
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Das Model Context Protocol (MCP) ist ein offener Standard, der es großen Sprachmodellen ermöglicht, über eine standardisierte Schnittstelle dynamisch mit externen Tools, Datenbanken und APIs zu interagieren.
In diesem Blog führe ich dich durch den Aufbau eines MCP-gestützten PR-Review-Servers, der mit Claude Desktop integriert ist. Dieser Server wird:
Wir werden das Model Context Protocol (MCP) verwenden, um die Kommunikation zwischen dem Server und Claude Desktop zu standardisieren und damit modular und skalierbar zu machen.
Das Model Context Protocol (MCP) ist ein offener Standard, der von Anthropic entwickelt wurde, um eine einfache und standardisierte Integration zwischen KI-Modellen und externen Tools zu ermöglichen. Es fungiert als universeller Konnektor, der es großen Sprachmodellen (LLMs) ermöglicht, dynamisch mit APIs, Datenbanken und Geschäftsanwendungen zu interagieren.
Ursprünglich wurde MCP entwickelt, um die Interaktion von Claude mit externen Systemen zu verbessern. Anthropic beschloss, MCP Anfang 2024 als Open Source zu veröffentlichen, um eine branchenweite Verbreitung zu fördern. Indem sie MCP öffentlich zugänglich machten, wollten sie ein standardisiertes Framework für die Kommunikation zwischen KI und Tools schaffen, das die Abhängigkeit von proprietären Integrationen verringert und eine größere Modularität und Interoperabilität zwischen KI-Anwendungen ermöglicht.
MCP basiert auf einer Client-Server-Architektur:
Quelle: Modell-Kontext-Protokoll
Hier erfährst du, warum du MCP für deine Projekte nutzen solltest:
Das PR-Review-System automatisiert die Codeanalyse und -dokumentation mit Claude Desktop und Notion.
Hier ist eine kurze Übersicht über die Pipeline:
Bevor wir beginnen, solltest du sicherstellen, dass du Python 3.10+ installiert hast. Dann richten wir unsere Umgebung ein und beginnen mit der Installation des uv Paketmanagers. Für Mac oder Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh # Mac/LinuxFür Windows (PowerShell):
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"Dann erstellen wir ein neues Projektverzeichnis und initialisieren es mit uv:
uv init pr_reviewer
cd pr_reviewerWir können jetzt eine virtuelle Umgebung erstellen und aktivieren. Für Mac oder Linux:
uv venv
source .venv/bin/activateFür Windows:
.venv\Scripts\activateJetzt installieren wir die erforderlichen Abhängigkeiten:
uv add "mcp[cli]" requests python-dotenv notion-clientWir werden uv gegenüber conda für dieses Projekt verwenden, weil es schneller und leichter ist und sich mehr auf die Verwaltung von Python-Paketen konzentriert. Lass uns rekapitulieren, was wir gerade getan haben:
pr_reviewer angelegt und dorthin navigiert.Sobald unsere Umgebung eingerichtet ist, richten wir unsere Abhängigkeiten mit den API-Schlüsseln und anderen Anforderungen ein. Erstelle eine requirements.txt Datei und füge ihr die folgenden Python-Pakete hinzu:
# Core dependencies for PR Analyzer
requests>=2.31.0 # For GitHub API calls
python-dotenv>=1.0.0 # For environment variables
mcp[cli]>=1.4.0 # For MCP server functionality
notion-client>=2.3.0 # For Notion integration
# Optional: Pin versions for stability
# requests==2.31.0
# python-dotenv==1.0.0
# mcp[cli]==1.4.0
# notion-client==2.3.0
Die Datei requirements.txt enthält alle Kernabhängigkeiten, die für das Projekt benötigt werden. Um die Abhängigkeiten einzurichten, führe einen der folgenden Befehle aus (verwende uv, wenn du es bereits installiert hast).
uv pip install -r requirements.txt
pip install -r requirements.txtJetzt hat deine Umgebung alle erforderlichen Abhängigkeiten installiert.
Als Nächstes erstellen wir eine .env Datei, die alle für dieses Projekt benötigten Schlüssel und Token enthält.
So generierst du GitHub-Tokens:
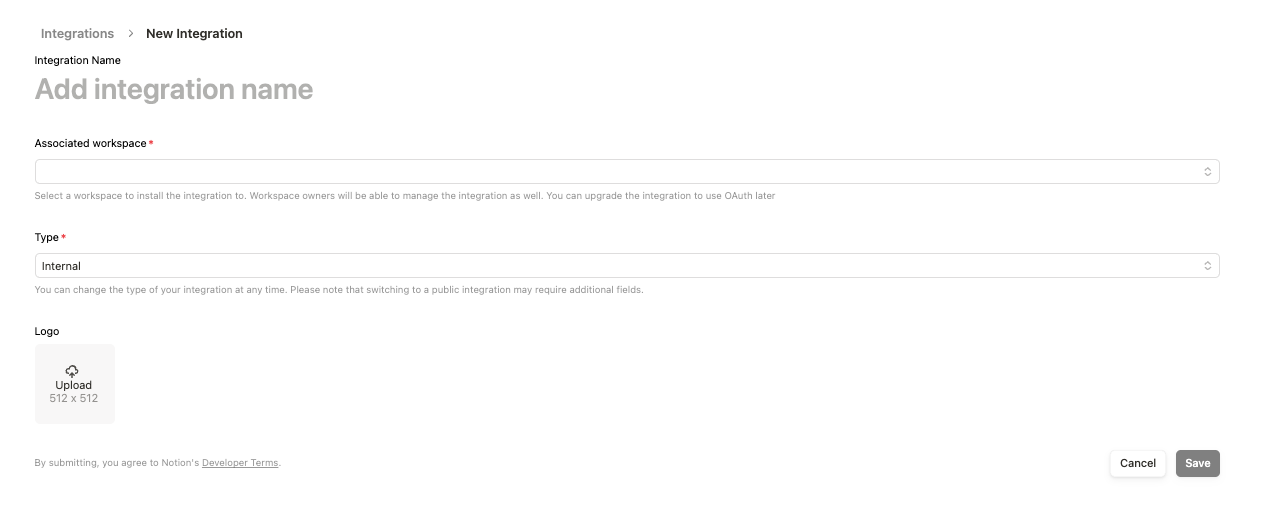
https://www.notion.so/profile/integrations/internal/UUID. Die UUID am Ende der URL ist der Universally Unique Identifier, den du dir notieren und als Notion Page ID verwenden musst. .env DateiErstelle nun eine .env Datei und füge den folgenden Text zusammen mit den API-Schlüsseln und dem Token hinzu, die wir oben erstellt haben.
GITHUB_TOKEN=your_github_token
NOTION_API_KEY=your_notion_api_key
NOTION_PAGE_ID=your_notion_page_idKonfigurieren wir unser GitHub-Integrationsmodul, um PR-Änderungen aus einem GitHub-Repository zu verwalten und abzurufen.
Erstelle eine github_integration.py Datei und schreibe den folgenden Code (wir werden ihn gleich erklären).
import os
import requests
import traceback
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
GITHUB_TOKEN = os.getenv('GITHUB_TOKEN')
def fetch_pr_changes(repo_owner: str, repo_name: str, pr_number: int) -> list:
"""Fetch changes from a GitHub pull request.
Args:
repo_owner: The owner of the GitHub repository
repo_name: The name of the GitHub repository
pr_number: The number of the pull request to analyze
Returns:
A list of file changes with detailed information about each change
"""
print(f" Fetching PR changes for {repo_owner}/{repo_name}#{pr_number}")
# Fetch PR details
pr_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/pulls/{pr_number}"
files_url = f"{pr_url}/files"
headers = {'Authorization': f'token {GITHUB_TOKEN}'}
try:
# Get PR metadata
pr_response = requests.get(pr_url, headers=headers)
pr_response.raise_for_status()
pr_data = pr_response.json()
# Get file changes
files_response = requests.get(files_url, headers=headers)
files_response.raise_for_status()
files_data = files_response.json()
# Combine PR metadata with file changes
changes = []
for file in files_data:
change = {
'filename': file['filename'],
'status': file['status'], # added, modified, removed
'additions': file['additions'],
'deletions': file['deletions'],
'changes': file['changes'],
'patch': file.get('patch', ''), # The actual diff
'raw_url': file.get('raw_url', ''),
'contents_url': file.get('contents_url', '')
}
changes.append(change)
# Add PR metadata
pr_info = {
'title': pr_data['title'],
'description': pr_data['body'],
'author': pr_data['user']['login'],
'created_at': pr_data['created_at'],
'updated_at': pr_data['updated_at'],
'state': pr_data['state'],
'total_changes': len(changes),
'changes': changes
}
print(f"Successfully fetched {len(changes)} changes")
return pr_info
except Exception as e:
print(f"Error fetching PR changes: {str(e)}")
traceback.print_exc()
return None
# Example usage for debugging
# pr_data = fetch_pr_changes('owner', 'repo', 1)
# print(pr_data) Die Funktion fetch_pr_changes() ruft die Änderungen einer bestimmten GitHub-Pull-Anfrage ab und gibt sie zurück. Sie benötigt drei Parameter, nämlich repo_owner, repo_name und pr_number, und gibt eine strukturierte Liste von Datei-Änderungen zusammen mit PR-Metadaten zurück.
Der Code verwendet die Bibliothek requests, um authentifizierte HTTP-GET-Anfragen zu senden und sowohl allgemeine PR-Metadaten als auch detaillierte Änderungen auf Dateiebene abzurufen:
Sobald die Daten abgerufen sind, strukturiert die Funktion die PR-Metadaten und kombiniert sie mit den Datei-Änderungen in einem Wörterbuch. Die Datei-Änderungen werden in einer Liste gespeichert, wobei jeder Eintrag detaillierte Informationen über eine Datei enthält. Die endgültige Datenstruktur enthält den PR-Titel, die Beschreibung, den Autor, die Zeitstempel, den Status, die Gesamtzahl der geänderten Dateien und eine detaillierte Aufschlüsselung der Dateiänderungen.
Nachdem wir nun alle Abhängigkeiten und Zusatzfunktionen eingerichtet haben, richten wir unseren MCP-Server ein. Wir erstellen eine pr_anayzer.py Datei, die:
Fügen wir zuerst den Code ein und erklären ihn danach
import sys
import os
import traceback
from typing import Any, List, Dict
from mcp.server.fastmcp import FastMCP
from github_integration import fetch_pr_changes
from notion_client import Client
from dotenv import load_dotenv
class PRAnalyzer:
def __init__(self):
# Load environment variables
load_dotenv()
# Initialize MCP Server
self.mcp = FastMCP("github_pr_analysis")
print("MCP Server initialized", file=sys.stderr)
# Initialize Notion client
self._init_notion()
# Register MCP tools
self._register_tools()
def _init_notion(self):
"""Initialize the Notion client with API key and page ID."""
try:
self.notion_api_key = os.getenv("NOTION_API_KEY")
self.notion_page_id = os.getenv("NOTION_PAGE_ID")
if not self.notion_api_key or not self.notion_page_id:
raise ValueError("Missing Notion API key or page ID in environment variables")
self.notion = Client(auth=self.notion_api_key)
print(f"Notion client initialized successfully", file=sys.stderr)
print(f"Using Notion page ID: {self.notion_page_id}", file=sys.stderr)
except Exception as e:
print(f"Error initializing Notion client: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
sys.exit(1)
def _register_tools(self):
"""Register MCP tools for PR analysis."""
@self.mcp.tool()
async def fetch_pr(repo_owner: str, repo_name: str, pr_number: int) -> Dict[str, Any]:
"""Fetch changes from a GitHub pull request."""
print(f"Fetching PR #{pr_number} from {repo_owner}/{repo_name}", file=sys.stderr)
try:
pr_info = fetch_pr_changes(repo_owner, repo_name, pr_number)
if pr_info is None:
print("No changes returned from fetch_pr_changes", file=sys.stderr)
return {}
print(f"Successfully fetched PR information", file=sys.stderr)
return pr_info
except Exception as e:
print(f"Error fetching PR: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
return {}
@self.mcp.tool()
async def create_notion_page(title: str, content: str) -> str:
"""Create a Notion page with PR analysis."""
print(f"Creating Notion page: {title}", file=sys.stderr)
try:
self.notion.pages.create(
parent={"type": "page_id", "page_id": self.notion_page_id},
properties={"title": {"title": [{"text": {"content": title}}]}},
children=[{
"object": "block",
"type": "paragraph",
"paragraph": {
"rich_text": [{
"type": "text",
"text": {"content": content}
}]
}
}]
)
print(f"Notion page '{title}' created successfully!", file=sys.stderr)
return f"Notion page '{title}' created successfully!"
except Exception as e:
error_msg = f"Error creating Notion page: {str(e)}"
print(error_msg, file=sys.stderr)
traceback.print_exc(file=sys.stderr)
return error_msg
def run(self):
"""Start the MCP server."""
try:
print("Running MCP Server for GitHub PR Analysis...", file=sys.stderr)
self.mcp.run(transport="stdio")
except Exception as e:
print(f"Fatal Error in MCP Server: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
analyzer = PRAnalyzer()
analyzer.run() Der obige Code richtet einen MCP Server ein, um GitHub PR-Änderungen abzurufen und speichert die Analyseergebnisse in Notion. Schauen wir uns die wichtigsten Komponenten an:
dotenv lädt Umgebungsvariablen und sorgt dafür, dass der Zugriff auf API-Schlüssel und Anmeldedaten sicher ist. PRAnalyzer einen MCP-Server mit der Funktion FastMCP(), die den MCP-Server mit dem Namen github_pr_analysis initialisiert und die Interaktion mit der Claude Desktop Anwendung ermöglicht..env gespeicherte Seiten-ID verwendet.fetch_pr() ruft Pull Request-Metadaten von GitHub ab, indem sie die Methode fetch_pr_changes() aus der Datei github_integration.py verwendet. Wenn sie erfolgreich ist, gibt sie ein Wörterbuch mit den PR-Details zurück.create_notion_page() erstellt eine Notion-Seite mit den Ergebnissen der PR-Analyse.run() startet den MCP-Server über mcp.run(transport="stdio") und ermöglicht die Interaktion zwischen Claude Desktop und den PR-Review-Tools.Nachdem wir nun alle Teile des Codes fertiggestellt haben, starten wir unseren Server mit folgendem Terminalbefehl:
python pr_analyzer.py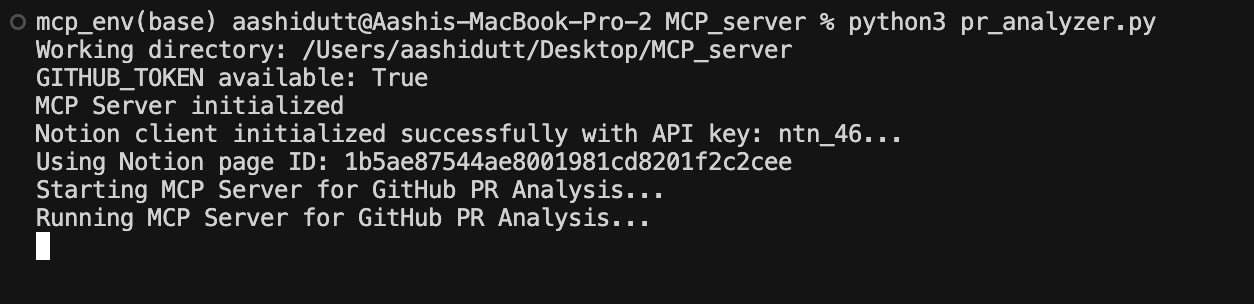
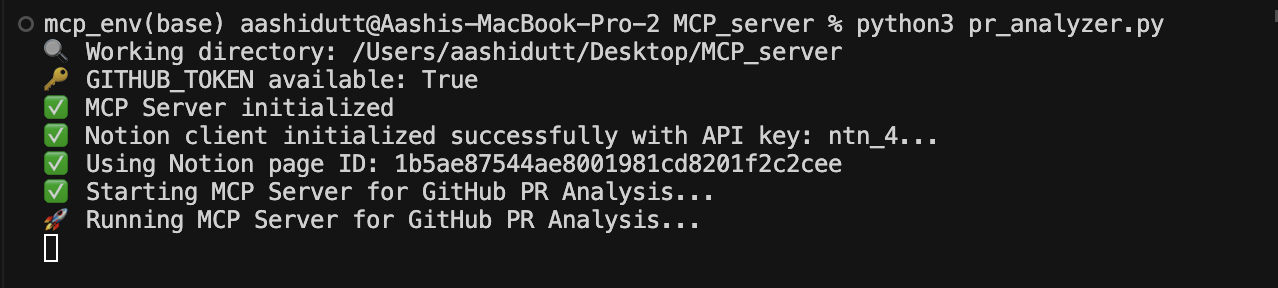
Sobald der Server läuft, öffnest du die Anwendung Claude Desktop und siehst ein Steckersymbol (🔌) im Textfeld. Dieser Stecker zeigt an, dass ein MCP in der Claude-Umgebung vorhanden ist. In demselben Textfeld siehst du ein hammerähnliches Symbol (🔨), das alle verfügbaren MCPs anzeigt, wie unten abgebildet.
Nun gibst du den Link an den PR weiter, den du analysieren möchtest, und Claude erledigt den Rest für dich.

Claude wird die PR zunächst analysieren und dann eine Zusammenfassung und Bewertung abgeben. Es fragt die Nutzer, ob sie die Details auf die Notion-Seite hochladen wollen. Du kannst diesen Prozess zwar automatisieren, aber der aktuelle Code ermöglicht es dir, die Zusammenfassung zu überprüfen, bevor du eine neue Notion-Seite erstellst.
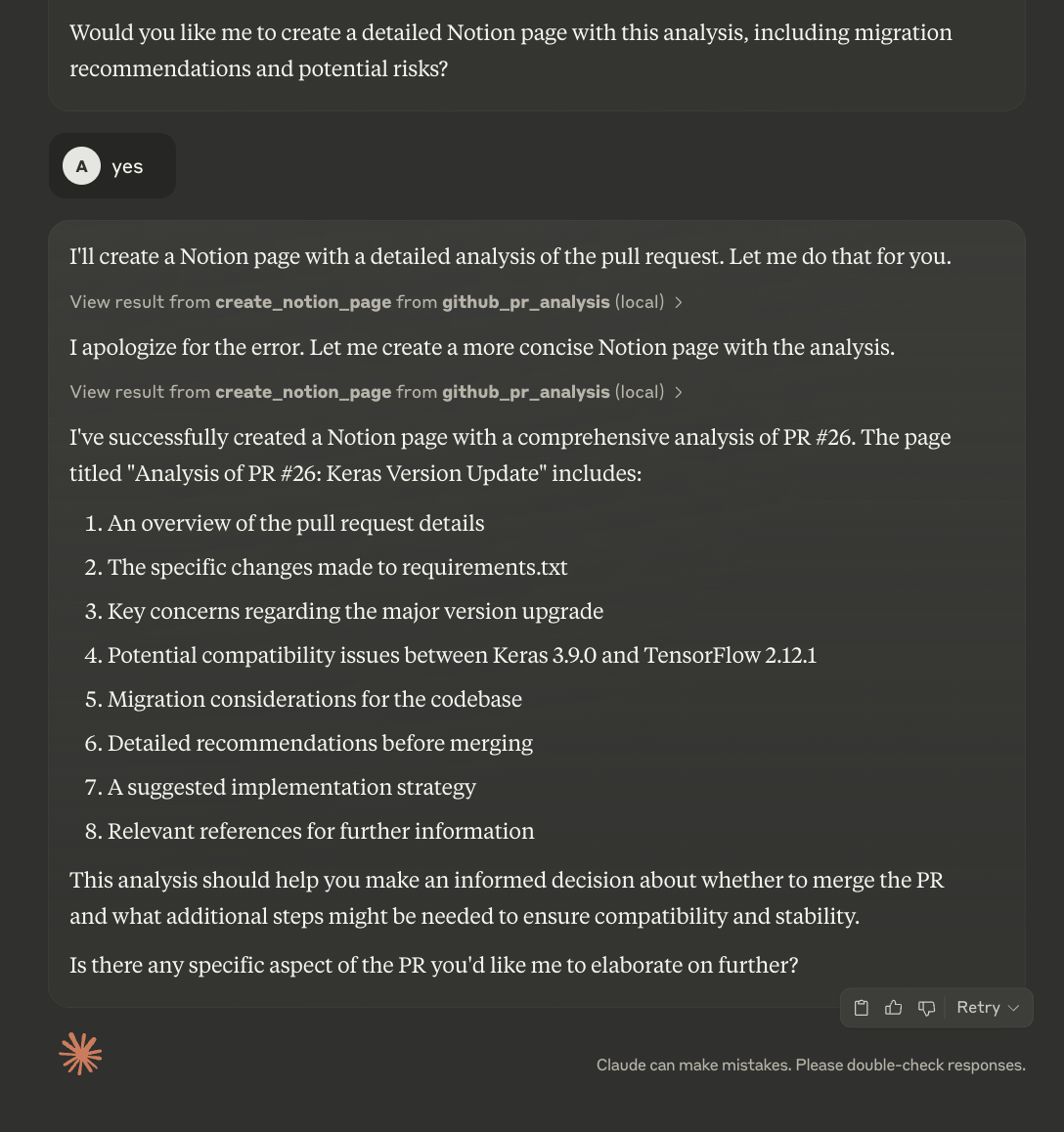
Die aktualisierte Notion-Seite sieht so aus:
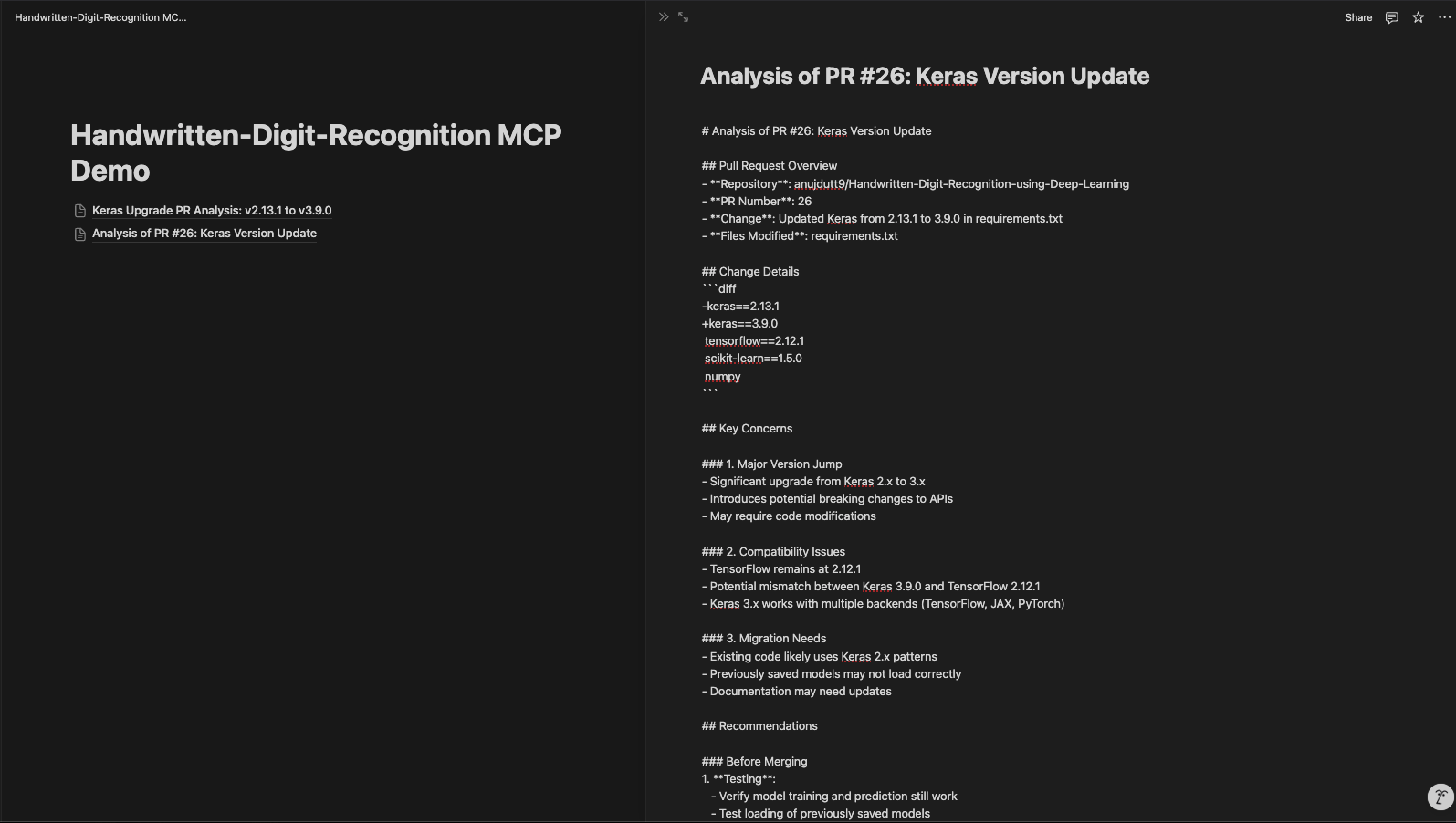
Unser PR Review MCP-basierter Server verbessert die Codeanalyse und -dokumentation und steigert so die Effizienz und Organisation des Review-Prozesses. Durch den Einsatz von MCP, der GitHub-API und der Notion-Integration unterstützt dieses System die automatische PR-Analyse, die einfache Zusammenarbeit und die strukturierte Dokumentation. Mit dieser Konfiguration können Entwickler schnell PR-Details abrufen, Codeänderungen mit Claude analysieren und die Erkenntnisse in Notion für spätere Referenzen speichern.
Um mehr über neuere KI-Tools zu erfahren, empfehle ich diese Blogs:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Moez Ali
Tutorial
DataCamp Team