
Curso
Trabajar con la API de OpenAI
3 h
141.6K
El último modelo OCR de Mistral, Mistral OCR 3, es capaz de extraer texto e imágenes incrustadas de una amplia gama de documentos con una fidelidad excepcional.
En este artículo, te enseñaré cómo sacar el máximo partido a Mistral OCR 3 utilizando tanto su AI Studio como su API con Python. Crearemos una pequeña aplicación que convierte una foto de un menú en un sitio web interactivo.

Si deseas obtener más información sobre cómo trabajar con API para crear herramientas basadas en IA, te recomiendo que consultes el curso curso Trabajar con la API de OpenAI.
OCR son las siglas de «reconocimiento óptico de caracteres» y su objetivo es convertir documentos en texto. Por ejemplo, puede convertir una foto de una nota manuscrita en texto o una tabla en un PDF en una tabla de texto real que se puede buscar y editar.
Mistral OCR 3 es el último modelo de comprensión de documentos de Mistral AI, que ofrece una precisión y eficiencia de vanguardia para documentos del mundo real. Extrae texto e imágenes incrustadas con alta fidelidad y conserva la estructura mediante salida Markdown con reconstrucción de tablas basada en HTML, con JSON estructurado opcional.
Mistral OCR 3 supera a todos tus competidores en una amplia gama de pruebas de rendimiento:
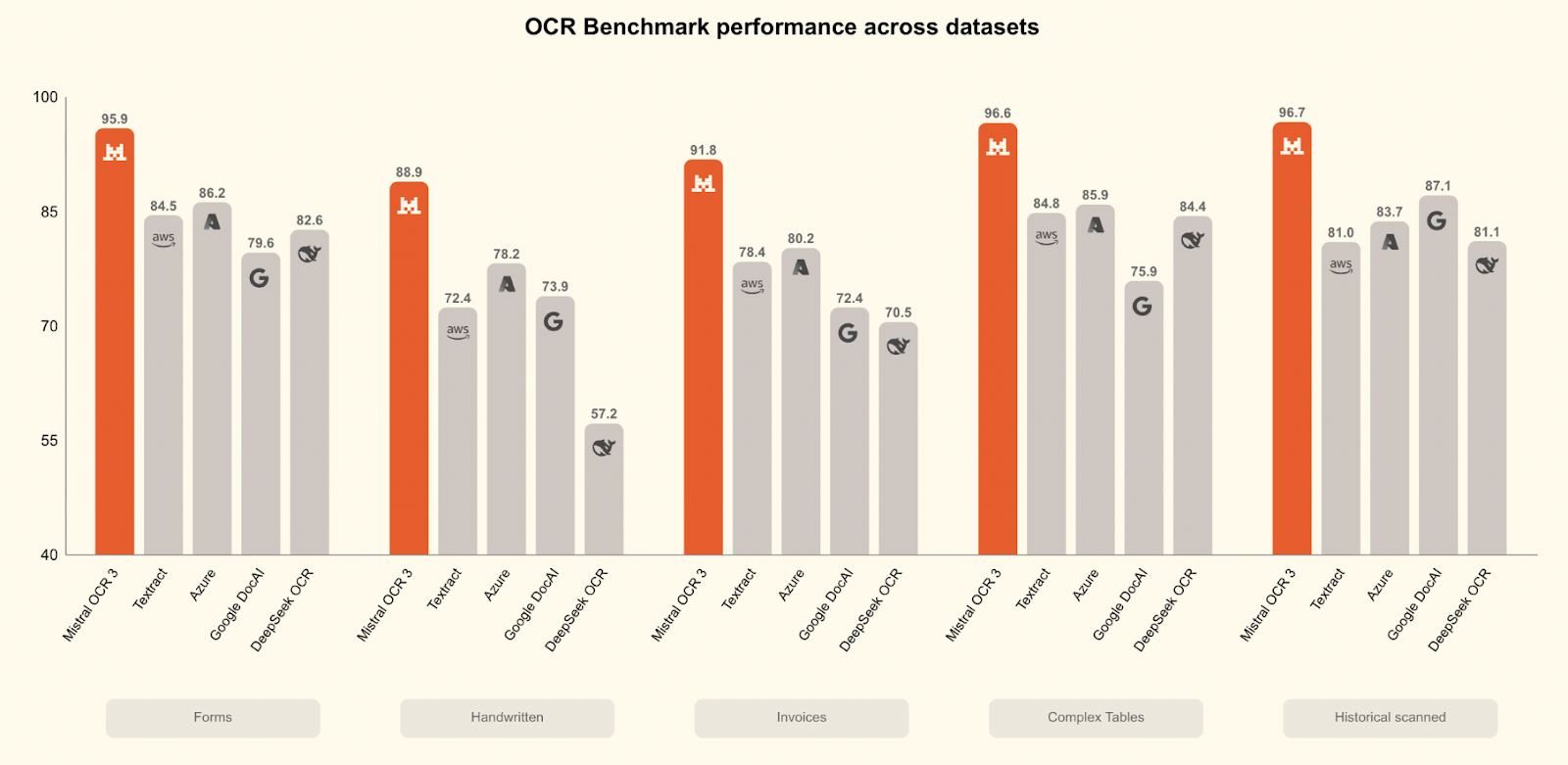
En comparación con Mistral OCR 2, alcanza una tasa de éxito global del 74 % en formularios, documentos escaneados, tablas complejas y escritura manuscrita, con importantes mejoras en escaneos de baja calidad y diseños densos.
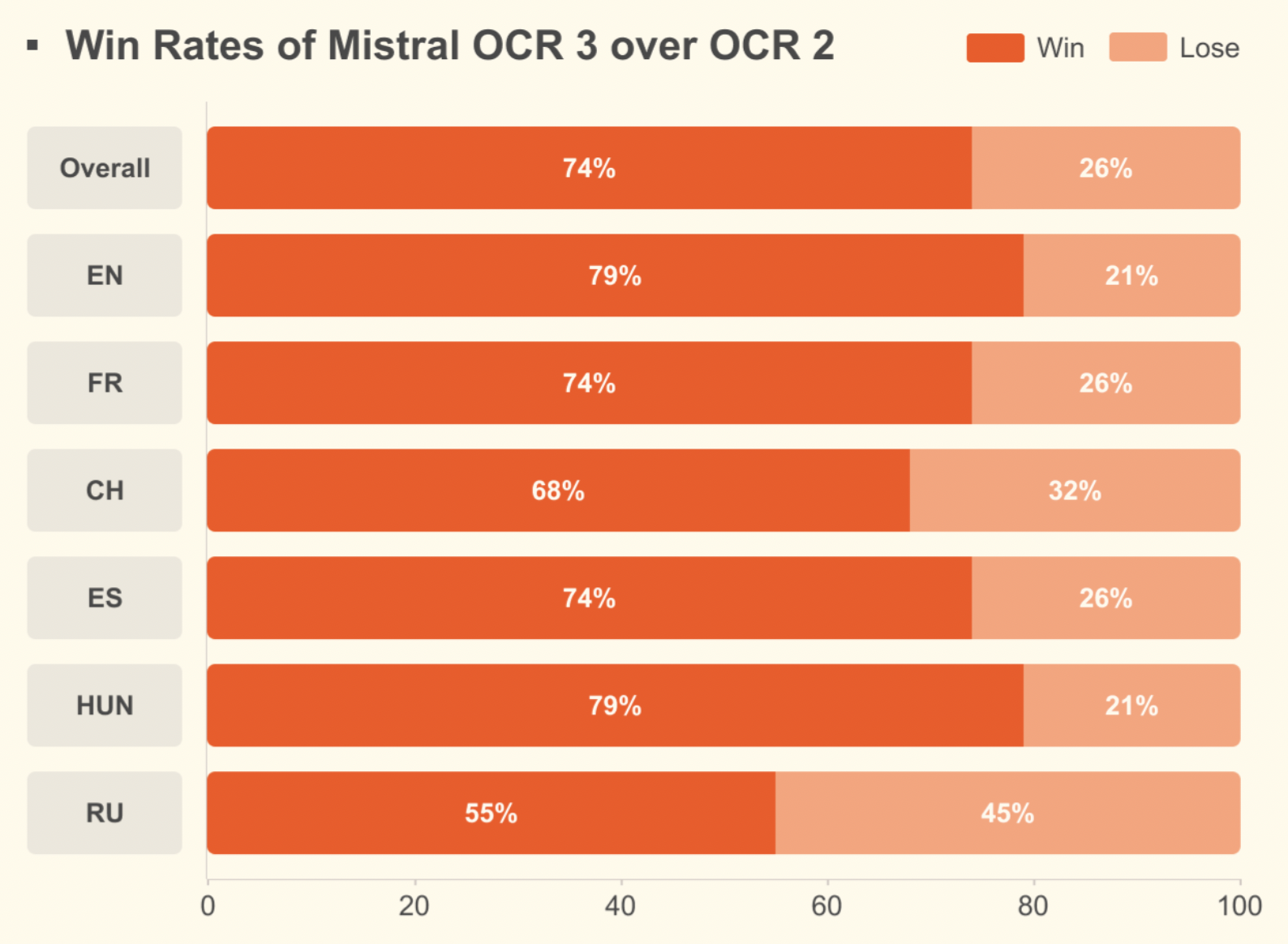
Para obtener más información sobre el OCR y el modelo anterior de Mistral, consulta este artículo: Mistral OCR: Una guía con ejemplos prácticos.
Veamos cómo configurar Mistral OCR 3 para utilizarlo con AI Studio.
Mistral OCR 3 está disponible para su uso en su estudio de IA. Esta es la forma más fácil de probarlo, ya que ofrece una interfaz fácil de usar.
Cuando os registráis, primero se os pide que creéis una organización:
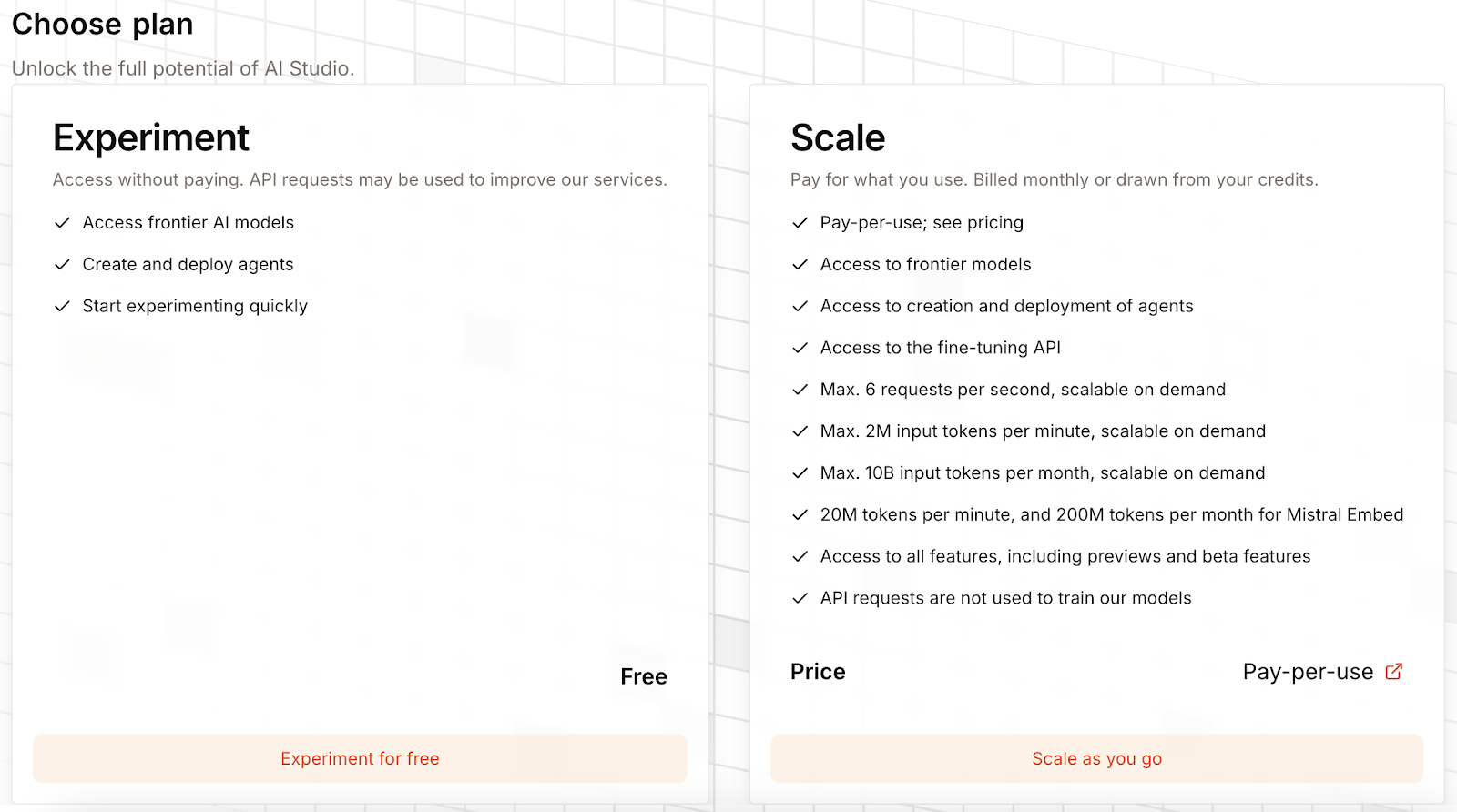
Inicialmente, Mistral OCR 3 estará bloqueado y tendrás que seleccionar un plan para desbloquearlo:

Es posible seleccionar un plan gratuito, que permite utilizar Mistral OCR 3 a cambio de que recopilen datos de uso para mejorar sus servicios. Como alternativa, podemos introducir los datos de la tarjeta de crédito y pagar por cada uso.
No hay cuota de suscripción, pero se os cobra 2 $ o 1 $ por cada 1000 páginas, dependiendo de si utilizáis solicitudes por lotes o no.
Una vez configurada la cuenta, podemos probar Mistral OCR 3 accediendo a la pestaña «Document AI» (IA para documentos) en AI Studio.
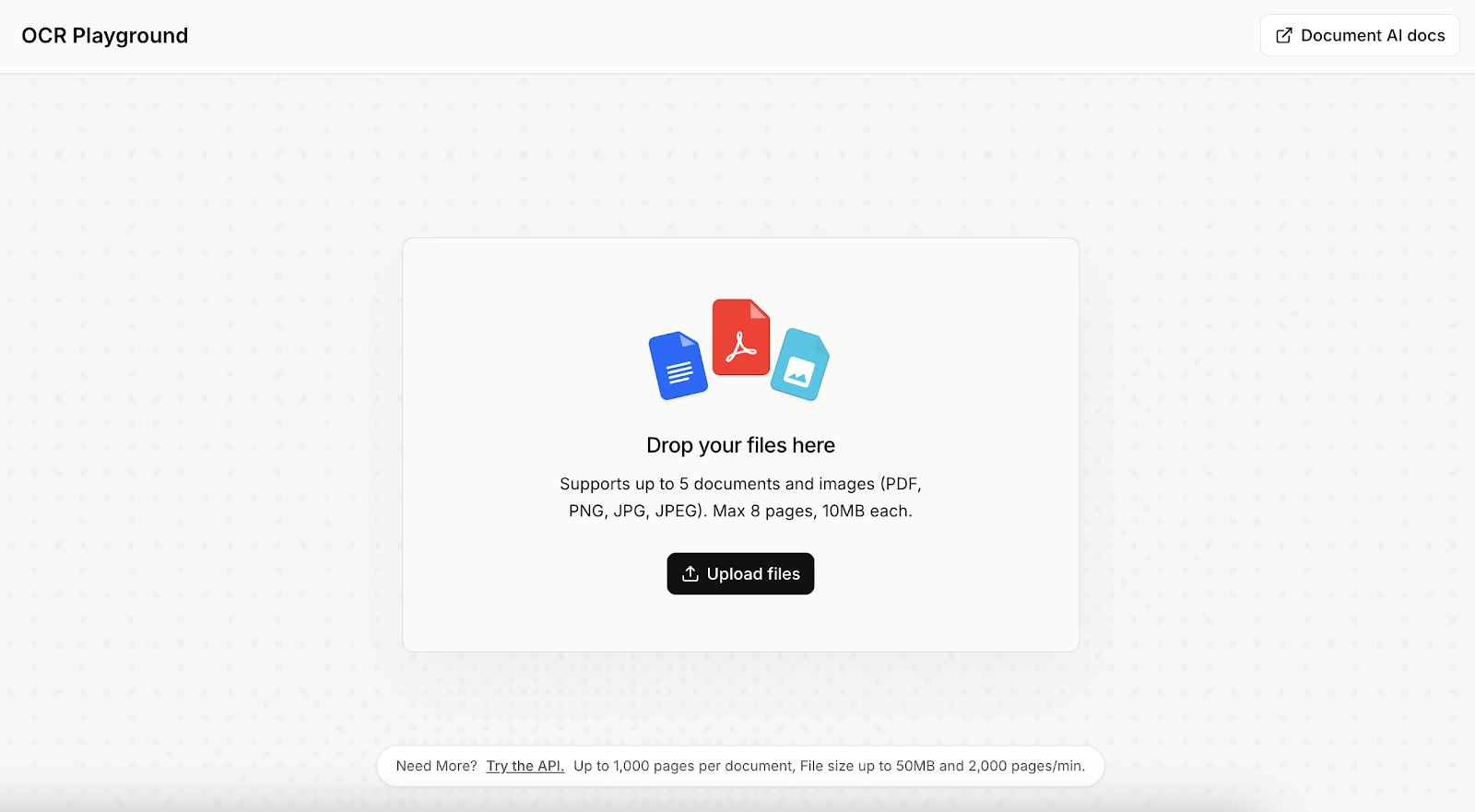
Para empezar, subimos el documento o la imagen en los que queremos realizar el OCR. En mi caso, escribí un texto y una tabla en una hoja de papel y lo subí. Mi letra es bastante mala, así que tenía curiosidad por ver si Mistral OCR 3 podía entenderla.

Cuando se selecciona el archivo, se nos presentan opciones sobre cómo se debe procesar el archivo. En este primer ejemplo, dejé las opciones predeterminadas y simplemente hice clic en el botón «Ejecutar» situado en la esquina superior derecha.
Aquí está el resultado:

El resultado es bastante bueno, pero no perfecto:
Una de las características interesantes de Mistral OCR 3 es la posibilidad de especificar una estructura JSON para analizar los datos. Esto resulta especialmente útil para analizar tablas, ya que nos permite especificar los nombres de las columnas y sus tipos de datos, de modo que obtenemos las filas como un diccionario JSON.
Intentemos analizar la tabla del ejemplo anterior de nuevo especificando un esquema JSON.

Para proporcionar un esquema JSON, es necesario seleccionar el esquema JSON en lugar del modo de texto antes de ejecutar el OCR.
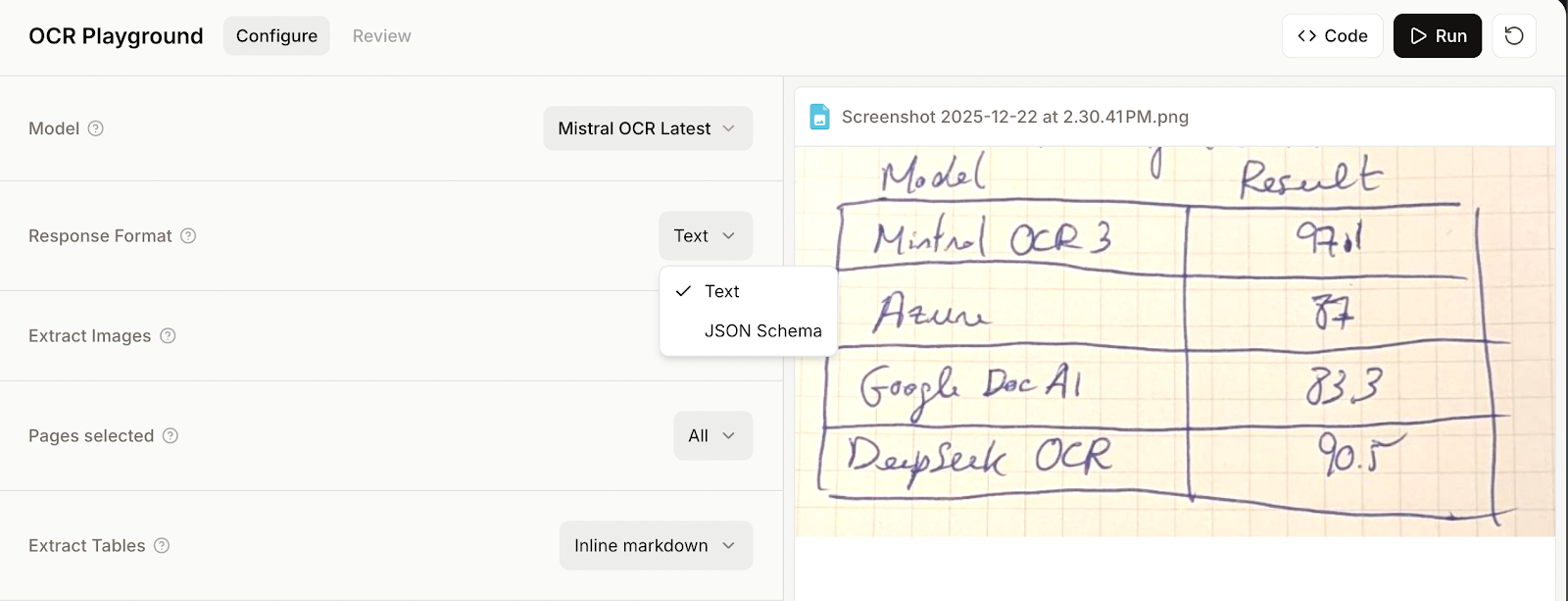
A continuación, proporcionamos un esquema con código o mediante la interfaz de usuario «Visual Builder». Recomiendo la segunda opción, ya que es más sencilla cuando ya estamos utilizando el modelo manualmente.
Al añadir un campo, especificamos:
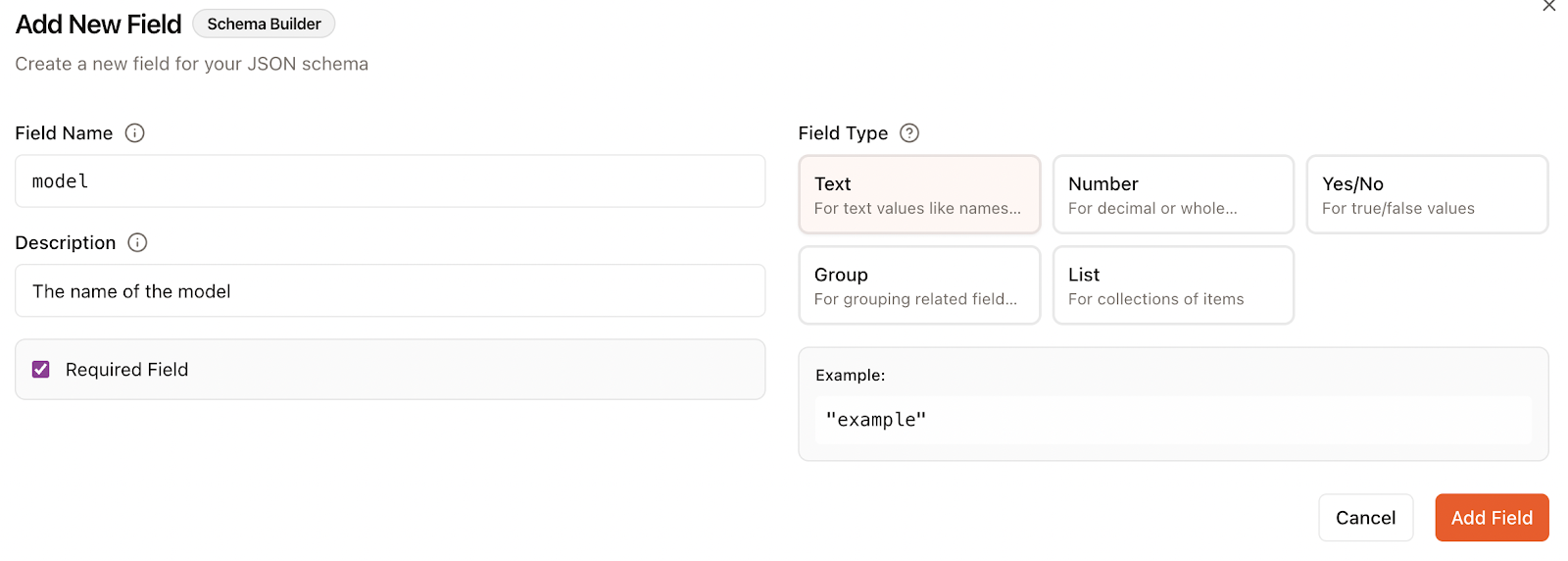
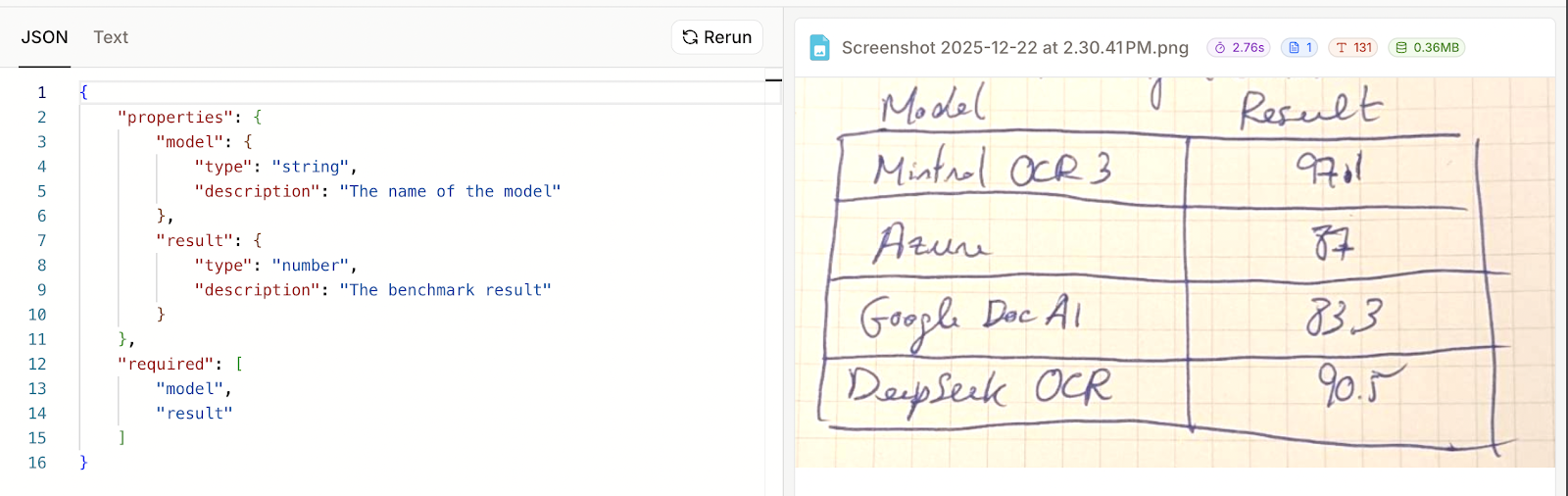
En este caso, especificaste dos campos, uno para el nombre del modelo y otro para el resultado de la prueba comparativa:
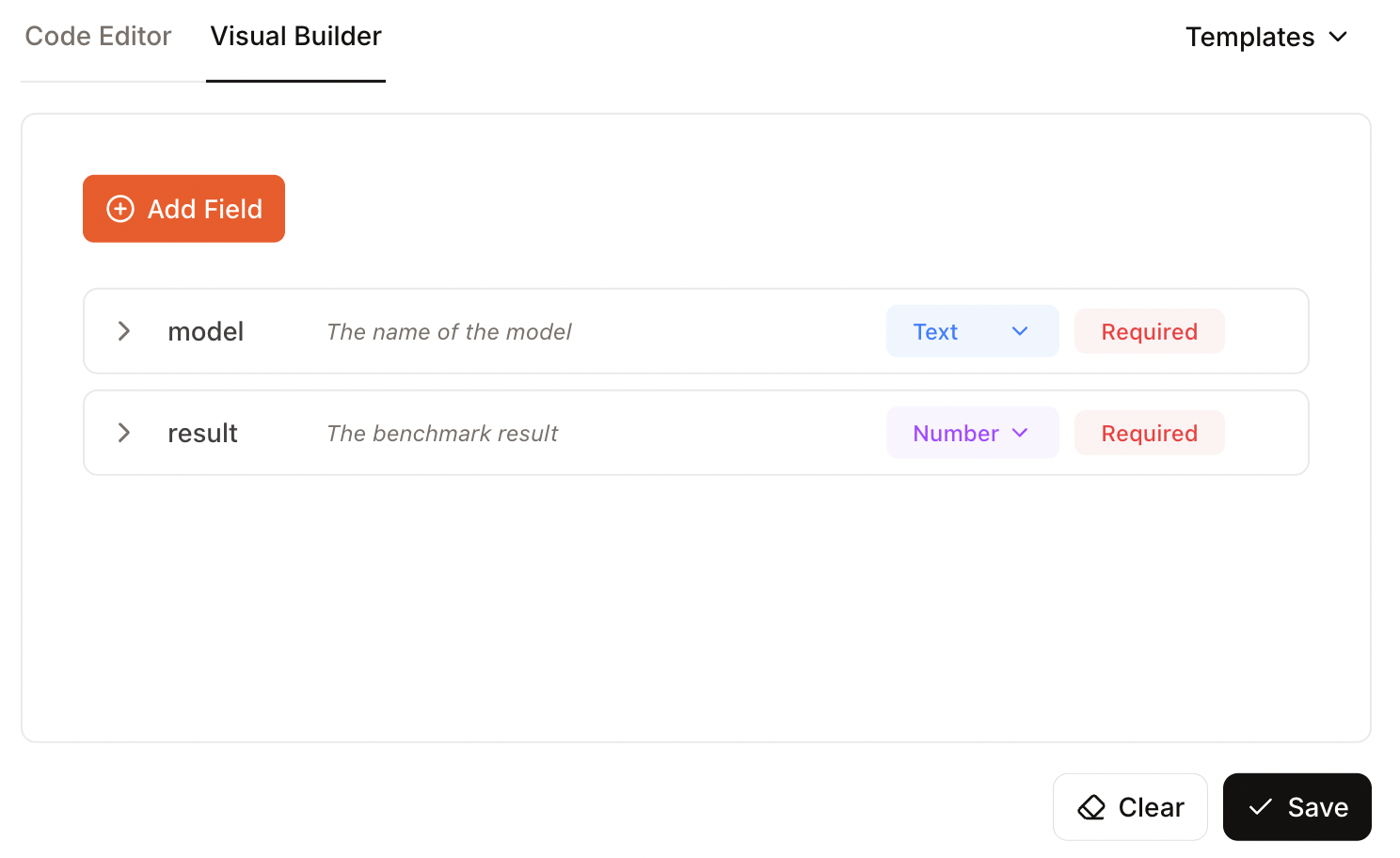
Ahora podemos hacer clic en «Ejecutar» y ver los resultados. Por desgracia, este ejemplo no funcionó. En los resultados, lo único que se proporcionó fue el esquema que yo proporcioné, no los datos reales.
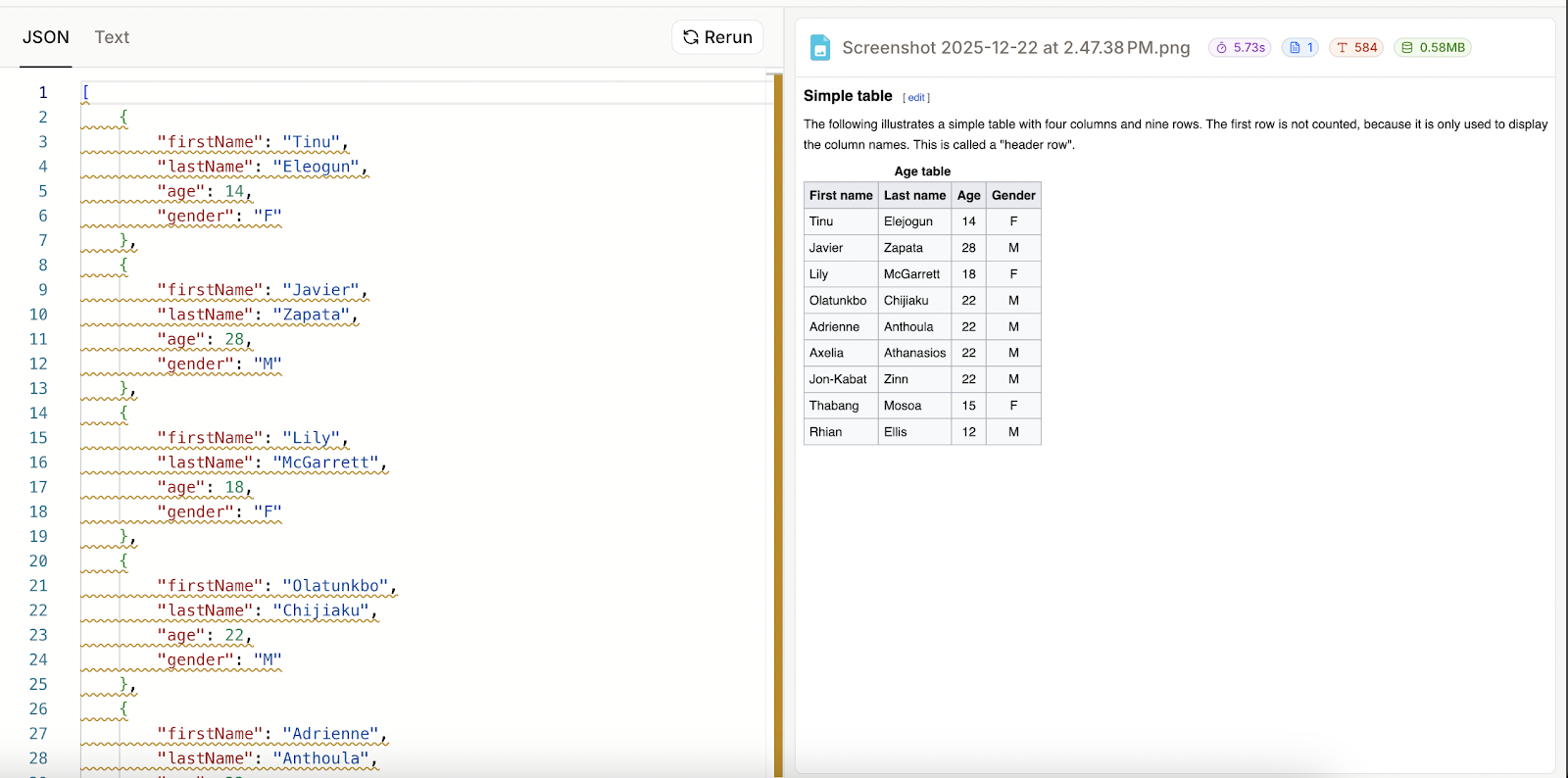
Pensé que tal vez lo había usado incorrectamente, así que, para asegurarme, hice una captura de pantalla de una tabla de muestra de Wikipedia) y lo intenté de nuevo.

Especifiqué cuatro columnas, dejando la última como opcional:

Esta vez funcionó bien. Parece que cuando falla el análisis, el resultado JSON es simplemente el esquema que se proporcionó. Esto también significa que Mistral OCR 3 no pudo analizar mi tabla escrita a mano como JSON, a pesar de que pudo representarla como texto.
En esta sección, exploraremos cómo usar Python para interactuar con la API de Mistral OCR 3. Esto proporciona mucha más flexibilidad, ya que podemos, por ejemplo, combinar el resultado con otros modelos de IA para procesar los datos extraídos.
Cuando subís un archivo a AI Studio, hay un botón «Código» junto al botón «Ejecutar». Al hacer clic aquí, podemos ver qué código se necesitaría para realizar esta operación utilizando la API.
Aquí tienes un ejemplo:
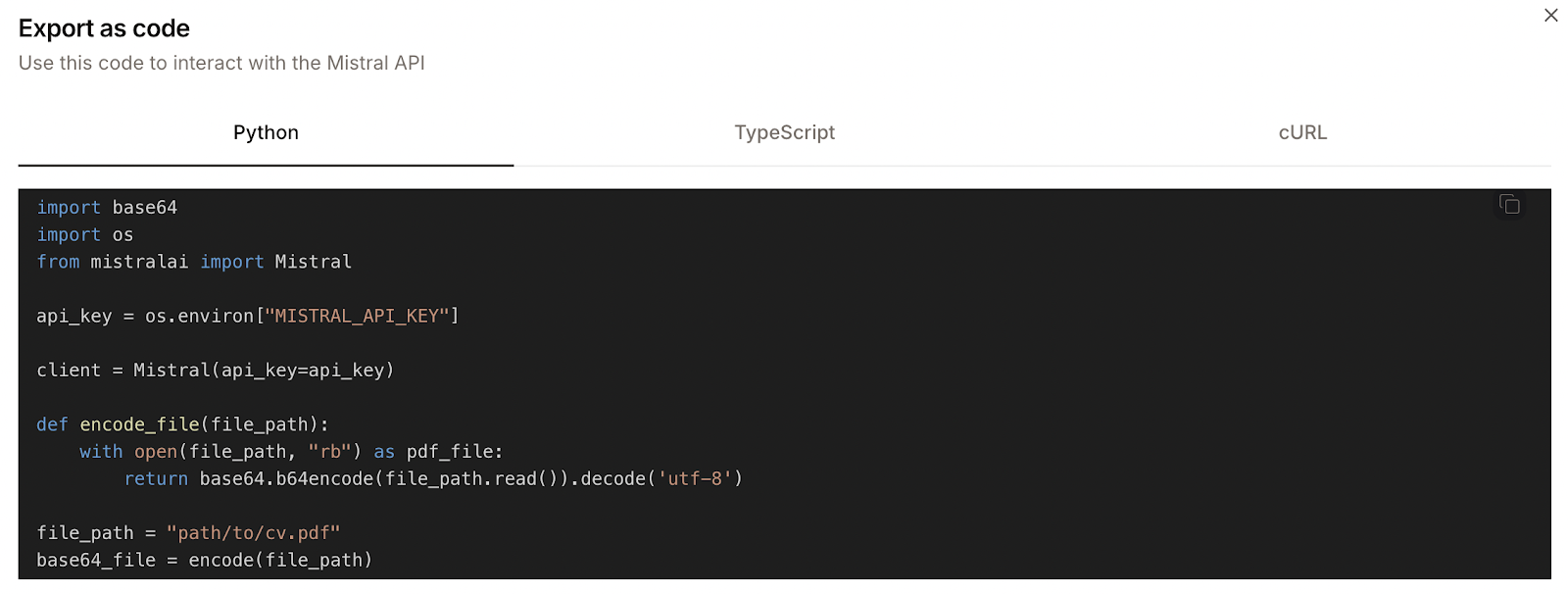
Sin embargo, el código Python proporcionado no es del todo preciso. Por ejemplo, define una función llamada encode_file, pero luego llama a una función llamada encode. Se trata de inconsistencias menores, pero hacen que el código no funcione directamente.
Pero no te preocupes, te explicaremos detalladamente cómo utilizar la API. Para obtener más información sobre la API, te recomendamos que consultes la documentación oficial.
Lo primero que debemos hacer es crear una clave API en la pestaña «Claves API» y copiar esa clave en un nuevo archivo llamado .env ubicado en la misma carpeta que el script de Python.
A continuación, instalamos las dependencias necesarias:
pip install mistralai python-dotenvAquí tienes un script en Python que carga una imagen JPEG local, realiza un reconocimiento óptico de caracteres (OCR) en ella y guarda el resultado en un archivo Markdown:
import sys
import base64
import os
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
# Load a file as base 64
def encode_file(file_path):
with open(file_path, "rb") as pdf_file:
return base64.b64encode(pdf_file.read()).decode('utf-8')
# Perform OCR on and image
def process_image_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},
include_image_base64=True
)
for index, page in enumerate(ocr_response.pages):
with open(f"page{index}.md", "wt") as f:
f.write(page.markdown)
if __name__ == "__main__":
# Load the input file from the arguments
file_path = sys.argv[1]
process_image_ocr(file_path)Cuando la entrada es un PDF en lugar de una imagen, lo único que cambia es el valor proporcionado en el campo « document » (Nombre del archivo de entrada). Para una imagen JPEG, utilizamos:
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},Para un PDF, en su lugar utilizamos:
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},Aquí tienes una función completa que puedes usar para procesar un PDF:
def process_pdf_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},
include_image_base64=True
)
process_pages(ocr_response)Tener dos funciones distintas para procesar archivos PDF y JPEG resulta un poco engorroso y tampoco es la mejor práctica, ya que hay mucho código compartido entre ambas.
Para evitar esto, hemos escrito una nueva función mejorada que utiliza el paquete mimetypes para intentar identificar el tipo de archivo proporcionado y crear la solicitud API en consecuencia. También actualizamos el código para guardar las imágenes identificadas en el documento.
Aquí está la versión final:
import sys
import os
import base64
import mimetypes
import datauri
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# List the supported image types
SUPPORTED_IMAGE_TYPES = {
"image/jpeg",
"image/png",
"image/webp",
"image/tiff",
}
PDF_MIME = "application/pdf"
# Load a file as base 64
def encode_file(file_path: str) -> str:
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# Build the document payload depending on the type of data contained in the file
def build_document_payload(file_path: str) -> dict:
mime_type, _ = mimetypes.guess_type(file_path)
if not mime_type:
raise ValueError(f"Could not determine MIME type for {file_path}")
base64_file = encode_file(file_path)
if mime_type == PDF_MIME:
return {
"type": "document_url",
"document_url": f"data:{mime_type};base64,{base64_file}",
}
if mime_type in SUPPORTED_IMAGE_TYPES:
return {
"type": "image_url",
"image_url": f"data:{mime_type};base64,{base64_file}",
}
raise ValueError(f"Unsupported file type: {mime_type}")
# Generic function to process OCR on a file
def process_ocr(file_path: str, output_filename: str = "output.md"):
document = build_document_payload(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document=document,
include_image_base64=True,
)
process_pages(ocr_response, output_filename)
# Save an image to a local file
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as f:
f.write(parsed.data)
# Process all pages from the OCR response
def process_pages(ocr_response, output_filename: str):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python ocr.py <file>")
sys.exit(1)
process_ocr(sys.argv[1])Para utilizar esta versión, es necesario el paquete datauri para guardar la imagen identificada por Mistral OCR 3, que se puede instalar mediante:
pip install datauriAnteriormente hemos aprendido que Mistral OCR 3 nos permite proporcionar un esquema JSON para analizar los datos. Esta función también está disponible cuando se utiliza a través de la API.
Para ello, debemos proporcionar el esquema JSON en el parámetro document_annotation_format al realizar la solicitud. A continuación se muestra un ejemplo de esquema JSON para las dos columnas model y result, correspondiente a la tabla de ejemplo escrita a mano.

document_annotation_format={
"name": "response_schema",
"schemaDefinition": {
"properties": {
"model": {
"type": "string",
"description": "The name of the model"
},
"result": {
"type": "number",
"description": "The benchmark result"
}
},
"required": [
"model"
]
}
}La estructura es siempre la misma. Debemos añadir una entrada por cada columna del campo « properties » (Tipo de datos), incluyendo información sobre el tipo de datos y una descripción que ayude al modelo a identificar los datos.
A continuación, enumeramos todos los campos obligatorios en el campo « required » (Campos de registro).
Para utilizarlo junto con el código, la forma más sencilla es almacenar el esquema en un archivo JSON y cargarlo utilizando el paquete json.
Una de las principales ventajas de utilizar Mistral OCR 3 con la API es la posibilidad de desarrollar sobre ella. En esta sección, presentamos algunas ideas de proyectos para que tú puedas desarrollar a partir de ellas.
Hemos aprendido cómo realizar OCR en una imagen. Podemos usar esto para crear una aplicación que tome una foto de un recibo de compra y luego utilice Mistral OCR 3 para procesar los datos de la imagen y extraer un diccionario JSON con la lista de los artículos del recibo y sus precios.
Estos gastos se pueden clasificar automáticamente y añadir a una base de datos, lo que permite al usuario llevar un control de sus gastos.
Podemos combinar Mistral OCR 3 con una IA de conversión de texto a voz para crear un lector de audio de documentos. El usuario puede seleccionar un PDF de texto y enviarlo a Mistral OCR 3 para su procesamiento. A continuación, el texto resultante se envía a un modelo de IA de conversión de texto a voz, como OpenAI Audio API o Eleven Labs.
Dado que Mistral OCR 3 también funciona con imágenes, se puede utilizar con fotos, lo que permite a los usuarios tomar una foto de un documento y escucharlo sobre la marcha.
Para obtener más información sobre la conversión de texto a voz, recomiendo uno de los siguientes recursos:
Mistral OCR 3 es una herramienta práctica y eficaz para convertir documentos del mundo real en texto utilizable y datos estructurados, tanto si estás experimentando en AI Studio como si estás realizando integraciones a través de Python.
Ilumina páginas escaneadas, formularios y tablas, conserva el diseño con marcas e imágenes, y admite esquemas JSON cuando necesitas estructura. Sin embargo, como hemos visto, una escritura manuscrita ilegible y encabezados ambiguos pueden seguir causando problemas, y los análisis de esquemas fallidos simplemente devuelven el esquema.
La API es sencilla una vez que resuelves pequeñas inconsistencias, y un gestor de archivos genérico, junto con el almacenamiento de imágenes, facilita su integración en pequeñas aplicaciones o procesos. Si solo quieres probarlo, Studio es la opción más rápida. Para el uso en producción, ten en cuenta el modelo de costes, procesa por lotes siempre que sea posible y añade validación para los casos extremos.
A partir de ahí, puedes iterar; ajustar esquemas, combinar resultados con otros modelos y crear utilidades específicas, como analizadores de recibos o lectores de audio, dejando que el modelo se encargue del trabajo pesado mientras tú te ocupas de la fiabilidad y la experiencia de usuario.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Duong Vu
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita


