
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Jeder Entwickler und Betriebsingenieur im IT-Bereich ist mit Docker vertraut, wenn es um die Erstellung und Bereitstellung von Anwendungen geht, egal ob lokal oder in der Cloud. Als Entwickler oder Betriebsingenieur für maschinelles Lernen möchtest du vielleicht Ressourcen optimieren, die Sicherheit erhöhen und die Systemintegration verbessern. Podman bietet eine überzeugende Alternative. Es ist ein kostenloses, quelloffenes Tool, das als Alternative zu Docker und Docker Desktop dient.
In diesem Tutorial erfahren wir, was Podman ist, was der Unterschied zwischen Podman und Docker ist und wie man Podman installiert und benutzt. Außerdem lernen wir, wie man Modelle für maschinelles Lernen mit Dockerfile und Podman-Befehlen trainiert, evaluiert und lokal einsetzt.

Bild vom Autor
Podman ist ein Open-Source-Container-Management-Tool, das Entwicklern und Ingenieuren für maschinelles Lernen eine nahtlose und sichere Erfahrung bietet. Im Gegensatz zu Docker arbeitet Podman ohne Daemon, was die Sicherheit und Flexibilität erhöht, da die Nutzer Container als rootlose Prozesse ausführen können. Diese wichtige Funktion ermöglicht es Podman, Container ohne Root-Rechte auszuführen und so potenzielle Schwachstellen zu minimieren.
Podman ist vollständig kompatibel mit den OCI-Standards (Open Container Initiative), sodass mit Podman erstellte Container und Images problemlos in andere OCI-kompatible Tools und Plattformen wie runc, Buildah und Skopeo integriert werden können. Außerdem unterstützt Podman die Erstellung und Verwaltung von Pods, d.h. Gruppen von Containern, die sich denselben Netzwerk-Namensraum teilen, ähnlich wie Kubernetes-Pods.
Einer der besten Aspekte bei der Verwendung von Podman ist, dass es eine ähnliche Erfahrung wie Docker bietet. Die Kommandozeilenschnittstelle ist mit der von Docker vergleichbar, und du kannst auch Images von Docker Hub beziehen. Diese Ähnlichkeit ermöglicht einen einfachen Übergang für diejenigen, die mit Docker vertraut sind, und bietet gleichzeitig fortschrittliche Funktionen, die den wachsenden Anforderungen der Entwicklung und Bereitstellung von Containeranwendungen gerecht werden.
Podman ist nur ein Werkzeug im Arsenal von MLOps. Erfahre mehr über alle Arten von Tools, die im MLOps-Ökosystem verwendet werden, indem du den Blog liest Die 25 wichtigsten MLOps-Tools, die du im Jahr 2025 kennen musst.
Docker und Podman sind bekannte Container-Management-Tools, die jeweils unterschiedliche Funktionen und Möglichkeiten bieten. Dieser Vergleich untersucht die Unterschiede und hilft dir bei der Entscheidung, welches System am besten zu deinen Bedürfnissen passt.
|
Docker |
Podman |
|
|
Architektur |
Docker verwendet eine Client-Server-Architektur mit einem Daemon-Prozess namens dockerd. |
Podman ist daemonlos und verwendet ein fork-exec-Modell, das die Sicherheit und Einfachheit erhöht. |
|
Sicherheit |
Docker führt Container standardmäßig als root aus, was ein Sicherheitsrisiko darstellen kann. |
Podman unterstützt standardmäßig Rootless-Container, um Sicherheitsrisiken zu verringern. |
|
Image Management |
Docker kann mit seinen eigenen Tools Container-Images erstellen und verwalten. |
Podman nutzt Buildah zum Erstellen von Images und kann Images aus Docker-Registries ausführen. |
|
Kompatibilität |
Docker ist weit verbreitet und in viele CI/CD-Tools integriert. |
Podman bietet ein Docker-kompatibles CLI, das den Wechsel ohne Änderung der Arbeitsabläufe erleichtert. |
|
Container-Orchestrierung |
Docker unterstützt Docker Swarm und Kubernetes für die Orchestrierung. |
Podman unterstützt Docker Swarm nicht, kann aber mit Kubernetes unter Verwendung von Pods arbeiten. |
|
Plattform-Unterstützung |
Docker läuft nativ auf Linux, macOS und Windows (mit WSL). |
Podman unterstützt auch Linux, macOS und Windows (mit WSL). |
|
Leistung |
Docker ist bekannt für seine effiziente Ressourcenverwaltung und schnelle Bereitstellung. |
Podman ist von der Leistung her vergleichbar und bietet schnellere Startzeiten. |
|
Anwendungsfälle |
Docker ist ideal für Projekte, die gut etablierte Tools und Integrationen erfordern. |
Podman eignet sich für Umgebungen, in denen Sicherheit und schlanke Abläufe im Vordergrund stehen. Ideal für groß angelegte Einsätze. |
Die Entscheidung zwischen Docker und Podman hängt größtenteils von den spezifischen Projektanforderungen ab, insbesondere in Bezug auf Sicherheit, Kompatibilität und Orchestrierung.
Docker ist nach wie vor eine gute Wahl für etablierte CI/CD-Pipelines und ein umfassendes Container-Management, während Podman eine sichere, leichtgewichtige Alternative für Umgebungen bietet, in denen Sicherheit und Rootless-Betrieb im Vordergrund stehen. Außerdem bietet es schnellere Startzeiten, was ideal für große Einsätze ist.
Entdecke Docker für Data Science Lies unseren Einführungsartikel, der Beispielcode und Beispiele enthält.
Zuerst musst du das Podman Desktop-Paket herunterladen und installieren. offiziellen Website.
Quelle: Podman
Die Installation ist einfach und schnell. Innerhalb weniger Minuten gelangst du zum Startbildschirm, auf dem du aufgefordert wirst, optionale Erweiterungen zu installieren.
Wenn du keine WSL in Windows hast, wird WSL automatisch installiert.
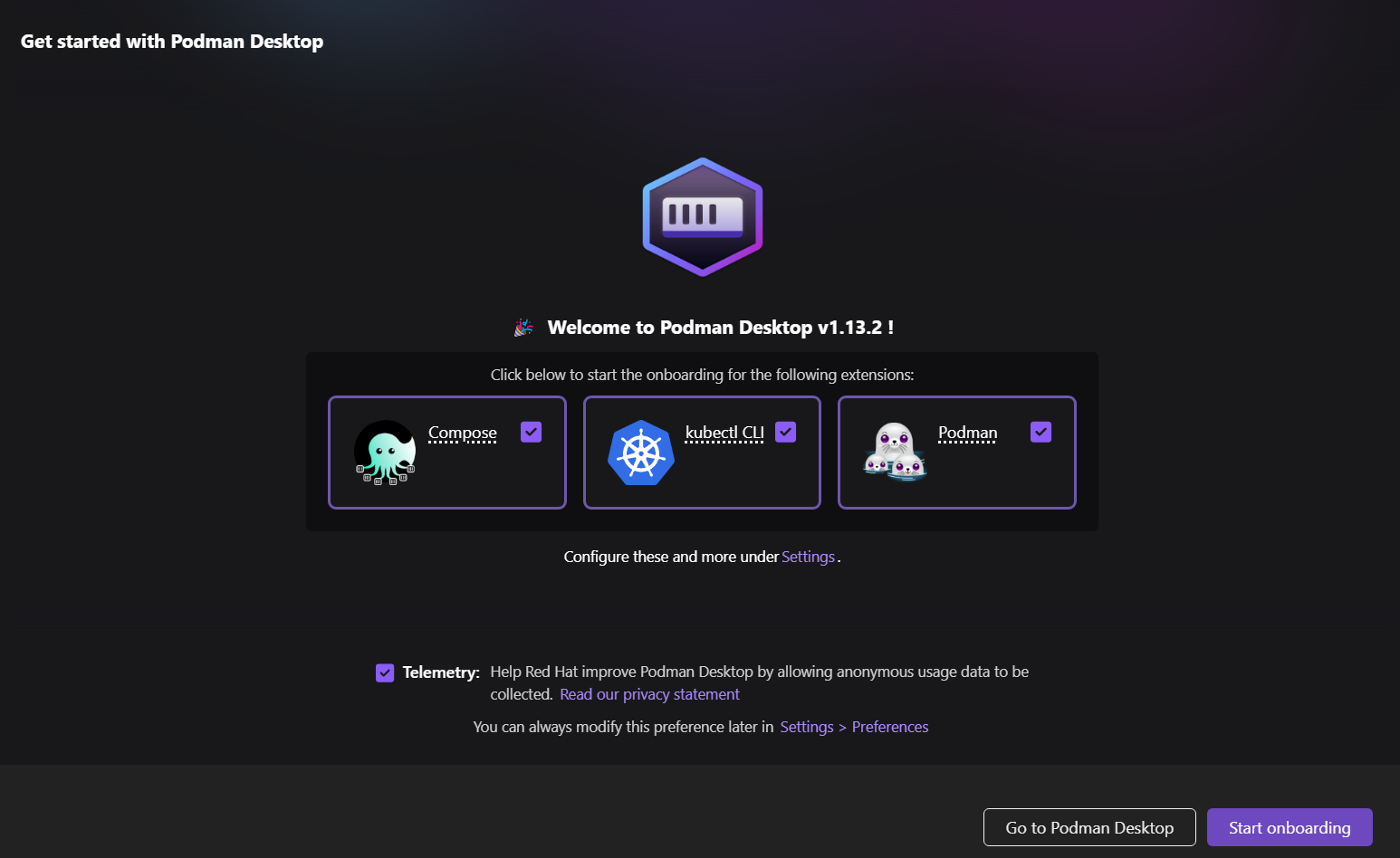
Als nächstes richtest du den Podman-Rechner ein.
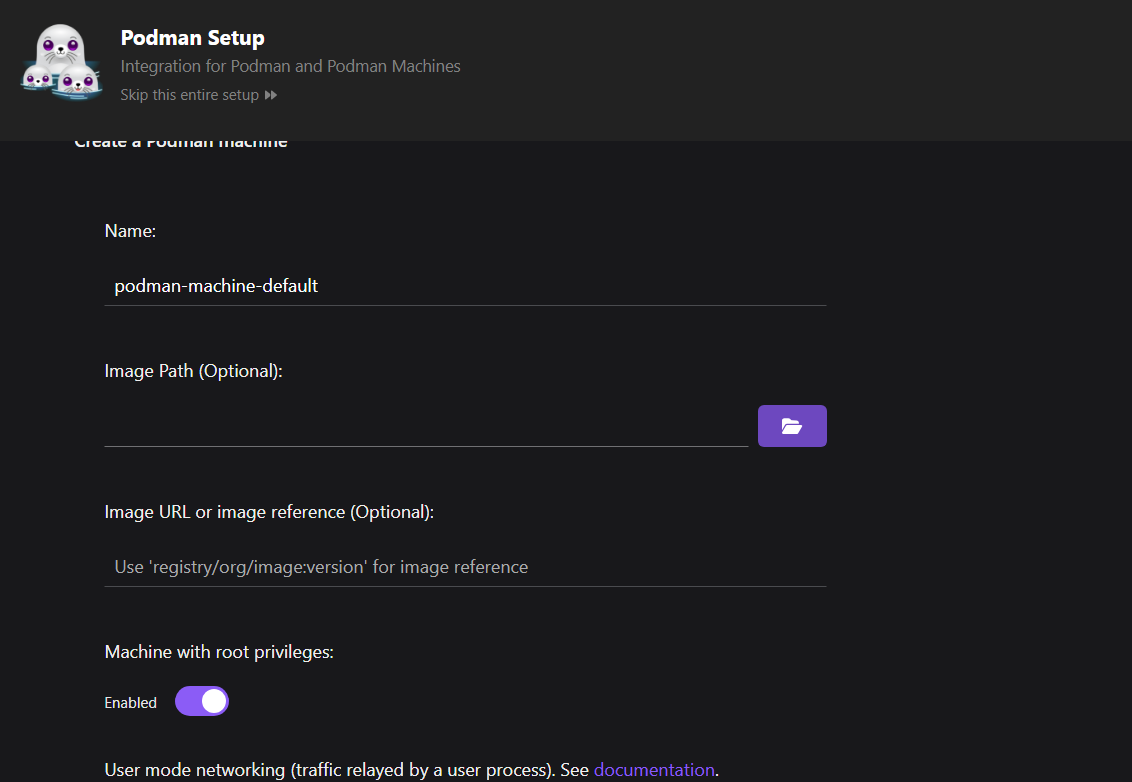
Im Vergleich zu Docker musst du keine Maschine einrichten. In Podman kannst du jedoch mehrere Maschinen mit verschiedenen Containern gleichzeitig verwalten, was eine bessere Ressourcenverwaltung ermöglicht.
Unser Rechner ist betriebsbereit und bereit, Images zu erstellen und die Container auszuführen.
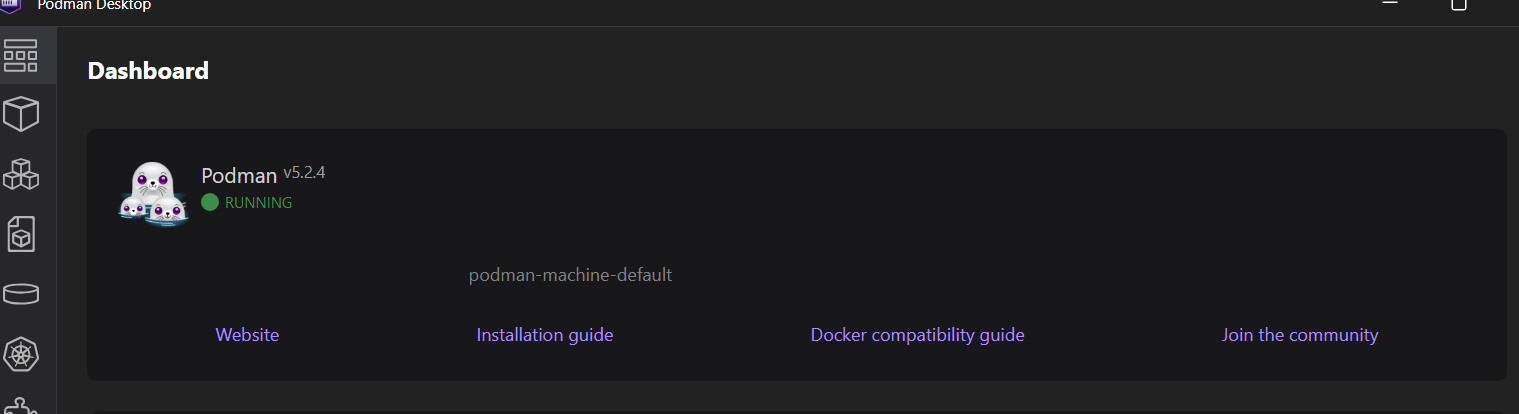
Um zu überprüfen, ob Podman richtig funktioniert, ziehen wir ein Beispiel-Image von quay.io und führen den Container aus.
$ podman run quay.io/podman/helloDer Podman-Rechner hat das Image erfolgreich gezogen und den Container gestartet.
Trying to pull quay.io/podman/hello:latest...
Getting image source signatures
Copying blob sha256:81df7ff16254ed9756e27c8de9ceb02a9568228fccadbf080f41cc5eb5118a44
Copying config sha256:5dd467fce50b56951185da365b5feee75409968cbab5767b9b59e325fb2ecbc0
Writing manifest to image destination
!... Hello Podman World ...!
.--"--.
/ - - \
/ (O) (O) \
~~~| -=(,Y,)=- |
.---. /` \ |~~
~/ o o \~~~~.----. ~~
| =(X)= |~ / (O (O) \
~~~~~~~ ~| =(Y_)=- |
~~~~ ~~~| U |~~
Project: https://github.com/containers/podman
Website: https://podman.io
Desktop: https://podman-desktop.io
Documents: https://docs.podman.io
YouTube: https://youtube.com/@Podman
X/Twitter: @Podman_io
Mastodon: @Podman_io@fosstodon.orgIn diesem MLOps-Projekt werden wir das Training und die Auswertung des Modells automatisieren und das Modell mithilfe von Dockerfile und Podman bereitstellen. Das funktioniert ähnlich wie bei Docker, nur dass wir stattdessen das Podman CLI verwenden, um Images zu erstellen und dann den Container zu starten.
Wenn du mit den Konzepten noch nicht vertraut bist, kannst du die Grundlagen von MLOPs lernen, indem du die MLOps-Konzepte Kurs absolvierst.
Um das Projekt für maschinelles Lernen einzurichten, müssen wir ein Trainings- und Serving-Skript sowie eine requirements.txt-Datei für die Installation der Python-Pakete erstellen.
Das Python-Skript für das Training lädt die Kreditwürdigkeitsklassifizierung Datensatz, verarbeitet ihn, kodiert ihn und trainiert das Modell. Wir werden auch eine Modellbewertung durchführen. Am Ende werden wir die Vorverarbeitungs- und Trainings-Pipeline zusammen mit dem Modell im Pickle-Format speichern.
src/train.py:
# src/train.py
import os
import pickle
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
roc_auc_score,
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
def load_data():
data_path = "data/train.csv"
df = pd.read_csv(data_path,low_memory=False)
print("Data loaded successfully!")
return df
def preprocess_data(df):
# Drop unnecessary columns
df = df.drop(columns=["ID", "Customer_ID", "SSN", "Name", "Month"])
# Drop rows with missing values
df = df.dropna()
# Convert data types
# Convert the 'Age' column to numeric, setting errors='coerce' to handle non-numeric values
df["Age"] = pd.to_numeric(df["Age"], errors="coerce")
# Filter the DataFrame to include only rows where 'Age' is between 1 and 60
df = df[(df["Age"] >= 1) & (df["Age"] <= 60)]
df["Annual_Income"] = pd.to_numeric(df["Annual_Income"], errors="coerce")
df["Monthly_Inhand_Salary"] = pd.to_numeric(
df["Monthly_Inhand_Salary"], errors="coerce"
)
# Separate features and target
X = df.drop("Credit_Score", axis=1)
y = df["Credit_Score"]
print("Data preprocessed successfully!")
return X, y
def encode_data(X):
# Identify categorical and numerical features
categorical_features = [
"Occupation",
"Credit_Mix",
"Payment_of_Min_Amount",
"Payment_Behaviour",
"Type_of_Loan",
]
numerical_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# Define preprocessing steps
numerical_transformer = SimpleImputer(strategy="median")
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numerical_transformer, numerical_features),
("cat", categorical_transformer, categorical_features),
]
)
return preprocessor
def split_data(X, y):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def train_model(X_train, y_train, preprocessor):
# Create a pipeline with preprocessing and model
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", RandomForestClassifier(n_estimators=100)),
]
)
# Train the model
clf.fit(X_train, y_train)
# Return the trained model
return clf
def evaluate_model(clf, X_test, y_test):
# Predict and evaluate
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, labels=["Poor", "Standard", "Good"])
cm = confusion_matrix(y_test, y_pred, labels=["Poor", "Standard", "Good"])
# Calculate AUC score
y_test_encoded = y_test.replace({"Poor": 0, "Standard": 1, "Good": 2})
y_pred_proba = clf.predict_proba(X_test)
auc_score = roc_auc_score(y_test_encoded, y_pred_proba, multi_class="ovr")
# Print metrics
print("Model Evaluation Metrics:")
print(f"Accuracy: {acc}")
print(f"AUC Score: {auc_score}")
print("Classification Report:")
print(report)
# Plot confusion matrix
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation="nearest", cmap=plt.cm.Blues)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(3)
plt.xticks(tick_marks, ["Poor", "Standard", "Good"], rotation=45)
plt.yticks(tick_marks, ["Poor", "Standard", "Good"])
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
cm_path = os.path.join("model", "confusion_matrix.png")
plt.savefig(cm_path)
print(f"Confusion matrix saved to {cm_path}")
def save_model(clf):
model_dir = "model"
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, "model.pkl")
# Save the trained model
with open(model_path, "wb") as f:
pickle.dump(clf, f)
print(f"Model saved to {model_path}")
def main():
# Execute steps
df = load_data()
X, y = preprocess_data(df)
preprocessor = encode_data(X)
X_train, X_test, y_train, y_test = split_data(X, y)
clf = train_model(X_train, y_train, preprocessor)
evaluate_model(clf, X_test, y_test)
save_model(clf)
if __name__ == "__main__":
main()
Das Skript zur Modellbereitstellung lädt die gespeicherte Modellpipeline mithilfe der Modelldatei, erstellt eine POST-Anfragefunktion, die eine Liste von Wörterbüchern vom Benutzer entgegennimmt, sie in einen DataFrame konvertiert, sie dem Modell zur Erstellung von Vorhersagen zur Verfügung stellt und dann das vorhergesagte Label zurückgibt. Wir verwenden FastAPI als API-Framework, mit dem wir das Modell mit nur wenigen Zeilen Code bedienen können.
src/app.py:
# src/app.py
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import os
# Load the trained model
model_path = os.path.join("model", "model.pkl")
with open(model_path, "rb") as f:
model = pickle.load(f)
app = FastAPI()
class InputData(BaseModel):
data: list # List of dictionaries representing feature values
@app.post("/predict")
def predict(input_data: InputData):
# Convert input data to DataFrame
X_new = pd.DataFrame(input_data.data)
# Ensure the columns match the training data
prediction = model.predict(X_new)
# Return predictions
return {"prediction": prediction.tolist()}
Wir müssen eine requirements.txt Datei erstellen, die alle notwendigen Python-Pakete enthält, um die oben genannten Skripte auszuführen. Diese Datei wird verwendet, um eine laufende Umgebung im Docker-Container einzurichten, damit wir die Python-Skripte reibungslos ausführen können.
requirements.txt:
fastapi
uvicorn[standard]
numpy
pandas
scikit-learn
pydantic
matplotlibErstelle ein "Dockerfile" und füge den folgenden Code hinzu.
Hier sind die Schritte, die dieses Dockerfile ausführt:
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY ./src/ ./src/
COPY ./data/ ./data/
# Ensure the model directory exists and is copied
RUN mkdir -p model
# Run the training script during the build
RUN python src/train.py
# Expose the port for the API
EXPOSE 8000
# Run the FastAPI app
CMD ["uvicorn", "src.app:app", "--host", "0.0.0.0", "--port", "8000"]Dein lokaler Arbeitsbereich sollte folgendermaßen organisiert sein:
data Ordner, der alle CSV-Dateien enthältmodels Ordnersrc Ordner, der Python-Skripte enthältrequirements.txt Datei und eine DockerfileDie restlichen Dateien sind zusätzliche Komponenten für die Automatisierung und Git-Operationen.
Das Erstellen des Docker-Images ist einfach: Gib dem Befehl build einfach den Namen deines Docker-Images und das aktuelle Verzeichnis an, in dem sich die Dockerdatei befindet.
$ podman build -t mlops_app .Das Build-Tool führt alle Befehle im Dockerfile der Reihe nach aus, vom Einrichten der Umgebung bis zum Ausliefern der Machine Learning-Anwendung.
Wir können auch sehen, dass die Protokolle die Ergebnisse der Modellbewertung enthalten. Das Modell hat eine Genauigkeit von 75% und einen ROC AUC-Wert von 0,89, was als durchschnittlich gilt.
STEP 1/11: FROM python:3.9-slim
STEP 2/11: WORKDIR /app
--> Using cache 72ac9e49ae29da1ff19e118653efca17e7a489ae9e7ead917c83d942a3ea4e13
--> 72ac9e49ae29
STEP 3/11: COPY requirements.txt .
--> Using cache 3a05ca95caaf98c448c53a796714328bf9f7cff7896cce348f84a26b8d0dae61
--> 3a05ca95caaf
STEP 4/11: RUN pip install --no-cache-dir -r requirements.txt
--> Using cache 28109d1183449396a5df0006ab603dd5cf2aa2c06a810bdc6bcf0f843f855ee0
--> 28109d118344
STEP 5/11: COPY ./src/ ./src/
--> f814f699c58a
STEP 6/11: COPY ./data/ ./data/
--> 922550900cd0
STEP 7/11: RUN mkdir -p model
--> 36fc01f2d169
STEP 8/11: RUN python src/train.py
Data loaded successfully!
Data preprocessed successfully!
Data encoded successfully!
Data split successfully!
Model trained successfully!
Model Evaluation Metrics:
Accuracy: 0.7546181417149159
ROC AUC Score: 0.8897184704689612
Classification Report:
precision recall f1-score support
Good 0.71 0.67 0.69 1769
Poor 0.75 0.76 0.75 3403
Standard 0.77 0.78 0.78 5709
accuracy 0.75 10881
macro avg 0.74 0.74 0.74 10881
weighted avg 0.75 0.75 0.75 10881
Model saved to model/model.pkl
--> 5d4777c08580
STEP 9/11: EXPOSE 8000
--> 7bb09a613e7f
STEP 10/11: WORKDIR /app/src
--> 06b6394c2e2d
STEP 11/11: CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
COMMIT mlops-app
--> 9a7a42b03664
Successfully tagged localhost/mlops-app:latest
9a7a42b03664f1e4631330cd682cb2de26e513c5d776fa2ce2042b3bb9455e14Wenn du die Podman Desktop Anwendung öffnest und auf die Registerkarte "Images" klickst, siehst du, dassdein mlops_app Image erfolgreich erstellt wurde.
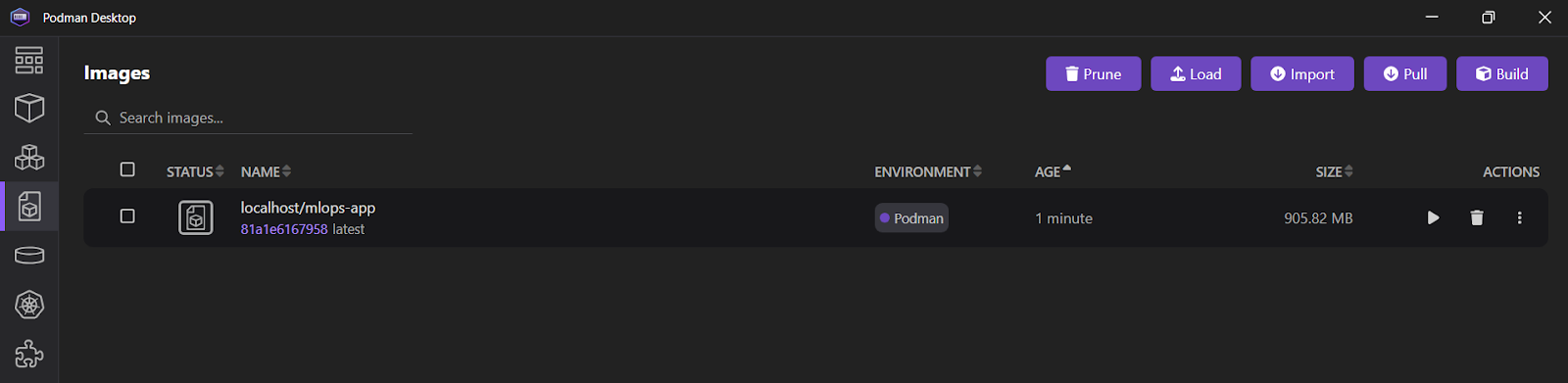
Schau dir die Docker für Datenwissenschaft Spickzettel, um alle relevanten Docker-Befehle zu lernen. Ersetze einfach den ersten Befehl, docker, durch podman.
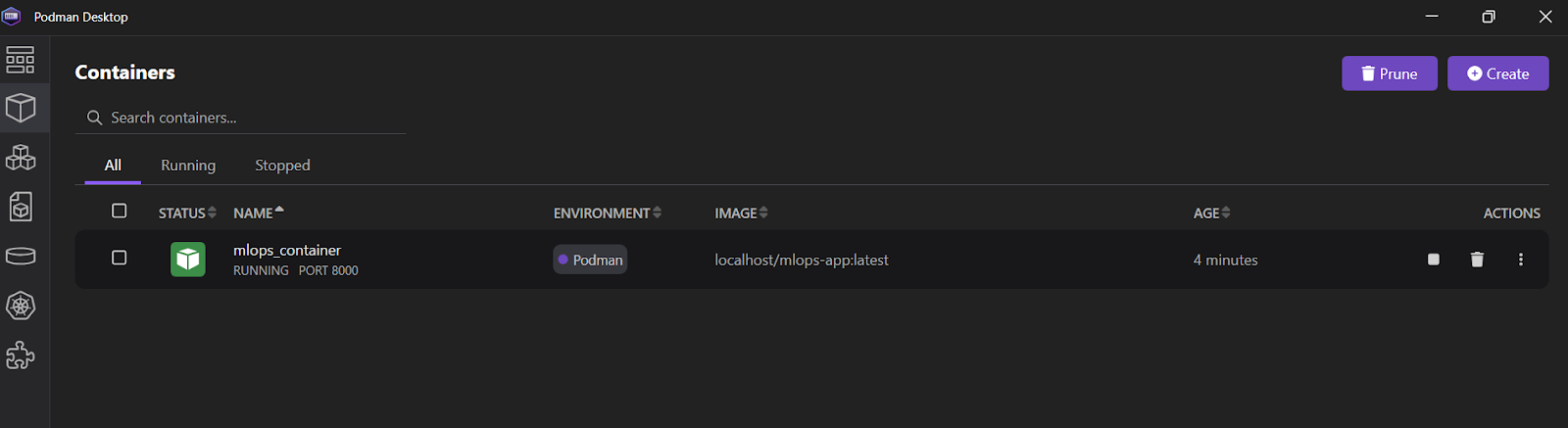
Wir verwenden den Befehl run, um einen Container namens "mlops_container" aus dem mlops-app Image zu starten. Dies geschieht im abgetrennten Modus (-d), wobei Port 8000 des Containers auf Port 8000 auf dem Host-Rechner abgebildet wird. Diese Einrichtung ermöglicht den Zugriff auf die FastAPI-Anwendung von außerhalb des Containers.
$ podman run -d --name mlops_container -p 8000:8000 mlops-app Um alle Logs für den "mlops_container" anzuzeigen, verwende den Befehl logs.
$ podman logs -f mlops_container Output:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
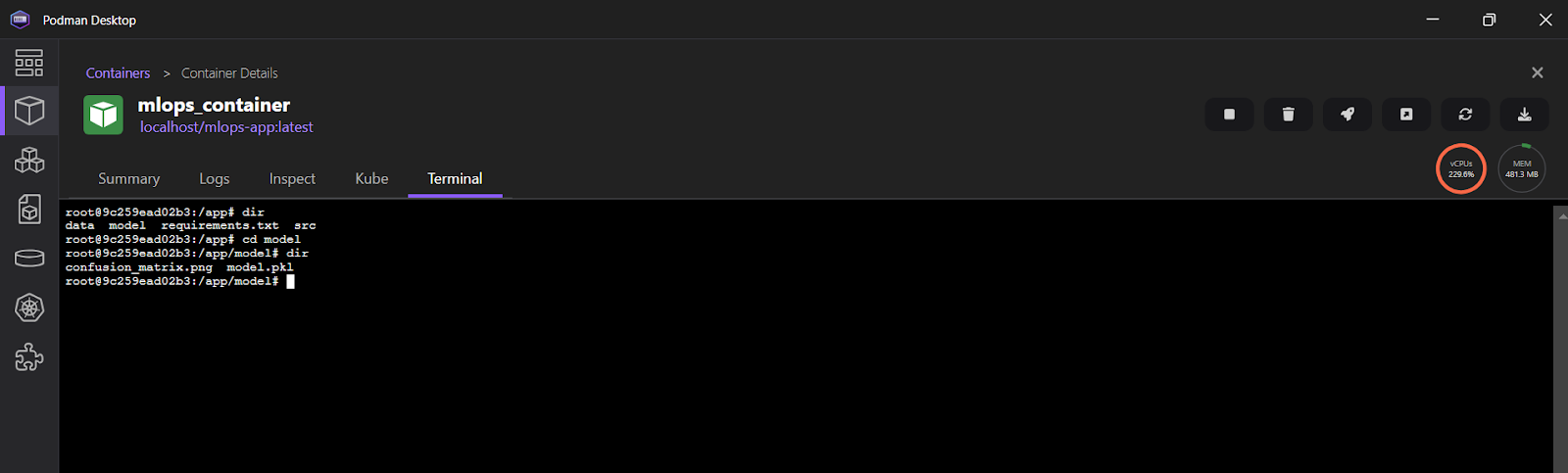
INFO: 10.88.0.1:36886 - "POST /predict HTTP/1.1" 200 OKDu kannst auch die Podman Desktop Anwendung öffnen und auf den Reiter "Container" klicken, um die laufenden Container zu sehen.
Um die Protokolle in der Podman Desktop Anwendung einzusehen, klicke auf "mlops_container" und wähle dann die Registerkarte "Terminal".
Wir werden nun die eingesetzte Anwendung testen, indem wir die interaktive Swagger-Benutzeroberfläche aufrufen: http://localhost:8000/docs. Die Swagger UI bietet eine benutzerfreundliche Oberfläche, mit der du alle verfügbaren API-Endpunkte erkunden kannst.
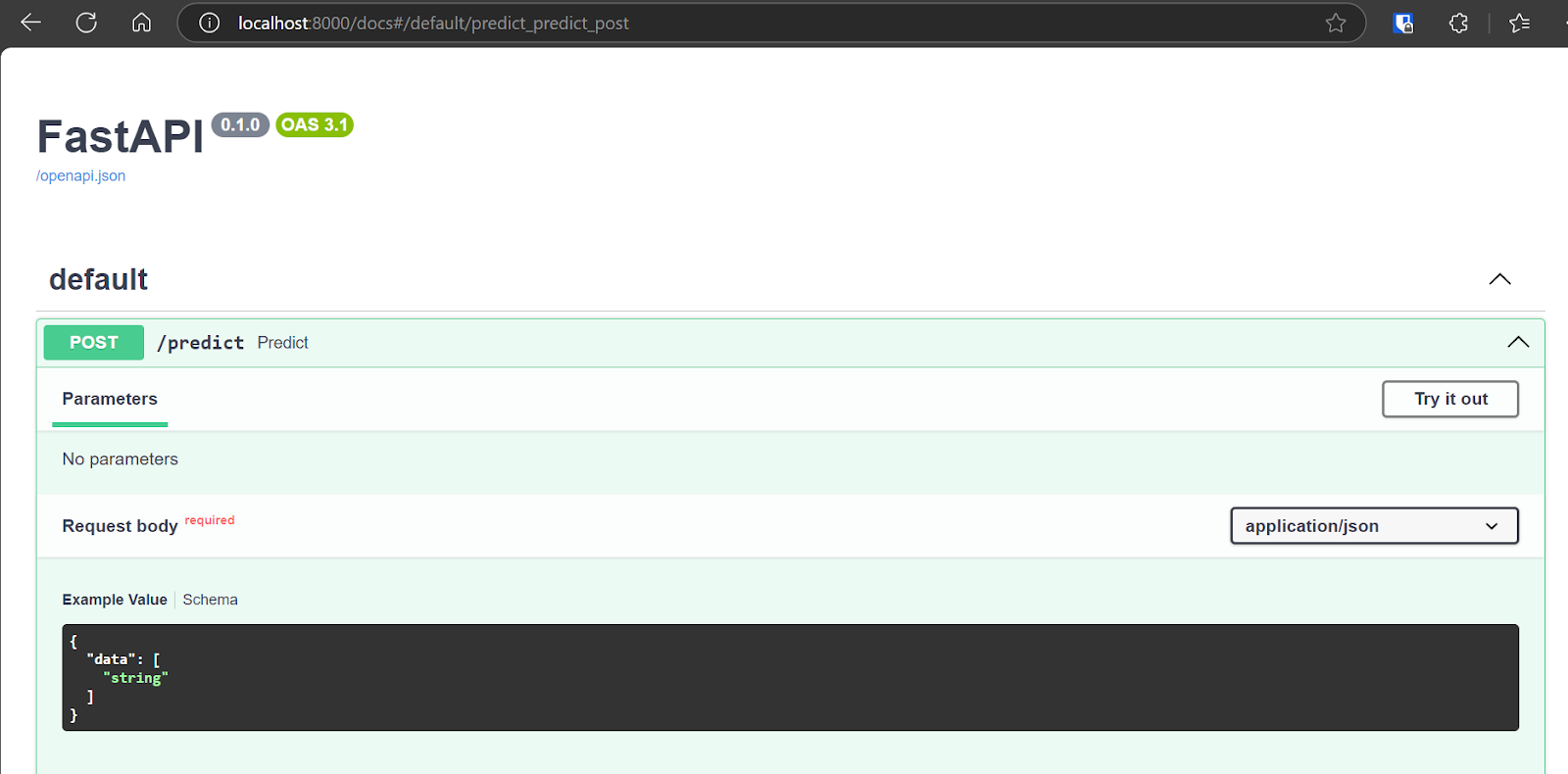
Wir können die API auch testen, indem wir den Befehl CURL im Terminal verwenden.
$ curl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"Age": 35,
"Occupation": "Engineer",
"Annual_Income": 85000,
"Monthly_Inhand_Salary": 7000,
"Num_Bank_Accounts": 2,
"Num_Credit_Card": 3,
"Interest_Rate": 5,
"Num_of_Loan": 1,
"Type_of_Loan": "Personal Loan",
"Delay_from_due_date": 2,
"Num_of_Delayed_Payment": 1,
"Changed_Credit_Limit": 15000,
"Num_Credit_Inquiries": 2,
"Credit_Mix": "Good",
"Outstanding_Debt": 10000,
"Credit_Utilization_Ratio": 30,
"Credit_History_Age": 15,
"Payment_of_Min_Amount": "Yes",
"Total_EMI_per_month": 500,
"Amount_invested_monthly": 1000,
"Payment_Behaviour": "Regular",
"Monthly_Balance": 5000
}
]
}'Der FastAPI-Server funktioniert einwandfrei, verarbeitet die Benutzereingaben erfolgreich und liefert eine genaue Vorhersage.
{"prediction":["Good"]}Nachdem wir mit der API experimentiert haben, werden wir den Container mit dem Befehl stop anhalten.
$ podman stop mlops_container Außerdem können wir den Container mit dem Befehl rm entfernen und so Systemressourcen freisetzen. Der Container muss erst angehalten werden, bevor er entfernt werden kann.
$ podman rm mlops_container Um das lokal gespeicherte Container-Image namens "mlops-app" zu entfernen, verwenden wir den Befehl rmi.
$ podman rmi mlops-app Wenn du Probleme hast, den obigen Code auszuführen oder deine eigene Docker-Datei zu erstellen, schau bitte im GitHub-Repository nach kingabzpro/mlops-with-podman. Sie enthält eine Bedienungsanleitung und alle notwendigen Dateien, damit du den Code auf deinem System ausführen kannst.
Der nächste Schritt auf deiner Lernreise ist der Versuch, ein 10 Ideen für Docker-Projektevon Anfängern bis zu Fortgeschrittenen, aber mit Podman. Dies wird dir helfen, das Podman-Ökosystem besser zu verstehen.
Podman bietet für bestimmte Anwendungsfälle eine überzeugende Alternative zu Docker, doch viele Entwickler bevorzugen weiterhin Docker Desktop und CLI. Diese Vorliebe ist vor allem auf die umfangreichen Integrationen und benutzerfreundlichen Tools von Docker zurückzuführen.
Für ein einfaches MLOps-Projekt könnten sich Ingenieure jedoch für Podman entscheiden, das im Vergleich zu Docker Desktop eine schlanke und einfache Einrichtung bietet.
In diesem Tutorial lernen wir Podman, ein beliebtes Container-Management-Tool, kennen. Wir vergleichen es mit Docker und zeigen, wie man Podman Desktop installiert. Außerdem führen wir dich durch ein MLOps-Projekt mit Podman, das die Erstellung eines Dockerfiles, die Erstellung eines Images und die Ausführung eines Containers umfasst. Der Einstieg in Podman ist ganz einfach, und wenn du bereits mit Docker vertraut bist, wirst du den nahtlosen Übergang zu schätzen wissen.
Nimm die MLOps-Bereitstellung und Lebenszyklus den Kurs, um das moderne MLOps-Framework zu erkunden und den Lebenszyklus und Einsatz von Machine Learning-Modellen zu erforschen.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
