
Cursus
Développer des applications d'IA
21 h
Le protocole de contexte de modèle (MCP) protocole de contexte de modèle (MCP) est une norme ouverte qui permet aux grands modèles de langage d'interagir dynamiquement avec des outils externes, des bases de données et des API par le biais d'une interface normalisée.
Dans ce blog, je vous guiderai dans la construction d'un serveur de revue de presse alimenté par MCP et intégré à Claude Desktop. Ce serveur va :
Nous utiliserons le Model Context Protocol (MCP) pour normaliser la communication entre le serveur et Claude Desktop, ce qui le rendra modulaire et évolutif.
Le Model Context Protocol (MCP) est un standard ouvert développé par Anthropic pour permettre une intégration facile et standardisée entre les modèles d'IA et les outils externes. Il agit comme un connecteur universel, permettant aux grands modèles de langage (LLM) d'interagir dynamiquement avec les API, les bases de données et les applications commerciales.
Construit à l'origine pour améliorer la capacité de Claude à interagir avec des systèmes externes, Anthropic a décidé d'ouvrir MCP au début de l'année 2024 afin d'encourager l'adoption par l'ensemble de l'industrie. En mettant MCP à la disposition du public, ils ont voulu créer un cadre normalisé pour la communication entre l'IA et les outils, en réduisant la dépendance à l'égard des intégrations propriétaires et en permettant une plus grande modularité et une meilleure interopérabilité entre les applications d'IA.
MCP suit une architecture client-serveur dans laquelle :
Source : Modèle Contexte Protocole
Voici pourquoi vous souhaiteriez utiliser MCP pour vos projets :
Le système de révision PR automatise l'analyse du code et la documentation à l'aide de Claude Desktop et de Notion.
Voici une présentation succincte de la filière :
Avant de commencer, assurez-vous que Python 3.10+ est installé. Ensuite, nous configurons notre environnement et commençons par installer le gestionnaire de paquets uv. Pour Mac ou Linux :
curl -LsSf https://astral.sh/uv/install.sh | sh # Mac/LinuxPour Windows (PowerShell) :
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"Ensuite, nous créons un nouveau répertoire de projet et l'initialisons avec uv:
uv init pr_reviewer
cd pr_reviewerNous pouvons maintenant créer et activer un environnement virtuel. Pour Mac ou Linux :
uv venv
source .venv/bin/activatePour Windows :
.venv\Scripts\activateNous allons maintenant installer les dépendances nécessaires :
uv add "mcp[cli]" requests python-dotenv notion-clientNous utiliserons uv plutôt que conda pour ce projet car il est plus rapide, plus léger et plus axé sur la gestion des paquets Python. Récapitulons ce que nous venons de faire :
pr_reviewer et nous y avons navigué.Une fois notre environnement mis en place, nous configurons nos dépendances avec les clés d'API et d'autres exigences. Créez un fichier requirements.txt et ajoutez-y les paquets Python suivants :
# Core dependencies for PR Analyzer
requests>=2.31.0 # For GitHub API calls
python-dotenv>=1.0.0 # For environment variables
mcp[cli]>=1.4.0 # For MCP server functionality
notion-client>=2.3.0 # For Notion integration
# Optional: Pin versions for stability
# requests==2.31.0
# python-dotenv==1.0.0
# mcp[cli]==1.4.0
# notion-client==2.3.0
Le fichier requirements.txt contient toutes les dépendances de base nécessaires au projet. Pour configurer les dépendances, exécutez l'une des commandes suivantes (utilisez uv si vous l'avez déjà installé).
uv pip install -r requirements.txt
pip install -r requirements.txtVotre environnement dispose désormais de toutes les dépendances nécessaires.
Ensuite, nous créons un fichier .env qui contient toutes les clés et tous les jetons nécessaires à ce projet.
Pour générer des jetons GitHub :
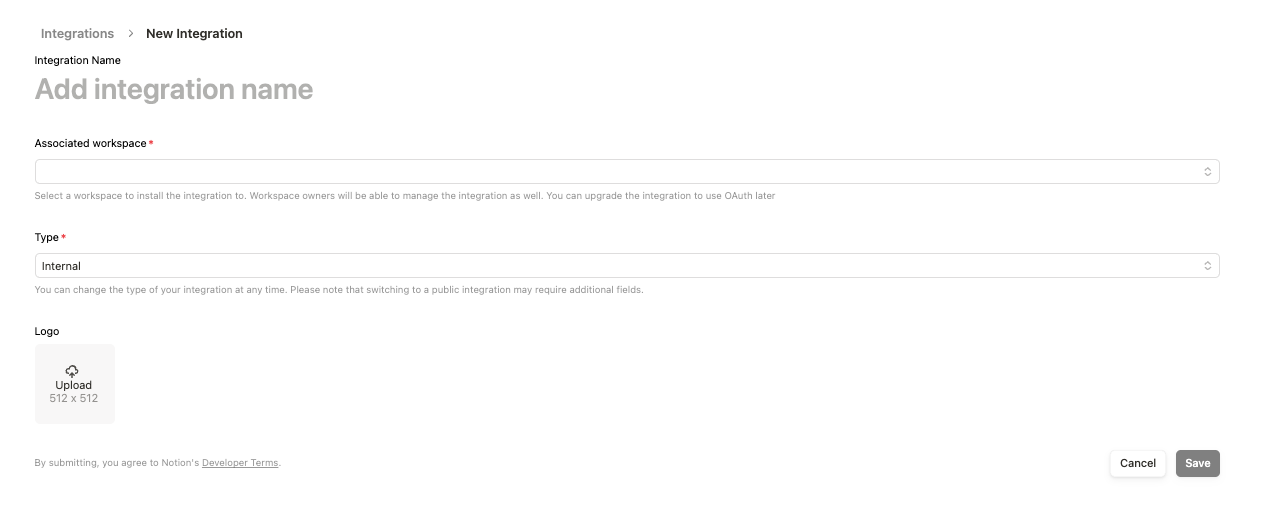
https://www.notion.so/profile/integrations/internal/UUID. Le UUID à la fin de l'URL est l'identifiant universel unique que vous devez noter et utiliser commeidentifiant de la page Notion. .env fichierMaintenant, créez un fichier .env et ajoutez le texte suivant avec les clés d'API et le jeton que nous avons générés ci-dessus.
GITHUB_TOKEN=your_github_token
NOTION_API_KEY=your_notion_api_key
NOTION_PAGE_ID=your_notion_page_idConfigurons notre module d'intégration GitHub pour gérer et récupérer les changements de RP d'un dépôt GitHub.
Créez un fichier github_integration.py et écrivez le code suivant (nous l'expliquerons dans un instant).
import os
import requests
import traceback
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
GITHUB_TOKEN = os.getenv('GITHUB_TOKEN')
def fetch_pr_changes(repo_owner: str, repo_name: str, pr_number: int) -> list:
"""Fetch changes from a GitHub pull request.
Args:
repo_owner: The owner of the GitHub repository
repo_name: The name of the GitHub repository
pr_number: The number of the pull request to analyze
Returns:
A list of file changes with detailed information about each change
"""
print(f" Fetching PR changes for {repo_owner}/{repo_name}#{pr_number}")
# Fetch PR details
pr_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/pulls/{pr_number}"
files_url = f"{pr_url}/files"
headers = {'Authorization': f'token {GITHUB_TOKEN}'}
try:
# Get PR metadata
pr_response = requests.get(pr_url, headers=headers)
pr_response.raise_for_status()
pr_data = pr_response.json()
# Get file changes
files_response = requests.get(files_url, headers=headers)
files_response.raise_for_status()
files_data = files_response.json()
# Combine PR metadata with file changes
changes = []
for file in files_data:
change = {
'filename': file['filename'],
'status': file['status'], # added, modified, removed
'additions': file['additions'],
'deletions': file['deletions'],
'changes': file['changes'],
'patch': file.get('patch', ''), # The actual diff
'raw_url': file.get('raw_url', ''),
'contents_url': file.get('contents_url', '')
}
changes.append(change)
# Add PR metadata
pr_info = {
'title': pr_data['title'],
'description': pr_data['body'],
'author': pr_data['user']['login'],
'created_at': pr_data['created_at'],
'updated_at': pr_data['updated_at'],
'state': pr_data['state'],
'total_changes': len(changes),
'changes': changes
}
print(f"Successfully fetched {len(changes)} changes")
return pr_info
except Exception as e:
print(f"Error fetching PR changes: {str(e)}")
traceback.print_exc()
return None
# Example usage for debugging
# pr_data = fetch_pr_changes('owner', 'repo', 1)
# print(pr_data) La fonction fetch_pr_changes() récupère et renvoie les modifications d'une demande d'extraction GitHub donnée. Il prend trois paramètres, à savoir repo_owner, repo_name, et pr_number, et renvoie une liste structurée des modifications apportées aux fichiers ainsi que des métadonnées PR.
Le code utilise la bibliothèque requests pour envoyer des requêtes HTTP GET authentifiées, récupérant à la fois les métadonnées générales du PR et les modifications détaillées au niveau des fichiers :
Une fois les données récupérées, la fonction structure et combine les métadonnées PR et les modifications de fichiers dans un dictionnaire. Les modifications apportées aux fichiers sont enregistrées dans une liste, chaque entrée contenant des informations détaillées sur le fichier. La structure finale des données comprend le titre du PR, la description, l'auteur, l'horodatage, l'état, le nombre total de fichiers modifiés et une ventilation détaillée des modifications apportées aux fichiers.
Maintenant que toutes les dépendances et les fonctions supplémentaires sont en place, nous configurons notre serveur MCP. Nous créons un fichier pr_anayzer.py, qui va.. :
Ajoutons d'abord le code et expliquons-le ensuite
import sys
import os
import traceback
from typing import Any, List, Dict
from mcp.server.fastmcp import FastMCP
from github_integration import fetch_pr_changes
from notion_client import Client
from dotenv import load_dotenv
class PRAnalyzer:
def __init__(self):
# Load environment variables
load_dotenv()
# Initialize MCP Server
self.mcp = FastMCP("github_pr_analysis")
print("MCP Server initialized", file=sys.stderr)
# Initialize Notion client
self._init_notion()
# Register MCP tools
self._register_tools()
def _init_notion(self):
"""Initialize the Notion client with API key and page ID."""
try:
self.notion_api_key = os.getenv("NOTION_API_KEY")
self.notion_page_id = os.getenv("NOTION_PAGE_ID")
if not self.notion_api_key or not self.notion_page_id:
raise ValueError("Missing Notion API key or page ID in environment variables")
self.notion = Client(auth=self.notion_api_key)
print(f"Notion client initialized successfully", file=sys.stderr)
print(f"Using Notion page ID: {self.notion_page_id}", file=sys.stderr)
except Exception as e:
print(f"Error initializing Notion client: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
sys.exit(1)
def _register_tools(self):
"""Register MCP tools for PR analysis."""
@self.mcp.tool()
async def fetch_pr(repo_owner: str, repo_name: str, pr_number: int) -> Dict[str, Any]:
"""Fetch changes from a GitHub pull request."""
print(f"Fetching PR #{pr_number} from {repo_owner}/{repo_name}", file=sys.stderr)
try:
pr_info = fetch_pr_changes(repo_owner, repo_name, pr_number)
if pr_info is None:
print("No changes returned from fetch_pr_changes", file=sys.stderr)
return {}
print(f"Successfully fetched PR information", file=sys.stderr)
return pr_info
except Exception as e:
print(f"Error fetching PR: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
return {}
@self.mcp.tool()
async def create_notion_page(title: str, content: str) -> str:
"""Create a Notion page with PR analysis."""
print(f"Creating Notion page: {title}", file=sys.stderr)
try:
self.notion.pages.create(
parent={"type": "page_id", "page_id": self.notion_page_id},
properties={"title": {"title": [{"text": {"content": title}}]}},
children=[{
"object": "block",
"type": "paragraph",
"paragraph": {
"rich_text": [{
"type": "text",
"text": {"content": content}
}]
}
}]
)
print(f"Notion page '{title}' created successfully!", file=sys.stderr)
return f"Notion page '{title}' created successfully!"
except Exception as e:
error_msg = f"Error creating Notion page: {str(e)}"
print(error_msg, file=sys.stderr)
traceback.print_exc(file=sys.stderr)
return error_msg
def run(self):
"""Start the MCP server."""
try:
print("Running MCP Server for GitHub PR Analysis...", file=sys.stderr)
self.mcp.run(transport="stdio")
except Exception as e:
print(f"Fatal Error in MCP Server: {str(e)}", file=sys.stderr)
traceback.print_exc(file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
analyzer = PRAnalyzer()
analyzer.run() Le code ci-dessus met en place un serveur MCP pour récupérer les changements de PR GitHub et stocke les résultats de l'analyse dans Notion. Passons en revue les principaux éléments :
dotenv charge les variables d'environnement, ce qui garantit un accès sécurisé aux clés et aux informations d'identification de l'API. PRAnalyzer initialise un serveur MCP à l'aide de la fonction FastMCP() qui initialise le serveur MCP avec le nom github_pr_analysis et permet l'interaction avec l'application Claude Desktop..env.fetch_pr() récupère les métadonnées des demandes d'extraction de GitHub à l'aide de la méthode fetch_pr_changes() du fichier github_integration.py. En cas de succès, il renvoie un dictionnaire contenant les détails de la RP.create_notion_page() génère une page Notion avec les résultats de l'analyse PR.run() démarre le serveur MCP à l'aide de mcp.run(transport="stdio"), ce qui permet l'interaction entre Claude Desktop et les outils d'examen des RP.Maintenant que tous les éléments du code sont en place, nous lançons notre serveur à l'aide de la commande suivante dans le terminal :
python pr_analyzer.py
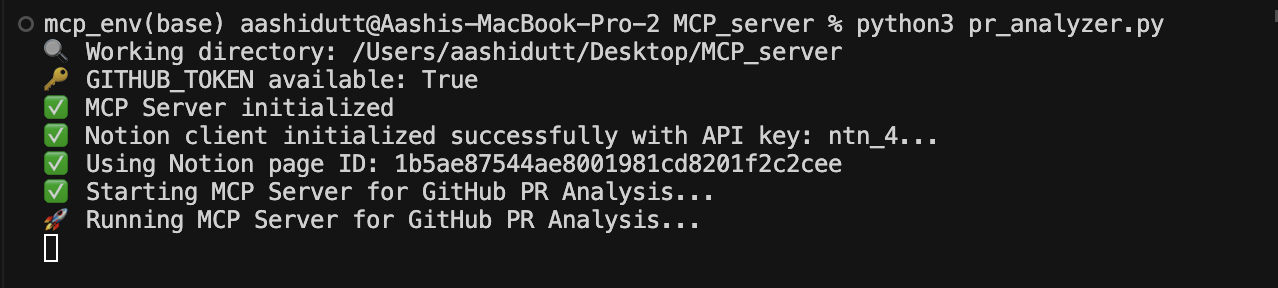
Une fois que le serveur est opérationnel, ouvrez l'application Claude Desktop et vous verrez une icône de prise (🔌) dans la zone de texte. Cette fiche indique la présence d'un MCP dans l'environnement Claude. Dans la même zone de texte, vous remarquerez une icône en forme de marteau (🔨) qui affiche tous les MCP disponibles, comme indiqué ci-dessous.
Transmettez le lien au PR que vous souhaitez analyser et Claude fera le reste pour vous.

Claude analysera d'abord le rapport d'évaluation, puis en fournira un résumé et une analyse. Il demandera aux utilisateurs s'ils souhaitent télécharger les détails sur la page Notion. Bien que vous puissiez automatiser ce processus, le code actuel vous permet de consulter le résumé avant de créer une nouvelle page Notion.
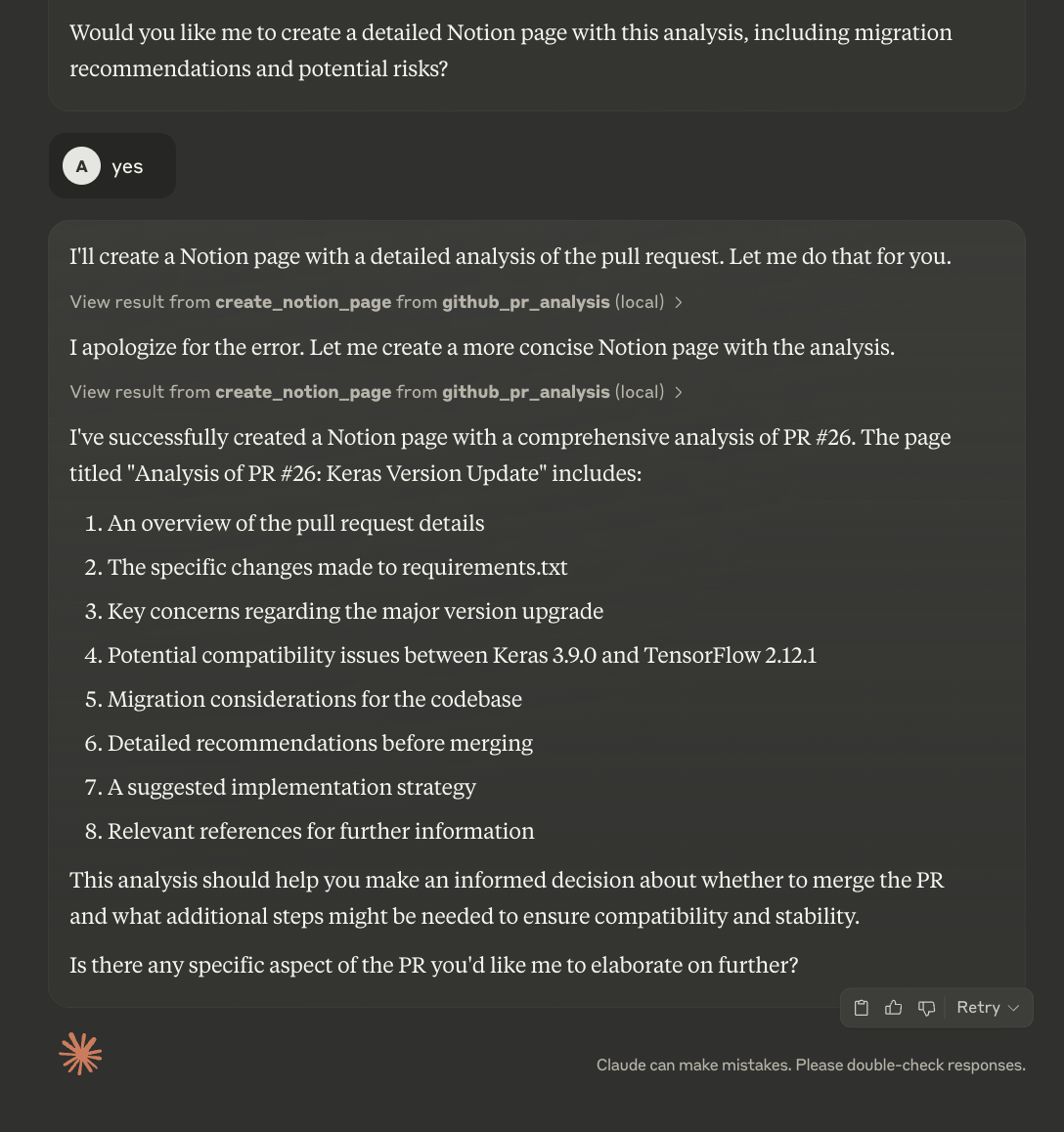
La page Notion mise à jour se présente comme suit :
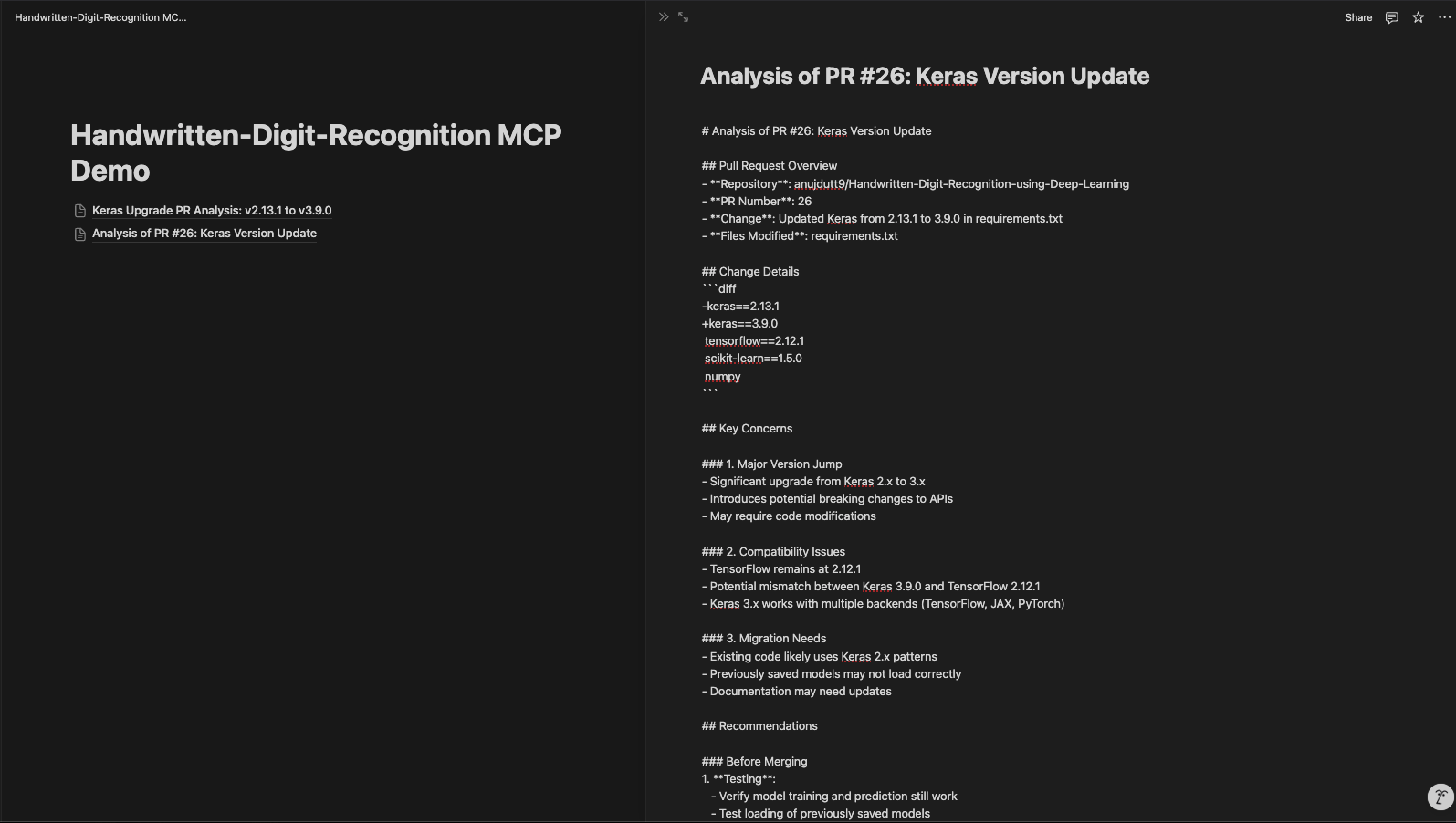
Notre serveur PR Review MCP améliore l'analyse et la documentation du code, en renforçant l'efficacité et l'organisation du processus de révision. En utilisant MCP, l'API GitHub et l'intégration Notion, ce système permet une analyse automatisée des relations publiques, une collaboration facile et une documentation structurée. Grâce à cette configuration, les développeurs peuvent rapidement récupérer les détails des RP, analyser les modifications de code à l'aide de Claude et stocker les informations dans Notion pour référence ultérieure.
Pour découvrir des outils d'IA plus récents, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Derrick Mwiti
