
Kurs
Feature Engineering für Machine Learning in Python
4 Std.
38.8K
Eine häufige Herausforderung beim maschinellen Lernen ist der Umgang mit kategorischen Variablen (wie Farben, Produkttypen oder Standorten), da die Algorithmen in der Regel numerische Eingaben erfordern. Eine Lösung für dieses Problem ist one-hot encoding.
Die One-Hot-Codierung ist eine Technik zur Darstellung kategorialer Daten als numerische Vektoren, bei der jede eindeutige Kategorie durch eine binäre Spalte mit dem Wert 1 für ihr Vorhandensein und 0 für ihr Fehlen dargestellt wird.
In diesem Artikel werden wir das Konzept des One-Hot-Encoding, seine Vorteile und seine praktische Umsetzung in Python mit Bibliotheken wie Pandas und Scikit-learn untersuchen.
Wenn du auf der Suche nach einem kuratierten Lernpfad zum Thema maschinelles Lernen bist, solltest du dir diesen Lernpfad mit vier Kursen anschauen Grundlagen des maschinellen Lernens mit Python.
Die One-Hot-Codierung ist eine Methode zur Umwandlung kategorischer Variablen in ein Format, das maschinellen Lernalgorithmen zur Verfügung gestellt werden kann, um die Vorhersage zu verbessern. Dabei werden neue binäre Spalten für jede einzelne Kategorie in einem Merkmal erstellt. Jede Spalte steht für eine einzige Kategorie, und ein Wert von 1 oder 0 zeigt an, ob diese Kategorie vorhanden ist oder nicht.
Betrachten wir ein Beispiel, um zu veranschaulichen, wie One-Hot-Codierung funktioniert. Angenommen, wir haben einen Datensatz mit einem einzigen kategorialen Merkmal, Color, das drei Werte annehmen kann: Red, Green, und Blue. Mit der One-Hot-Codierung können wir dieses Merkmal wie folgt umwandeln:
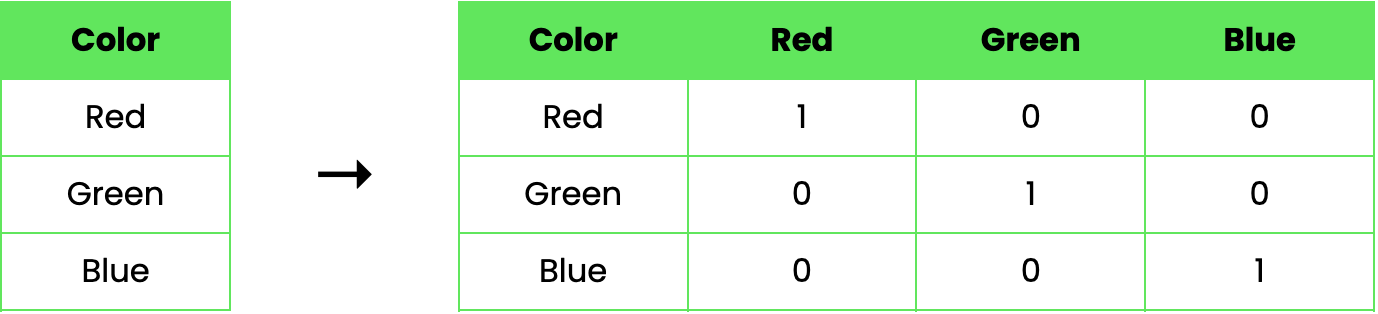
In diesem Beispiel wird die ursprüngliche Spalte "Farbe" durch drei neue binäre Spalten ersetzt, die jeweils eine der Farben darstellen. Ein Wert von 1 bedeutet, dass die Farbe in dieser Reihe vorhanden ist, während eine 0 bedeutet, dass sie nicht vorhanden ist.
Die One-Hot-Codierung ist aus mehreren Gründen eine wichtige Technik der Datenvorverarbeitung. Es wandelt kategorische Daten in ein Format um, das maschinelle Lernmodelle leicht verstehen und nutzen können. Diese Umwandlung ermöglicht es, jede Kategorie unabhängig voneinander zu behandeln, ohne falsche Beziehungen zwischen ihnen zu implizieren.
Außerdem unterstützen viele Bibliotheken für Datenverarbeitung und maschinelles Lernen die One-Hot-Codierung. Sie fügt sich nahtlos in den Workflow der Datenvorverarbeitung ein und erleichtert die Vorbereitung von Datensätzen für verschiedene Algorithmen des maschinellen Lernens.
Die meisten Algorithmen für maschinelles Lernen benötigen numerische Eingaben, um ihre Berechnungen durchzuführen. Kategoriale Daten müssen in ein numerisches Format umgewandelt werden, damit diese Algorithmen effektiv arbeiten können. Die One-Hot-Codierung bietet eine einfache Möglichkeit, diese Umwandlung zu erreichen, sodass kategoriale Variablen in Machine-Learning-Modelle integriert werden können.
Die Label-Codierung ist eine weitere Methode, um kategoriale Daten in numerische Werte umzuwandeln, indem jeder Kategorie eine eindeutige Nummer zugewiesen wird. Dieser Ansatz kann jedoch zu Problemen führen, weil er eine Reihenfolge oder ein Ranking zwischen den Kategorien suggeriert, die in Wirklichkeit gar nicht existieren.
Wenn du zum Beispiel 1 zu Red, 2 zu Green und 3 zu Blue zuordnest, könnte das Modell denken, dass Green größer ist als Red und Blue größer als beide. Dieses Missverständnis kann sich negativ auf die Leistung des Modells auswirken.
Die One-Hot-Kodierung löst dieses Problem, indem sie für jede Kategorie eine eigene binäre Spalte erstellt. Auf diese Weise kann das Modell erkennen, dass jede Kategorie unterschiedlich ist und nichts mit den anderen zu tun hat.
Die Label-Codierung ist nützlich, wenn die kategorialen Daten eine inhärente ordinale Beziehung aufweisen, d.h. die Kategorien haben eine sinnvolle Reihenfolge oder Rangfolge. In solchen Fällen können die numerischen Werte, die durch die Labelcodierung zugewiesen werden, diese Reihenfolge effektiv darstellen, was sie zu einer geeigneten Wahl macht.
Betrachte einen Datensatz mit einem Merkmal, das das Bildungsniveau darstellt. Die Kategorien sind:
High SchoolBachelor's DegreeMaster's DegreePhDDiese Kategorien haben eine klare Reihenfolge: PhD steht für ein höheres Bildungsniveau als Master's Degree, das wiederum höher ist als Bachelor's Degree, und so weiter. In diesem Fall kann die Label-Kodierung die ordinale Natur der Daten effektiv erfassen:
In diesem Beispiel spiegeln die Zahlenwerte die Entwicklung des Bildungsniveaus wider, so dass die Kodierung von Bezeichnungen eine geeignete Wahl ist. Das Modell kann diese Werte richtig interpretieren und versteht, dass höhere Zahlen einem höheren Bildungsniveau entsprechen.
Nachdem wir nun wissen, was One-Hot-Encoding ist und warum es wichtig ist, wollen wir uns ansehen, wie man es in Python implementiert.
Python bietet leistungsstarke Bibliotheken wie Pandas und Scikit-learn, die bequeme und effiziente Möglichkeiten zur One-Hot-Kodierung bieten.
In diesem Abschnitt gehen wir Schritt für Schritt durch die Anwendung der One-Hot-Codierung mit diesen Bibliotheken. Wir beginnen mit der Funktion get_dummies() von Pandas, die schnell und einfach für einfache Kodierungsaufgaben geeignet ist. Dann werden wir Scikit-learns OneHotEncoder erkunden, das mehr Flexibilität und Kontrolle bietet und besonders für komplexere Kodierungsanforderungen nützlich ist.
get_dummies()Pandas bietet eine sehr praktische Funktion, get_dummies(), mit der du direkt aus einem DataFrame einhändig kodierte Spalten erstellen kannst.
Hier erfährst du, wie du ihn verwenden kannst (wir erklären dir den gesamten Code Schritt für Schritt weiter unten):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Zuerst importieren wir die Pandas-Bibliothek. Dann erstellen wir ein Wörterbuch data mit einem einzigen Schlüssel 'Color' und einer Liste von Farbnamen als Werte. Anschließend wandeln wir dieses Wörterbuch in einen Pandas DataFrame df um. Der DataFrame sieht wie folgt aus:
Color
0 Red
1 Green
2 Blue
3 RedMit der Funktion pd.get_dummies() wenden wir die One-Hot-Codierung auf den DataFrame df an. Diese Funktion erkennt automatisch die kategoriale(n) Spalte(n) und erstellt neue binäre Spalten für jede eindeutige Kategorie. Das Argument dtype=int stellt sicher, dass die Kodierung mit 1 und 0 anstelle der standardmäßigen Booleschen Werte durchgeführt wird. Der resultierende DataFrame df_encoded sieht wie folgt aus:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoderUm mehr Flexibilität und Kontrolle über den Kodierungsprozess zu haben, bietet Scikit-learn die Klasse OneHotEncoder. Diese Klasse bietet erweiterte Optionen, z. B. den Umgang mit unbekannten Kategorien und die Anpassung des Encoders an die Trainingsdaten.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Wir importieren die Klasse OneHotEncoder von sklearn.preprocessing, und wir importieren auch numpy. Danach erstellen wir eine Instanz von OneHotEncoder. Der Parameter handle_unknown='ignore' weist den Encoder an, unbekannte Kategorien (Kategorien, die während des Anpassungsprozesses nicht gesehen wurden) während der Transformation zu ignorieren. Dann erstellen wir eine Liste von Listen X, wobei jede innere Liste eine einzelne Farbe enthält. Das sind die Daten, die wir für die Anpassung des Encoders verwenden werden.
Wir passen den Encoder an die Beispieldaten X an. In diesem Schritt lernt der Encoder die eindeutigen Kategorien in den Daten. Wir verwenden den angepassten Encoder, um neue Daten zu transformieren. In diesem Fall transformieren wir eine einzelne Farbe, 'Red'. Die Methode .transform() liefert eine dünnbesetzte Matrix, die wir mit der Methode .toarray() in ein dichtes Array umwandeln.
Das Ergebnis [[1. 0. 0.]] zeigt an, dass 'Red' vorhanden ist (1) und 'Green' und 'Blue' nicht vorhanden sind (0).
Eine große Herausforderung bei der One-Hot-Codierung ist der "Fluch der Dimensionalität". Das passiert, wenn ein kategoriales Merkmal eine große Anzahl eindeutiger Werte hat, was zu einer explosionsartigen Zunahme der Spalten führt. Das kann dazu führen, dass der Datensatz spärlich und rechenintensiv ist. Schauen wir uns an, welche Techniken wir anwenden können, um dieses Problem zu lösen.
Feature-Hashing, auch bekannt als der Hashing-Trick, kann helfen, die Dimensionalität zu reduzieren, indem Kategorien in eine feste Anzahl von Spalten gehasht werden. Bei diesem Ansatz bleibt die Effizienz erhalten, während die Anzahl der Merkmale kontrolliert wird. Hier ist ein Beispiel, wie du das machen kannst:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Wir importieren die notwendigen Bibliotheken, einschließlich FeatureHasher von sklearn.feature_extraction und pandas. Anschließend erstellen wir einen DataFrame mit einem kategorialen Merkmal 'Color'.
Wir initialisieren FeatureHasher mit der gewünschten Anzahl von Ausgangsmerkmalen (n_features=3) und geben den Eingabetyp als 'string' an. Danach wenden wir die Transformationsmethode auf die Spalte 'Color' an und wandeln die resultierende dünnbesetzte Matrix in ein dichtes Array um, das dann in einen DataFrame umgewandelt wird. Zum Schluss drucken wir den DataFrame mit den gehashten Merkmalen aus.
Nach der One-Hot-Codierung können Techniken wie die Hauptkomponentenanalyse (PCA) angewandt werden, um die Anzahl der Dimensionen zu reduzieren und gleichzeitig die wesentlichen Informationen des Datensatzes zu erhalten.
Die PCA kann dabei helfen, die hochdimensionalen Daten in einen niedrigdimensionalen Raum zu komprimieren, so dass sie für Algorithmen des maschinellen Lernens besser handhabbar sind.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)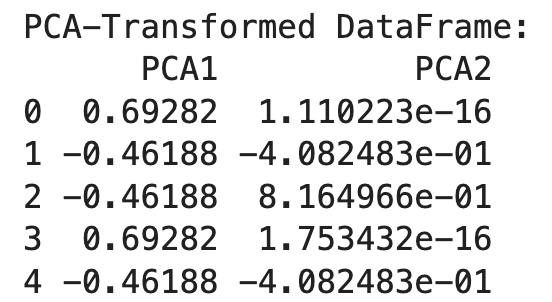
Wir verwenden OneHotEncoder, um das kategoriale Merkmal in ein kodiertes Format umzuwandeln. Das Ergebnis ist ein DataFrame mit binären Spalten für jede Kategorie.
Danach initialisieren wir die PCA mit der gewünschten Anzahl von Komponenten (n_components=2) und wenden sie auf die einhändig kodierten Daten an. Das Ergebnis ist ein transformierter DataFrame mit zwei Hauptkomponenten.
Die PCA hilft dabei, die Dimensionalität der kodierten Daten zu reduzieren, so dass sie besser handhabbar werden und gleichzeitig wichtige Informationen erhalten bleiben. Dieser Ansatz ist besonders nützlich, wenn du mit hochdimensionalen Daten aus der One-Hot-Codierung arbeitest.
Die One-Hot-Codierung ist zwar ein leistungsfähiges Instrument, aber eine unsachgemäße Umsetzung kann zu Problemen wie Multikollinearität oder Ineffizienz bei der Verarbeitung neuer Daten führen. Lass uns einige bewährte Verfahren und Überlegungen untersuchen.
Beim Einsatz von Modellen für maschinelles Lernen kommt es häufig vor, dass in der Testmenge Kategorien gefunden werden, die in der Trainingsmenge nicht vorhanden waren. Scikit-learns OneHotEncoder kann mit unbekannten Kategorien umgehen, indem es sie ignoriert oder sie einer eigenen Spalte zuordnet, damit das Modell neue Daten weiterhin effektiv verarbeiten kann.
Dieses Beispiel zeigt, wie man den Encoder an die Trainingsdaten anpasst und dann sowohl die Trainings- als auch die Testdaten umwandelt, einschließlich der Behandlung von Kategorien, die in der Trainingsmenge nicht vorhanden waren.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)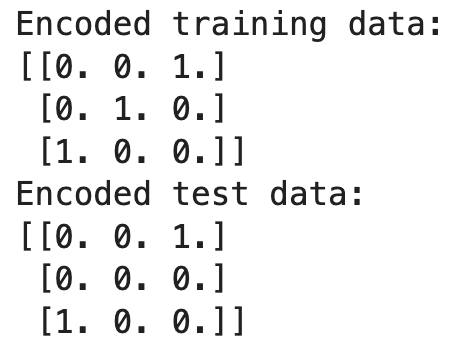
In diesem Beispiel wird der Encoder an die Trainingsdaten angepasst und lernt die Kategorien 'Red', 'Green' und 'Blue'. Bei der Umwandlung der Testdaten stößt er auf 'Yellow', was beim Training nicht der Fall war. Da wir handle_unknown='ignore' eingestellt haben, produziert der Kodierer eine Reihe von Nullen für 'Yellow' und ignoriert damit die unbekannte Kategorie.
Indem wir unbekannte Kategorien auf diese Weise behandeln, können wir sicherstellen, dass dein Modell neue Daten effektiv verarbeiten kann, auch wenn sie bisher unbekannte Kategorien enthalten.
Nach der Anwendung der One-Hot-Codierung ist es wichtig, die ursprüngliche kategoriale Spalte aus dem Datensatz zu entfernen. Die Beibehaltung der ursprünglichen Spalte kann zu Multikollinearität führen, bei der redundante Informationen die Leistung des Modells beeinträchtigen. Stelle sicher, dass jede Kategorie nur einmal im Datensatz vorkommt, um die Integrität zu wahren.
Hier erfährst du, wie du die ursprüngliche kategoriale Spalte nach der Anwendung der One-Hot-Codierung löschen kannst, um Multikollinearität zu vermeiden und sicherzustellen, dass jede Kategorie nur einmal im Datensatz vertreten ist.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
In diesem Beispiel beginnen wir mit einem DataFrame, der eine kategoriale Spalte 'Color' enthält. Mit pd.get_dummies() wenden wir die One-Hot-Codierung auf die Spalte 'Color' an und geben mit columns=['Color'] an, welche Spalte codiert werden soll. Dabei wird die ursprüngliche 'Color' Spalte automatisch gelöscht und durch die einhändig kodierten Spalten ersetzt. Der resultierende DataFrame df_encoded enthält nun binäre Spalten, die jede einzelne Kategorie repräsentieren. So wird sichergestellt, dass jede Kategorie nur einmal vertreten ist und das Risiko der Multikollinearität ausgeschlossen wird.
Durch das Weglassen der ursprünglichen kategorialen Spalte können wir die Integrität des Datensatzes erhalten und die Leistung des maschinellen Lernmodells verbessern.
OneHotEncoder vs. get_dummies()Die Entscheidung zwischen get_dummies() von Pandas und OneHotEncoder von Scikit-learn hängt von deinen Bedürfnissen ab. Für eine schnelle und unkomplizierte Codierung ist get_dummies() bequem und einfach zu bedienen. Für komplexere Szenarien, die mehr Kontrolle und Flexibilität erfordern, wie z. B. die Handhabung unbekannter Kategorien oder die Anpassung des Encoders an bestimmte Daten, ist OneHotEncoder die bessere Wahl.
Die One-Hot-Codierung ist eine leistungsstarke und wichtige Technik, um kategoriale Daten in ein numerisches Format umzuwandeln, das für maschinelle Lernalgorithmen geeignet ist. Sie verbessert die Genauigkeit und Effizienz von maschinellen Lernmodellen, indem sie die Fallstricke der Ordinalität vermeidet und die Verwendung kategorischer Daten erleichtert.
Die Implementierung von One-Hot-Encoding in Python ist mit Tools wie get_dummies() von Pandas und OneHotEncoder von Scikit-learn ganz einfach. Denke daran, die Dimensionalität deiner Daten zu berücksichtigen und unbekannte Kategorien effektiv zu behandeln.
Wenn du mehr über dieses Thema erfahren möchtest, schau dir diesen Kurs über Preprocessing for Maschinelles Lernen in Python.
Lerne maschinelles Lernen mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Javier Canales Luna
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Adel Nehme


