
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Mit Docker kannst du konsistente, portable und isolierte Umgebungen schaffen, was es für LLMOps (Large Language Models Operations) unverzichtbar macht. Indem verschiedene LLM-Anwendungen und ihre Abhängigkeiten in Containern gekapselt werden, vereinfacht Docker die Bereitstellung, gewährleistet systemübergreifende Kompatibilität und rationalisiert die Tests.
In diesem Tutorial lernst du, wie du eine Chatbot-Anwendung "Dokument Q&A" erstellst und sie mit Docker in der Cloud bereitstellst. Wir werden Gradio für die Benutzeroberfläche, LlamaIndex für die Orchestrierung, LlamaParse für das Parsen von Dokumenten, Mixedbread AI für die Einbettung, Groq für den Zugriff auf große Sprachmodelle, Docker für die Paketierung der Anwendung und ihrer Abhängigkeiten und Hugging Face Spaces für die Bereitstellung der Anwendung in der Cloud verwenden.
Dieses Tutorial ist so einfach gehalten, dass auch Personen mit geringen Kenntnissen über die Funktionsweise von KI-Anwendungen es kostenlos erstellen können.
Es gibt zwei Hauptansätze für die Entwicklung und den Einsatz von KI-Anwendungen:
Beide Ansätze haben Vor- und Nachteile. In unserem Fall haben wir uns für den zweiten Ansatz entschieden und mehrere KI-Dienste integriert. So können wir eine schnelle KI-Anwendung erstellen, die nur wenige Sekunden zum Aufbau und Einsatz benötigt. Unser Hauptaugenmerk liegt darauf, die Größe des Docker-Images zu reduzieren, was durch die Integration mehrerer KI-Dienste effektiv erreicht werden kann.
Schau dir das Tutorial "Lokale KI mit Docker, n8n, Qdrant und Ollama " an, um eine LLM-Anwendung mit Open-Source-Tools und -Frameworks für mehr Privatsphäre zu erstellen!
Wir werden einen universellen Q&A-Chatbot bauen, der es Nutzern ermöglicht, Dokumente hochzuladen und mit ihnen in Echtzeit zu chatten. Es ist dem NotebookLM von Google sehr ähnlich.
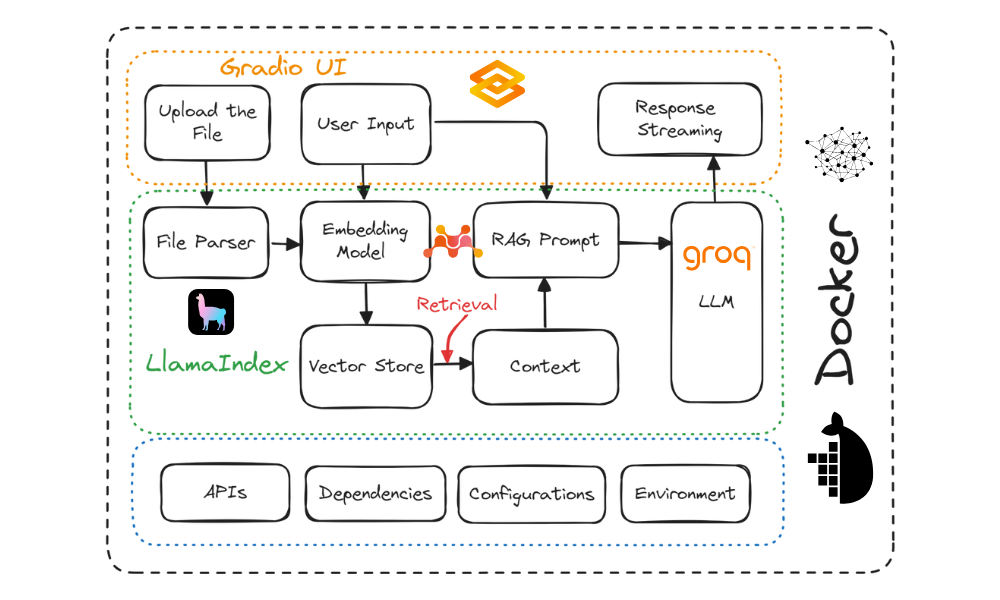
Projektdiagramm. Bild vom Autor
Hier sind die Werkzeuge, die wir in diesem Projekt verwenden werden:
Wenn du neu auf dem Gebiet der LLMs bist, solltest du den Kurs Master Large Language Models (LLMs) Concepts besuchen, um die grundlegenden Terminologien, Methoden, ethischen Überlegungen und die neuesten Forschungsergebnisse kennenzulernen.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Bevor wir die LLM-App erstellen, müssen wir Docker von der offiziellen Website herunterladen und installieren.
.env Datei hinzu. In dieser Datei werden wir die API-Schlüssel für LlamaCloud, MixedBread AI und Groq Cloud speichern.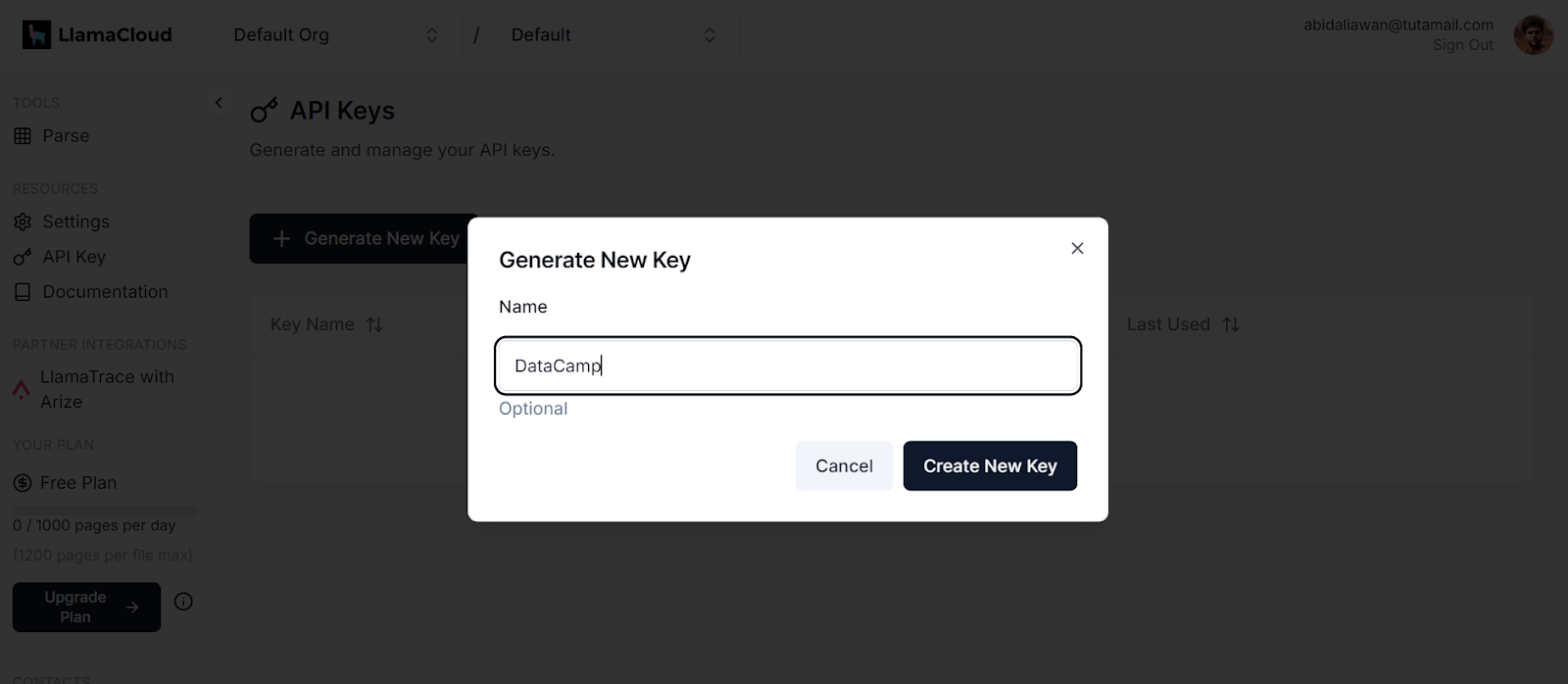
Erzeugen eines neuen Schlüssels in LlamaCloud. Bildquelle: LlamaCloud
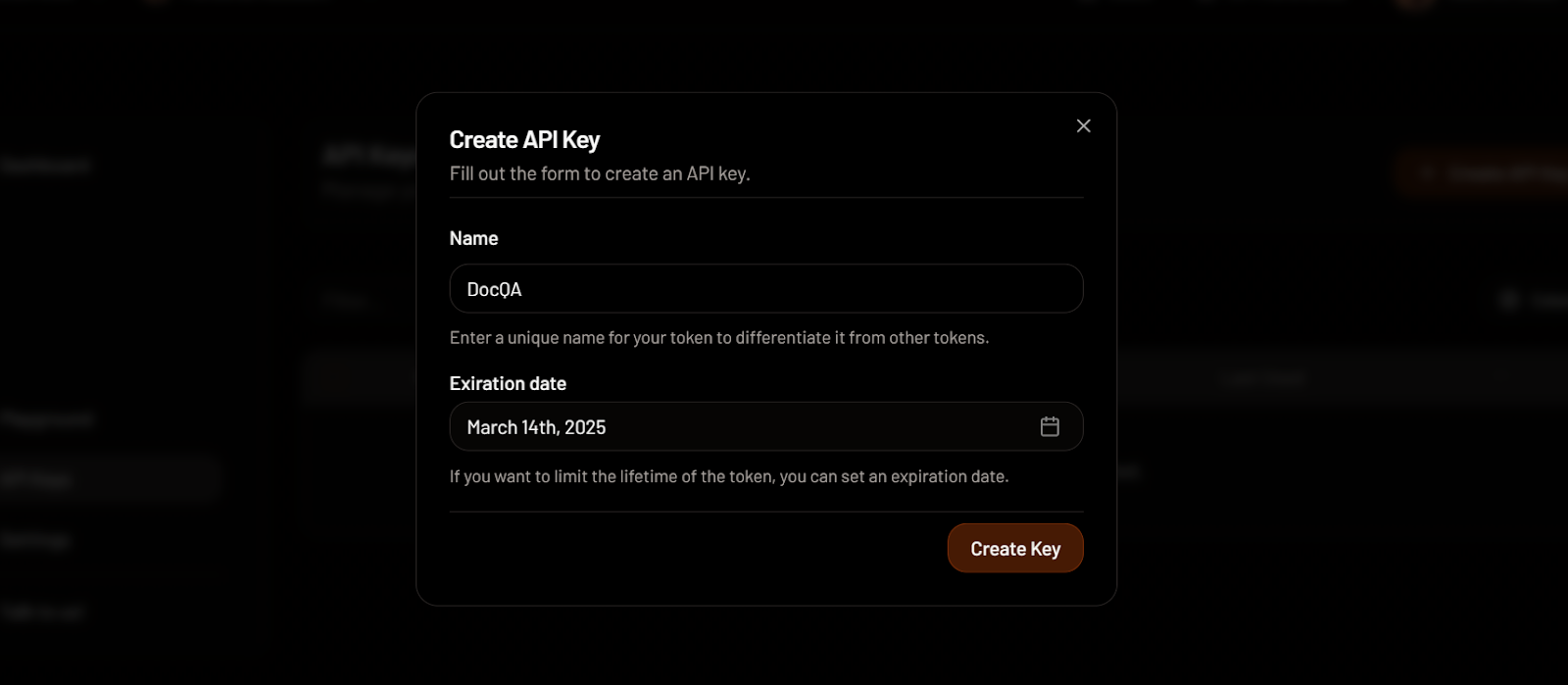
Erstellen eines API-Schlüssels in MixedBread. Bildquelle: MixedBread
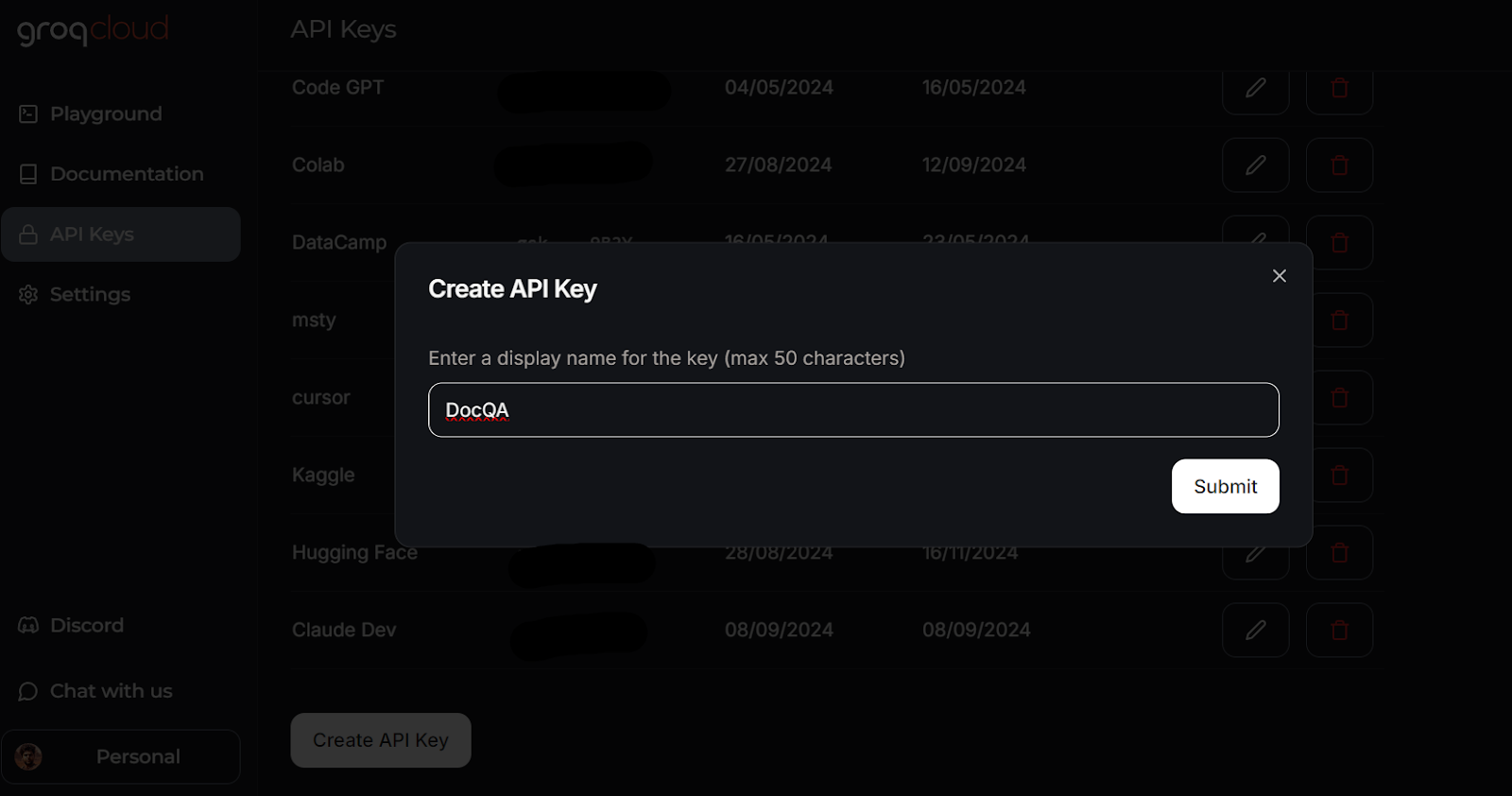
Erstellen eines API-Schlüssels in GroqCloud. Bildquelle: GroqCloud
Erfahre alles über GroqCloud, indem du den Artikel über die Groq LPU Inference Engine liest. Du wirst die Groq-API und ihre Funktionen anhand von Codebeispielen kennenlernen. Außerdem lernst du, wie du mit der Groq API und LlamaIndex kontextbezogene KI-Anwendungen erstellen kannst.
So sollte deine .env Datei aussehen:
LLAMA_CLOUD_API_KEY=llx-XXXXXX
GROQ_API_KEY=gsk_XXXXXXX
MXBAI_API_KEY=emb_XXXXXXVergiss nicht, die Datei .env zu deiner .gitignore Datei hinzuzufügen, um zu verhindern, dass deine API-Schlüssel versehentlich öffentlich zugänglich gemacht werden.
Wir erstellen nun ein Python-Skript namens app.py und fügen die Komponenten der Benutzeroberfläche hinzu, während wir alle KI-Dienste mit LlamaParser integrieren, um die Retrieval-Augmented Generation (RAG) Pipeline mit LlamaIndex zu entwickeln.
Das Skript app.py macht Folgendes:
.env.mixedbread-ai/mxbai-embed-large-v1.llama-3.1-70b-versatile.Als Nächstes werden die folgenden Python-Funktionen implementiert:
load_files(): Diese Funktion lädt die Dateien, parst sie mit dem LlamaParser, wandelt sie in Einbettungen um und speichert sie im Vektorspeicher. Es wird eine Ausnahmebehandlung eingeführt, um Fälle zu behandeln, in denen keine Dateien oder nicht unterstützte Dateiformate hochgeladen werden.respond(): Diese Funktion nimmt Benutzereingaben entgegen, ruft Inhalte aus dem Vektorspeicher ab und generiert daraus eine Antwort, die das Groq-Modell nutzt. Die Antwort wird im Streaming-Format generiert, und es werden Ausnahmen behandelt, wenn keine Dateien hochgeladen wurden.Schließlich werden die UI-Komponenten erstellt, darunter ein Datei-Uploader, Schaltflächen, ein Chat-Feld und die gesamte Chat-Oberfläche.
Erfahre mehr über das LlamaIndex-Framework, indem du dem einfachen LlamaIndex-Tutorial folgst.
Hier ist das app.py Skript:
import os
import gradio as gr
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.mixedbreadai import MixedbreadAIEmbedding
from llama_index.llms.groq import Groq
from llama_parse import LlamaParse
# API keys
llama_cloud_key = os.environ.get("LLAMA_CLOUD_API_KEY")
groq_key = os.environ.get("GROQ_API_KEY")
mxbai_key = os.environ.get("MXBAI_API_KEY")
if not (llama_cloud_key and groq_key and mxbai_key):
raise ValueError(
"API Keys not found! Ensure they are passed to the Docker container."
)
# models name
llm_model_name = "llama-3.1-70b-versatile"
embed_model_name = "mixedbread-ai/mxbai-embed-large-v1"
# Initialize the parser
parser = LlamaParse(api_key=llama_cloud_key, result_type="markdown")
# Define file extractor with various common extensions
file_extractor = {
".pdf": parser,
".docx": parser,
".doc": parser,
".txt": parser,
".csv": parser,
".xlsx": parser,
".pptx": parser,
".html": parser,
".jpg": parser,
".jpeg": parser,
".png": parser,
".webp": parser,
".svg": parser,
}
# Initialize the embedding model
embed_model = MixedbreadAIEmbedding(api_key=mxbai_key, model_name=embed_model_name)
# Initialize the LLM
llm = Groq(model="llama-3.1-70b-versatile", api_key=groq_key)
# File processing function
def load_files(file_path: str):
global vector_index
if not file_path:
return "No file path provided. Please upload a file."
valid_extensions = ', '.join(file_extractor.keys())
if not any(file_path.endswith(ext) for ext in file_extractor):
return f"The parser can only parse the following file types: {valid_extensions}"
document = SimpleDirectoryReader(input_files=[file_path], file_extractor=file_extractor).load_data()
vector_index = VectorStoreIndex.from_documents(document, embed_model=embed_model)
print(f"Parsing completed for: {file_path}")
filename = os.path.basename(file_path)
return f"Ready to provide responses based on: {filename}"
# Respond function
def respond(message, history):
try:
# Use the preloaded LLM
query_engine = vector_index.as_query_engine(streaming=True, llm=llm)
streaming_response = query_engine.query(message)
partial_text = ""
for new_text in streaming_response.response_gen:
partial_text += new_text
# Yield an empty string to cleanup the message textbox and the updated conversation history
yield partial_text
except (AttributeError, NameError):
print("An error occurred while processing your request.")
yield "Please upload the file to begin chat."
# Clear function
def clear_state():
global vector_index
vector_index = None
return [None, None, None]
# UI Setup
with gr.Blocks(
theme=gr.themes.Default(
primary_hue="green",
secondary_hue="blue",
font=[gr.themes.GoogleFont("Poppins")],
),
css="footer {visibility: hidden}",
) as demo:
gr.Markdown("# DataCamp Doc Q&A 🤖📃")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
file_count="single", type="filepath", label="Upload Document"
)
with gr.Row():
btn = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Status")
with gr.Column(scale=3):
chatbot = gr.ChatInterface(
fn=respond,
chatbot=gr.Chatbot(height=300),
theme="soft",
show_progress="full",
textbox=gr.Textbox(
placeholder="Ask questions about the uploaded document!",
container=False,
),
)
# Set up Gradio interactions
btn.click(fn=load_files, inputs=file_input, outputs=output)
clear.click(
fn=clear_state, # Use the clear_state function
outputs=[file_input, output],
)
# Launch the demo
if __name__ == "__main__":
demo.launch()$ python app.py Ausgabe:

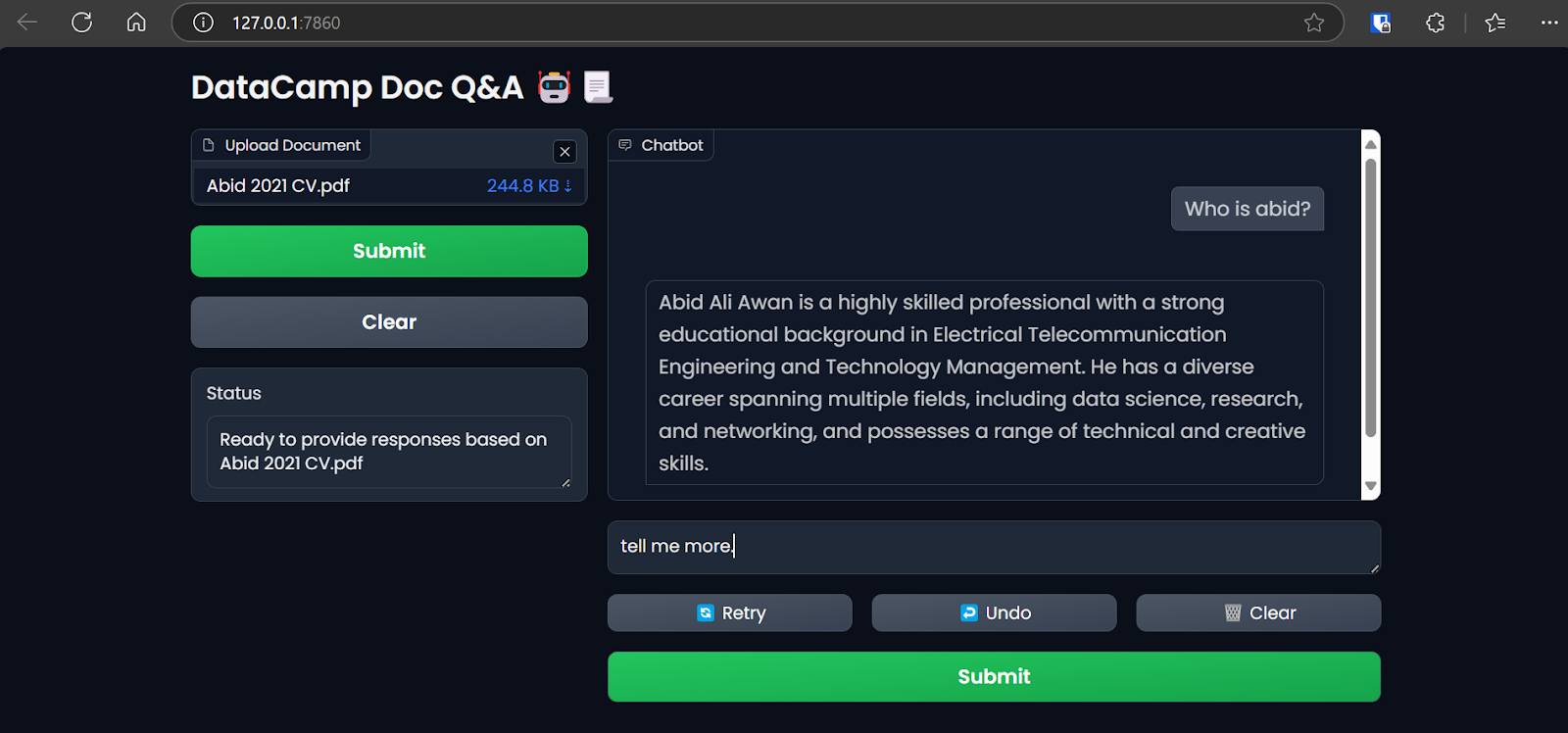
Zugriff auf die Gradio-App über den Browser. Bild vom Autor
Wir verwenden LlamaIndex, um unsere LLM-Anwendung für diesen Lehrgang zu erstellen. Du kannst eine ähnliche Anwendung mit LangChain erstellen, indem du den Kurzkurs Developing LLM Applications with LangChain belegst.
Dockerfile, um das Anwendungsskript, die Python-Abhängigkeiten und die Serverkonfigurationen zu verpacken und den Gradio-Server zu initialisieren. Die Dockerfile übernimmt die folgenden Aufgaben:
requirements.txt in das Verzeichnis /app. Diese Datei enthält die Namen aller benötigten Python-Pakete.requirements.txt angegeben sind.app.py in das Verzeichnis /app.So sollte die Dockerfile aussehen:
# Dockerfile
# Use the official Python image with the desired version
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy the requirements file to the working directory
COPY requirements.txt /app
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code to the working directory
COPY app.py /app
# Expose the port that Gradio will run on (default is 7860)
EXPOSE 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
# Command to run your application
CMD ["python", "app.py"]requirements.txt aus. Füge sie auch zu deinem Projekt hinzu:gradio
llama-index-embeddings-mixedbreadai
llama-index-llms-groq
llama-indexdocqa Docker-Image zu erstellen. Es wird die Dockerfile verwenden, um das Docker-Image zu erstellen.$ docker build -t docqa . Wir können die Protokolle der Prozesse sehen, die während der Erstellung des Docker-Images ablaufen:
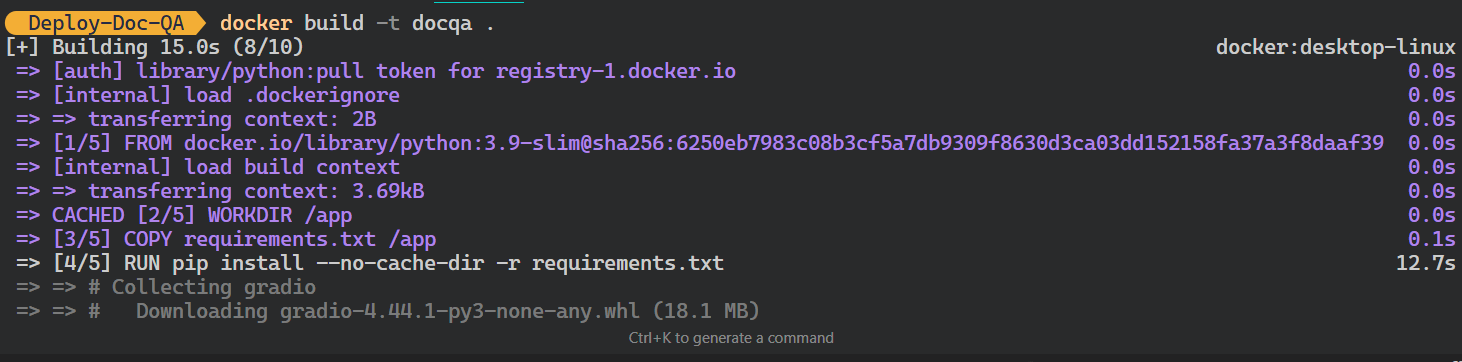
Erstellen des LLM-Docker-Images. Bild vom Autor
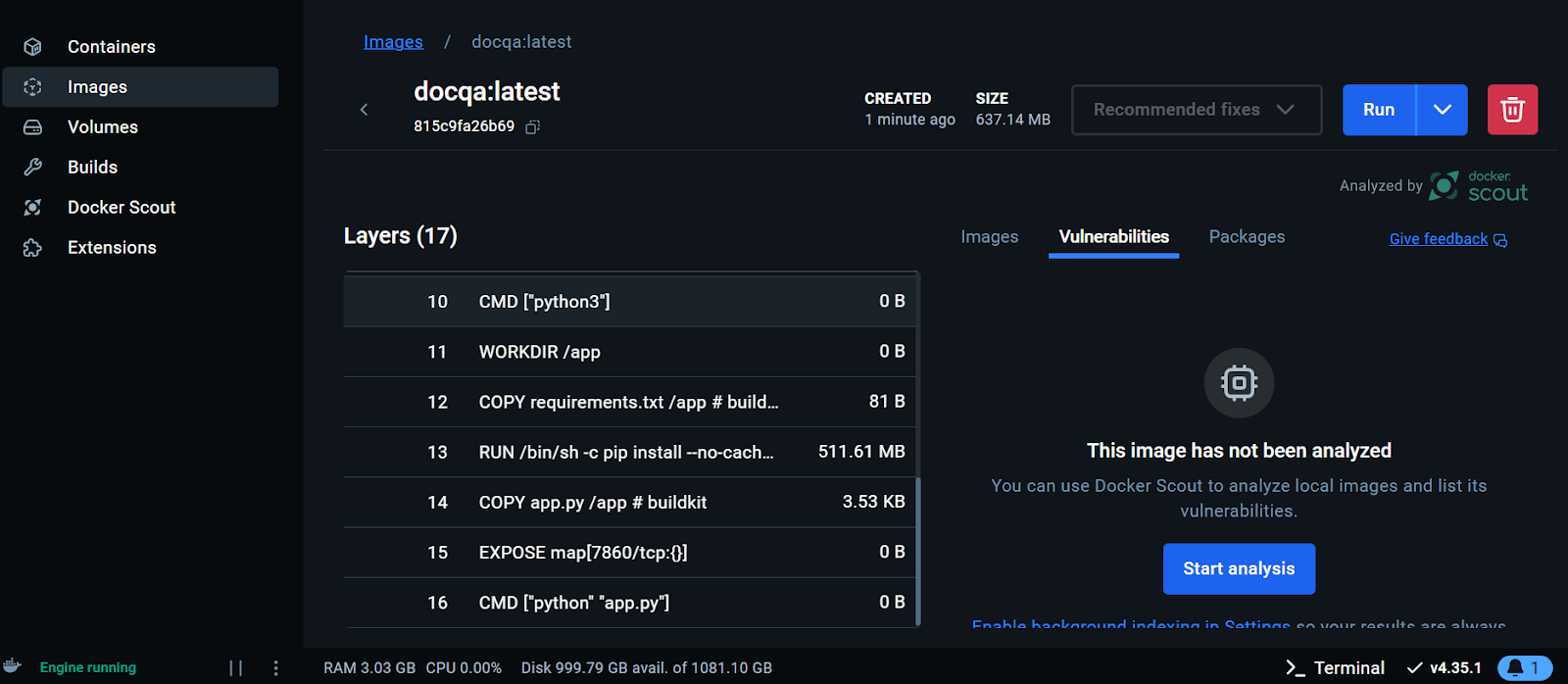
Anzeige des Docker-Images auf dem Docker-Desktop. Bild vom Autor
Wir werden nun den Docker-Container lokal mit dem Image ausführen. Wir geben ihm die Portnummer, eine .env Datei zum Einrichten von Umgebungsvariablen, den Namen des Docker Containers und das Docker Image Tag.
$ docker run -p 7860:7860 --env-file .env --name docqa-container docqaSobald der Container läuft, kannst du auf die Gradio-App zugreifen, indem du die URL, in diesem Fall http://0.0.0.1:7860/, in den Browser einfügst.
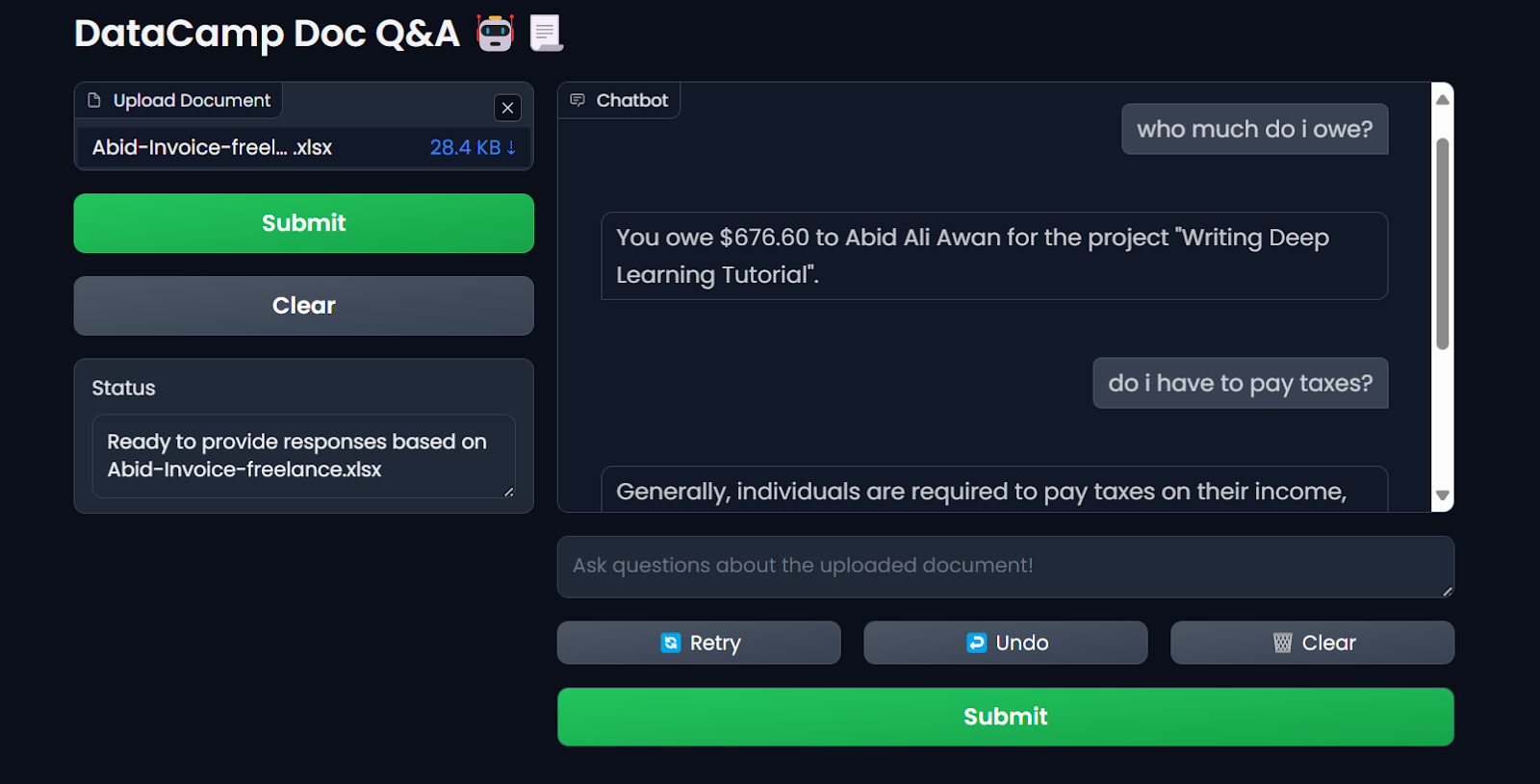
Testen der LLM-Anwendung im Docker-Container. Bild vom Autor
$ docker psAusgabe:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ff2a11da13d7 docqa "python app.py" 17 seconds ago Up 16 seconds 0.0.0.0:7860->7860/tcp docqa-containerstop anhalten:$ docker stop docqa-container rm entfernen:$ docker rm docqa-container Sobald wir ein Docker-Image haben, können wir unsere LLM-Anwendung überall einsetzen: GCP, AWS, Azure oder jeder andere Cloud-Server, der die Docker-Bereitstellung unterstützt.
Um es Anfängern zu erleichtern, werden wir die App mit Docker in der Hugging Face Cloud (Spaces) bereitstellen.
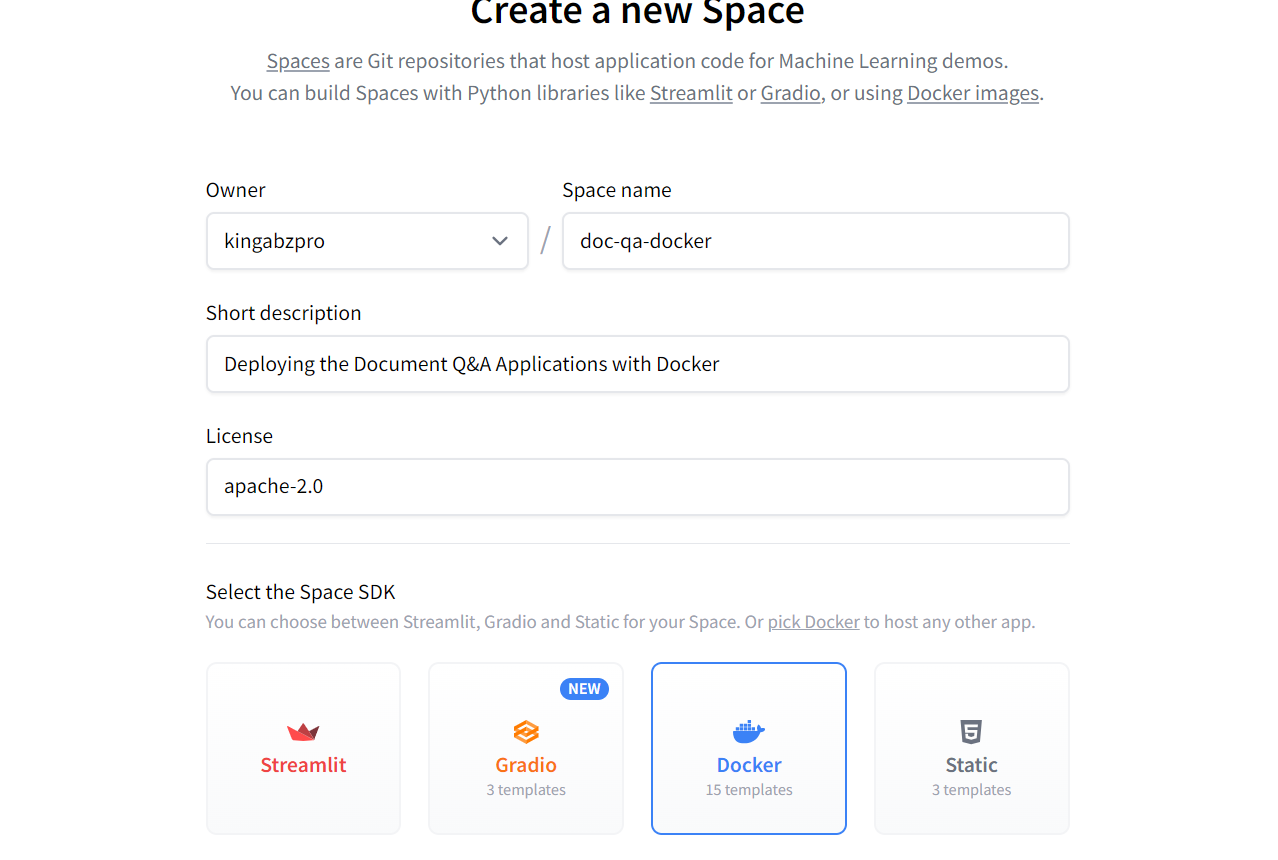
Erstellen des neuen Hugging Face Space mit Docker. Bild Quelle: Hugging Face
Sobald das Space-Repository erstellt ist, erhältst du Anweisungen, wie du es klonen und die erforderlichen Dateien hinzufügen kannst.
$ git clone https://huggingface.co/spaces/kingabzpro/doc-qa-dockerSo sollte dein Projektverzeichnis mit allen Dateien aussehen. Achte immer darauf, dass du die Datei .env nicht pushst, also füge sie der .gitignore hinzu.
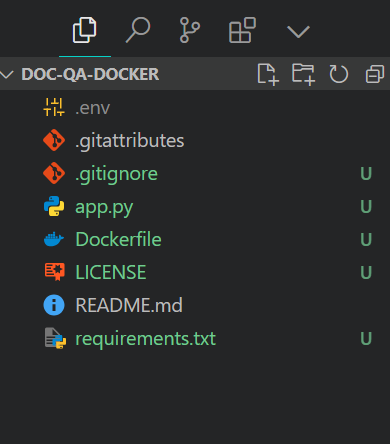
Struktur der Projektdatei. Bild vom Autor
$ git add .
$ git commit -m "Deploying the App"
$ git pushAusgabe:
Enumerating objects: 8, done.
Counting objects: 100% (8/8), done.
Delta compression using up to 16 threads
Compressing objects: 100% (7/7), done.
Writing objects: 100% (7/7), 7.60 KiB | 7.60 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To https://huggingface.co/spaces/kingabzpro/doc-qa-docker
afb20ad..5ca6388 main -> main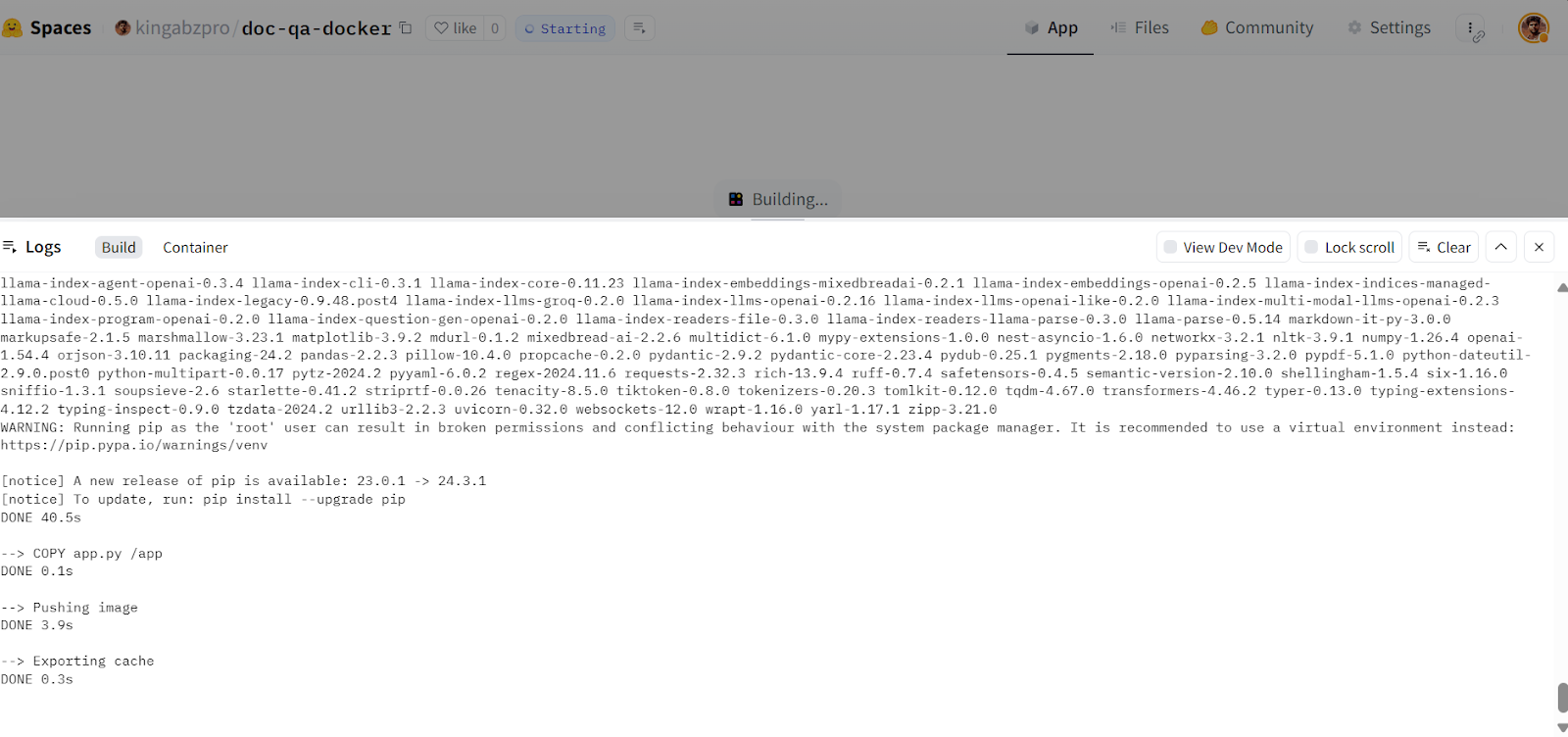
Erstellen des Docker-Images in der Hugging Face Cloud. Bildquelle: Doc Qa Docker
Wenn du eine Fehlermeldung wie die unten stehende siehst, mach dir keine Sorgen. Es liegt an fehlenden Umgebungsvariablen. Alles, was wir tun müssen, ist, diese Variablen im Hugging Face Space einzurichten.

Laufzeitfehler in der bereitgestellten App. Bildquelle: Doc Qa Docker
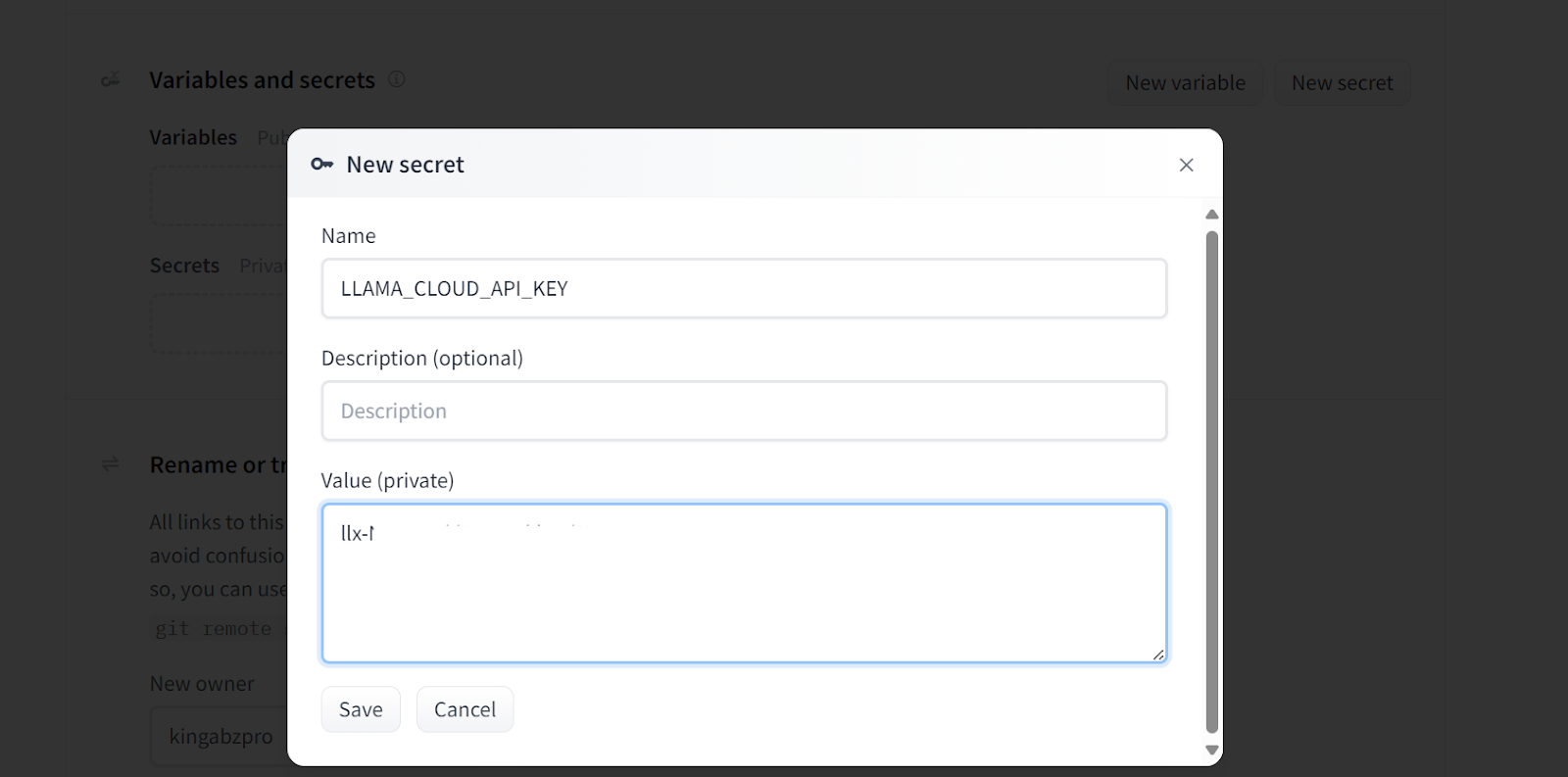
Hinzufügen von Geheimnissen zu der bereitgestellten App. Bildquelle: Doc Qa Docker-Einstellungen.
So sollten deine Geheimnisse aussehen, nachdem du alle notwendigen API-Schlüssel als Umgebungsvariablen hinzugefügt hast:
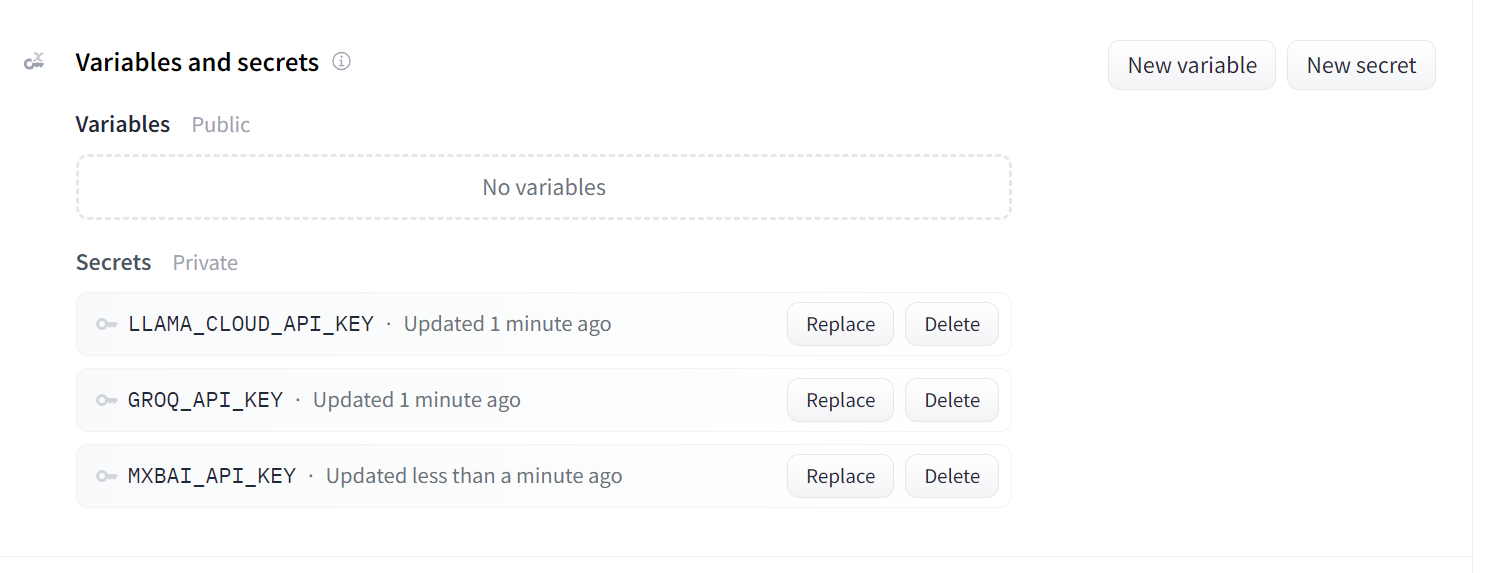
Geheimnisse für die eingesetzte App. Bildquelle: Doc Qa Docker-Einstellungen.
Sobald du die Geheimnisse eingerichtet hast, wird die App automatisch neu gestartet und du solltest sehen, dass die App läuft. Nutze sie und genieße deine Q&A-Anwendung in der Cloud!
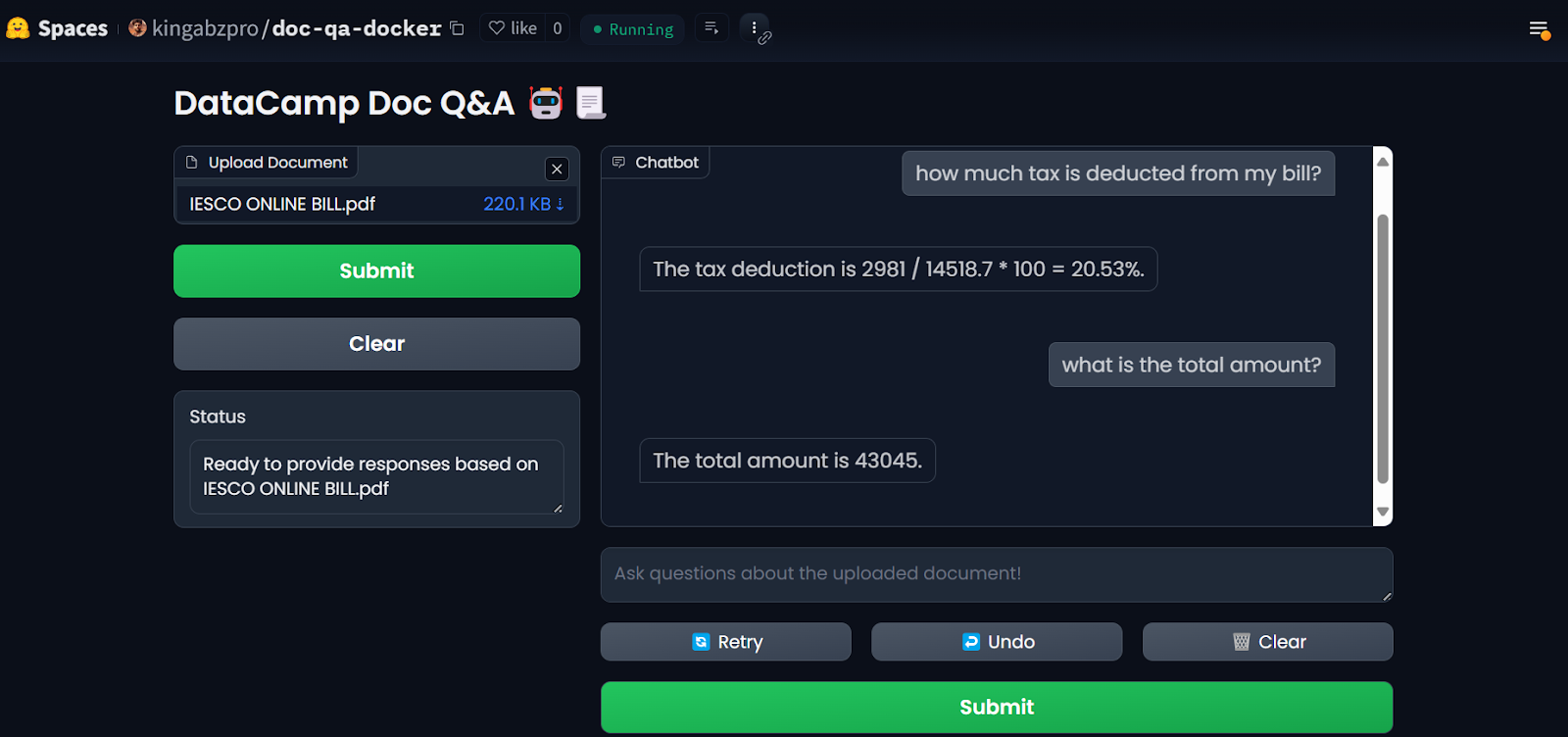
LLM-App auf den Hugging Face Spaces. Bildquellee: Doc Qa Docker
Um die Ergebnisse zu reproduzieren, findest du alle Dateien und Konfigurationen im GitHub-Repositoriumsitory: kingabzpro/Deploy-Doc-QA.
Die Nutzung von KI-Diensten hat Vorteile: Du musst keine Dienste einrichten oder verwalten, du bekommst einen hohen Durchsatz und ein Dashboard mit den Protokollen.
Dein LlamaCloud Dashboard protokolliert alle Dokumente, die geparst wurden. Du kannst dir die Historie ansehen oder die Nutzung anfordern und vergleichen.
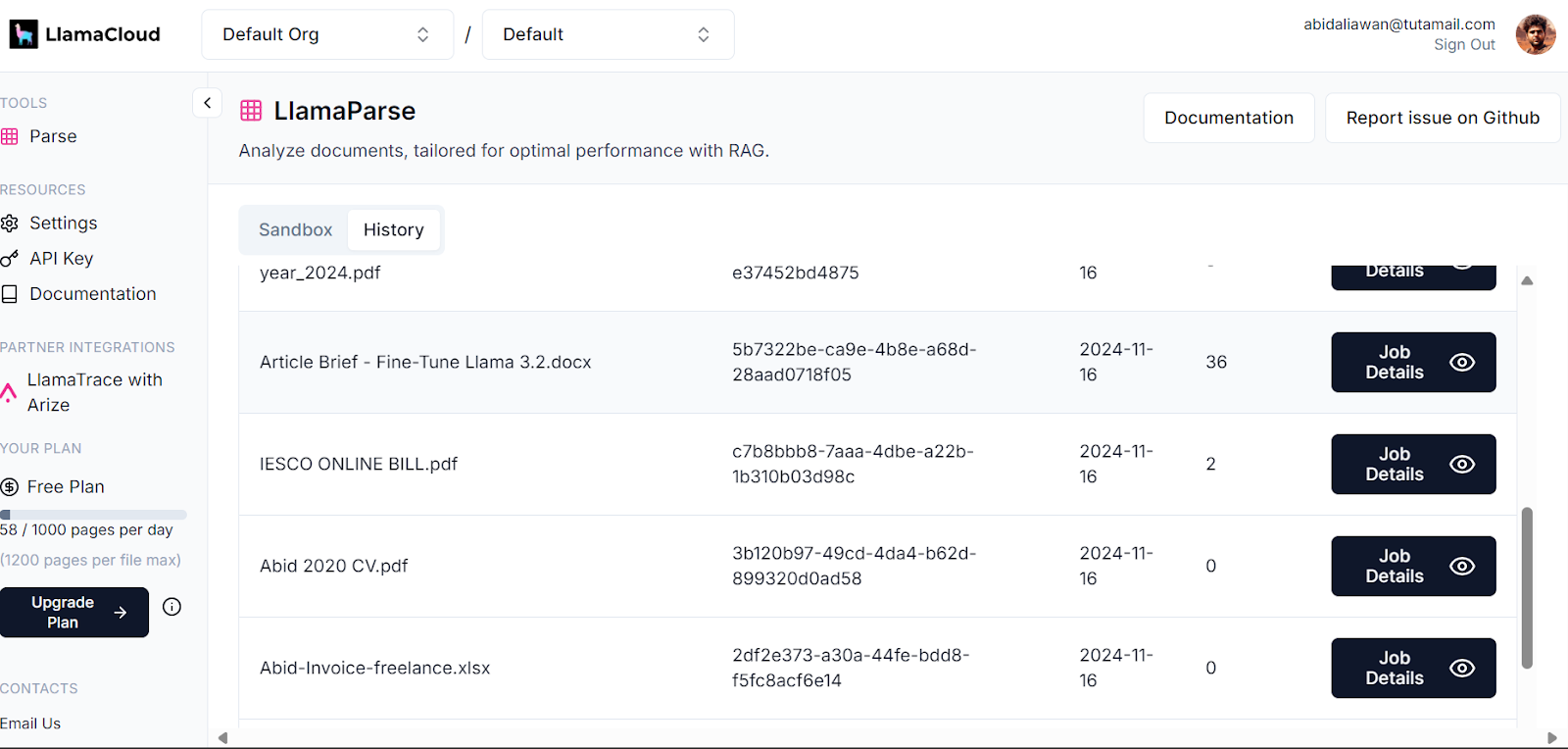
Llama Cloud Dashboard. Bild source: LlamaCloud
Du kannst auch die Anzahl der Token, die wir für das Einbettungsmodell verwendet haben, und die Anzahl der generierten Anfragen überprüfen.
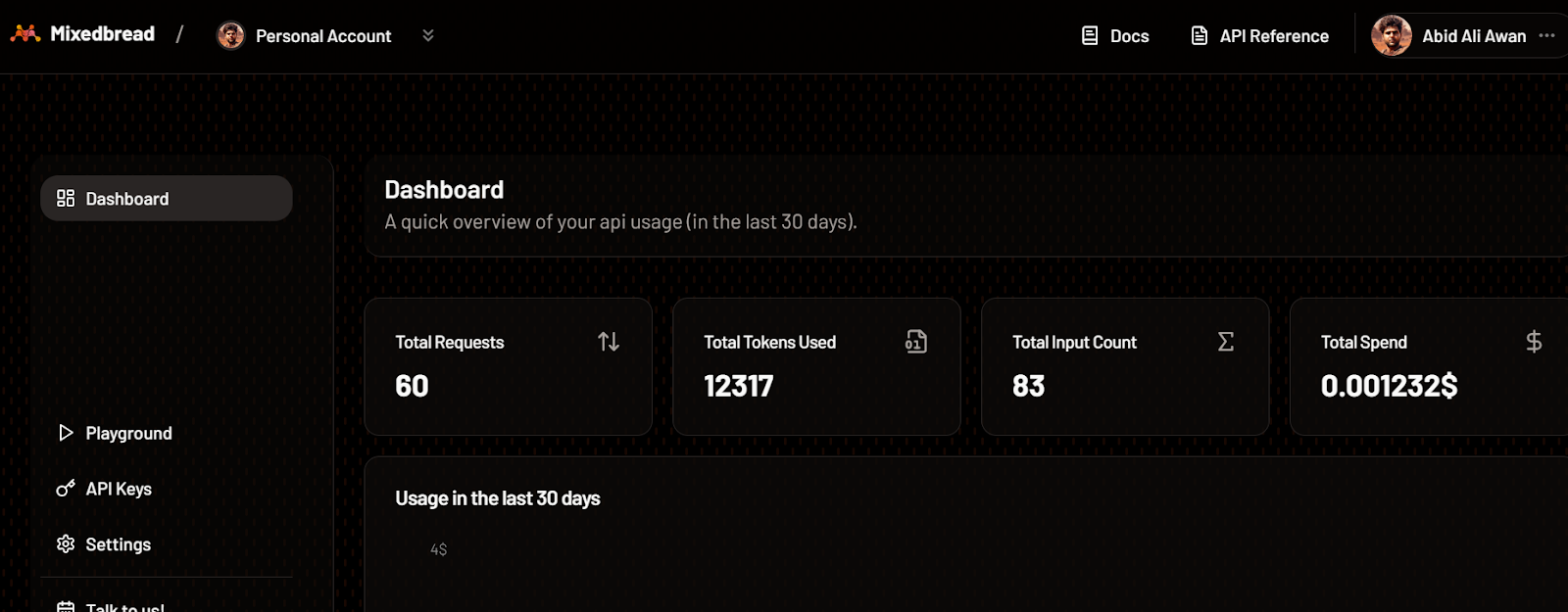
Mixedbread Dashboard. Bildquellee: Mischbrot
Die detailliertesten Logs für jede API findest du in der GroqCloud, mit Informationen über die Latenz, die Anzahl der Token, den AI-Schlüssel und die Request-ID, damit du das System debuggen kannst.
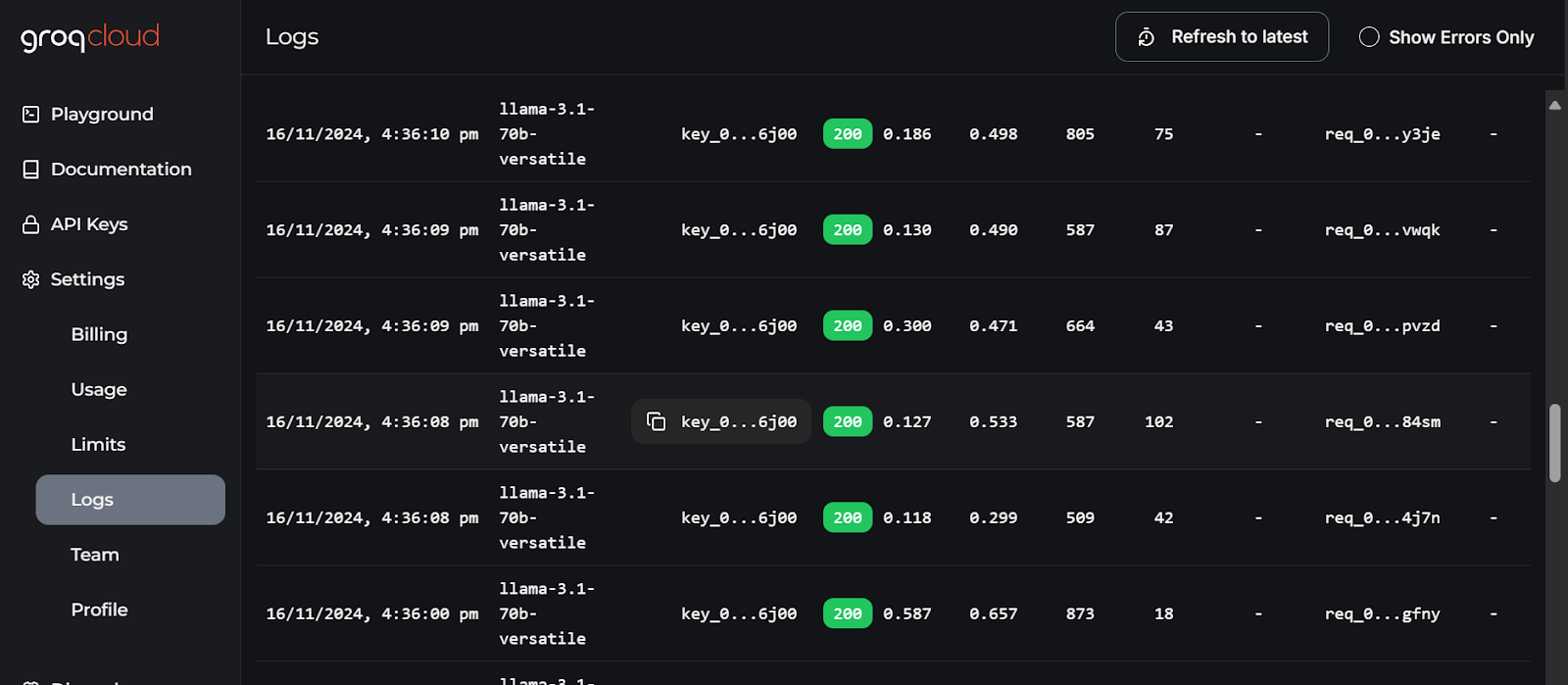
GroqCloud logs. Bild source: GroqCloud
In diesem Leitfaden haben wir gelernt, wie wir mehrere Dienste kombinieren können, um eine effiziente Q&A-Anwendung mit minimalem Ressourcenverbrauch und Rechenaufwand zu erstellen. Alle Dienste und Tools, die wir verwendet haben, sind frei verfügbar, damit du deine eigene Anwendung testen und erstellen kannst.
Wir haben die Größe unseres Docker-Images um 600 MB reduziert, indem wir mehrere sofort einsatzbereite KI-Dienste genutzt haben. Hätten wir alles selbst implementiert, wäre das Image 20 GB oder mehr groß gewesen.
Ich empfehle die LLMOps Concepts: From Ideation to Deployment ist der nächste Schritt auf deiner Lernreise. In diesem Kurs erhältst du Einblicke in den Lebenszyklus der LLM-Entwicklung und in die Herausforderungen bei der Bereitstellung von Anwendungen. Außerdem lernst du, wie du diese Konzepte effektiv anwenden kannst.
Erfahre mehr über LLMs mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.