
Curso
Inferência para Regressão Linear em R
4 h
15.9K
A regressão linear é uma das técnicas mais simples de aprendizado de máquina. Envolve a previsão do valor de uma variável dependente com base em uma ou mais variáveis independentes.
Por exemplo, a regressão linear pode ser aplicada para prever os preços das casas com base no tamanho da casa ou para prever o peso de uma pessoa com base em sua altura. Os modelos de regressão linear são categorizados principalmente em dois tipos: regressão linear simples e múltipla.
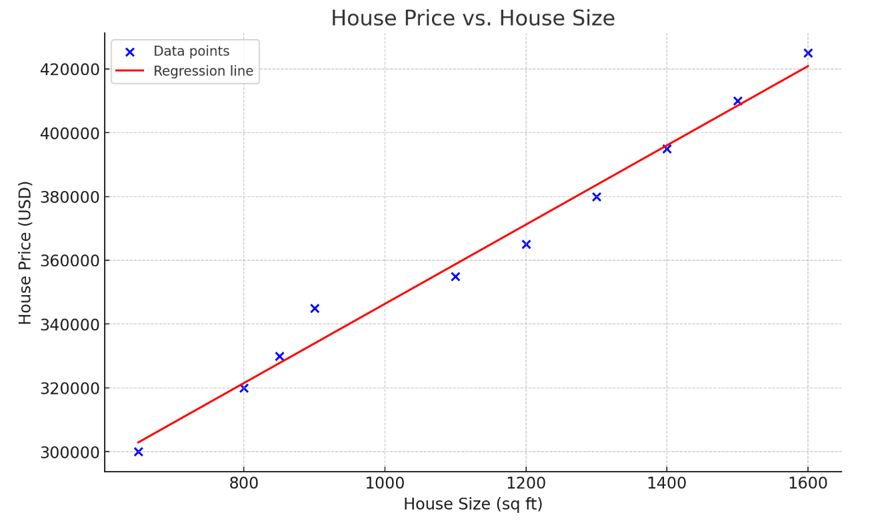
Imagem da OpenAI
O gráfico acima representa uma regressão linear simples, modelando a relação entre o tamanho da casa (variável independente) e o preço da casa (variável dependente). Conforme observado na visualização, quanto maior a casa, mais cara ela é.
A equação da linha de regressão é:
y = mx + c + ⍷
Se a fórmula acima parece familiar, é porque você provavelmente aprendeu na escola que y = mx + c é a equação de uma linha reta. Nessa equação:
⍷ representa o termo residual ou de erro. Essa é a diferença entre o valor real e o valor previsto pelo valor da regressão. distingue uma linha de regressão de uma linha reta puramente determinística, fazendo com que a relação entre x e y não seja perfeitamente previsível.
Para obter um guia mais detalhado sobre o assunto, leia nosso artigo que explica os fundamentos da regressão linear.
Aqui estão alguns fatores que tornam o Excel uma ferramenta eficaz para a realização de regressão linear:
Em 2024, o Excel era usado por mais de 731.000 empresas nos Estados Unidos e por inúmeras outras em todo o mundo, conforme relatado pelo Statista. Os executivos de todos os níveis organizacionais usam o Excel para fins de gerenciamento de dados e geração de relatórios.
Ao criar modelos preditivos como regressão linear no Excel, as empresas podem consolidar seus relatórios e atividades de modelagem preditiva em uma única plataforma. Isso permite que as organizações otimizem os fluxos de trabalho em vez de precisar alternar constantemente entre ambientes de programação e planilhas do Excel.
Se você for um iniciante no setor de dados, a simples ideia de criar um modelo preditivo pode parecer intimidadora devido à codificação envolvida. O Excel simplifica esse processo, permitindo que você trabalhe em uma interface com a qual já está familiarizado. Com o Excel, a construção de um modelo de regressão linear se torna um processo simples, que pode ser realizado com apenas alguns cliques.
O Excel oferece recursos avançados de visualização, permitindo que você faça gráficos da relação entre diferentes variáveis para entendê-las melhor. Além disso, ele simplifica a criação de relatórios, garantindo que as visualizações possam ser facilmente incorporadas em apresentações do PowerPoint para uma comunicação eficaz com as partes interessadas.
Antes de se aprofundar neste tutorial, baixe o conjunto de dados disponível neste repositório do GitHub. Esse conjunto de dados foi criado especificamente pela OpenAI para fins educacionais. Se você dominar as operações básicas de planilhas, como inserir dados, aplicar fórmulas simples e navegar pelas planilhas, poderá acompanhar melhor este tutorial.
Primeiro, precisamos ativar o Data Analysis ToolPak no Excel. Esse é um programa suplementar do Excel que fornece várias ferramentas de análise de dados, incluindo a que usaremos para regressão linear.
Para fazer isso, primeiro abra o arquivo do Excel e navegue até Arquivo -> Opções. Na caixa de diálogo Opções, selecione Suplementos -> Suplementos do Excel e clique em Ir:
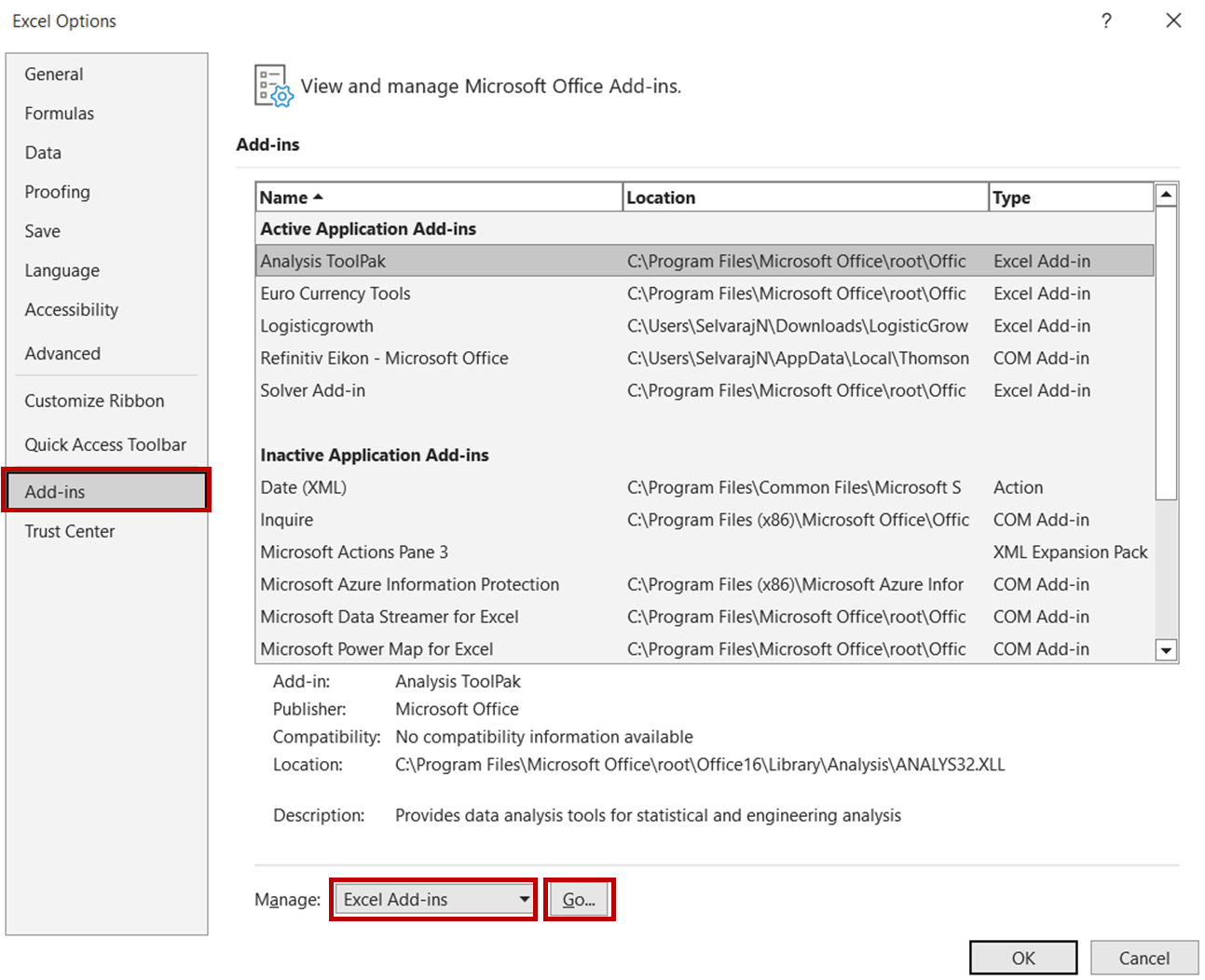
Na caixa de diálogo Add-ins, marque a opção Analysis ToolPak e clique em OK.
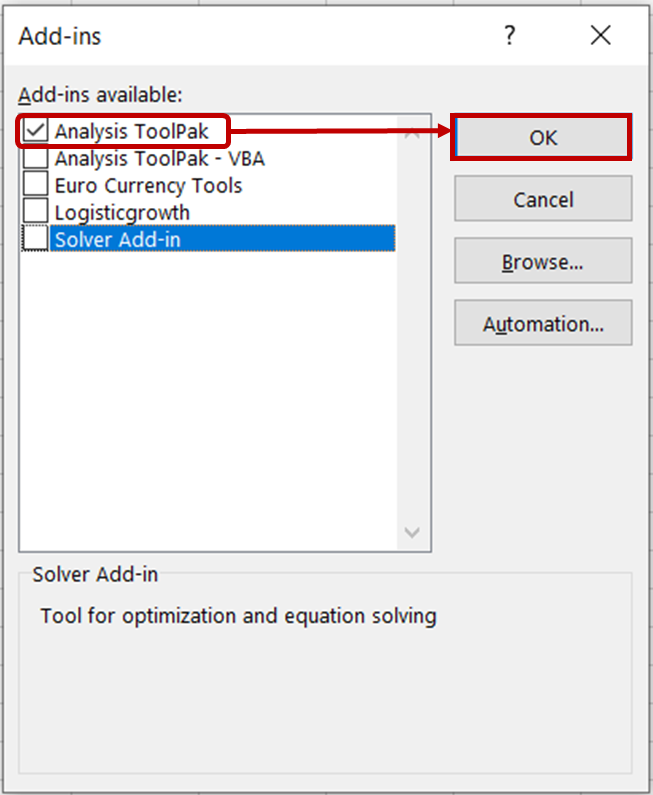
Agora você deve ver as ferramentas de análise de dados na guia Data (Dados).
Agora que ativamos o Data Analysis ToolPak, podemos continuar a executar a regressão linear no conjunto de dados. Abra o conjunto de dados de vendas de sorvete e navegue até a guia Data (Dados ). No grupo Análise, clique em Análise de dados.

Em seguida, selecione Regressão na lista de ferramentas de análise e clique em OK.
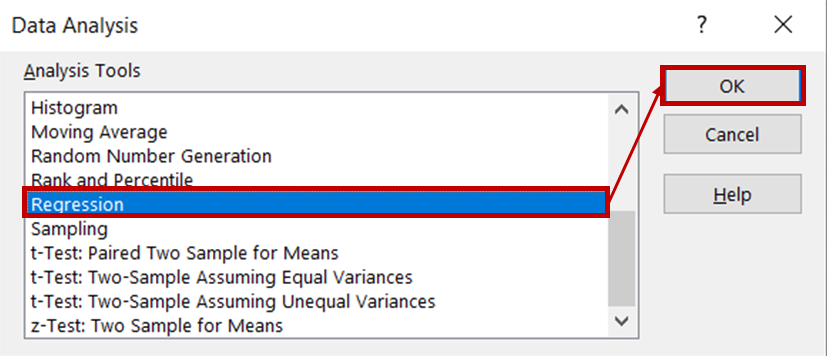
Na caixa de diálogo de regressão, para o intervalo Y de entrada, selecione a coluna que contém os dados de vendas de sorvete. Para o intervalo Input X, selecione as colunas que contêm dados de temperatura e preço. Certifique-se de que a caixa Rótulos esteja marcada, pois isso ajudará o Excel a reconhecer os cabeçalhos e a tratar as linhas restantes como dados numéricos. Na seção Opções de saída , selecione New Worksheet Ply para ver os resultados exibidos em uma nova planilha.
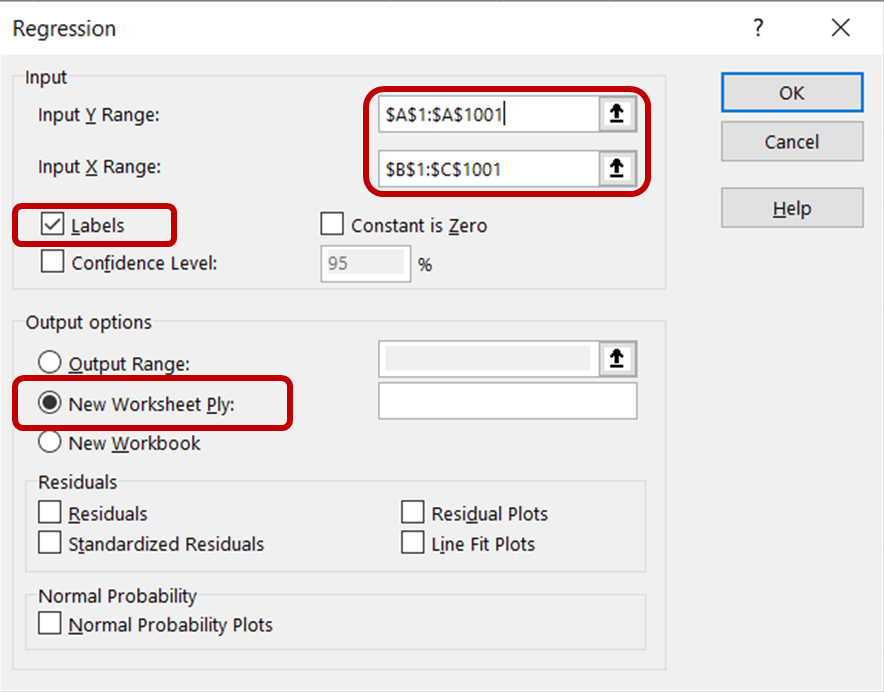
Em seguida, clique em OK para executar a análise de regressão no conjunto de dados.
Depois de realizar a regressão, você verá uma nova planilha aparecer automaticamente no arquivo do Excel, mostrando uma série de tabelas de resultados com a seguinte aparência:
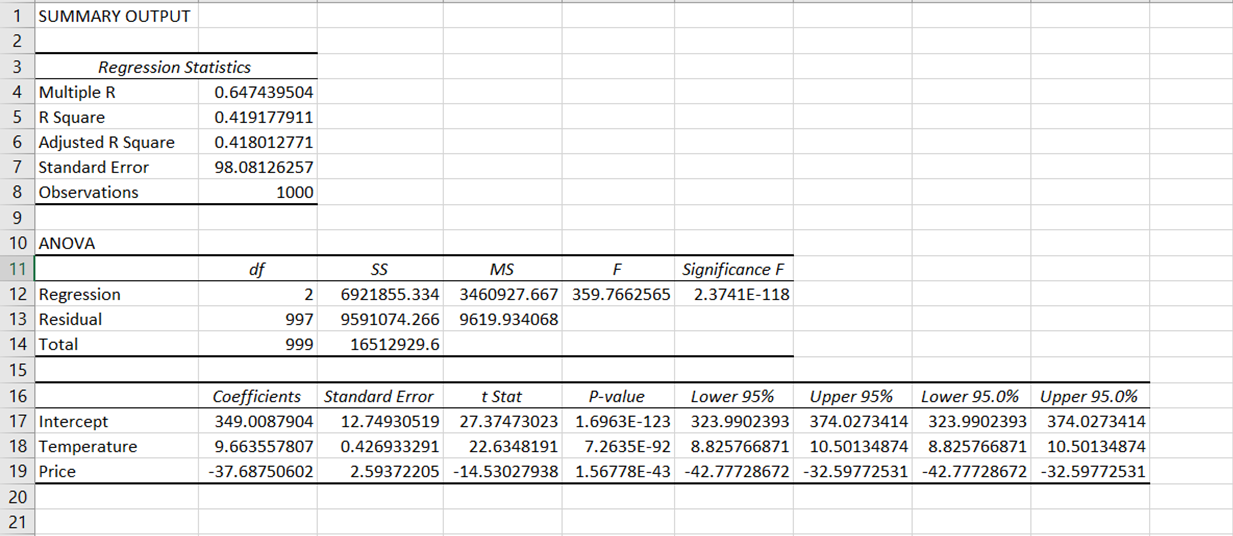
Os resultados da saída da regressão foram divididos em vários componentes: estatísticas de regressão, ANOVA, coeficientes, erro padrão, t Stat, valor P e intervalo de confiança.
Vamos examinar cada um desses componentes com mais detalhes:
O Excel informa as seguintes estatísticas resumidas como resultado da análise de regressão:
Múltiplo R
Esse é um coeficiente de correlação que mede a força e a direção de uma relação linear entre variáveis. Ele varia de -1 a 1, sendo que valores próximos a -1 ou 1 indicam uma relação forte e valores próximos a 0 sugerem que não há correlação.
Em nossa análise, o coeficiente de correlação é de aproximadamente 0,65, mostrando uma correlação positiva moderada entre nossa variável dependente (vendas de sorvete) e as variáveis independentes (preço e temperatura).
R Quadrado
O R2 é uma medida estatística que nos informa quão bem os dados se ajustam ao modelo de regressão. É o quadrado do coeficiente de correlação, Multiple R, e representa a proporção da variação na variável dependente que pode ser explicada pelas variáveis independentes.
O R2 varia de 0 a 1, sendo que os valores mais próximos de 1 sugerem um melhor ajuste do modelo. NossoR2 é de aproximadamente 0,419, o que significa que cerca de 41,9% da variação nas vendas de sorvete pode ser explicada pelo modelo.
Quadrado R ajustado
Esse é o valor R-quadrado ajustado para o número de preditores no modelo. Em geral, é uma medida melhor ao comparar modelos com diferentes números de preditores. Em nosso caso, oR2 ajustado é de 0,418. Isso é muito semelhante ao nossoR2, sugerindo que as variáveis independentes que incluímos (temperatura e preço) são relevantes para o modelo e não introduziram uma grande penalidade.
Erro padrão
O erro padrão mede a distância média que os valores observados ficam da linha de regressão. Um erro padrão menor é melhor, pois significa que a linha de regressão é um ajuste mais próximo dos dados.
Em nosso caso, o erro padrão é de aproximadamente 98,05, indicando que os valores reais de vendas de sorvete se desviam dos valores previstos em cerca de 98,05 unidades.
Observações
Refere-se ao número total de pontos de dados (linhas) analisados no conjunto de dados, excluindo os cabeçalhos.
ANOVA significa Análise de Variância. É uma técnica estatística que fornece informações sobre o nível de variabilidade em um modelo de regressão:
Graus de liberdade (df)
Isso representa o número de valores no cálculo final que podem variar livremente. No contexto da ANOVA, "Regressão" df refere-se ao número de variáveis independentes no modelo, que é 2. O df "residual" é calculado subtraindo-se o número de variáveis independentes e 1 do número total de observações. No nosso caso, é 997.
Soma de quadrados (SS)
Isso quantifica a variação. O "SS de regressão" mede a variação na variável dependente que pode ser explicada pelo modelo. O "SS residual" representa a variação não explicada.
Quadrado médio (MS)
Isso é obtido dividindo-se a soma dos quadrados (SS) pelos graus de liberdade (df).
Estatística F (F)
Essa estatística determina a importância geral do modelo. Um valor F mais alto indica que o modelo se ajusta melhor aos dados.
Significância F
Esse é o valor P associado à estatística F. Um valor p muito pequeno (menor que 0,05) indica que seu modelo se ajusta melhor aos dados do que um modelo sem variáveis independentes. Em nosso caso, o valor de significância F é menor que 0,05, indicando que o modelo se ajusta bem aos dados.
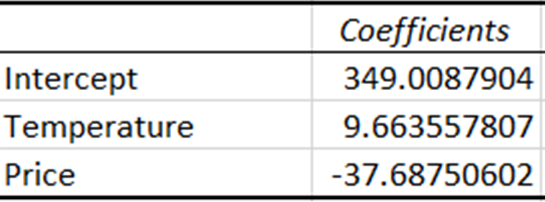
Os coeficientes representam a quantidade estimada de alteração na variável dependente para uma alteração de uma unidade na variável independente.
O coeficiente de temperatura indica que, a cada aumento de uma unidade na temperatura, as vendas aumentam em cerca de 9,66 unidades. Por outro lado, o coeficiente do preço indica que as vendas diminuem em aproximadamente 37,69 unidades com um aumento de uma unidade no preço.
O erro padrão mede a distância média entre os valores observados e a linha de regressão. Um erro padrão menor indica um modelo melhor.
A estatística t é o coeficiente dividido por seu erro padrão. Uma estatística t maior indica que o coeficiente é diferente de zero, o que significa que ele tem um impacto maior sobre a variável dependente.
Os valores de P nos informam a probabilidade de observar uma estatística t tão extrema quanto a observada sob a suposição de que a hipótese nula é verdadeira (ou seja, o coeficiente de uma variável independente é 0).
Em termos simples, quanto maior for a estatística t e menor for o valor P, maior será a evidência contra a hipótese nula, apoiando a conclusão de que as variáveis independentes (preço e temperatura) têm um impacto estatisticamente significativo sobre a variável dependente (vendas de sorvete).
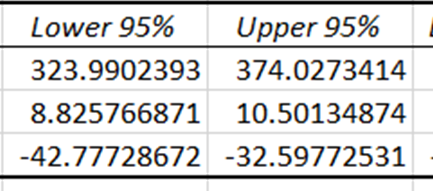
Os intervalos de confiança fornecem os limites inferior e superior dentro dos quais se espera que os coeficientes verdadeiros das variáveis independentes caiam, com um nível de confiança de 95%. Como os intervalos de confiança para preço e temperatura são diferentes de zero, esses coeficientes têm um impacto estatisticamente significativo na previsão de vendas de sorvete.
Visualizar a relação entre duas variáveis pode melhorar muito a compreensão que você tem do conjunto de dados. Embora o Analysis ToolPak do Excel forneça estatísticas resumidas detalhadas, uma representação gráfica pode mostrar instantaneamente a você a força e a direção de uma relação entre variáveis.
A criação de um gráfico de dispersão com uma linha de tendência é uma maneira eficaz de visualizar essa relação e pode ser feita em menos de cinco minutos. Essa técnica de visualização permite que você veja rapidamente como uma variável afeta outra.
Veja como você pode visualizar a relação entre "Vendas de sorvete" e "Temperatura":
Primeiro, destaque as células que contêm as variáveis "Ice Cream Sales" (Vendas de sorvete) e "Temperature" (Temperatura). Em seguida, navegue até a guia "Insert" (Inserir) e clique no ícone do gráfico "Scatter" (Dispersão):
Você verá um gráfico de dispersão simples com a seguinte aparência:
Vamos agora renomear o gráfico para descrever com precisão a relação que estamos visualizando. Basta clicar no título do gráfico e alterá-lo para "Relação entre as vendas de sorvete e a temperatura".
Em seguida, para alterar o rótulo do eixo x, navegue até "Chart Design". No menu suspenso "Add Chart Element" (Adicionar elemento de gráfico), selecione "Axis Titles" (Títulos de eixo) -> "Primary Horizontal" (Horizontal primário):
Clique no título padrão do eixo que aparece e digite "Ice Cream Sales" (Vendas de sorvete) para rotular o eixo com precisão. Faça o mesmo com o eixo y selecionando "Primary Vertical" e substituindo o título do eixo por "Temperature:"
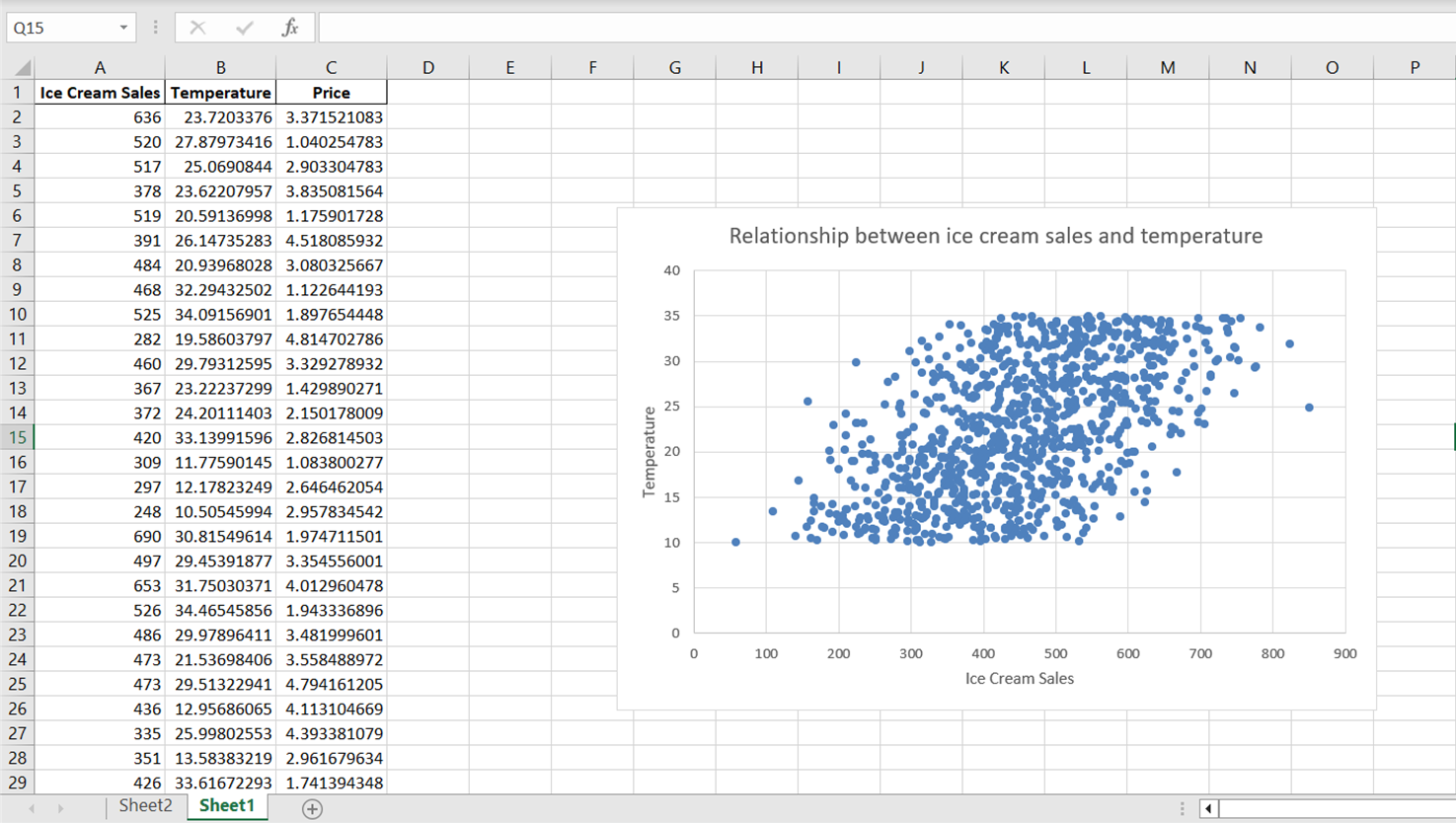
Observe que, embora o gráfico de dispersão revele uma direção geral na relação entre a temperatura e as vendas de sorvete, os pontos de dados parecem estar amplamente dispersos. Para resumir melhor essa relação, incluindo sua direção geral e inclinação, vamos incorporar uma linha de tendência ou uma linha de melhor ajuste.
Para adicionar uma linha de tendência a esse gráfico, basta clicar em qualquer ponto de dados nesse gráfico de dispersão. Essa ação selecionará todos os pontos de dados no gráfico. Em seguida, clique com o botão direito do mouse nos pontos de dados selecionados. No menu que aparece, escolha "Add Trendline:" (Adicionar linha de tendência).
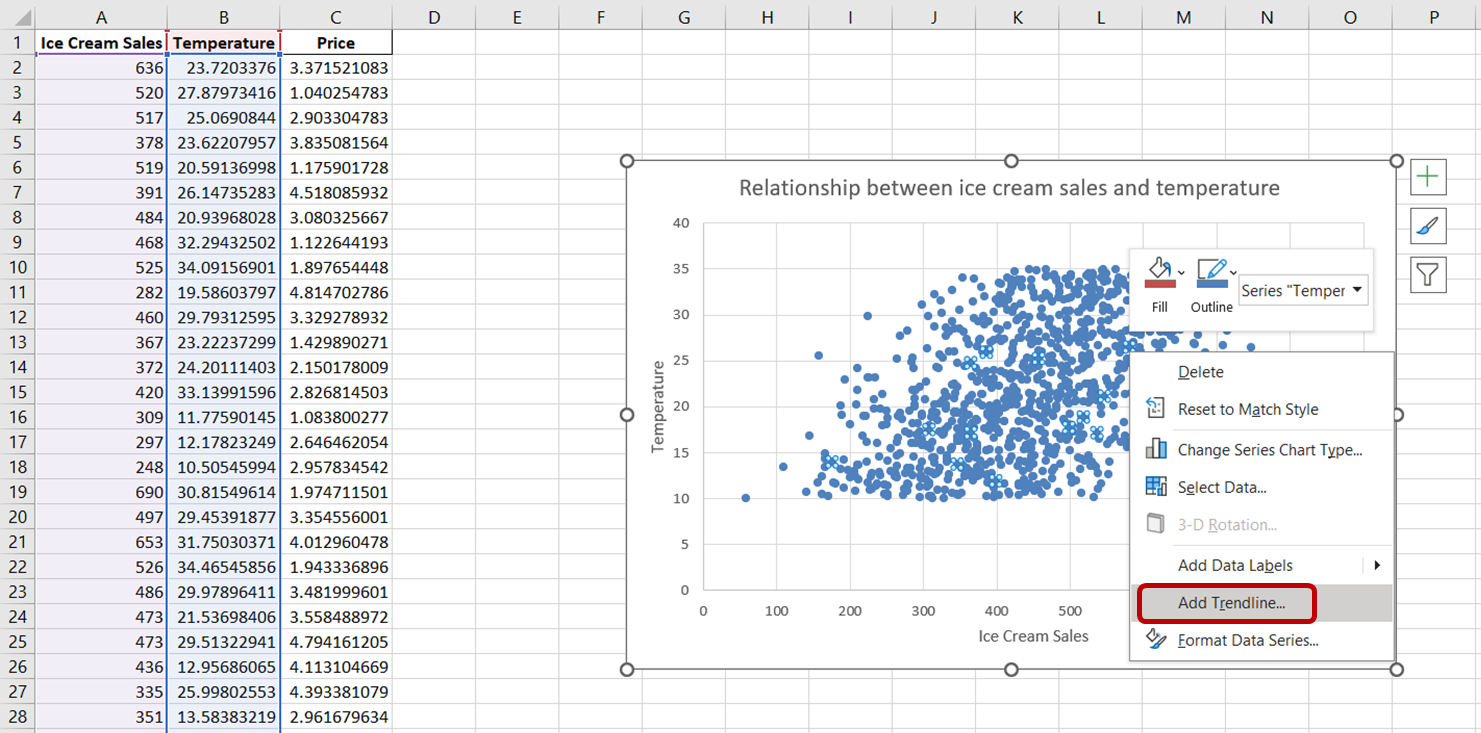
Você deverá ver uma linha pontilhada aparecer no gráfico, ilustrando a direção geral da relação entre as variáveis:
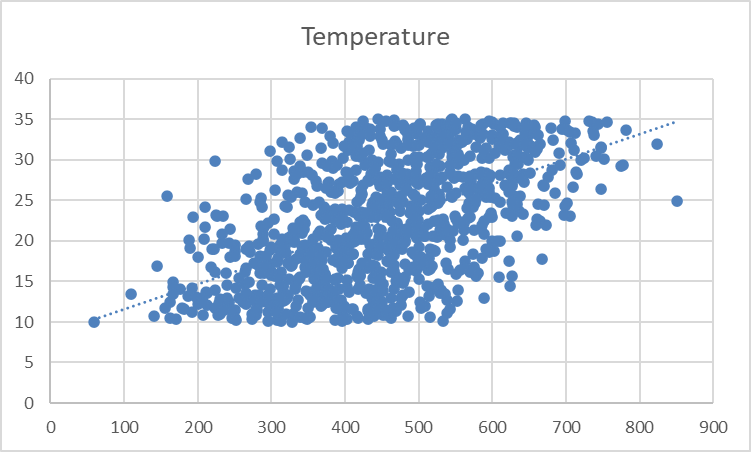
A linha de tendência parece fraca e sutil. Vamos ajustar sua formatação para melhorar a visibilidade.
Primeiro, clique na linha de tendência para selecioná-la. O painel de tarefas "Formatar linha de tendência" aparecerá no lado direito da janela do Excel. Nesse painel de tarefas, selecione a opção "Fill & Line" (Preenchimento e linha). Em seguida, aumente a largura da linha de tendência para 3 pontos e altere sua cor para vermelho:
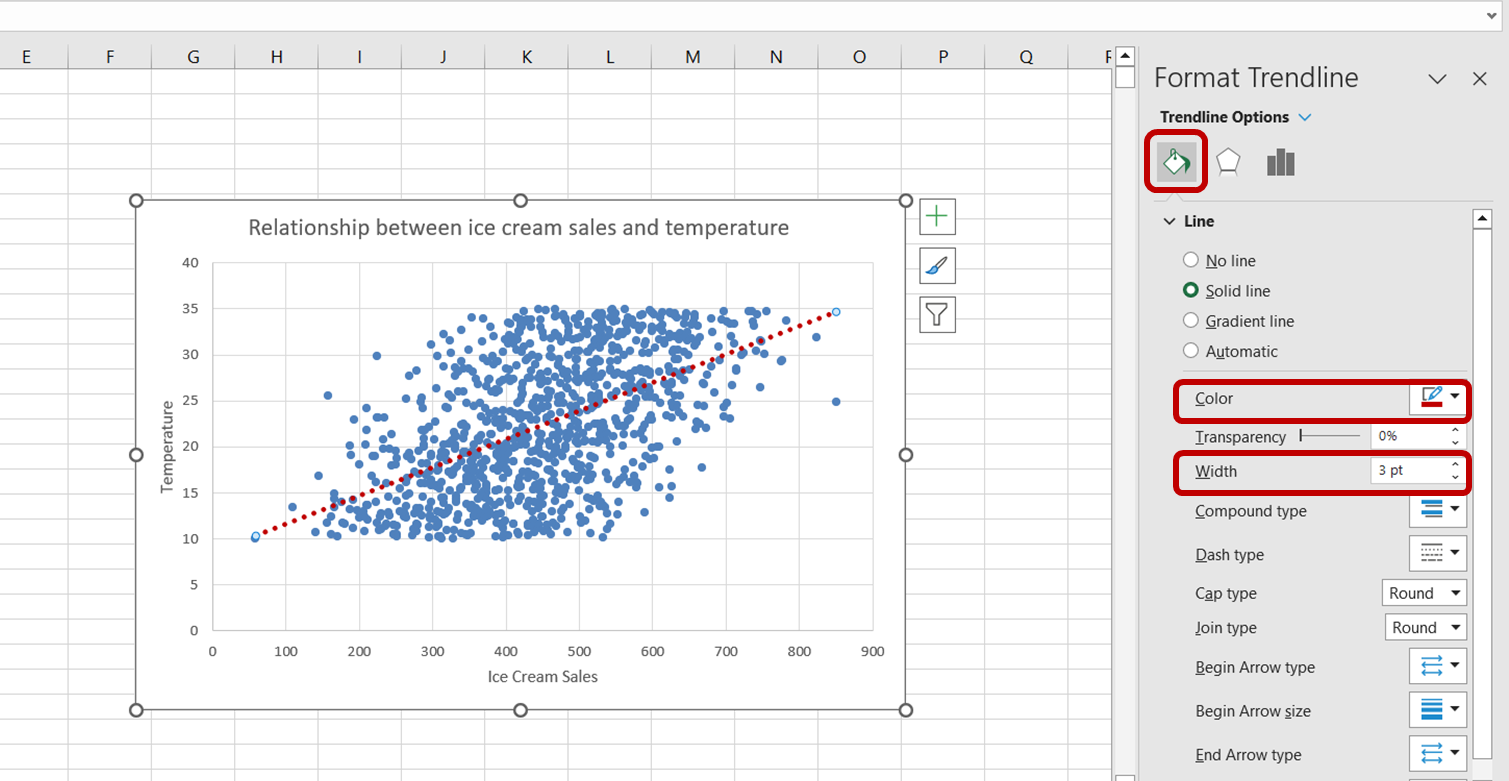
Agora, criamos com sucesso uma visualização para entender melhor a relação entre as vendas de sorvete e a temperatura.
Apenas observando o gráfico acima, podemos dizer que há uma relação positiva entre a temperatura e as vendas de sorvete. Conforme a temperatura aumenta, parece que as vendas de sorvete também aumentam, indicando que a temperatura é um indicador significativo das vendas de sorvete.
Observe que essa observação é semelhante à que derivamos dos resultados da análise de regressão na seção anterior.
Agora você tem uma sólida noção de como realizar a regressão linear no Excel, interpretar várias medidas estatísticas para avaliar o ajuste de um modelo e visualizar a análise de regressão usando gráficos de dispersão e linhas de tendência.
Mas a jornada não termina aqui.
Acredite você ou não, a modelagem preditiva está apenas começando, e há muito mais a aprender. Aqui estão algumas possíveis próximas etapas para você aprofundar seu conhecimento sobre o assunto.
Pratique os conceitos que você aprendeu neste artigo para garantir que não os esqueça. Por exemplo, pegue o conjunto de dados usado neste tutorial e crie um gráfico de dispersão para ilustrar a relação entre as vendas e os preços do sorvete.
Você pode até mesmo dar um passo adiante, aprendendo a exibir a equação de regressão na linha de tendência.
Como já foi dito anteriormente neste artigo, o uso extensivo do Excel em várias organizações faz com que ele seja muito requisitado. Ter um bom domínio do Excel pode aumentar significativamente suas chances de emprego em vários setores, devido à sua ampla aplicação.
Se você encontrou dificuldades ao seguir este tutorial ou se ainda não se sente confortável com as fórmulas do Excel, considere a possibilidade de se inscrever em nosso curso de aprendizado de Fundamentos do Excel. Este curso apresentará a você várias técnicas de visualização de dados, tabelas dinâmicas e funções lógicas, como COUNTIFs e IFs aninhados, preparando o caminho para o domínio do Excel.
Adquira as habilidades para maximizar o Excel - não é necessário ter experiência.
Comece sua jornada de regressão hoje mesmo!
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Eladio Montero Porras
Tutorial
Vidhi Chugh
Tutorial
Chloe Lubin
Tutorial
Abid Ali Awan
Tutorial
Natassha Selvaraj


