
Cursus
Principes fondamentaux de l'IA
10 h
Après le lancement de la première version de LLaMA par Meta, une nouvelle course à l'armement s'est engagée pour construire de meilleurs grands modèles linguistiques (LLM) capables de rivaliser avec des modèles tels que GPT-3.5 (ChatGPT). La communauté des logiciels libres a rapidement publié des modèles de plus en plus puissants. Les passionnés d'IA ont eu l'impression de fêter Noël, avec l'annonce fréquente de nouveaux développements.
Toutefois, ces progrès ont eu des inconvénients. La plupart des modèles à code source ouvert sont soumis à une licence restreinte, ce qui signifie qu'ils ne peuvent être utilisés qu'à des fins de recherche. Deuxièmement, seules les grandes entreprises ou les instituts de recherche disposant d'un budget important pouvaient se permettre d'affiner ou de former les modèles. Enfin, le déploiement et la maintenance de grands modèles à la pointe de la technologie étaient coûteux.
La nouvelle version des modèles LLaMA vise à répondre à ces questions. Il est doté d'une licence commerciale, ce qui le rend accessible à un plus grand nombre d'organisations. En outre, de nouvelles méthodologies permettent désormais un réglage fin sur les GPU grand public à mémoire limitée.
Cette démocratisation de l'IA est essentielle pour son adoption à grande échelle. En surmontant les barrières à l'entrée, même les petites entreprises peuvent construire des modèles personnalisés adaptés à leurs besoins et à leur budget.
Dans ce tutoriel, nous allons explorer Llama-2 et montrer comment l'affiner sur un nouvel ensemble de données à l'aide de Google Colab. En outre, nous aborderons de nouvelles méthodologies et des techniques de réglage fin qui peuvent contribuer à réduire l'utilisation de la mémoire et à accélérer le processus de formation.

Image générée par l'auteur à l'aide de DALL-E 3
Llama 2 est une collection de LLM open-source de deuxième génération de Meta qui est fournie avec une licence commerciale. Il est conçu pour traiter un large éventail de tâches de traitement du langage naturel, avec des modèles dont l'échelle varie de 7 à 70 milliards de paramètres. Pour en savoir plus sur les modèles LLaMA, lisez notre article, Introduction au LLaMA de Meta AI : Favoriser l'innovation en matière d'IA.
Llama-2-Chat, qui est optimisé pour le dialogue, a montré des performances similaires à celles de modèles fermés populaires tels que ChatGPT et PaLM. Nous pouvons même améliorer les performances du modèle en le peaufinant sur un ensemble de données conversationnelles de haute qualité.
Le réglage fin dans l'apprentissage automatique est le processus d'ajustement des poids et des paramètres d'un modèle pré-entraîné sur de nouvelles données afin d'améliorer ses performances dans une tâche spécifique. Il s'agit d'entraîner le modèle sur un nouvel ensemble de données spécifique à la tâche à accomplir, tout en mettant à jour les poids du modèle pour s'adapter aux nouvelles données. Pour en savoir plus sur le réglage fin, consultez notre guide sur le réglage fin de GPT 3.5.
Il est impossible d'affiner les LLM sur du matériel grand public en raison de l'inadéquation des VRAM et de l'informatique. Cependant, dans ce tutoriel, nous allons surmonter ces problèmes de mémoire et de calcul et entraîner notre modèle en utilisant une version gratuite de Google Colab Notebook.
Dans cette partie, nous allons découvrir toutes les étapes nécessaires pour affiner le modèle Llama 2 avec 7 milliards de paramètres sur un GPU T4. Vous avez la possibilité d'utiliser un GPU gratuit sur Google Colab ou Kaggle. Le code fonctionne sur les deux plateformes.
Le GPU Colab T4 dispose d'une VRAM limitée à 16 Go. C'est à peine suffisant pour stocker les poids du lama 2-7b, ce qui signifie qu'un réglage fin complet n'est pas possible et que nous devons utiliser des techniques de réglage fin efficaces en termes de paramètres, telles que LoRA ou QLoRA.
Nous utiliserons la technique QLoRA pour affiner le modèle en précision 4 bits et optimiser l'utilisation de la VRAM. Pour cela, nous utiliserons l'écosystème Hugging Face des bibliothèques LLM : transformers, accelerate, peft, trl, et bitsandbytes.
Nous commencerons par installer les bibliothèques nécessaires.
%%capture
%pip install accelerate peft bitsandbytes transformers trlEnsuite, nous chargerons les modules nécessaires à partir de ces bibliothèques.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainerVous pouvez accéder au modèle officiel du Llama-2 de la Meta à partir de Hugging Face, mais vous devez faire une demande et attendre quelques jours pour obtenir une confirmation. Au lieu d'attendre, nous utiliserons le lama-2-7b-chat-hf de NousResearch comme modèle de base. Il est identique à l'original mais facilement accessible.
Image tirée de Hugging Face
Nous allons affiner notre modèle de base en utilisant un ensemble de données plus petit appelé mlabonne/guanaco-llama2-1k et écrire le nom du modèle affiné.
# Model from Hugging Face hub
base_model = "NousResearch/Llama-2-7b-chat-hf"
# New instruction dataset
guanaco_dataset = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model
new_model = "llama-2-7b-chat-guanaco"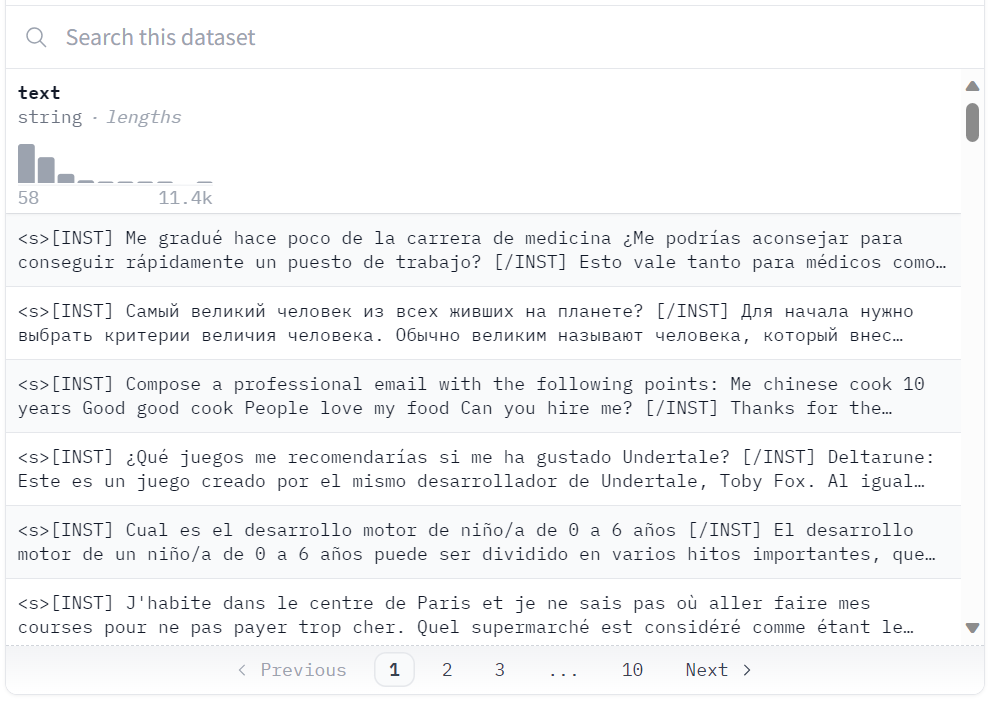
Ensemble de données à Hugging Face
Nous allons charger l'ensemble de données "guanaco-llama2-1k" à partir du hub Hugging Face. Le jeu de données contient 1000 échantillons et a été traité pour correspondre au format d'invite de Llama 2. Il s'agit d'un sous-ensemble de l'excellent jeu de données timdettmers/openassistant-guanaco.
dataset = load_dataset(guanaco_dataset, split="train")Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/mlabonne--guanaco-llama2-1k-f1f1134768f90029/0.0.0/0b6d5799bb726b24ad7fc7be720c170d8e497f575d02d47537de9a5bac074901. Subsequent calls will reuse this data.La quantification à 4 bits via QLoRA permet un réglage fin efficace d'énormes modèles LLM sur du matériel grand public tout en conservant des performances élevées. Cela améliore considérablement l'accessibilité et la facilité d'utilisation pour les applications du monde réel.
QLoRA quantifie un modèle linguistique pré-entraîné sur 4 bits et fige les paramètres. Un petit nombre de couches d'adaptateurs de faible rang pouvant être entraînées sont ensuite ajoutées au modèle.
Lors du réglage fin, les gradients sont rétropropagés à travers le modèle quantifié gelé de 4 bits dans les seules couches de l'adaptateur de bas rang. Ainsi, l'ensemble du modèle pré-entraîné reste fixé à 4 bits alors que seuls les adaptateurs sont mis à jour. De plus, la quantification sur 4 bits ne nuit pas à la performance du modèle.
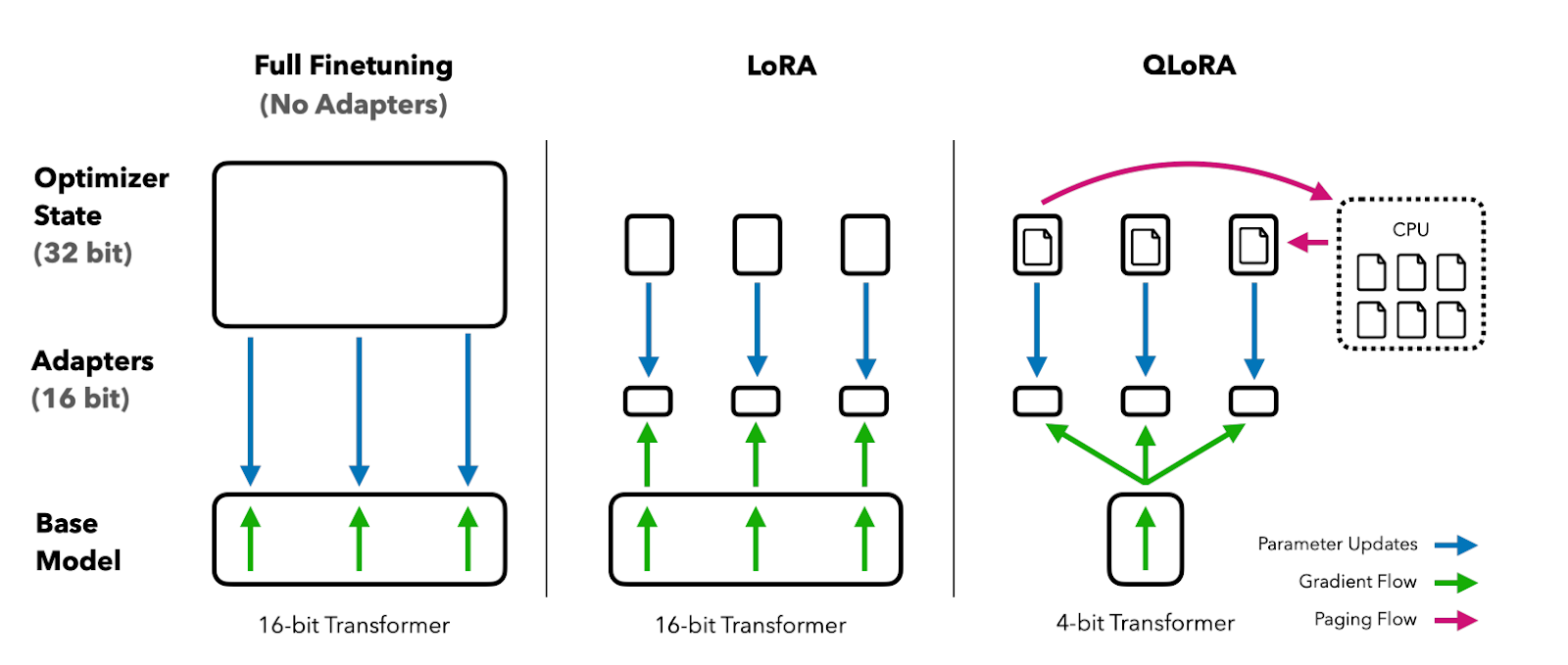
Image tirée du document QLoRA
Vous pouvez lire le document pour mieux comprendre.
Dans notre cas, nous créons une quantification sur 4 bits avec une configuration de type NF4 en utilisant BitsAndBytes.
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)Nous allons maintenant charger un modèle utilisant une précision de 4 bits avec le dtype de calcul "float16" de Hugging Face pour une formation plus rapide.
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1Ensuite, nous allons charger le tokenizer de Hugginface et mettre padding_side à "right" pour résoudre le problème avec fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Le réglage fin traditionnel des modèles linguistiques pré-entraînés (PLM) nécessite la mise à jour de tous les paramètres du modèle, ce qui est coûteux en termes de calcul et requiert des quantités massives de données.
Le Parameter-Efficient Fine-Tuning (PEFT) consiste à ne mettre à jour qu'un petit sous-ensemble des paramètres les plus influents du modèle, ce qui le rend beaucoup plus efficace. Pour en savoir plus sur les paramètres, consultez la documentation officielle de PEFT.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)Vous trouverez ci-dessous une liste d'hyperparamètres qui peuvent être utilisés pour optimiser le processus d'apprentissage :
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)Le réglage fin supervisé (SFT) est une étape clé de l'apprentissage par renforcement à partir du feedback humain (RLHF). La bibliothèque TRL de HuggingFace fournit une API facile à utiliser pour créer des modèles SFT et les entraîner sur votre ensemble de données avec seulement quelques lignes de code. Il est accompagné d'outils permettant d'entraîner des modèles linguistiques à l'aide de l'apprentissage par renforcement, en commençant par l'ajustement supervisé, puis la modélisation de la récompense et, enfin, l'optimisation de la politique proximale (PPO).
Nous fournirons à SFT Trainer le modèle, le jeu de données, la configuration de Lora, le tokenizer et les paramètres d'apprentissage.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)Nous utiliserons .train() pour affiner le modèle Llama 2 sur un nouvel ensemble de données. Il a fallu une heure et demie au modèle pour compléter une époque.

Après avoir formé le modèle, nous sauvegarderons l'adopteur de modèle et les tokenizers. Vous pouvez également télécharger le modèle sur Hugging Face à l'aide d'une API similaire.
trainer.model.save_pretrained(new_model)
trainer.tokenizer.save_pretrained(new_model)
Nous pouvons maintenant examiner les résultats de la formation dans la session interactive de Tensorboard.
from tensorboard import notebook
log_dir = "results/runs"
notebook.start("--logdir {} --port 4000".format(log_dir))
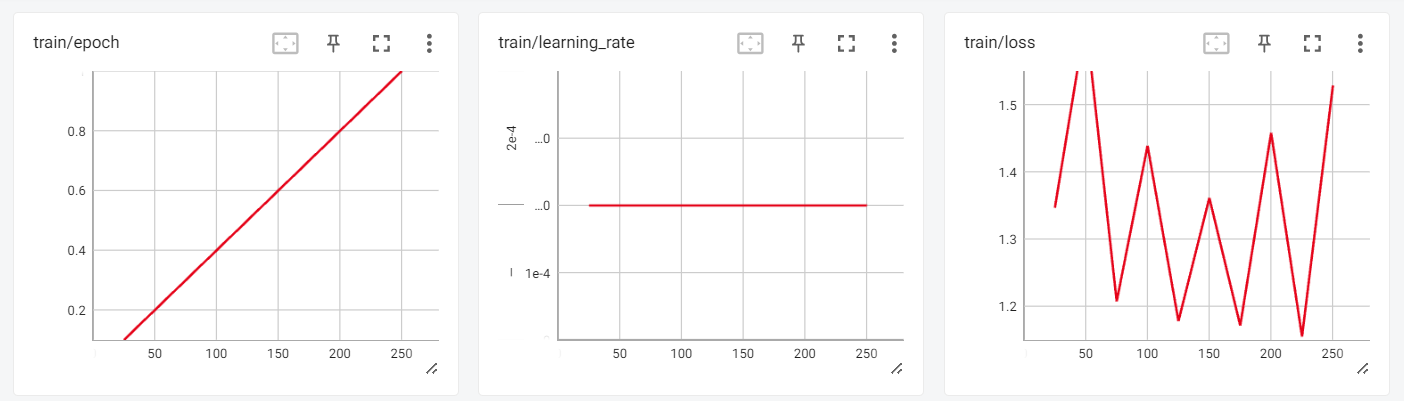
Pour tester notre modèle affiné, nous utiliserons le pipeline de génération de texte transformers et poserons des questions simples telles que "Qui est Leonardo Da Vinci ?".
logging.set_verbosity(logging.CRITICAL)
prompt = "Who is Leonardo Da Vinci?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Sortie :
Comme vous pouvez le constater, nous avons obtenu des résultats étonnants.
<s>[INST] Who is Leonardo Da Vinci? [/INST] Leonardo da Vinci (1452-1519) was an Italian polymath, artist, inventor, and engineer.
Da Vinci is widely considered one of the greatest painters of all time, and his works include the famous Mona Lisa. He was also an accomplished engineer, inventor, and anatomist, and his designs for machines and flight were centuries ahead of his time.
Da Vinci was born in the town of Vinci, Italy, and he was the illegitimate son of a local notary. Despite his humble origins, he was able to study art and engineering in Florence, and he became a renowned artist and inventor.
Da Vinci's work had a profound impact on the Renaissance, and his legacy continues to inspire artists, engineers, and inventors to this day. He
Posons une autre question.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Sortie :
Guanaco est un ensemble de données de haute qualité qui a été utilisé pour affiner les LLM de pointe dans le passé. L'ensemble des données de Guanaco est disponible sur Hugging Face et il a le potentiel d'atteindre des performances encore plus élevées sur une variété de tâches de langage naturel.
<s>[INST] What is Datacamp Career track? [/INST] DataCamp Career Track is a program that offers a comprehensive learning experience to help you build your skills and prepare for a career in data science.
The program includes a range of courses, projects, and assessments that are designed to help you build your skills in data science. You will learn how to work with data, create visualizations, and build predictive models.
In addition to the technical skills, you will also learn how to communicate your findings to stakeholders and how to work with a team to solve complex problems.
The program is designed to be flexible, so you can learn at your own pace and on your own schedule. You will also have access to a community of learners and mentors who can provide support and guidance throughout the program.
Overall, DataCamp Career Track is a great way to build your skills and prepare for a career inVoici le carnet de notes Colab avec le code et les résultats pour vous aider dans votre parcours de codage.
Ensuite, vous pouvez utiliser LlamaIndex et créer votre propre application d'IA en utilisant votre nouveau modèle d'entraînement en suivant le lien LlamaIndex : Ajout de données personnelles aux LLM tutorial. Vous pouvez vous inspirer pour votre projet en consultant 5 projets réalisés à l'aide de modèles génératifs et d'outils open source.
Le tutoriel a fourni un guide complet sur le réglage fin du modèle LLaMA 2 en utilisant des techniques telles que QLoRA, PEFT, et SFT pour surmonter les limitations de mémoire et de calcul. En tirant parti des bibliothèques Hugging Face telles que transformers, accelerate, peft, trl, et bitsandbytes, nous avons pu affiner avec succès le modèle LLaMA 2 à 7B paramètres sur un GPU grand public.
Dans l'ensemble, ce tutoriel a montré comment les progrès récents ont permis la démocratisation et l'accessibilité de grands modèles de langage, permettant même aux amateurs de construire une IA de pointe avec des ressources limitées.
Si vous êtes novice en matière de modèles linguistiques de grande taille, envisagez de suivre le cours Master LLMs Concepts. Et si vous voulez commencer votre carrière dans l'intelligence artificielle, alors vous devriez vous inscrire au cursus de compétences AI Fundamentals.
Commencez dès aujourd'hui votre voyage dans l'IA !
Cursus
Cours
Cours