=None)Si crees que la pérdida no disminuye, siempre puedes cancelar el trabajo utilizando la función jobs.cancel.
# Cancel a job
client.fine_tuning.jobs.cancel(job_id)Cuando finalice el trabajo de ajuste, recibirás un correo electrónico informándote de que el modelo ajustado está listo para ser utilizado.
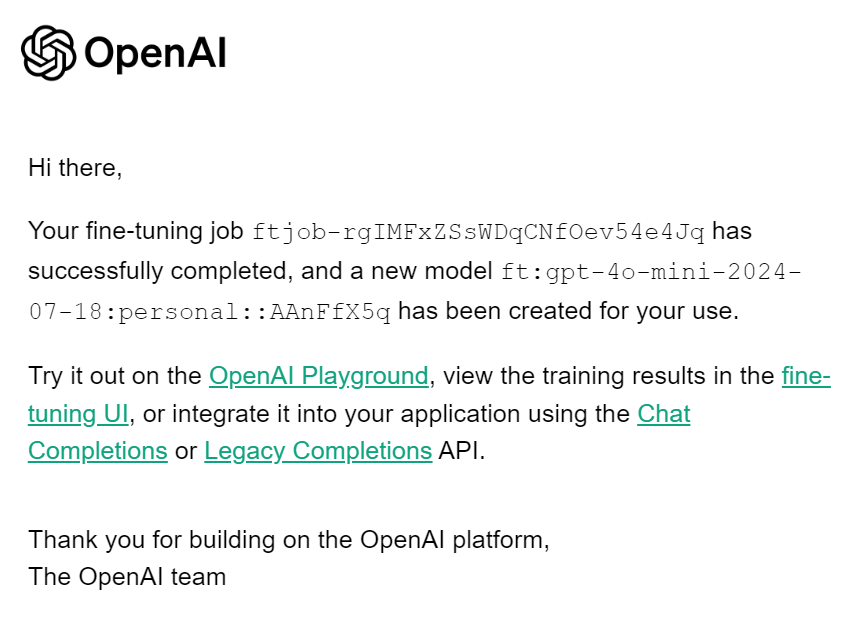
Para acceder al modelo afinado, necesitamos obtener el nombre del modelo afinado. Para ello, recopilaremos información sobre todos los trabajos de puesta a punto, seleccionaremos el último y, a continuación, seleccionaremos el nombre del modelo.
result = client.fine_tuning.jobs.list()
# Retrieve the fine tuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)Este es el nombre de nuestro modelo afinado.
ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5qGenera el reposo proporcionando a la función de finalización del chat un nombre de modelo afinado, mensajes con una indicación correcta del sistema y una muestra del conjunto de datos.
completion = client.chat.completions.create(
model = fine_tuned_model,
messages=[
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": "Just went to my first homecoming, and they played a song I've always wanted to dance to at an official dance. Sorry for the terrible quality, but my happiness in this moment couldn't be exaggerated!"}
]
)
print(completion.choices[0].message.content)¡Éxito! He predicho correctamente la etiqueta.
"non-stress"Si no estás satisfecho con tu modelo, siempre puedes borrarlo utilizando el siguiente comando. No lo haremos porque antes debemos realizar evaluaciones adicionales del modelo.
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete(fine_tuned_model)Hay otra forma de acceder al modelo afinado y probarlo con varias indicaciones de forma más eficaz.
Ve al panel de control de OpenAI, haz clic en la pestaña "Ajuste fino", selecciona el trabajo ejecutado recientemente y, a continuación, haz clic en el botón "Zona de juegos" situado en la parte inferior derecha.
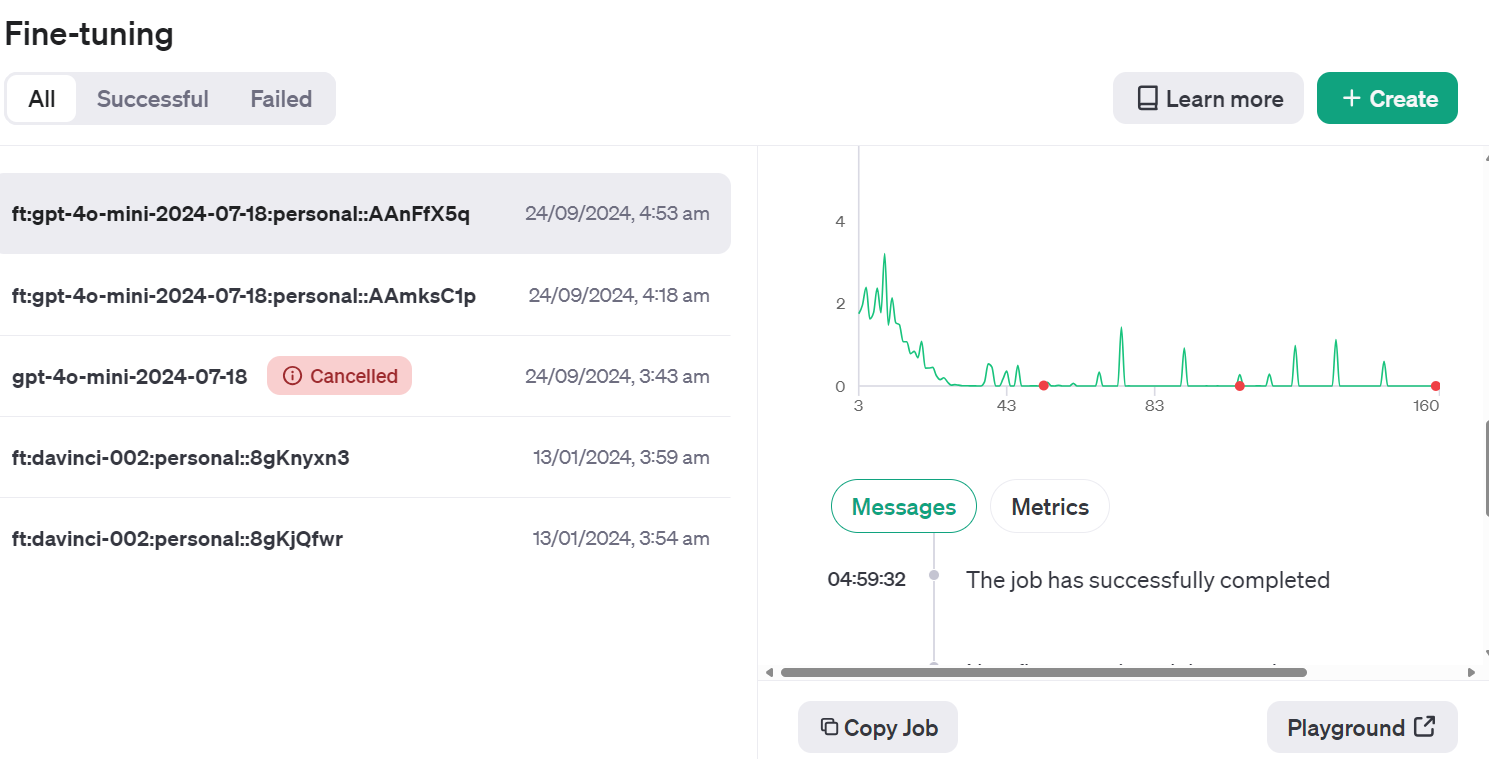
Te llevará a la aplicación del chatbot. Allí, puedes proporcionar una indicación del sistema y empezar a escribir la publicación de ejemplo de Reddit.
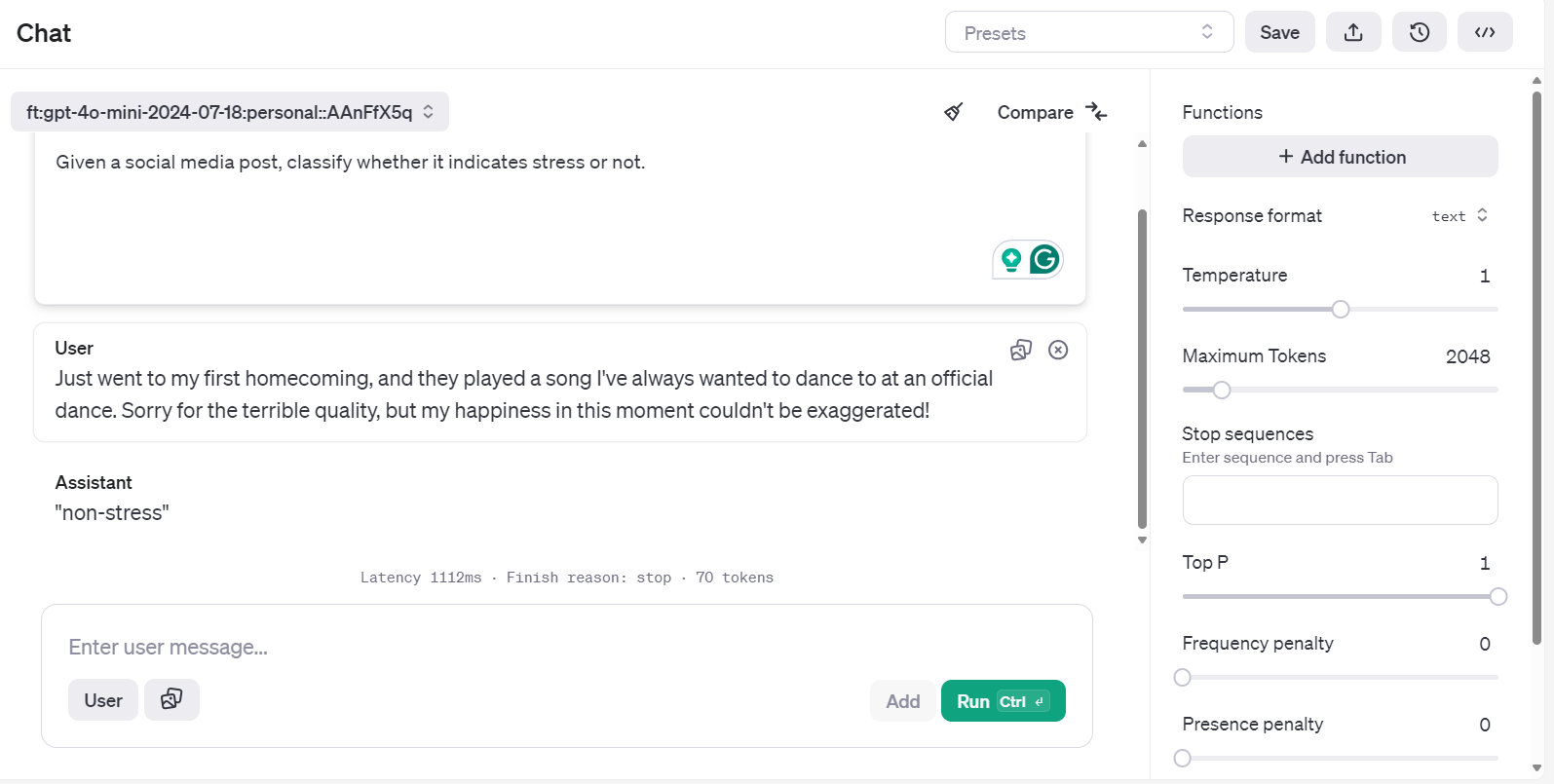
Incluso puedes ejecutar la misma consulta y compararla con otro modelo para un mejor análisis.
Hemos afinado el modelo y creemos que es suficientemente bueno. Pero, ¿te has planteado si ya era mejor desde el principio? No hemos hecho una comparación detallada del antes y el después.
En esta sección, utilizaremos datos de validación para predecir las etiquetas utilizando el modelo base y luego lo compararemos con un modelo afinado. Compararemos ambos modelos basándonos en la precisión, el informe de clasificación y las métricas de confusión.
Crea una función predict que introduzca el conjunto de datos y el nombre del modelo para generar una lista de etiquetas predichas. Utiliza los mismos mensajes de sistema y títulos de entrada del conjunto de datos.
def predict(test, model):
y_pred = []
categories = ["non-stress", "stress"]
for index, row in test.iterrows():
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'.",
},
{"role": "user", "content": row["title"]},
],
)
answer = response.choices[0].message.content
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_predA continuación, crearemos la función evaluate, que utilizará las etiquetas predichas y las reales para generar una puntuación de precisión, un informe de clasificación y una métrica de confusión.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
def evaluate(y_true, y_pred):
labels = ["non-stress", "stress"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(
x, -1
) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f"Accuracy: {accuracy:.3f}")
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [
i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label
]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f"Accuracy for label {labels[label]}: {label_accuracy:.3f}")
# Generate classification report
class_report = classification_report(
y_true=y_true_mapped,
y_pred=y_pred_mapped,
target_names=labels,
labels=list(range(len(labels))),
)
print("\nClassification Report:")
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(
y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels)))
)
print("\nConfusion Matrix:")
print(conf_matrix)
Proporciona a la función predict el conjunto de datos de validación y el nombre del modelo base. A continuación, proporciona las etiquetas predichas y reales a la función evaluate y genera un informe de evaluación del modelo.
y_pred = predict(validation_data, "gpt-4o-mini-2024-07-18")
y_true = validation_data["label"]
evaluate(y_true, y_pred)Nuestro modelo base clasifica bastante bien el texto. Alcanzamos una precisión del 92,5%.
Accuracy: 0.925
Accuracy for label non-stress: 0.947
Accuracy for label stress: 0.905
Classification Report:
precision recall f1-score support
non-stress 0.90 0.95 0.92 19
stress 0.95 0.90 0.93 21
accuracy 0.93 40
macro avg 0.93 0.93 0.92 40
weighted avg 0.93 0.93 0.93 40
Confusion Matrix:
[[18 1]
[ 2 19]]Utilicemos la función predict con el nombre del modelo ajustado para generar etiquetas de tensión. A continuación, podemos utilizar la etiqueta predicha y las etiquetas reales para generar el informe detallado de la ecuación del modelo.
fine_tuned_model = "ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5q"
y_pred = predict(validation_data,fine_tuned_model)
evaluate(y_true, y_pred)El rendimiento de nuestro modelo ha mejorado. Alcanzamos una precisión del 97,5%, lo que supone una mejora significativa.
Accuracy: 0.975
Accuracy for label non-stress: 1.000
Accuracy for label stress: 0.952
Classification Report:
precision recall f1-score support
non-stress 0.95 1.00 0.97 19
stress 1.00 0.95 0.98 21
accuracy 0.97 40
macro avg 0.97 0.98 0.97 40
weighted avg 0.98 0.97 0.98 40
Confusion Matrix:
[[19 0]
[ 1 20]]El ajuste fino en determinadas tareas puede mejorar significativamente la precisión. Se trataba sólo de una prueba de muestra, pero en los proyectos del mundo real, el ajuste fino mejora la precisión y el rendimiento del modelo en tareas de clasificación, estilo y salida estructurada.
Si tienes problemas al ejecutar el código anterior, consulta el espacio de trabajo DataLab: Puesta a punto del GPT-4 Mini.
El siguiente paso en tu viaje es utilizar este modelo afinado para crear una aplicación de IA adecuada. Puedes aprenderlo siguiendo el código: Creación de asistentes de IA con GPT-4o.
En este tutorial, hemos afinado con éxito el minimodelo GPT-4o para clasificar el texto en etiquetas de "estrés" y "no estrés". A continuación, accedimos a este modelo perfeccionado mediante la API de OpenAI y el patio de recreo de OpenAI, lo que permitió su aplicación práctica y la realización de más pruebas.
La evaluación del modelo afinado proporcionó resultados reveladores, demostrando una mejora en el rendimiento de la clasificación en varias métricas en comparación con el modelo base. Este proceso puso de manifiesto el valor del ajuste fino para conseguir un resultado más fiable y preciso, sobre todo cuando se trata de tareas como la clasificación de textos.
Si quieres utilizar un modelo gratuito y de código abierto, tenemos un tutorial excelente llamado Puesta a punto de Llama 3.2 y uso local: Guía paso a paso. En esta guía, te mostraremos cómo poner a punto el último modelo de Llama y convertirlo al formato GGUF para utilizarlo localmente en tu portátil.
Cursos DataCamp OpenAI
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita


