
Curso
Trabalhar com a API da OpenAI
3 h
141.6K
Antes de você começar a fazer o ajuste fino do modelo GPT-4o Mini, recomendamos que você faça a engenharia imediata, encadeamento imediatoe chamada de função para personalizar as respostas do modelo e obter respostas específicas do domínio.
O ajuste fino é necessário quando você deseja ajustar o estilo, o tom ou o formato. Ele é usado para aumentar a confiabilidade e a precisão, lidar com prompts complexos ou executar uma nova tarefa que o engenheiro de prompts não conseguiu realizar.
Neste tutorial, faremos o ajuste fino do modelo GPT-4o Mini para classificar o texto em rótulos de "estresse" e "sem estresse". Posteriormente, acessaremos o modelo ajustado usando a API do OpenAI e o playground do OpenAI. Por fim, avaliaremos o modelo com ajuste fino comparando seu desempenho antes e depois do ajuste usando várias métricas de classificação.

Imagem do autor
O GPT-4o Mini é o modelo de linguagem geral grande mais econômico disponível. Ele tem pontuação de 82% no MMLU e atualmente supera o desempenho do Claude 3.5 Sonnet nas preferências de bate-papo na tabela de classificação do LMSYS. Seu preço é de 15 centavos por milhão de tokens de entrada e 60 centavos por milhão de tokens de saída, o que é 60% mais barato que o GPT-3.5 Turbo.
Atualmente, o GPT-4o mini suporta texto e imagens como entrada. O modelo tem uma janela de contexto de 128 mil tokens, suporta até 16 mil tokens de saída por solicitação e tem conhecimento até outubro de 2023. O GPT-4o Mini pode lidar com textos que não estejam em inglês, pois está usando o tokenizador GPT-4o. Temos o melhor dos dois mundos a um custo baixo.
Saiba mais sobre o caso de uso, a API de conclusão de bate-papo e os benchmarks detalhados do GPT-4o Mini lendo nosso blog, O que é o GPT-4o Mini?
Vá para o site da OpenAI e crie uma conta. O ajuste fino é caro, e o uso do GPT-4o Mini via API exige que você tenha um método de pagamento vinculado à sua conta. Para evitar problemas, certifique-se de que você tenha pelo menos um saldo de crédito de US$ 10 na sua conta antes de tentar ajustar o modelo.
Vá para o painel principal, clique na guia "Chaves de API" e gere a chave secreta da API da OpenAI.
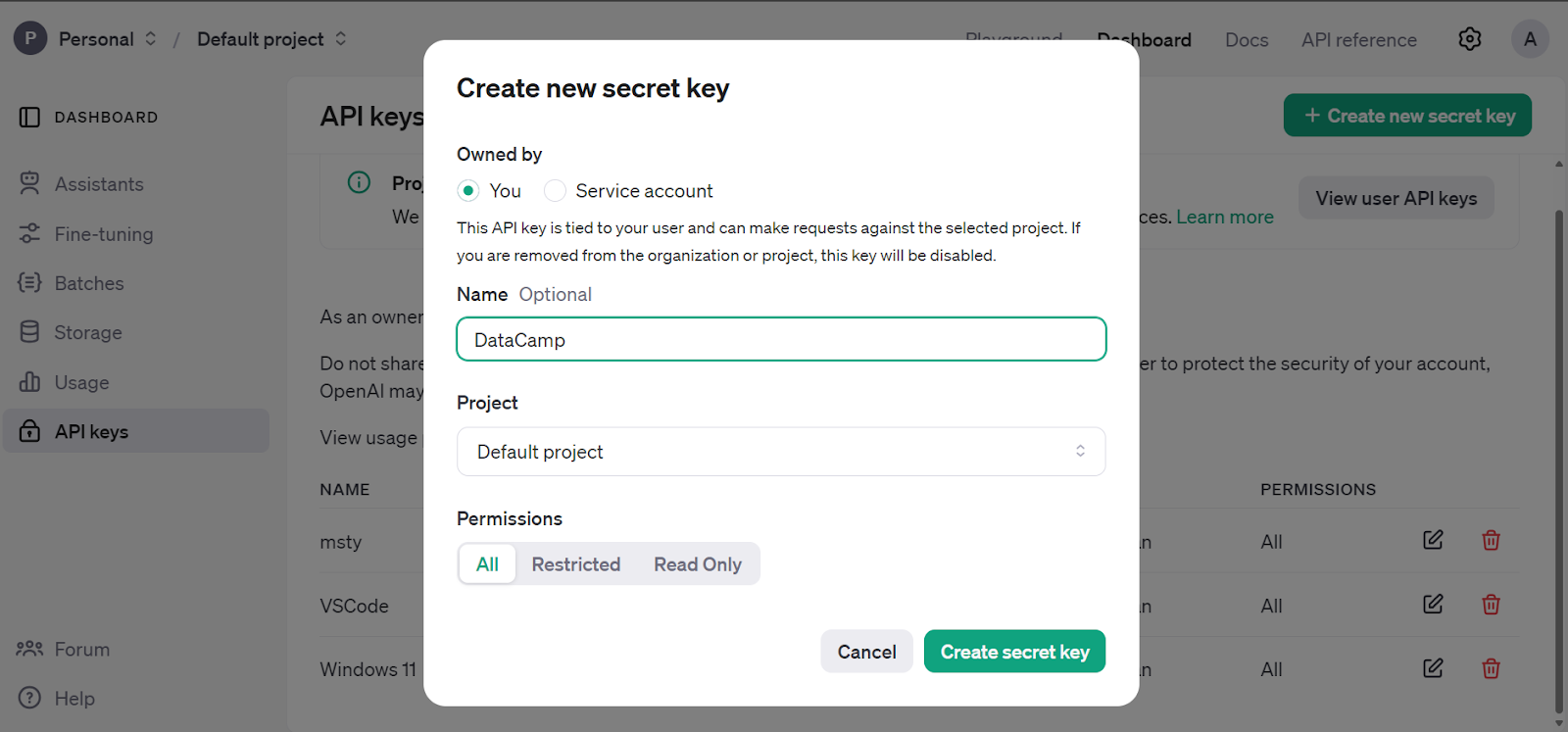
Estamos usando o DataLab da DataCamp como nosso editor de código. Para configurar a variável de ambiente da chave da API da OpenAI, vá para a guia ambiente e clique na opção de variável de ambiente. Em seguida, adicione a variável de ambiente para a chave de API e ative-a conforme mostrado abaixo.
Instale o pacote OpenAI Python para acessar o GPT-4o Mini.
%%capture
%pip install openai
Crie o cliente usando a chave da API da OpenAI e gere uma resposta usando o prompt de amostra. A função de conclusão de bate-papo requer o nome do modelo e as mensagens em uma lista de formato de dicionário.
from IPython.display import Markdown, display
from openai import OpenAI
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(api_key=openai_api_key)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a great philosopher."},
{"role": "user", "content": "What is the meaning of life?"}
]
)
display(Markdown(response.choices[0].message.content))Nossa API OpenAI está totalmente configurada e estamos prontos para iniciar o trabalho de ajuste fino.

Você é novo na API da OpenAI? Você pode seguir o tutorial simples e detalhado GPT-4o API Tutorial: Primeiros passos com a API da OpenAI para você entender como escrever algumas linhas de código para acessar modelos de última geração.
Nesta seção, faremos o ajuste fino do modelo GPT-4o Mini em Detecção de estresse dos artigos de mídia social do Kaggle. O conjunto de dados contém publicações do Reddit e do Twitter, classificando-as em rótulos de estresse e não estresse.
Agora, carregaremos e processaremos o conjunto de dados.
Observação: Garanta o formato correto do conjunto de dados, que inclui o prompt do sistema, a consulta do usuário e a resposta. A resposta será o rótulo.
import pandas as pd
import json
from sklearn.model_selection import train_test_split
# Load the CSV file with the correct delimiter
file_path = 'Reddit_Title.csv' # Change this to your local path
data = pd.read_csv(file_path, sep=';')
# Clean up and drop unnecessary columns, and select the top 200 rows
data_cleaned = data[['title', 'label']].head(200)
# Mapping the 'label' column to more human-readable text
label_mapping = {0: "non-stress", 1: "stress"}
data_cleaned['label'] = data_cleaned['label'].map(label_mapping)
# Split the data into training and validation sets (80% train, 20% validation)
train_data, validation_data = train_test_split(data_cleaned, test_size=0.2, random_state=42)
def save_to_jsonl(data, output_file_path):
jsonl_data = []
for index, row in data.iterrows():
jsonl_data.append({
"messages": [
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": row['title']},
{"role": "assistant", "content": f"\"{row['label']}\""}
]
})
# Save to JSONL format
with open(output_file_path, 'w') as f:
for item in jsonl_data:
f.write(json.dumps(item) + '\n')
# Save the training and validation sets to separate JSONL files
train_output_file_path = 'stress_detection_train.jsonl'
validation_output_file_path = 'stress_detection_validation.jsonl'
save_to_jsonl(train_data, train_output_file_path)
save_to_jsonl(validation_data, validation_output_file_path)
print(f"Training dataset save to {train_output_file_path}")
print(f"Validation dataset save to {validation_output_file_path}")Saída:
Training dataset save to stress_detection_train.jsonl
Validation dataset save to stress_detection_validation.jsonlAgora, usaremos o cliente OpenAI para carregar os conjuntos de dados de treinamento e validação para ajuste fino.
train_file = client.files.create(
file=open(train_output_file_path, "rb"),
purpose="fine-tune"
)
valid_file = client.files.create(
file=open(validation_output_file_path, "rb"),
purpose="fine-tune"
)
print(f"Training file Info: {train_file}")
print(f"Validation file Info: {valid_file}")A API da OpenAI primeiro validará o conjunto de dados, depois fará o upload dos conjuntos de dados e gerará metadados que poderemos usar para ajustar o modelo.
Training file Info: FileObject(id='file-b2lo2chod6xuMhYg9JcEsnp6', bytes=48563, created_at=1727133513, filename='stress_detection_train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)
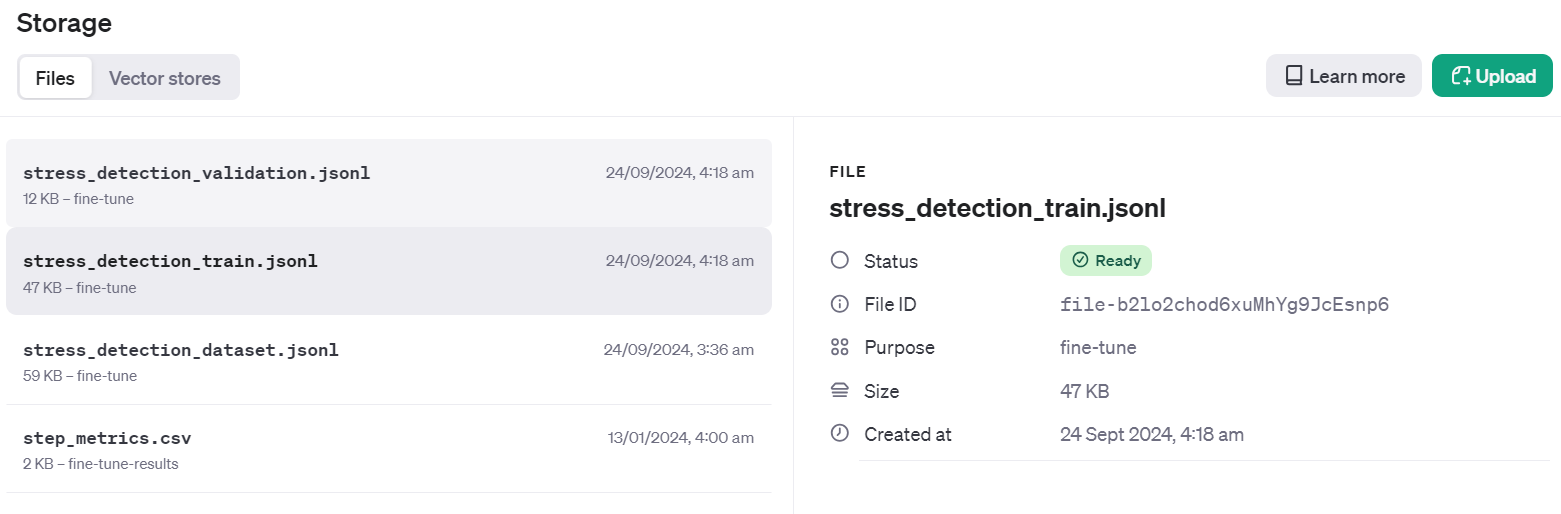
Validation file Info: FileObject(id='file-Fae0AVSUhTGr49qhQz8d2yyp', bytes=12284, created_at=1727133514, filename='stress_detection_validation.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)Para verificar se o conjunto de dados foi enviado com êxito para a nuvem, vá para o Dashboard e clique na guia "Storage" (Armazenamento). Dois arquivos estarão lá e prontos para serem usados.
Crie o trabalho de ajuste fino usando a API do cliente. A função de ajuste fino requer o ID do arquivo do conjunto de dados de treinamento, o ID do arquivo do conjunto de dados de validação, o nome do modelo e os hiperparâmetros. Faremos o ajuste fino de nosso modelo em três épocas. Para melhorar o desempenho do modelo, você sempre pode treinar no conjunto de dados completo com pelo menos 5 épocas.
model = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=valid_file.id,
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = model.id
status = model.status
print(f'Fine-tuning model with jobID: {job_id}.')
print(f"Training Response: {model}")
print(f"Training Status: {status}")Quando executarmos a função, o trabalho de ajuste fino será iniciado e exibirá os registros.
Fine-tuning model with jobID: ftjob-rgIMFxZSsWDqCNfOev54e4Jq.
Training Response: FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='validating_files', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=None, integrations=[], user_provided_suffix=None)
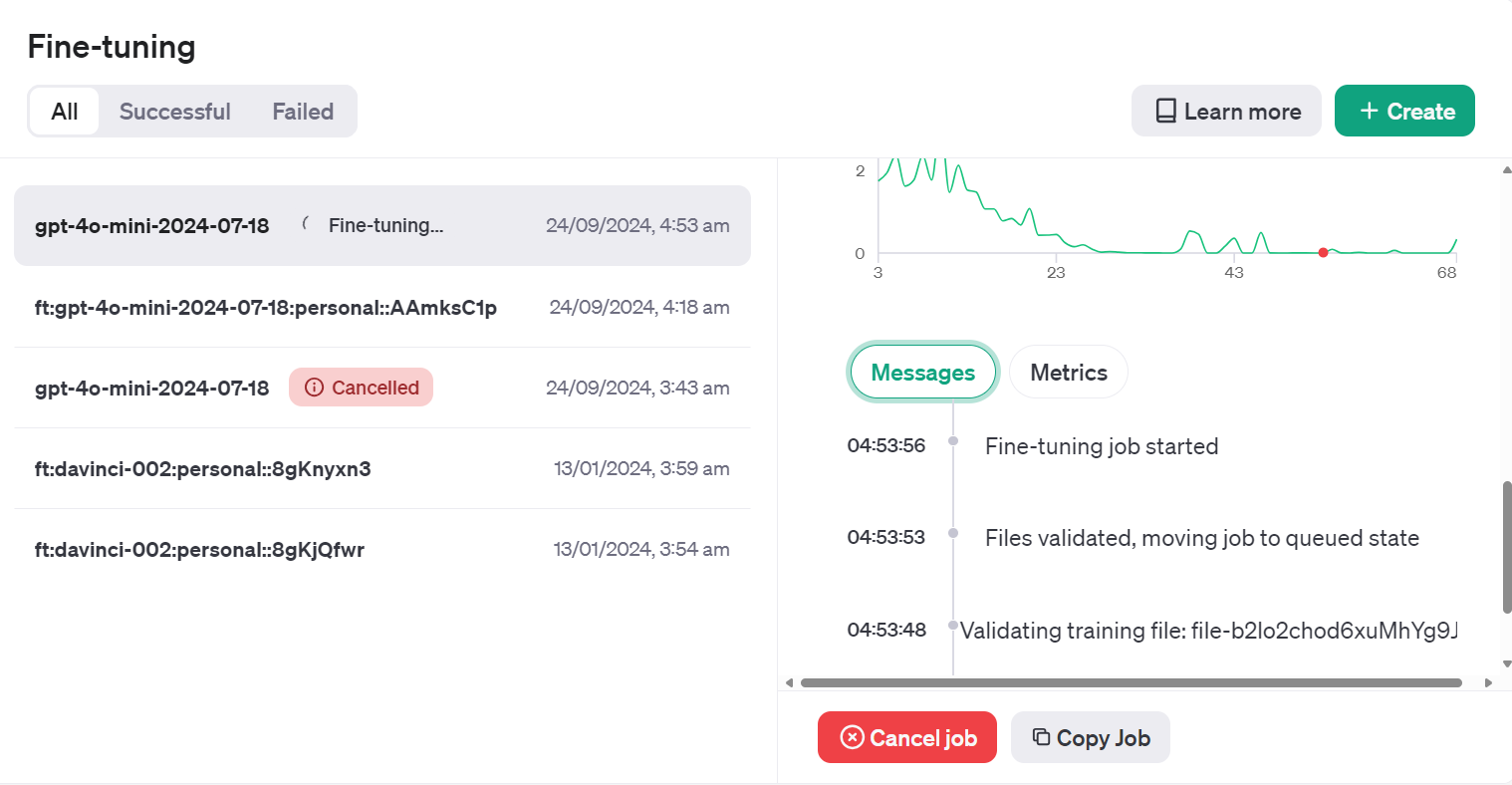
Training Status: validating_filesVocê pode visualizar o status do trabalho de ajuste fino no painel clicando na guia "Fine-tuning" (Ajuste fino) e clicando no ID do trabalho.
Ou podemos verificar o status do trabalho de ajuste fino usando a função jobs.retrieve.
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve(job_id)Saída:
FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='running', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=1727135943, integrations=[], user_provided_suffix=None)Se achar que a perda não está diminuindo, você sempre poderá cancelar o trabalho usando a função jobs.cancel.
# Cancel a job
client.fine_tuning.jobs.cancel(job_id)Quando o trabalho de ajuste fino for concluído, você receberá um e-mail informando que o modelo ajustado está pronto para ser usado.
Para acessar o modelo com ajuste fino, precisamos obter o nome do modelo com ajuste fino. Para fazer isso, reuniremos informações sobre todos os trabalhos de ajuste fino, selecionaremos o mais recente e, em seguida, selecionaremos o nome do modelo.
result = client.fine_tuning.jobs.list()
# Retrieve the fine tuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)Esse é o nome do nosso modelo ajustado.
ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5qGerar repouso fornecendo à função de conclusão de bate-papo um nome de modelo ajustado, mensagens com um prompt de sistema correto e uma amostra do conjunto de dados.
completion = client.chat.completions.create(
model = fine_tuned_model,
messages=[
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": "Just went to my first homecoming, and they played a song I've always wanted to dance to at an official dance. Sorry for the terrible quality, but my happiness in this moment couldn't be exaggerated!"}
]
)
print(completion.choices[0].message.content)Sucesso! Eu previ o rótulo corretamente.
"non-stress"Se não estiver satisfeito com seu modelo, você sempre poderá excluí-lo usando o seguinte comando. Não faremos isso porque precisamos executar avaliações adicionais do modelo primeiro.
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete(fine_tuned_model)Há outra maneira de acessar o modelo ajustado e testá-lo em vários prompts com mais eficiência.
Acesse o painel do OpenAI, clique na guia "Fine-tuning" (Ajuste fino), selecione o trabalho executado recentemente e, em seguida, clique no botão "Playground" (Playground) localizado no canto inferior direito.
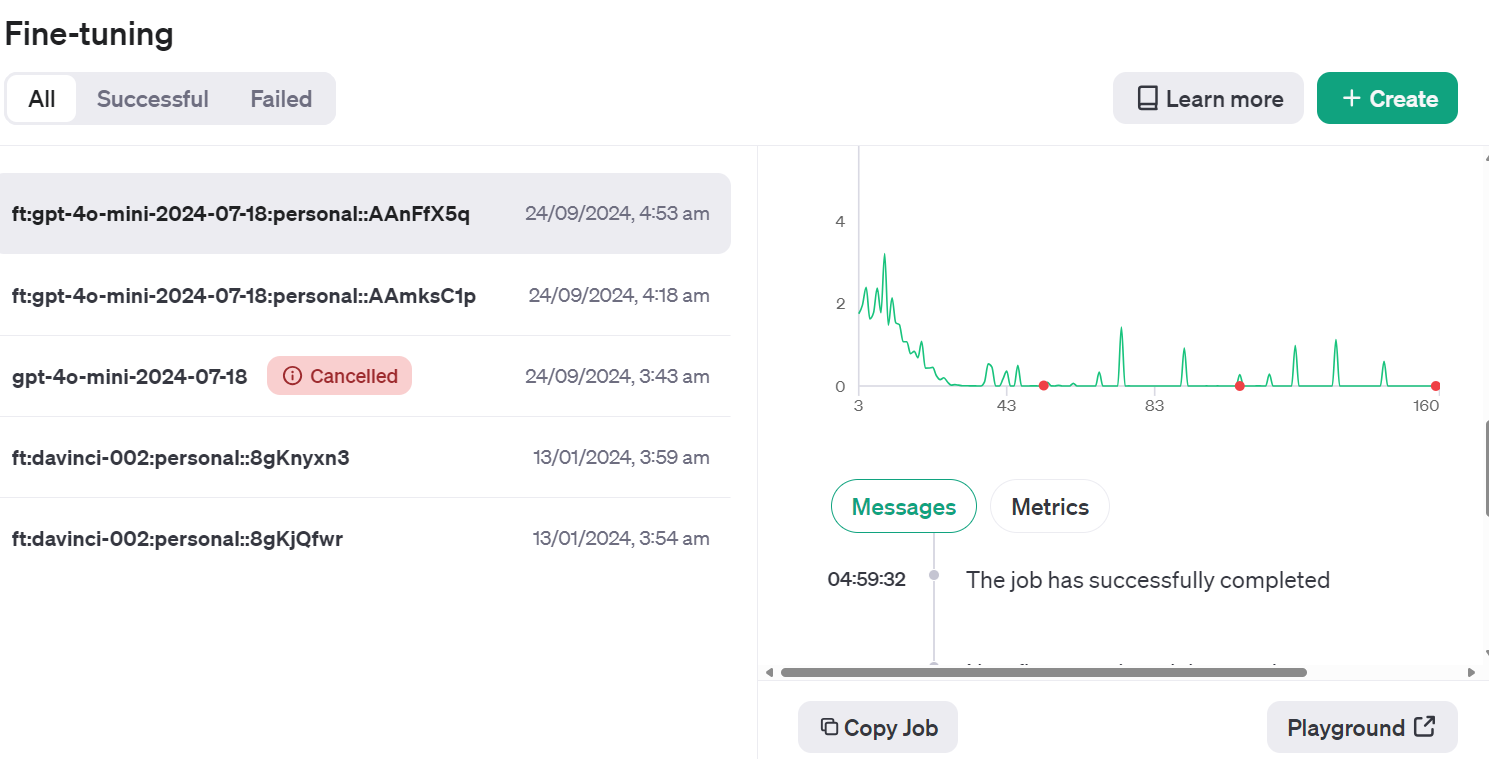
Isso levará você ao aplicativo do chatbot. Lá, você pode fornecer um prompt do sistema e começar a digitar a postagem de exemplo do Reddit.
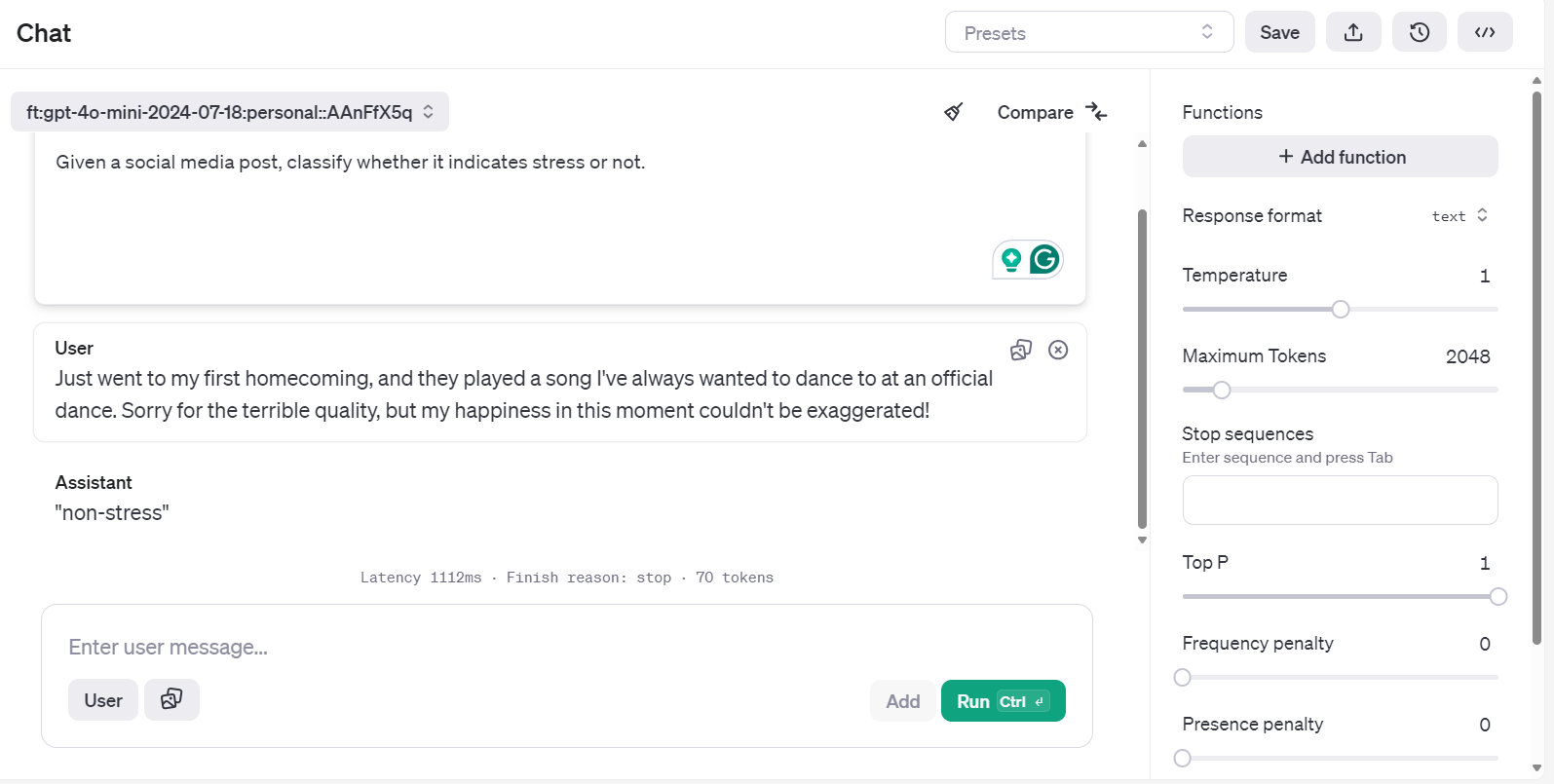
Você pode até mesmo executar o mesmo prompt e compará-lo com outro modelo para uma melhor análise.
Nós ajustamos o modelo e acreditamos que ele é bom o suficiente. Mas você já pensou se já era melhor desde o início? Não fizemos uma comparação detalhada antes e depois.
Nesta seção, usaremos dados de validação para prever os rótulos usando o modelo básico e depois o compararemos com um modelo ajustado. Compararemos os dois modelos com base na precisão, no relatório de classificação e nas métricas de confusão.
Crie uma função predict que insira o conjunto de dados e o nome do modelo para gerar uma lista de rótulos previstos. Ele usa as mesmas mensagens do sistema e títulos de postagens do conjunto de dados.
def predict(test, model):
y_pred = []
categories = ["non-stress", "stress"]
for index, row in test.iterrows():
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'.",
},
{"role": "user", "content": row["title"]},
],
)
answer = response.choices[0].message.content
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_predEm seguida, criaremos a função evaluate, que usará os rótulos previstos e reais para gerar uma pontuação de precisão, um relatório de classificação e métricas de confusão.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
def evaluate(y_true, y_pred):
labels = ["non-stress", "stress"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(
x, -1
) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f"Accuracy: {accuracy:.3f}")
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [
i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label
]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f"Accuracy for label {labels[label]}: {label_accuracy:.3f}")
# Generate classification report
class_report = classification_report(
y_true=y_true_mapped,
y_pred=y_pred_mapped,
target_names=labels,
labels=list(range(len(labels))),
)
print("\nClassification Report:")
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(
y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels)))
)
print("\nConfusion Matrix:")
print(conf_matrix)
Forneça à função predict o conjunto de dados de validação e o nome do modelo básico. Em seguida, forneça os rótulos previstos e reais para a função evaluate e gere um relatório de avaliação do modelo.
y_pred = predict(validation_data, "gpt-4o-mini-2024-07-18")
y_true = validation_data["label"]
evaluate(y_true, y_pred)Nosso modelo básico é muito bom para classificar o texto. Obtivemos 92,5% de precisão.
Accuracy: 0.925
Accuracy for label non-stress: 0.947
Accuracy for label stress: 0.905
Classification Report:
precision recall f1-score support
non-stress 0.90 0.95 0.92 19
stress 0.95 0.90 0.93 21
accuracy 0.93 40
macro avg 0.93 0.93 0.92 40
weighted avg 0.93 0.93 0.93 40
Confusion Matrix:
[[18 1]
[ 2 19]]Vamos usar a função predict com o nome do modelo ajustado para gerar rótulos de estresse. Em seguida, podemos usar o rótulo previsto e os rótulos reais para gerar o relatório detalhado da equação do modelo.
fine_tuned_model = "ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5q"
y_pred = predict(validation_data,fine_tuned_model)
evaluate(y_true, y_pred)O desempenho do nosso modelo melhorou. Alcançamos 97,5% de precisão, o que representa uma melhoria significativa.
Accuracy: 0.975
Accuracy for label non-stress: 1.000
Accuracy for label stress: 0.952
Classification Report:
precision recall f1-score support
non-stress 0.95 1.00 0.97 19
stress 1.00 0.95 0.98 21
accuracy 0.97 40
macro avg 0.97 0.98 0.97 40
weighted avg 0.98 0.97 0.98 40
Confusion Matrix:
[[19 0]
[ 1 20]]O ajuste fino de determinadas tarefas pode melhorar significativamente a precisão. Esse foi apenas um teste de amostra, mas em projetos do mundo real, o ajuste fino melhora a precisão e o desempenho do modelo em tarefas de classificação, estilo e saída estruturada.
Se você estiver com problemas para executar o código acima, consulte o espaço de trabalho do DataLab: Ajuste fino do GPT-4 Mini.
A próxima etapa da sua jornada é usar esse modelo ajustado para criar um aplicativo de IA adequado. Você pode aprender sobre isso seguindo o código: Criação de assistentes de IA com o GPT-4o.
Neste tutorial, ajustamos com sucesso o mini modelo GPT-4o para classificar o texto em rótulos de "estresse" e "sem estresse". Em seguida, acessamos esse modelo ajustado usando a API OpenAI e o playground OpenAI, permitindo a aplicação prática e testes adicionais.
A avaliação do modelo ajustado forneceu resultados perspicazes, demonstrando uma melhoria no desempenho da classificação em várias métricas quando comparado ao modelo básico. Esse processo destacou o valor do ajuste fino para obter um resultado mais confiável e preciso, especialmente ao lidar com tarefas como classificação de texto.
Se você deseja usar um modelo gratuito e de código aberto, temos um excelente tutorial chamado Fine-tuning Llama 3.2 and Using It Locally: Um guia passo a passo. Neste guia, mostraremos a você como ajustar o modelo mais recente do Llama e convertê-lo no formato GGUF para uso local no seu laptop.
Principais cursos do DataCamp OpenAI
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Nisha Arya Ahmed
10 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Arunn Thevapalan




