
Cours
Déploiement MLOps et cycle de vie
4 h
12K
Metaflow est un cadre puissant pour la construction et la gestion de flux de données. Dans ce tutoriel, vous apprendrez comment démarrer. Nous aborderons notamment les points suivants :
À la fin de cet article, vous aurez acquis les compétences nécessaires pour rationaliser et développer efficacement vos flux de travail !
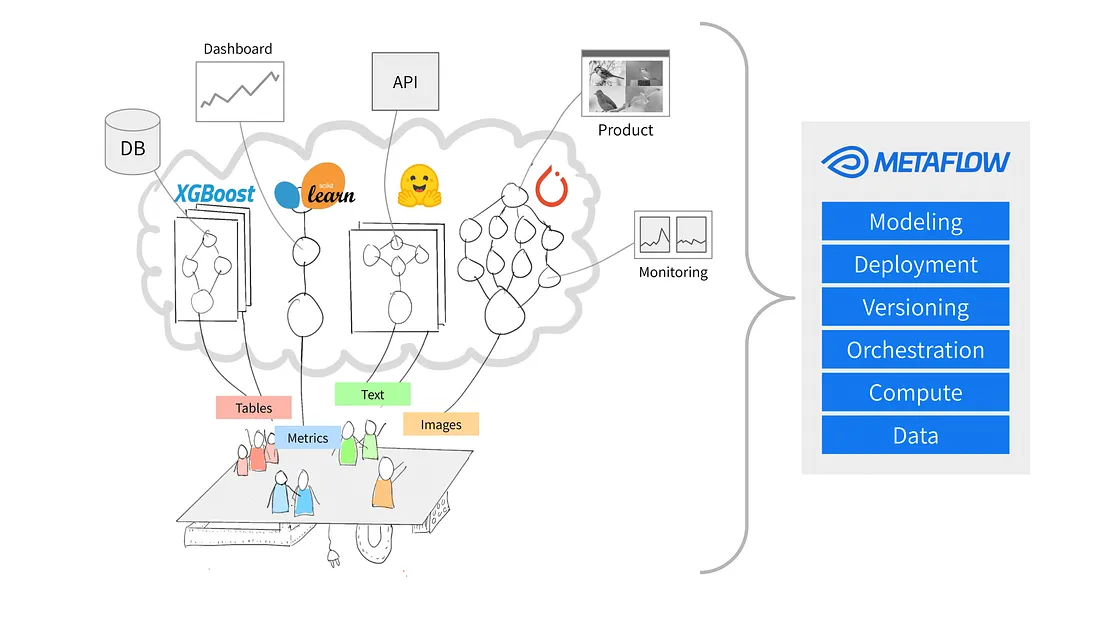
Source : Pourquoi Metaflow ?
Metaflow est un framework Python conçu pour faciliter la gestion des projets de science des données. Netflix a initialement développé l'outil pour aider les scientifiques des données et les ingénieurs en apprentissage automatique à être plus productifs. Il atteint cetobjectif en simplifiant les tâches complexes, comme l'orchestration des flux de travail, qui garantit le bon déroulement des processus du début à la fin.
Parmi les principales caractéristiques de Metaflow figurent le versionnage automatique des données, qui permet de suivre les modifications apportées à vos flux de travail, et la prise en charge des flux de travail évolutifs, qui permet aux utilisateurs de gérer des ensembles de données plus importants et des tâches plus complexes.
Un autre avantage de Metaflow est qu'il s'intègre facilement à AWS. Cela signifie que les utilisateurs peuvent exploiter les ressources du cloud pour le stockage et la puissance de calcul. En outre, son API Python conviviale le rend accessible aux débutants comme aux utilisateurs expérimentés.
Commençons à le mettre en place.
Metaflowsuggère aux utilisateurs d'installer Python 3 plutôt que Python 2.7 pour les nouveaux projets. La documentation indique que "Python 3 a moins de bogues et est mieux pris en charge que Python 2.7, qui est déprécié."
L'étape suivante consiste à créer un environnement virtuel pour gérer les dépendances de votre projet. Pour ce faire, exécutez la commande suivante :
python -m venv venv
source venv/bin/activateCela permet de créer et d'activer un environnement virtuel. Une fois activé, vous êtes prêt à installer Metaflow.
Metaflow est disponible sous la forme d'un paquetage Python pour MacOS et Linux. La dernière version peut être installée à partir du dépôt Github de Metaflow ou de PyPi en exécutant la commande suivante :
pip install metaflowMalheureusement, à l'heure où nous écrivons ces lignes, Metaflow n'offre pas de support natif pour les utilisateurs de Windows. Toutefois, les utilisateurs de Windows 10 peuvent utiliser WSL (Windows Subsystem for Linux) pour installer Metaflow, ce qui leur permet d'exécuter un environnement Linux à l'intérieur de leur système d'exploitation Windows. Consultezla documentation pour obtenir un guide étape par étape sur l'installation de Metaflow sur Windows 10.
Metaflow offre une liaison transparente avec AWS, ce qui permet aux utilisateurs de faire évoluer leurs flux de travail à l'aide d'une infrastructure cloud. Pour intégrer AWS, vous devez configurer vos identifiants AWS.
Note : Ces étapes supposent que vous disposez déjà d'un compte AWS et que vous avez installé AWS CLI. Pour plus de détails, suivez les instructions de la documentation AWS.
pip install awscliaws configureÀ partir de là, vous serez invité à saisir votre ID de clé d'accès AWS et votre clé d'accès secrète - il s'agit simplement des informations d'identification que l'interface de commande AWS utilise pour authentifier vos demandes auprès d'AWS. Notez que vous pouvez également être invité à entrer votre région et votre format de sortie.
Une fois que vous avez saisi ces informations, voilà ! Metaflow utilisera automatiquement vos identifiants AWS pour exécuter les flux de travail.
Maintenant que Metaflow est installé, il est temps de créer votre premier flux de travail. Dans cette section, je vous expliquerai les bases de la création d'un flux, de son exécution et de la compréhension de l'organisation des tâches et des étapes dans Metaflow.
À la fin de cette section, vous disposerez d'un flux de travail qui traitera des données et effectuera des opérations simples. Allons-y !
Metaflow utilise le paradigme du flux de données, qui représente un programme sous la forme d'un graphe orienté d'opérations. Cette approche est idéale pour créer des pipelines de traitement de données, en particulier dans le domaine de l'apprentissage automatique.
Dans Metaflow, le graphe des opérations est appelé flux. Un flux consiste en une série de tâches divisées en étapes. Notez que chaque étape peut être considérée comme une opération représentée par un nœud, les transitions entre les étapes constituant les arêtes du graphe.
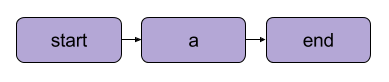
Une transition linéaire de base Metaflow Source : Documentation Metaflow
Il existe quelques règles structurelles pour les flux dans Metaflow. Par exemple, chaque flux doit comprendre une étape de démarrage et une étape defin. Lorsqu'un flux s'exécute ( ), il commence par l'étape de départ et est considéré comme réussi s'il atteint l'étape de fin sans erreur.
Ce qui se passe entre les étapes de début et de fin dépend entièrement de vous, comme vous le verrez dans le segment suivant.
Voici un flux simple pour commencer. Note : Le code peut être exécuté à l'adresse dans DataLab.
from metaflow import FlowSpec, step
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
if __name__ == '__main__':
MyFirstFlow()Dans ce flux :
start() initialise le flux de travail et définit un ensemble de données.process_data() traite les données en doublant chaque élément.end() complète le flux.Chaque étape utilise le décorateur @step et vous définissez la séquence de flux à l'aide de self.next() pour relier les étapes.
Après avoir rédigé votre flux, sauvegardez-le sous my_first_flow.py. Exécutez-le à partir de la ligne de commande en utilisant :
py -m my_first_flow.py runUne nouvelle fonctionnalité a été ajoutée dans Metaflow 2.12 qui permet aux utilisateurs de développer et d'exécuter des flux dans des carnets.
Pour exécuter un flux dans une cellule définie, il vous suffit d'ajouter la ligne NBRunner à la dernière ligne de la même cellule. Par exemple :
from metaflow import FlowSpec, step, NBRunner
class MyFirstFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.process_data)
@step
def process_data(self):
self.processed_data = [x * 2 for x in self.data] # Simple data processing
print("Processed data:", self.processed_data)
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(MyFirstFlow).nbrun()Si vous obtenez l'erreur suivante :
"Metaflow n'a pas pu déterminer votre nom d'utilisateur sur la base des variables d'environnement ($USERNAME etc.)"
Ajoutez ce qui suit à votre code avant l'exécution de Metaflow :
import os
if os.environ.get("USERNAME") is None:
os.environ["USERNAME"] = "googlecolab"Dans les deux cas, Metaflow exécute le flux étape par étape. En d'autres termes, il affichera le résultat de chaque étape dans le terminal de la manière suivante :
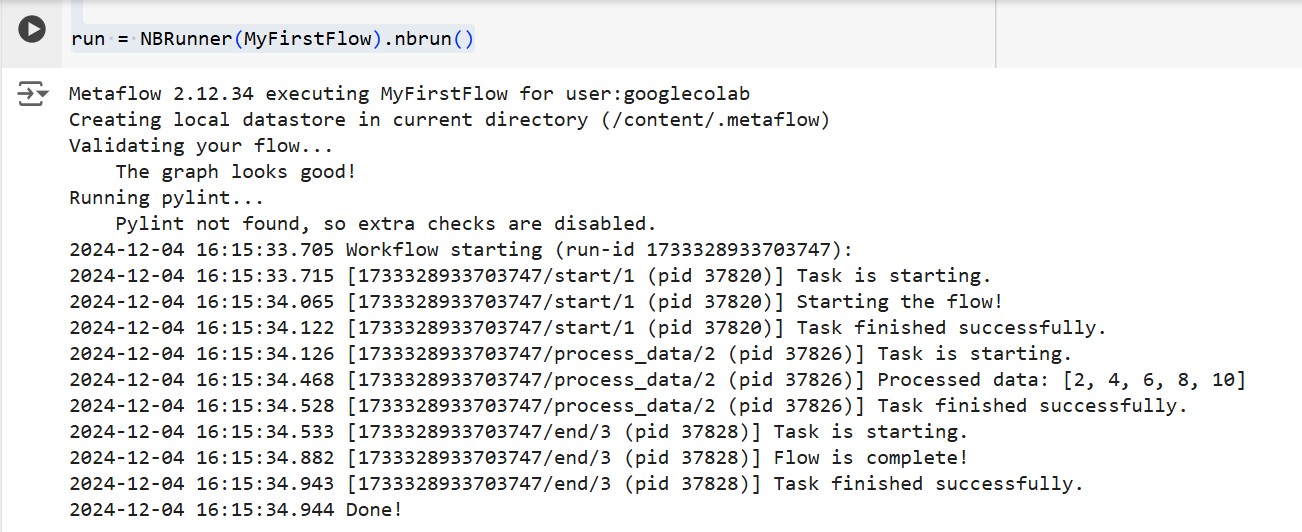
La sortie du code ci-dessus Source : Image de l'auteur
Comprendre les concepts fondamentaux de Metaflow est essentiel pour construire des flux de données efficaces et évolutifs. Dans cette section, j'aborderai trois concepts fondamentaux :
Ces éléments constituent l'épine dorsale de la structure et de l'exécution des flux de travail de Metaflow, ce qui vous permet de gérer facilement des processus complexes.
Nous avons brièvement abordé les étapes plus haut dans l'article, mais par souci de clarté, nous allons y revenir. La chose la plus importante à comprendre à propos des flux de travail Metaflow est qu'ils sont construits autour d'étapes.
Les étapes représentent chaque tâche individuelle au sein d'un flux de travail. En d'autres termes, chaque étape effectue une opération spécifique (par exemple, chargement de données, traitement, modélisation, etc.)
L'exemple que nous avons créé ci-dessus dans "Écrire votre premier flux" était une transformation linéaire. Outre les étapes séquentielles, Metaflow permet également aux utilisateurs d'accéder aux flux de travail et. Les flux de travail par branche vous permettent d'exécuter plusieurs tâches en parallèle en créant des chemins d'exécution distincts.
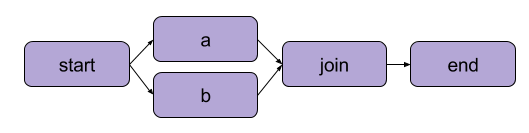
Un exemple de ramification | Source : Documentation Metaflow
Le principal avantage d'une succursale est la performance. Le branchement signifie que Metaflow peut exécuter diverses étapes sur plusieurs cœurs de CPU ou instances dans le cloud.
Voici à quoi ressemblerait une branche dans le code :
from metaflow import FlowSpec, step, NBRunner
class BranchFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset
self.next(self.split)
@step
def split(self):
self.next(self.branch1, self.branch2)
@step
def branch1(self):
# Code for branch 1
print("This is branch 1")
self.next(self.join)
@step
def branch2(self):
# Code for branch 2
print("This is branch 2")
self.next(self.join)
@step
def join(self, inputs):
# Merging branches back
print("Branches joined.")
self.next(self.end)
@step
def end(self):
print("Flow is complete!")
run = NBRunner(BranchFlow).nbrun()|
💡TLDR : Le branchement permet aux utilisateurs de concevoir des flux de travail complexes qui peuvent traiter simultanément plusieurs tâches. |
Artefacts dedonnées sont des variables qui vous permettent de stocker et de transmettre des données entre les étapes d'un flux de travail. Ces artefacts conservent les résultats d'une étape à l'étape suivante - c'est ainsi que les données sont mises à la disposition des étapes suivantes.
Essentiellement, lorsque vous affectez des données à self dans une étape d'une classe Metaflow, vous les enregistrez en tant qu'artefact, auquel toute autre étape du flux peut ensuite accéder (voir les commentaires dans le code).
class ArtifactFlow(FlowSpec):
@step
def start(self):
# Step 1: Initializing data
print("Starting the flow!")
self.data = [1, 2, 3, 4, 5] # Example dataset saved as an artifact
self.next(self.process_data)
@step
def process_data(self):
# Step 2: Processing the data from the 'start' step
self.processed_data = [x * 2 for x in self.data] # Processing artifact data
print("Processed data:", self.processed_data)
self.next(self.save_results)
@step
def save_results(self):
# Step 3: Saving the processed data artifact
self.results = sum(self.processed_data) # Saving final result as an artifact
print("Sum of processed data:", self.results)
self.next(self.end)
@step
def end(self):
# Final step
print("Flow is complete!")
print(f"Final result: {self.results}") # Accessing artifact in final stepPourquoi les artefacts sont-ils un concept central de Metaflow ? Parce qu'ils ont de nombreux usages :
Metaflow gère automatiquement les versions pour vos flux de travail. Cela signifie que chaque fois qu'un flux est exécuté, il fait l'objet d'un cursus unique. En d'autres termes, chaque exécution a sa propre version, ce qui vous permet de revoir et de reproduire facilement les exécutions précédentes.
Pour ce faire, Metaflow attribue des identifiants uniques à chaque exécution et préserve les données et les artefacts de cette exécution. Cette persistance garantit qu'aucune donnée n'est perdue entre les exécutions. Les flux de travail antérieurs peuvent facilement être revus et inspectés, et des étapes spécifiques peuvent être réexécutées si nécessaire. Par conséquent, le débogage et le développement itératif sont beaucoup plus efficaces et le maintien de la reproductibilité est simplifié.
Dans cette section, je vous guiderai dans l'utilisation de Metaflow pour former un modèle d'apprentissage automatique. Vous apprendrez à :
À la fin, vous comprendrez mieux comment utiliser Metaflow pour structurer et exécuter efficacement des flux de travail d'apprentissage automatique. Allons-y !
Pour commencer, nous allons créer un flux de base qui charge un ensemble de données, effectue la formation et produit les résultats du modèle.
Note : Le code peut êtreexécuté à l'adresse dans DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner
class TrainModelFlow(FlowSpec):
@step
def start(self):
# Load and split the dataset
print("Loading data...")
self.data = [1, 2, 3, 4, 5] # Replace with actual data loading logic
self.labels = [0, 1, 0, 1, 0] # Replace with labels
self.next(self.train_model)
@step
def train_model(self):
# Training a simple model (e.g., linear regression)
print("Training the model...")
self.model = sum(self.data) / len(self.data) # Replace with actual model training
print(f"Model output: {self.model}")
self.next(self.end)
@step
def end(self):
# Final step
print("Training complete. Model ready for deployment!")fDans ce code, nous définissons trois étapes :
start(): Charge et divise le jeu de données. Dans un scénario réel, vous chargeriez des données à partir d'une source réelle (par exemple, un fichier ou une base de données).train_model(): Simule la formation d'un modèle. Ici, un simple calcul de moyenne est effectué au lieu d'un véritable algorithme d'apprentissage automatique, mais vous pouvez le remplacer par n'importe quel code d'apprentissage dont vous avez besoin.end(): Marque la fin du flux et signifie que le modèle est prêt à être déployé.Une fois le flux défini, vous pouvez l'exécuter à l'aide de la commande suivante :
run = NBRunner(TrainModelFlow)
run.nbrun()Notez que ce code ne fonctionne que dans les carnets (tout le code doit être dans une seule cellule).
Si vous souhaitez exécuter ce code sous forme de script, supprimez les commandes NBRunner et ajoutez ce qui suit à la fin de votre script, puis enregistrez-le (par exemple, "metaflow_ml_model.py") :
if __name__ == "__main__":
TrainModelFlow()Ensuite, pour exécuter le script, accédez à la ligne de commande et exécutez la commande suivante :
py -m metaflow_ml_model.py Metaflow effectue automatiquement le cursus de chaque exécution et vous permet de visualiser les résultats grâce à l'interface utilisateur Metaflow.
Alors, comment tirer le meilleur parti des fonctionnalités de Metaflow ? Voici quelques bonnes pratiques qui peuvent vous aider à réaliser cet exploit tout en optimisant vos flux de travail :
Si vous ne connaissez pas Metaflow, commencez par des flux de travail simples pour vous familiariser avec son API. En commençant par un projet de petite envergure, vous comprendrez mieux le fonctionnement du cadre et prendrez confiance en ses capacités avant de passer à des projets plus complexes. Cette approche réduit la courbe d'apprentissage et garantit la solidité de vos fondations.
Metaflow comprend une interface utilisateur puissantequi peut être extrêmement utile pour le débogage et le suivi de vos flux de travail. Utilisez l'interface utilisateur pour contrôler les exécutions, vérifier les résultats des différentes étapes et identifier les problèmes éventuels. La visualisation de vos données et de vos journaux facilite l'identification et la résolution des problèmes au cours de l'exécution de votre flux.
Lorsque vous installez Metaflow pour la première fois, il fonctionne en mode local. Dans ce mode, les artefacts et les métadonnées sont enregistrés dans un répertoire local et les calculs sont exécutés à l'aide de processus locaux. Cette configuration fonctionne bien pour un usage personnel, mais si votre projet implique une collaboration ou de grands ensembles de données, il est conseillé de configurer Metaflow pour utiliser AWS afin d'améliorer l'évolutivité. L'avantage est que Metaflow offre une excellente intégration avec AWS.
Dans ce tutoriel, nous avons exploré comment démarrer avec Metaflow, de l'installation à la construction de votre premier workflow de science des données. Nous avons abordé les concepts de base, tels que la définition des étapes, l'utilisation d'artefacts de données pour passer des données entre les étapes, et le versionnage pour suivre et reproduire les exécutions. Nous avons également abordé un exemple pratique de formation d'un modèle d'apprentissage automatique, qui montre comment définir, exécuter et surveiller votre flux de travail. Enfin, nous avons abordé quelques bonnes pratiques pour vous aider à tirer le meilleur parti de Metaflow.
Pour poursuivre votre apprentissage des MLOps, consultez les ressources suivantes :
Apprenez-en plus sur Python et l'apprentissage automatique avec ces cours !
Cours
Cours
Cours