
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Llama 3.1 ist eine gute Wahl für RAG, eine Technik, die Retrievalsysteme mit den textgenerierenden Fähigkeiten von Sprachmodellen kombiniert, um genauere und relevantere Ergebnisse zu gewährleisten.
Bei RAG durchsucht ein Retrievalsystem zunächst große Datensätze, um die relevantesten Informationen zu finden, die das Sprachmodell dann verwendet, um die endgültige Antwort zu generieren. Dies ist besonders nützlich für Aufgaben wie die Beantwortung von Fragen, den Aufbau von Chatbots und die Bewältigung informationslastiger Aufgaben, bei denen herkömmliche Sprachmodelle veraltete oder irrelevante Antworten geben könnten.
Mit seiner Fähigkeit, bis zu 128K Token zu verarbeiten und mehrere Sprachen zu unterstützen, verbessert Llama 3.1 die Qualität und Zuverlässigkeit von KI-generierten Inhalten in RAG-Systemen.
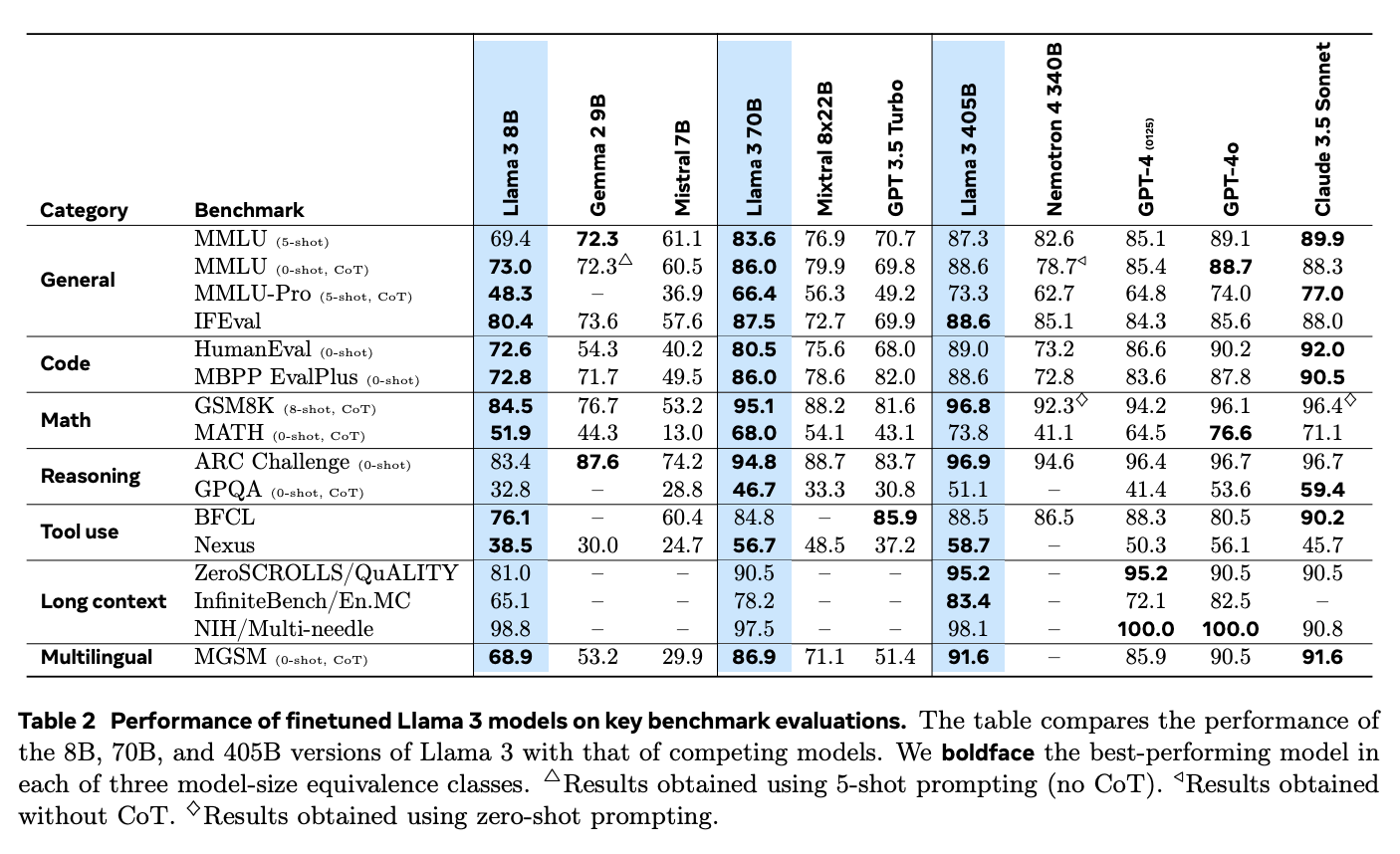
Quelle: Die Llama 3 Herde von Modellen
Darüber hinaus hebt sich Llama 3.1 bei RAG-Anwendungen im Vergleich zu Closed-Source-Modellen wie GPT-4o und Claude 3.5 Sonnet. Dank seines ausgeprägten logischen Denkvermögens und seiner Fähigkeit, längere Texte zu verarbeiten, kann er komplexe Fragen besser bearbeiten und relevantere Antworten geben.
Beim Needle-in-a-Haystack (NIH)-Benchmark, bei dem die Fähigkeit eines Modells getestet wird, bestimmte Informationen ("Nadeln") in großen Textmengen ("Heuhaufen") zu finden, glänzt Llama 3.1 mit einer nahezu perfekten Trefferquote über alle Modellgrößen hinweg. Das zeigt, dass sie komplexe Suchaufgaben bewältigen kann und damit ideal für RAG-Systeme ist, die präzise Informationen aus großen Datenbeständen extrahieren müssen.
Auch im Multi-Nadel-Benchmark, bei dem mehrere Informationen genau abgerufen werden müssen, schnitt das Modell außergewöhnlich gut ab. Die nahezu perfekten Ergebnisse in diesem Test sind ein weiterer Beweis für seine Fähigkeit, komplexe Abrufaufgaben zu bewältigen.
Um eine RAG-Anwendung mit Llama 3.1 einzurichten, sind mehrere Schritte erforderlich. Dazu gehört das Herunterladen des Llama 3.1-Modells auf deinen lokalen Rechner, das Einrichten der Umgebung, das Laden der notwendigen Bibliotheken und das Erstellen eines Abrufmechanismus. Schließlich kombinieren wir dies mit einem Sprachmodell, um eine vollständige Anwendung zu erstellen.
Im Folgenden findest du eine klare Schritt-für-Schritt-Anleitung, die dir hilft, eine RAG-Anwendung mit Llama 3.1 zu implementieren.
Als erstes installierst du die Ollama-Anwendung, mit der wir Llama 3.1 und andere Open-Source-Sprachmodelle auf deinem lokalen Rechner ausführen können. Du kannst die Ollama App von ihrer offiziellen Website.
Wenn du Ollama installiert und geöffnet hast, musst du als Nächstes das Llama 3.1 Modell auf deinen lokalen Rechner herunterladen. Für dieses Lernprogramm verwenden wir die Version mit 8B Parametern. Um sie herunterzuladen, öffne dein Terminal und führe die folgende Befehlszeile aus:
ollama run llama3.1Nachdem das Modell heruntergeladen wurde, können wir es mit Langchain verbinden. Wie das geht, zeigen wir dir in späteren Abschnitten.
Bevor du beginnst, solltest du sicherstellen, dass du die richtigen Python-Bibliotheken installiert hast. Wir brauchen Bibliotheken wie langchain, langchain_community, langchain-ollama, langchain_openai. Wenn du sie noch nicht installiert hast, kannst du das unter pip mit diesem Befehl tun:
pip install langchain langchain_community langchain-openai scikit-learn langchain-ollamaDer erste Schritt bei der Erstellung deines RAG-Systems besteht darin, die Dokumente zu laden, die wir als Wissensbasis verwenden wollen. In diesem Beispiel werden wir Webseiten als Quelle verwenden.
So geht's:
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
"<https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/>",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]Hier wird WebBaseLoader verwendet, um Inhalte von jeder angegebenen URL abzurufen. Die daraus resultierenden verschachtelten Listen von Dokumenten werden dann zu einer einzigen, flachen Liste namens docs_list zusammengefasst, die uns eine Liste von Dokumenten liefert.
Um den Suchprozess effizienter zu gestalten, teilen wir die Dokumente mit Hilfe von RecursiveCharacterTextSplitter in kleinere Brocken auf. So kann das System den Text besser verarbeiten und durchsuchen.
Wir können den Textsplitter einrichten, indem wir die Stückgröße und die Überlappung angeben. Im folgenden Code richten wir zum Beispiel einen Textsplitter mit einer Stückgröße von 250 Zeichen und ohne Überlappung ein.
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)Als Nächstes müssen wir die Textabschnitte in Einbettungenumwandeln, die dann in einem Vektorspeicher abgelegt werden, damit wir sie schnell und effizient auf der Grundlage von Ähnlichkeiten abrufen können.
Dazu verwenden wir OpenAIEmbeddings, um Einbettungen für jedes Textstück zu erzeugen, die dann in einem SKLearnVectorStore gespeichert werden. Der Vektorspeicher ist so eingerichtet, dass er für jede Abfrage die 4 relevantesten Dokumente zurückgibt, indem er mit as_retriever(k=4) konfiguriert wird.
from langchain_community.vectorstores import SKLearnVectorStore
from langchain_openai import OpenAIEmbeddings
# Create embeddings for documents and store them in a vector store
vectorstore = SKLearnVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(openai_api_key="api_key"),
)
retriever = vectorstore.as_retriever(k=4)In diesem Schritt richten wir den LLM ein und erstellen eine Eingabeaufforderungsvorlage, um Antworten auf der Grundlage der abgerufenen Dokumente zu generieren.
Zuerst müssen wir eine Vorlage für die Eingabeaufforderung definieren, die dem LLM vorgibt, wie er seine Antworten formatieren soll. Diese Vorlage sagt dem Modell, dass es die bereitgestellten Dokumente nutzen soll, um Fragen kurz und in maximal drei Sätzen zu beantworten. Wenn das Modell keine Antwort findet, sollte es einfach sagen, dass es die Antwort nicht kennt.
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for the LLM
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)Als Nächstes verbinden wir uns mit dem Llama 3.1 Modell über ChatOllama von Langchain, das wir mit einer Temperatureinstellung von 0 konfiguriert haben, um einheitliche Antworten zu erhalten.
# Initialize the LLM with Llama 3.1 model
llm = ChatOllama(
model="llama3.1",
temperature=0,
)Zum Schluss erstellen wir eine Kette, die die Prompt-Vorlage mit der LLM kombiniert und StrOutputParser verwendet, um sicherzustellen, dass die Ausgabe ein sauberer, einfacher String ist, der für die Anzeige geeignet ist.
# Create a chain combining the prompt template and LLM
rag_chain = prompt | llm | StrOutputParser()In diesem Schritt werden wir den Retriever und die RAG-Kette kombinieren, um eine vollständige RAG-Anwendung zu erstellen. Dazu erstellen wir eine Klasse namens RAGApplication , die sowohl das Abrufen von Dokumenten als auch das Generieren von Antworten übernimmt.
Die Klasse RAGApplication verfügt über die Methode run, die die Frage des Benutzers aufnimmt, den Retriever verwendet, um relevante Dokumente zu finden, und dann den Text aus diesen Dokumenten extrahiert. Dann gibt es die Frage und den Text des Dokuments an die RAG-Kette weiter, um eine präzise Antwort zu generieren.
# Define the RAG application class
class RAGApplication:
def __init__(self, retriever, rag_chain):
self.retriever = retriever
self.rag_chain = rag_chain
def run(self, question):
# Retrieve relevant documents
documents = self.retriever.invoke(question)
# Extract content from retrieved documents
doc_texts = "\\n".join([doc.page_content for doc in documents])
# Get the answer from the language model
answer = self.rag_chain.invoke({"question": question, "documents": doc_texts})
return answerZum Schluss können wir unsere RAG-Anwendung mit einigen Beispielfragen testen, um sicherzustellen, dass sie richtig funktioniert. Du kannst die Prompt-Vorlage oder die Abrufeinstellungen anpassen, um die Leistung zu verbessern oder die Anwendung an bestimmte Bedürfnisse anzupassen.
# Initialize the RAG application
rag_application = RAGApplication(retriever, rag_chain)
# Example usage
question = "What is prompt engineering"
answer = rag_application.run(question)
print("Question:", question)
print("Answer:", answer)Question: What is prompt engineering
Answer: Prompt engineering refers to methods for communicating with Large Language Models (LLMs) to steer their behavior towards desired outcomes without updating the model weights. It's an empirical science that requires experimentation and heuristics, aiming at alignment and model steerability. The goal is to optimize prompts to achieve specific results, often using techniques like iterative prompting or external tool use.Die fortschrittlichen Funktionen von Llama 3.1 und die Unterstützung für RAG machen es ideal für verschiedene wirkungsvolle Anwendungen.
Für Chatbot-EntwicklungDie Integration von Llama 3.1 mit RAG ermöglicht es Chatbots, durch den Zugriff auf externe Datenbanken oder Wissensdatenbanken genauere und kontextbezogene Antworten zu geben. Dies stellt sicher, dass die Informationen, die den Nutzern zur Verfügung gestellt werden, aktuell und relevant sind, was besonders in Bereichen wie dem Kundenservice wichtig ist, wo zeitnahe und genaue Antworten die Zufriedenheit und Effizienz der Nutzer erheblich steigern können. Da Llama 3.1 mehrere Sprachen unterstützt, ist es auch für eine vielfältige Nutzerbasis geeignet.
In Frage-Antwort-Systemen geht Llama 3.1 auf die Einschränkungen traditioneller Sprachmodelle ein, die sich nur auf ihre internen Datensätze verlassen. Durch die Nutzung von RAG, um auf aktuelle Informationen aus externen Quellen zuzugreifen, verbessert Llama 3.1 die Genauigkeit und Zuverlässigkeit seiner Antworten. Dies ist besonders nützlich in Bereichen wie Gesundheitswesen und Bildungwo präzise und aktuelle Informationen unerlässlich sind.
Ein medizinischer KI-Assistent, der von Llama 3.1 angetrieben wird, kann zum Beispiel medizinisches Fachpersonal mit den neuesten Forschungsergebnissen oder Behandlungsrichtlinien versorgen, indem er medizinische Datenbanken in Echtzeit abfragt und so zu einer besseren klinischen Entscheidungsfindung beiträgt.
Llama 3.1 ist auch für wissensintensive Aufgaben wie das Erstellen detaillierter Berichte oder gründliche Recherchen sehr effektiv. Durch die Verwendung von RAG, um aus einer Vielzahl von Quellen zu schöpfen, können Llama 3.1-Modelle umfassendere und differenziertere Analysen liefern, was sie zu wertvollen Werkzeugen für Fachleute in Bereichen wie Forschung, Finanzen und strategische Planung macht.
Die Implementierung einer RAG-Anwendung mit Llama 3.1 unter Verwendung von Ollama und Langchain bietet eine gute Lösung für die Erstellung fortgeschrittener, kontextbezogener Sprachmodelle.
Wenn du die beschriebenen Schritte befolgst - das Einrichten der Umgebung, das Laden und Verarbeiten von Dokumenten, das Erstellen von Einbettungen und die Integration des Retrievers mit dem LLM - kannst du ein funktionierendes RAG-System aufbauen, das in der Lage ist, relevante Informationen abzurufen und genaue Antworten zu geben.
Die Integration von Llama 3.1 in RAG ist besonders wertvoll für reale Anwendungen wie Chatbots, Frage-Antwort-Systeme und Forschungswerkzeuge, bei denen der Zugang zu aktuellen externen Informationen wichtig ist.
Lerne, KI-Anwendungen zu entwickeln!
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
