
Programa
Containerização e virtualização com o Docker e o Kubernetes
13 h
Todo desenvolvedor e engenheiro de operações da área de TI está familiarizado com o Docker para criar e implantar aplicativos, seja localmente ou na nuvem. No entanto, como desenvolvedor ou engenheiro de operações de aprendizado de máquina, você pode estar procurando otimizar recursos, aumentar a segurança e melhorar a integração do sistema. A Podman oferece uma alternativa interessante. É uma ferramenta gratuita e de código aberto que serve como alternativa ao Docker e ao Docker Desktop.
Neste tutorial, exploraremos o que é o Podman, as diferenças entre o Podman e o Docker e como você pode instalar e usar o Podman. Além disso, abordaremos como treinar, avaliar e implantar modelos de aprendizado de máquina localmente usando os comandos Dockerfile e Podman.

Imagem do autor
O Podman é uma ferramenta de gerenciamento de contêineres de código aberto projetada para oferecer aos desenvolvedores e engenheiros de aprendizado de máquina uma experiência perfeita e segura. Ao contrário do Docker, o Podman opera sem daemon, o que aumenta a segurança e a flexibilidade, permitindo que os usuários executem contêineres como processos sem raiz. Esse recurso fundamental permite que o Podman execute contêineres sem exigir privilégios de root, minimizando assim as possíveis vulnerabilidades.
O Podman é totalmente compatível com os padrões da OCI (Open Container Initiative), garantindo que os contêineres e as imagens criados com o Podman possam ser facilmente integrados a outras ferramentas e plataformas compatíveis com a OCI, como runc, Buildah e Skopeo. Além disso, o Podman oferece suporte à criação e ao gerenciamento de pods, que são grupos de contêineres que compartilham o mesmo namespace de rede, semelhante aos pods do Kubernetes.
Um dos melhores aspectos do uso do Podman é que ele oferece uma experiência semelhante à do Docker. A interface de linha de comando é comparável à do Docker, e você também pode extrair imagens do Docker Hub. Essa semelhança permite uma transição fácil para aqueles que já estão familiarizados com o Docker e, ao mesmo tempo, oferece recursos avançados que atendem às necessidades crescentes de desenvolvimento e implantação de aplicativos em contêineres.
O Podman é apenas uma ferramenta no arsenal de MLOps. Saiba mais sobre todos os tipos de ferramentas usadas no ecossistema de MLOps lendo o blog 25 principais ferramentas de MLOps que você precisa conhecer em 2025.
O Docker e o Podman são ferramentas importantes de gerenciamento de contêineres, cada uma oferecendo recursos e capacidades diferentes. Esta comparação examinará as diferenças entre eles e ajudará você a decidir qual deles atende melhor às suas necessidades.
|
Docker |
Podman |
|
|
Arquitetura |
O Docker usa uma arquitetura cliente-servidor com um processo daemon chamado dockerd. |
O Podman não tem daemon e usa um modelo fork-exec, o que aumenta a segurança e a simplicidade. |
|
Segurança |
O Docker executa contêineres como raiz por padrão, o que pode representar riscos de segurança. |
O Podman oferece suporte a contêineres sem raiz por padrão, reduzindo os riscos de segurança. |
|
Gerenciamento de imagens |
O Docker pode criar e gerenciar imagens de contêineres usando suas próprias ferramentas. |
O Podman depende do Buildah para criar imagens e pode executar imagens de registros do Docker. |
|
Compatibilidade |
O Docker é amplamente usado e integrado a muitas ferramentas de CI/CD. |
O Podman oferece uma CLI compatível com o Docker, facilitando a mudança para os usuários sem alterar os fluxos de trabalho. |
|
Orquestração de contêineres |
O Docker oferece suporte ao Docker Swarm e ao Kubernetes para orquestração. |
O Podman não é compatível com o Docker Swarm, mas pode trabalhar com o Kubernetes usando pods. |
|
Suporte à plataforma |
O Docker é executado nativamente no Linux, macOS e Windows (com WSL). |
O Podman também é compatível com Linux, macOS e Windows (com WSL). |
|
Desempenho |
O Docker é conhecido por seu gerenciamento eficiente de recursos e implantação rápida. |
Em geral, o Podman é comparável em termos de desempenho e oferece tempos de inicialização mais rápidos. |
|
Casos de uso |
O Docker é ideal para projetos que exigem ferramentas e integrações bem estabelecidas. |
O Podman é adequado para ambientes que priorizam a segurança e operações leves. Ideal para implementações em grande escala. |
A escolha entre o Docker e o Podman depende, em grande parte, dos requisitos específicos do projeto, principalmente no que diz respeito às necessidades de segurança, compatibilidade e orquestração.
O Docker continua sendo uma boa opção para pipelines de CI/CD estabelecidos e gerenciamento abrangente de contêineres, enquanto o Podman oferece uma alternativa segura e leve para ambientes que priorizam a segurança e operações sem raiz. Ele também oferece tempos de inicialização mais rápidos, o que é ideal para implementações em grande escala.
Descubra Docker para ciência de dados Leia nosso artigo introdutório, que inclui código de amostra e exemplos.
Primeiro, você deve fazer o download e instalar o pacote do Podman Desktop acessando o site oficial.
Fonte: Podman
A instalação é simples e rápida. Em poucos minutos, você estará na tela de introdução, onde será solicitado a instalar extensões opcionais.
Se você não tiver o WSL no Windows, ele instalará automaticamente o WSL.
Em seguida, configure a máquina Podman.
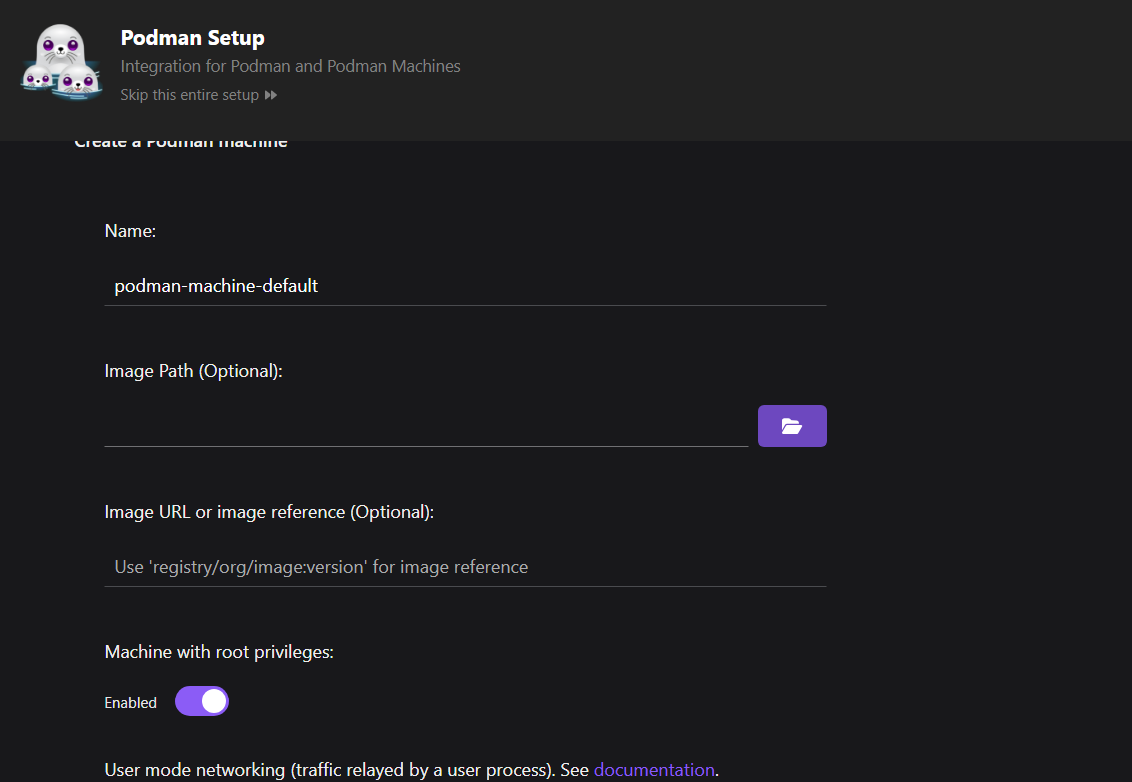
Em comparação com o Docker, você não precisa configurar uma máquina. No entanto, no Podman, você pode gerenciar várias máquinas que lidam com diferentes contêineres simultaneamente, o que permite um melhor gerenciamento de recursos.
Nossa máquina está em funcionamento, pronta para criar imagens e executar os contêineres.
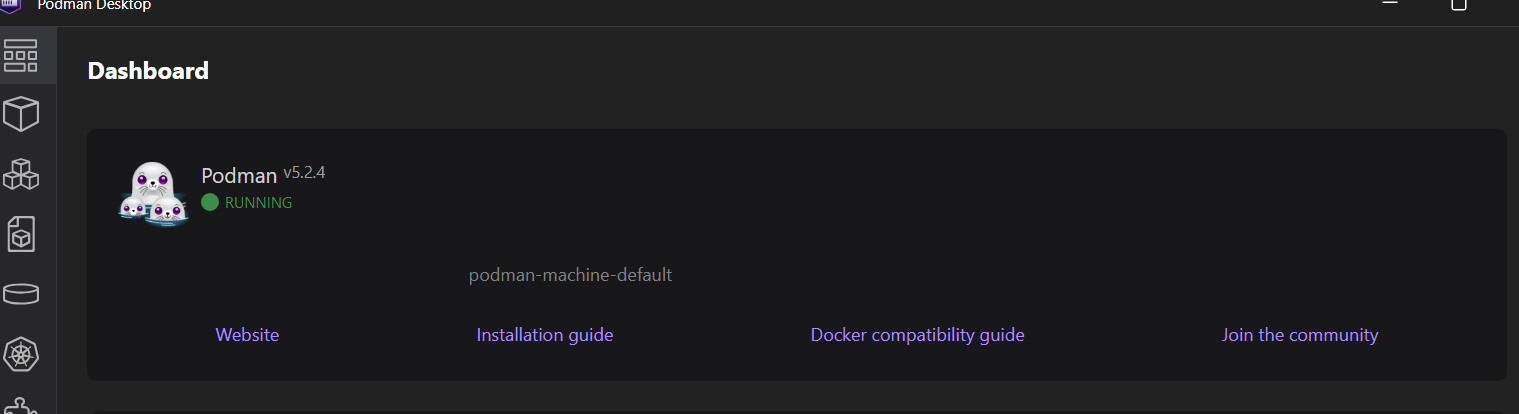
Para verificar se o Podman está funcionando corretamente, extrairemos uma imagem de amostra do quay.io e executaremos o contêiner.
$ podman run quay.io/podman/helloA máquina Podman extraiu a imagem com sucesso e executou o contêiner, exibindo os logs.
Trying to pull quay.io/podman/hello:latest...
Getting image source signatures
Copying blob sha256:81df7ff16254ed9756e27c8de9ceb02a9568228fccadbf080f41cc5eb5118a44
Copying config sha256:5dd467fce50b56951185da365b5feee75409968cbab5767b9b59e325fb2ecbc0
Writing manifest to image destination
!... Hello Podman World ...!
.--"--.
/ - - \
/ (O) (O) \
~~~| -=(,Y,)=- |
.---. /` \ |~~
~/ o o \~~~~.----. ~~
| =(X)= |~ / (O (O) \
~~~~~~~ ~| =(Y_)=- |
~~~~ ~~~| U |~~
Project: https://github.com/containers/podman
Website: https://podman.io
Desktop: https://podman-desktop.io
Documents: https://docs.podman.io
YouTube: https://youtube.com/@Podman
X/Twitter: @Podman_io
Mastodon: @Podman_io@fosstodon.orgNeste projeto MLOps, automatizaremos o treinamento e a avaliação do modelo e o serviremos usando Dockerfile e Podman. Isso será semelhante ao Docker, mas, em vez disso, usaremos a CLI do Podman para criar imagens e, em seguida, executar o contêiner.
Se você ainda não conhece os conceitos, pode aprender os fundamentos dos MLOPs concluindo o curso Conceitos de MLOps que você pode fazer.
Para configurar o projeto de aprendizado de máquina, precisamos criar um script de treinamento e de serviço, bem como um arquivo requirements.txt para instalar os pacotes Python.
O script Python de treinamento carregará a classificação de pontuação de crédito processa-o, codifica-o e treina o modelo. Também realizaremos a avaliação do modelo. No final, salvaremos o pipeline de pré-processamento e treinamento junto com o modelo usando o formato pickle.
src/train.py:
# src/train.py
import os
import pickle
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
roc_auc_score,
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
def load_data():
data_path = "data/train.csv"
df = pd.read_csv(data_path,low_memory=False)
print("Data loaded successfully!")
return df
def preprocess_data(df):
# Drop unnecessary columns
df = df.drop(columns=["ID", "Customer_ID", "SSN", "Name", "Month"])
# Drop rows with missing values
df = df.dropna()
# Convert data types
# Convert the 'Age' column to numeric, setting errors='coerce' to handle non-numeric values
df["Age"] = pd.to_numeric(df["Age"], errors="coerce")
# Filter the DataFrame to include only rows where 'Age' is between 1 and 60
df = df[(df["Age"] >= 1) & (df["Age"] <= 60)]
df["Annual_Income"] = pd.to_numeric(df["Annual_Income"], errors="coerce")
df["Monthly_Inhand_Salary"] = pd.to_numeric(
df["Monthly_Inhand_Salary"], errors="coerce"
)
# Separate features and target
X = df.drop("Credit_Score", axis=1)
y = df["Credit_Score"]
print("Data preprocessed successfully!")
return X, y
def encode_data(X):
# Identify categorical and numerical features
categorical_features = [
"Occupation",
"Credit_Mix",
"Payment_of_Min_Amount",
"Payment_Behaviour",
"Type_of_Loan",
]
numerical_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# Define preprocessing steps
numerical_transformer = SimpleImputer(strategy="median")
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numerical_transformer, numerical_features),
("cat", categorical_transformer, categorical_features),
]
)
return preprocessor
def split_data(X, y):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def train_model(X_train, y_train, preprocessor):
# Create a pipeline with preprocessing and model
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", RandomForestClassifier(n_estimators=100)),
]
)
# Train the model
clf.fit(X_train, y_train)
# Return the trained model
return clf
def evaluate_model(clf, X_test, y_test):
# Predict and evaluate
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, labels=["Poor", "Standard", "Good"])
cm = confusion_matrix(y_test, y_pred, labels=["Poor", "Standard", "Good"])
# Calculate AUC score
y_test_encoded = y_test.replace({"Poor": 0, "Standard": 1, "Good": 2})
y_pred_proba = clf.predict_proba(X_test)
auc_score = roc_auc_score(y_test_encoded, y_pred_proba, multi_class="ovr")
# Print metrics
print("Model Evaluation Metrics:")
print(f"Accuracy: {acc}")
print(f"AUC Score: {auc_score}")
print("Classification Report:")
print(report)
# Plot confusion matrix
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation="nearest", cmap=plt.cm.Blues)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(3)
plt.xticks(tick_marks, ["Poor", "Standard", "Good"], rotation=45)
plt.yticks(tick_marks, ["Poor", "Standard", "Good"])
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
cm_path = os.path.join("model", "confusion_matrix.png")
plt.savefig(cm_path)
print(f"Confusion matrix saved to {cm_path}")
def save_model(clf):
model_dir = "model"
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, "model.pkl")
# Save the trained model
with open(model_path, "wb") as f:
pickle.dump(clf, f)
print(f"Model saved to {model_path}")
def main():
# Execute steps
df = load_data()
X, y = preprocess_data(df)
preprocessor = encode_data(X)
X_train, X_test, y_train, y_test = split_data(X, y)
clf = train_model(X_train, y_train, preprocessor)
evaluate_model(clf, X_test, y_test)
save_model(clf)
if __name__ == "__main__":
main()
O script de serviço de modelo carregará o pipeline de modelo salvo usando o arquivo de modelo, criará uma função de solicitação POST que recebe uma lista de dicionários do usuário, converte-a em um DataFrame, fornece-a ao modelo para gerar previsões e, em seguida, retorna o rótulo previsto. Estamos usando FastAPI como nossa estrutura de API, o que nos permite servir o modelo com apenas algumas linhas de código.
src/app.py:
# src/app.py
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import os
# Load the trained model
model_path = os.path.join("model", "model.pkl")
with open(model_path, "rb") as f:
model = pickle.load(f)
app = FastAPI()
class InputData(BaseModel):
data: list # List of dictionaries representing feature values
@app.post("/predict")
def predict(input_data: InputData):
# Convert input data to DataFrame
X_new = pd.DataFrame(input_data.data)
# Ensure the columns match the training data
prediction = model.predict(X_new)
# Return predictions
return {"prediction": prediction.tolist()}
Precisamos criar um arquivo requirements.txt que inclua todos os pacotes Python necessários para executar os scripts mencionados acima. Esse arquivo será usado para configurar um ambiente de execução no contêiner do Docker, garantindo que possamos executar os scripts Python sem problemas.
requisitos.txt:
fastapi
uvicorn[standard]
numpy
pandas
scikit-learn
pydantic
matplotlibCrie um "Dockerfile" e adicione o seguinte código.
Aqui estão as etapas que esse Dockerfile executa:
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY ./src/ ./src/
COPY ./data/ ./data/
# Ensure the model directory exists and is copied
RUN mkdir -p model
# Run the training script during the build
RUN python src/train.py
# Expose the port for the API
EXPOSE 8000
# Run the FastAPI app
CMD ["uvicorn", "src.app:app", "--host", "0.0.0.0", "--port", "8000"]Seu espaço de trabalho local deve ser organizado da seguinte forma:
data contendo todos os arquivos CSVmodels src que contém scripts Pythonrequirements.txt e um arquivo DockerfileOs arquivos restantes são componentes adicionais para automação e operações do Git.
Criar a imagem do Docker é simples: Basta fornecer ao comando build o nome da imagem do Docker e o diretório atual onde o Dockerfile está localizado.
$ podman build -t mlops_app .A ferramenta de compilação executará todos os comandos no Dockerfile sequencialmente, desde a configuração do ambiente até o fornecimento do aplicativo de aprendizado de máquina.
Também podemos ver que os registros contêm os resultados da avaliação do modelo. O modelo tem uma precisão de 75% e uma pontuação ROC AUC de 0,89, que é considerada média.
STEP 1/11: FROM python:3.9-slim
STEP 2/11: WORKDIR /app
--> Using cache 72ac9e49ae29da1ff19e118653efca17e7a489ae9e7ead917c83d942a3ea4e13
--> 72ac9e49ae29
STEP 3/11: COPY requirements.txt .
--> Using cache 3a05ca95caaf98c448c53a796714328bf9f7cff7896cce348f84a26b8d0dae61
--> 3a05ca95caaf
STEP 4/11: RUN pip install --no-cache-dir -r requirements.txt
--> Using cache 28109d1183449396a5df0006ab603dd5cf2aa2c06a810bdc6bcf0f843f855ee0
--> 28109d118344
STEP 5/11: COPY ./src/ ./src/
--> f814f699c58a
STEP 6/11: COPY ./data/ ./data/
--> 922550900cd0
STEP 7/11: RUN mkdir -p model
--> 36fc01f2d169
STEP 8/11: RUN python src/train.py
Data loaded successfully!
Data preprocessed successfully!
Data encoded successfully!
Data split successfully!
Model trained successfully!
Model Evaluation Metrics:
Accuracy: 0.7546181417149159
ROC AUC Score: 0.8897184704689612
Classification Report:
precision recall f1-score support
Good 0.71 0.67 0.69 1769
Poor 0.75 0.76 0.75 3403
Standard 0.77 0.78 0.78 5709
accuracy 0.75 10881
macro avg 0.74 0.74 0.74 10881
weighted avg 0.75 0.75 0.75 10881
Model saved to model/model.pkl
--> 5d4777c08580
STEP 9/11: EXPOSE 8000
--> 7bb09a613e7f
STEP 10/11: WORKDIR /app/src
--> 06b6394c2e2d
STEP 11/11: CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
COMMIT mlops-app
--> 9a7a42b03664
Successfully tagged localhost/mlops-app:latest
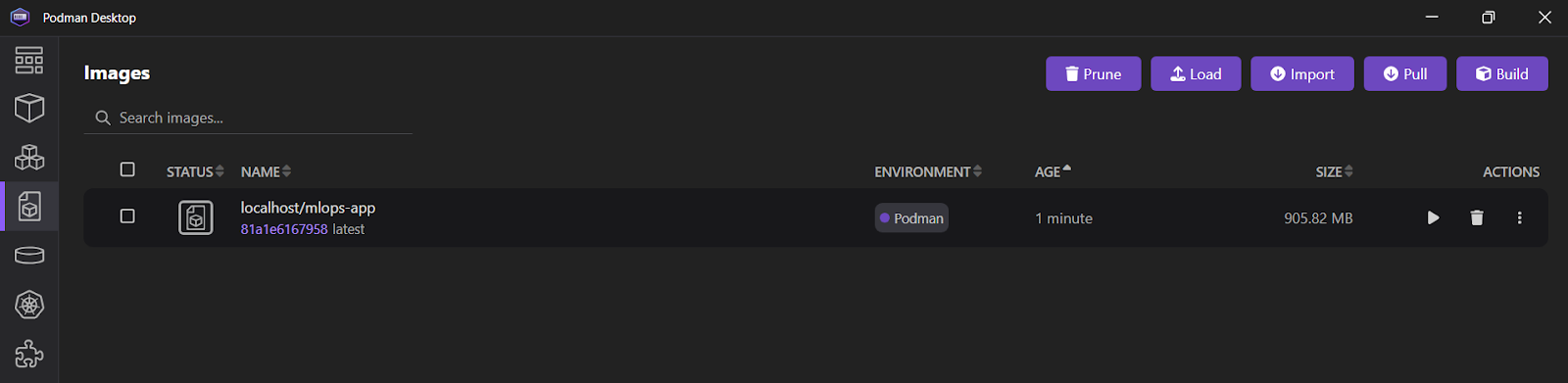
9a7a42b03664f1e4631330cd682cb2de26e513c5d776fa2ce2042b3bb9455e14Se você abrir o aplicativo Podman Desktop e clicar na guia "Images", verá quea imagem mlops_app foi criada com sucesso.
Dê uma olhada no Docker para ciência de dados para que você aprenda todos os comandos relevantes do Docker. Basta substituir o primeiro comando, docker, por podman.
Usaremos o comando run para iniciar um contêiner chamado "mlops_container" a partir da imagem mlops-app. Isso será feito no modo desanexado (-d), mapeando a porta 8000 do contêiner para a porta 8000 no computador host. Essa configuração permitirá que você acesse o aplicativo FastAPI de fora do contêiner.
$ podman run -d --name mlops_container -p 8000:8000 mlops-app Para exibir todos os registros do "mlops_container", use o comando logs.
$ podman logs -f mlops_container Saída:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
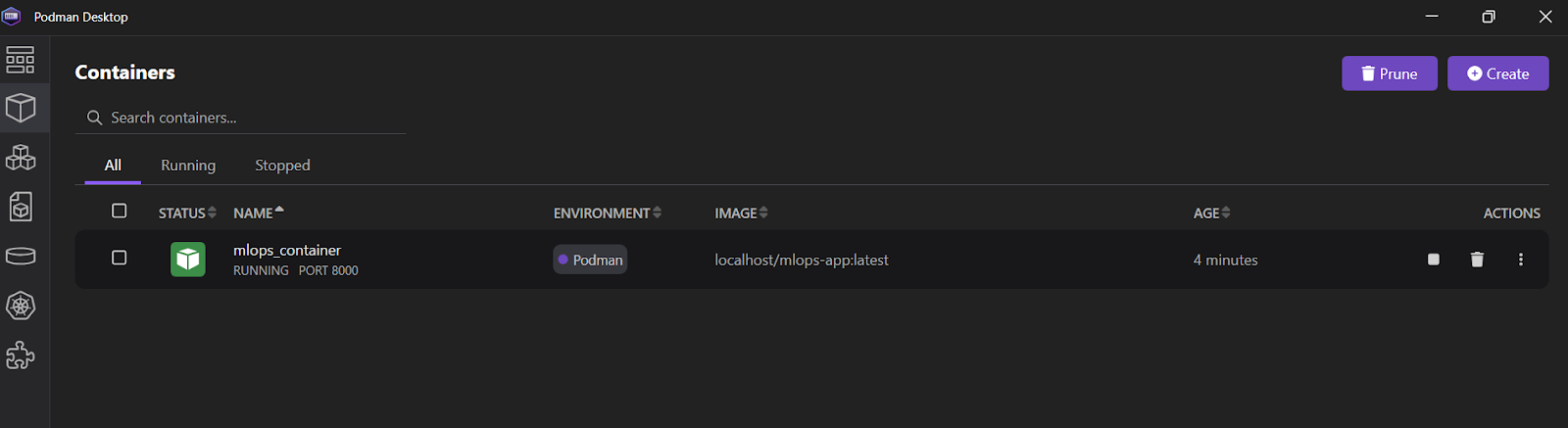
INFO: 10.88.0.1:36886 - "POST /predict HTTP/1.1" 200 OKVocê também pode abrir o aplicativo Podman Desktop e clicar na guia "Containers" (Contêineres) para visualizar os contêineres em execução.
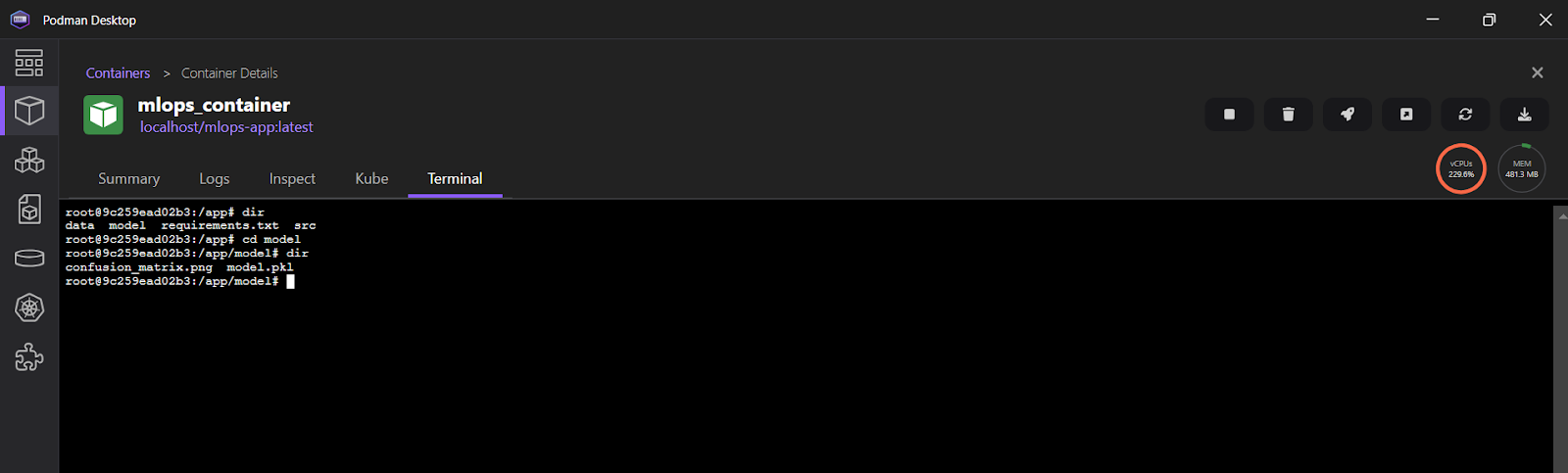
Para visualizar os registros no aplicativo Podman Desktop, clique em "mlops_container" e, em seguida, selecione a guia "Terminal".
Agora, testaremos o aplicativo implantado acessando a UI interativa do Swagger em: http://localhost:8000/docs. A interface de usuário do Swagger oferece uma interface amigável que permite que você explore todos os pontos de extremidade de API disponíveis.
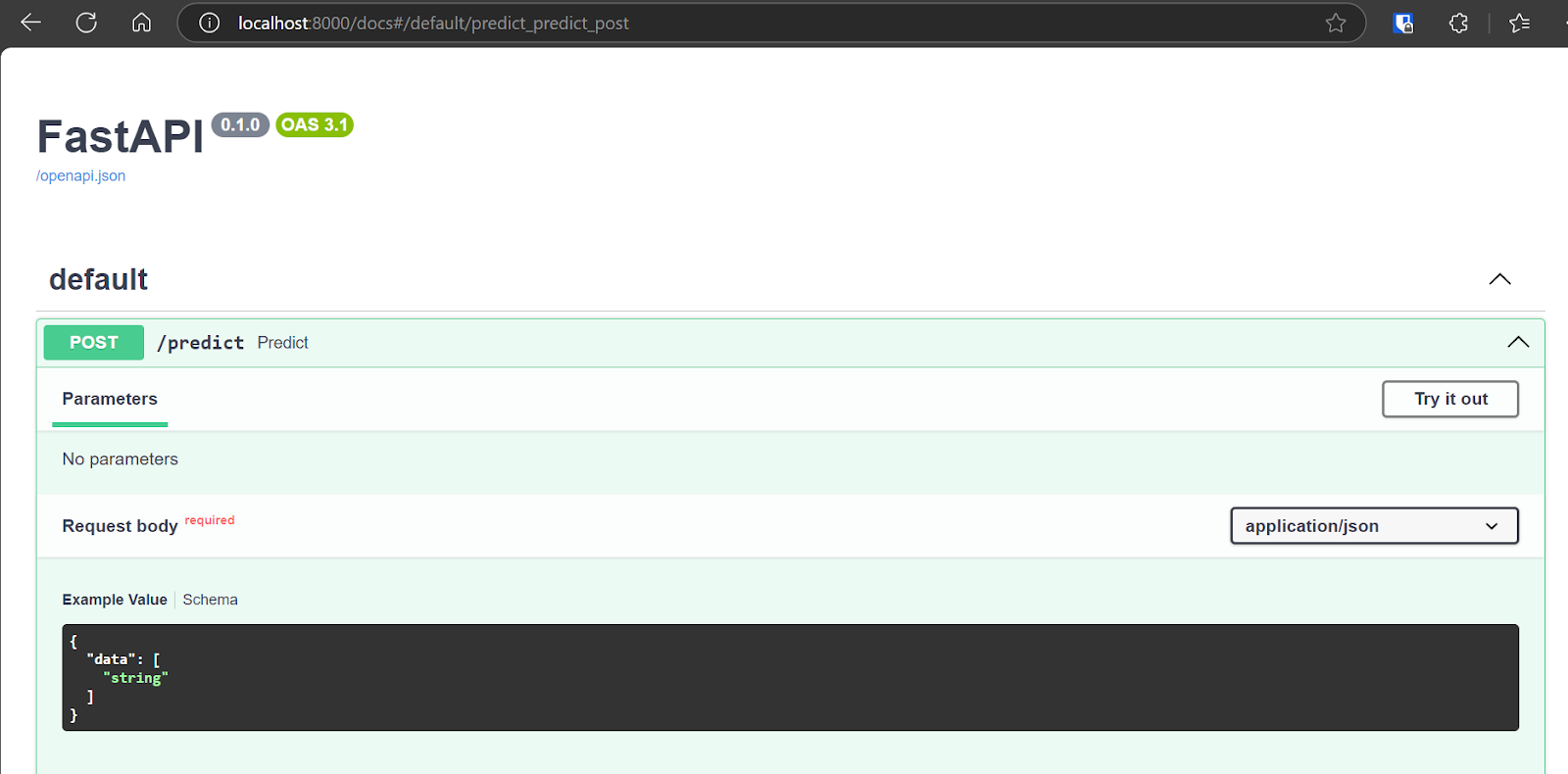
Também podemos testar a API usando o comando CURL no terminal.
$ curl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"Age": 35,
"Occupation": "Engineer",
"Annual_Income": 85000,
"Monthly_Inhand_Salary": 7000,
"Num_Bank_Accounts": 2,
"Num_Credit_Card": 3,
"Interest_Rate": 5,
"Num_of_Loan": 1,
"Type_of_Loan": "Personal Loan",
"Delay_from_due_date": 2,
"Num_of_Delayed_Payment": 1,
"Changed_Credit_Limit": 15000,
"Num_Credit_Inquiries": 2,
"Credit_Mix": "Good",
"Outstanding_Debt": 10000,
"Credit_Utilization_Ratio": 30,
"Credit_History_Age": 15,
"Payment_of_Min_Amount": "Yes",
"Total_EMI_per_month": 500,
"Amount_invested_monthly": 1000,
"Payment_Behaviour": "Regular",
"Monthly_Balance": 5000
}
]
}'O servidor FastAPI está funcionando corretamente, processando com êxito a entrada do usuário e retornando uma previsão precisa.
{"prediction":["Good"]}Depois de fazer experiências com a API, interromperemos o contêiner usando o comando stop.
$ podman stop mlops_container Além disso, podemos remover o contêiner usando o comando rm, liberando recursos do sistema. O contêiner deve ser parado antes de ser removido.
$ podman rm mlops_container Para remover a imagem de contêiner armazenada localmente chamada "mlops-app", usaremos o comando rmi.
$ podman rmi mlops-app Se você estiver enfrentando problemas para executar o código acima ou criar seu próprio arquivo Docker, verifique o repositório do GitHub kingabzpro/mlops-with-podman. Ele inclui um guia de uso e todos os arquivos necessários para que você possa executar o código em seu sistema.
A próxima etapa de sua jornada de aprendizado é tentar criar 10 ideias de projetos do Dockerque vão do iniciante ao avançado, mas com o Podman. Isso ajudará você a entender melhor o ecossistema do Podman.
O Podman oferece uma alternativa atraente ao Docker para determinados casos de uso, mas muitos desenvolvedores continuam a preferir o Docker Desktop e a CLI. Essa preferência se deve em grande parte às extensas integrações e ferramentas fáceis de usar do Docker.
No entanto, para um projeto simples de MLOps, os engenheiros podem optar pelo Podman, que oferece uma configuração leve e fácil em comparação com o Docker Desktop.
Neste tutorial, exploramos o Podman, uma ferramenta popular de gerenciamento de contêineres, comparando-o com o Docker e demonstrando como instalar o Podman Desktop. Também orientamos você em um projeto MLOps usando o Podman, abordando a criação de um Dockerfile, a criação de uma imagem e a execução de um contêiner. Começar a usar o Podman é simples e, se você já estiver familiarizado com o Docker, apreciará a transição perfeita.
Faça o Implantação e ciclo de vida de MLOps para conhecer a estrutura moderna de MLOps, explorando o ciclo de vida e a implantação de modelos de aprendizado de máquina.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Stanislav Karzhev
12 min
blog
Kurtis Pykes
8 min
blog
Abid Ali Awan
5 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan

