
Curso
Implantação e ciclo de vida em MLOps
4 h
12K
O Metaflow é uma estrutura avançada para criar e gerenciar fluxos de trabalho de dados. Neste tutorial, você aprenderá como começar. Em especial, abordaremos o assunto:
Ao final deste artigo, você terá as habilidades necessárias para otimizar e dimensionar seus fluxos de trabalho com eficiência!
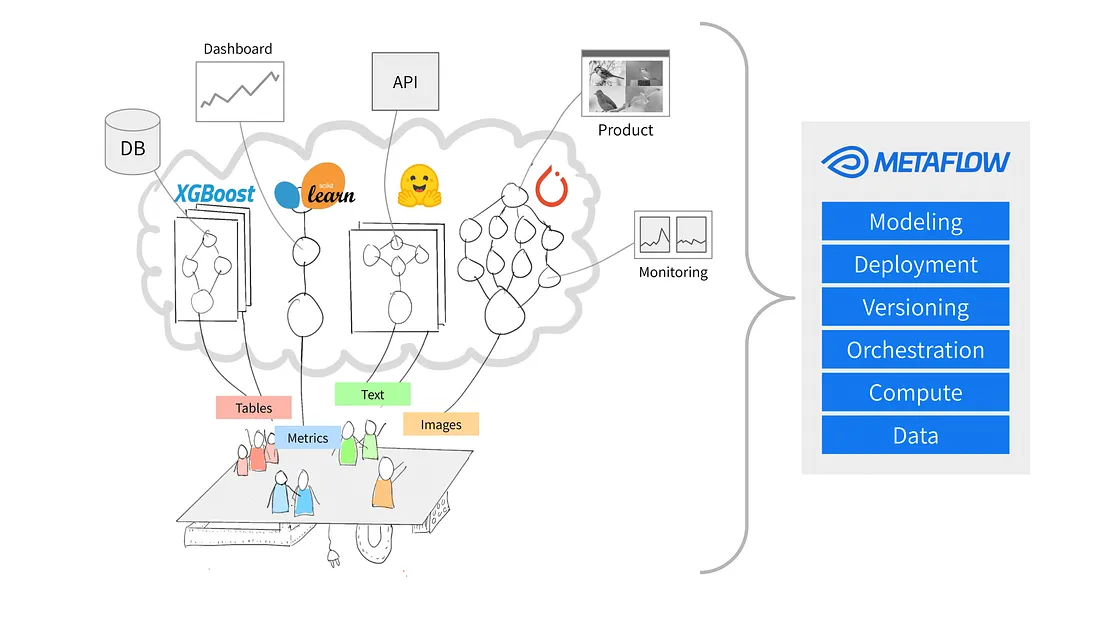
Fonte: Por que a Metaflow?
O Metaflow é uma estrutura Python projetada para ajudar a gerenciar projetos de ciência de dados. Inicialmente, a Netflix desenvolveu a ferramenta para ajudar os cientistas de dados e engenheiros de aprendizado de máquina a serem mais produtivos. Ele atinge esseobjetivo simplificando tarefas complexas, como a orquestração do fluxo de trabalho, que garante que os processos sejam executados sem problemas do início ao fim.
Os principais recursos do Metaflow incluem o controle automático de versões de dados, que rastreia as alterações nos fluxos de trabalho, e o suporte a fluxos de trabalho dimensionáveis, que permite aos usuários lidar com conjuntos de dados maiores e tarefas mais complexas.
Outra vantagem do Metaflow é que ele se integra facilmente ao AWS. Isso significa que os usuários podem aproveitar os recursos da nuvem para armazenamento e capacidade de computação. Além disso, sua API Python de fácil utilização o torna acessível tanto para iniciantes quanto para usuários experientes.
Vamos começar a configurá-lo.
O Metaflowsugere que os usuários instalem o Python 3 em vez do Python 2.7 para novos projetos. A documentação afirma que "o Python 3 tem menos bugs e é mais bem suportado do que o depreciado Python 2.7".
A próxima etapa é criar um ambiente virtual para gerenciar as dependências do seu projeto. Para isso, execute o seguinte comando:
python -m venv venv
source venv/bin/activateIsso criará e ativará um ambiente virtual. Depois de ativado, você estará pronto para instalar o Metaflow.
O Metaflow está disponível como um pacote Python para MacOS e Linux. A versão mais recente pode ser instalada a partir do repositório Metaflow Github ou do PyPi, executando o seguinte comando:
pip install metaflowInfelizmente, no momento em que este artigo foi escrito, o Metaflow não oferece suporte nativo para usuários do Windows. No entanto, os usuários do Windows 10 podem usar o WSL (Subsistema Windows para Linux) para instalar o Metaflow, o que lhes permite executar um ambiente Linux dentro do sistema operacional Windows. Acessea documentação para obter um guia passo a passo sobre a instalação do Metaflow no Windows 10.
O Metaflow oferece integração perfeita com o AWS, o que permite aos usuários dimensionar seus fluxos de trabalho usando a infraestrutura de nuvem. Para integrar o AWS, você precisará configurar suas credenciais do AWS.
Observação: Essas etapas pressupõem que você já tenha uma conta do AWS e o AWS CLI instalado. Para obter mais detalhes, siga as instruções da documentação da AWS.
pip install awscliaws configureA partir daqui, você será solicitado a inserir o ID da chave de acesso do AWS e a chave de acesso secreta - essas são simplesmente as credenciais que a CLI do AWS usa para autenticar suas solicitações ao AWS. Observe que você também pode ser solicitado a inserir sua região e o formato de saída.
Quando você tiver inserido esses detalhes, pronto! O Metaflow usará automaticamente suas credenciais do AWS para executar fluxos de trabalho.
Agora que o Metaflow está configurado, é hora de você criar seu primeiro fluxo de trabalho. Nesta seção, mostrarei a você os conceitos básicos para criar um fluxo, executá-lo e entender como as tarefas e etapas são organizadas na Metaflow.
Ao final desta seção, você terá um fluxo de trabalho que processa dados e executa operações simples. Vamos lá!
O Metaflow usa o paradigma de fluxo de dados, que representa um programa como um gráfico direcionado de operações. Essa abordagem é ideal para a criação de pipelines de processamento de dados, especialmente em aprendizado de máquina.
No Metaflow, o gráfico de operações é chamado de fluxo. Um fluxo consiste em uma série de tarefas divididas em etapas. Observe que cada etapa pode ser considerada uma operação representada como um nó, com as transições entre as etapas atuando como as bordas do gráfico.
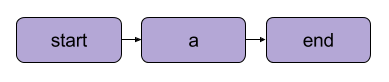
Uma transição linear básica do Metaflow Fonte: Documentação do Metaflow
Existem algumas regras estruturais para fluxos no Metaflow. Por exemplo, todo fluxo deve incluir uma etapainicial e uma etapafinal. Quando um fluxo é executado, conhecido como run, ele começa com a etapa inicial e é considerado bem-sucedido se atingir a etapa final sem erros .
O que acontece entre as etapas inicial e final depende inteiramente de você, como verá no próximo segmento.
Aqui está um fluxo simples para você começar. Observação: O código pode ser executado em no DataLab.
from metaflow import FlowSpec, step
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
if __name__ == '__main__':
MyFirstFlow()Nesse fluxo:
start() inicializa o fluxo de trabalho e define um conjunto de dados.process_data() processa os dados duplicando cada elemento.end() conclui o fluxo.Cada etapa usa o decorador @step, e você define a sequência de fluxo usando self.next() para conectar as etapas.
Depois de escrever seu fluxo, salve-o como my_first_flow.py. Execute-o na linha de comando usando:
py -m my_first_flow.py runUm novo recurso foi adicionado ao Metaflow 2.12, permitindo que os usuários desenvolvam e executem fluxos em notebooks.
Para executar um fluxo em uma célula definida, tudo o que você deve fazer é adicionar a linha NBRunner na última linha da mesma célula. Por exemplo:
from metaflow import FlowSpec, step, NBRunner
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(MyFirstFlow).nbrun()Se você receber o seguinte erro:
"O Metaflow não pôde determinar seu nome de usuário com base em variáveis de ambiente ($USERNAME etc.)"
Adicione o seguinte ao seu código antes da execução do Metaflow:
import os
if os.environ.get("USERNAME") is None:
os.environ["USERNAME"] = "googlecolab"Em ambos os casos, o Metaflow executará o fluxo passo a passo. Ou seja, ele exibirá a saída de cada etapa no terminal da seguinte forma:
A saída do código acima Fonte: Imagem do autor
Compreender os principais conceitos do Metaflow é essencial para a criação de fluxos de trabalho de dados eficientes e dimensionáveis. Nesta seção, abordarei três conceitos fundamentais:
Esses elementos formam a espinha dorsal da estrutura e da execução de fluxos de trabalho do Metaflow, permitindo que você gerencie processos complexos com facilidade.
Falamos brevemente sobre as etapas no início do artigo, mas, para maior clareza, vamos revisá-las novamente. O mais importante que você deve entender sobre os fluxos de trabalho do Metaflow é que eles são criados com base em etapas.
As etapas representam cada tarefa individual em um fluxo de trabalho. Em outras palavras, cada etapa executará uma operação específica (por exemplo, carregamento de dados, processamento, modelagem etc.).
O exemplo que criamos acima em "Escrevendo seu primeiro fluxo" foi uma transformação linear. Além das etapas sequenciais, o Metaflow também permite que os usuários ramifiquem fluxos de trabalho. Os fluxos de trabalho de ramificação permitem que você execute várias tarefas em paralelo, criando caminhos separados para a execução.
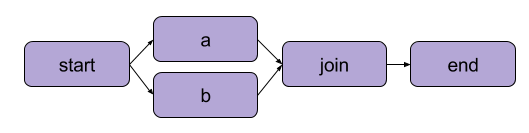
Um exemplo de ramificação | Fonte: Documentação do Metaflow
O principal benefício de uma filial é o desempenho. A ramificação significa que o Metaflow pode executar várias etapas em vários núcleos de CPU ou instâncias na nuvem.
Aqui está a aparência de uma ramificação no código:
from metaflow import FlowSpec, step, NBRunner
class BranchFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.split)
@step
def split(self):
self.next(self.branch1, self.branch2)
@step
def branch1(self):
# Code for branch 1
print("This is branch 1")
self.next(self.join)
@step
def branch2(self):
# Code for branch 2
print("This is branch 2")
self.next(self.join)
@step
def join(self, inputs):
# Merging branches back
print("Branches joined.")
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(BranchFlow).nbrun()|
💡TLDR: A ramificação permite que os usuários criem fluxos de trabalho complexos que podem processar simultaneamente várias tarefas. |
Artefatosde dados são variáveis que permitem que você armazene e passe dados entre as etapas de um fluxo de trabalho. Esses artefatos mantêm o resultado de uma etapa para a próxima - é assim que os dados são disponibilizados para as etapas subsequentes.
Essencialmente, quando você atribui dados a self em uma etapa de uma classe Metaflow, você os salva como um artefato, que pode ser acessado por qualquer outra etapa do fluxo (consulte os comentários no código).
class ArtifactFlow(FlowSpec):
@step
def start(self):
# Step 1: Initializing data
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset saved as an artifact
self.next(self.process_data)
@step
def process_data(self):
# Step 2: Processing the data from the 'start' step
self.processed_data = [x * 2 for x in self.data] # Processing artifact data
print("Processed data:", self.processed_data)
self.next(self.save_results)
@step
def save_results(self):
# Step 3: Saving the processed data artifact
self.results = sum(self.processed_data) # Saving final result as an artifact
print("Sum of processed data:", self.results)
self.next(self.end)
@step
def end(self):
# Final step
print("Flow is complete!")
print(f"Final result: {self.results}") # Accessing artifact in final stepPor que os artefatos são um conceito central do Metaflow? Porque eles têm vários usos:
O Metaflow lida automaticamente com o controle de versão para seus fluxos de trabalho. Isso significa que cada vez que um fluxo é executado, ele é rastreado como uma execução exclusiva. Em outras palavras, cada execução tem sua própria versão, permitindo que você revise e reproduza facilmente as execuções anteriores.
O Metaflow faz isso atribuindo identificadores exclusivos a cada execução e preservando os dados e artefatos dessa execução. Essa persistência garante que nenhum dado seja perdido entre as execuções. Os fluxos de trabalho anteriores podem ser facilmente revisitados e inspecionados, e etapas específicas podem ser executadas novamente, se necessário. Como resultado, a depuração e o desenvolvimento iterativo são muito mais eficientes, e a manutenção da reprodutibilidade é simplificada.
Nesta seção, vou orientar você no uso do Metaflow para treinar um modelo de aprendizado de máquina. Você aprenderá a:
Ao final, você entenderá melhor como usar o Metaflow para estruturar e executar fluxos de trabalho de aprendizado de máquina com eficiência. Vamos lá!
Para começar, criaremos um fluxo básico que carrega um conjunto de dados, executa o treinamento e gera os resultados do modelo.
Observação: O código pode ser executado no DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner
class TrainModelFlow(FlowSpec):
@step
def start(self):
# Load and split the dataset
print("Loading data...")
self.data = [1, 2, 3, 4, 5] # Replace with actual data loading logic
self.labels = [0, 1, 0, 1, 0] # Replace with labels
self.next(self.train_model)
@step
def train_model(self):
# Training a simple model (e.g., linear regression)
print("Training the model...")
self.model = sum(self.data) / len(self.data) # Replace with actual model training
print(f"Model output: {self.model}")
self.next(self.end)
@step
def end(self):
# Final step
print("Training complete. Model ready for deployment!")fNesse código, definimos três etapas:
start(): Carrega e divide o conjunto de dados. Em um cenário do mundo real, você carregaria dados de uma fonte real (por exemplo, um arquivo ou banco de dados).train_model(): Simula o treinamento de um modelo. Aqui, um simples cálculo de média é realizado em vez de um algoritmo real de aprendizado de máquina, mas você pode substituí-lo por qualquer código de treinamento que precisar.end(): Marca o fim do fluxo e significa que o modelo está pronto para ser implantado.Depois de definir o fluxo, você pode executá-lo usando o seguinte comando:
run = NBRunner(TrainModelFlow)
run.nbrun()Observe que esse código só funciona em notebooks (todo o código deve estar em uma célula).
Se você quiser executar esse código como um script, remova os comandos NBRunner e anexe o seguinte ao final do script e salve-o (por exemplo, "metaflow_ml_model.py"):
if __name__ == "__main__":
TrainModelFlow()Em seguida, para executar o script, navegue até a linha de comando e execute o seguinte comando:
py -m metaflow_ml_model.py O Metaflow rastreia automaticamente cada execução e permite que você visualize os resultados por meio da interface do usuário do Metaflow.
Então, como você pode aproveitar ao máximo os recursos do Metaflow? Aqui estão algumas práticas recomendadas que podem ajudar você a realizar essa façanha e, ao mesmo tempo, otimizar seus fluxos de trabalho:
Se você for novo no Metaflow, comece com fluxos de trabalho simples para se familiarizar com a API. Começar com algo pequeno ajudará você a entender como a estrutura funciona e a criar confiança em seus recursos antes de passar para projetos mais complexos. Essa abordagem reduz a curva de aprendizado e garante que você tenha uma base sólida.
O Metaflow inclui uma interface de usuário avançadaque pode ser extremamente útil para depurar e rastrear seus fluxos de trabalho. Use a interface do usuário para monitorar execuções, verificar os resultados de etapas individuais e identificar quaisquer problemas que possam surgir. A visualização dos dados e dos registros facilita a identificação e a correção de problemas durante a execução do fluxo.
Quando você instala o Metaflow pela primeira vez, ele opera no modo local. Nesse modo, os artefatos e os metadados são salvos em um diretório local e os cálculos são executados usando processos locais. Essa configuração funciona bem para uso pessoal, mas se o seu projeto envolver colaboração ou grandes conjuntos de dados, é recomendável configurar o Metaflow para utilizar o AWS para melhorar a escalabilidade. O ponto positivo aqui é que o Metaflow oferece excelente integração com o AWS.
Neste tutorial, exploramos como você pode começar a usar o Metaflow, desde a instalação até a criação do seu primeiro fluxo de trabalho de ciência de dados. Abordamos os principais conceitos, como a definição de etapas, o uso de artefatos de dados para passar dados entre etapas e o controle de versão para rastrear e reproduzir execuções. Também apresentamos um exemplo prático de treinamento de um modelo de aprendizado de máquina, que demonstrou como definir, executar e monitorar seu fluxo de trabalho. Por fim, abordamos algumas práticas recomendadas para ajudar você a tirar o máximo proveito do Metaflow.
Para continuar aprendendo sobre MLOps, confira os seguintes recursos:
Aprenda mais sobre Python e aprendizado de máquina com estes cursos!
Curso
Curso
Curso
Tutorial
Nadia mhadhbi
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma