
Kurs
Schlussfolgern bei der linearen Regression in R
4 Std.
15.9K
Die lineare Regression ist eine der einfachsten Methoden des maschinellen Lernens. Es geht darum, den Wert einer abhängigen Variable auf der Grundlage einer oder mehrerer unabhängiger Variablen vorherzusagen.
Die lineare Regression kann zum Beispiel angewendet werden, um Hauspreise anhand der Hausgröße vorherzusagen oder das Gewicht einer Person anhand ihrer Größe zu bestimmen. Lineare Regressionsmodelle werden hauptsächlich in zwei Typen unterteilt: einfache und multiple lineare Regression.
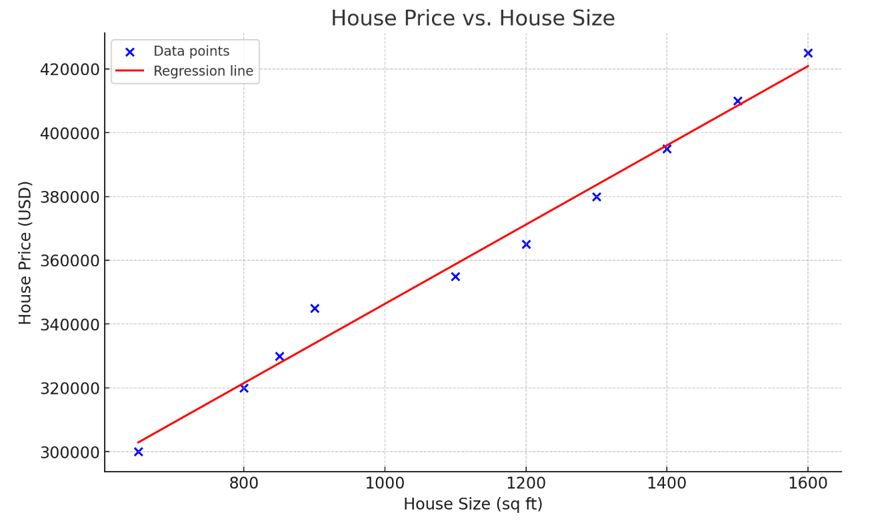
Bild von OpenAI
Das obige Diagramm stellt eine einfache lineare Regression dar, die die Beziehung zwischen der Hausgröße (unabhängige Variable) und dem Hauspreis (abhängige Variable) modelliert. Wie in der Visualisierung zu sehen ist, gilt: Je größer das Haus, desto teurer ist es.
Die Gleichung der Regressionsgeraden lautet:
y = mx + c + ⍷
Wenn dir die obige Formel bekannt vorkommt, liegt das daran, dass du wahrscheinlich in der Schule gelernt hast, dass y = mx + c die Gleichung einer Geraden ist. In dieser Gleichung:
⍷ steht für den Residual- oder Fehlerterm. Dies ist die Differenz zwischen dem tatsächlichen Wert und dem durch den Regressionswert vorhergesagten Wert. Das unterscheidet eine Regressionsgerade von einer rein deterministischen Geraden und macht die Beziehung zwischen x und y nicht perfekt vorhersehbar.
Einen ausführlicheren Leitfaden zum Thema findest du in unserem Artikel, der die Grundlagen der linearen Regression erklärt.
Hier sind einige Faktoren, die Excel zu einem effektiven Werkzeug für die Durchführung einer linearen Regression machen:
Im Jahr 2024 wird Excel laut Statista von über 731.000 Unternehmen in den Vereinigten Staaten und unzähligen weiteren weltweit genutzt. Führungskräfte auf allen Organisationsebenen nutzen Excel für die Datenverwaltung und für Berichte.
Durch die Erstellung von Vorhersagemodellen wie der linearen Regression in Excel können Unternehmen ihre Berichterstattungs- und Vorhersagemodellierungsaktivitäten auf einer einzigen Plattform konsolidieren. So können Unternehmen ihre Arbeitsabläufe straffen, ohne ständig zwischen Programmierumgebungen und Excel-Tabellen wechseln zu müssen.
Wenn du ein Anfänger in der Datenbranche bist, kann der bloße Gedanke an die Erstellung eines Vorhersagemodells aufgrund der damit verbundenen Codierung einschüchternd wirken. Excel vereinfacht diesen Prozess, indem es dir ermöglicht, in einer Oberfläche zu arbeiten, mit der du bereits vertraut bist. Mit Excel wird das Erstellen eines linearen Regressionsmodells zu einem einfachen Prozess, der mit nur wenigen Klicks zu bewältigen ist.
Excel bietet starke Visualisierungsfunktionen, mit denen du die Beziehung zwischen verschiedenen Variablen grafisch darstellen kannst, um sie besser zu verstehen. Außerdem vereinfacht es die Erstellung von Berichten und stellt sicher, dass die Visualisierungen leicht in PowerPoint-Präsentationen eingebettet werden können, um eine effektive Kommunikation mit den Stakeholdern zu ermöglichen.
Bevor du in dieses Tutorial einsteigst, lade den Datensatz herunter, der in diesem GitHub-Repository verfügbar ist. Dieser Datensatz wurde von OpenAI speziell für Bildungszwecke erstellt. Wenn du die Grundlagen der Tabellenkalkulation beherrschst, z. B. das Eingeben von Daten, das Anwenden einfacher Formeln und das Navigieren in Arbeitsblättern, kannst du diesem Lernprogramm besser folgen.
Zuerst müssen wir das Datenanalyse-ToolPak in Excel aktivieren. Dies ist ein Excel-Zusatzprogramm, das eine Vielzahl von Datenanalysetools bietet, darunter auch das, das wir für die lineare Regression verwenden werden.
Dazu öffnest du zunächst die Excel-Datei und navigierst zu Datei -> Optionen. Wähle im Dialogfeld Optionen die Option Add-ins -> Excel Add-ins und klicke auf Los:
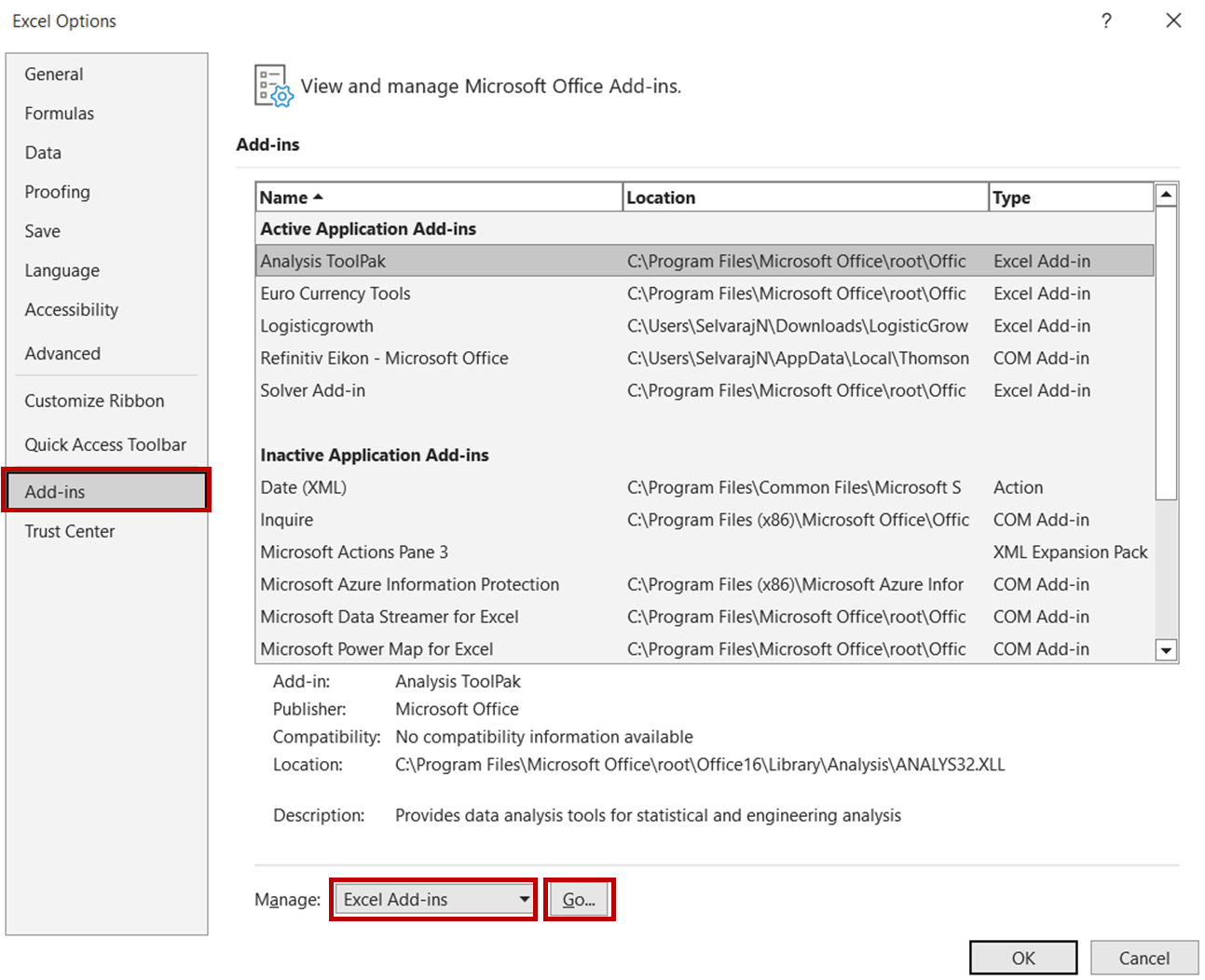
Markiere im Dialogfeld Add-ins die Option Analysis ToolPak und klicke auf OK.
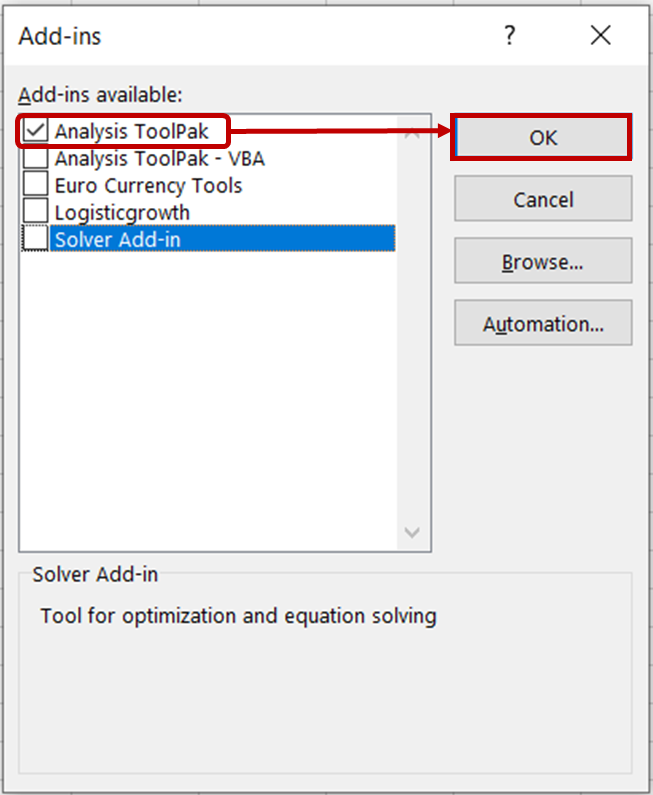
Auf der Registerkarte Daten solltest du jetzt die Werkzeuge zur Datenanalyse sehen.
Jetzt, wo wir das Datenanalyse-ToolPak aktiviert haben, können wir eine lineare Regression für den Datensatz durchführen. Öffne den Eiscreme-Verkaufsdatensatz und navigiere zur Registerkarte Daten. Klicke in der Gruppe " Analyse" auf " Datenanalyse".

Wähle dann Regression aus der Liste der Analysewerkzeuge und klicke auf OK.
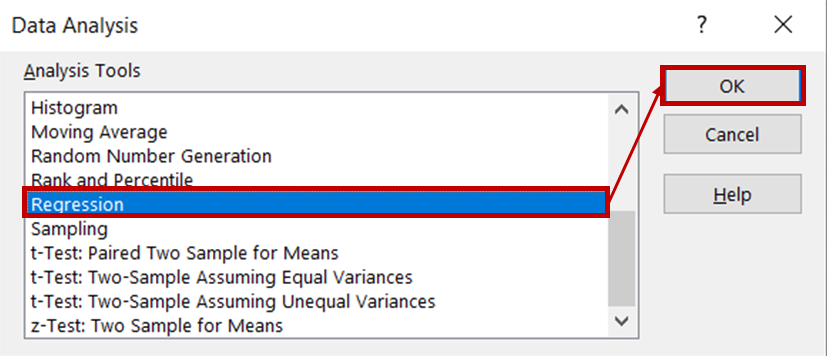
Wähle im Regressionsdialogfeld für den Eingabe-Y-Bereich die Spalte mit den Eiscreme-Verkaufsdaten aus. Wähle für den Bereich Eingabe X die Spalten mit den Temperatur- und Preisdaten aus. Achte darauf, dass das Kontrollkästchen Beschriftungen aktiviert ist, damit Excel die Überschriften erkennt und die übrigen Zeilen als numerische Daten behandelt. Wähle im Abschnitt " Ausgabeoptionen" die Option " Neues Arbeitsblatt" , um die Ergebnisse in einem neuen Arbeitsblatt anzuzeigen.
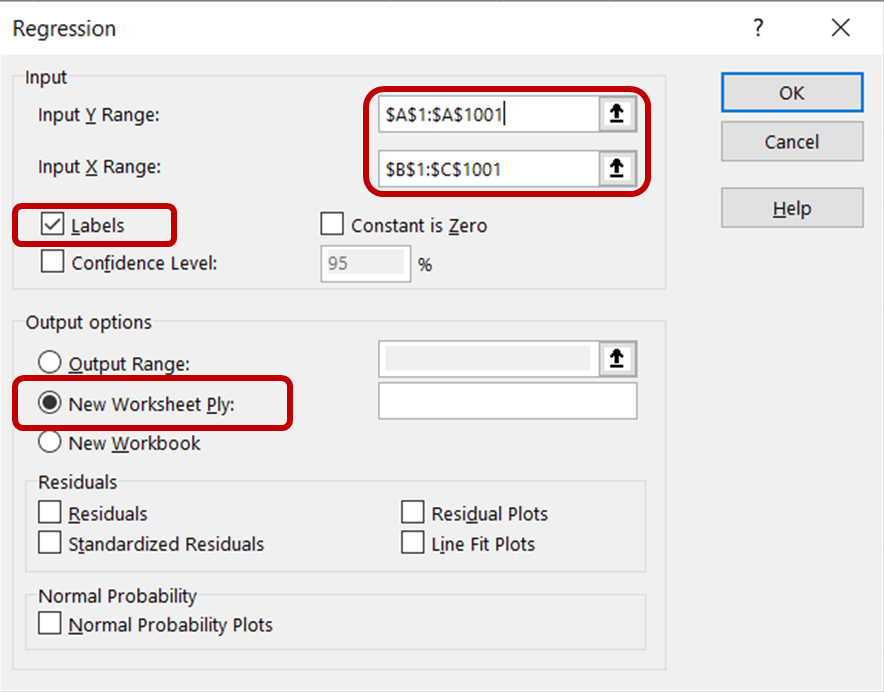
Klicke dann auf OK, um die Regressionsanalyse mit dem Datensatz durchzuführen.
Nachdem du die Regression durchgeführt hast, solltest du sehen, dass automatisch ein neues Arbeitsblatt in der Excel-Datei erscheint, das eine Reihe von Tabellen mit den Ergebnissen enthält, die so aussehen:
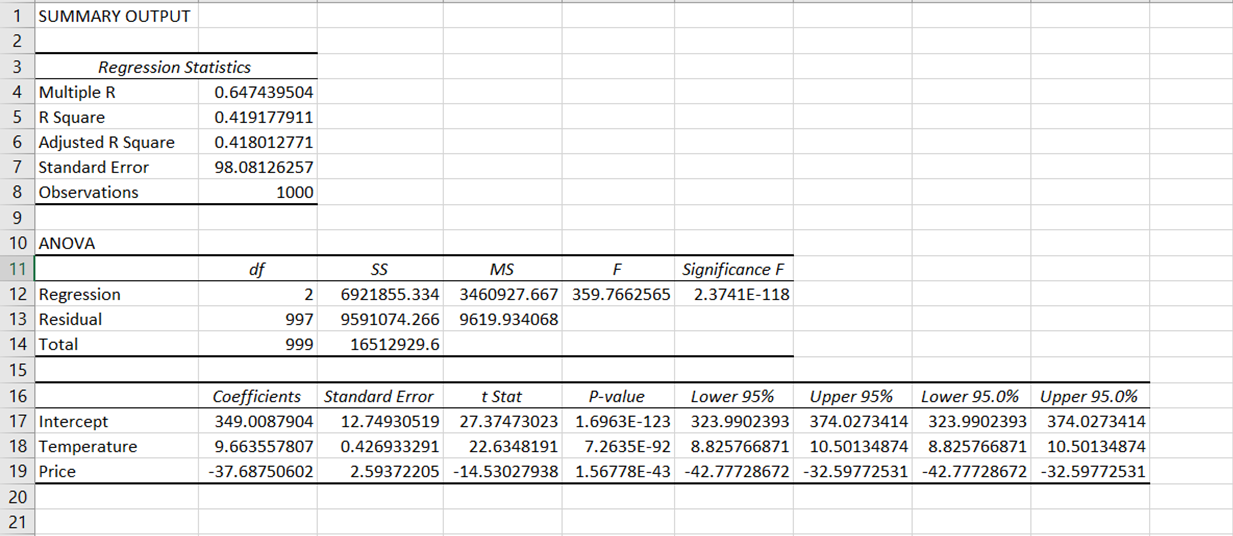
Die Ergebnisse der Regressionsausgabe wurden in verschiedene Komponenten aufgeschlüsselt: Regressionsstatistik, ANOVA, Koeffizienten, Standardfehler, t Stat, P-Wert und Konfidenzintervall.
Schauen wir uns jede dieser Komponenten genauer an:
Excel meldet die folgenden zusammenfassenden Statistiken als Ergebnis der Regressionsanalyse:
Mehrere R
Dies ist ein Korrelationskoeffizient, der die Stärke und Richtung einer linearen Beziehung zwischen Variablen misst. Sie reicht von -1 bis 1, wobei Werte nahe -1 oder 1 auf eine starke Beziehung und Werte nahe 0 auf keine Korrelation hindeuten.
In unserer Analyse liegt der Korrelationskoeffizient bei etwa 0,65, was eine mäßig positive Korrelation zwischen unserer abhängigen Variable (Eisverkauf) und den unabhängigen Variablen (Preis und Temperatur) zeigt.
R Quadrat
R2 ist ein statistisches Maß, das uns sagt, wie gut die Daten mit dem Regressionsmodell übereinstimmen. Er ist das Quadrat des Korrelationskoeffizienten, Multiple R, und stellt den Anteil der Varianz in der abhängigen Variable dar, der durch unabhängige Variablen erklärt werden kann.
R2 reicht von 0 bis 1, wobei Werte, die näher an 1 liegen, auf eine bessere Modellanpassung hindeuten. UnserR2 liegt bei etwa 0,419, was bedeutet, dass etwa 41,9 % der Varianz der Speiseeisverkäufe durch das Modell erklärt werden können.
Bereinigtes R-Quadrat
Dies ist der R-Quadrat-Wert, bereinigt um die Anzahl der Prädiktoren im Modell. Sie ist in der Regel ein besseres Maß, wenn Modelle mit einer unterschiedlichen Anzahl von Prädiktoren verglichen werden. In unserem Fall beträgt das bereinigteR2 0,418. Dies ist unseremR2 sehr ähnlich, was darauf hindeutet, dass die unabhängigen Variablen, die wir einbezogen haben (Temperatur und Preis), für das Modell relevant sind und keinen großen Nachteil mit sich gebracht haben.
Standardfehler
Der Standardfehler misst den durchschnittlichen Abstand, den die beobachteten Werte von der Regressionslinie haben. Ein kleinerer Standardfehler ist besser, da er bedeutet, dass die Regressionslinie besser zu den Daten passt.
In unserem Fall beträgt der Standardfehler etwa 98,05, was bedeutet, dass die tatsächlichen Eisverkaufswerte um etwa 98,05 Einheiten von den vorhergesagten abweichen.
Beobachtungen
Dies bezieht sich auf die Gesamtzahl der analysierten Datenpunkte (Zeilen) im Datensatz, ohne Kopfzeilen.
ANOVA steht für Analyse der Varianz. Sie ist eine statistische Technik, die Informationen über den Grad der Variabilität innerhalb eines Regressionsmodells liefert:
Freiheitsgrade (df)
Dies ist die Anzahl der Werte in der endgültigen Berechnung, die frei variieren können. Im Kontext der ANOVA bezieht sich "Regression" df auf die Anzahl der unabhängigen Variablen im Modell, die 2 beträgt. Der "Rest" df wird berechnet, indem die Anzahl der unabhängigen Variablen und 1 von der Gesamtzahl der Beobachtungen abgezogen wird. In unserem Fall ist dies 997.
Summe der Quadrate (SS)
Dies quantifiziert die Variation. "Regression SS" misst die Variation der abhängigen Variable, die durch das Modell erklärt werden kann. Der "Rest-SS" stellt die unerklärte Variation dar.
Mittleres Quadrat (MS)
Dieser wird ermittelt, indem die Summe der Quadrate (SS) durch die Freiheitsgrade (df) geteilt wird.
F-Statistik (F)
Diese Statistik bestimmt die allgemeine Signifikanz des Modells. Ein höherer F-Wert zeigt an, dass das Modell besser zu den Daten passt.
Signifikanz F
Dies ist der P-Wert, der mit der F-Statistik verbunden ist. Ein sehr kleiner p-Wert (weniger als 0,05) zeigt an, dass dein Modell besser zu den Daten passt als ein Modell ohne unabhängige Variablen. In unserem Fall ist der Signifikanzwert F kleiner als 0,05, was bedeutet, dass das Modell gut zu den Daten passt.
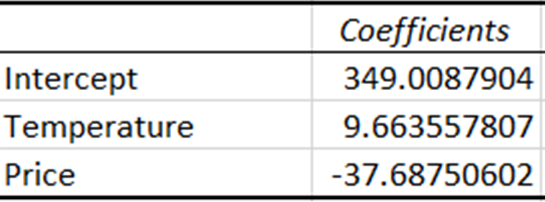
Die Koeffizienten geben die geschätzte Veränderung der abhängigen Variable bei einer Veränderung der unabhängigen Variable um eine Einheit an.
Der Koeffizient für die Temperatur zeigt, dass mit jeder Temperaturerhöhung um eine Einheit der Umsatz um etwa 9,66 Einheiten steigt. Umgekehrt zeigt der Koeffizient für den Preis, dass die Verkäufe um etwa 37,69 Einheiten zurückgehen, wenn der Preis um eine Einheit steigt.
Der Standardfehler misst den durchschnittlichen Abstand zwischen den beobachteten Werten und der Regressionslinie. Ein geringerer Standardfehler deutet auf ein besseres Modell hin.
Die t-Statistik ist der Koeffizient geteilt durch seinen Standardfehler. Eine größere t-Statistik zeigt an, dass der Koeffizient von Null verschieden ist, was bedeutet, dass er einen größeren Einfluss auf die abhängige Variable hat.
P-Werte geben die Wahrscheinlichkeit an, dass die t-Statistik genauso extrem ist wie die, die unter der Annahme der Nullhypothese (d. h. der Koeffizient für eine unabhängige Variable ist 0) beobachtet wird.
Einfach ausgedrückt: Je größer die t-Statistik und je kleiner der P-Wert, desto größer ist die Evidenz gegen die Nullhypothese, was die Schlussfolgerung stützt, dass die unabhängigen Variablen (Preis und Temperatur) einen statistisch signifikanten Einfluss auf die abhängige Variable (Speiseeisabsatz) haben.
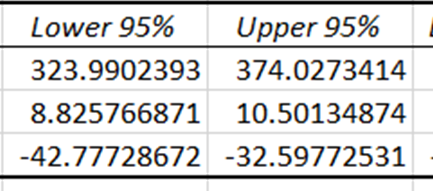
Konfidenzintervalle geben die unteren und oberen Grenzen an, innerhalb derer die wahren Koeffizienten der unabhängigen Variablen mit einem Konfidenzniveau von 95% liegen dürften. Da sich die Konfidenzintervalle für Preis und Temperatur von Null unterscheiden, haben diese Koeffizienten einen statistisch signifikanten Einfluss auf die Vorhersage der Speiseeisverkäufe.
Die Visualisierung der Beziehung zwischen zwei Variablen kann dein Verständnis des Datensatzes erheblich verbessern. Während das Analyse-ToolPak von Excel detaillierte zusammenfassende Statistiken liefert, kannst du mit einer grafischen Darstellung sofort die Stärke und Richtung einer Beziehung zwischen Variablen erkennen.
Die Erstellung eines Streudiagramms mit einer Trendlinie ist eine effektive Methode, um diese Beziehung zu visualisieren, und kann in weniger als fünf Minuten erledigt werden. Mit dieser Visualisierungstechnik kannst du auf einen Blick sehen, wie sich eine Variable auf eine andere auswirkt.
So visualisierst du die Beziehung zwischen "Eiscreme-Verkauf" und "Temperatur":
Markiere zunächst die Zellen mit den Variablen "Eiscreme-Verkauf" und "Temperatur". Navigiere dann zur Registerkarte "Einfügen" und klicke auf das Symbol "Streuungsdiagramm":
Du wirst ein einfaches Streudiagramm sehen, das wie folgt aussieht:
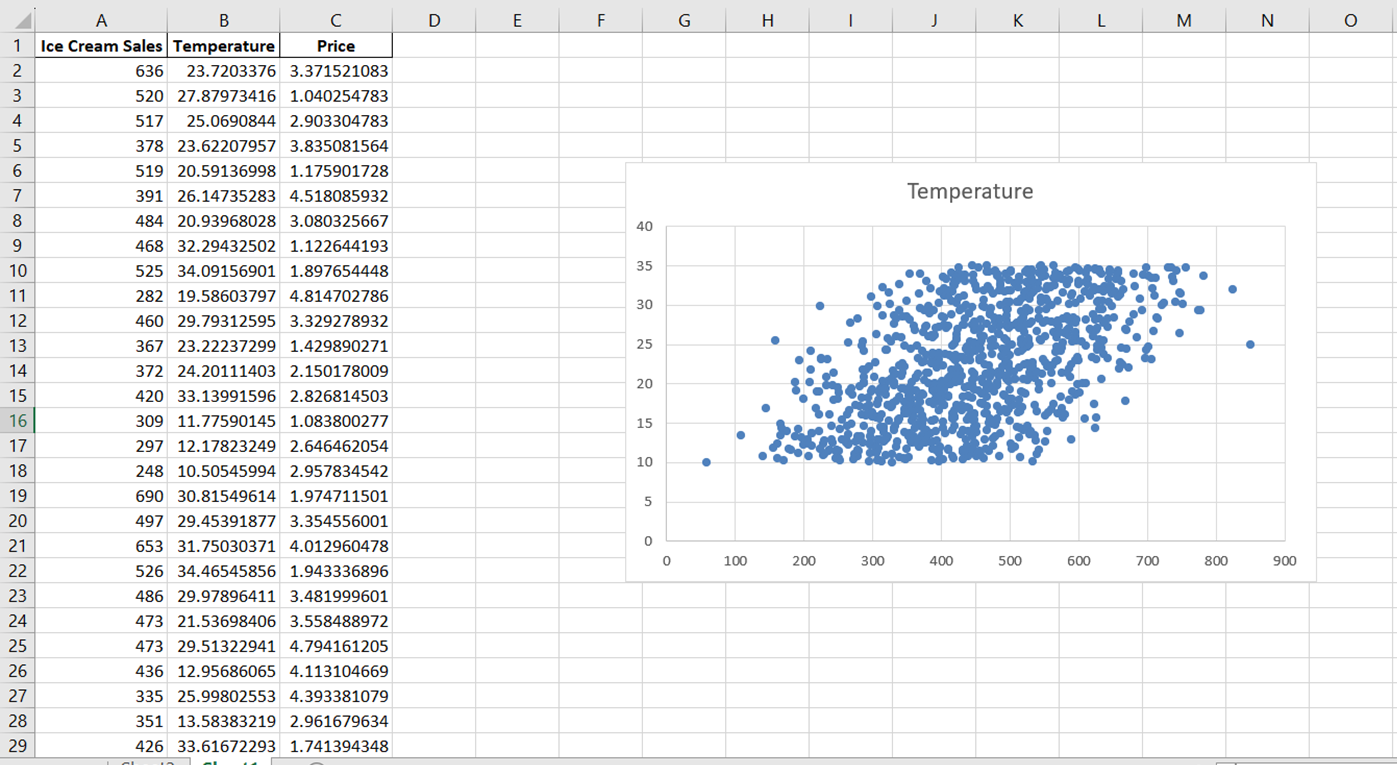
Benennen wir nun das Diagramm um, um die Beziehung, die wir visualisieren wollen, genau zu beschreiben. Klicke einfach auf den Titel des Diagramms und ändere ihn in "Beziehung zwischen Eiscremeverkäufen und Temperatur".
Um die Beschriftung der x-Achse zu ändern, navigierst du zu "Diagrammdesign". Wähle im Dropdown-Menü "Diagrammelement hinzufügen" die Option "Achsentitel" -> "Primäre Horizontale":
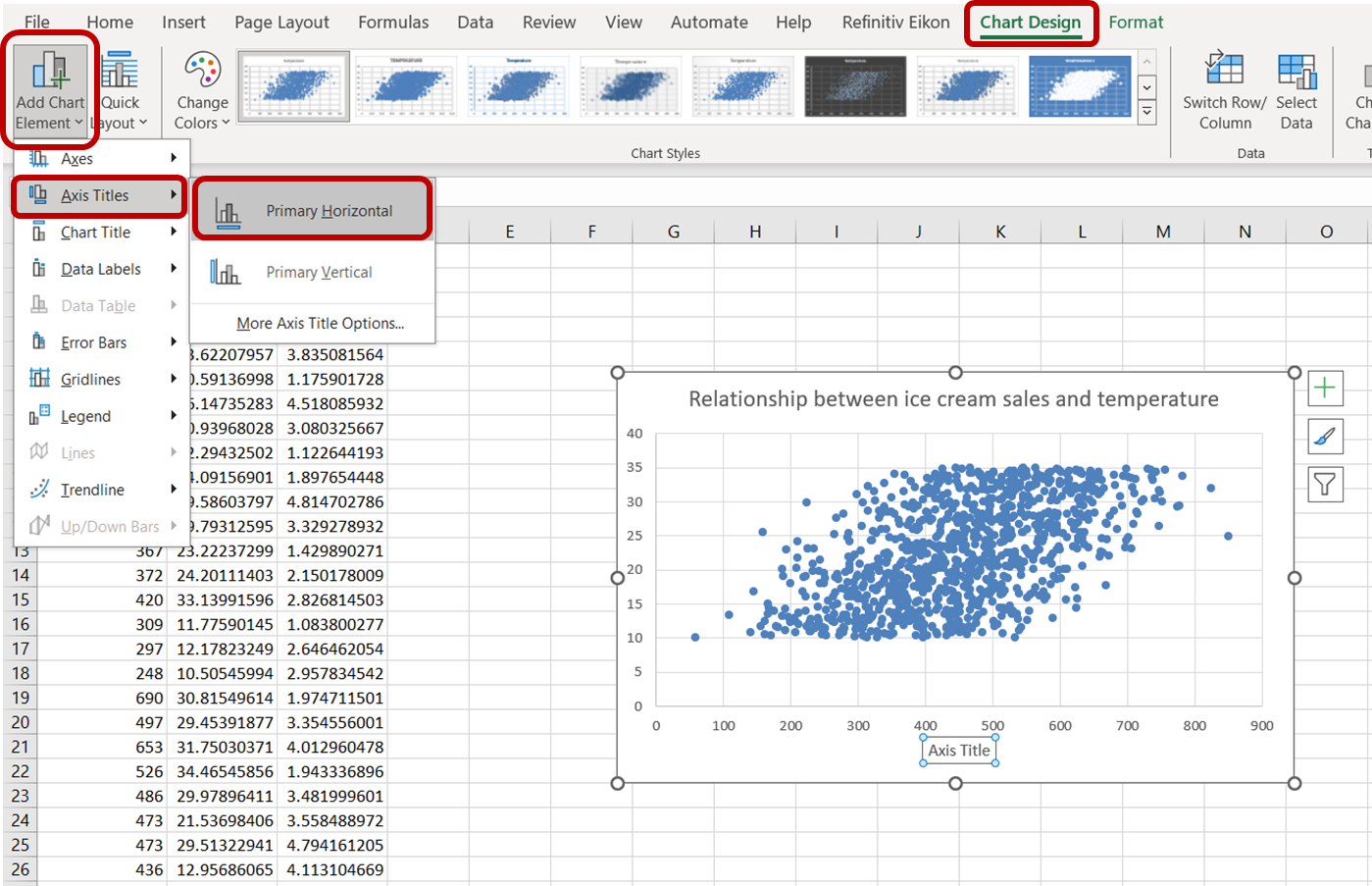
Klicke auf den Standard-Achsentitel, der angezeigt wird, und gib "Eiscremeverkäufe" ein, um die Achse genau zu beschriften. Mache dasselbe für die y-Achse, indem du "Primäre Vertikale" auswählst und den Achsentitel durch "Temperatur:" ersetzst.
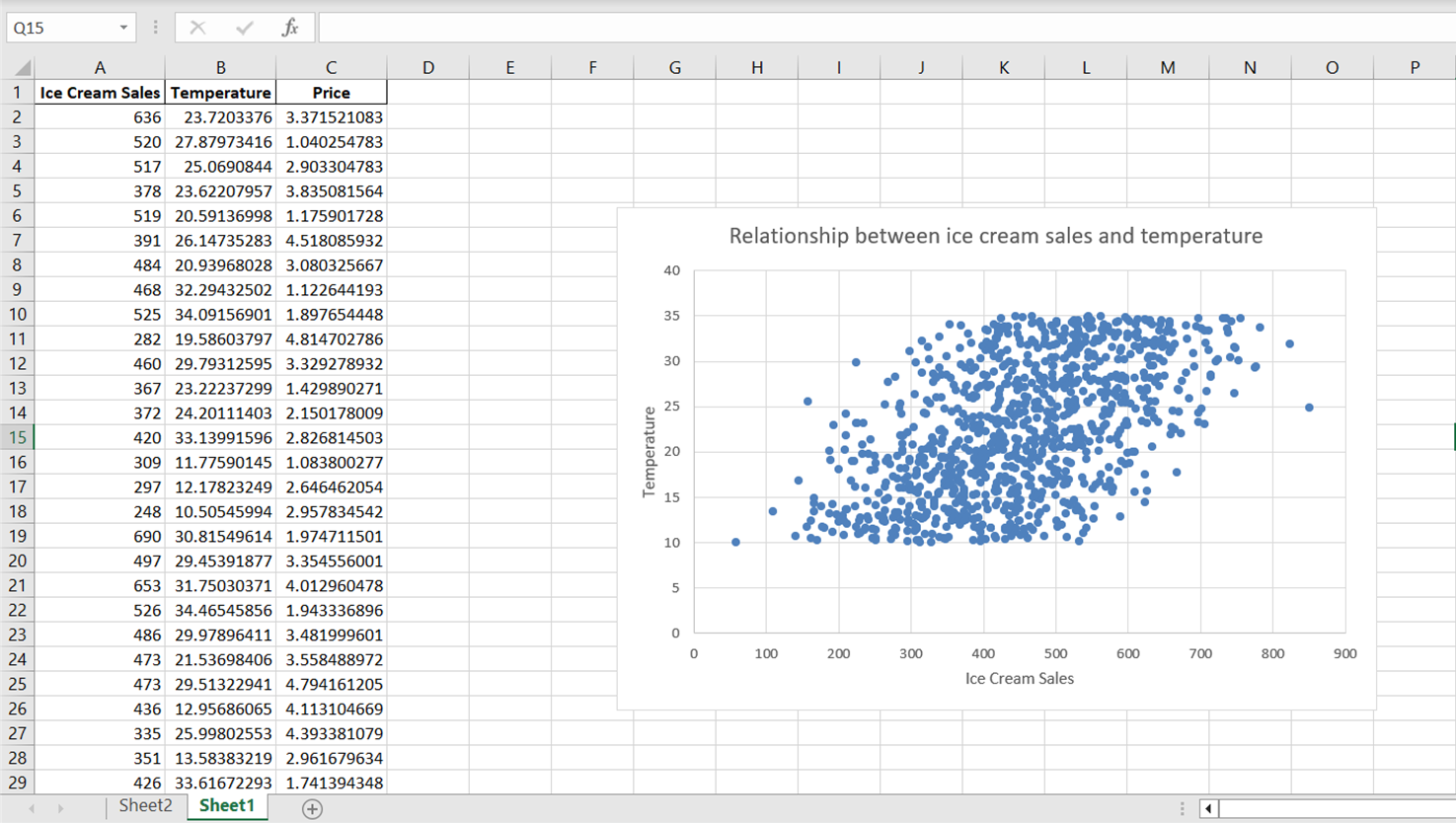
Beachte, dass das Streudiagramm zwar eine allgemeine Richtung in der Beziehung zwischen Temperatur und Speiseeisverkauf erkennen lässt, die Datenpunkte aber breit gestreut zu sein scheinen. Um diese Beziehung, einschließlich ihrer allgemeinen Richtung und Steigung, besser zusammenzufassen, können wir eine Trendlinie oder eine Linie der besten Anpassung einfügen.
Um eine Trendlinie zu diesem Diagramm hinzuzufügen, klicke einfach auf einen beliebigen Datenpunkt in diesem Streudiagramm. Mit dieser Aktion werden alle Datenpunkte im Diagramm ausgewählt. Klicke dann mit der rechten Maustaste auf die ausgewählten Datenpunkte. Wähle im erscheinenden Menü "Trendlinie hinzufügen:".
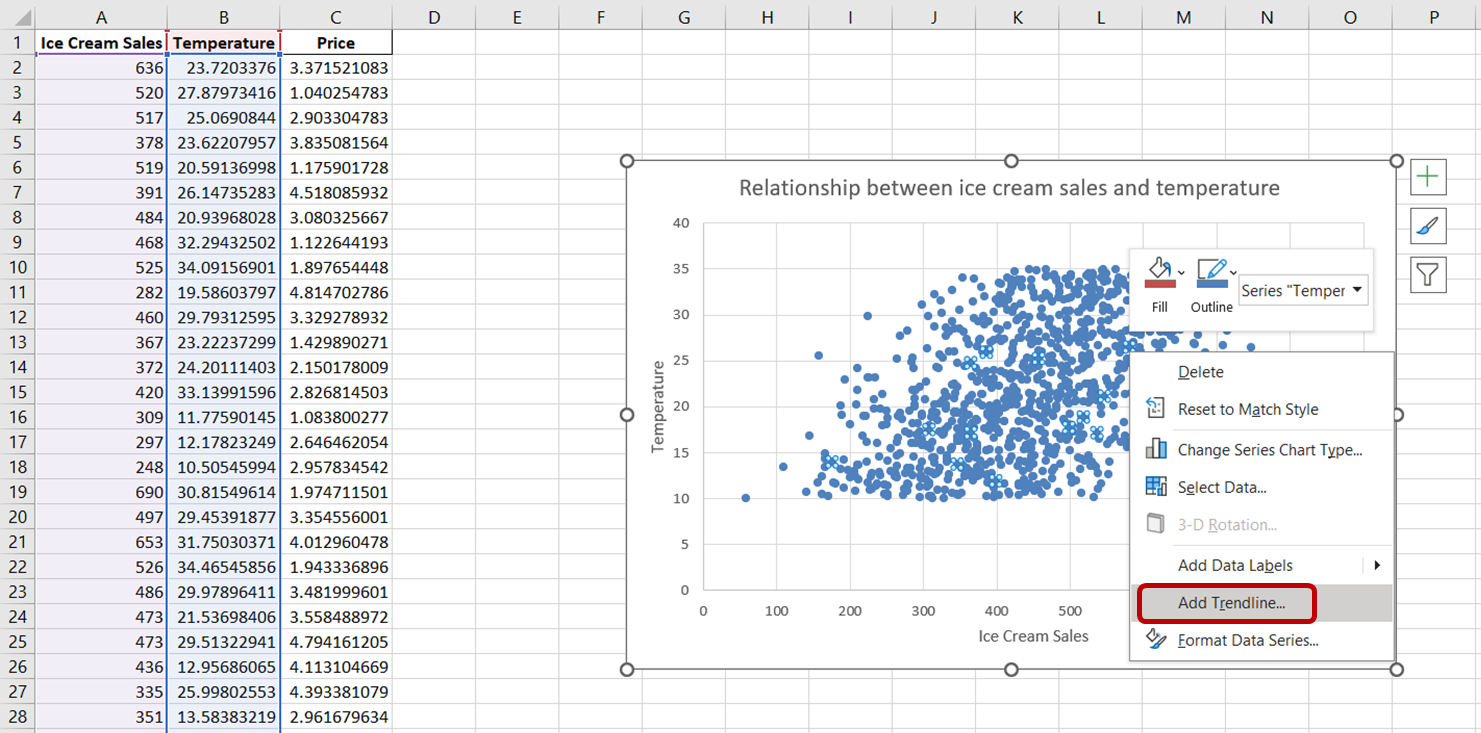
Du solltest im Diagramm eine gepunktete Linie sehen, die die allgemeine Richtung der Beziehung zwischen den Variablen anzeigt:
Die Trendlinie erscheint schwach und unauffällig. Lass uns die Formatierung für eine bessere Sichtbarkeit anpassen.
Klicke zunächst auf die Trendlinie, um sie auszuwählen. Der Aufgabenbereich "Trendlinie formatieren" wird auf der rechten Seite deines Excel-Fensters angezeigt. In diesem Aufgabenbereich wählst du die Option "Füllen & Linie". Erhöhe dann die Breite der Trendlinie auf 3pt und ändere ihre Farbe in rot:
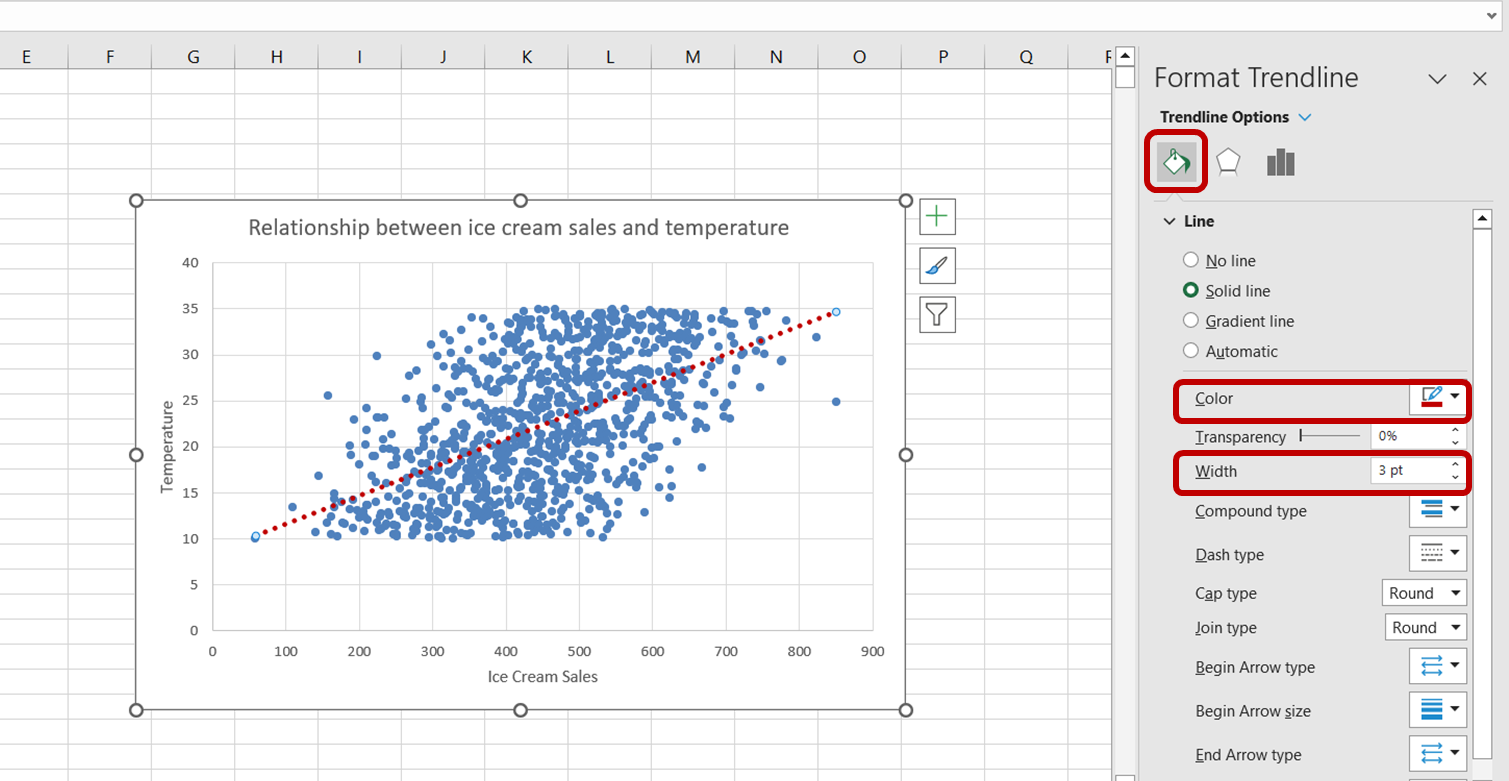
Wir haben jetzt erfolgreich eine Visualisierung erstellt, um die Beziehung zwischen Eiscreme-Verkauf und Temperatur besser zu verstehen.
Anhand der obigen Grafik können wir erkennen, dass es eine positive Beziehung zwischen Temperatur und Eisverkauf gibt. Mit steigender Temperatur scheinen auch die Eisverkäufe zu steigen, was darauf hindeutet, dass die Temperatur ein wichtiger Prädiktor für den Eisverkauf ist.
Diese Beobachtung ähnelt derjenigen, die wir aus den Ergebnissen der Regressionsanalyse im vorherigen Abschnitt abgeleitet haben.
Du weißt jetzt, wie du eine lineare Regression in Excel durchführst, verschiedene statistische Maße zur Bewertung der Modellanpassung interpretierst und die Regressionsanalyse mithilfe von Streudiagrammen und Trendlinien visualisierst.
Aber die Reise ist hier noch nicht zu Ende.
Ob du es glaubst oder nicht, wir haben nur an der Oberfläche der prädiktiven Modellierung gekratzt, und es gibt noch so viel zu lernen. Hier sind einige mögliche nächste Schritte, um dein Verständnis für das Thema zu vertiefen.
Übe die Konzepte, die du in diesem Artikel gelernt hast, um sicherzustellen, dass du sie nicht vergisst. Nimm zum Beispiel den Datensatz, der in diesem Lernprogramm verwendet wird, und erstelle ein Streudiagramm, um die Beziehung zwischen Eiscremeverkäufen und Preisen zu veranschaulichen.
Du kannst sogar noch einen Schritt weiter gehen, indem du lernst, wie du die Regressionsgleichung auf der Trendlinie darstellen kannst.
Wie wir bereits in diesem Artikel festgestellt haben, wird Excel in vielen Unternehmen eingesetzt und ist daher sehr gefragt. Wenn du Excel gut beherrschst, kannst du deine Chancen auf eine Anstellung in verschiedenen Branchen deutlich verbessern, da es weit verbreitet ist.
Wenn du bei diesem Lernprogramm auf Schwierigkeiten gestoßen bist oder dich mit den Formeln von Excel noch nicht auskennst, solltest du dich für unseren Lernpfad Excel-Grundlagen anmelden. In diesem Kurs lernst du verschiedene Techniken zur Datenvisualisierung, Pivot-Tabellen und logische Funktionen wie COUNTIFs und verschachtelte IFs kennen, die dir den Weg zur Beherrschung von Excel ebnen.
Erwerbe die Fähigkeiten, um Excel optimal zu nutzen - keine Erfahrung erforderlich.
Beginne deine Regressionsreise noch heute!
Kurs
Kurs
Tutorial
Aditya Sharma
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
Tutorial
Satyabrata Pal
Tutorial
Allan Ouko

