
Cours
Travailler avec l'API OpenAI
3 h
142.5K
Avant de commencer à peaufiner le modèle GPT-4o Mini, nous vous recommandons l'ingénierie rapide, un chaînage rapideet appel de fonction pour personnaliser les réponses du modèle et obtenir des réponses spécifiques au domaine.
La mise au point est nécessaire lorsque vous souhaitez ajuster le style, le ton ou le format. Il est utilisé pour améliorer la fiabilité et la précision, traiter des messages complexes ou effectuer une nouvelle tâche que l'ingénieur chargé du message n'a pas pu réaliser.
Dans ce tutoriel, nous allons affiner le modèle GPT-4o Mini pour classer le texte en étiquettes "stress" et "non stress". Par la suite, nous accéderons au modèle affiné à l'aide de l'API OpenAI et de l'aire de jeu OpenAI. Enfin, nous évaluerons le modèle ajusté en comparant ses performances avant et après l'ajustement à l'aide de diverses mesures de classification.

Image par l'auteur
GPT-4o Mini est le modèle de langue générale le plus rentable qui soit. Il obtient un score de 82% sur le MMLU et surpasse actuellement les performances suivantes Claude 3.5 Sonnet sur les préférences de chat dans le classement LMSYS. Son prix est de 15 cents par million de jetons d'entrée et de 60 cents par million de jetons de sortie, soit 60 % de moins que le GPT-3.5 Turbo.
Le GPT-4o mini prend actuellement en charge le texte et les images en entrée. Le modèle dispose d'une fenêtre contextuelle de 128 000 jetons, prend en charge jusqu'à 16 000 jetons de sortie par demande et dispose de connaissances jusqu'en octobre 2023. GPT-4o Mini peut traiter des textes non anglais, car il utilise le tokenizer de GPT-4o. Nous bénéficions du meilleur des deux mondes à moindre coût.
Découvrez le cas d'utilisation, l'API d'achèvement du chat et les références détaillées de GPT-4o Mini en lisant notre blog, Qu'est-ce que GPT-4o Mini ?
Rendez-vous sur le site de l OpenAI et créez un compte. La mise au point est coûteuse et l'utilisation du GPT-4o Mini via l'API nécessite qu'une méthode de paiement soit associée à votre compte. Pour éviter tout problème, assurez-vous de disposer d'un solde créditeur d'au moins 10 USD sur votre compte avant d'essayer d'affiner le modèle.
Allez dans le tableau de bord principal, cliquez sur l'onglet "clés API" et générez la clé secrète de l'API OpenAI.
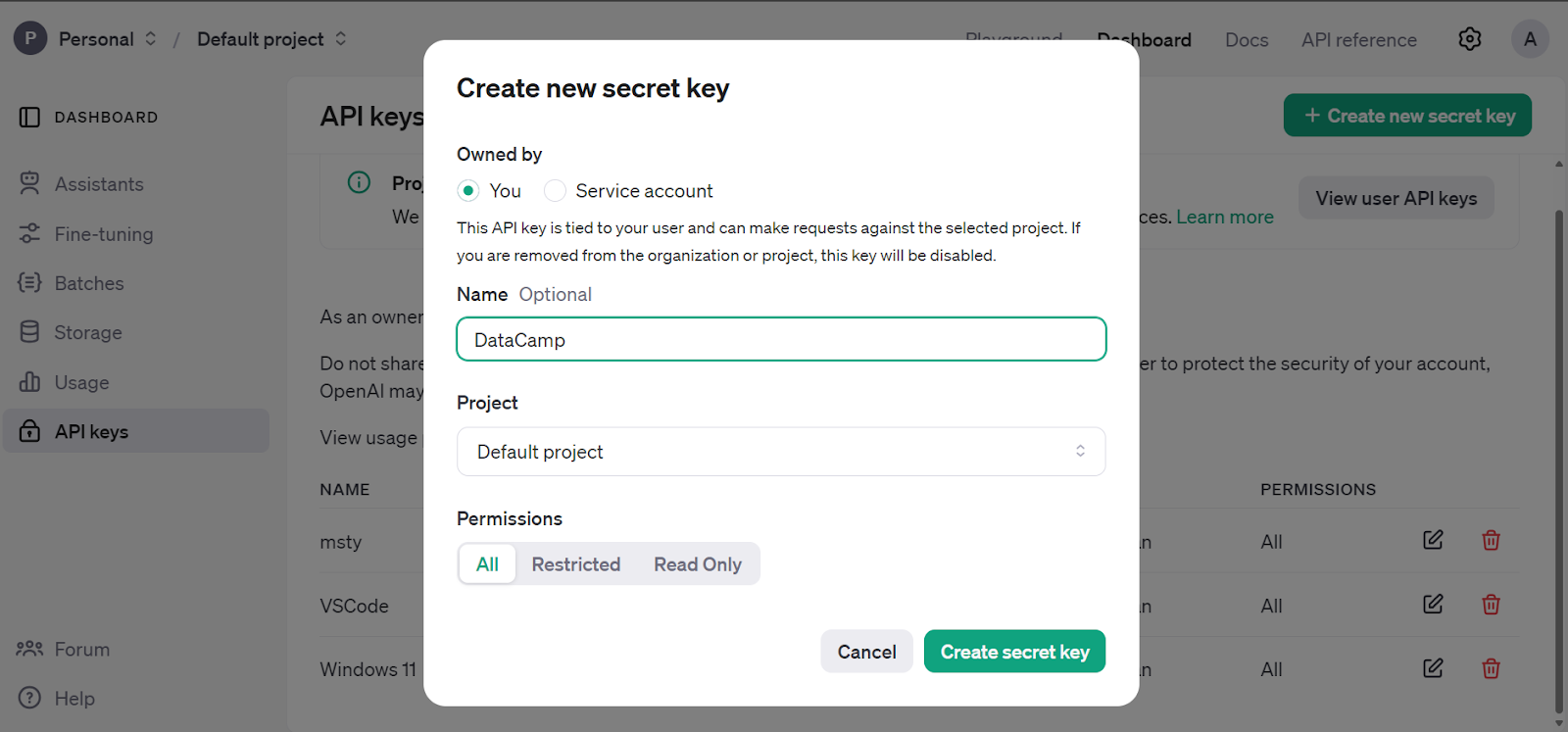
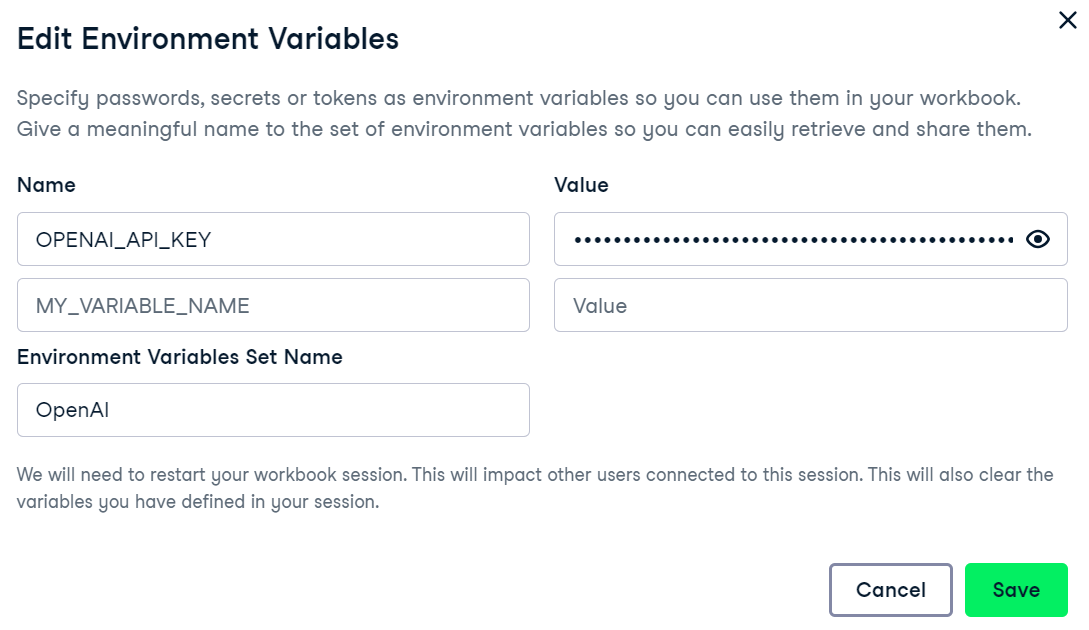
Nous utilisons le logiciel de DataCamp, le DataLab de DataCamp comme éditeur de code. Pour configurer la variable d'environnement de la clé API OpenAI, allez dans l'onglet Environnement et cliquez sur l'option Variable d'environnement. Ensuite, ajoutez la variable d'environnement pour la clé API et activez-la comme indiqué ci-dessous.
Installez le paquet OpenAI Python pour accéder au GPT-4o Mini.
%%capture
%pip install openai
Créez le client à l'aide de la clé API OpenAI et générez une réponse à l'aide de l'exemple d'invite. La fonction d'achèvement du chat requiert le nom du modèle et les messages sous forme de liste de dictionnaires.
from IPython.display import Markdown, display
from openai import OpenAI
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(api_key=openai_api_key)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a great philosopher."},
{"role": "user", "content": "What is the meaning of life?"}
]
)
display(Markdown(response.choices[0].message.content))Notre API OpenAI est entièrement configurée et nous sommes prêts à entamer le travail de mise au point.

Nouveau dans l'API d'OpenAI ? Vous pouvez suivre le tutoriel simple et détaillé GPT-4o API Tutorial : Premiers pas avec l'API d'OpenAI pour comprendre comment écrire quelques lignes de code pour accéder à des modèles de pointe.
Dans cette section, nous allons affiner le modèle GPT-4o Mini sur la base des données suivantes Détection du stress dans les articles de médias sociaux de Kaggle. L'ensemble de données contient des messages provenant de Reddit et de Twitter, classés en deux catégories : les messages stressants et les messages non stressants.
Nous allons maintenant charger et traiter l'ensemble de données.
Note : Veillez à ce que le format de l'ensemble de données soit correct, c'est-à-dire qu'il comprenne l'invite du système, la requête de l'utilisateur et la réponse. La réponse sera l'étiquette.
import pandas as pd
import json
from sklearn.model_selection import train_test_split
# Load the CSV file with the correct delimiter
file_path = 'Reddit_Title.csv' # Change this to your local path
data = pd.read_csv(file_path, sep=';')
# Clean up and drop unnecessary columns, and select the top 200 rows
data_cleaned = data[['title', 'label']].head(200)
# Mapping the 'label' column to more human-readable text
label_mapping = {0: "non-stress", 1: "stress"}
data_cleaned['label'] = data_cleaned['label'].map(label_mapping)
# Split the data into training and validation sets (80% train, 20% validation)
train_data, validation_data = train_test_split(data_cleaned, test_size=0.2, random_state=42)
def save_to_jsonl(data, output_file_path):
jsonl_data = []
for index, row in data.iterrows():
jsonl_data.append({
"messages": [
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": row['title']},
{"role": "assistant", "content": f"\"{row['label']}\""}
]
})
# Save to JSONL format
with open(output_file_path, 'w') as f:
for item in jsonl_data:
f.write(json.dumps(item) + '\n')
# Save the training and validation sets to separate JSONL files
train_output_file_path = 'stress_detection_train.jsonl'
validation_output_file_path = 'stress_detection_validation.jsonl'
save_to_jsonl(train_data, train_output_file_path)
save_to_jsonl(validation_data, validation_output_file_path)
print(f"Training dataset save to {train_output_file_path}")
print(f"Validation dataset save to {validation_output_file_path}")Sortie:
Training dataset save to stress_detection_train.jsonl
Validation dataset save to stress_detection_validation.jsonlNous allons maintenant utiliser le client OpenAI pour télécharger les ensembles de données d'entraînement et de validation afin de les affiner.
train_file = client.files.create(
file=open(train_output_file_path, "rb"),
purpose="fine-tune"
)
valid_file = client.files.create(
file=open(validation_output_file_path, "rb"),
purpose="fine-tune"
)
print(f"Training file Info: {train_file}")
print(f"Validation file Info: {valid_file}")L'API OpenAI validera d'abord l'ensemble de données, puis téléchargera les ensembles de données et générera des métadonnées que nous pourrons utiliser pour affiner le modèle.
Training file Info: FileObject(id='file-b2lo2chod6xuMhYg9JcEsnp6', bytes=48563, created_at=1727133513, filename='stress_detection_train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)
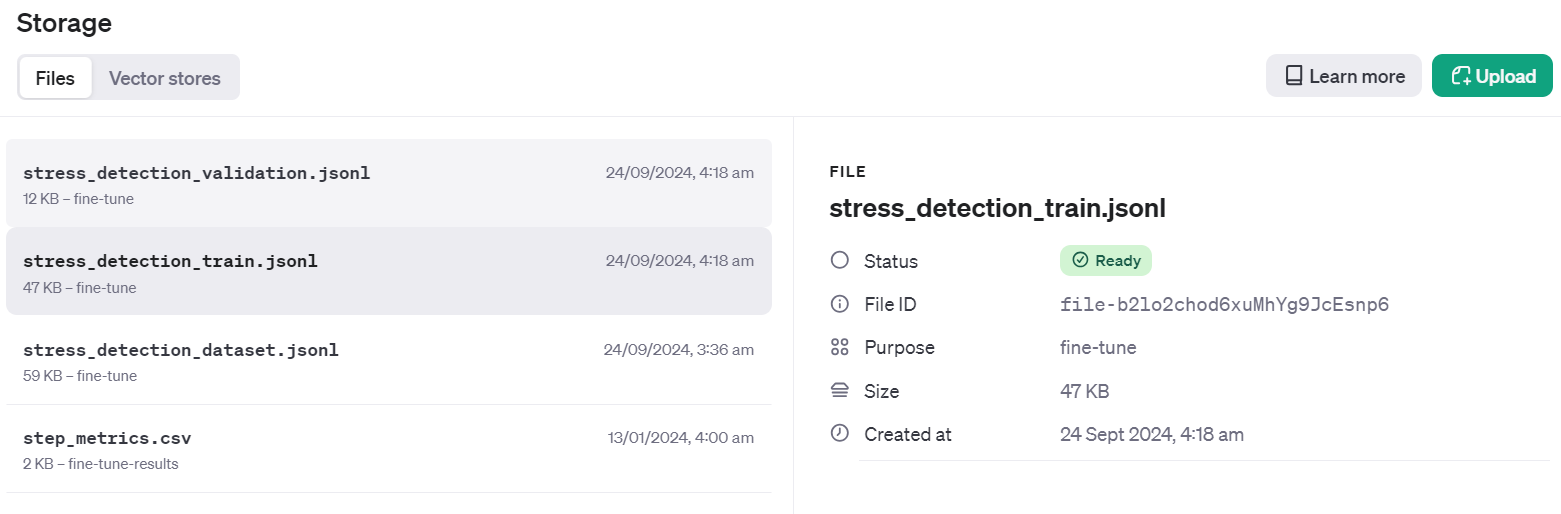
Validation file Info: FileObject(id='file-Fae0AVSUhTGr49qhQz8d2yyp', bytes=12284, created_at=1727133514, filename='stress_detection_validation.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)Pour vérifier si le jeu de données a été poussé avec succès vers le cloud, accédez au tableau de bord et cliquez sur l'onglet "Stockage". Deux fichiers seront présents et prêts à être utilisés.
Créez la tâche de réglage fin à l'aide de l'API client. La fonction de réglage fin requiert l'ID du fichier de l'ensemble de données d'apprentissage, l'ID du fichier de l'ensemble de données de validation, le nom du modèle et les hyperparamètres. Nous affinerons notre modèle pendant trois époques. Pour améliorer les performances du modèle, vous pouvez toujours vous entraîner sur l'ensemble des données avec au moins 5 époques.
model = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=valid_file.id,
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = model.id
status = model.status
print(f'Fine-tuning model with jobID: {job_id}.')
print(f"Training Response: {model}")
print(f"Training Status: {status}")Une fois la fonction exécutée, le travail de réglage fin démarre et affiche les journaux.
Fine-tuning model with jobID: ftjob-rgIMFxZSsWDqCNfOev54e4Jq.
Training Response: FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='validating_files', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=None, integrations=[], user_provided_suffix=None)
Training Status: validating_filesNous pouvons voir le statut du travail de mise au point sur le tableau de bord en cliquant sur l'onglet "Mise au point" et en cliquant sur l'ID du travail.
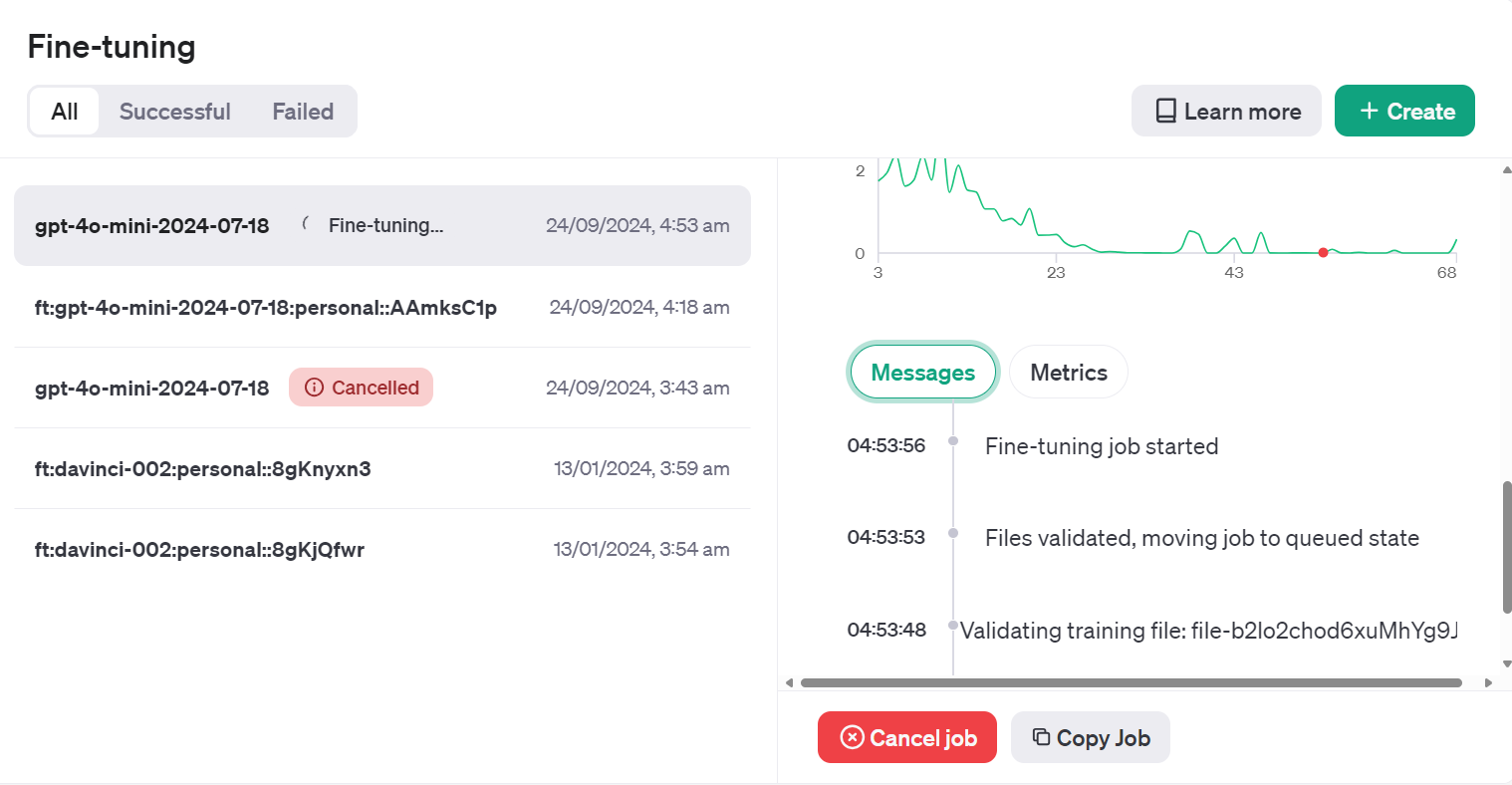
Vous pouvez également vérifier l'état de la tâche de réglage fin à l'aide de la fonction jobs.retrieve.
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve(job_id)Sortie :
FineTuningJob(id='ftjob-rgIMFxZSsWDqCNfOev54e4Jq', created_at=1727135628, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model='gpt-4o-mini-2024-07-18', object='fine_tuning.job', organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=748607710, status='running', trained_tokens=None, training_file='file-b2lo2chod6xuMhYg9JcEsnp6', validation_file='file-Fae0AVSUhTGr49qhQz8d2yyp', estimated_finish=1727135943, integrations=[], user_provided_suffix=None)Si vous pensez que la perte ne diminue pas, vous pouvez toujours annuler le travail à l'aide de la fonction jobs.cancel.
# Cancel a job
client.fine_tuning.jobs.cancel(job_id)Lorsque le travail de mise au point est terminé, vous recevez un courrier électronique vous indiquant que le modèle mis au point est prêt à être utilisé.
Pour accéder au modèle affiné, nous devons obtenir le nom du modèle affiné. Pour ce faire, nous recueillerons des informations sur tous les travaux de mise au point, nous sélectionnerons le dernier en date, puis nous choisirons le nom du modèle.
result = client.fine_tuning.jobs.list()
# Retrieve the fine tuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)Il s'agit de notre nom de modèle affiné.
ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5qGénérez un repos en fournissant à la fonction d'achèvement du chat un nom de modèle affiné, des messages avec une invite système correcte et un échantillon de l'ensemble de données....
completion = client.chat.completions.create(
model = fine_tuned_model,
messages=[
{"role": "system", "content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'."},
{"role": "user", "content": "Just went to my first homecoming, and they played a song I've always wanted to dance to at an official dance. Sorry for the terrible quality, but my happiness in this moment couldn't be exaggerated!"}
]
)
print(completion.choices[0].message.content)Succès ! J'ai correctement prédit l'étiquette.
"non-stress"Si vous n'êtes pas satisfait de votre modèle, vous pouvez toujours le supprimer à l'aide de la commande suivante. Nous ne le ferons pas, car nous devons d'abord procéder à des évaluations supplémentaires du modèle.
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete(fine_tuned_model)Il existe un autre moyen d'accéder au modèle affiné et de le tester plus efficacement sur différentes invites.
Allez sur le tableau de bord d'OpenAI, cliquez sur l'onglet "Fine-tuning", sélectionnez le travail récemment exécuté, puis cliquez sur le bouton "Playground" situé en bas à droite.
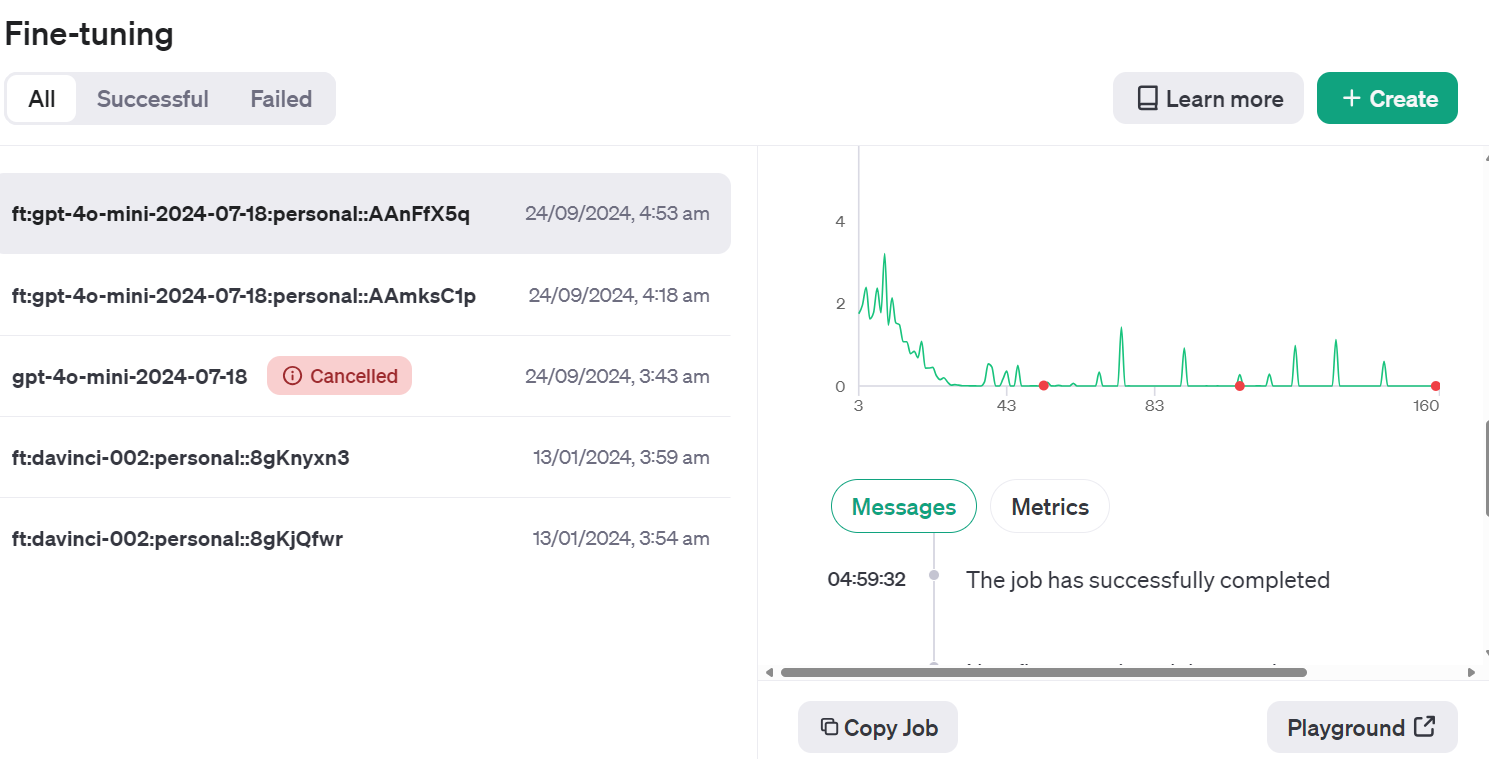
Vous accéderez à l'application de chatbot. Vous pouvez alors fournir une invite système et commencer à taper l'exemple de message Reddit.
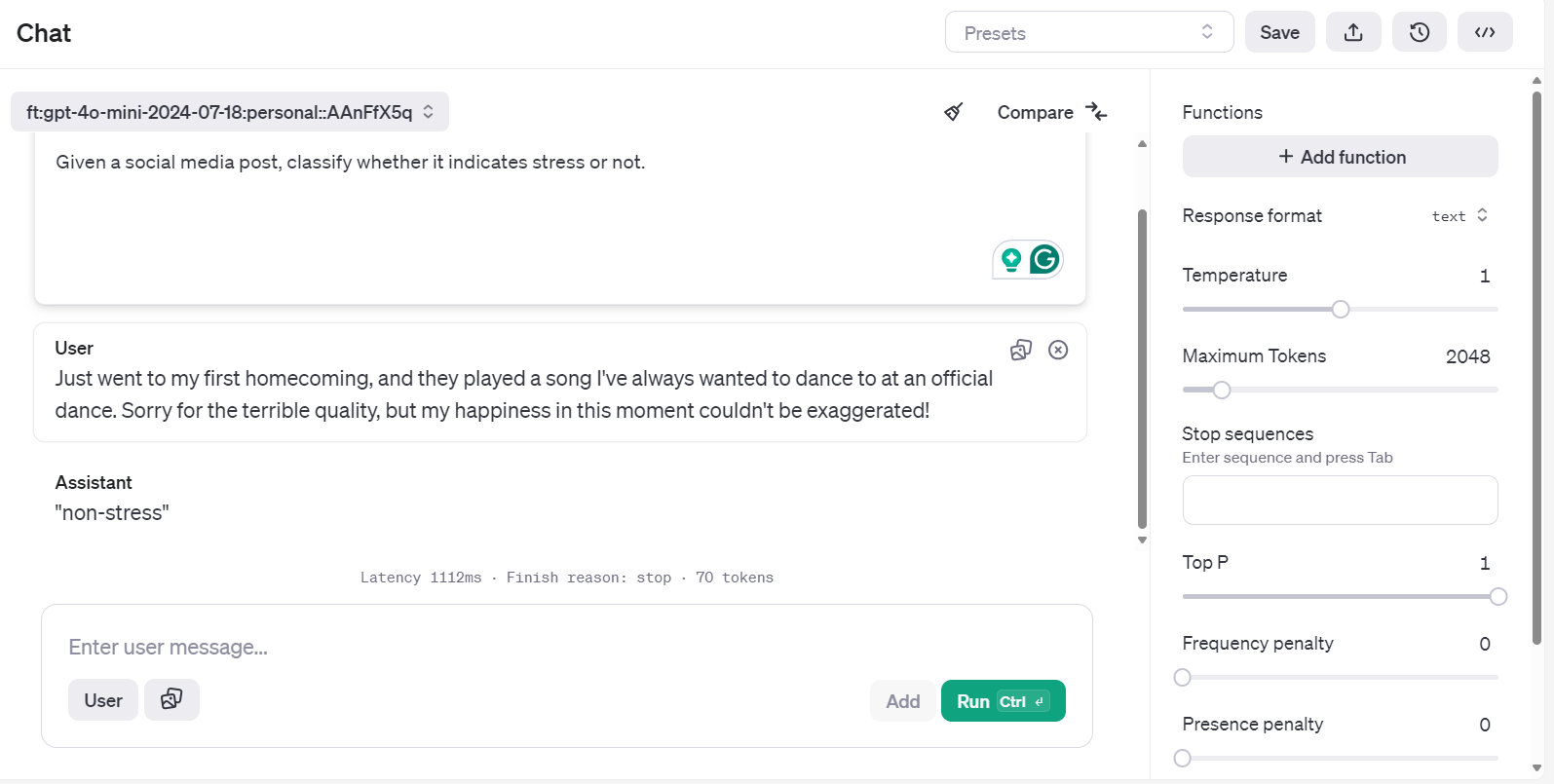
Vous pouvez même exécuter la même invite et la comparer avec un autre modèle pour une meilleure analyse.
Nous avons affiné le modèle et pensons qu'il est suffisamment bon. Mais vous êtes-vous demandé si ce n'était pas déjà mieux dès le départ ? Nous n'avons pas effectué de comparaison détaillée avant et après.
Dans cette section, nous utiliserons des données de validation pour prédire les étiquettes à l'aide du modèle de base, puis nous le comparerons à un modèle affiné. Nous comparerons les deux modèles sur la base de la précision, du rapport de classification et des mesures de confusion.
Créez une fonction predict qui entre le jeu de données et le nom du modèle pour générer une liste d'étiquettes prédites. Il utilise les mêmes messages du système et les mêmes titres de messages de l'ensemble de données.
def predict(test, model):
y_pred = []
categories = ["non-stress", "stress"]
for index, row in test.iterrows():
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Given a social media post, classify whether it indicates 'stress' or 'non-stress'.",
},
{"role": "user", "content": row["title"]},
],
)
answer = response.choices[0].message.content
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_predEnsuite, nous créerons la fonction evaluate, qui utilisera les étiquettes prédites et réelles pour générer un score de précision, un rapport de classification et des mesures de confusion.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
def evaluate(y_true, y_pred):
labels = ["non-stress", "stress"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(
x, -1
) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f"Accuracy: {accuracy:.3f}")
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [
i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label
]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f"Accuracy for label {labels[label]}: {label_accuracy:.3f}")
# Generate classification report
class_report = classification_report(
y_true=y_true_mapped,
y_pred=y_pred_mapped,
target_names=labels,
labels=list(range(len(labels))),
)
print("\nClassification Report:")
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(
y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels)))
)
print("\nConfusion Matrix:")
print(conf_matrix)
Fournissez à la fonction predict l'ensemble de données de validation et le nom du modèle de base. Fournissez ensuite les étiquettes prédites et réelles à la fonction evaluate et générez un rapport d'évaluation du modèle.
y_pred = predict(validation_data, "gpt-4o-mini-2024-07-18")
y_true = validation_data["label"]
evaluate(y_true, y_pred)Notre modèle de base est assez performant pour classer le texte. Nous avons obtenu une précision de 92,5 %.
Accuracy: 0.925
Accuracy for label non-stress: 0.947
Accuracy for label stress: 0.905
Classification Report:
precision recall f1-score support
non-stress 0.90 0.95 0.92 19
stress 0.95 0.90 0.93 21
accuracy 0.93 40
macro avg 0.93 0.93 0.92 40
weighted avg 0.93 0.93 0.93 40
Confusion Matrix:
[[18 1]
[ 2 19]]Utilisons la fonction predict avec le nom du modèle affiné pour générer des étiquettes de contrainte. Ensuite, nous pouvons utiliser les étiquettes prédites et les étiquettes réelles pour générer le rapport détaillé de l'équation du modèle.
fine_tuned_model = "ft:gpt-4o-mini-2024-07-18:personal::AAnFfX5q"
y_pred = predict(validation_data,fine_tuned_model)
evaluate(y_true, y_pred)La performance de notre modèle s'est améliorée. Nous avons obtenu une précision de 97,5 %, ce qui représente une amélioration significative.
Accuracy: 0.975
Accuracy for label non-stress: 1.000
Accuracy for label stress: 0.952
Classification Report:
precision recall f1-score support
non-stress 0.95 1.00 0.97 19
stress 1.00 0.95 0.98 21
accuracy 0.97 40
macro avg 0.97 0.98 0.97 40
weighted avg 0.98 0.97 0.98 40
Confusion Matrix:
[[19 0]
[ 1 20]]La précision de certaines tâches peut être améliorée de manière significative. Il ne s'agissait que d'un exemple de test, mais dans les projets réels, le réglage fin améliore la précision et les performances du modèle pour les tâches de classification, le stylisme et les résultats structurés.
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer à l'espace de travail DataLab : Mise au point du GPT-4 Mini.
L'étape suivante consiste à utiliser ce modèle affiné pour créer une application d'IA appropriée. Vous pouvez l'apprendre en suivant le code : Créer des assistants IA avec GPT-4o.
Dans ce tutoriel, nous avons réussi à affiner le mini-modèle GPT-4o pour classer un texte en deux catégories : "stress" et "non-stress". Nous avons ensuite accédé à ce modèle affiné en utilisant l'API OpenAI et le terrain de jeu OpenAI, ce qui a permis une application pratique et des tests supplémentaires.
L'évaluation du modèle affiné a fourni des résultats intéressants, démontrant une amélioration de la performance de la classification à travers diverses mesures par rapport au modèle de base. Ce processus a mis en évidence la valeur du réglage fin pour obtenir un résultat plus fiable et plus précis, en particulier lorsqu'il s'agit de tâches telles que la classification de textes.
Si vous souhaitez utiliser un modèle libre et gratuit, nous avons un excellent tutoriel intitulé Fine-tuning Llama 3.2 and Using It Locally : Un guide étape par étape. Dans ce guide, nous vous montrerons comment peaufiner le dernier modèle de lama et le convertir au format GGUF pour une utilisation locale sur votre ordinateur portable.
Les meilleurs cours de DataCamp OpenAI
Cours
Cours
Cours