
Cours
Travailler avec l'API OpenAI
3 h
141.6K
Le dernier modèle OCR de Mistral, Mistral OCR 3, est capable d'extraire du texte et des images intégrées à partir d'une large gamme de documents avec une fidélité exceptionnelle.
Dans cet article, je vais vous expliquer comment tirer le meilleur parti de Mistral OCR 3 en utilisant à la fois leur AI Studio et leur API avec Python. Nous allons développer une petite application qui transforme une photo d'un menu en un site web interactif.

Si vous souhaitez en savoir plus sur l'utilisation des API pour créer des outils basés sur l'IA, je vous recommande de consulter le cours cours « Travailler avec l'API OpenAI ».
OCR signifie « reconnaissance optique de caractères » et vise à convertir des documents en texte. Par exemple, il est capable de convertir une photo d'une note manuscrite en texte ou un tableau dans un PDF en un tableau de texte réel pouvant être recherché et modifié.
Mistral OCR 3 est le tout dernier modèle de compréhension de documents de Mistral AI, offrant une précision et une efficacité de pointe pour les documents du monde réel. Il extrait le texte et les images intégrées avec une grande fidélité et préserve la structure grâce à une sortie Markdown avec reconstruction de tableaux basée sur HTML, avec JSON structuré en option.
Mistral OCR 3 surpasse tous ses concurrents dans un large éventail de tests de performance :
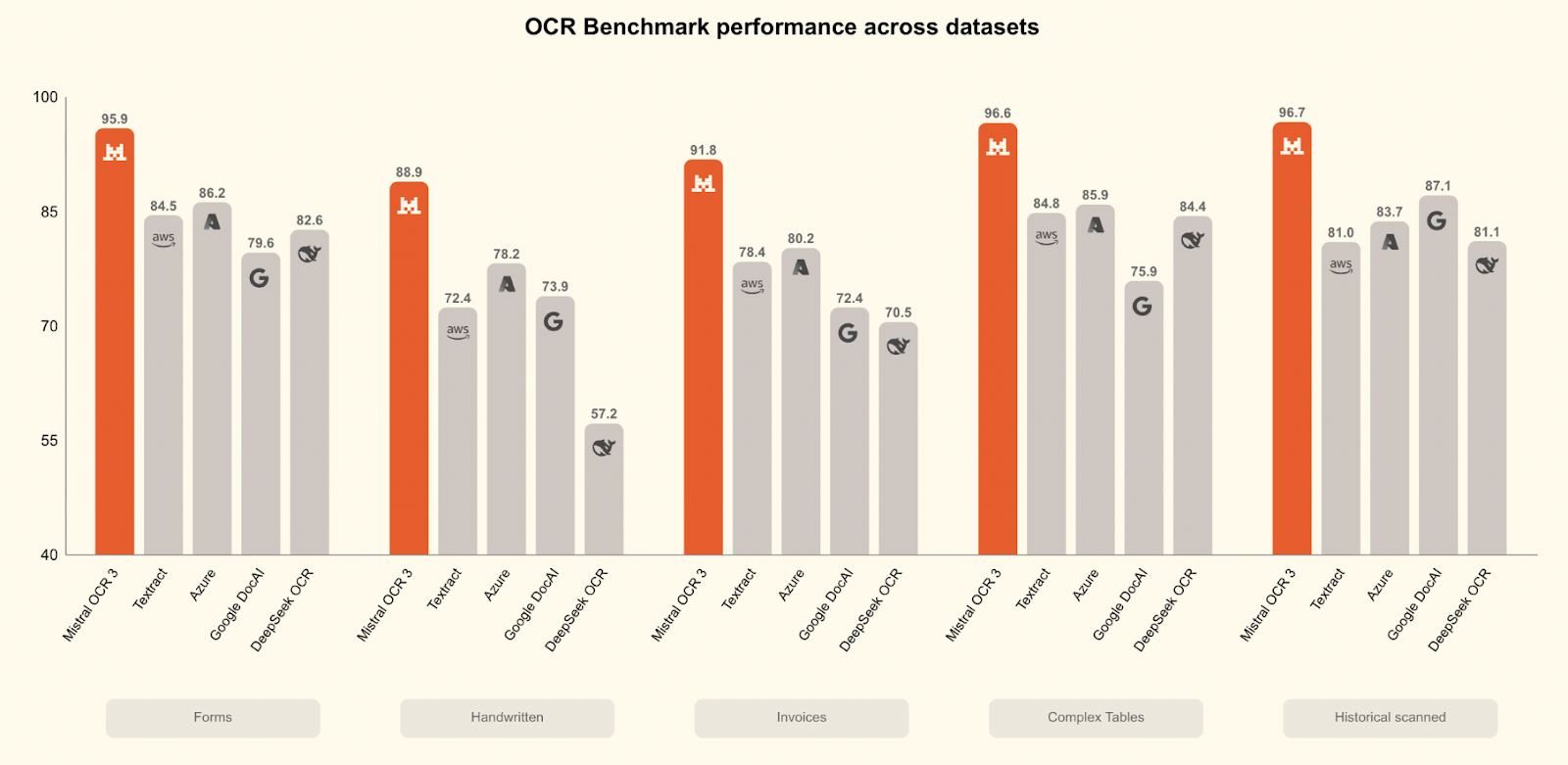
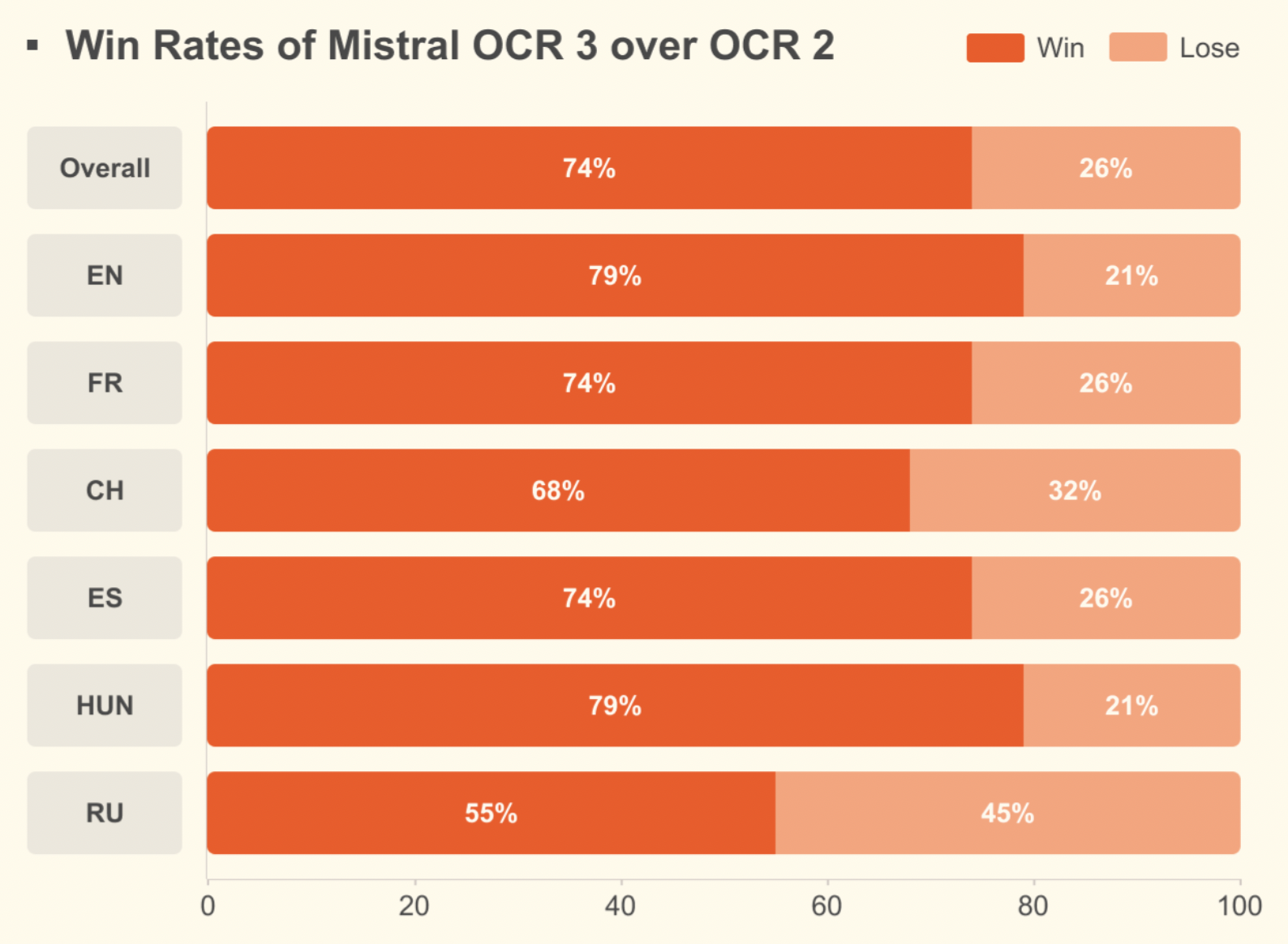
Par rapport à Mistral OCR 2, il atteint un taux de réussite global de 74 % sur les formulaires, les documents numérisés, les tableaux complexes et les écritures manuscrites, avec des gains importants sur les numérisations de faible qualité et les mises en page denses.
Pour en savoir plus sur l'OCR et le modèle précédent de Mistral, veuillez consulter cet article : Mistral OCR : Un guide avec des exemples pratiques.
Veuillez découvrir comment configurer Mistral OCR 3 avec AI Studio.
Mistral OCR 3 est disponible pour une utilisation sur leur studio d'IA. Il s'agit de la méthode la plus simple pour l'essayer, car elle offre une interface conviviale.
Lorsque nous nous inscrivons, nous sommes d'abord invités à créer une organisation :
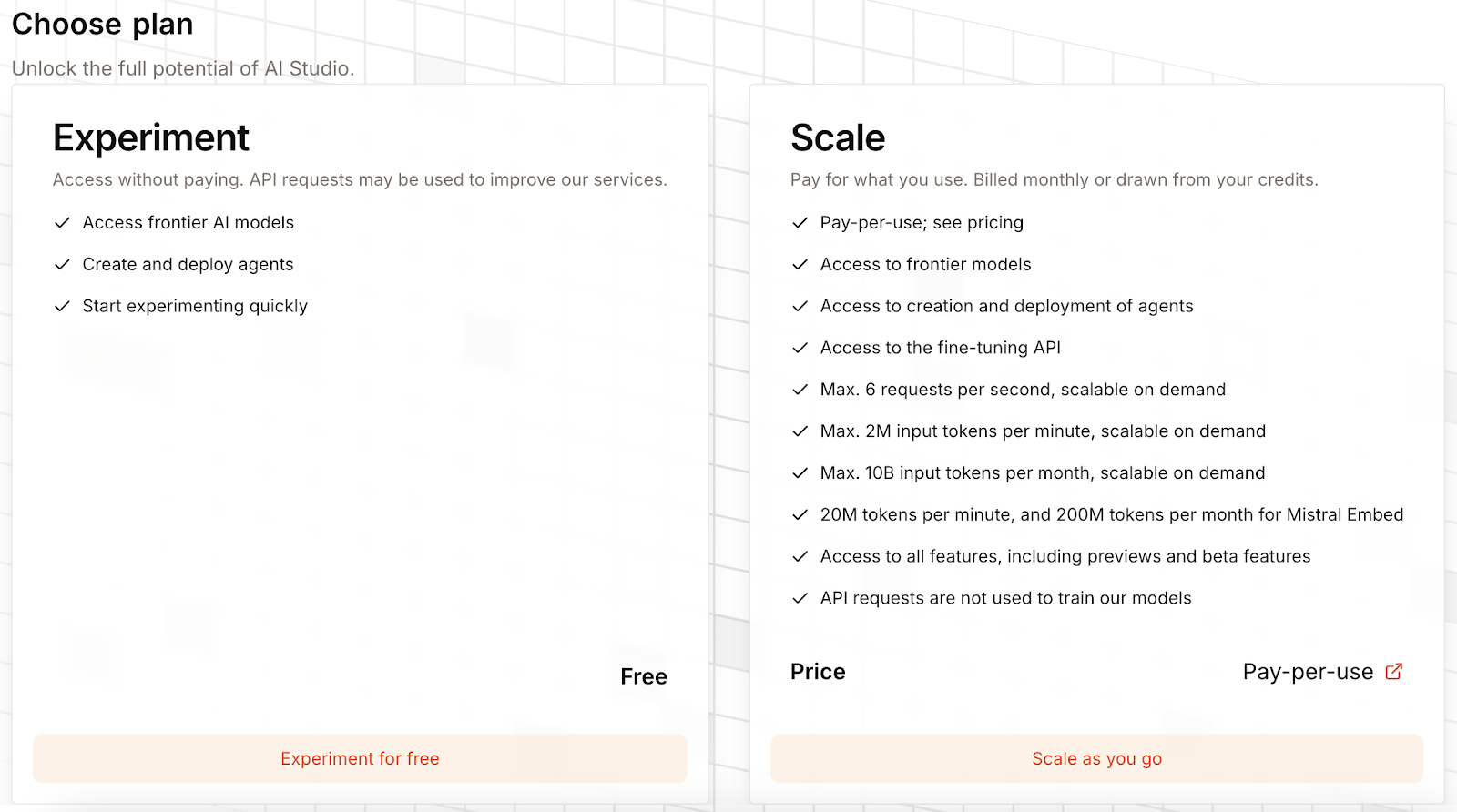
Au départ, Mistral OCR 3 sera verrouillé, et il sera nécessaire de sélectionner un forfait pour le déverrouiller :

Il est possible de choisir une formule gratuite qui permet d'utiliser Mistral OCR 3 en autorisant la collecte de données d'utilisation afin d'améliorer leurs services. Nous pouvons également saisir les informations relatives à notre carte de crédit et être facturés à chaque utilisation.
Il n'y a pas de frais d'abonnement, mais nous sommes facturés 2 $ ou 1 $ par 1 000 pages, selon que nous utilisons ou non des requêtes groupées.
Une fois le compte créé, nous pouvons tester Mistral OCR 3 en accédant à l'onglet « Document AI » dans AI Studio.
Pour commencer, nous téléchargeons le document ou l'image sur lequel nous souhaitons effectuer la reconnaissance optique de caractères. Dans mon cas, j'ai rédigé un texte et un tableau sur une feuille de papier, puis je l'ai téléchargé. Mon écriture est assez mauvaise, j'étais donc curieux de voir si Mistral OCR 3 pouvait la reconnaître.

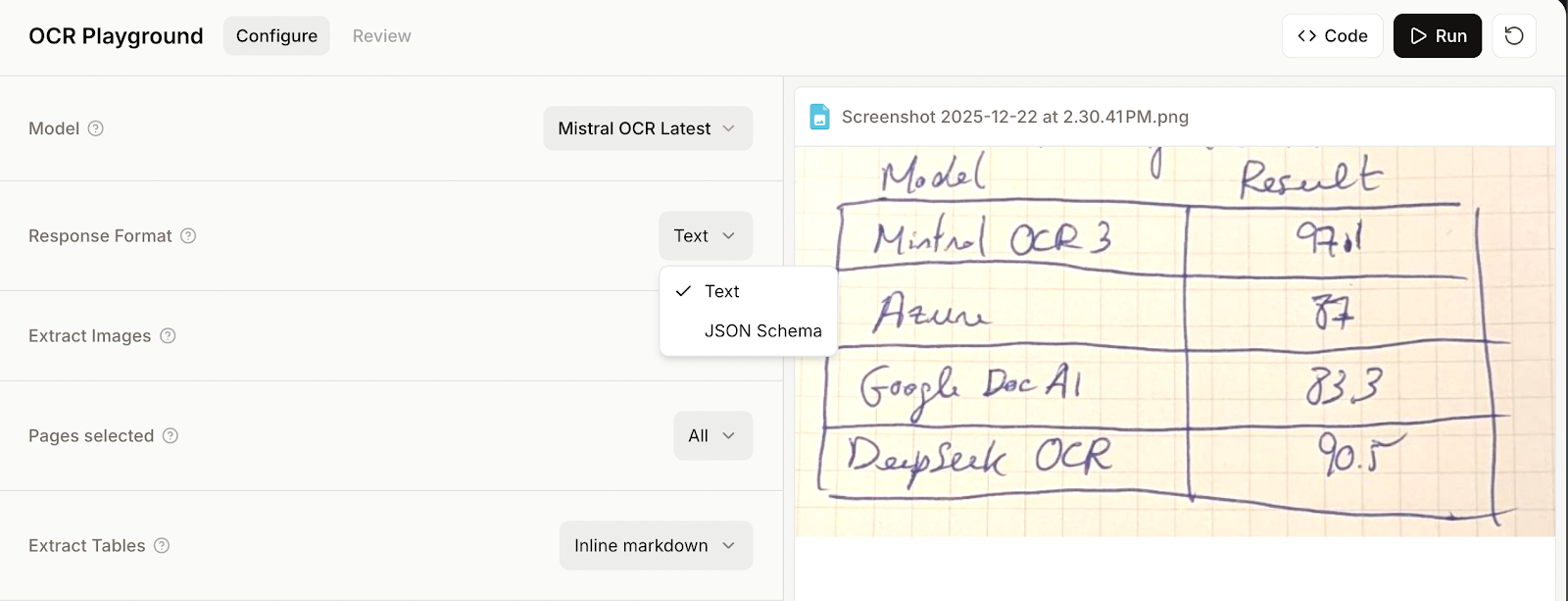
Une fois le fichier sélectionné, plusieurs options s'offrent à nous pour le traitement du fichier. Dans ce premier exemple, j'ai conservé les options par défaut et j'ai simplement cliqué sur le bouton « Exécuter » situé dans le coin supérieur droit.
Voici le résultat :

Le résultat est satisfaisant, mais n'est pas parfait :
L'une des fonctionnalités intéressantes de Mistral OCR 3 est la possibilité de définir une structure JSON pour l'analyse des données. Ceci est particulièrement utile pour analyser des tableaux, car cela nous permet de spécifier les noms des colonnes et leurs types de données afin d'obtenir les lignes sous forme de dictionnaire JSON.
Veuillez essayer à nouveau d'analyser le tableau de l'exemple précédent en spécifiant un schéma JSON.

Pour fournir un schéma JSON, il est nécessaire de sélectionner le schéma JSON au lieu du mode texte avant d'exécuter l'OCR.
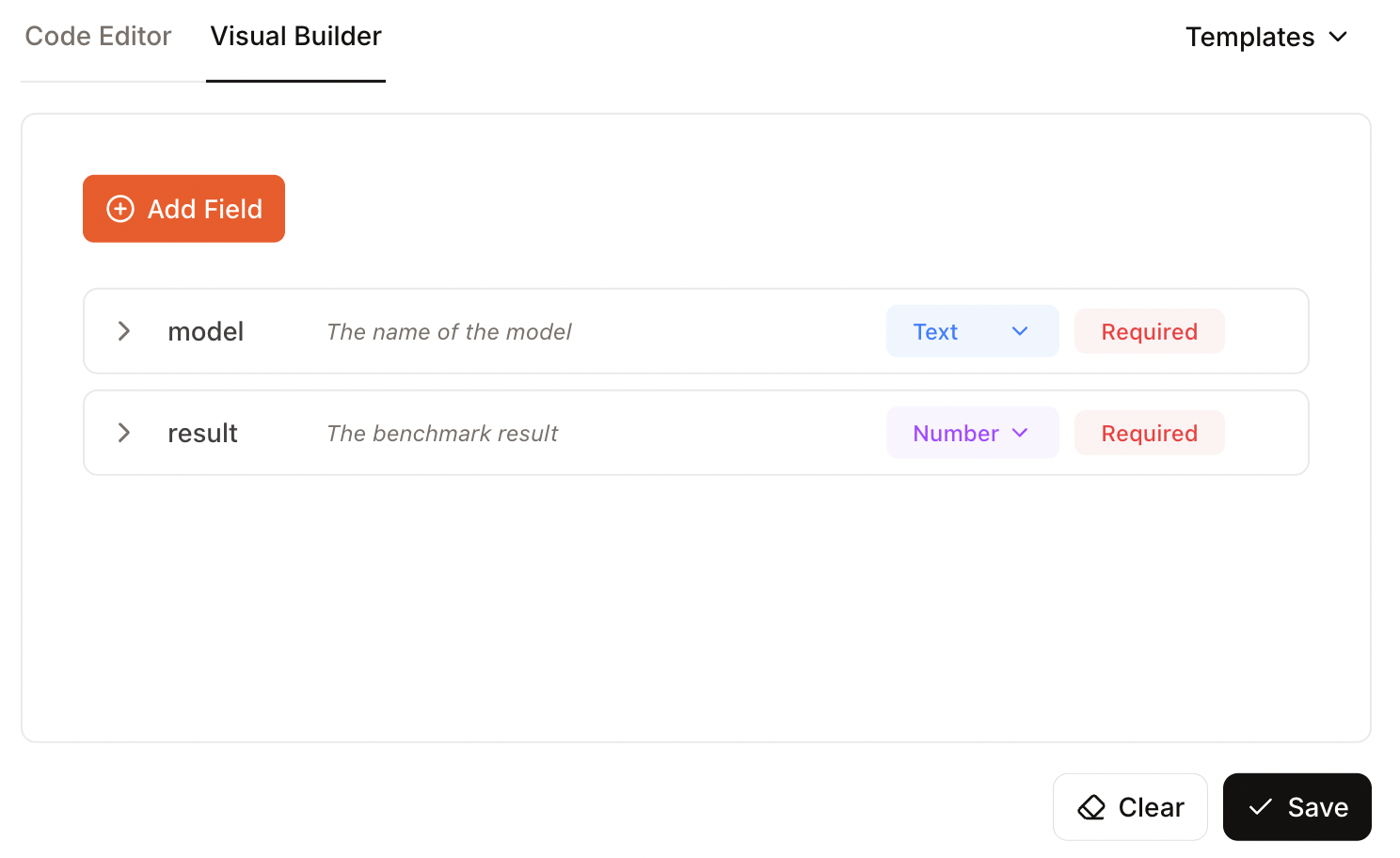
Ensuite, nous fournissons un schéma soit avec du code, soit en utilisant l'interface utilisateur « Visual Builder ». Je recommande la deuxième option, car elle est plus simple lorsque nous utilisons déjà le modèle manuellement.
Lors de l'ajout d'un champ, nous précisons :
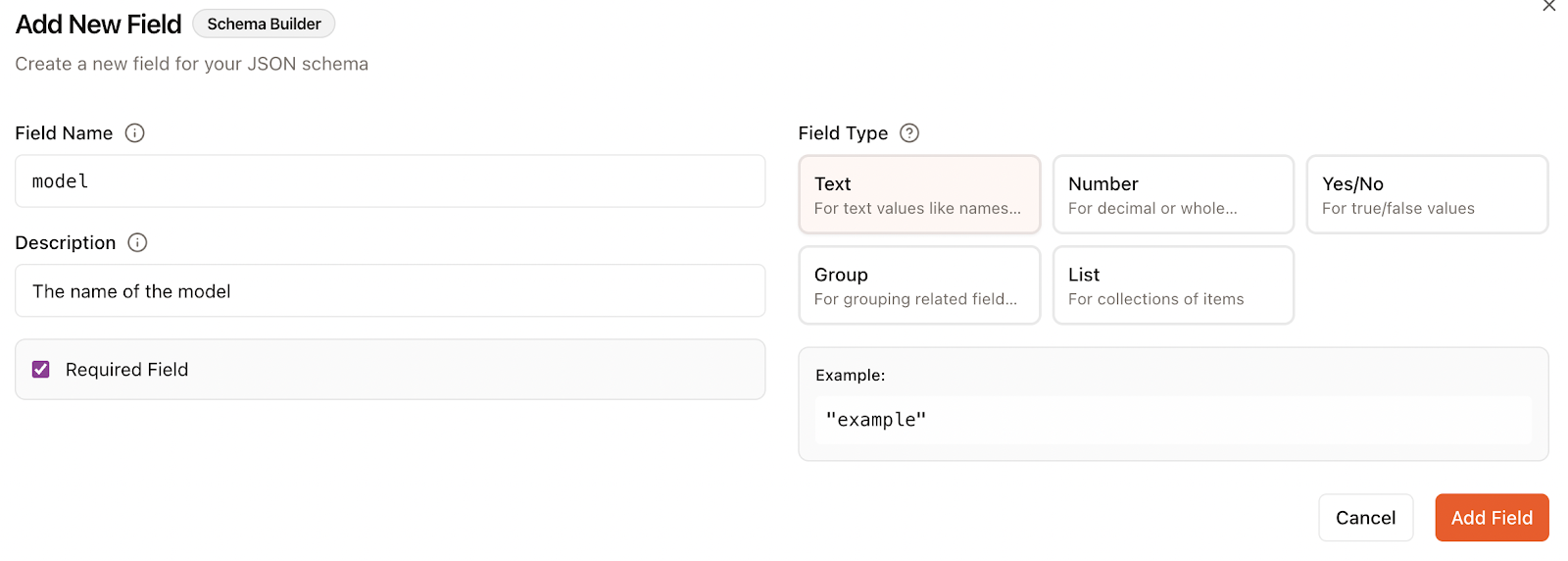
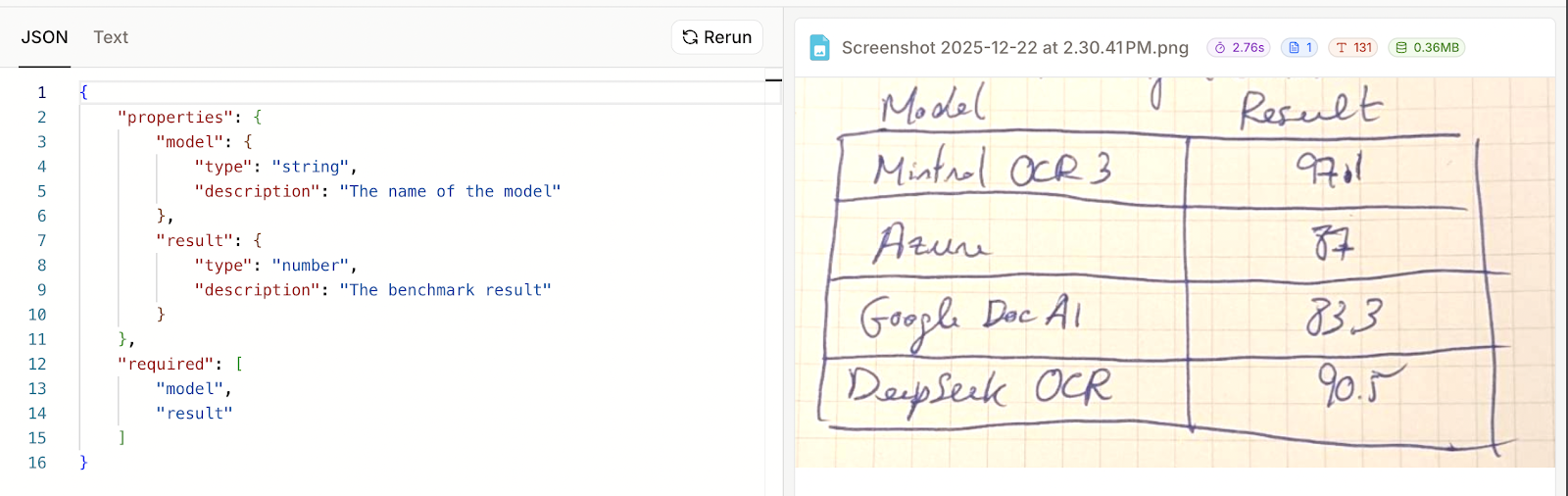
Dans ce cas, j'ai spécifié deux champs, l'un pour le nom du modèle et l'autre pour le résultat du benchmark :
Nous pouvons maintenant cliquer sur « Exécuter » et observer les résultats. Malheureusement, cet exemple n'a pas fonctionné. Dans les résultats, seul le schéma que j'ai fourni a été présenté, et non les données réelles.
Je me suis demandé si je ne l'avais pas utilisé de manière incorrecte, alors pour m'en assurer, j'ai pris une capture d'écran d'un tableau type sur Wikipédia) et j'ai réessayé.

J'ai spécifié quatre colonnes, la dernière étant facultative :

Cette fois-ci, cela a bien fonctionné. Il semble que lorsque l'analyse échoue, le résultat JSON correspond simplement au schéma qui a été fourni. Cela signifie également que Mistral OCR 3 n'a pas réussi à analyser mon tableau manuscrit au format JSON, bien qu'il ait été en mesure de le restituer sous forme de texte.
Dans cette section, nous examinerons comment utiliser Python pour interagir avec l'API Mistral OCR 3. Cela offre une plus grande flexibilité, car nous pouvons, par exemple, combiner les résultats avec d'autres modèles d'IA pour traiter les données extraites.
Lorsque nous téléchargeons un fichier dans AI Studio, un bouton « Code » est disponible à côté du bouton « Exécuter ». En cliquant ici, nous pouvons voir quel code serait nécessaire pour effectuer cette opération à l'aide de l'API.
Voici un exemple :
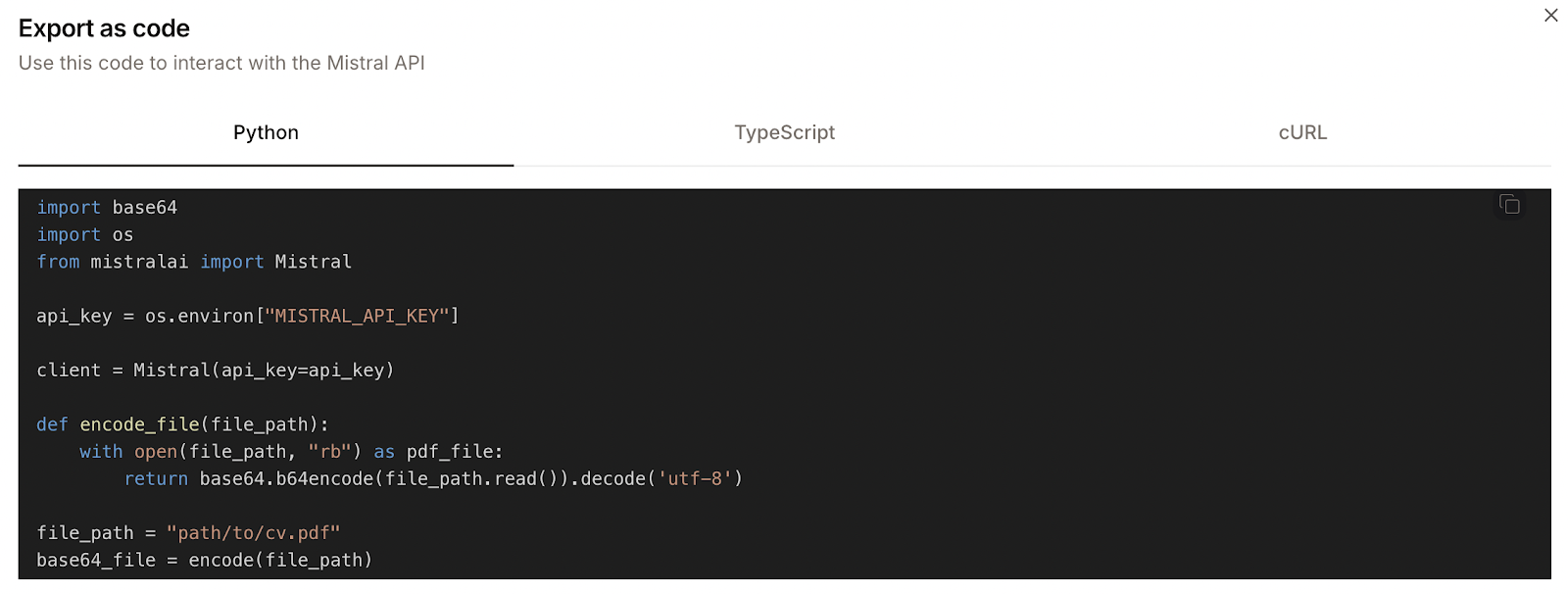
Cependant, le code Python fourni n'est pas tout à fait exact. Par exemple, il définit une fonction nommée encode_file, mais appelle ensuite une fonction nommée encode. Il s'agit d'incohérences mineures, mais elles empêchent le code de fonctionner immédiatement.
Cependant, ne vous inquiétez pas, nous vous expliquerons en détail comment utiliser l'API. Pour en savoir plus sur l'API, nous vous recommandons de consulter la documentation officielle.
La première étape consiste à créer une clé API dans l'onglet « API Keys » et à copier cette clé dans un nouveau fichier nommé .env situé dans le même dossier que le script Python.
Ensuite, nous installons les dépendances requises :
pip install mistralai python-dotenvVoici un script Python qui charge une image JPEG locale, effectue une reconnaissance optique de caractères (OCR) sur celle-ci et enregistre le résultat dans un fichier Markdown :
import sys
import base64
import os
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
# Load a file as base 64
def encode_file(file_path):
with open(file_path, "rb") as pdf_file:
return base64.b64encode(pdf_file.read()).decode('utf-8')
# Perform OCR on and image
def process_image_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},
include_image_base64=True
)
for index, page in enumerate(ocr_response.pages):
with open(f"page{index}.md", "wt") as f:
f.write(page.markdown)
if __name__ == "__main__":
# Load the input file from the arguments
file_path = sys.argv[1]
process_image_ocr(file_path)Lorsque l'entrée est un fichier PDF plutôt qu'une image, le seul élément qui change est la valeur fournie dans le champ « document » (Nom du fichier PDF). Pour une image JPEG, nous avons utilisé :
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},Pour un fichier PDF, nous utilisons plutôt :
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},Voici une fonction complète que nous pouvons utiliser pour traiter un PDF :
def process_pdf_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},
include_image_base64=True
)
process_pages(ocr_response)Disposer de deux fonctions distinctes pour traiter les fichiers PDF et JPEG peut s'avérer quelque peu fastidieux et n'est pas la meilleure approche, car ces deux fonctions partagent une grande partie de leur code.
Pour éviter cela, nous avons développé une nouvelle fonction améliorée qui utilise le package mimetypes afin d'identifier le type de fichier fourni et de construire la requête API en conséquence. Nous avons également mis à jour le code afin d'enregistrer les images identifiées dans le document.
Voici la version finale :
import sys
import os
import base64
import mimetypes
import datauri
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# List the supported image types
SUPPORTED_IMAGE_TYPES = {
"image/jpeg",
"image/png",
"image/webp",
"image/tiff",
}
PDF_MIME = "application/pdf"
# Load a file as base 64
def encode_file(file_path: str) -> str:
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# Build the document payload depending on the type of data contained in the file
def build_document_payload(file_path: str) -> dict:
mime_type, _ = mimetypes.guess_type(file_path)
if not mime_type:
raise ValueError(f"Could not determine MIME type for {file_path}")
base64_file = encode_file(file_path)
if mime_type == PDF_MIME:
return {
"type": "document_url",
"document_url": f"data:{mime_type};base64,{base64_file}",
}
if mime_type in SUPPORTED_IMAGE_TYPES:
return {
"type": "image_url",
"image_url": f"data:{mime_type};base64,{base64_file}",
}
raise ValueError(f"Unsupported file type: {mime_type}")
# Generic function to process OCR on a file
def process_ocr(file_path: str, output_filename: str = "output.md"):
document = build_document_payload(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document=document,
include_image_base64=True,
)
process_pages(ocr_response, output_filename)
# Save an image to a local file
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as f:
f.write(parsed.data)
# Process all pages from the OCR response
def process_pages(ocr_response, output_filename: str):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python ocr.py <file>")
sys.exit(1)
process_ocr(sys.argv[1])L'utilisation de cette version nécessite le paquet datauri pour enregistrer l'image identifiée par Mistral OCR 3, qui peut être installé à l'aide de :
pip install datauriNous avons appris précédemment que Mistral OCR 3 nous permet de fournir un schéma JSON pour analyser les données. Cette fonctionnalité est également disponible lors de l'utilisation via l'API.
Pour ce faire, il est nécessaire de fournir le schéma JSON dans le paramètre « document_annotation_format » lors de la demande. Vous trouverez ci-dessous un exemple de schéma JSON pour les deux colonnes model et result, correspondant au tableau manuscrit présenté en exemple.

document_annotation_format={
"name": "response_schema",
"schemaDefinition": {
"properties": {
"model": {
"type": "string",
"description": "The name of the model"
},
"result": {
"type": "number",
"description": "The benchmark result"
}
},
"required": [
"model"
]
}
}La structure est toujours identique. Il est nécessaire d'ajouter une entrée pour chaque colonne dans le champ « properties » (Description des données), y compris des informations sur le type de données et une description pour aider le modèle à identifier les données.
Ensuite, nous répertorions tous les champs obligatoires sous le champ « required » (Champs obligatoires).
Pour l'utiliser avec le code, la méthode la plus simple consiste à enregistrer le schéma dans un fichier JSON et à le charger à l'aide du package json.
L'un des principaux avantages de l'utilisation de Mistral OCR 3 avec l'API est la possibilité de développer des fonctionnalités supplémentaires. Dans cette section, nous vous présentons quelques idées de projets sur lesquels vous pouvez vous appuyer.
Nous avons appris comment effectuer une reconnaissance optique de caractères (OCR) sur une image. Nous pouvons utiliser cette fonctionnalité pour développer une application qui prend une photo d'un ticket de caisse, puis utilise Mistral OCR 3 pour traiter les données contenues dans l'image et extraire un dictionnaire JSON répertoriant les articles figurant sur le ticket et leurs prix.
Ces dépenses peuvent ensuite être automatiquement classées et ajoutées à une base de données, permettant ainsi à l'utilisateur de suivre ses dépenses.
Nous pouvons associer Mistral OCR 3 à une intelligence artificielle de synthèse vocale afin de créer un lecteur audio de documents. L'utilisateur peut sélectionner un fichier PDF contenant du texte et l'envoyer à Mistral OCR 3 pour traitement. Ensuite, le texte obtenu est envoyé à un modèle d'IA de synthèse vocale tel que OpenAI Audio API ou Eleven Labs.
Étant donné que Mistral OCR 3 fonctionne également avec des images, il peut être utilisé avec des photos, permettant aux utilisateurs de prendre une photo d'un document et de l'écouter lors de leurs déplacements.
Pour en savoir plus sur la synthèse vocale, je vous recommande l'un des ouvrages suivants :
Mistral OCR 3 est un outil performant et pratique qui permet de convertir des documents réels en texte exploitable et en données structurées, que vous meniez des expériences dans AI Studio ou que vous procédiez à une intégration via Python.
Il met en valeur les pages, les formulaires et les tableaux numérisés, préserve la mise en page avec les balises et les images, et prend en charge le schéma JSON lorsque vous avez besoin d'une structure. Cependant, comme nous l'avons constaté, une écriture manuscrite illisible et des en-têtes ambigus peuvent encore causer des problèmes, et les analyses de schéma qui échouent renvoient simplement le schéma.
Une fois les quelques incohérences mineures résolues, l'API est simple à utiliser. Un gestionnaire de fichiers générique, associé à une fonction d'enregistrement d'images, facilite son intégration dans de petites applications ou des pipelines. Si vous souhaitez simplement l'essayer, le Studio est la solution la plus rapide. Pour une utilisation en production, veuillez prendre en considération le modèle de coût, regrouper les tâches lorsque cela est possible et ajouter une validation pour les cas limites.
À partir de là, vous pouvez itérer, ajuster les schémas, combiner les résultats avec d'autres modèles et créer des utilitaires spécialisés tels que des analyseurs de reçus ou des lecteurs audio, laissant le modèle effectuer les tâches complexes pendant que vous vous concentrez sur la fiabilité et l'expérience utilisateur.
Meilleurs cours DataCamp
Cours
Cours
Cours