Kurs
Grundlagen der Wahrscheinlichkeit mit R
4 Std.
42.2K
Auf meiner zehnjährigen Reise durch die quantitative Finanzwelt bin ich auf zahlreiche statistische Verteilungen gestoßen, aber nur wenige haben sich als so faszinierend benannt und praktisch wertvoll erwiesen wie die negative Binomialverteilung. Bei der Analyse von Handelsmustern und Risikomodellen habe ich entdeckt, dass diese Verteilung trotz ihres scheinbar pessimistischen Namens Einblicke in Zählprozesse bietet, die viele einfachere Modelle nicht erfassen.
Die negative Binomialverteilung bietet einen ausgefeilten Rahmen für die Modellierung solcher Szenarien und ist flexibler als ihre einfacheren Gegenstücke wie die Poisson-Verteilung. Sie ist eine natürliche Erweiterung der Binomialverteilung und passt sich an Situationen an, in denen wir die Anzahl der Versuche modellieren müssen, bis eine bestimmte Anzahl von Ereignissen eintritt, anstatt die Anzahl der Ereignisse in einer festen Anzahl von Versuchen.
In diesem umfassenden Handbuch erkunden wir die mathematischen Grundlagen der negativen Binomialverteilung, ihre praktischen Anwendungen und ihre Implementierung in Python und R. Angefangen bei ihren grundlegenden Eigenschaften bis hin zu fortgeschrittenen Anwendungen erarbeiten wir uns ein umfassendes Verständnis dieses leistungsstarken statistischen Instruments.
Die negative Binomialverteilung entstand im 18. Jahrhundert durch die Untersuchung der Wahrscheinlichkeit in Glücksspielen. Diese diskrete Wahrscheinlichkeitsverteilung modelliert die Anzahl der Fehlschläge in einer Folge unabhängiger Bernoulli-Versuche, bevor eine bestimmte Anzahl von Erfolgen erreicht wird. Jeder Versuch muss unabhängig sein und die gleiche Erfolgswahrscheinlichkeit haben.
Um diese Verteilung intuitiv zu verstehen, betrachte ein einfaches Experiment: Du führst Vorstellungsgespräche, bis du drei qualifizierte Bewerber für eine Stelle gefunden hast. Die Verteilung würde die Anzahl der erfolglosen Vorstellungsgespräche (Misserfolge) modellieren, die nötig sind, um diese drei qualifizierten Kandidaten (Erfolge) zu finden. Dies unterscheidet sich grundlegend von der Binomialverteilung, die stattdessen die Anzahl der Erfolge in einer festen Anzahl von Versuchen modelliert - zum Beispiel die Anzahl der qualifizierten Bewerber, die in genau 20 Vorstellungsgesprächen gefunden wurden.
Du siehst also: Auch wenn der Name "negatives Binom" aufhorchen lässt, bedeutet er nichts Negatives im herkömmlichen Sinne. Der "negative" Aspekt ergibt sich aus der historischen Ableitung mit negativen Exponenten.
Die negative Binomialverteilung wird auf viele verschiedene Arten verwendet. Sie wird im Finanzwesen eingesetzt, wo ich sie am häufigsten einsetze. Sie modelliert Szenarien wie die Anzahl der Handelstage bis zum Erreichen eines Gewinnziels oder die Anzahl der Kreditanträge, die geprüft werden, bevor eine bestimmte Anzahl qualifizierter Kreditnehmer gefunden wird.
Generell hat sich die negative Binomialverteilung auch für die Modellierung von Zähldaten bewährt, wenn die Varianz den Mittelwert übersteigt, was als Überdispersion bekannt ist. Während die Poisson-Verteilung davon ausgeht, dass der Mittelwert gleich der Varianz ist, weisen reale Zähldaten oft eine größere Variabilität auf. In der Epidemiologie zum Beispiel schwankt die Zahl der Krankheitsfälle oft stärker, als ein Poisson-Modell vorhersagen würde, sodass die negative Binomialverteilung für die Modellierung der Krankheitsausbreitung besser geeignet ist.
Genetiker verlassen sich bei der Analyse von Sequenzierungsdaten auf diese Verteilung. In RNA-Sequenzierungsexperimenten zeigen die Gene unterschiedliche Expressionsniveaus mit hoher Variabilität. Das negative Binomial modelliert die Anzahl der Sequenz-Reads, die jedem Gen zugeordnet sind, und berücksichtigt dabei sowohl technische als auch biologische Variationen. Dadurch können unterschiedlich exprimierte Gene genauer identifiziert werden als bei Methoden, die von einer konstanten Varianz ausgehen.
In ökologischen Studien nutzen Forscher sie, um die Häufigkeit von Arten zu modellieren. Bei der Untersuchung von Vogelpopulationen kann es vorkommen, dass es in einigen Gebieten nur wenige Vögel gibt, während in anderen große Gruppen leben, was zu einer größeren Varianz als erwartet führt. Die negative Binomialverteilung modelliert diese Verteilungscluster effektiv und hilft Ökologen, die Populationsdynamik zu verstehen und Schutzmaßnahmen zu planen.
Die negative Binomialverteilung wird durch zwei Schlüsselparameter charakterisiert, die ihre Form und ihr Verhalten bestimmen. Das Verständnis dieser Parameter und der mathematischen Darstellung hilft uns zu verstehen, wie diese Verteilung reale Phänomene modelliert. Lass uns diese Merkmale systematisch untersuchen.
Die negative Binomialverteilung hat zwei grundlegende Parameter:
Diese Parameter bestimmen, wie sich die Verteilung verhält. Überlege dir, wie viele Lernpfade nötig sind, um fünf neue Kunden zu gewinnen (r = 5), wenn jeder Lernpfad eine Erfolgschance von 20% hat (p = 0,2). Der Wert von r legt unseren Haltepunkt fest, während p bestimmt, wie lange wir voraussichtlich weiter telefonieren werden.
Wenn wir r erhöhen und p konstant halten, verschiebt sich die Verteilung nach rechts und wird breiter, was zeigt, dass wir mehr Versuche brauchen, um mehr Erfolge zu erzielen. Wenn wir dagegen p erhöhen und r konstant halten, verschiebt sich die Verteilung nach links und wird konzentrierter, was darauf hindeutet, dass in der Regel weniger Versuche nötig sind, wenn der Erfolg wahrscheinlicher ist.
Die Wahrscheinlichkeitsmassenfunktion gibt uns die Wahrscheinlichkeit an, dass wir genau k Misserfolge brauchen, bevor wir r Erfolge erzielen. Für die negative Binomialverteilung lautet die PMF:
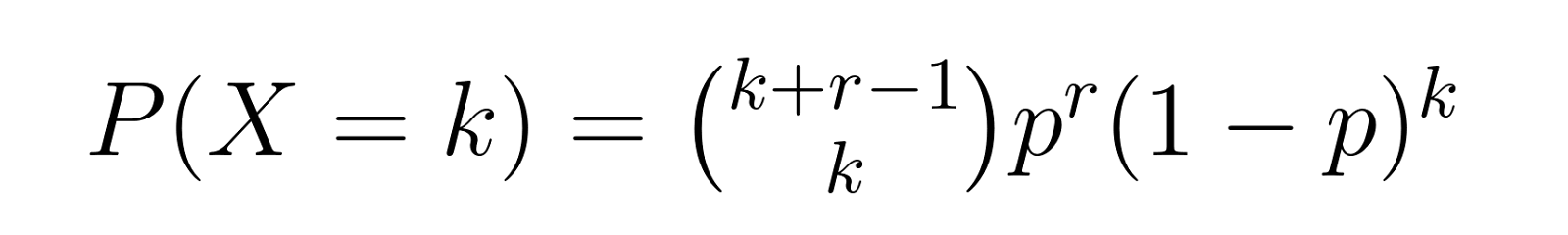
Wo:
Beispiel: Wenn wir in der Qualitätskontrolle 3 fehlerhafte Einheiten benötigen (r = 3) und jede Einheit eine Wahrscheinlichkeit von 10% hat, fehlerhaft zu sein (p = 0,1), können wir bestimmte Wahrscheinlichkeiten berechnen. Die Wahrscheinlichkeit, genau 5 fehlerfreie Einheiten (k = 5) zu erhalten, bevor die dritte fehlerhafte Einheit gefunden wird, ist zum Beispiel:
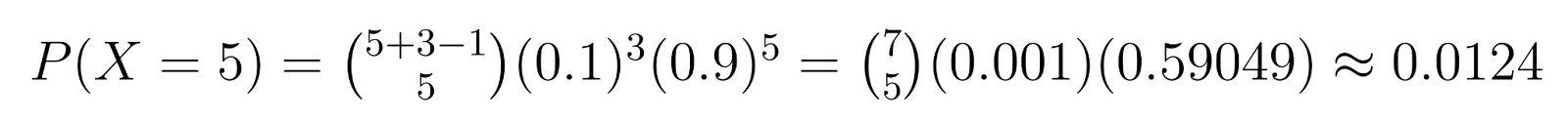
Diese Berechnung ergibt eine Wahrscheinlichkeit von 1,24 %, dass du genau 5 nicht defekte Einheiten brauchst, bevor du die dritte defekte Einheit findest.
Die kumulative Verteilungsfunktion (CDF) baut auf der PMF auf und gibt uns die Wahrscheinlichkeit an, dass wir k oder weniger Fehlschläge benötigen, bevor wir unsere Zielanzahl an Erfolgen erreichen:
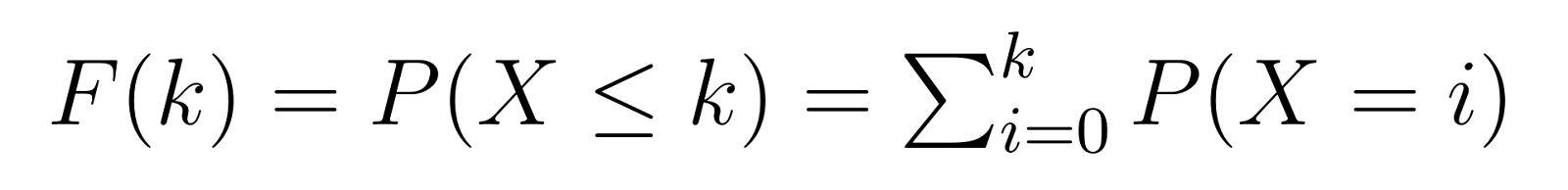
Das bedeutet, dass F(k) die Wahrscheinlichkeit angibt, dass wir höchstens k nicht defekte Einheiten benötigen, bevor wir die dritte defekte Einheit finden. F(5) würde uns zum Beispiel die Wahrscheinlichkeit geben, dass wir 5 oder weniger nicht defekte Einheiten benötigen.
Für den Mittelwert (Erwartungswert) und die Varianz der negativen Binomialverteilung gibt es elegante Formeln, die wichtige Eigenschaften über den Mittelwert (μ) und die Varianz (σ²) offenbaren.
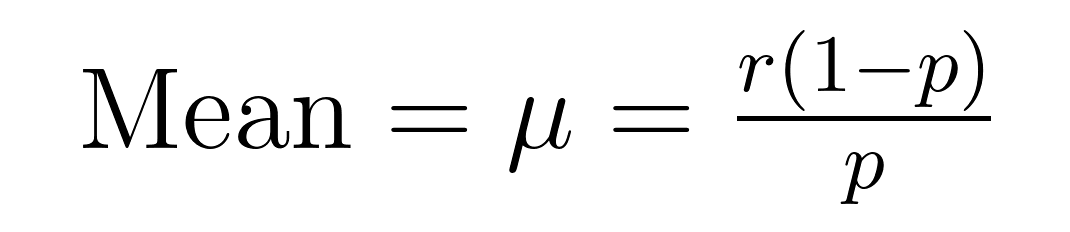
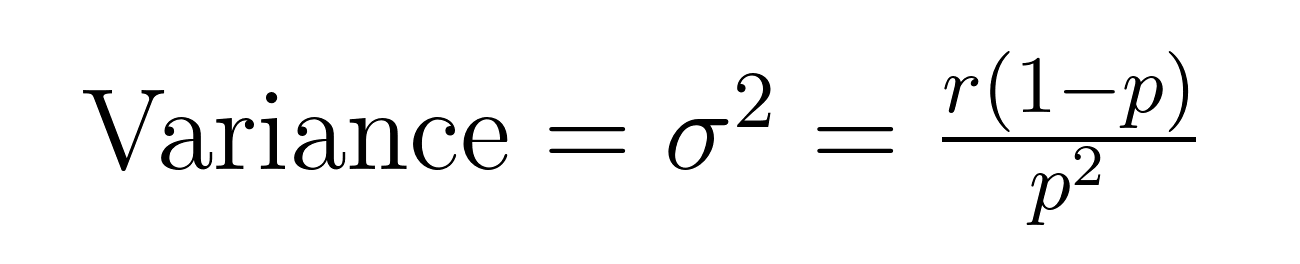
Diese Formeln zeigen, warum sich diese Verteilung hervorragend für die Modellierung von überdispersen Daten eignet. Beachte, dass die Varianz immer um den Faktor 1/p größer ist als der Mittelwert. Aufgrund dieser eingebauten Eigenschaft eignet sie sich besonders für Datensätze, bei denen die Variabilität den Durchschnitt übersteigt.
Wenn wir zum Beispiel Kundendienstanrufe modellieren, bei denen wir erwarten, 5 Fälle (r = 5) mit einer Erfolgsquote von 20 % pro Versuch (p = 0,2) zu lösen, wäre die erwartete Anzahl der Fehlversuche:
Diese höhere Varianz trägt der Tatsache Rechnung, dass einige Fälle schnell gelöst werden können, während andere viele weitere Versuche erfordern, ein Muster, das in der Praxis häufig zu beobachten ist.
Das Verständnis dieser Eigenschaften hilft uns zu erkennen, wann wir die negative Binomialverteilung anwenden und wie wir ihre Ergebnisse effektiv interpretieren können. Diese mathematischen Grundlagen bilden die Grundlage für praktische Anwendungen und die Umsetzung, die wir in den folgenden Abschnitten untersuchen werden.
Überprüfen wir unser früheres Beispiel: Berechne die Wahrscheinlichkeit, genau 5 nicht defekte Einheiten zu erhalten, bevor du die dritte defekte Einheit findest (r=3, p=0,1).
import scipy.stats as stats
import math
def calculate_nb_pmf(k, r, p):
# Calculate binomial coefficient (k+r-1 choose k)
binom_coef = math.comb(k + r - 1, k)
# Calculate p^r * (1-p)^k
prob = (p ** r) * ((1 - p) ** k)
return binom_coef * prob
# Our example parameters
k = 5 # failures (non-defective units)
r = 3 # successes (defective units)
p = 0.1 # probability of success (defective)
# Calculate using our function
prob_manual = calculate_nb_pmf(k, r, p)
print(f"Manual calculation: {prob_manual:.4f}")
# Verify using scipy
prob_scipy = stats.nbinom.pmf(k, r, p)
print(f"SciPy calculation: {prob_scipy:.4f}")Das obige Codeschnipsel sollte die folgende Ausgabe liefern:
Manual calculation: 0.0124
SciPy calculation: 0.0124# Calculate probability mass function
k <- 5 # failures (non-defective units)
r <- 3 # successes (defective units)
p <- 0.1 # probability of success (defective)
# Using dnbinom
prob_r <- dnbinom(k, size = r, prob = p)
print(sprintf("R calculation: %.4f", prob_r))
# Manual calculation for verification
manual_calc <- choose(k + r - 1, k) * p^r * (1-p)^k
print(sprintf("Manual calculation: %.4f", manual_calc))Das obige Codeschnipsel sollte die gleichen Zahlen wie in unserem Python-Beispiel ausgeben:
R calculation: 0.0124
Manual Calculation: 0.0124Beide Umsetzungen bestätigen unsere zuvor berechnete Wahrscheinlichkeit von etwa 0,0124 oder 1,24%.
Wenn du verstehst, wie die negative Binomialverteilung mit anderen Wahrscheinlichkeitsverteilungen zusammenhängt, kannst du besser einschätzen, wann du sie verwenden solltest. Die negative Binomialverteilung hat einzigartige Verbindungen zu mehreren wichtigen Verteilungen in der Statistik.
Die Binomialverteilung dient als grundlegender Ausgangspunkt. Während die Binomialverteilung Erfolge in einer festen Anzahl von Versuchen zählt, kehrt die negative Binomialverteilung dieses Konzept um, indem sie die Versuche zählt, die für eine feste Anzahl von Erfolgen benötigt werden. Diese Verteilungen sind komplementär - wenn du genau 3 Erfolge brauchst und wissen willst, wie hoch die Wahrscheinlichkeit ist, dies in genau 8 Versuchen zu erreichen, verwende die Binomialverteilung. Wenn du wissen willst, wie hoch die Wahrscheinlichkeit ist, dass du genau 8 Versuche brauchst, um 3 Erfolge zu erzielen, verwende die negative Binomialform.
Die Poisson-Verteilung wird bei der Modellierung von Zähldaten oft mit der negativen Binomialverteilung verglichen. Beide behandeln diskrete Ereignisse, aber sie unterscheiden sich in ihren Varianzannahmen. Die Poisson-Verteilung zeichnet sich dadurch aus, dass ihr Mittelwert gleich ihrer Varianz ist. Allerdings weisen reale Zähldaten häufig eine Überdispersion auf, bei der die Varianz den Mittelwert übersteigt. Die negative Binomialverteilung nimmt diese zusätzliche Variabilität auf natürliche Weise auf und eignet sich daher besser für Phänomene wie:
Die geometrische Verteilung ist ein Spezialfall der negativen Binomialverteilung, wenn wir r=1 setzen, was bedeutet, dass wir nur auf einen Erfolg warten. Das macht sie perfekt für die Modellierung von Szenarien wie:
Schließlich kann das negative Binomial als Gamma-Poisson-Gemisch abgeleitet werden, was eine theoretische Grundlage für seine Fähigkeit bietet, mit Überdispersion umzugehen. Diese Beziehung hilft zu erklären, warum die negative Binomialverteilung in hierarchischen Modellen gut funktioniert, in denen die einzelnen Raten des Auftretens gemäß einer Gammaverteilung variieren.
Die negative Binomialverteilung bietet deutliche Vorteile, die sie für die Modellierung realer Phänomene wertvoll machen, hat aber auch wichtige Einschränkungen, die Datenwissenschaftler berücksichtigen sollten.
Die negative Binomialregression erweitert die traditionelle Regression auf Zähldaten, insbesondere wenn die Daten eine Überdispersion aufweisen. Während bei der Poisson-Regression davon ausgegangen wird, dass der Mittelwert gleich der Varianz ist, wird diese Bedingung bei der negativen Binomialregression gelockert, wodurch sie sich besser für reale Anwendungen eignet.
Stell dir ein Call Center-Szenario vor: Wir wollen die Anzahl der Kundendienstanrufe pro Stunde vorhersagen. Unsere Prädiktoren könnten sein:
Die Standard-Poisson-Regression unterschätzt möglicherweise die Schwankungen des Anrufvolumens, vor allem zu Spitzenzeiten oder bei besonderen Ereignissen. Die negative Binomialregression trägt dieser zusätzlichen Variabilität Rechnung und liefert realistischere Vorhersagen und Konfidenzintervalle.
Durch ihre Fähigkeit, komplexe Zähldaten zu modellieren und mit Überstreuung umzugehen, ist die negative Binomialverteilung nach wie vor ein unverzichtbares Instrument für das Verständnis und die Vorhersage von Phänomenen in der realen Welt. Wie du gesehen hast, eignet sie sich hervorragend für die Modellierung von übermäßig verstreuten Daten, sie bietet Flexibilität für die Modellierung einer großen Anzahl verschiedener Szenarien und sie lässt sich sogar auf natürliche Weise auf die Regressionsanalyse ausweiten.
Wenn du dein Wissen über Wahrscheinlichkeitsverteilungen und ihre Anwendungen vertiefen möchtest, bieten dir unsere Kurse in Probabilistik & Statistik eine umfassende Abdeckung dieser Themen. Unsere Kurse beinhalten praktische Übungen mit realen Datensätzen, die dir helfen, sowohl theoretische Konzepte als auch praktische Implementierungen in Python und R zu beherrschen. Ziehe auch unseren Lernpfad "Machine Learning Scientist in Python " in Betracht. Ich verspreche dir, du wirst eine Menge lernen.
Lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
