
programa
Contenedores y virtualización con Docker y Kubernetes
13 h
Todo desarrollador e ingeniero de operaciones en el campo de las TI está familiarizado con Docker para crear y desplegar aplicaciones, ya sea localmente o en la nube. Sin embargo, como desarrollador o ingeniero de operaciones de aprendizaje automático, puedes estar buscando optimizar recursos, aumentar la seguridad y mejorar la integración del sistema. Podman ofrece una alternativa convincente. Es una herramienta gratuita y de código abierto que sirve como alternativa a Docker y Docker Desktop.
En este tutorial, exploraremos qué es Podman, las diferencias entre Podman y Docker, y cómo instalar y utilizar Podman. Además, cubriremos cómo entrenar, evaluar y desplegar modelos de aprendizaje automático localmente utilizando comandos Dockerfile y Podman.

Imagen del autor
Podman es una herramienta de gestión de contenedores de código abierto diseñada para proporcionar a los desarrolladores e ingenieros de aprendizaje automático una experiencia fluida y segura. A diferencia de Docker, Podman funciona sin demonio, lo que mejora la seguridad y la flexibilidad al permitir a los usuarios ejecutar contenedores como procesos sin raíz. Esta característica clave permite a Podman ejecutar contenedores sin necesidad de privilegios de root, minimizando así posibles vulnerabilidades.
Podman es totalmente compatible con los estándares OCI (Open Container Initiative), lo que garantiza que los contenedores e imágenes creados con Podman puedan integrarse fácilmente con otras herramientas y plataformas compatibles con OCI, como runc, Buildah y Skopeo. Además, Podman admite la creación y gestión de pods, que son grupos de contenedores que comparten el mismo espacio de nombres de red, de forma similar a los pods de Kubernetes.
Uno de los mejores aspectos de utilizar Podman es que ofrece una experiencia similar a Docker. La interfaz de línea de comandos es comparable a la de Docker, y también puedes extraer imágenes de Docker Hub. Esta similitud permite una transición fácil para quienes están familiarizados con Docker, al tiempo que proporciona funciones avanzadas que satisfacen las necesidades cambiantes del desarrollo y despliegue de aplicaciones en contenedores.
Podman es sólo una herramienta del arsenal de MLOps. Conoce todos los tipos de herramientas utilizadas en el ecosistema de MLOps leyendo el blog 25 Herramientas MLOps que debes conocer en 2025.
Docker y Podman son herramientas destacadas de gestión de contenedores, cada una de las cuales ofrece características y capacidades distintas. Esta comparación examinará sus diferencias y te ayudará a decidir cuál se ajusta mejor a tus necesidades.
|
Docker |
Podman |
|
|
Arquitectura |
Docker utiliza una arquitectura cliente-servidor con un proceso demonio llamado dockerd. |
Podman no tiene demonio, y utiliza un modelo de ejecución fork, que mejora la seguridad y la simplicidad. |
|
Seguridad |
Docker ejecuta los contenedores como root por defecto, lo que puede plantear riesgos de seguridad. |
Podman admite contenedores sin raíz por defecto, lo que reduce los riesgos de seguridad. |
|
Gestión de imágenes |
Docker puede construir y gestionar imágenes de contenedores utilizando sus propias herramientas. |
Podman se basa en Buildah para construir imágenes y puede ejecutar imágenes desde registros Docker. |
|
Compatibilidad |
Docker se utiliza ampliamente y se integra con muchas herramientas CI/CD. |
Podman ofrece una CLI compatible con Docker, lo que facilita a los usuarios el cambio sin modificar los flujos de trabajo. |
|
Orquestación de contenedores |
Docker admite Docker Swarm y Kubernetes para la orquestación. |
Podman no es compatible con Docker Swarm, pero puede trabajar con Kubernetes utilizando pods. |
|
Plataforma de apoyo |
Docker funciona de forma nativa en Linux, macOS y Windows (con WSL). |
Podman también es compatible con Linux, macOS y Windows (con WSL). |
|
Rendimiento |
Docker es conocido por su eficaz gestión de recursos y su rápido despliegue. |
Podman es generalmente comparable en rendimiento y ofrece tiempos de arranque más rápidos. |
|
Casos prácticos |
Docker es ideal para proyectos que requieren herramientas e integraciones bien establecidas. |
Podman es adecuado para entornos que priorizan la seguridad y las operaciones ligeras. Ideal para despliegues a gran escala. |
La elección entre Docker y Podman depende en gran medida de los requisitos específicos del proyecto, especialmente en lo que respecta a las necesidades de seguridad, compatibilidad y orquestación.
Docker sigue siendo una opción sólida para las canalizaciones CI/CD establecidas y la gestión integral de contenedores, mientras que Podman ofrece una alternativa segura y ligera para los entornos que priorizan la seguridad y las operaciones sin raíces. También ofrece tiempos de arranque más rápidos, lo que es ideal para implantaciones a gran escala.
Descubre Docker para la Ciencia de Datos leyendo nuestro artículo introductorio, que incluye código de muestra y ejemplos.
En primer lugar, deberás descargar e instalar el paquete Podman Desktop accediendo al sitio web oficial.
Fuente: Podman
La instalación es sencilla y rápida. En unos minutos, estarás en la pantalla de inicio, donde se te pedirá que instales extensiones opcionales.
Si no tienes WSL en Windows, se instalará automáticamente.
A continuación, configura la máquina Podman.
En comparación con Docker, no necesitas configurar una máquina. Sin embargo, en Podman, puedes gestionar varias máquinas manejando diferentes contenedores simultáneamente, lo que permite una mejor gestión de los recursos.
Nuestra máquina está en funcionamiento, lista para crear imágenes y ejecutar los contenedores.
Para comprobar que Podman funciona correctamente, sacaremos una imagen de muestra de quay.io y ejecutaremos el contenedor.
$ podman run quay.io/podman/helloLa máquina Podman ha extraído correctamente la imagen y ha ejecutado el contenedor, mostrando los registros.
Trying to pull quay.io/podman/hello:latest...
Getting image source signatures
Copying blob sha256:81df7ff16254ed9756e27c8de9ceb02a9568228fccadbf080f41cc5eb5118a44
Copying config sha256:5dd467fce50b56951185da365b5feee75409968cbab5767b9b59e325fb2ecbc0
Writing manifest to image destination
!... Hello Podman World ...!
.--"--.
/ - - \
/ (O) (O) \
~~~| -=(,Y,)=- |
.---. /` \ |~~
~/ o o \~~~~.----. ~~
| =(X)= |~ / (O (O) \
~~~~~~~ ~| =(Y_)=- |
~~~~ ~~~| U |~~
Project: https://github.com/containers/podman
Website: https://podman.io
Desktop: https://podman-desktop.io
Documents: https://docs.podman.io
YouTube: https://youtube.com/@Podman
X/Twitter: @Podman_io
Mastodon: @Podman_io@fosstodon.orgEn este proyecto MLOps, automatizaremos el entrenamiento y la evaluación del modelo y lo serviremos utilizando Dockerfile y Podman. Esto será similar a Docker, pero en su lugar, utilizaremos la CLI Podman para construir imágenes y luego ejecutar el contenedor.
Si eres nuevo en los conceptos, puedes aprender los fundamentos de los MLOPs completando el curso Conceptos MLOP de MLOPS.
Para configurar el proyecto de aprendizaje automático, necesitamos crear un script de entrenamiento y de servicio, así como un archivo requirements.txt para instalar los paquetes de Python.
El script Python de entrenamiento cargará la clasificación de la puntuación crediticia procesarlo, codificarlo y entrenar el modelo. También realizaremos la evaluación del modelo. Al final, guardaremos la tubería de preprocesamiento y entrenamiento junto con el modelo utilizando el formato pickle.
src/train.py:
# src/train.py
import os
import pickle
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
roc_auc_score,
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
def load_data():
data_path = "data/train.csv"
df = pd.read_csv(data_path,low_memory=False)
print("Data loaded successfully!")
return df
def preprocess_data(df):
# Drop unnecessary columns
df = df.drop(columns=["ID", "Customer_ID", "SSN", "Name", "Month"])
# Drop rows with missing values
df = df.dropna()
# Convert data types
# Convert the 'Age' column to numeric, setting errors='coerce' to handle non-numeric values
df["Age"] = pd.to_numeric(df["Age"], errors="coerce")
# Filter the DataFrame to include only rows where 'Age' is between 1 and 60
df = df[(df["Age"] >= 1) & (df["Age"] <= 60)]
df["Annual_Income"] = pd.to_numeric(df["Annual_Income"], errors="coerce")
df["Monthly_Inhand_Salary"] = pd.to_numeric(
df["Monthly_Inhand_Salary"], errors="coerce"
)
# Separate features and target
X = df.drop("Credit_Score", axis=1)
y = df["Credit_Score"]
print("Data preprocessed successfully!")
return X, y
def encode_data(X):
# Identify categorical and numerical features
categorical_features = [
"Occupation",
"Credit_Mix",
"Payment_of_Min_Amount",
"Payment_Behaviour",
"Type_of_Loan",
]
numerical_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# Define preprocessing steps
numerical_transformer = SimpleImputer(strategy="median")
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numerical_transformer, numerical_features),
("cat", categorical_transformer, categorical_features),
]
)
return preprocessor
def split_data(X, y):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def train_model(X_train, y_train, preprocessor):
# Create a pipeline with preprocessing and model
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", RandomForestClassifier(n_estimators=100)),
]
)
# Train the model
clf.fit(X_train, y_train)
# Return the trained model
return clf
def evaluate_model(clf, X_test, y_test):
# Predict and evaluate
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, labels=["Poor", "Standard", "Good"])
cm = confusion_matrix(y_test, y_pred, labels=["Poor", "Standard", "Good"])
# Calculate AUC score
y_test_encoded = y_test.replace({"Poor": 0, "Standard": 1, "Good": 2})
y_pred_proba = clf.predict_proba(X_test)
auc_score = roc_auc_score(y_test_encoded, y_pred_proba, multi_class="ovr")
# Print metrics
print("Model Evaluation Metrics:")
print(f"Accuracy: {acc}")
print(f"AUC Score: {auc_score}")
print("Classification Report:")
print(report)
# Plot confusion matrix
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation="nearest", cmap=plt.cm.Blues)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(3)
plt.xticks(tick_marks, ["Poor", "Standard", "Good"], rotation=45)
plt.yticks(tick_marks, ["Poor", "Standard", "Good"])
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
cm_path = os.path.join("model", "confusion_matrix.png")
plt.savefig(cm_path)
print(f"Confusion matrix saved to {cm_path}")
def save_model(clf):
model_dir = "model"
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, "model.pkl")
# Save the trained model
with open(model_path, "wb") as f:
pickle.dump(clf, f)
print(f"Model saved to {model_path}")
def main():
# Execute steps
df = load_data()
X, y = preprocess_data(df)
preprocessor = encode_data(X)
X_train, X_test, y_train, y_test = split_data(X, y)
clf = train_model(X_train, y_train, preprocessor)
evaluate_model(clf, X_test, y_test)
save_model(clf)
if __name__ == "__main__":
main()
El script de servicio del modelo cargará la canalización del modelo guardado utilizando el archivo del modelo, creará una función de solicitud POST que tome una lista de diccionarios del usuario, la convierta en un DataFrame, se la proporcione al modelo para generar predicciones y, a continuación, devuelva la etiqueta predicha. Estamos utilizando FastAPI como nuestro marco API, lo que nos permite servir el modelo con sólo unas pocas líneas de código.
src/app.py:
# src/app.py
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import os
# Load the trained model
model_path = os.path.join("model", "model.pkl")
with open(model_path, "rb") as f:
model = pickle.load(f)
app = FastAPI()
class InputData(BaseModel):
data: list # List of dictionaries representing feature values
@app.post("/predict")
def predict(input_data: InputData):
# Convert input data to DataFrame
X_new = pd.DataFrame(input_data.data)
# Ensure the columns match the training data
prediction = model.predict(X_new)
# Return predictions
return {"prediction": prediction.tolist()}
Necesitamos crear un archivo requirements.txt que incluya todos los paquetes Python necesarios para ejecutar los scripts mencionados anteriormente. Este archivo se utilizará para configurar un entorno de ejecución en el contenedor Docker, garantizando que podamos ejecutar los scripts de Python sin problemas.
requisitos.txt:
fastapi
uvicorn[standard]
numpy
pandas
scikit-learn
pydantic
matplotlibCrea un "Dockerfile" y añade el siguiente código.
Estos son los pasos que realiza este Dockerfile:
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY ./src/ ./src/
COPY ./data/ ./data/
# Ensure the model directory exists and is copied
RUN mkdir -p model
# Run the training script during the build
RUN python src/train.py
# Expose the port for the API
EXPOSE 8000
# Run the FastAPI app
CMD ["uvicorn", "src.app:app", "--host", "0.0.0.0", "--port", "8000"]Tu espacio de trabajo local debe estar organizado como sigue:
data que contenga todos los archivos CSVmodels src que contiene scripts de Pythonrequirements.txt y un archivo DockerfileLos archivos restantes son componentes adicionales para la automatización y las operaciones Git.
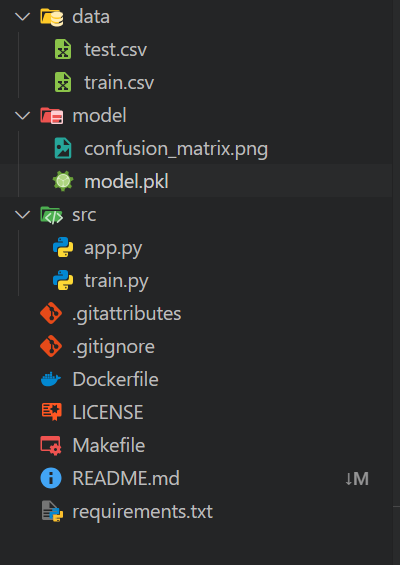
Construir la imagen Docker es sencillo: Sólo tienes que proporcionar al comando build el nombre de tu imagen Docker y el directorio actual donde se encuentra el archivo Dockerfile.
$ podman build -t mlops_app .La herramienta de compilación ejecutará todos los comandos del archivo Docker de forma secuencial, desde la configuración del entorno hasta el servicio de la aplicación de aprendizaje automático.
También podemos ver que los registros contienen los resultados de la evaluación del modelo. El modelo tiene una precisión del 75% y una puntuación ROC AUC de 0,89, que se considera media.
STEP 1/11: FROM python:3.9-slim
STEP 2/11: WORKDIR /app
--> Using cache 72ac9e49ae29da1ff19e118653efca17e7a489ae9e7ead917c83d942a3ea4e13
--> 72ac9e49ae29
STEP 3/11: COPY requirements.txt .
--> Using cache 3a05ca95caaf98c448c53a796714328bf9f7cff7896cce348f84a26b8d0dae61
--> 3a05ca95caaf
STEP 4/11: RUN pip install --no-cache-dir -r requirements.txt
--> Using cache 28109d1183449396a5df0006ab603dd5cf2aa2c06a810bdc6bcf0f843f855ee0
--> 28109d118344
STEP 5/11: COPY ./src/ ./src/
--> f814f699c58a
STEP 6/11: COPY ./data/ ./data/
--> 922550900cd0
STEP 7/11: RUN mkdir -p model
--> 36fc01f2d169
STEP 8/11: RUN python src/train.py
Data loaded successfully!
Data preprocessed successfully!
Data encoded successfully!
Data split successfully!
Model trained successfully!
Model Evaluation Metrics:
Accuracy: 0.7546181417149159
ROC AUC Score: 0.8897184704689612
Classification Report:
precision recall f1-score support
Good 0.71 0.67 0.69 1769
Poor 0.75 0.76 0.75 3403
Standard 0.77 0.78 0.78 5709
accuracy 0.75 10881
macro avg 0.74 0.74 0.74 10881
weighted avg 0.75 0.75 0.75 10881
Model saved to model/model.pkl
--> 5d4777c08580
STEP 9/11: EXPOSE 8000
--> 7bb09a613e7f
STEP 10/11: WORKDIR /app/src
--> 06b6394c2e2d
STEP 11/11: CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
COMMIT mlops-app
--> 9a7a42b03664
Successfully tagged localhost/mlops-app:latest
9a7a42b03664f1e4631330cd682cb2de26e513c5d776fa2ce2042b3bb9455e14Si abres la aplicación Podman Desktop y haces clic en la pestaña "Imágenes", verás quetu imagen mlops_app se ha creado correctamente.
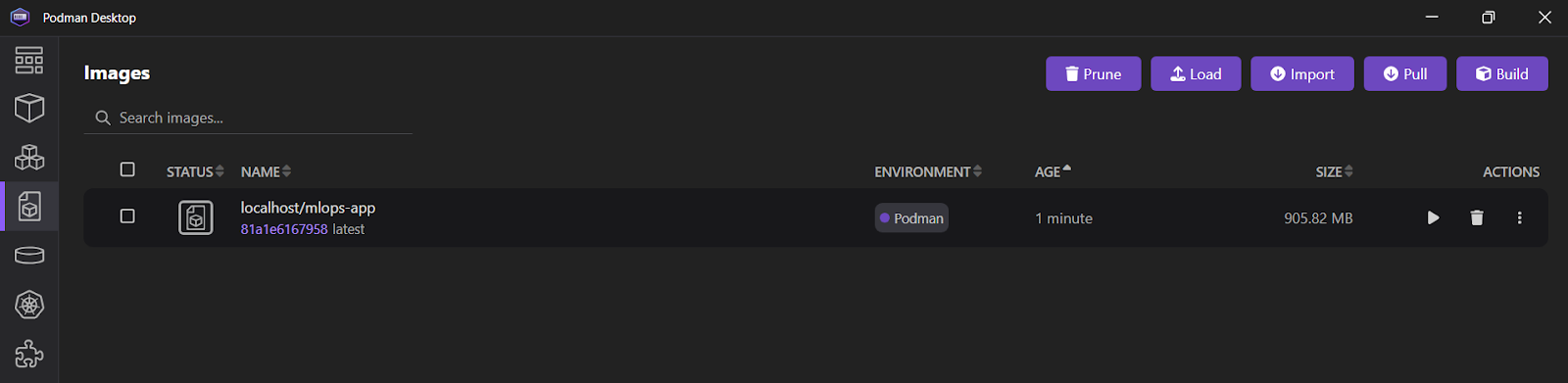
Echa un vistazo a Docker para la Ciencia de Datos para aprender todos los comandos Docker relevantes. Sólo tienes que sustituir el primer comando, docker, por podman.
Utilizaremos el comando run para iniciar un contenedor llamado "mlops_container" desde la imagen mlops-app. Esto se hará en modo separado (-d), asignando el puerto 8000 del contenedor al puerto 8000 de la máquina anfitriona. Esta configuración permitirá acceder a la aplicación FastAPI desde fuera del contenedor.
$ podman run -d --name mlops_container -p 8000:8000 mlops-app Para ver todos los registros del "mlops_container", utiliza el comando logs.
$ podman logs -f mlops_container Salida:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
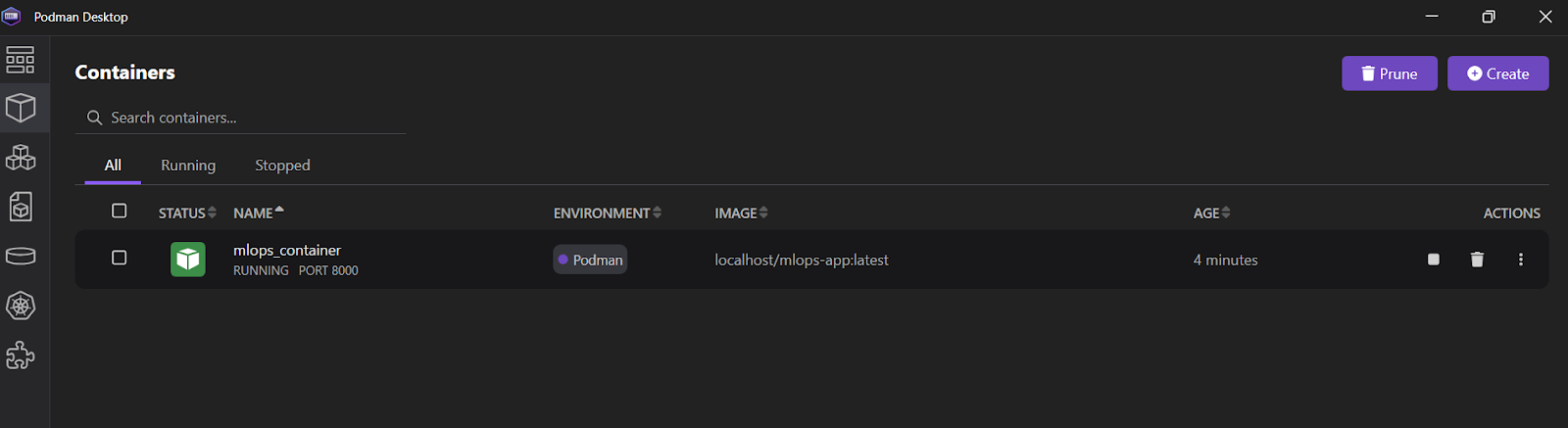
INFO: 10.88.0.1:36886 - "POST /predict HTTP/1.1" 200 OKTambién puedes abrir la aplicación Podman Desktop y hacer clic en la pestaña "Contenedores" para ver los contenedores en ejecución.
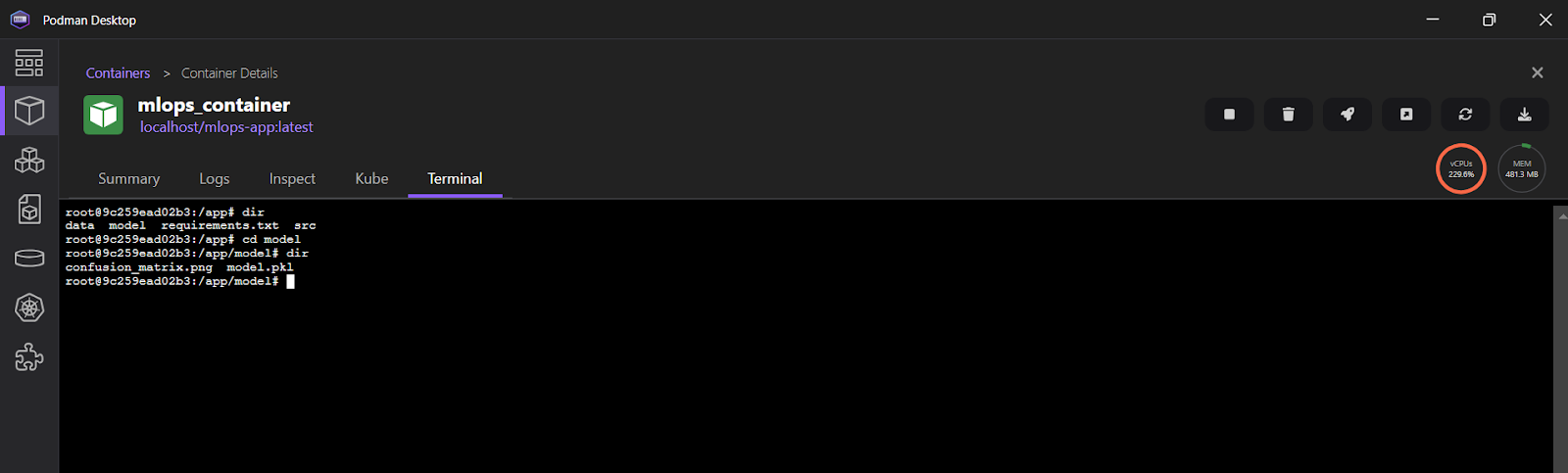
Para ver los registros en la aplicación Podman Desktop, haz clic en "mlops_container" y luego selecciona la pestaña "Terminal".
Ahora probaremos la aplicación desplegada accediendo a la interfaz de usuario Swagger interactiva en: http://localhost:8000/docs. La Swagger UI ofrece una interfaz fácil de usar que te permite explorar todos los puntos finales de API disponibles.
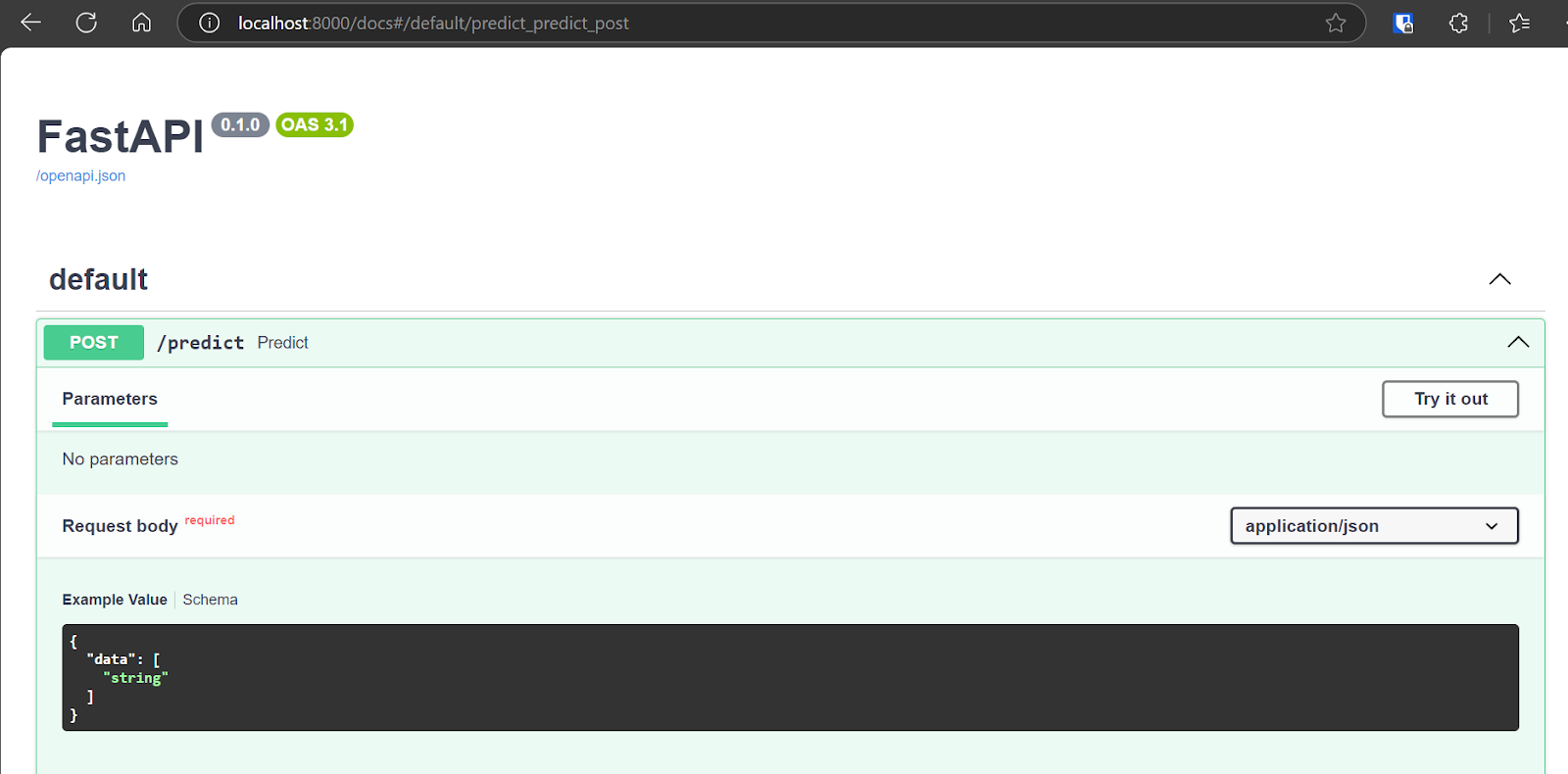
También podemos probar la API utilizando el comando CURL en el terminal.
$ curl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"Age": 35,
"Occupation": "Engineer",
"Annual_Income": 85000,
"Monthly_Inhand_Salary": 7000,
"Num_Bank_Accounts": 2,
"Num_Credit_Card": 3,
"Interest_Rate": 5,
"Num_of_Loan": 1,
"Type_of_Loan": "Personal Loan",
"Delay_from_due_date": 2,
"Num_of_Delayed_Payment": 1,
"Changed_Credit_Limit": 15000,
"Num_Credit_Inquiries": 2,
"Credit_Mix": "Good",
"Outstanding_Debt": 10000,
"Credit_Utilization_Ratio": 30,
"Credit_History_Age": 15,
"Payment_of_Min_Amount": "Yes",
"Total_EMI_per_month": 500,
"Amount_invested_monthly": 1000,
"Payment_Behaviour": "Regular",
"Monthly_Balance": 5000
}
]
}'El servidor FastAPI funciona correctamente, procesa con éxito la entrada del usuario y devuelve una predicción precisa.
{"prediction":["Good"]}Después de experimentar con la API, detendremos el contenedor utilizando el comando stop.
$ podman stop mlops_container Además, podemos eliminar el contenedor utilizando el comando rm, liberando recursos del sistema. Primero hay que parar el contenedor antes de retirarlo.
$ podman rm mlops_container Para eliminar la imagen contenedor almacenada localmente llamada "mlops-app" utilizaremos el comando rmi.
$ podman rmi mlops-app Si tienes problemas para ejecutar el código anterior o para crear tu propio archivo Docker, consulta el repositorio de GitHub kingabzpro/mlops-con-podman. Incluye una guía de uso y todos los archivos necesarios para que ejecutes el código en tu sistema.
El siguiente paso en tu viaje de aprendizaje es intentar construir 10 ideas de proyectos Dockerdesde principiantes hasta avanzados, pero con Podman. Esto te ayudará a comprender mejor el ecosistema Podman.
Podman ofrece una alternativa convincente a Docker para determinados casos de uso, aunque muchos desarrolladores siguen prefiriendo Docker Desktop y CLI. Esta preferencia se debe en gran medida a las amplias integraciones de Docker y a sus herramientas fáciles de usar.
Sin embargo, para un proyecto MLOps sencillo, los ingenieros podrían optar por Podman, que proporciona una configuración ligera y fácil en comparación con Docker Desktop.
En este tutorial, exploramos Podman, una popular herramienta de gestión de contenedores, comparándola con Docker y demostrando cómo instalar Podman Desktop. También te guiaremos a través de un proyecto MLOps utilizando Podman, cubriendo la creación de un Dockerfile, la construcción de una imagen y la ejecución de un contenedor. Empezar a utilizar Podman es sencillo, y si ya estás familiarizado con Docker, apreciarás la transición fluida.
Toma el Despliegue y ciclo de vida de MLOps para explorar el moderno marco MLOps, explorando el ciclo de vida y el despliegue de los modelos de aprendizaje automático.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Kurtis Pykes
8 min
blog
Natassha Selvaraj
15 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev


