
Cursus
Conteneurisation et virtualisation avec Docker et Kubernetes
13 h
Tous les développeurs et ingénieurs d'exploitation dans le domaine de l'informatique connaissent Docker pour la création et le déploiement d'applications, que ce soit en local ou dans le cloud. Cependant, en tant que développeur ou ingénieur opérationnel en apprentissage automatique, vous pouvez chercher à optimiser les ressources, à renforcer la sécurité et à améliorer l'intégration des systèmes. Podman offre une alternative convaincante. Il s'agit d'un outil gratuit et open-source qui constitue une alternative à Docker et Docker Desktop.
Dans ce tutoriel, nous verrons ce qu'est Podman, les différences entre Podman et Docker, et comment installer et utiliser Podman. En outre, nous verrons comment entraîner, évaluer et déployer localement des modèles d'apprentissage automatique à l'aide des commandes Dockerfile et Podman.

Image par l'auteur
Podman est un outil de gestion de conteneurs open-source conçu pour offrir aux développeurs et aux ingénieurs en apprentissage automatique une expérience transparente et sécurisée. Contrairement à Docker, Podman fonctionne sans démon, ce qui renforce la sécurité et la flexibilité en permettant aux utilisateurs d'exécuter des conteneurs en tant que processus sans racine. Cette fonctionnalité clé permet à Podman d'exécuter des conteneurs sans nécessiter de privilèges root, minimisant ainsi les vulnérabilités potentielles.
Podman est entièrement compatible avec les normes de l'OCI (Open Container Initiative), ce qui garantit que les conteneurs et les images créés avec Podman peuvent être facilement intégrés à d'autres outils et plateformes conformes à l'OCI, tels que runc, Buildah et Skopeo. En outre, Podman prend en charge la création et la gestion de pods, qui sont des groupes de conteneurs partageant le même espace de noms réseau, à l'instar des pods Kubernetes.
L'un des meilleurs aspects de l'utilisation de Podman est qu'il offre une expérience similaire à celle de Docker. L'interface en ligne de commande est comparable à celle de Docker, et vous pouvez également extraire des images de Docker Hub. Cette similitude permet une transition facile pour ceux qui sont familiers avec Docker tout en offrant des fonctionnalités avancées qui répondent aux besoins évolutifs du développement et du déploiement d'applications conteneurisées.
Podman n'est qu'un outil parmi d'autres dans l'arsenal des MLOps. Découvrez tous les types d'outils utilisés dans l'écosystème MLOps en lisant le blog 25 Top MLOps Tools You Need to Know in 2025 (en anglais).
Docker et Podman sont des outils de gestion de conteneurs de premier plan, chacun offrant des caractéristiques et des capacités distinctes. Cette comparaison examinera leurs différences et vous aidera à choisir celui qui répond le mieux à vos besoins.
|
Docker |
Podman |
|
|
L'architecture |
Docker utilise une architecture client-serveur avec un processus démon appelé dockerd. |
Podman n'a pas de démon et utilise un modèle d'exécution à fourche, ce qui renforce la sécurité et la simplicité. |
|
Sécurité |
Docker exécute les conteneurs en tant que root par défaut, ce qui peut poser des risques de sécurité. |
Podman prend en charge par défaut les conteneurs sans racine, ce qui réduit les risques de sécurité. |
|
Gestion des images |
Docker peut construire et gérer des images de conteneurs à l'aide de ses propres outils. |
Podman s'appuie sur Buildah pour construire des images et peut exécuter des images à partir des registres Docker. |
|
Compatibilité |
Docker est largement utilisé et intégré à de nombreux outils CI/CD. |
Podman offre un CLI compatible avec Docker, ce qui permet aux utilisateurs de passer plus facilement d'un système à l'autre sans modifier les flux de travail. |
|
Orchestration de conteneurs |
Docker prend en charge Docker Swarm et Kubernetes pour l'orchestration. |
Podman ne prend pas en charge Docker Swarm mais peut fonctionner avec Kubernetes à l'aide de pods. |
|
Soutien à la plate-forme |
Docker fonctionne nativement sur Linux, macOS et Windows (avec WSL). |
Podman est également compatible avec Linux, macOS et Windows (avec WSL). |
|
Performance |
Docker est connu pour sa gestion efficace des ressources et son déploiement rapide. |
Podman est généralement comparable en termes de performances et offre des temps de démarrage plus rapides. |
|
Cas d'utilisation |
Docker est idéal pour les projets nécessitant des outils et des intégrations bien établis. |
Podman convient aux environnements qui privilégient la sécurité et les opérations légères. Idéal pour les déploiements à grande échelle. |
Le choix entre Docker et Podman dépend en grande partie des exigences spécifiques du projet, notamment en matière de sécurité, de compatibilité et d'orchestration.
Docker reste un choix solide pour les pipelines CI/CD établis et la gestion complète des conteneurs, tandis que Podman offre une alternative sécurisée et légère pour les environnements privilégiant la sécurité et les opérations sans racine. Il offre également des temps de démarrage plus rapides, ce qui est idéal pour les déploiements à grande échelle.
Découvrez Docker pour la science des données en lisant notre article d'introduction, qui comprend des exemples de code et des exemples.
Tout d'abord, vous devez télécharger et installer le paquetage de Podman Desktop en allant sur le site officiel.
Source : Podman
L'installation est simple et rapide. En quelques minutes, vous serez sur l'écran de démarrage, où il vous sera demandé d'installer des extensions optionnelles.
Si vous n'avez pas WSL dans Windows, il installera automatiquement WSL.
Ensuite, configurez la machine Podman.
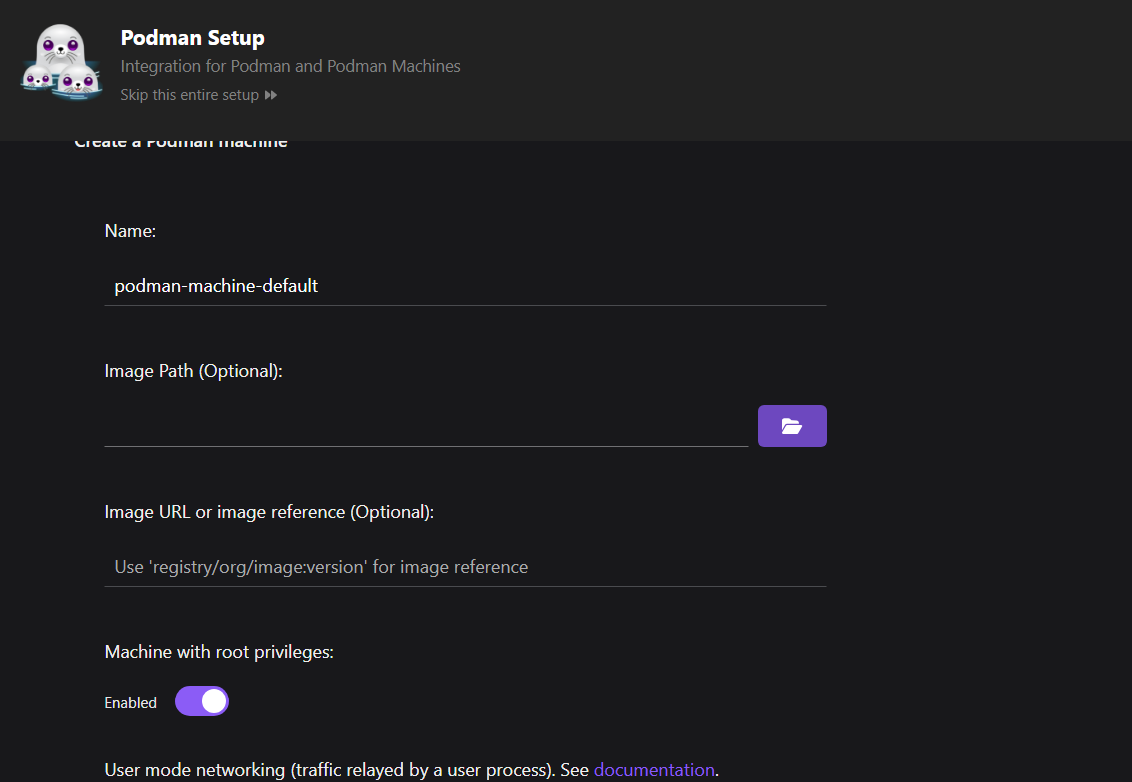
Par rapport à Docker, vous n'avez pas besoin de configurer une machine. Cependant, dans Podman, vous pouvez gérer simultanément plusieurs machines manipulant différents conteneurs, ce qui permet une meilleure gestion des ressources.
Notre machine est opérationnelle, prête à créer des images et à exécuter les conteneurs.
Pour vérifier que Podman fonctionne correctement, nous allons extraire une image d'exemple de quay.io et exécuter le conteneur.
$ podman run quay.io/podman/helloLa machine Podman a réussi à extraire l'image et à exécuter le conteneur, en affichant les journaux.
Trying to pull quay.io/podman/hello:latest...
Getting image source signatures
Copying blob sha256:81df7ff16254ed9756e27c8de9ceb02a9568228fccadbf080f41cc5eb5118a44
Copying config sha256:5dd467fce50b56951185da365b5feee75409968cbab5767b9b59e325fb2ecbc0
Writing manifest to image destination
!... Hello Podman World ...!
.--"--.
/ - - \
/ (O) (O) \
~~~| -=(,Y,)=- |
.---. /` \ |~~
~/ o o \~~~~.----. ~~
| =(X)= |~ / (O (O) \
~~~~~~~ ~| =(Y_)=- |
~~~~ ~~~| U |~~
Project: https://github.com/containers/podman
Website: https://podman.io
Desktop: https://podman-desktop.io
Documents: https://docs.podman.io
YouTube: https://youtube.com/@Podman
X/Twitter: @Podman_io
Mastodon: @Podman_io@fosstodon.orgDans ce projet MLOps, nous allons automatiser l'entraînement et l'évaluation du modèle et servir le modèle à l'aide de Dockerfile et Podman. Le fonctionnement est similaire à celui de Docker, mais nous utiliserons l'interface de programmation Podman pour créer des images et exécuter le conteneur.
Si vous ne connaissez pas encore les concepts, vous pouvez apprendre les principes fondamentaux des MLOPs en complétant le formulaire suivant Concepts MLOps en suivant le cours MLOps Concepts.
Pour mettre en place le projet d'apprentissage automatique, nous devons créer un script d'entraînement et de service, ainsi qu'un fichier requirements.txt pour l'installation des paquets Python.
Le script Python de formation chargera les données suivantes classification des scores de crédit le traitera, l'encodera et entraînera le modèle. Nous procéderons également à l'évaluation du modèle. Enfin, nous enregistrerons le pipeline de prétraitement et d'entraînement ainsi que le modèle au format pickle.
src/train.py :
# src/train.py
import os
import pickle
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
roc_auc_score,
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
def load_data():
data_path = "data/train.csv"
df = pd.read_csv(data_path,low_memory=False)
print("Data loaded successfully!")
return df
def preprocess_data(df):
# Drop unnecessary columns
df = df.drop(columns=["ID", "Customer_ID", "SSN", "Name", "Month"])
# Drop rows with missing values
df = df.dropna()
# Convert data types
# Convert the 'Age' column to numeric, setting errors='coerce' to handle non-numeric values
df["Age"] = pd.to_numeric(df["Age"], errors="coerce")
# Filter the DataFrame to include only rows where 'Age' is between 1 and 60
df = df[(df["Age"] >= 1) & (df["Age"] <= 60)]
df["Annual_Income"] = pd.to_numeric(df["Annual_Income"], errors="coerce")
df["Monthly_Inhand_Salary"] = pd.to_numeric(
df["Monthly_Inhand_Salary"], errors="coerce"
)
# Separate features and target
X = df.drop("Credit_Score", axis=1)
y = df["Credit_Score"]
print("Data preprocessed successfully!")
return X, y
def encode_data(X):
# Identify categorical and numerical features
categorical_features = [
"Occupation",
"Credit_Mix",
"Payment_of_Min_Amount",
"Payment_Behaviour",
"Type_of_Loan",
]
numerical_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# Define preprocessing steps
numerical_transformer = SimpleImputer(strategy="median")
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numerical_transformer, numerical_features),
("cat", categorical_transformer, categorical_features),
]
)
return preprocessor
def split_data(X, y):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def train_model(X_train, y_train, preprocessor):
# Create a pipeline with preprocessing and model
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", RandomForestClassifier(n_estimators=100)),
]
)
# Train the model
clf.fit(X_train, y_train)
# Return the trained model
return clf
def evaluate_model(clf, X_test, y_test):
# Predict and evaluate
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, labels=["Poor", "Standard", "Good"])
cm = confusion_matrix(y_test, y_pred, labels=["Poor", "Standard", "Good"])
# Calculate AUC score
y_test_encoded = y_test.replace({"Poor": 0, "Standard": 1, "Good": 2})
y_pred_proba = clf.predict_proba(X_test)
auc_score = roc_auc_score(y_test_encoded, y_pred_proba, multi_class="ovr")
# Print metrics
print("Model Evaluation Metrics:")
print(f"Accuracy: {acc}")
print(f"AUC Score: {auc_score}")
print("Classification Report:")
print(report)
# Plot confusion matrix
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation="nearest", cmap=plt.cm.Blues)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(3)
plt.xticks(tick_marks, ["Poor", "Standard", "Good"], rotation=45)
plt.yticks(tick_marks, ["Poor", "Standard", "Good"])
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
cm_path = os.path.join("model", "confusion_matrix.png")
plt.savefig(cm_path)
print(f"Confusion matrix saved to {cm_path}")
def save_model(clf):
model_dir = "model"
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, "model.pkl")
# Save the trained model
with open(model_path, "wb") as f:
pickle.dump(clf, f)
print(f"Model saved to {model_path}")
def main():
# Execute steps
df = load_data()
X, y = preprocess_data(df)
preprocessor = encode_data(X)
X_train, X_test, y_train, y_test = split_data(X, y)
clf = train_model(X_train, y_train, preprocessor)
evaluate_model(clf, X_test, y_test)
save_model(clf)
if __name__ == "__main__":
main()
Le script de service de modèle charge le pipeline de modèles enregistré à l'aide du fichier de modèle, crée une fonction de requête POST qui prend une liste de dictionnaires de l'utilisateur, la convertit en un DataFrame, la fournit au modèle pour générer des prédictions, puis renvoie l'étiquette prédite. Nous utilisons FastAPI comme cadre d'API, ce qui nous permet de servir le modèle avec seulement quelques lignes de code.
src/app.py :
# src/app.py
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import os
# Load the trained model
model_path = os.path.join("model", "model.pkl")
with open(model_path, "rb") as f:
model = pickle.load(f)
app = FastAPI()
class InputData(BaseModel):
data: list # List of dictionaries representing feature values
@app.post("/predict")
def predict(input_data: InputData):
# Convert input data to DataFrame
X_new = pd.DataFrame(input_data.data)
# Ensure the columns match the training data
prediction = model.predict(X_new)
# Return predictions
return {"prediction": prediction.tolist()}
Nous devons créer un fichier requirements.txt qui inclut tous les paquets Python nécessaires à l'exécution des scripts mentionnés ci-dessus. Ce fichier sera utilisé pour mettre en place un environnement d'exécution dans le conteneur Docker, en veillant à ce que nous puissions exécuter les scripts Python sans problème.
requirements.txt :
fastapi
uvicorn[standard]
numpy
pandas
scikit-learn
pydantic
matplotlibCréez un "Dockerfile" et ajoutez le code suivant.
Voici les étapes de ce fichier Docker :
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY ./src/ ./src/
COPY ./data/ ./data/
# Ensure the model directory exists and is copied
RUN mkdir -p model
# Run the training script during the build
RUN python src/train.py
# Expose the port for the API
EXPOSE 8000
# Run the FastAPI app
CMD ["uvicorn", "src.app:app", "--host", "0.0.0.0", "--port", "8000"]Votre espace de travail local doit être organisé comme suit :
data contenant tous les fichiers CSVmodels src qui contient les scripts Pythonrequirements.txt et un fichier DockerfileLes autres fichiers sont des composants supplémentaires pour l'automatisation et les opérations Git.
La construction de l'image Docker est simple : Il suffit d'indiquer à la commande build le nom de votre image Docker et le répertoire actuel dans lequel se trouve le fichier Docker.
$ podman build -t mlops_app .L'outil de construction exécutera toutes les commandes du fichier Docker de manière séquentielle, de la mise en place de l'environnement au service de l'application d'apprentissage automatique.
Nous pouvons également constater que les journaux contiennent les résultats de l'évaluation du modèle. Le modèle a une précision de 75 % et un score ROC AUC de 0,89, ce qui est considéré comme moyen.
STEP 1/11: FROM python:3.9-slim
STEP 2/11: WORKDIR /app
--> Using cache 72ac9e49ae29da1ff19e118653efca17e7a489ae9e7ead917c83d942a3ea4e13
--> 72ac9e49ae29
STEP 3/11: COPY requirements.txt .
--> Using cache 3a05ca95caaf98c448c53a796714328bf9f7cff7896cce348f84a26b8d0dae61
--> 3a05ca95caaf
STEP 4/11: RUN pip install --no-cache-dir -r requirements.txt
--> Using cache 28109d1183449396a5df0006ab603dd5cf2aa2c06a810bdc6bcf0f843f855ee0
--> 28109d118344
STEP 5/11: COPY ./src/ ./src/
--> f814f699c58a
STEP 6/11: COPY ./data/ ./data/
--> 922550900cd0
STEP 7/11: RUN mkdir -p model
--> 36fc01f2d169
STEP 8/11: RUN python src/train.py
Data loaded successfully!
Data preprocessed successfully!
Data encoded successfully!
Data split successfully!
Model trained successfully!
Model Evaluation Metrics:
Accuracy: 0.7546181417149159
ROC AUC Score: 0.8897184704689612
Classification Report:
precision recall f1-score support
Good 0.71 0.67 0.69 1769
Poor 0.75 0.76 0.75 3403
Standard 0.77 0.78 0.78 5709
accuracy 0.75 10881
macro avg 0.74 0.74 0.74 10881
weighted avg 0.75 0.75 0.75 10881
Model saved to model/model.pkl
--> 5d4777c08580
STEP 9/11: EXPOSE 8000
--> 7bb09a613e7f
STEP 10/11: WORKDIR /app/src
--> 06b6394c2e2d
STEP 11/11: CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
COMMIT mlops-app
--> 9a7a42b03664
Successfully tagged localhost/mlops-app:latest
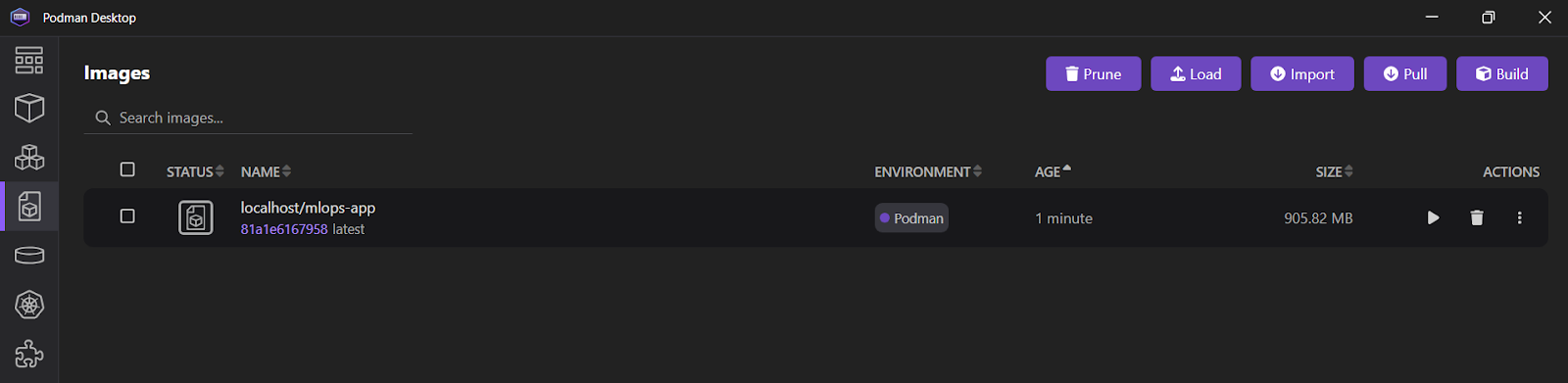
9a7a42b03664f1e4631330cd682cb2de26e513c5d776fa2ce2042b3bb9455e14Si vous ouvrez l'application Podman Desktop et cliquez sur l'onglet "Images", vous verrez quevotre image mlops_app a été créée avec succès.
Consultez la page Docker pour la science des données pour apprendre toutes les commandes Docker pertinentes. Remplacez simplement la première commande, docker, par podman.
Nous allons utiliser la commande run pour démarrer un conteneur nommé "mlops_container" à partir de l'image mlops-app. Cela se fera en mode détaché (-d), en faisant correspondre le port 8000 du conteneur au port 8000 de la machine hôte. Cette configuration permet d'accéder à l'application FastAPI depuis l'extérieur du conteneur.
$ podman run -d --name mlops_container -p 8000:8000 mlops-app Pour afficher tous les journaux du "mlops_container", utilisez la commande logs.
$ podman logs -f mlops_container Sortie :
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
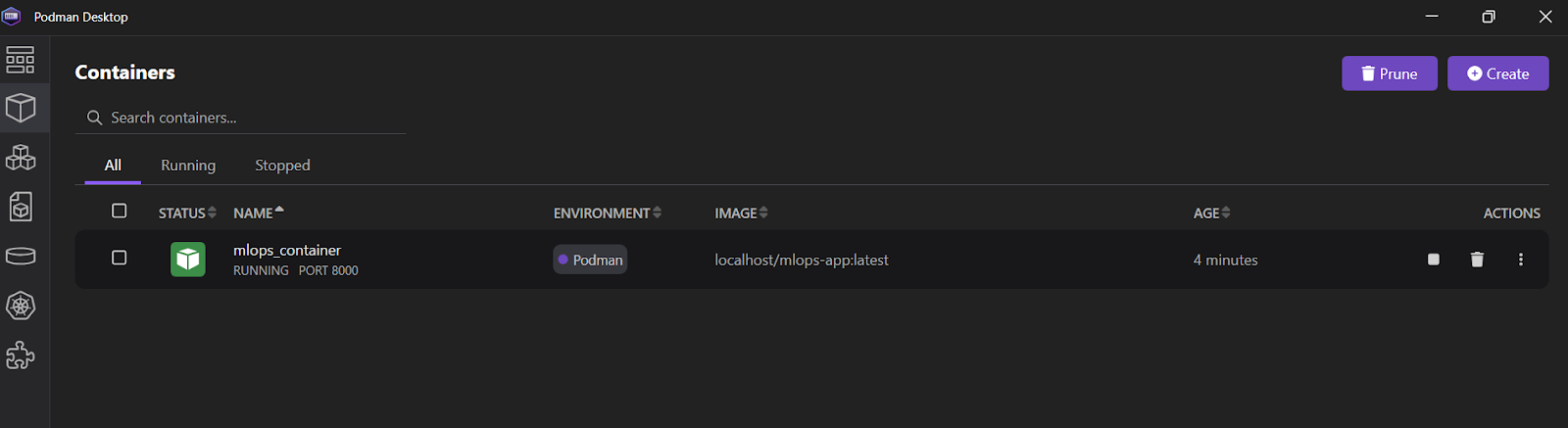
INFO: 10.88.0.1:36886 - "POST /predict HTTP/1.1" 200 OKVous pouvez également ouvrir l'application Podman Desktop et cliquer sur l'onglet "Conteneurs" pour voir les conteneurs en cours d'exécution.
Pour visualiser les journaux dans l'application Podman Desktop, cliquez sur "mlops_container" et sélectionnez ensuite l'onglet "Terminal".
Nous allons maintenant tester l'application déployée en accédant à l'interface interactive Swagger à l'adresse suivante : http://localhost:8000/docs. L'interface Swagger offre une interface conviviale qui vous permet d'explorer tous les points de terminaison d'API disponibles.
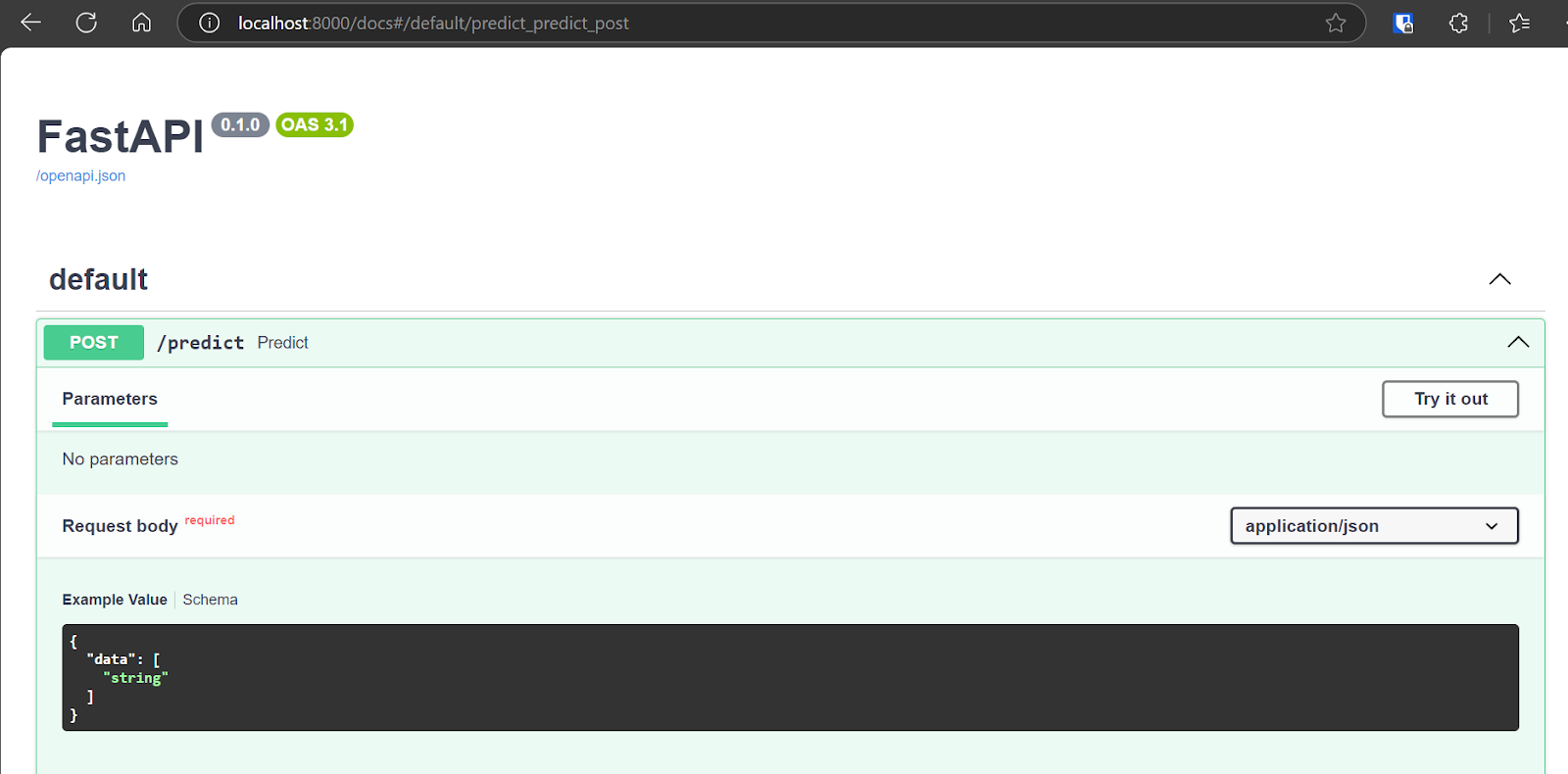
Nous pouvons également tester l'API en utilisant la commande CURL dans le terminal.
$ curl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"Age": 35,
"Occupation": "Engineer",
"Annual_Income": 85000,
"Monthly_Inhand_Salary": 7000,
"Num_Bank_Accounts": 2,
"Num_Credit_Card": 3,
"Interest_Rate": 5,
"Num_of_Loan": 1,
"Type_of_Loan": "Personal Loan",
"Delay_from_due_date": 2,
"Num_of_Delayed_Payment": 1,
"Changed_Credit_Limit": 15000,
"Num_Credit_Inquiries": 2,
"Credit_Mix": "Good",
"Outstanding_Debt": 10000,
"Credit_Utilization_Ratio": 30,
"Credit_History_Age": 15,
"Payment_of_Min_Amount": "Yes",
"Total_EMI_per_month": 500,
"Amount_invested_monthly": 1000,
"Payment_Behaviour": "Regular",
"Monthly_Balance": 5000
}
]
}'Le serveur FastAPI fonctionne correctement, il traite l'entrée de l'utilisateur et renvoie une prédiction exacte.
{"prediction":["Good"]}Après avoir expérimenté l'API, nous arrêterons le conteneur à l'aide de la commande stop.
$ podman stop mlops_container Nous pouvons également supprimer le conteneur à l'aide de la commande rm, ce qui libère des ressources système. Le conteneur doit d'abord être arrêté avant d'être retiré.
$ podman rm mlops_container Pour supprimer l'image de conteneur stockée localement et nommée "mlops-app", nous allons utiliser la commande rmi.
$ podman rmi mlops-app Si vous rencontrez des difficultés à exécuter le code ci-dessus ou à créer votre propre fichier Docker, veuillez consulter le dépôt GitHub kingabzpro/mlops-with-podman. Il comprend un guide d'utilisation et tous les fichiers nécessaires à l'exécution du code sur votre système.
L'étape suivante de votre apprentissage consiste à essayer de construire 10 idées de projets Dockerallant de débutant à avancé, mais avec Podman. Cela vous aidera à mieux comprendre l'écosystème Podman.
Podman offre une alternative convaincante à Docker pour certains cas d'utilisation, mais de nombreux développeurs continuent de privilégier Docker Desktop et CLI. Cette préférence est largement due aux intégrations étendues et aux outils conviviaux de Docker.
Cependant, pour un projet MLOps simple, les ingénieurs pourraient opter pour Podman, qui offre une configuration légère et facile par rapport à Docker Desktop.
Dans ce tutoriel, nous explorons Podman, un outil populaire de gestion de conteneurs, en le comparant à Docker et en montrant comment installer Podman Desktop. Nous vous guidons également à travers un projet MLOps utilisant Podman, couvrant la création d'un fichier Docker, la construction d'une image et l'exécution d'un conteneur. La prise en main de Podman est simple, et si vous êtes déjà familiarisé avec Docker, vous apprécierez la transition transparente.
Prenez le Déploiement et cycle de vie de MLOps pour explorer le cadre moderne de MLOps, le cycle de vie et le déploiement des modèles d'apprentissage automatique.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours