

Lernpfad
Grundlagen der KI
10 Std.
Das Entwickeln mit KI-Modellen heißt meistens, dass man sich mit API-Schlüsseln rumschlagen, Dokumentationen lesen und Standardcode schreiben muss, bevor man überhaupt eine einzige Eingabe testen kann. Google AI Studio überspringt diese Einrichtung und bringt dich direkt in eine browserbasierte Spielumgebung, wo du mit Gemini-Modellen chatten, Medien erstellen und Anwendungsprototypen entwickeln kannst, ohne Code zu berühren.
Dieses Tutorial zeigt dir die wichtigsten Funktionen von Google AI Studio: Chat-Modus zum schnellen Testen, Stream-Modus für Sprach- und Videointeraktionen, Build-Modus zum Erstellen von Apps mit natürlicher Sprache und Tools zur Medienerstellung für Bilder, Videos und Audio.
Du lernst, welche Gemini-Modelle du für verschiedene Aufgaben verwenden kannst und wie du deine Prototypen in produktionsreifen Code umwandelst. Die neuesten Infos zu den KI-Ankündigungen von Google in diesem Jahr findest du in unserem Leitfaden zu Gemini 3 und Google Antigravity Tutorial. Du kannst auch lernen, wie man KI-Agenten mit Google ADK erstellt.
Google AI Studio ist 'ne kostenlose, browserbasierte Plattform zum Erstellen von Prototypen mit Gemini-KI-Modellen. Es gibt einen Chat-Modus zum Testen von Eingabeaufforderungen, einen Build-Modus zum Erstellen von React-Apps aus natürlicher Sprache und einen Stream-Modus für Sprach- und Videointeraktionen – und das alles ohne dass du Setup-Code schreiben musst.
Der Einstieg in Google AI Studio dauert weniger als eine Minute. Geh zu aistudio.google.com und logg dich mit einem beliebigen Google-Konto ein. Du musst nichts installieren, brauchst keine Kreditkarte und musst nicht warten. Die Plattform läuft komplett in deinem Browser.
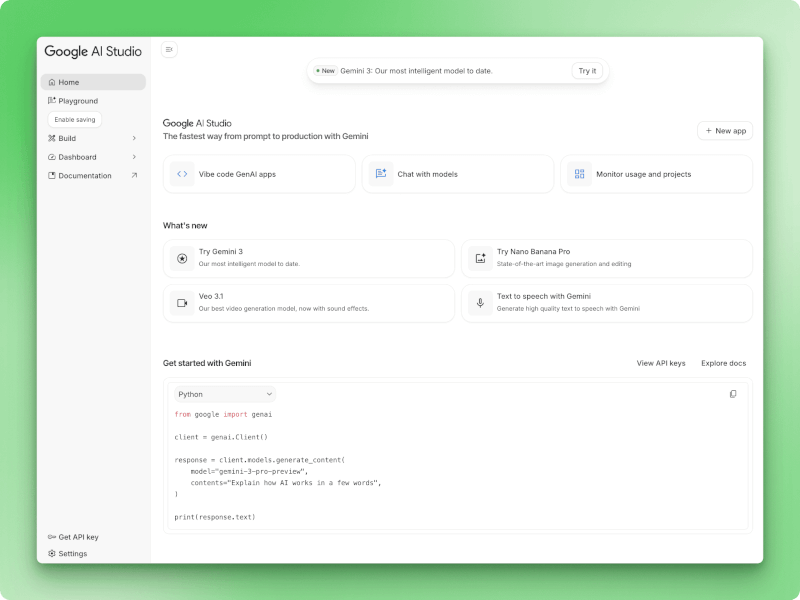
Die Benutzeroberfläche hat eine linke Seitenleiste für die Navigation mit fünf Hauptbereichen: Startseite, Spielplatz, Erstellen, Dashboard und Dokumentation. Auf der Startseite gibt's drei Aktionskarten, mit denen du schnell zu den üblichen Sachen wie Chatten mit Models oder Apps erstellen kommst. Unten in der Seitenleiste findest du Links zu „API-Schlüssel abrufen“ und „Einstellungen“ für die Verwaltung deines Kontos.
Google AI Studio Homepage
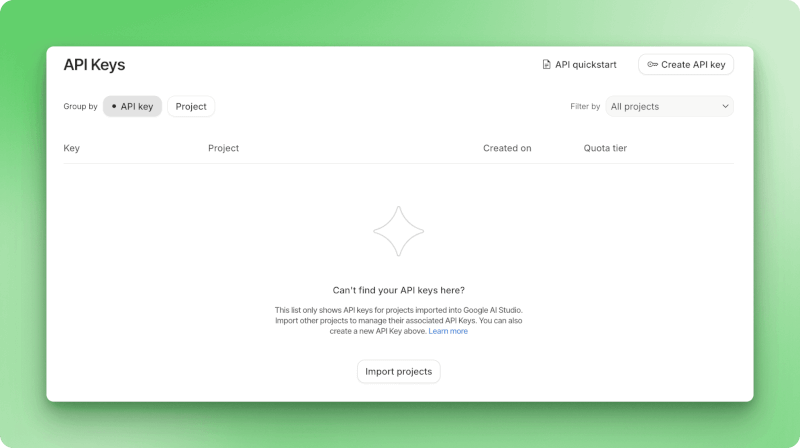
Um die Gemini-API in deinen eigenen Apps zu nutzen, klick einfach unten in der linken Seitenleiste auf „API-Schlüssel abrufen“. Das öffnet die Seite zur Verwaltung der API-Schlüssel, wo du mit dem Button „API-Schlüssel erstellen“ neue Schlüssel anlegen kannst.
Mit der kostenlosen Stufe kannst du sofort loslegen, mit Nutzungsbeschränkungen, die für Prototypen super sind (zwischen 5 und 15 Anfragen pro Minute, je nach Modell). Für höhere Limits und den Einsatz in der Produktion kannst du auf eine kostenpflichtige Stufe upgraden.
API-Schlüssel-Verwaltungsseite
Pass gut auf deinen API-Schlüssel auf und speichere ihn nicht in öffentlichen Repositorys.
Bevor du mit dem Experimentieren anfängst, solltest du wissen, welches Gemini-Modell für deine Aufgabe am besten passt. Mit AI Studio kannst du aus mehreren Optionen wählen, die alle ihre eigenen Vorteile haben.
Im AI Studio gibt's mehrere Gemini-Modelle, die alle für unterschiedliche Aufgaben entwickelt wurden. Deine Entscheidung hängt davon ab, ob du auf Denkvermögen, Geschwindigkeit, Kosten oder spezielle Funktionen wie die Bilderzeugung optimierst.
Das Modell „ gemini-3-pro “ kann komplexe Denkaufgaben lösen, bei denen man eine gründliche Analyse braucht. Es hat 1501 Punkte auf der Elo-Rangliste geknackt und ist damit das beste Modell für mehrstufiges Denken.
Mit einem Kontextfenster von 1 Million Token kannst du ganze Codebasen oder Forschungsarbeiten einspeisen und bekommst bis zu 65.000 Token zurück.
Das Modell hat einen Parameter namens „ thinking_level “ , mit dem du die Tiefe der Schlussfolgerungen je nach Aufgabe erhöhen oder verringern kannst. Wenn du dich genauer mit den Funktionen und Benchmarks von Gemini 3 beschäftigen willst, schau dirden Gemini 3-Leitfaden von DataCamp unter an.
Für die Bilderzeugung kann „ gemini-3-pro-image “ (Spitzname „Nano Banana Pro“) 2K- und 4K-Bilder mit lesbarem Text erstellen. Die meisten Bildmodelle können mit der Textdarstellung nicht richtig umgehen, aber dieses hier macht das gut. Du bekommst 65.000 Eingabetoken und 32.000 Ausgabetoken, mit denen du arbeiten kannst.
Eine Sache, die du bei „ “ beachten solltest: Die Google Maps-Funktion ist bei den Gemini 3-Modellen nicht verfügbar. Wenn du Standortfunktionen brauchst, solltest du lieber Gemini 2.5 Pro nehmen.
Das Modell „ gemini-2.5-pro “ geht nach dem Motto „Erst denken, dann handeln“ vor und nimmt sich mehr Zeit für komplexe Analysen, bevor es reagiert. Es passt zum 1-Meter-Kontext und zur 65K-Ausgabekapazität von Gemini 3 Pro und ist das einzige Modell, das Google Maps Grounding unterstützt.
Die Flash-Varianten tauschen ein bisschen Argumentationstiefe gegen Geschwindigkeit und Kosten ein:
· gemini-2.5-flash: Schnellere Antworten als bei den Pro-Modellen, aber mit dem 1-Meter-Kontextfenster. Gute Standardeinstellung für allgemeine Aufgaben
· gemini-2.5-flash-lite: Entwickelt für große Datenmengen, wo du einfache Abfragen in großem Maßstab durchführst.
Fang mit gemini-3-pro , wenn du dich mit Programmierproblemen, mathematischer Analyse oder irgendwas anderem beschäftigst, das schrittweises Denken erfordert.
Wechsel zu gemini-2.5-pro , wenn du eine Bodenhaftung brauchst oder einen auf das Denken fokussierten Ansatz willst.
Für die meisten alltäglichen Aufgaben gemini-2.5-flash bietet dir zuverlässige Leistung ohne große Kosten.
Benutze gemini-2.5-flash-lite , wenn du viele einfachere Anfragen bearbeitest.
Und greif zu gemini-3-pro-image , wenn du Bilder mit Text brauchst, die man auch lesen kann.
Die kostenlosen Nutzungsbeschränkungen liegen zwischen 5 und 15 Anfragen pro Minute, je nachdem, welches Modell du wählst.
Jetzt, wo du weißt, welches Modell du verwenden solltest, schauen wir uns mal an, wie du mit ihnen im Chat-Modus interagieren kannst. Dort kannst du Eingabeaufforderungen testen und deinen Ansatz verfeinern, bevor du Code schreibst.
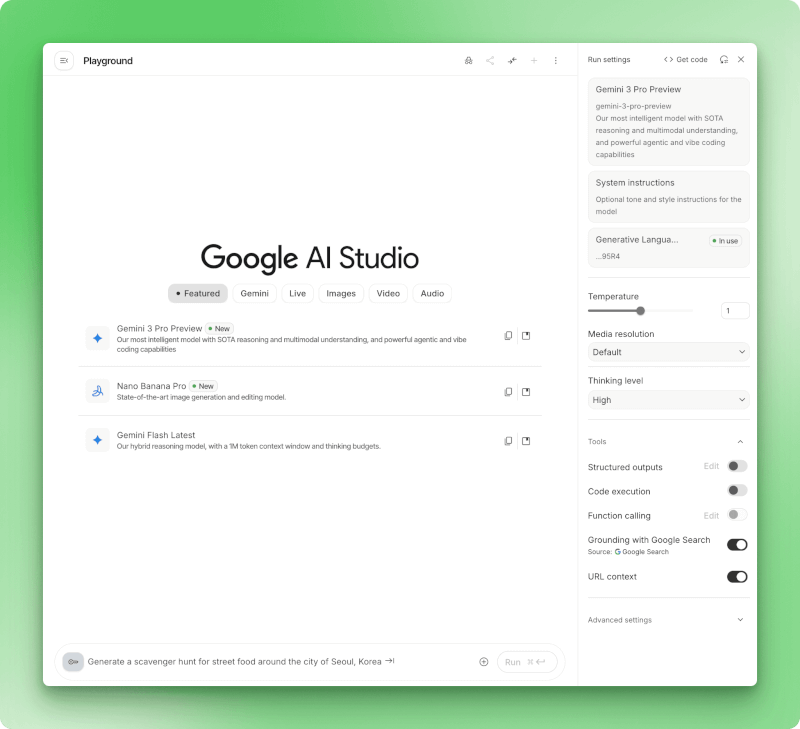
Mit dem Playground kannst du Eingabeaufforderungen mit visuellen Steuerelementen für jede Einstellung testen. Du kannst Parameter anpassen, Tools ein- und ausschalten und die ganze Konfiguration als funktionierenden Code exportieren, wenn du was gefunden hast, das funktioniert.
Die Google AI Studio Playground-Oberfläche zeigt Systemanweisungen, Modellparameter wie Temperatur und Denkvermögen sowie Tools wie Codeausführung und Google-Suche.
Die Systemanweisungen bestimmen, wie sich das Modell während der ganzen Unterhaltung verhält, sodass du nicht bei jeder Eingabe den gleichen Kontext wiederholen musst. Die Temperatur bestimmt, wie zufällig die Antworten sind: Niedrigere Werte um 0,3 sorgen für eine einheitliche Formatierung, während höhere Werte um 1,5 besser für kreatives Schreiben geeignet sind. Mit dem Dropdown-Menü „Denkstufe“ bei den Gemini 3-Modellen kannst du die Tiefe der Argumentation gegen Geschwindigkeit eintauschen.
Wähle das Modell „Nano Banana Pro” aus dem oberen Dropdown-Menü aus, wenn du Bilder statt Text erstellen willst. Es gelten die gleichen Parametersteuerungen, aber du bekommst 2K- oder 4K-Bilder mit lesbarer Textdarstellung.
Der Chat-Modus kann nicht nur Bilder, sondern auch andere Medien. Veo 3 macht Videos mit echtem Ton und Lippensynchronisation. Für Audio kannst du Text-to-Speech oder Lyria 2 zum Erzeugen von Musik nutzen. Lyria RealTime macht interaktive Musikproduktion möglich, bei der das Modell in Echtzeit auf deine Eingaben reagiert.
Tools wie „Grounding with Google Search“ holen aktuelle Infos rein, wenn die Trainingsdaten des Modells nicht ausreichen.
Die Codeausführung nutzt Python direkt für Berechnungen oder Datenverarbeitung. Die anderen Schalter verbinden sich mit deinen eigenen APIs, setzen JSON-Schemas durch oder fügen URLs in die Unterhaltung ein.
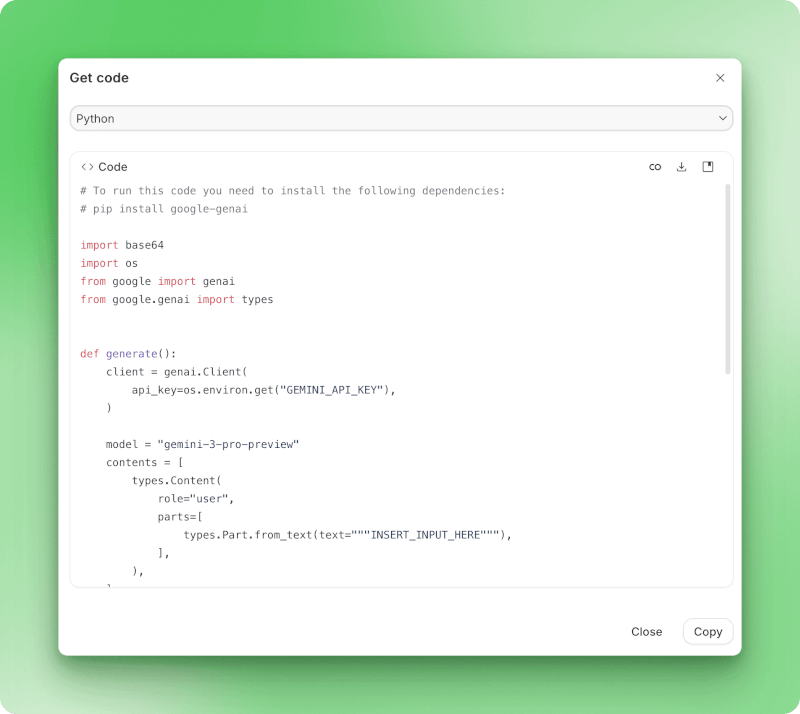
Dialogfeld „Code abrufen“ in Google AI Studio, das den Export von Python-Code mit Gemini-API-Implementierung anzeigt
Wenn du bereit bist, von der Testphase zur Produktion überzugehen, exportiert „Code abrufen“ alles als Implementierungscode.
Der Stream-Modus geht noch einen Schritt weiter und fügt Sprach- und Videointeraktionen hinzu.
Der Stream-Modus verwandelt Text-Eingaben in Gespräche, bei denen Gemini dich sehen und hören kann. Du redest über dein Mikrofon mit dem Modell, zeigst deinen Bildschirm und bekommst in Echtzeit gesprochene Antworten, ohne was tippen zu müssen.
Um den Stream-Modus zu starten, geh einfach auf https://aistudio.google.com/live.
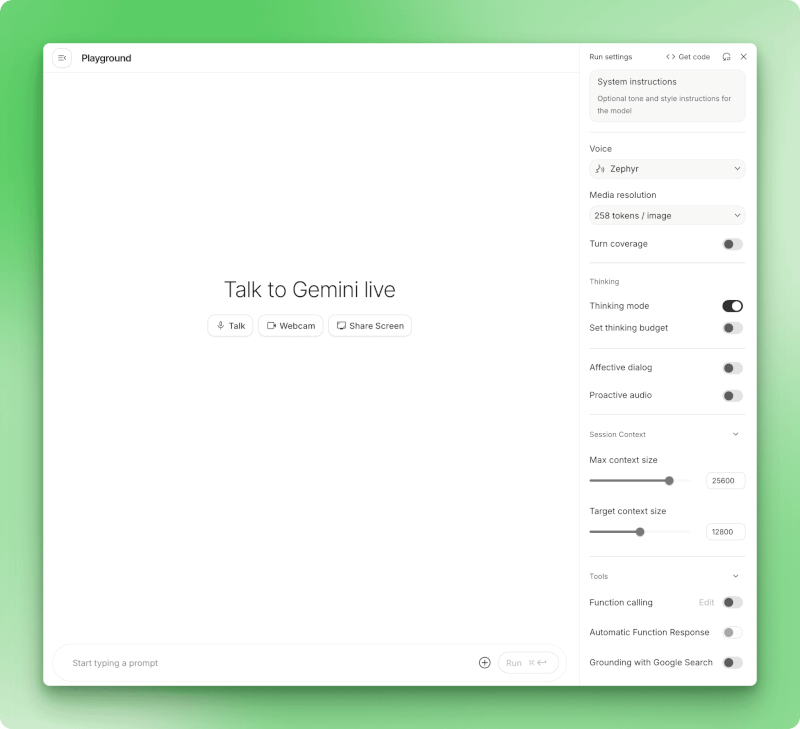
Die Benutzeroberfläche von Google AI Studio im Stream-Modus mit den Schaltflächen „Talk“, „Webcam“ und „Bildschirm teilen“ sowie den Spracheinstellungen und Konfigurationsoptionen in der Seitenleiste.
Die Benutzeroberfläche bietet dir drei Optionen: Sprich einfach, um nur mit deiner Stimme zu chatten, schalte deine Webcam ein, um dich zu zeigen, oder teile deinen Bildschirm, um zu zeigen, was du gerade auf deinem Display hast.
Die Spracherkennung läuft automatisch ab. Gemini wartet, bis du eine Pause machst, bevor es antwortet, damit du deine Erklärung durchdenken kannst, ohne zwischen den Spielzügen irgendwas anzuklicken. Das Modell verarbeitet deine Stimme, jedes Video von deiner Webcam und alles, was du gerade zeigst, gleichzeitig.
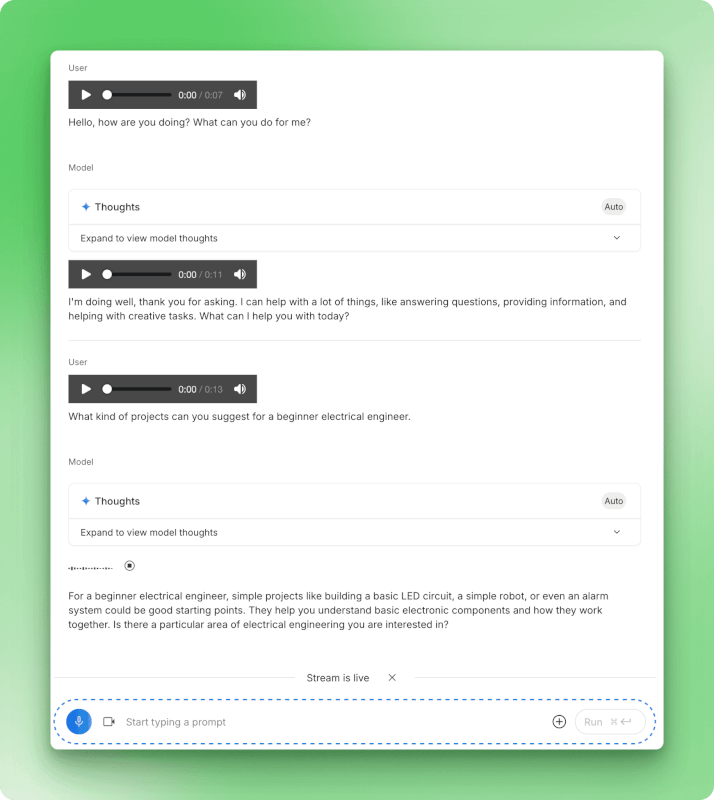
Du kannst sogar verschiedene Stimmen für die Antworten des Modells auswählen, wie zum Beispiel die Stimme „Zephyr“, die in den Einstellungen angezeigt wird. Die internen Überlegungen des Modells werden in ausklappbaren Abschnitten „Gedanken“ angezeigt, sodass du sehen kannst, wie es zu den einzelnen Antworten gekommen ist.
Stream-Modus-Konversation, die die Sprachinteraktion mit Audio-Wellenformen, Modellgedanken und Echtzeit-Antworten zwischen dem Nutzer und Gemini zeigt.
Die Freisprechfunktion ist super für Live-Nachhilfestunden, wo du deine Arbeit zeigen und direkt mündliche Tipps bekommen musst.
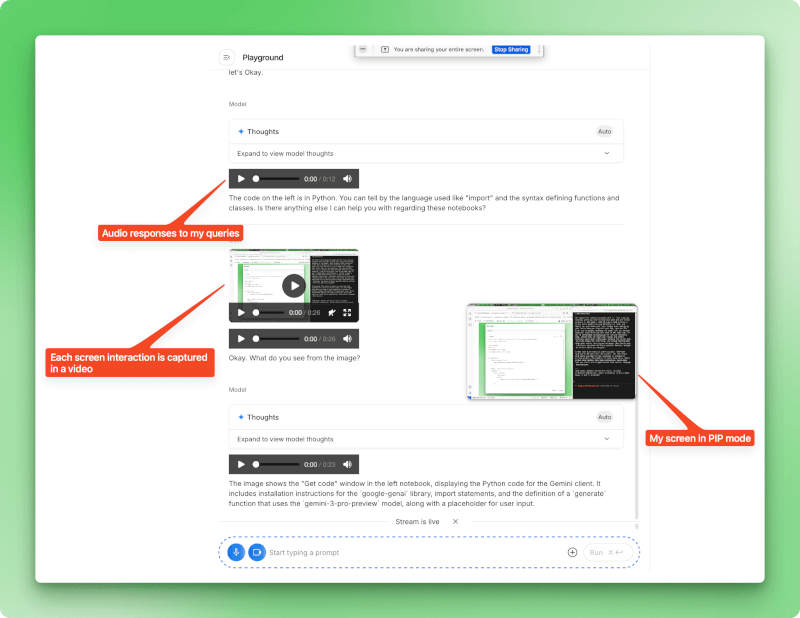
Du kannst eine Matheaufgabe durchgehen und dabei laut deine Überlegungen erklären, und Gemini kann erkennen, wo deine Logik nicht mehr ganz passt. Das Debuggen geht schneller, wenn du deine IDE zeigen und den Fehler beschreiben kannst, den du siehst. Dein Bildschirm wird im Bild-in-Bild-Modus angezeigt, sodass Gemini genau sehen kann, worauf du dich beziehst.
Stream-Modus mit aktiver Bildschirmfreigabe, der eine Bild-in-Bild-Ansicht des freigegebenen Bildschirms und Audioantworten anzeigt, während Gemini den angezeigten Inhalt analysiert.
Wenn du eine Präsentation übst oder eine Demo durchspielst, kann der Stream-Modus deine Folien anschauen und Fragen zum Inhalt beantworten. Das hilft auch, wenn du dich in eine neue Software einarbeitest. Du kannst Gemini deine Benutzeroberfläche zeigen, fragen, wo du eine bestimmte Funktion findest, und dir während der Navigation Anweisungen geben lassen.
Der Stream-Modus passt super für Situationen, in denen du in Echtzeit mit Sprache und Bildern hin und her wechseln willst. Für Aufgaben mit viel Text, bei denen du Antworten kopieren oder schriftliche Eingaben wiederholen musst, ist der Chat-Modus immer noch besser geeignet. Während der Stream-Modus für Echtzeit-Interaktionen zuständig ist, kannst du im Build-Modus ganze Anwendungen aus Beschreibungen in natürlicher Sprache erstellen.
Der Build-Modus verwandelt Beschreibungen in funktionierende React-Apps. Du gibst ein, was du willst, und das Modell schreibt den Code. Google nennt das „Vibe Coding“, aber es geht einfach darum, in weniger als einer Minute von der Idee zum Prototyp zu kommen.
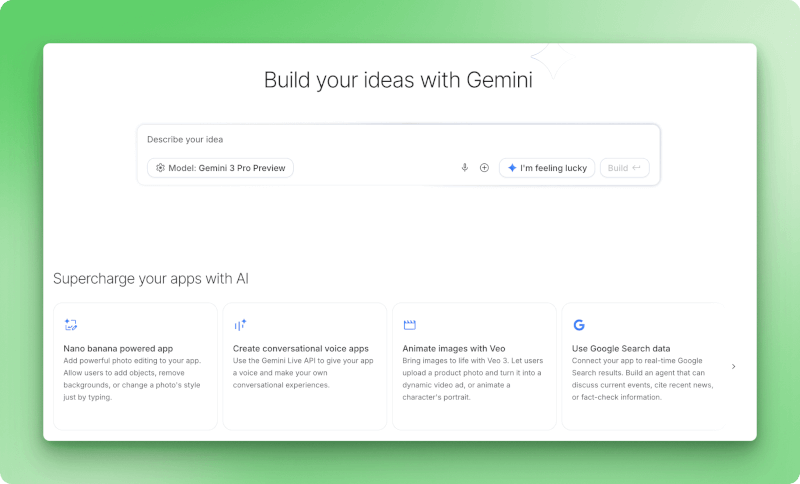
Landingpage im Build-Modus mit Eingabefeld für die Gemini 3 Pro Preview-Modellauswahl, „Ich bin glücklich”-Button und Bereich „AI Chips” mit Optionen für Nano Banana-basierte Apps, Sprachassistenten, Veo-Videoanimationen und Google-Suchdatenintegration.
Ich hab mir zuerst die Starter-Galerie angeschaut. Apps wie Shader Pilot zeigen, was alles möglich ist – interaktive 3D-Visualisierungen, Landingpages mit individueller Typografie, sogar kleine Spiele. Du kannst jedes Beispiel kopieren und den Code über das Assistentenfenster ändern.
Starter-Apps-Galerie mit Beispielen für Gemini 3 Pro, darunter 3D-Spiele, multimodale Apps und ein toller Bereich mit Landingpages mit AlphaQubit-Forschungsvisualisierungen, der Veranstaltungsseite für das Lumina Festival und einer E-Commerce-Demo von Aura Quiet Living.
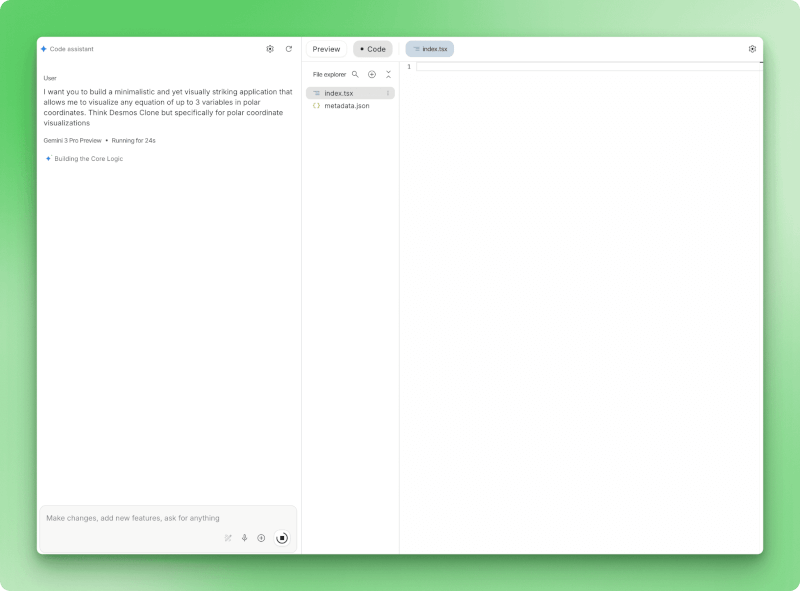
Ich wollte ganz von vorne anfangen, also hab ich eingegeben: „Eine minimalistische und trotzdem optisch ansprechende Anwendung, mit der ich jede Gleichung mit bis zu drei Variablen in Polarkoordinaten visualisieren kann.“
Polar.ai wird gerade erstellt und zeigt eine Benutzeraufforderung für den Visualisierer für Polarkoordinatengleichungen an, die Statusanzeige von Gemini 3 Pro Preview zeigt „Running for 24s“ (Läuft seit 24 Sekunden) mit der Fortschrittsmeldung „Building the Core Logic“ (Erstellt die Kernlogik) an, und das Datei-Explorer-Fenster zeigt die erstellten Dateien „index.tsx“ und „metadata.json“ an.
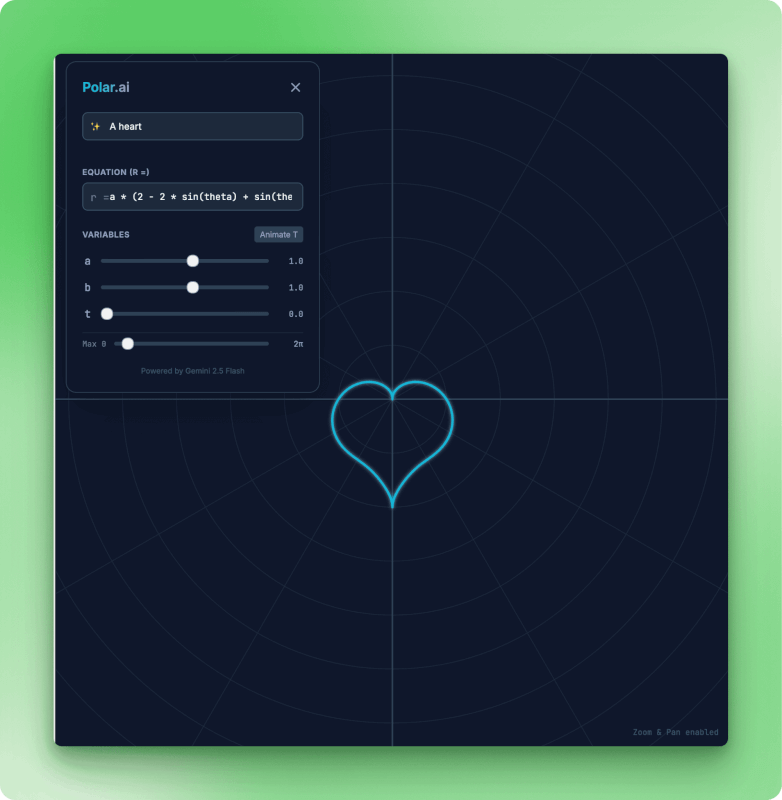
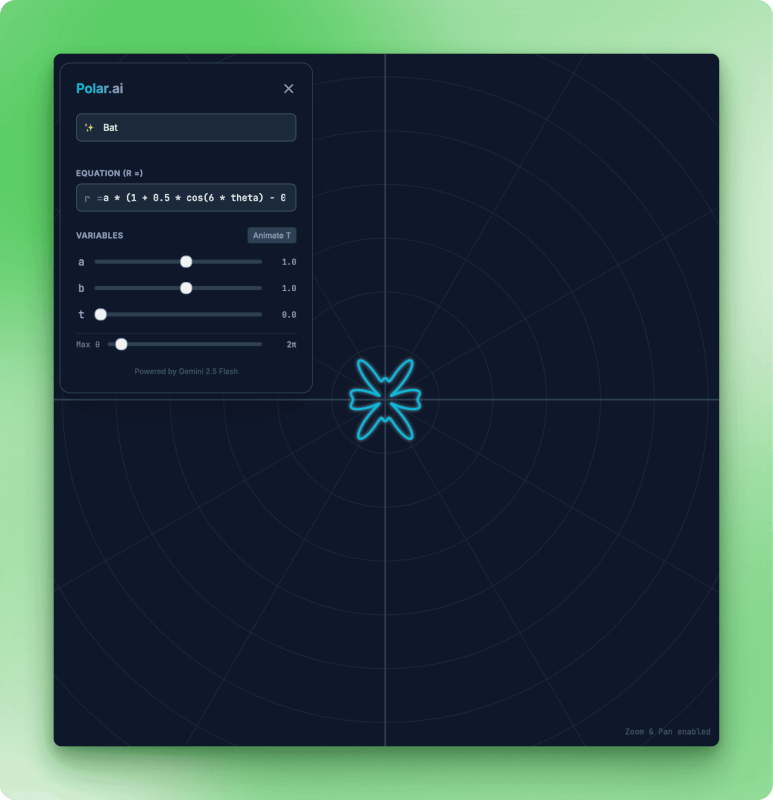
Ungefähr 60 Sekunden später tauchte Polar.ai auf. Das Modell hat React-Dateien erstellt (index.tsx, metadata.json), einen Gleichungsparser gebaut und variable Schieberegler eingerichtet. Ich hab „ein Herz“ getippt und zugesehen, wie es die Polarkurve gezeichnet hat. Durch Umschalten auf „Fledermaus“ entstand eine andere Form.
Die Polar.ai-App zeigt eine herzförmige Polarkurve in Cyan auf einem dunklen Gitterhintergrund, mit einem Gleichungseditor, der die Formel r gleich a mal Sinus anzeigt, variablen Schiebereglern für a, b, t auf 1,0, Max-Theta bei 2 Pi, einer T-Taste zum Animieren und dem Hinweis „Powered by Gemini 2.5 Flash Credit”.
Die Polar.ai-App zeigt eine Fledermaus-förmige Polarisierungsvisualisierung mit einem sechsflügeligen symmetrischen Muster in Cyan. Der Gleichungseditor zeigt eine modifizierte Kosinusformel mit variablen Steuerelementen zum Einstellen der Kurvenparameter a auf 1,0, b auf 1,0, t auf 0,0 und dem Schieberegler „Max. Theta“.
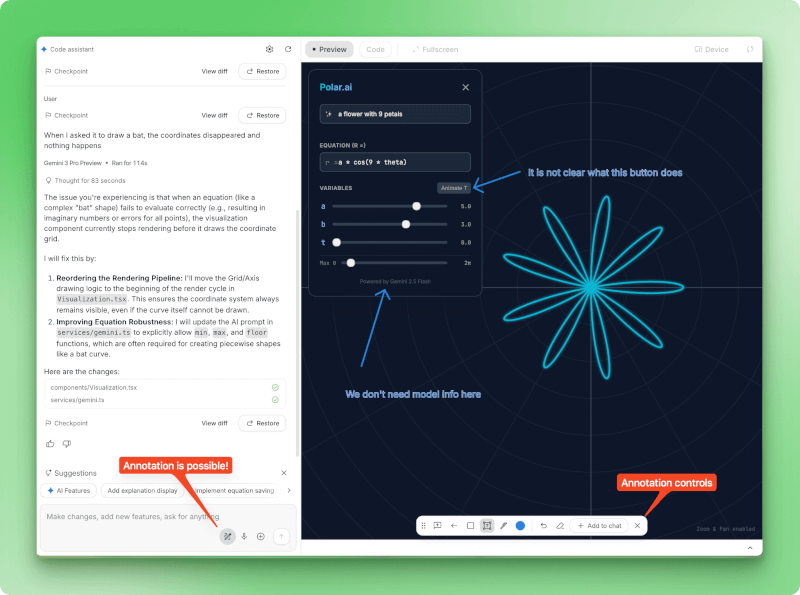
Als die Fledermaus-Koordinaten mitten in der Kurve verschwanden, habe ich das Problem im Chat beschrieben. Das Modell hat das Problem erkannt (imaginäre Zahlen, die den Renderer kaputt machen), die Lösung erklärt und mit „View diff“ einen Checkpoint erstellt, damit ich sehen konnte, was sich geändert hat.
Polar.ai-Debugging-Sitzung mit links im Panel einem Bug-Report vom Nutzer über verschwundene Fledermauskoordinaten, einer Modellantwort, die das Problem mit imaginären Zahlen bei der Gleichungsauswertung mit 83 Sekunden Denkzeit analysiert, einem detaillierten Plan zur Behebung des Problems durch Neuanordnung der Rendering-Pipeline, Checkpoint-Steuerelementen mit den Schaltflächen „View diff“ und „Restore“ sowie rechts im Panel einer Live-Vorschau mit einer Anmerkungs-Symbolleiste am unteren Rand, die Zeichenwerkzeuge und die Option „Add to chat“ anzeigt.
Mit der Anmerkungssymbolleiste kannst du auf Elemente der Benutzeroberfläche klicken, um visuelle Änderungen zu machen. Sobald deine App funktioniert, kannst du sie als ZIP-Download exportieren, auf GitHub hochladen oder auf einem Cloud-Hosting-Server bereitstellen. Der generierte Code nutzt Standard-React-Muster, aber du musst ihn wahrscheinlich noch anpassen, bevor du ihn in der Produktion einsetzt.
Export-Symbolleiste, die den Status „Nicht gespeichert“ anzeigt, mit sechs Aktionssymbolen zum Speichern des Projekts in Google Drive, Herunterladen als ZIP-Datei, Übertragen in das GitHub-Repository, Bereitstellen im Cloud-Hosting, Teilen über einen Link und Projektmanagement-Optionen.
Wenn du bereit bist, KI-Aufgaben über die Google-Plattform hinaus zu erledigen, wirst du bei konkurrierenden Diensten verschiedene Vor- und Nachteile entdecken. Die umfangreiche Plugin-Bibliothek und der sitzungsübergreifende Speicher von chatGPT haben es für viele Leute zur ersten Wahl gemacht.
Claude zielt auf Entwickler ab, die mit Artifacts Unterhaltungen in dauerhafte Apps verwandeln und über MCP-Verbindungen mit Slack oder Asana verbunden sind.
Grok verbindet sich mit dem Echtzeit-Feed von X, hat aber bei komplizierten Denkaufgaben noch Nachholbedarf. Für einen detaillierten Vergleich der Leistung von Gemini und chatGPT anhand verschiedener Benchmarks schau dir unsere direkte Gegenüberstellung von Gemini und chatGPT.
|
Plattform |
Kostenlose Stufe |
Bezahlte Stufe |
Wichtigste Stärken |
Am besten geeignet für |
|
Google AI Studio |
Eingeschränkt (5–15 U/min, kostenpflichtige Premium-Modelle) |
Pay-as-you-go |
Bau-Modus, Stream-Modus, Video (Veo 3), Karten-Bodenverbindung |
Multimodales Prototyping, Experimentieren mit Gemini |
|
ChatGPT |
10–60 Nachrichten/5 Stunden (GPT-4o) |
20 $/Monat |
Speicher, Plugins, ausgereiftes Ökosystem |
Allgemeine Aufgaben, festgelegte Arbeitsabläufe |
|
Claude |
20–40 Nachrichten pro Tag |
20 $/Monat |
Artefakte, Projekte (200K), gut im Programmieren |
App-Prototyping, Hilfe beim Programmieren |
|
Grok |
2-10 Aufforderungen/2 Stunden |
40 $/Monat |
Echtzeit-X-Daten, Aurora-Bilder |
X-Integration, leicht zu bedienen |
Die Situation bei den kostenlosen Tarifen ist je nach Plattform ziemlich unterschiedlich:
chatGPT und Claude verlangen 20 Dollar im Monat für den vollen Webzugang. Grok hat das auf 40 Dollar verdoppelt. Bei der API-Arbeit ist Grok mit 0,20 Dollar pro Million Token echt der Gewinner, verglichen mit 5 Dollar für GPT-4o oder 3 Dollar für Claude Sonnet.
Das Budget und die Prioritäten machen diese Entscheidung für jeden anders. Wenn du Prototypen für multimodale Apps entwickelst, sind der Build-Modus und die Videogenerierung von AI Studio die strengeren Ratenbeschränkungen wert.
Das chatGPT-Ökosystem hat echt Schwung: Plugins, Speicher und eingespielte Arbeitsabläufe machen den Wechsel ziemlich teuer. Claudes 200K-Token-Projekte sind für Entwickler interessant, die große Kontextfenster für ihren Code brauchen. Grok hat seine Nische im günstigen API-Zugang (0,20 $ pro Million Token) und der Echtzeit-X-Integration gefunden und akzeptiert dabei den Kompromiss bei der Performance.
In diesem Tutorial hab ich gezeigt, wie Google AI Studio drei verschiedene Arbeitsabläufe macht: das Testen von Eingabeaufforderungen im Chat-Modus, das Erstellen von Apps über natürliche Sprache im Build-Modus und das Besprechen von Problemen mit Sprache und Video im Stream-Modus. Die Plattform ist super, wenn du Prototypen mit Gemini-Modellen erstellen willst, ohne Setup-Code schreiben zu müssen.
Die kostenlosen Nutzungsbeschränkungen (5–15 Anfragen pro Minute) sind für erste Tests okay. Wenn du bereit bist, Gemini in Produktionsanwendungen zu integrieren, empfehle ich dir, dir das Gemini-API-Tutorial, das sich mit Authentifizierung, Fehlerbehandlung und Optimierungsmustern beschäftigt.
Die Stärke von AI Studio ist das schnelle Prototyping. Du kannst eine Idee im Chat-Modus ausprobieren, sie im Build-Modus ausarbeiten und dann den Code exportieren, wenn sie funktioniert. Die browserbasierte Oberfläche macht die üblichen Probleme überflüssig, aber für den Einsatz in der Produktion brauchst du trotzdem eine ordentliche API-Integration.
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal