
Curso
Trabalhar com a API da OpenAI
3 h
142.5K
O mais recente modelo OCR da Mistral, o Mistral OCR 3, consegue extrair texto e imagens incorporadas de vários tipos de documentos com uma precisão incrível.
Neste artigo, vou te ensinar como aproveitar ao máximo o Mistral OCR 3 usando tanto o AI Studio quanto a API com Python. Vamos criar um pequeno aplicativo que transforma uma foto de um menu em um site interativo.

Se você quiser saber mais sobre como usar APIs pra criar ferramentas com inteligência artificial, recomendo dar uma olhada no curso curso Trabalhando com a API OpenAI.
OCR significa Reconhecimento Ótico de Caracteres e serve pra transformar documentos em texto. Por exemplo, ele pode transformar uma foto de uma nota escrita à mão em texto ou uma tabela em um PDF em uma tabela de texto de verdade que dá pra pesquisar e editar.
O Mistral OCR 3 é o mais recente modelo de compreensão de documentos da Mistral AI, oferecendo precisão e eficiência de ponta para documentos do mundo real. Ele extrai texto e imagens incorporadas com alta fidelidade e mantém a estrutura por meio da saída markdown com reconstrução de tabelas baseada em HTML, com JSON estruturado opcional.
O Mistral OCR 3 supera todos os concorrentes em vários testes de desempenho:
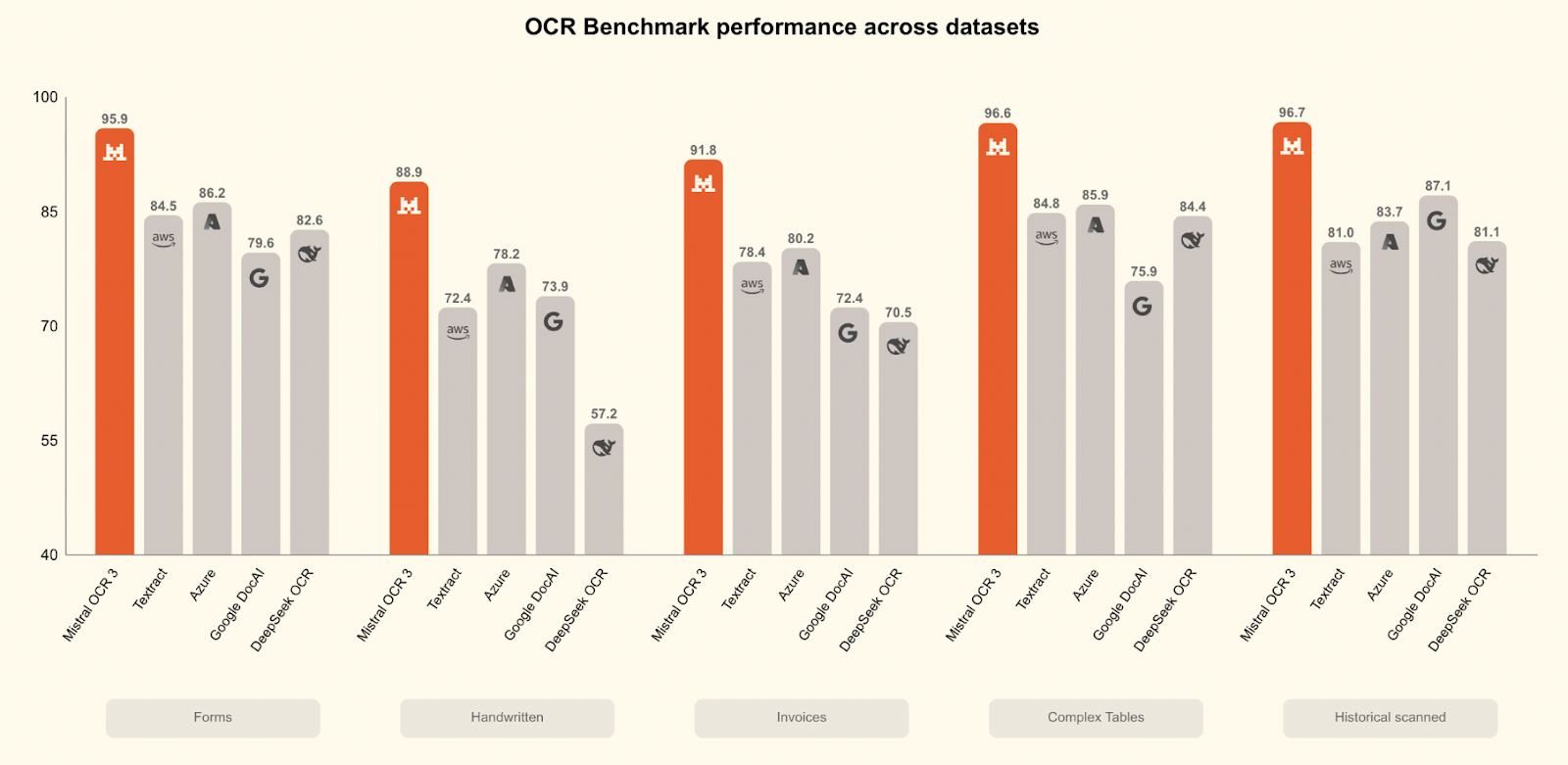
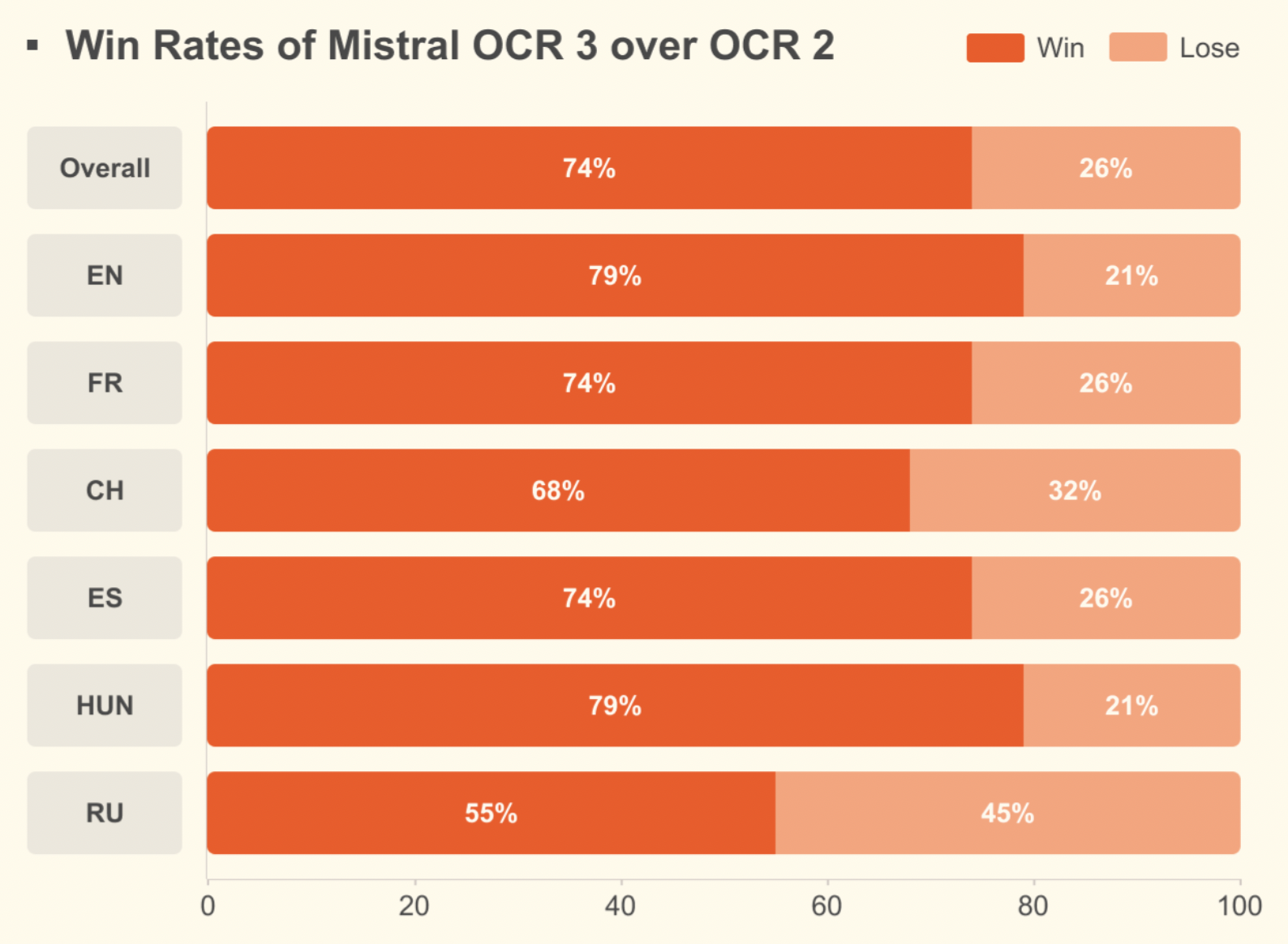
Comparado com o Mistral OCR 2, ele consegue uma taxa de acerto geral de 74% em formulários, documentos digitalizados, tabelas complexas e manuscritos, com ganhos significativos em digitalizações de baixa qualidade e layouts densos.
Para saber mais sobre OCR e o modelo anterior da Mistral, dá uma olhada neste artigo: Mistral OCR: Um guia com exemplos práticos.
Vamos ver como configurar o Mistral OCR 3 com o AI Studio.
O Mistral OCR 3 está disponível para uso no seu estúdio de IA. Essa é a maneira mais fácil de experimentar, porque tem uma interface bem fácil de usar.
Quando a gente se inscreve, primeiro a gente é solicitado a criar uma organização:
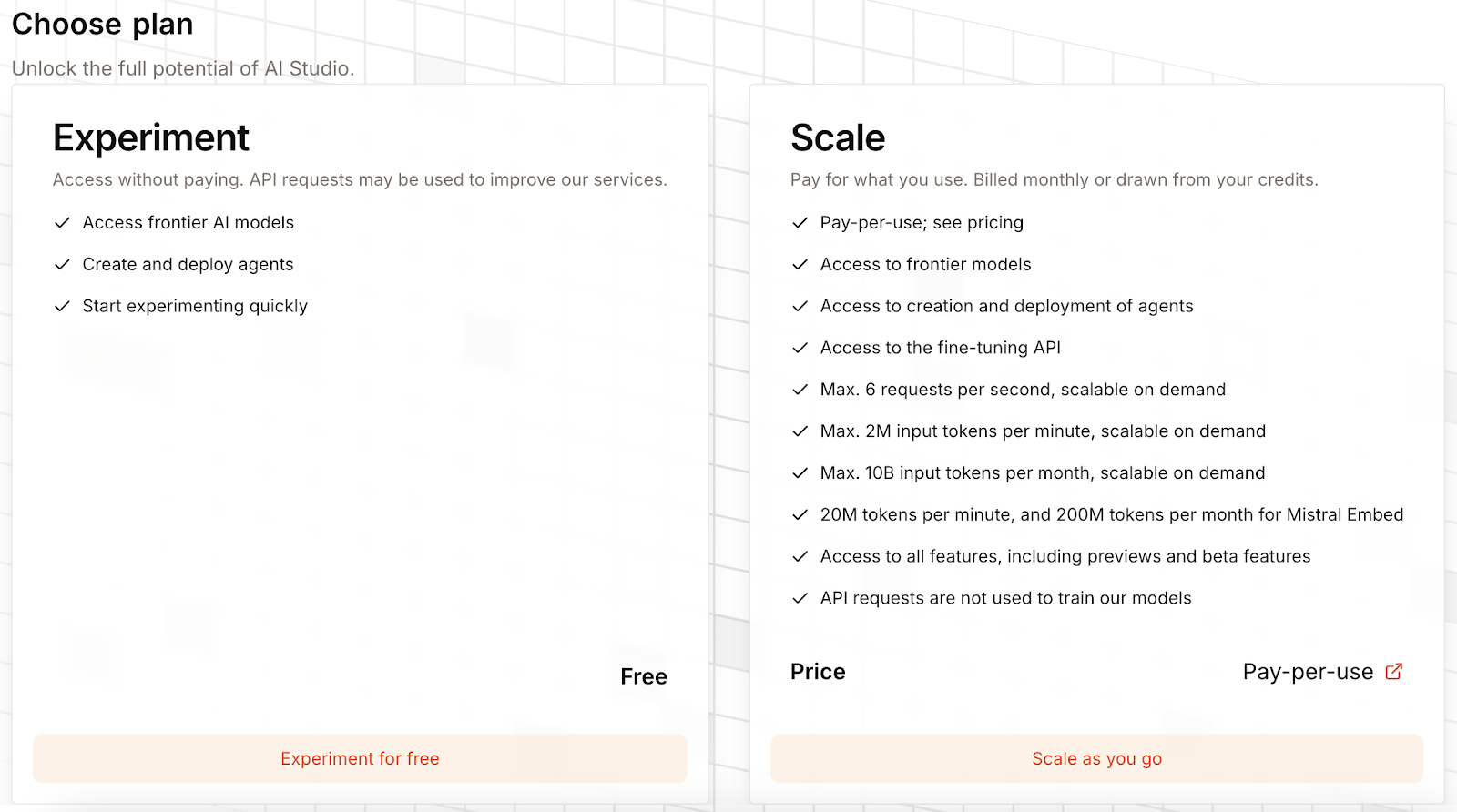
No começo, o Mistral OCR 3 vai estar bloqueado, e a gente precisa escolher um plano pra desbloquear:

Dá pra escolher um plano grátis, que permite usar o Mistral OCR 3, mas eles vão coletar dados de uso pra melhorar os serviços deles. Ou, a gente pode colocar os dados do cartão de crédito e ser cobrado por uso.
Não tem taxa de assinatura, mas a gente paga US$ 2 ou US$ 1 por cada 1.000 páginas, dependendo se usamos ou não solicitações em lote.
Depois que a conta estiver pronta, a gente pode testar o Mistral OCR 3 acessando a aba “Document AI” no AI Studio.
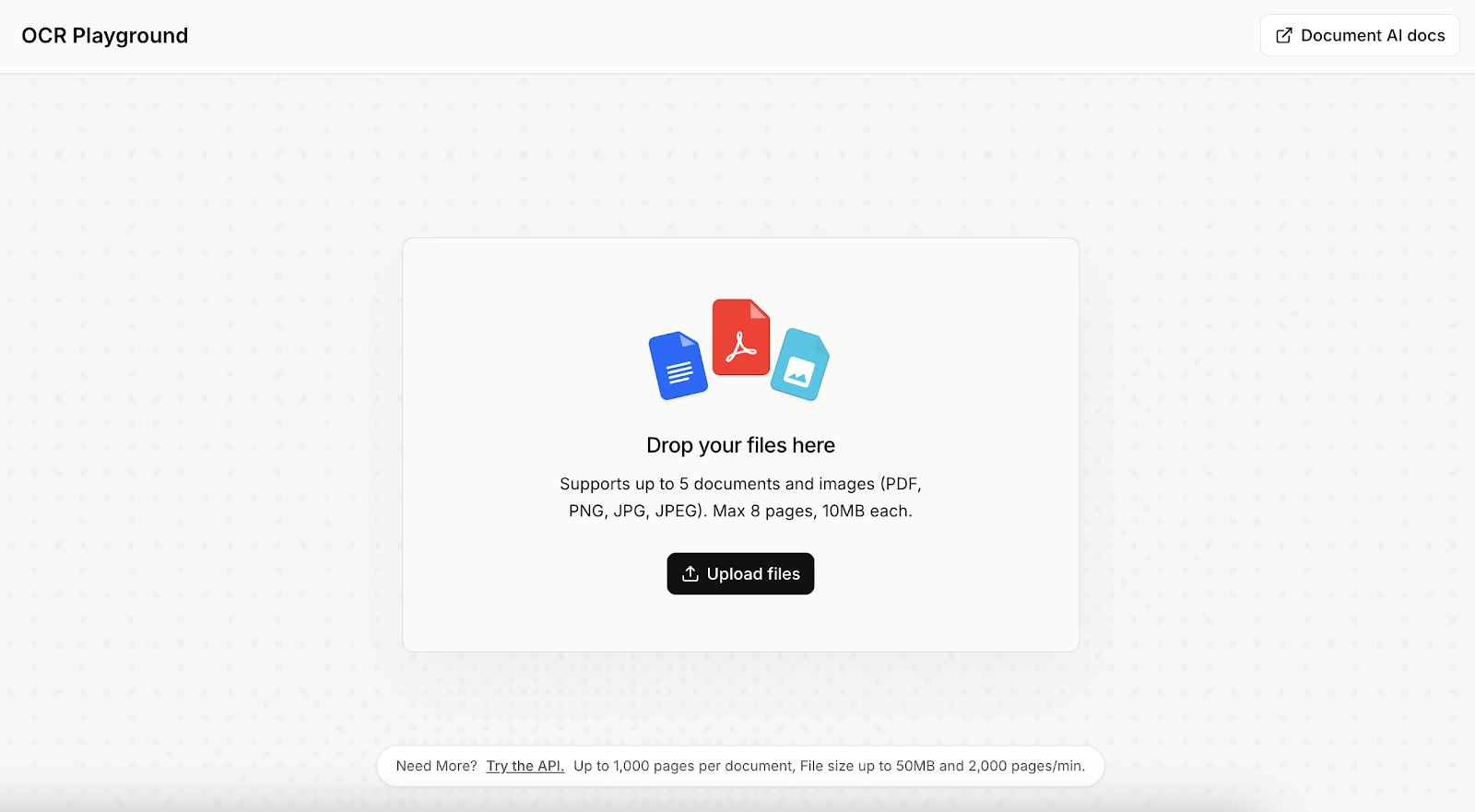
Pra começar, a gente carrega o documento ou imagem que a gente quer fazer o OCR. No meu caso, escrevi um texto e fiz uma tabela em um pedaço de papel e enviei. Minha caligrafia é bem ruim, então fiquei curioso pra ver se o Mistral OCR 3 conseguiria entender.

Quando o arquivo é selecionado, aparecem opções sobre como ele deve ser processado. Neste primeiro exemplo, deixei as opções padrão e simplesmente cliquei no botão “Executar” no canto superior direito.
E aí está o resultado:

O resultado é bem legal, mas não é perfeito:
Uma das funcionalidades legais do Mistral OCR 3 é poder definir uma estrutura JSON pra analisar os dados. Isso é super útil pra analisar tabelas, porque a gente pode especificar os nomes das colunas e seus tipos de dados pra conseguir as linhas como um dicionário JSON.
Vamos tentar analisar a tabela do exemplo anterior de novo, especificando um esquema JSON.

Para fornecer um esquema JSON, precisamos selecionar o esquema JSON em vez do modo texto antes de executar o OCR.
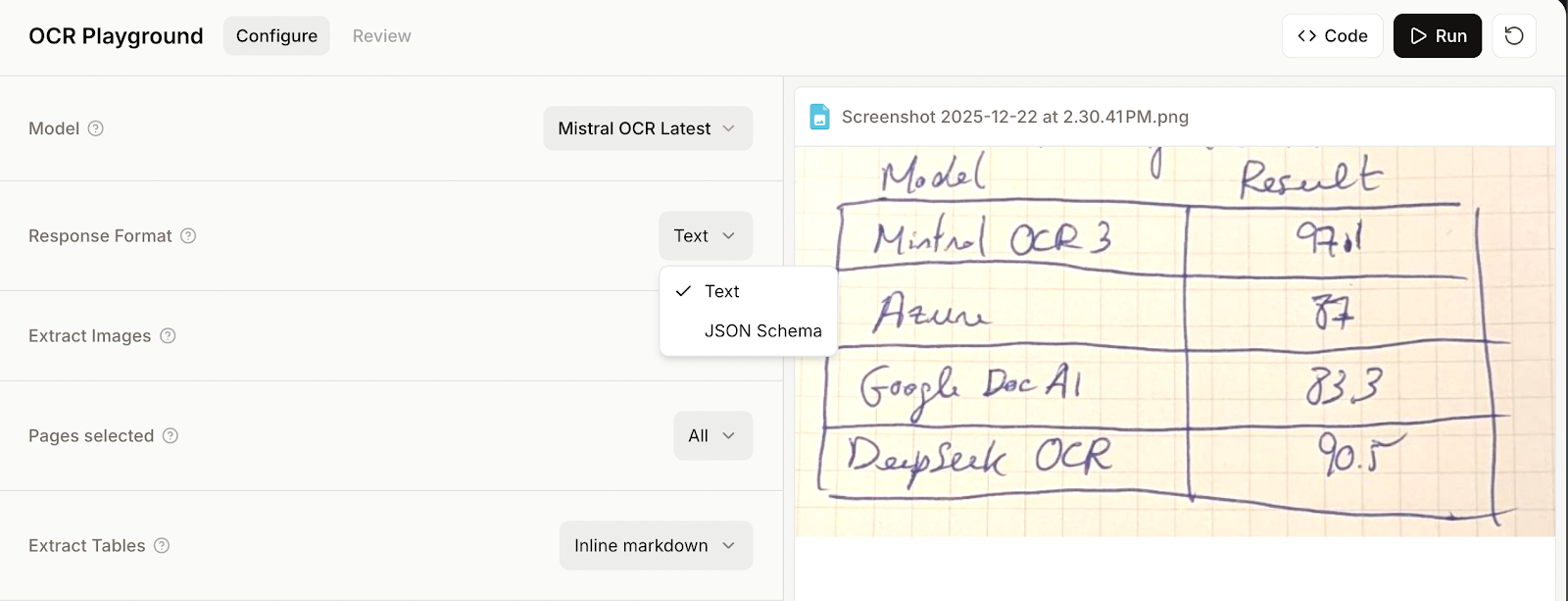
Em seguida, fornecemos um esquema com código ou usando a interface de usuário “Visual Builder”. Eu recomendo a segunda opção, porque é mais simples quando já estamos usando o modelo manualmente.
Ao adicionar um campo, a gente especifica:
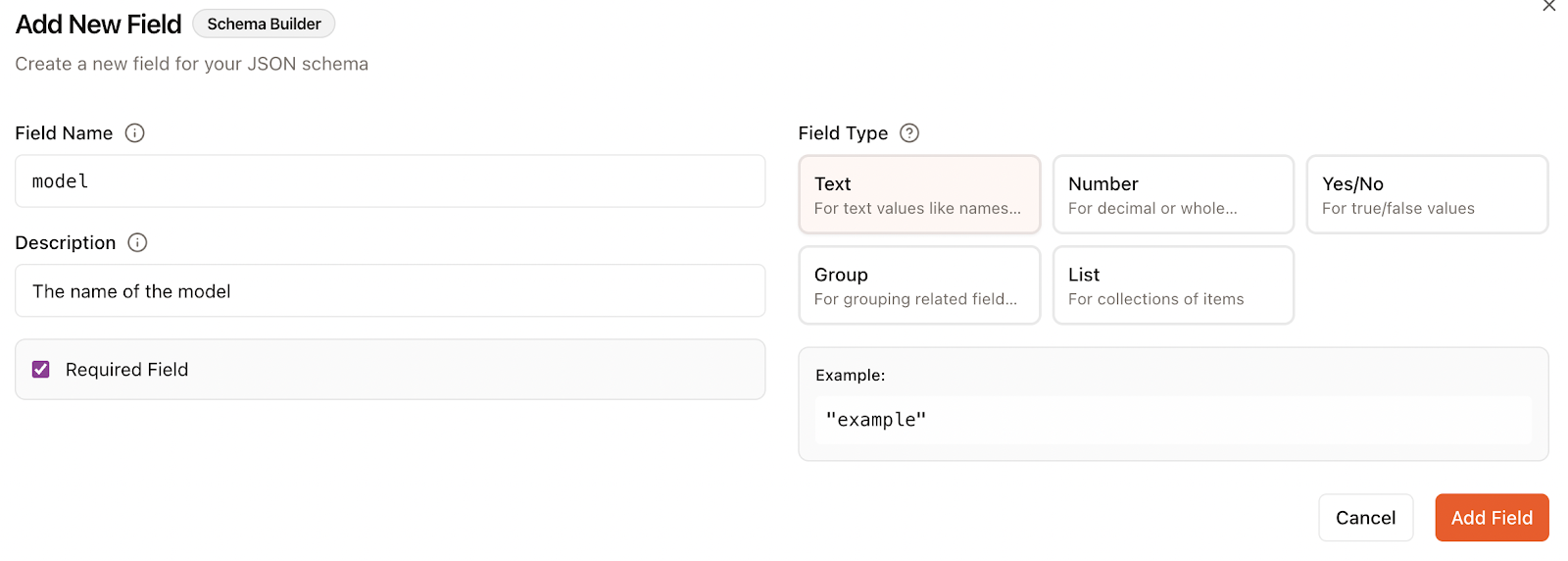
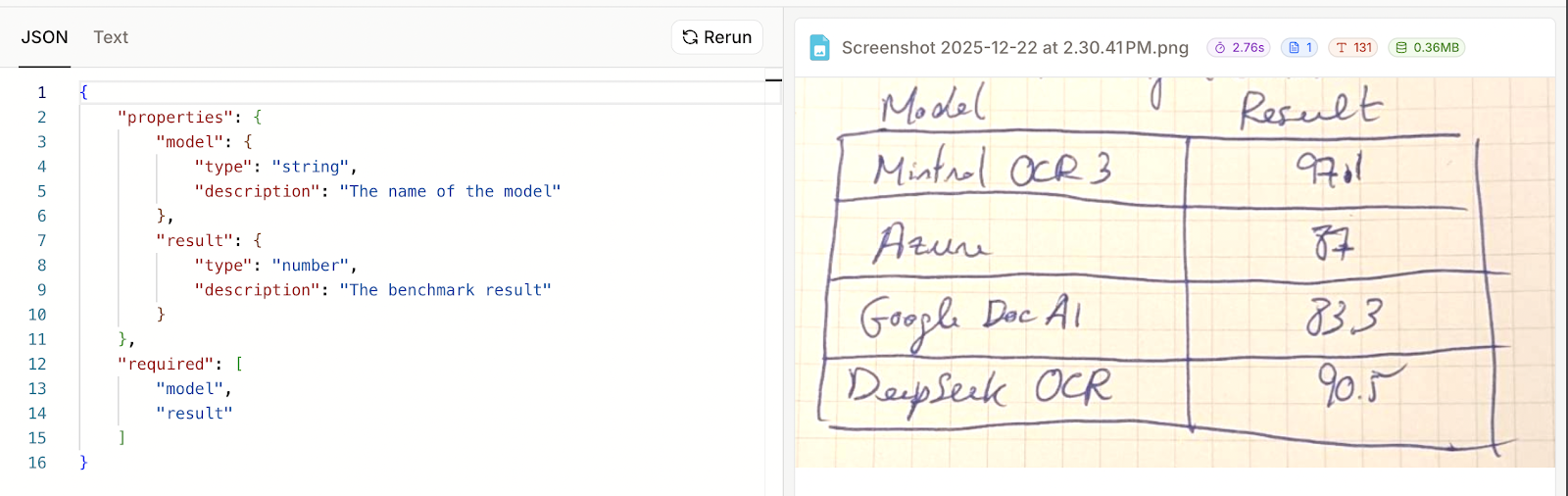
Nesse caso, eu especifiquei dois campos, um para o nome do modelo e outro para o resultado do benchmark:
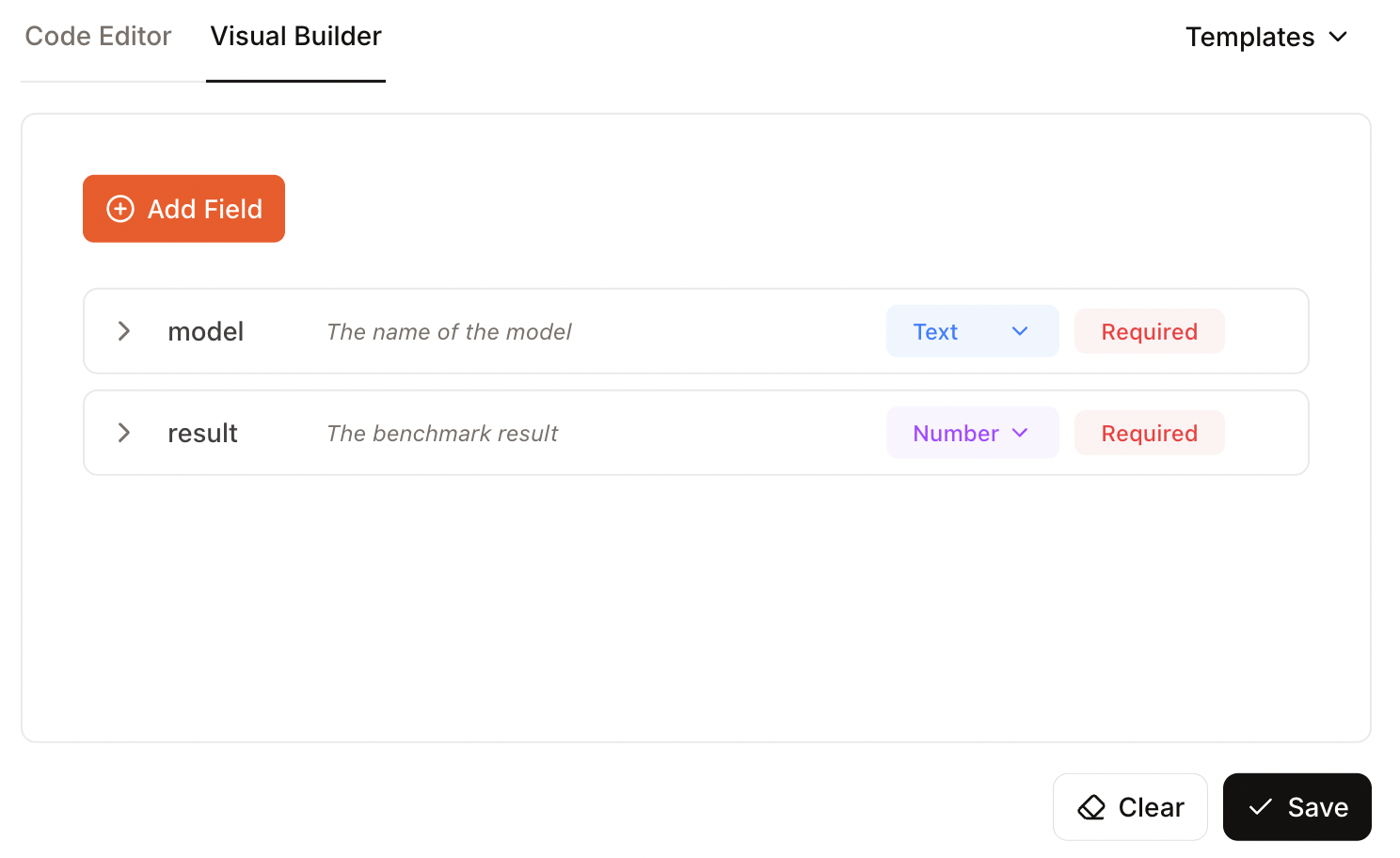
Agora podemos clicar em “Executar” e ver os resultados. Infelizmente, esse exemplo não deu certo. Nos resultados, a única coisa que apareceu foi o esquema que eu forneci, não os dados reais.
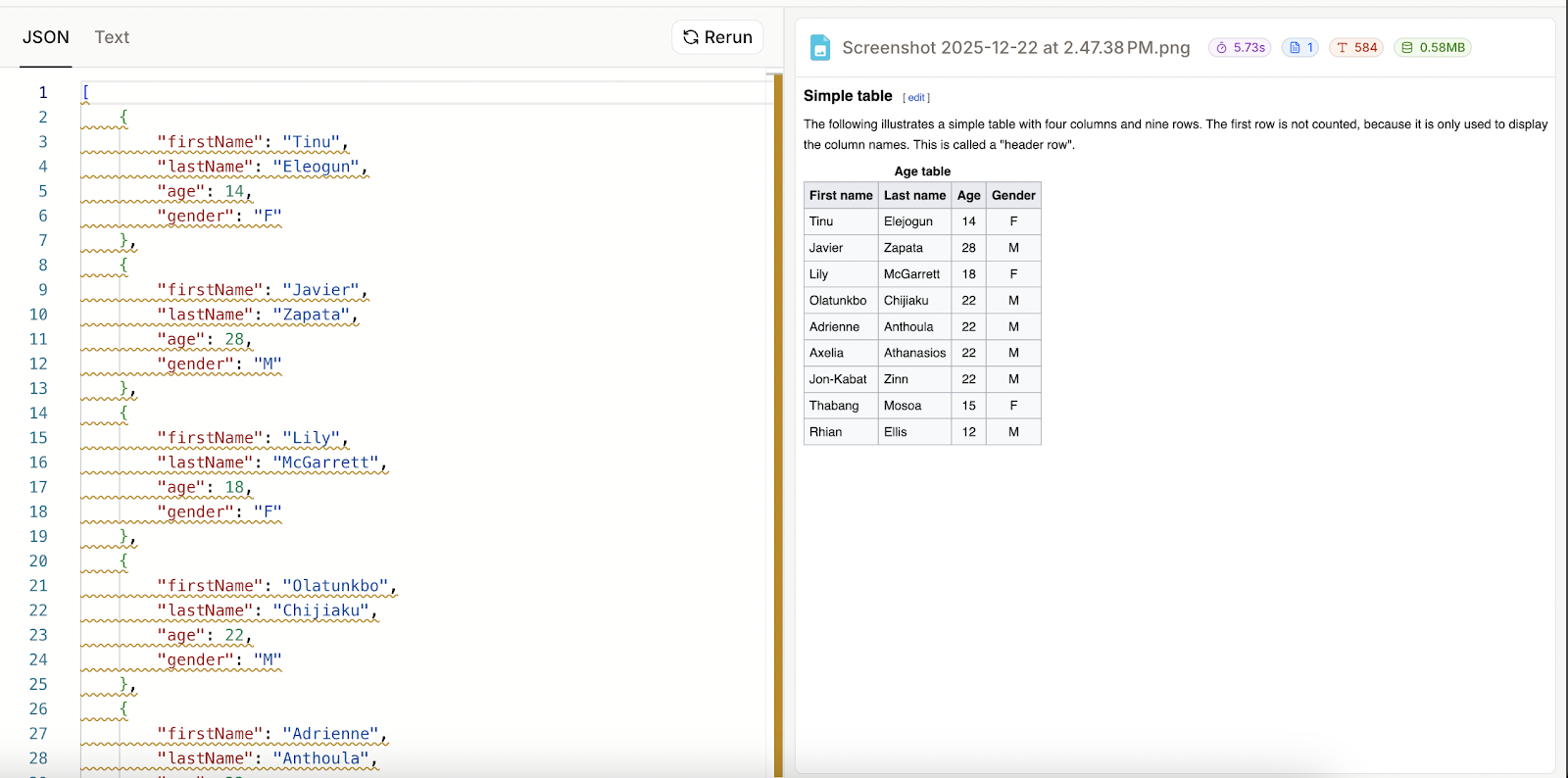
Achei que talvez tivesse usado incorretamente, então, para ter certeza, tirei uma captura de tela de uma tabela de exemplo da Wikipedia) e tentei de novo.

Especifiquei quatro colunas, deixando a última como opcional:

Desta vez funcionou bem. Parece que, quando a análise falha, o resultado JSON é só o esquema que foi fornecido. Isso também quer dizer que o Mistral OCR 3 não conseguiu analisar minha tabela escrita à mão como JSON, mesmo que conseguisse renderizá-la como texto.
Nesta seção, vamos ver como usar o Python para interagir com a API do Mistral OCR 3. Isso dá muito mais flexibilidade, porque a gente pode, por exemplo, juntar o resultado com outros modelos de IA para processar os dados extraídos.
Quando a gente carrega um arquivo no AI Studio, tem um botão “Código” ao lado do botão “Executar”. Ao clicar aqui, dá pra ver qual código seria necessário pra fazer essa operação usando a API.
Aqui vai um exemplo:
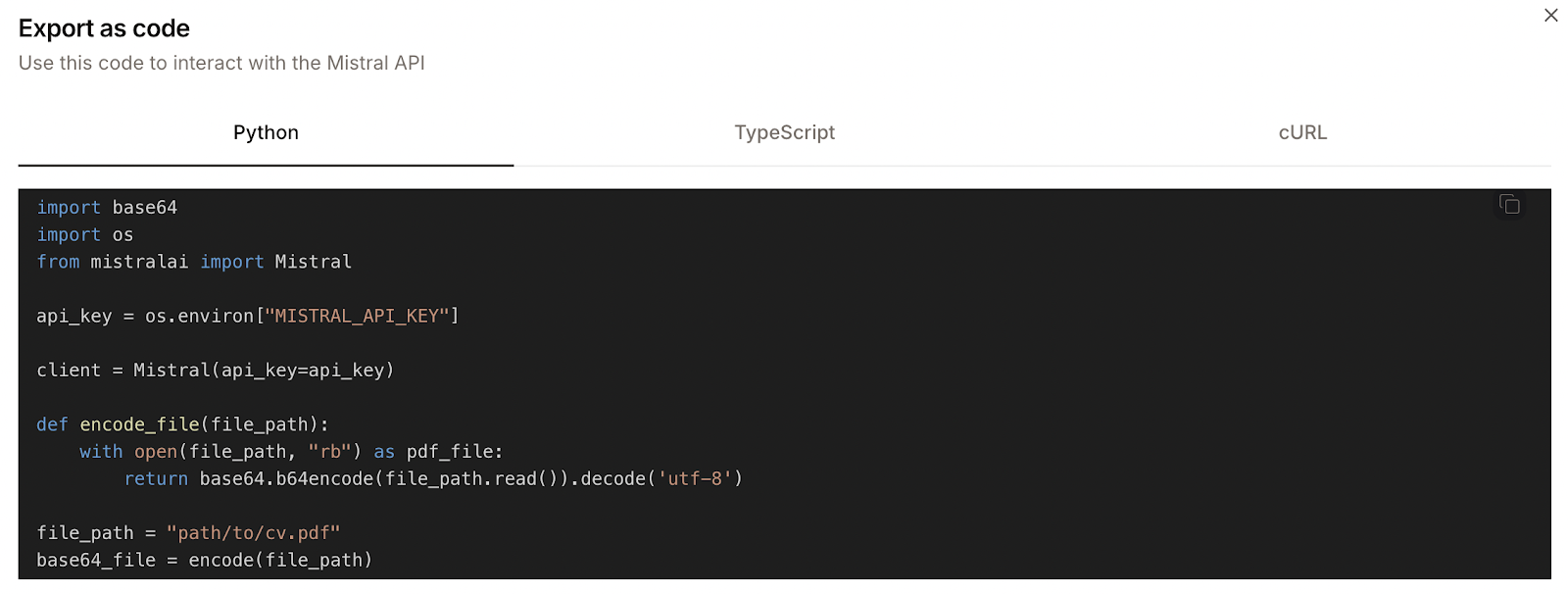
Mas, o código Python que te deram não está totalmente certo. Por exemplo, define uma função chamada encode_file, mas depois chama uma função chamada encode. São pequenas inconsistências, mas fazem com que o código não funcione logo de cara.
Mas não se preocupe, vamos explicar em detalhes como usar a API. Pra saber mais sobre a API, a gente recomenda dar uma olhada a documentação oficial.
A primeira coisa que precisamos fazer é criar uma chave API na aba “Chaves API” e copiar essa chave para um novo arquivo chamado .env localizado na mesma pasta que o script Python.
Depois, a gente instala as dependências necessárias:
pip install mistralai python-dotenvAqui tá um script Python que carrega uma imagem JPEG local, faz OCR nela e salva o resultado num arquivo markdown:
import sys
import base64
import os
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
# Load a file as base 64
def encode_file(file_path):
with open(file_path, "rb") as pdf_file:
return base64.b64encode(pdf_file.read()).decode('utf-8')
# Perform OCR on and image
def process_image_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},
include_image_base64=True
)
for index, page in enumerate(ocr_response.pages):
with open(f"page{index}.md", "wt") as f:
f.write(page.markdown)
if __name__ == "__main__":
# Load the input file from the arguments
file_path = sys.argv[1]
process_image_ocr(file_path)Quando a entrada é um PDF em vez de uma imagem, a única coisa que muda é o valor fornecido no campo “ document ”. Para uma imagem JPEG, usamos:
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{base64_file}"
},Para um PDF, usamos:
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},Aqui está uma função completa que podemos usar para processar um PDF:
def process_pdf_ocr(file_path):
base64_file = encode_file(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": f"data:application/pdf;base64,{base64_file}"
},
include_image_base64=True
)
process_pages(ocr_response)Ter duas funções diferentes para processar arquivos PDF e JPEG é meio chato e também não é a melhor prática, já que tem muito código em comum entre as duas.
Pra evitar isso, a gente criou uma função nova e melhorada que usa o pacote mimetypes pra tentar identificar o tipo do arquivo fornecido e construir a solicitação da API de acordo com isso. Também atualizamos o código para salvar as imagens identificadas no documento.
Aqui está a versão final:
import sys
import os
import base64
import mimetypes
import datauri
from mistralai import Mistral
from dotenv import load_dotenv
# Load the API key from the .env file
load_dotenv()
# Initialize the Mistral client
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# List the supported image types
SUPPORTED_IMAGE_TYPES = {
"image/jpeg",
"image/png",
"image/webp",
"image/tiff",
}
PDF_MIME = "application/pdf"
# Load a file as base 64
def encode_file(file_path: str) -> str:
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# Build the document payload depending on the type of data contained in the file
def build_document_payload(file_path: str) -> dict:
mime_type, _ = mimetypes.guess_type(file_path)
if not mime_type:
raise ValueError(f"Could not determine MIME type for {file_path}")
base64_file = encode_file(file_path)
if mime_type == PDF_MIME:
return {
"type": "document_url",
"document_url": f"data:{mime_type};base64,{base64_file}",
}
if mime_type in SUPPORTED_IMAGE_TYPES:
return {
"type": "image_url",
"image_url": f"data:{mime_type};base64,{base64_file}",
}
raise ValueError(f"Unsupported file type: {mime_type}")
# Generic function to process OCR on a file
def process_ocr(file_path: str, output_filename: str = "output.md"):
document = build_document_payload(file_path)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document=document,
include_image_base64=True,
)
process_pages(ocr_response, output_filename)
# Save an image to a local file
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as f:
f.write(parsed.data)
# Process all pages from the OCR response
def process_pages(ocr_response, output_filename: str):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python ocr.py <file>")
sys.exit(1)
process_ocr(sys.argv[1])Pra usar essa versão, você precisa do pacote datauri pra salvar a imagem identificada pelo Mistral OCR 3, que pode ser instalado usando:
pip install datauriA gente viu acima que o Mistral OCR 3 permite usar um esquema JSON pra analisar os dados. Esse recurso também está disponível quando você usa a API.
Para isso, precisamos fornecer o esquema JSON no parâmetro document_annotation_format ao fazer a solicitação. Abaixo está um exemplo de um esquema JSON para as duas colunas model e result, que correspondem à tabela de exemplo escrita à mão.

document_annotation_format={
"name": "response_schema",
"schemaDefinition": {
"properties": {
"model": {
"type": "string",
"description": "The name of the model"
},
"result": {
"type": "number",
"description": "The benchmark result"
}
},
"required": [
"model"
]
}
}A estrutura é sempre a mesma. Precisamos adicionar uma entrada para cada coluna no campo “ properties ”, incluindo informações sobre o tipo de dados e uma descrição para ajudar o modelo a identificar os dados.
Depois, listamos todos os campos obrigatórios no campo “ required ”.
Pra usar junto com o código, o jeito mais fácil é guardar o esquema num arquivo JSON e carregá-lo usando o pacote json.
Uma das principais vantagens de usar o Mistral OCR 3 com a API é a possibilidade de fazer coisas em cima dele. Nesta seção, a gente apresenta algumas ideias de projetos para você desenvolver.
A gente aprendeu como fazer OCR numa imagem. A gente pode usar isso pra criar um aplicativo que tira uma foto de um recibo de compras e, em seguida, usa o Mistral OCR 3 pra processar os dados da imagem e extrair um dicionário JSON listando os itens do recibo e seus preços.
Essas despesas podem então ser automaticamente categorizadas e adicionadas a um banco de dados, permitindo que o usuário acompanhe seus gastos.
A gente pode juntar o Mistral OCR 3 com uma IA de conversão de texto em voz para criar um leitor de áudio de documentos. O usuário pode escolher um PDF de texto e mandar pro Mistral OCR 3 pra ser processado. Depois, o texto que sai é mandado para um modelo de IA de conversão de texto em fala, tipo o OpenAI Audio API ou o Eleven Labs.
Como o Mistral OCR 3 também funciona com imagens, ele pode ser usado com fotos, permitindo que os usuários tirem uma foto de um documento e o ouçam em qualquer lugar.
Pra saber mais sobre conversão de texto em fala, recomendo um dos seguintes recursos:
O Mistral OCR 3 é uma ferramenta prática e eficiente para transformar documentos reais em texto utilizável e dados estruturados, seja você fazendo experiências no AI Studio ou integrando via Python.
Ele funciona super bem em páginas digitalizadas, formulários e tabelas, mantém o layout com marcações e imagens e dá suporte ao esquema JSON quando você precisa de estrutura. Mas, como vimos, uma caligrafia confusa e cabeçalhos ambíguos ainda podem atrapalhar, e as análises de esquema com falha simplesmente devolvem o esquema.
A API é bem simples depois que você resolve algumas pequenas inconsistências, e um manipulador de arquivos genérico, junto com o salvamento de imagens, facilita a integração em pequenos aplicativos ou pipelines. Se você está apenas experimentando, o Studio é o caminho mais rápido. Para uso em produção, pense no modelo de custo, use lotes sempre que possível e adicione validação para casos extremos.
A partir daí, você pode iterar; ajustar esquemas, combinar resultados com outros modelos e criar utilitários específicos, como analisadores de recibos ou leitores de áudio, deixando o modelo fazer o trabalho pesado enquanto você cuida da confiabilidade e da experiência do usuário.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer


