
Kurs
MLOps-Bereitstellung und Lebenszyklus
4 Std.
12K
Metaflow ist ein leistungsstarkes Framework für die Erstellung und Verwaltung von Daten-Workflows. In diesem Lernprogramm erfährst du, wie du loslegen kannst. Das heißt, wir werden uns mit folgenden Themen beschäftigen:
Am Ende dieses Artikels wirst du über die nötigen Fähigkeiten verfügen, um deine Arbeitsabläufe effizient zu optimieren und zu skalieren!
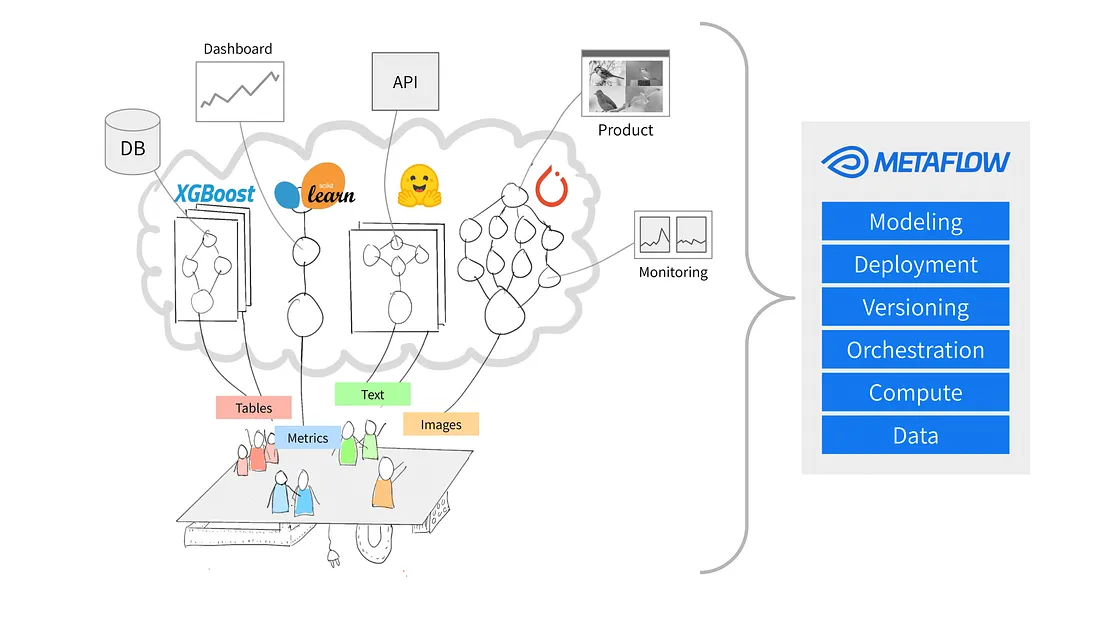
Quelle: Warum Metaflow?
Metaflow ist ein Python-Framework, das für die Verwaltung von Data Science-Projekten entwickelt wurde. Netflix hat das Tool ursprünglich entwickelt, um Datenwissenschaftlern und Ingenieuren für maschinelles Lernen zu helfen, produktiver zu sein. Es erreicht diesesZiel durch die Vereinfachung komplexer Aufgaben wie der Workflow-Orchestrierung, die dafür sorgt, dass Prozesse von Anfang bis Ende reibungslos ablaufen.
Zu den wichtigsten Funktionen von Metaflow gehören die automatische Datenversionierung, mit der Änderungen an deinen Workflows nachverfolgt werden können, und die Unterstützung skalierbarer Workflows, mit denen du größere Datensätze und komplexere Aufgaben bewältigen kannst.
Ein weiterer Vorteil von Metaflow ist, dass es sich problemlos in AWS integrieren lässt. Das bedeutet, dass die Nutzer/innen Cloud-Ressourcen für Speicherplatz und Rechenleistung nutzen können. Dank der benutzerfreundlichen Python-API ist es sowohl für Anfänger als auch für erfahrene Nutzer zugänglich.
Fangen wir an, es einzurichten.
Metaflowempfiehlt, für neue Projekte Python 3 und nicht Python 2.7 zu installieren. In der Dokumentation steht, dass "Python 3 weniger Fehler hat und besser unterstützt wird als das veraltete Python 2.7."
Der nächste Schritt besteht darin, eine virtuelle Umgebung zu erstellen, um deine Projektabhängigkeiten zu verwalten. Führe dazu den folgenden Befehl aus:
python -m venv venv
source venv/bin/activateDadurch wird eine virtuelle Umgebung erstellt und aktiviert. Nach der Aktivierung bist du bereit, Metaflow zu installieren.
Metaflow ist als Python-Paket für MacOS und Linux erhältlich. Die neueste Version kann vom Metaflow Github Repository oder von PyPi installiert werden, indem du den folgenden Befehl ausführst:
pip install metaflowLeider bietet Metaflow zum Zeitpunkt der Erstellung dieses Artikels keine native Unterstützung für Windows-Nutzer. Nutzer/innen von Windows 10 können jedoch WSL (Windows Subsystem for Linux) verwenden, um Metaflow zu installieren, wodurch sie eine Linux-Umgebung innerhalb ihres Windows-Betriebssystems ausführen können. Check die Dokumentation für eine Schritt-für-Schritt-Anleitung zur Installation von Metaflow unter Windows 10.
Metaflow arbeitet nahtlos mit AWS zusammen, was es den Nutzern von ermöglicht, ihre Arbeitsabläufe über die Cloud-Infrastruktur zu skalieren. Um AWS zu integrieren, musst du deine AWS-Anmeldedaten einrichten.
Hinweis: Diese Schritte setzen voraus, dass du bereits ein AWS-Konto hast und AWS CLI installiert ist. Weitere Einzelheiten findest du unter in der AWS-Dokumentation.
pip install awscliaws configureHier wirst du aufgefordert, deine AWS-Zugangsschlüssel-ID und deinen geheimen Zugangsschlüssel einzugeben - das sind einfach die Anmeldeinformationen, die die AWS CLI verwendet, um deine Anfragen bei AWS zu authentifizieren. Beachte, dass du eventuell auch aufgefordert wirst, deine Region und dein Ausgabeformat anzugeben.
Sobald du diese Details eingegeben hast, voila! Metaflow verwendet automatisch deine AWS-Anmeldedaten, um Workflows auszuführen.
Jetzt, wo Metaflow eingerichtet ist, ist es an der Zeit, deinen ersten Workflow zu erstellen. In diesem Abschnitt führe ich dich durch die Grundlagen, wie du einen Flow erstellst, ihn ausführst und verstehst, wie Aufgaben und Schritte in Metaflow organisiert sind.
Am Ende dieses Abschnitts wirst du einen Workflow haben, der Daten verarbeitet und einfache Operationen durchführt. Los geht's!
Metaflow verwendet das Datenfluss-Paradigma, das ein Programm als gerichteten Graphen von Operationen darstellt. Dieser Ansatz ist ideal für den Aufbau von Datenverarbeitungspipelines, insbesondere beim maschinellen Lernen.ocessing pipelines.
In Metaflow wird der Graph der Operationen als Flow bezeichnet. Ein Ablauf besteht aus einer Reihe von Aufgaben, die in Schritte unterteilt sind. Beachte, dass jeder Schritt als eine Operation betrachtet werden kann, die als Knoten dargestellt wird, wobei die Übergänge zwischen den Schritten die Kanten des Graphen darstellen.
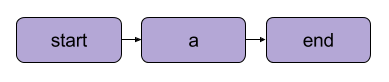
Ein Metaflow-Basis-Linearübergang | Quelle: Metaflow-Dokumentation
Es gibt ein paar strukturelle Regeln für Flows in Metaflow. Zum Beispiel muss jeder Fluss einen Startschritt und einen Endschritt enthalten. Wenn ein Ablauf ausgeführt wird, was als Lauf bezeichnet wird, beginnt er mit dem Startschritt und gilt als erfolgreich, wenn er den Endschritt ohne Fehler erreicht .
Was zwischen den Start- und Endschritten passiert, liegt ganz bei dir - wie du im nächsten Abschnitt sehen wirst.
Hier ist ein einfacher Ablauf, mit dem du anfangen kannst. Hinweis: Der Code kann unter in DataLab ausgeführt werden.
from metaflow import FlowSpec, step
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
if __name__ == '__main__':
MyFirstFlow()In diesem Fluss:
start() initialisiert den Workflow und definiert einen Datensatz.process_data() werden die Daten verarbeitet, indem jedes Element verdoppelt wird.end() schließt den Fluss ab.Jeder Schritt verwendet den @step Dekorator, und du definierst die Ablaufsequenz mit self.next(), um die Schritte zu verbinden.
Nachdem du deinen Flow geschrieben hast, speichere ihn als my_first_flow.py. Führe es von der Kommandozeile aus, indem du
py -m my_first_flow.py runIn Metaflow 2.12 wurde eine neue Funktion hinzugefügt, die es Nutzern ermöglicht, Abläufe in Notizbüchern zu entwickeln und auszuführen.
Um einen Fluss in einer definierten Zelle auszuführen, musst du nur den Einzeiler NBRunner in der letzten Zeile derselben Zelle hinzufügen. Zum Beispiel:
from metaflow import FlowSpec, step, NBRunner
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(MyFirstFlow).nbrun()Wenn du die folgende Fehlermeldung erhältst:
"Metaflow konnte deinen Benutzernamen nicht anhand von Umgebungsvariablen ($USERNAME usw.) ermitteln"
Füge vor der Ausführung von Metaflow Folgendes zu deinem Code hinzu:
import os
if os.environ.get("USERNAME") is None:
os.environ["USERNAME"] = "googlecolab"In beiden Fällen führt Metaflow den Ablauf Schritt für Schritt aus. Die Ausgabe der einzelnen Schritte wird nämlich wie folgt im Terminal angezeigt:
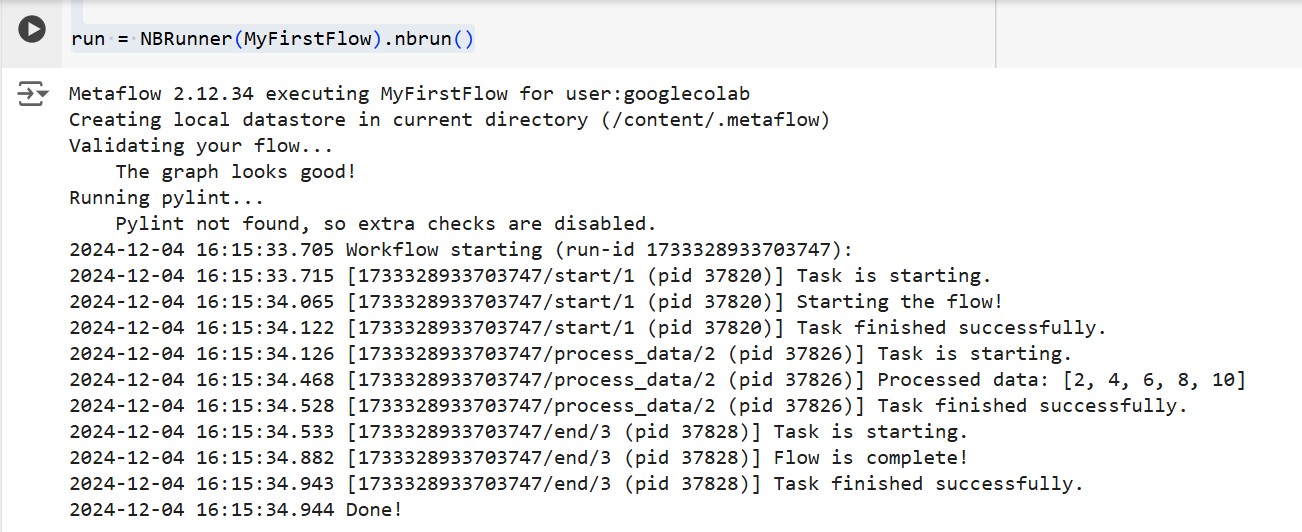
Die Ausgabe des obigen Codes | Quelle: Bild vom Autor
Das Verständnis der Kernkonzepte von Metaflow ist für den Aufbau effizienter und skalierbarer Datenworkflows unerlässlich. In diesem Abschnitt gehe ich auf drei grundlegende Konzepte ein:
Diese Elemente bilden das Rückgrat der Struktur und Ausführung von Arbeitsabläufen in Metaflow und ermöglichen es dir, komplexe Prozesse einfach zu verwalten.
Wir haben die Schritte schon früher in diesem Artikel kurz angesprochen , aber der Klarheit halber gehen wir noch einmal darauf ein. Das Wichtigste, was du über Metaflow-Workflows wissen musst, ist, dass sie aus Schritten aufgebaut sind.
Schritte stehen für jede einzelne Aufgabe innerhalb eines Workflows. Mit anderen Worten: Jeder Schritt führt einen bestimmten Vorgang aus (z. B. Daten laden, verarbeiten, modellieren usw.).
Das Beispiel, das wir oben in "Schreibe deinen ersten Flow" erstellt haben, war eine lineare Transformation. Zusätzlich zu den sequentiellen Schritten ermöglicht Metaflow auch dieVerzweigung von Arbeitsabläufen . Verzweigungsworkflows ermöglichen es dir, mehrere Aufgaben parallel auszuführen, indem du getrennte Pfade für die Ausführung erstellst.
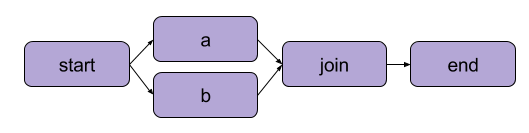
Ein Beispiel für eine Verzweigung | Quelle: Metaflow-Dokumentation
Der größte Vorteil einer Filiale ist die Leistung. Verzweigung bedeutet, dass Metaflow verschiedene Schritte über mehrere CPU-Kerne oder Instanzen in der Cloud ausführen kann.
So würde eine Verzweigung im Code aussehen:
from metaflow import FlowSpec, step, NBRunner
class BranchFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.split)
@step
def split(self):
self.next(self.branch1, self.branch2)
@step
def branch1(self):
# Code for branch 1
print("This is branch 1")
self.next(self.join)
@step
def branch2(self):
# Code for branch 2
print("This is branch 2")
self.next(self.join)
@step
def join(self, inputs):
# Merging branches back
print("Branches joined.")
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(BranchFlow).nbrun()|
💡TLDR: Verzweigungen ermöglichen es, komplexe Arbeitsabläufe zu gestalten, die mehrere Aufgaben gleichzeitig bearbeiten können. |
Datenartefakte sind Variablen, die es dir ermöglichen, Daten zu speichern und zwischen den Schritten eines Workflows weiterzugeben. Diese Artefakte halten die Ergebnisse eines Schritts bis zum nächsten aufrecht - so werden die Daten für die nachfolgenden Schritte verfügbar gemacht.
Wenn du innerhalb eines Schritts in einer Metaflow-Klasse Daten an self zuweist, speicherst du sie als Artefakt, auf das dann jeder andere Schritt im Flow zugreifen kann (siehe die Kommentare im Code).
class ArtifactFlow(FlowSpec):
@step
def start(self):
# Step 1: Initializing data
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset saved as an artifact
self.next(self.process_data)
@step
def process_data(self):
# Step 2: Processing the data from the 'start' step
self.processed_data = [x * 2 for x in self.data] # Processing artifact data
print("Processed data:", self.processed_data)
self.next(self.save_results)
@step
def save_results(self):
# Step 3: Saving the processed data artifact
self.results = sum(self.processed_data) # Saving final result as an artifact
print("Sum of processed data:", self.results)
self.next(self.end)
@step
def end(self):
# Final step
print("Flow is complete!")
print(f"Final result: {self.results}") # Accessing artifact in final stepWarum sind Artefakte ein Kernkonzept von Metaflow? Denn sie haben eine Reihe von Einsatzmöglichkeiten:
Metaflow übernimmt automatisch die Versionierung für deine Workflows. Das bedeutet, dass jedes Mal, wenn ein Lernpfad ausgeführt wird, dieser als einzigartiger Lauf verfolgt wird. Mit anderen Worten: Jeder Lauf hat seine eigene Version, so dass du vergangene Läufe leicht überprüfen und reproduzieren kannst.
Metaflow tut dies, indem es jedem Lauf eindeutige Bezeichner zuweist und die Daten und Artefakte dieser Ausführung aufbewahrt. Diese Persistenz stellt sicher, dass keine Daten zwischen den Läufen verloren gehen. Frühere Arbeitsabläufe können leicht überprüft und kontrolliert werden, und bestimmte Schritte können bei Bedarf wiederholt werden. Dadurch werden die Fehlersuche und die iterative Entwicklung viel effizienter und die Aufrechterhaltung der Reproduzierbarkeit wird vereinfacht.
In diesem Abschnitt führe ich dich durch die Verwendung von Metaflow zum Trainieren eines maschinellen Lernmodells. Du wirst lernen, wie man:
Am Ende wirst du besser verstehen, wie du Metaflow nutzen kannst, um Workflows für maschinelles Lernen effizient zu strukturieren und auszuführen. Los geht's!
Zu Beginn werden wir einen einfachen Ablauf erstellen, der einen Datensatz lädt, das Training durchführt und die Ergebnisse des Modells ausgibt.
Hinweis: Der Code kann unter in DataLab ausgeführt werden.
from metaflow import FlowSpec, step, Parameter, NBRunner
class TrainModelFlow(FlowSpec):
@step
def start(self):
# Load and split the dataset
print("Loading data...")
self.data = [1, 2, 3, 4, 5] # Replace with actual data loading logic
self.labels = [0, 1, 0, 1, 0] # Replace with labels
self.next(self.train_model)
@step
def train_model(self):
# Training a simple model (e.g., linear regression)
print("Training the model...")
self.model = sum(self.data) / len(self.data) # Replace with actual model training
print(f"Model output: {self.model}")
self.next(self.end)
@step
def end(self):
# Final step
print("Training complete. Model ready for deployment!")fIn diesem Code legen wir drei Schritte fest:
start(): Lädt und splittet den Datensatz. In einem realen Szenario würdest du Daten aus einer tatsächlichen Quelle (z. B. einer Datei oder Datenbank) laden.train_model(): Simuliert das Training eines Modells. Hier wird eine einfache Durchschnittsberechnung anstelle eines tatsächlichen Algorithmus für maschinelles Lernen durchgeführt, aber du kannst diesen durch jeden beliebigen Trainingscode ersetzen, den du brauchst.end(): Markiert das Ende des Flusses und zeigt an, dass das Modell bereit für den Einsatz ist.Sobald du den Fluss definiert hast, kannst du ihn mit dem folgenden Befehl ausführen:
run = NBRunner(TrainModelFlow)
run.nbrun()Beachte, dass dieser Code nur in Notizbüchern funktioniert (der gesamte Code muss in einer Zelle stehen).
Wenn du diesen Code als Skript ausführen willst, entferne die NBRunner Befehle und füge Folgendes an das Ende deines Skripts an und speichere es (z. B. "metaflow_ml_model.py"):
if __name__ == "__main__":
TrainModelFlow()Um das Skript auszuführen, navigierst du zur Befehlszeile und führst den folgenden Befehl aus:
py -m metaflow_ml_model.py Metaflow verfolgt automatisch jeden Lernpfad und lässt dich die Ergebnisse über die Metaflow-Benutzeroberflächevisualisieren .
Wie können wir also das Beste aus den Funktionen von Metaflow herausholen? Hier sind ein paar Best Practices, die dir helfen können, dieses Ziel zu erreichen und gleichzeitig deine Arbeitsabläufe zu optimieren:
Wenn du Metaflow zum ersten Mal verwendest, solltest du mit einfachen Workflows beginnen, um dich mit der API vertraut zu machen. Wenn du klein anfängst, kannst du besser verstehen, wie das Framework funktioniert und Vertrauen in seine Fähigkeiten aufbauen, bevor du dich an komplexere Projekte wagst. Dieser Ansatz reduziert die Lernkurve und stellt sicher, dass dein Fundament solide ist.
Metaflow verfügt über eine leistungsstarke Benutzeroberfläche, die für das Debugging und die Nachverfolgung deiner Arbeitsabläufe äußerst hilfreich sein kann. Nutze die Benutzeroberfläche, um Läufe zu überwachen, die Ergebnisse einzelner Schritte zu überprüfen und eventuelle Probleme zu erkennen. Die Visualisierung deiner Daten und Protokolle macht es einfacher, Probleme während der Ausführung deines Workflows zu erkennen und zu beheben.
Wenn du Metaflow zum ersten Mal installierst, arbeitet es im lokalen Modus. In diesem Modus werden Artefakte und Metadaten in einem lokalen Verzeichnis gespeichert und die Berechnungen werden mit lokalen Prozessen ausgeführt. Für den persönlichen Gebrauch ist diese Konfiguration gut geeignet, aber wenn dein Projekt Zusammenarbeit oder große Datenmengen beinhaltet, ist es ratsam, Metaflow so zu konfigurieren, dass es AWS für eine bessere Skalierbarkeit nutzt. Das Gute daran ist, dass Metaflow eine hervorragende Integration mit AWS bietet.
In diesem Tutorial haben wir uns angesehen, wie du mit Metaflow anfängst, von der Installation bis zur Erstellung deines ersten Data Science Workflows. Wir haben die wichtigsten Konzepte behandelt, wie z.B. die Definition von Lernpfaden, die Verwendung von Datenartefakten, um Daten zwischen Lernpfaden weiterzugeben, und die Versionierung, um Läufe zu verfolgen und zu reproduzieren. Außerdem haben wir ein praktisches Beispiel für das Training eines maschinellen Lernmodells durchgespielt, in dem wir gezeigt haben, wie du deinen Workflow definierst, ausführst und überwachst. Zum Schluss haben wir noch einige Best Practices besprochen, die dir helfen, Metaflow optimal zu nutzen.
Wenn du mehr über MLOps erfahren möchtest, schau dir die folgenden Ressourcen an:
Lerne mehr über Python und maschinelles Lernen mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.