
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.6K
Das neueste OCR-Modell von Mistral, Mistral OCR 3, kann Text und eingebettete Bilder aus vielen verschiedenen Dokumenten mit einer super Genauigkeit extrahieren.
In diesem Artikel zeige ich dir, wie du Mistral OCR 3 mit AI Studio und der API mit Python optimal nutzen kannst. Wir machen eine kleine App, die ein Foto von einer Speisekarte in eine interaktive Website verwandelt.

Wenn du mehr darüber erfahren möchtest, wie man mit APIs arbeitet, um KI-gestützte Tools zu entwickeln, empfehle ich dir den Kurs „Arbeiten mit der OpenAI-API“. Kurs „Arbeiten mit der OpenAI-API“.
OCR steht für „Optical Character Recognition“ (optische Zeichenerkennung) und ist dafür da, Dokumente in Text umzuwandeln. Zum Beispiel kann es ein Foto von einer handgeschriebenen Notiz in Text umwandeln oder eine Tabelle in einem PDF in eine richtige Tabelle, die man durchsuchen und bearbeiten kann.
Mistral OCR 3 ist das neueste Modell von Mistral AI zum Verstehen von Dokumenten und bietet top Genauigkeit und Effizienz für echte Dokumente. Es extrahiert Text und eingebettete Bilder mit hoher Genauigkeit und behält die Struktur durch Markdown-Ausgabe mit HTML-basierter Rekonstruktion von Tabellen bei, optional auch mit strukturiertem JSON.
Mistral OCR 3 ist in vielen Benchmarks besser als alle anderen Programme:
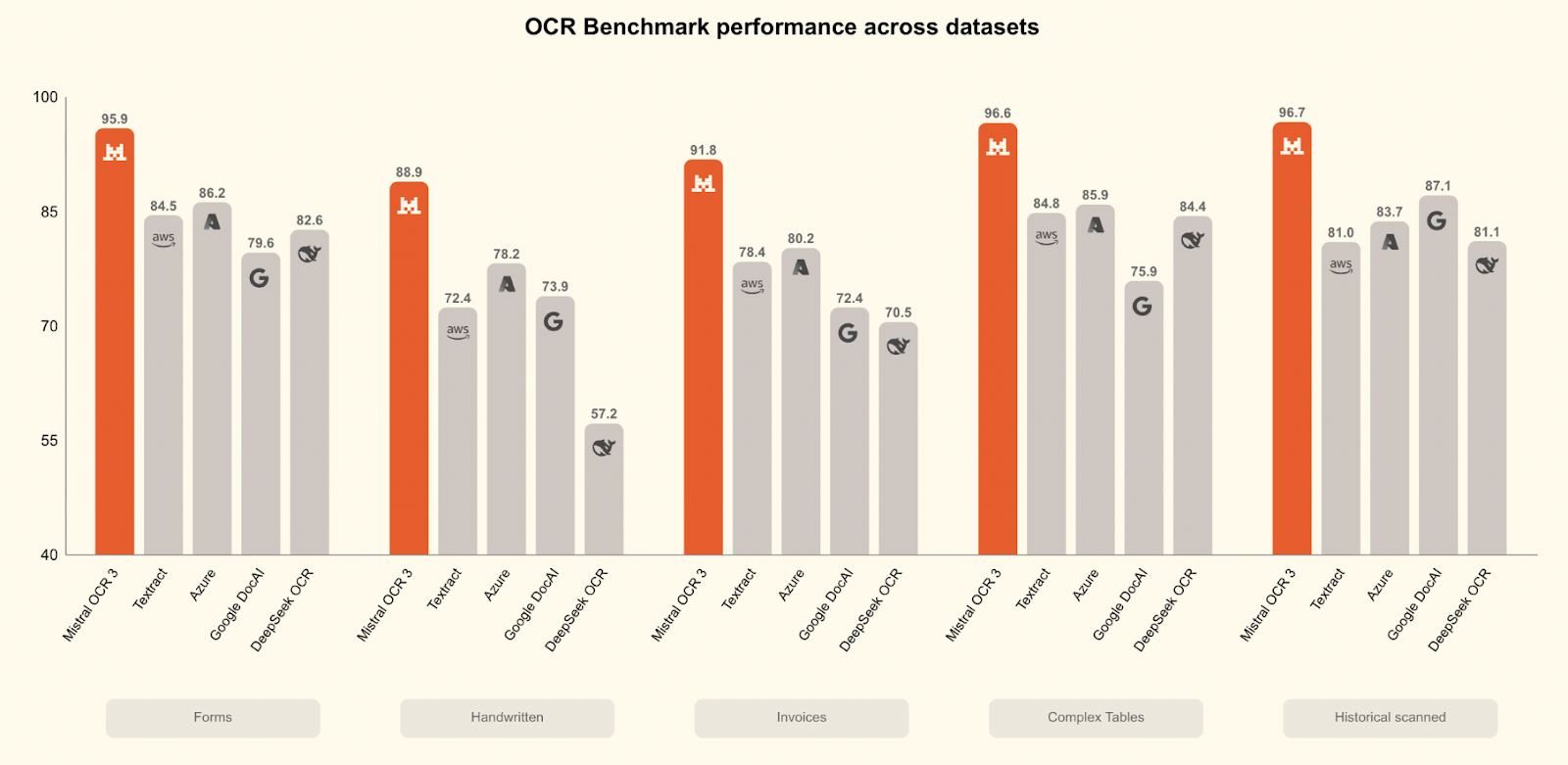
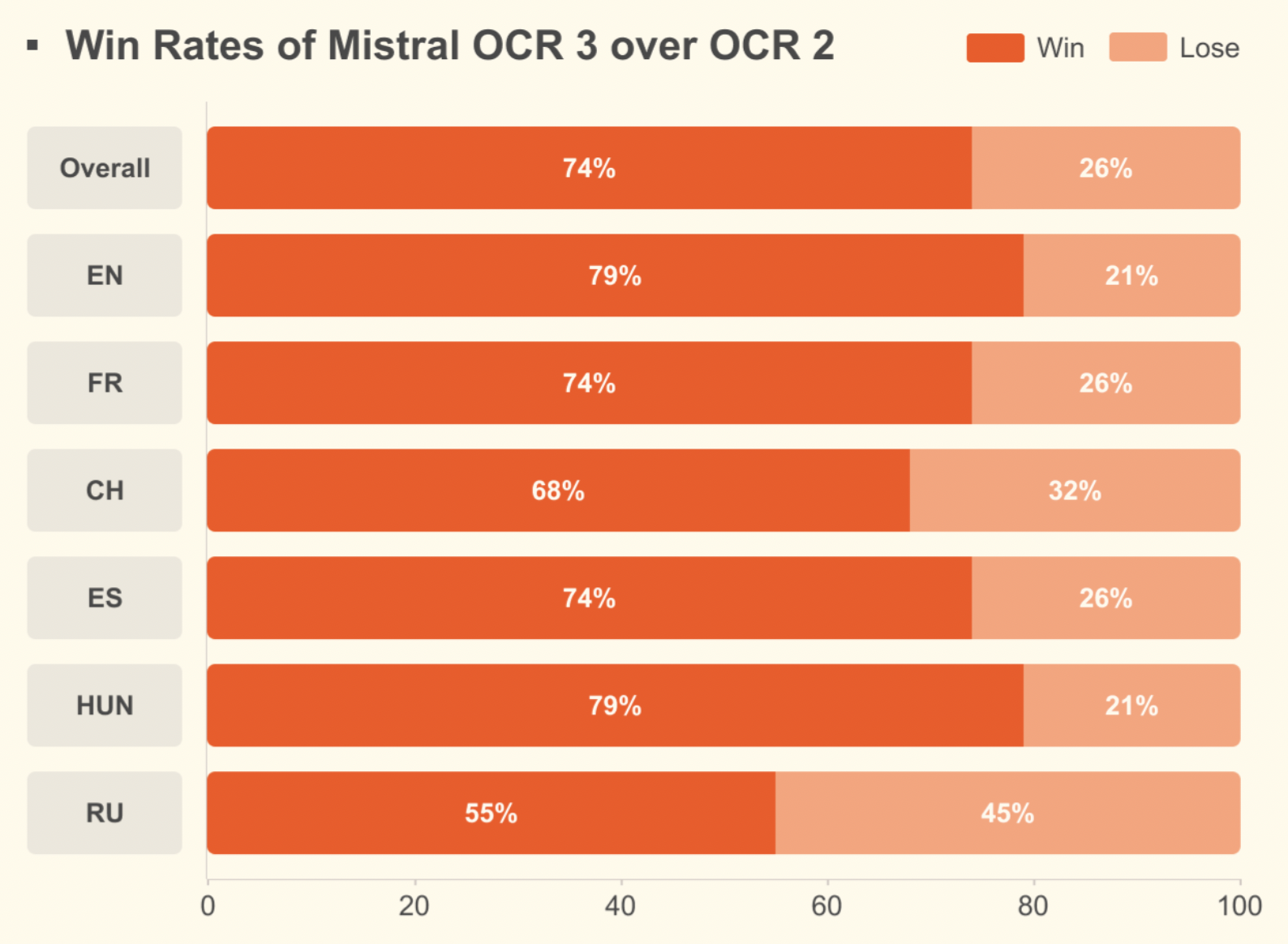
Im Vergleich zu Mistral OCR 2 schafft es eine Erfolgsquote von 74 % bei Formularen, gescannten Dokumenten, komplizierten Tabellen und Handschriften, mit großen Verbesserungen bei Scans mit schlechter Qualität und dichten Layouts.
Mehr über OCR und das Vorgängermodell von Mistral erfährst du in diesem Artikel: Mistral OCR: Ein Leitfaden mit praktischen Beispielen.
Schauen wir mal, wie du Mistral OCR 3 mit AI Studio einrichten kannst.
Mistral OCR 3 kann in ihrem AI Studio. Das ist die einfachste Art, es auszuprobieren, weil es eine benutzerfreundliche Oberfläche hat.
Wenn wir uns anmelden, werden wir zuerst gefragt, ob wir eine Organisation erstellen wollen:
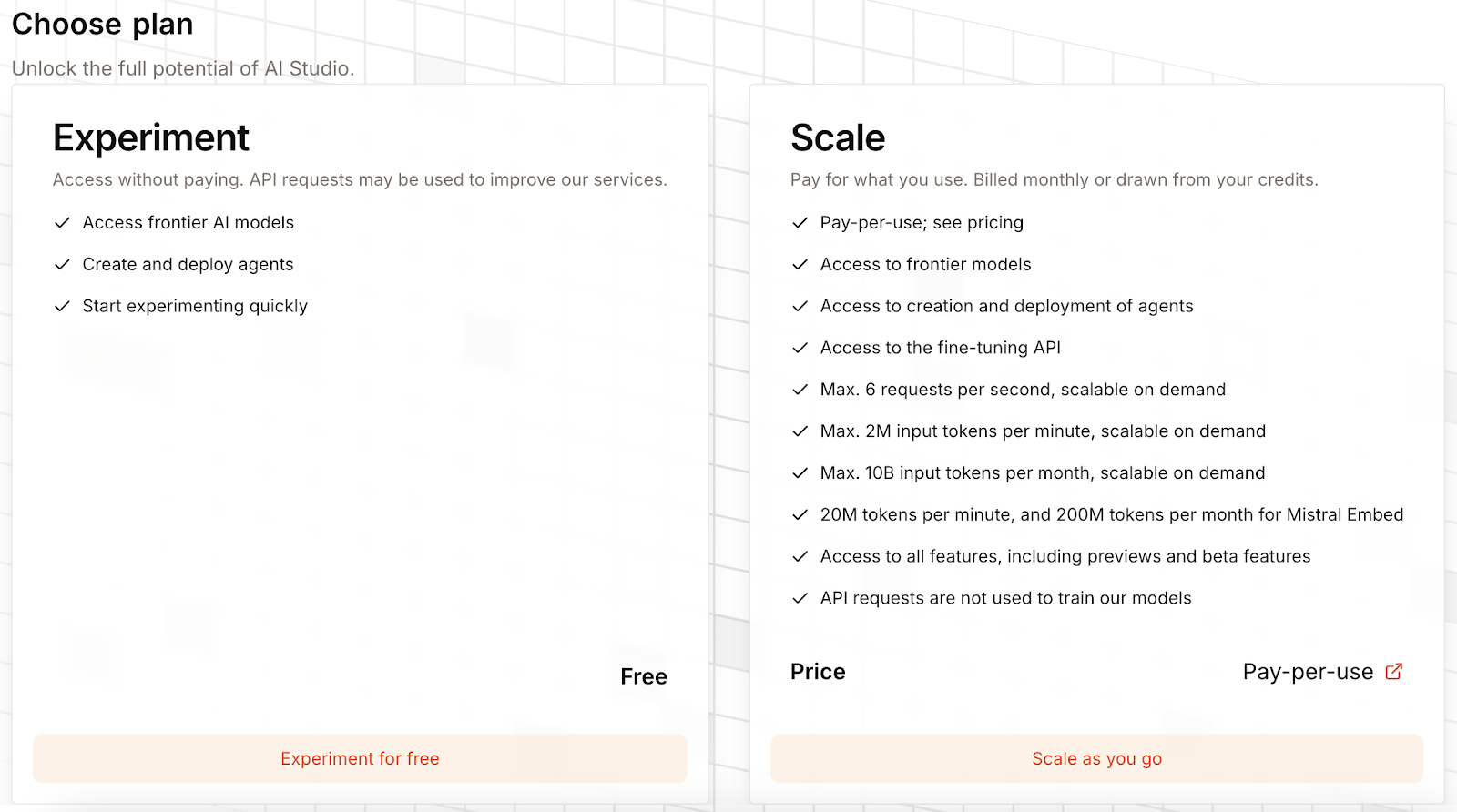
Zuerst ist Mistral OCR 3 gesperrt, und wir müssen einen Tarif auswählen, um es freizuschalten:

Man kann einen kostenlosen Tarif wählen, bei dem man Mistral OCR 3 nutzen kann, wenn man dem Unternehmen erlaubt, Nutzungsdaten zu sammeln, um seine Dienste zu verbessern. Alternativ können wir auch Kreditkartendaten eingeben und die Kosten werden dann bei jeder Nutzung abgebucht.
Es gibt keine Abogebühr, aber wir zahlen 2 oder 1 Dollar pro 1.000 Seiten, je nachdem, ob wir Sammelanfragen nutzen oder nicht.
Sobald das Konto eingerichtet ist, können wir Mistral OCR 3 ausprobieren, indem wir im AI Studio auf den Reiter „Document AI” klicken.
Um loszulegen, laden wir das Dokument oder Bild hoch, das wir per OCR bearbeiten wollen. Ich hab einfach einen Text und eine Tabelle auf ein Blatt Papier geschrieben und hochgeladen. Meine Handschrift ist echt mies, deshalb war ich gespannt, ob Mistral OCR 3 sie verstehen würde.

Wenn die Datei ausgewählt ist, gibt's Optionen, wie die Datei bearbeitet werden soll. In diesem ersten Beispiel hab ich die Standardoptionen so gelassen, wie sie waren, und einfach auf den „Ausführen“-Button oben rechts geklickt.
Hier ist das Ergebnis:

Das Ergebnis ist ziemlich gut, aber nicht perfekt:
Eine der coolen Funktionen von Mistral OCR 3 ist, dass man eine JSON-Struktur zum Parsen der Daten festlegen kann. Das ist besonders praktisch, wenn wir Tabellen analysieren, weil wir die Spaltennamen und ihre Datentypen angeben können, sodass wir die Zeilen als JSON-Wörterbuch bekommen.
Versuchen wir mal, die Tabelle aus dem vorherigen Beispiel nochmal zu analysieren, indem wir ein JSON-Schema angeben.

Um ein JSON-Schema bereitzustellen, müssen wir vor dem Ausführen der OCR das JSON-Schema anstelle des Textmodus auswählen.
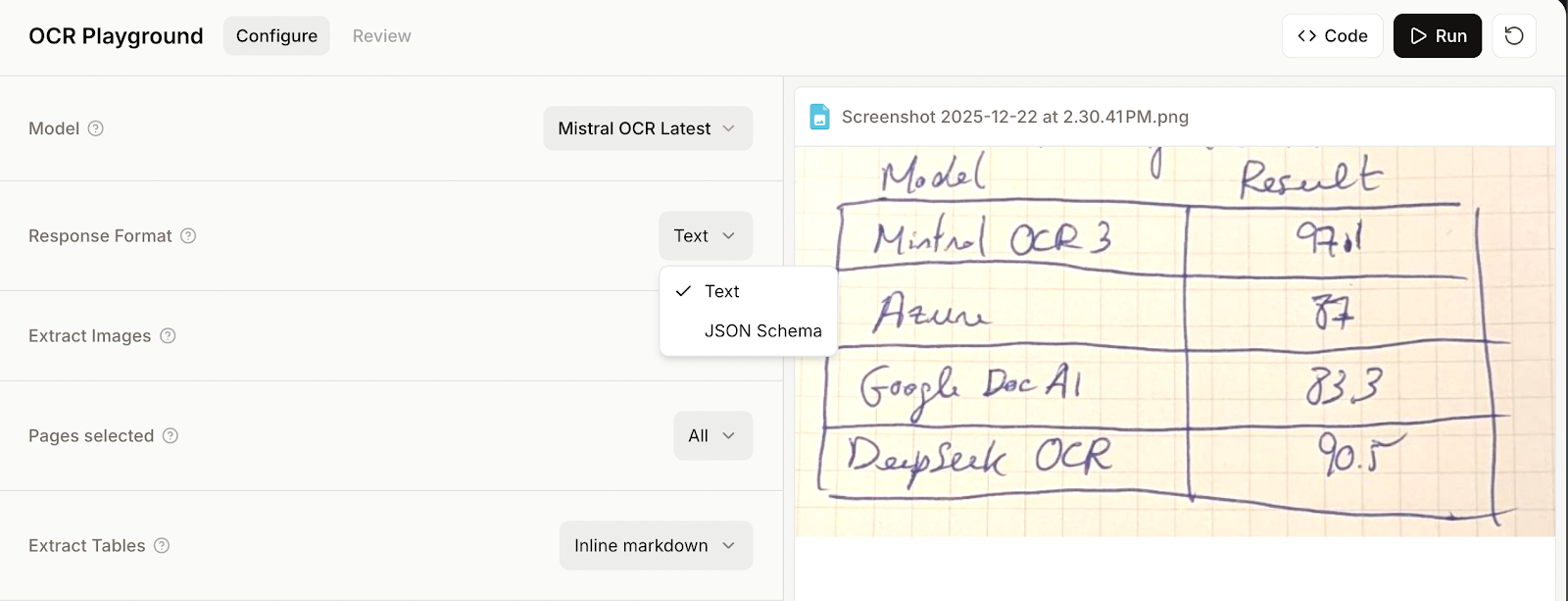
Dann stellen wir ein Schema entweder mit Code oder über die Benutzeroberfläche „Visual Builder” zur Verfügung. Ich empfehle die zweite Option, weil sie einfacher ist, wenn wir das Modell schon manuell nutzen.
Beim Hinzufügen eines Feldes geben wir Folgendes an:
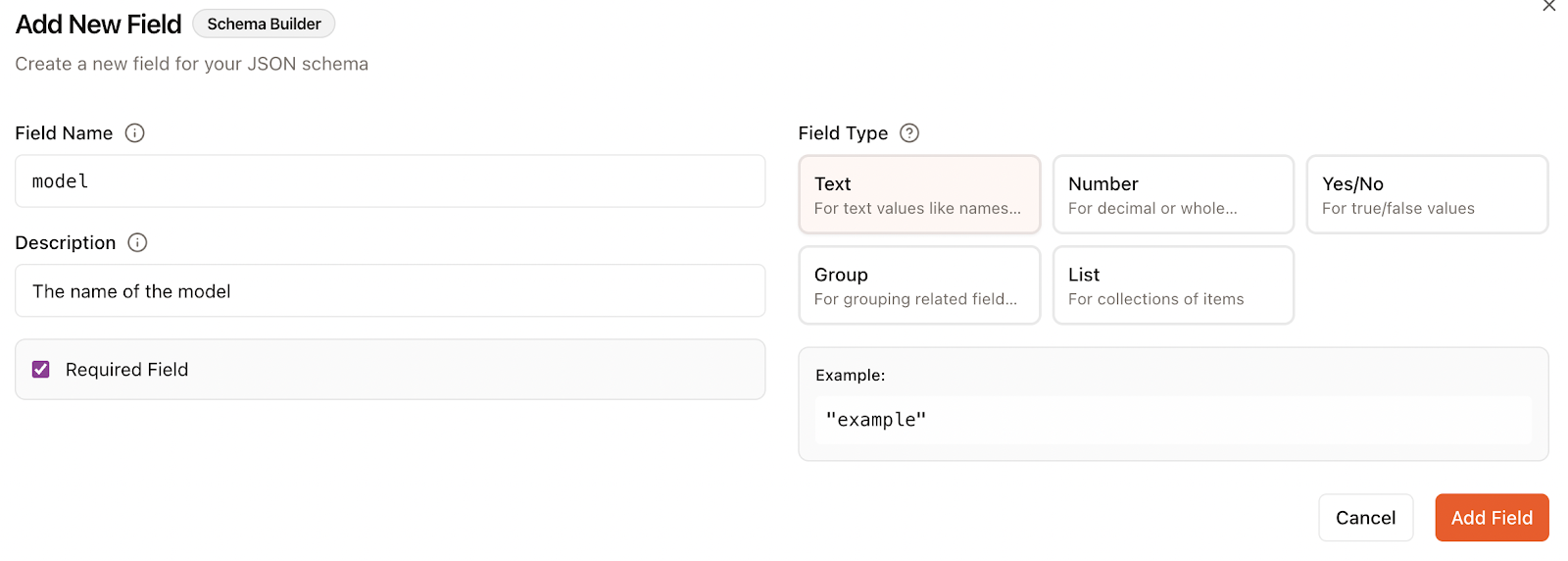
In diesem Fall habe ich zwei Felder angegeben, eins für den Namen des Modells und eins für das Benchmark-Ergebnis:
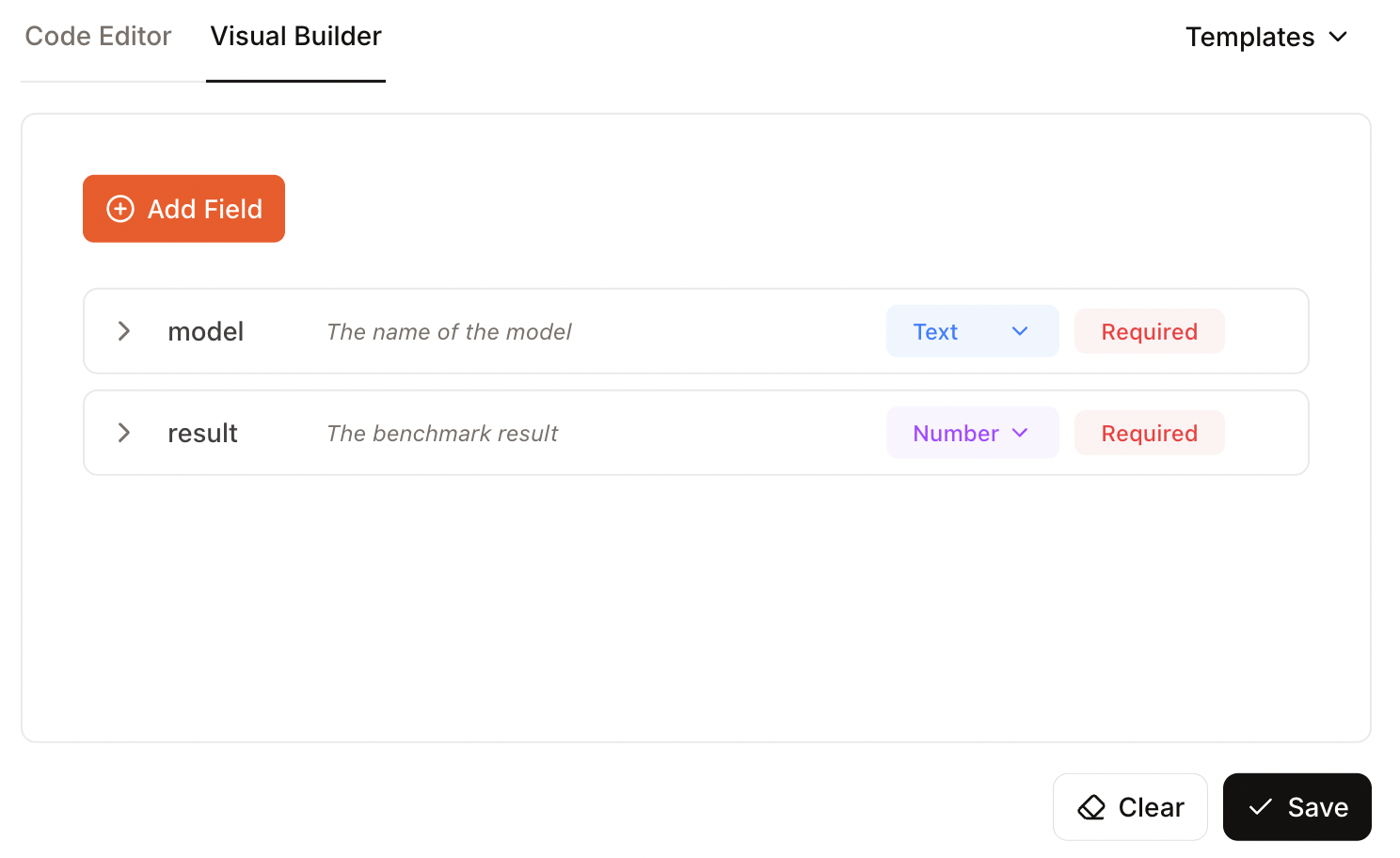
Jetzt können wir auf „Ausführen“ klicken und die Ergebnisse anschauen. Leider hat dieses Beispiel nicht geklappt. In den Ergebnissen war nur das Schema, das ich angegeben hatte, und nicht die eigentlichen Daten.
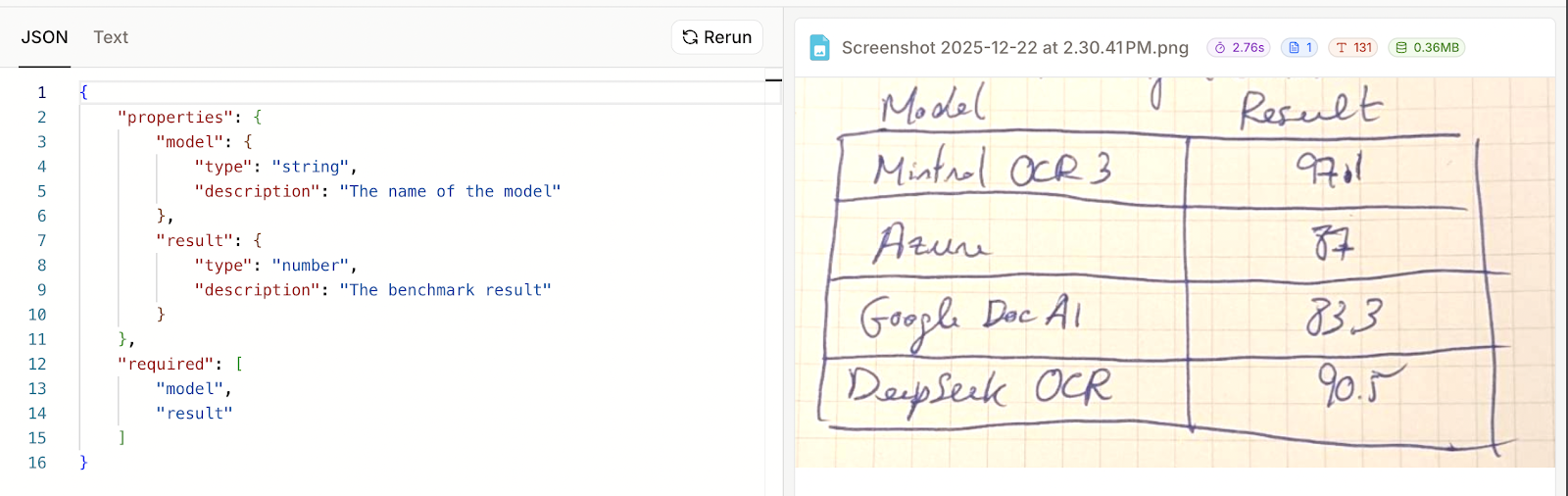
Ich dachte, dass ich es vielleicht falsch benutzt hatte, also hab ich zur Sicherheit einen Screenshot von einer Beispieltabelle aus Wikipedia) und es nochmal versucht.

Ich hab vier Spalten angegeben und die letzte als optional gelassen:

Diesmal hat's gut geklappt. Wenn das Parsen nicht klappt, scheint das JSON-Ergebnis einfach das Schema zu sein, das angegeben wurde. Das heißt auch, dass Mistral OCR 3 meine handgeschriebene Tabelle nicht als JSON analysieren konnte, obwohl es sie als Text anzeigen konnte.
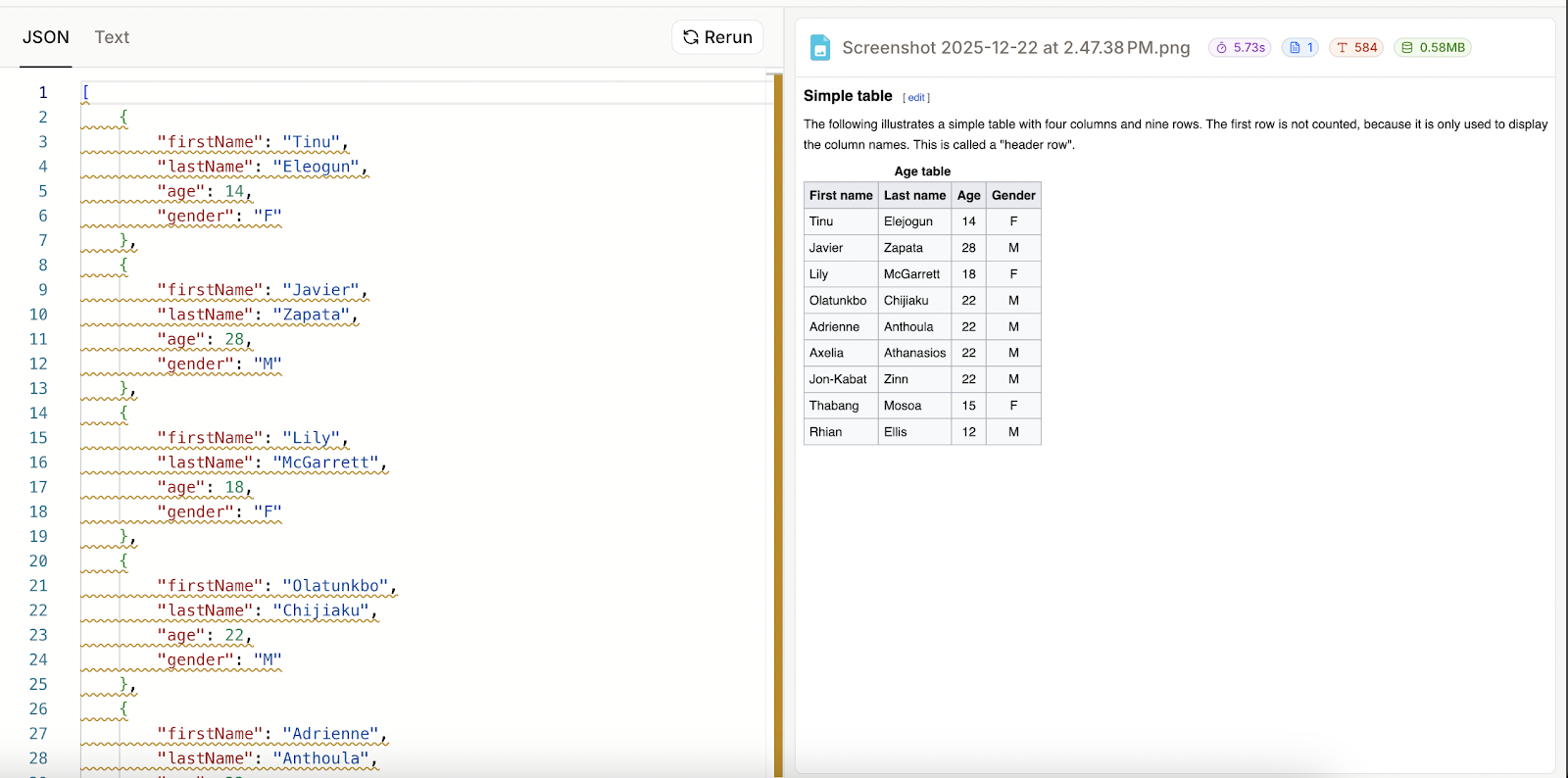
In diesem Abschnitt schauen wir uns an, wie man Python benutzt, um mit der Mistral OCR 3 API zu interagieren. Das gibt uns viel mehr Flexibilität, weil wir zum Beispiel die Ergebnisse mit anderen KI-Modellen kombinieren können, um die extrahierten Daten zu verarbeiten.
Wenn wir eine Datei ins AI Studio hochladen, gibt's neben dem „Ausführen“-Button einen „Code“-Button. Wenn wir hier draufklicken, sehen wir, welcher Code nötig wäre, um diesen Vorgang stattdessen über die API zu machen.
Hier ist ein Beispiel:
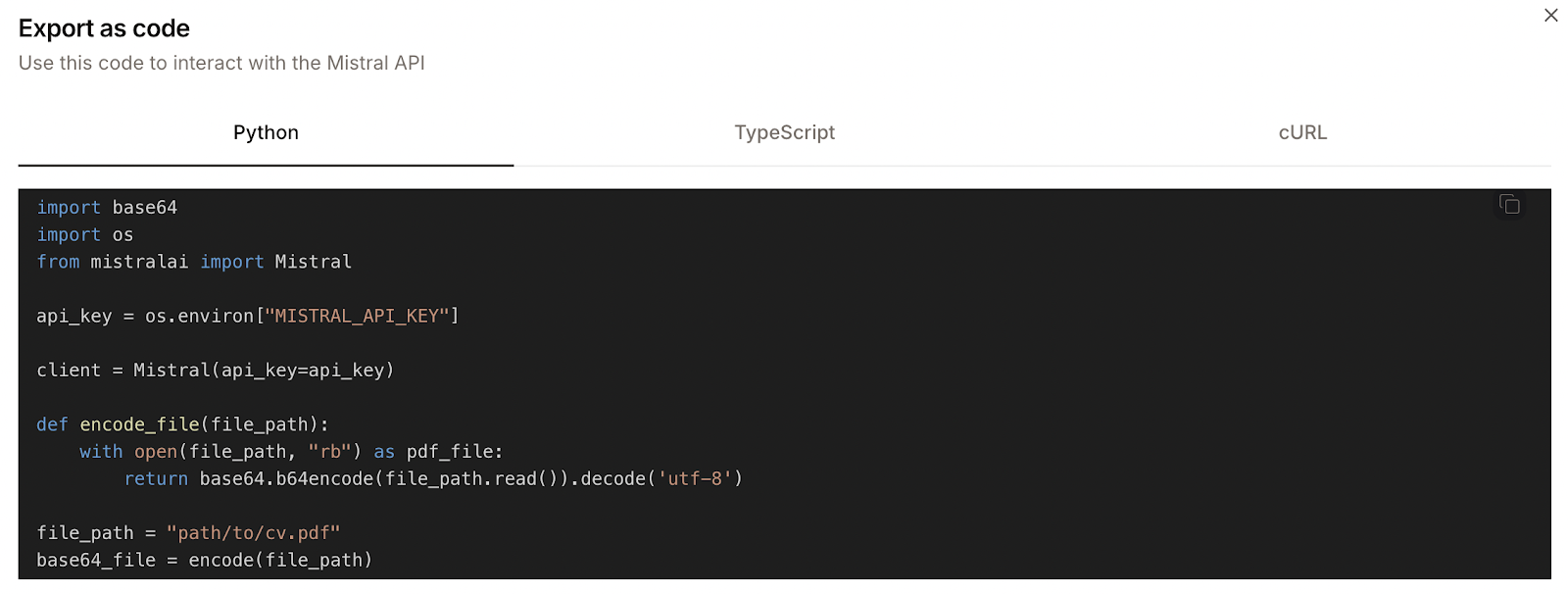
Der Python-Code ist aber nicht ganz richtig. Zum Beispiel definiert es eine Funktion namens „ encode_file “, ruft dann aber eine Funktion namens „ encode “ auf. Das sind zwar nur kleine Unstimmigkeiten, aber sie sorgen dafür, dass der Code nicht sofort funktioniert.
Aber keine Sorge, wir erklären dir genau, wie du die API nutzen kannst. Um mehr über die API zu erfahren, schau dir am besten die offizielle Dokumentation.
Als Erstes müssen wir einen API-Schlüssel im Reiter „API Keys“ erstellen und diesen Schlüssel in eine neue Datei namens „ .env “ kopieren, die sich im selben Ordner wie das Python-Skript befindet.
Als Nächstes installieren wir die benötigten Abhängigkeiten:
pip install mistralai python-dotenvHier ist ein Python-Skript, das ein lokales JPEG-Bild lädt, eine OCR-Erkennung durchführt und das Ergebnis in einer Markdown-Datei speichert:
import sys
import base64
import os
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
# Load a file as base 64
def encode_file(file_path):
with open(file_path, "rb") as pdf_file:
return base64.b64encode(pdf_file.read()).decode('utf-8')
# Perform OCR on and image
def process_image_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},
include_image_base64=True
)
for index, page in enumerate(ocr_response.pages):
with open(f"page{index}.md", "wt") as f:
f.write(page.markdown)
if __name__ == "__main__":
# Load the input file from the arguments
file_path = sys.argv[1]
process_image_ocr(file_path)Wenn die Eingabe ein PDF statt ein Bild ist, ändert sich nur der Wert im Feld „ document “. Für ein JPEG-Bild haben wir Folgendes benutzt:
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},Für ein PDF verwenden wir stattdessen:
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},Hier ist eine komplette Funktion, mit der wir eine PDF-Datei bearbeiten können:
def process_pdf_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},
include_image_base64=True
)
process_pages(ocr_response)Zwei verschiedene Funktionen zum Bearbeiten von PDF- und JPEG-Dateien zu haben, ist ein bisschen umständlich und auch nicht die beste Lösung, weil es viel gemeinsamen Code zwischen den beiden gibt.
Um das zu vermeiden, haben wir eine neue, verbesserte Funktion geschrieben, die das Paket „ mimetypes “ nutzt, um den Typ der bereitgestellten Datei zu erkennen und die API-Anfrage entsprechend zu erstellen. Wir haben auch den Code aktualisiert, um die im Dokument gefundenen Bilder zu speichern.
Hier ist die endgültige Version:
import sys
import os
import base64
import mimetypes
import datauri
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# List the supported image types
SUPPORTED_IMAGE_TYPES = {
"image/jpeg",
"image/png",
"image/webp",
"image/tiff",
}
PDF_MIME = "application/pdf"
# Load a file as base 64
def encode_file(file_path: str) -> str:
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# Build the document payload depending on the type of data contained in the file
def build_document_payload(file_path: str) -> dict:
mime_type, _ = mimetypes.guess_type(file_path)
if not mime_type:
raise ValueError(f"Could not determine MIME type for {file_path}")
base64_file = encode_file(file_path)
if mime_type == PDF_MIME:
return {
"type": "document_url",
"document_url": f"data:{mime_type};base64,{base64_file}",
}
if mime_type in SUPPORTED_IMAGE_TYPES:
return {
"type": "image_url",
"image_url": f"data:{mime_type};base64,{base64_file}",
}
raise ValueError(f"Unsupported file type: {mime_type}")
# Generic function to process OCR on a file
def process_ocr(file_path: str, output_filename: str = "output.md"):
document = build_document_payload(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document=document,
include_image_base64=True,
)
process_pages(ocr_response, output_filename)
# Save an image to a local file
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as f:
f.write(parsed.data)
# Process all pages from the OCR response
def process_pages(ocr_response, output_filename: str):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python ocr.py <file>")
sys.exit(1)
process_ocr(sys.argv[1])Um diese Version zu nutzen, brauchst du das Paket „ datauri “, um das von Mistral OCR 3 identifizierte Bild zu speichern. Das kannst du so installieren:
pip install datauriWir haben oben gelernt, dass wir mit Mistral OCR 3 ein JSON-Schema zum Parsen der Daten bereitstellen können. Diese Funktion kannst du auch über die API nutzen.
Dafür müssen wir bei der Anfrage das JSON-Schema im Parameter „ document_annotation_format “ angeben. Hier ist ein Beispiel für ein JSON-Schema für die beiden Spalten „ model “ und „ result “, das der handgeschriebenen Beispiel-Tabelle entspricht.

document_annotation_format={
"name": "response_schema",
"schemaDefinition": {
"properties": {
"model": {
"type": "string",
"description": "The name of the model"
},
"result": {
"type": "number",
"description": "The benchmark result"
}
},
"required": [
"model"
]
}
}Die Struktur ist immer gleich. Wir müssen für jede Spalte im Feld „ properties “ einen Eintrag hinzufügen, einschließlich Infos zum Datentyp und einer Beschreibung, damit das Modell die Daten besser erkennen kann.
Dann listen wir alle Pflichtfelder unter dem Feld „ required “ auf.
Um es zusammen mit dem Code zu nutzen, speicherst du das Schema am besten in einer JSON-Datei und lädst es mit dem Paket „ json “.
Einer der Hauptvorteile von Mistral OCR 3 mit der API ist, dass man darauf aufbauen kann. In diesem Abschnitt zeigen wir dir ein paar Projektideen, auf denen du aufbauen kannst.
Wir haben gelernt, wie man OCR auf ein Bild anwendet. Damit können wir eine App machen, die ein Foto von einem Einkaufsbeleg macht und dann mit Mistral OCR 3 die Daten im Bild verarbeitet und ein JSON-Wörterbuch mit den Artikeln auf dem Beleg und ihren Preisen herauszieht.
Diese Ausgaben können dann automatisch kategorisiert und in eine Datenbank eingegeben werden, sodass der Nutzer seine Ausgaben im Blick behalten kann.
Wir können Mistral OCR 3 mit einer Text-to-Speech-KI kombinieren, um einen Dokumenten-Vorleser zu erstellen. Der Benutzer kann eine Text-PDF-Datei auswählen und zur Verarbeitung an Mistral OCR 3 senden. Dann wird der Text an ein Text-zu-Sprache-KI-Modell wie OpenAI Audio API oder Eleven Labs geschickt.
Weil Mistral OCR 3 auch mit Bildern klappt, kann man es mit Fotos nutzen. So kann man ein Dokument einfach abfotografieren und unterwegs anhören.
Um mehr über Text-to-Speech zu erfahren, schlage ich dir Folgendes vor:
Mistral OCR 3 ist ein leistungsstarkes, praktisches Tool, um echte Dokumente in nutzbaren Text und strukturierte Daten umzuwandeln, egal ob du im AI Studio experimentierst oder über Python integrierst.
Es funktioniert super bei gescannten Seiten, Formularen und Tabellen, behält das Layout mit Markdown und Bildern bei und unterstützt JSON-Schemas, wenn du eine Struktur brauchst. Wie wir gesehen haben, können aber unordentliche Handschrift und unklare Überschriften immer noch Probleme machen, und wenn das Schema nicht richtig analysiert wird, wird einfach das Schema zurückgegeben.
Die API ist einfach zu verstehen, sobald man ein paar kleine Unstimmigkeiten geklärt hat, und dank eines generischen Datei-Handlers und der Möglichkeit, Bilder zu speichern, lässt sie sich leicht in kleine Apps oder Pipelines einbauen. Wenn du es nur mal ausprobieren willst, ist das Studio der schnellste Weg. Für den produktiven Einsatz solltest du das Kostenmodell berücksichtigen, nach Möglichkeit Batches verwenden und eine Validierung für Randfälle hinzufügen.
Von da an kannst du weitermachen: Schemata anpassen, Ergebnisse mit anderen Modellen kombinieren und spezielle Tools wie Belegparser oder Audio-Reader entwickeln, sodass das Modell die harte Arbeit übernimmt, während du dich um Zuverlässigkeit und Benutzererfahrung kümmerst.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
Tutorial
Derrick Mwiti
Tutorial
Sejal Jaiswal
